决策树
决策树(红酒数据集)
In [ ]:
from sklearn import tree # 导入树模块
from sklearn.datasets import load_wine # 导入红酒数据集
from sklearn.model_selection import train_test_split # 导入分训练集和测试集的模块
In [3]:
wine = load_wine()
In [4]:
wine
Out[4]:
{'data': array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
...,
[1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,
8.350e+02],
[1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,
8.400e+02],
[1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,
5.600e+02]]),
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2]),
'target_names': array(['class_0', 'class_1', 'class_2'], dtype='<U7'),
'DESCR': 'Wine Data Database\n====================\n\nNotes\n-----\nData Set Characteristics:\n :Number of Instances: 178 (50 in each of three classes)\n :Number of Attributes: 13 numeric, predictive attributes and the class\n :Attribute Information:\n \t\t- 1) Alcohol\n \t\t- 2) Malic acid\n \t\t- 3) Ash\n\t\t- 4) Alcalinity of ash \n \t\t- 5) Magnesium\n\t\t- 6) Total phenols\n \t\t- 7) Flavanoids\n \t\t- 8) Nonflavanoid phenols\n \t\t- 9) Proanthocyanins\n\t\t- 10)Color intensity\n \t\t- 11)Hue\n \t\t- 12)OD280/OD315 of diluted wines\n \t\t- 13)Proline\n \t- class:\n - class_0\n - class_1\n - class_2\n\t\t\n :Summary Statistics:\n \n ============================= ==== ===== ======= =====\n Min Max Mean SD\n ============================= ==== ===== ======= =====\n Alcohol: 11.0 14.8 13.0 0.8\n Malic Acid: 0.74 5.80 2.34 1.12\n Ash: 1.36 3.23 2.36 0.27\n Alcalinity of Ash: 10.6 30.0 19.5 3.3\n Magnesium: 70.0 162.0 99.7 14.3\n Total Phenols: 0.98 3.88 2.29 0.63\n Flavanoids: 0.34 5.08 2.03 1.00\n Nonflavanoid Phenols: 0.13 0.66 0.36 0.12\n Proanthocyanins: 0.41 3.58 1.59 0.57\n Colour Intensity: 1.3 13.0 5.1 2.3\n Hue: 0.48 1.71 0.96 0.23\n OD280/OD315 of diluted wines: 1.27 4.00 2.61 0.71\n Proline: 278 1680 746 315\n ============================= ==== ===== ======= =====\n\n :Missing Attribute Values: None\n :Class Distribution: class_0 (59), class_1 (71), class_2 (48)\n :Creator: R.A. Fisher\n :Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)\n :Date: July, 1988\n\nThis is a copy of UCI ML Wine recognition datasets.\nhttps://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data\n\nThe data is the results of a chemical analysis of wines grown in the same\nregion in Italy by three different cultivators. There are thirteen different\nmeasurements taken for different constituents found in the three types of\nwine.\n\nOriginal Owners: \n\nForina, M. et al, PARVUS - \nAn Extendible Package for Data Exploration, Classification and Correlation. \nInstitute of Pharmaceutical and Food Analysis and Technologies,\nVia Brigata Salerno, 16147 Genoa, Italy.\n\nCitation:\n\nLichman, M. (2013). UCI Machine Learning Repository\n[http://archive.ics.uci.edu/ml]. Irvine, CA: University of California,\nSchool of Information and Computer Science. \n\nReferences\n----------\n(1) \nS. Aeberhard, D. Coomans and O. de Vel, \nComparison of Classifiers in High Dimensional Settings, \nTech. Rep. no. 92-02, (1992), Dept. of Computer Science and Dept. of \nMathematics and Statistics, James Cook University of North Queensland. \n(Also submitted to Technometrics). \n\nThe data was used with many others for comparing various \nclassifiers. The classes are separable, though only RDA \nhas achieved 100% correct classification. \n(RDA : 100%, QDA 99.4%, LDA 98.9%, 1NN 96.1% (z-transformed data)) \n(All results using the leave-one-out technique) \n\n(2) \nS. Aeberhard, D. Coomans and O. de Vel, \n"THE CLASSIFICATION PERFORMANCE OF RDA" \nTech. Rep. no. 92-01, (1992), Dept. of Computer Science and Dept. of \nMathematics and Statistics, James Cook University of North Queensland. \n(Also submitted to Journal of Chemometrics). \n',
'feature_names': ['alcohol',
'malic_acid',
'ash',
'alcalinity_of_ash',
'magnesium',
'total_phenols',
'flavanoids',
'nonflavanoid_phenols',
'proanthocyanins',
'color_intensity',
'hue',
'od280/od315_of_diluted_wines',
'proline']}
In [5]:
wine.data # 我们所需要的数据
Out[5]:
array([[1.423e+01, 1.710e+00, 2.430e+00, ..., 1.040e+00, 3.920e+00,
1.065e+03],
[1.320e+01, 1.780e+00, 2.140e+00, ..., 1.050e+00, 3.400e+00,
1.050e+03],
[1.316e+01, 2.360e+00, 2.670e+00, ..., 1.030e+00, 3.170e+00,
1.185e+03],
...,
[1.327e+01, 4.280e+00, 2.260e+00, ..., 5.900e-01, 1.560e+00,
8.350e+02],
[1.317e+01, 2.590e+00, 2.370e+00, ..., 6.000e-01, 1.620e+00,
8.400e+02],
[1.413e+01, 4.100e+00, 2.740e+00, ..., 6.100e-01, 1.600e+00,
5.600e+02]])
In [6]:
wine.target # 数据集的标签,三分类
Out[6]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2])
In [7]:
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1) # 因为是纵向的连接,所以是axis=1,讲数据集数据和数据集标签以表的形式连接
Out[7]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.640000 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.380000 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.680000 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.800000 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.320000 | 1.04 | 2.93 | 735.0 | 0 |
| 5 | 14.20 | 1.76 | 2.45 | 15.2 | 112.0 | 3.27 | 3.39 | 0.34 | 1.97 | 6.750000 | 1.05 | 2.85 | 1450.0 | 0 |
| 6 | 14.39 | 1.87 | 2.45 | 14.6 | 96.0 | 2.50 | 2.52 | 0.30 | 1.98 | 5.250000 | 1.02 | 3.58 | 1290.0 | 0 |
| 7 | 14.06 | 2.15 | 2.61 | 17.6 | 121.0 | 2.60 | 2.51 | 0.31 | 1.25 | 5.050000 | 1.06 | 3.58 | 1295.0 | 0 |
| 8 | 14.83 | 1.64 | 2.17 | 14.0 | 97.0 | 2.80 | 2.98 | 0.29 | 1.98 | 5.200000 | 1.08 | 2.85 | 1045.0 | 0 |
| 9 | 13.86 | 1.35 | 2.27 | 16.0 | 98.0 | 2.98 | 3.15 | 0.22 | 1.85 | 7.220000 | 1.01 | 3.55 | 1045.0 | 0 |
| 10 | 14.10 | 2.16 | 2.30 | 18.0 | 105.0 | 2.95 | 3.32 | 0.22 | 2.38 | 5.750000 | 1.25 | 3.17 | 1510.0 | 0 |
| 11 | 14.12 | 1.48 | 2.32 | 16.8 | 95.0 | 2.20 | 2.43 | 0.26 | 1.57 | 5.000000 | 1.17 | 2.82 | 1280.0 | 0 |
| 12 | 13.75 | 1.73 | 2.41 | 16.0 | 89.0 | 2.60 | 2.76 | 0.29 | 1.81 | 5.600000 | 1.15 | 2.90 | 1320.0 | 0 |
| 13 | 14.75 | 1.73 | 2.39 | 11.4 | 91.0 | 3.10 | 3.69 | 0.43 | 2.81 | 5.400000 | 1.25 | 2.73 | 1150.0 | 0 |
| 14 | 14.38 | 1.87 | 2.38 | 12.0 | 102.0 | 3.30 | 3.64 | 0.29 | 2.96 | 7.500000 | 1.20 | 3.00 | 1547.0 | 0 |
| 15 | 13.63 | 1.81 | 2.70 | 17.2 | 112.0 | 2.85 | 2.91 | 0.30 | 1.46 | 7.300000 | 1.28 | 2.88 | 1310.0 | 0 |
| 16 | 14.30 | 1.92 | 2.72 | 20.0 | 120.0 | 2.80 | 3.14 | 0.33 | 1.97 | 6.200000 | 1.07 | 2.65 | 1280.0 | 0 |
| 17 | 13.83 | 1.57 | 2.62 | 20.0 | 115.0 | 2.95 | 3.40 | 0.40 | 1.72 | 6.600000 | 1.13 | 2.57 | 1130.0 | 0 |
| 18 | 14.19 | 1.59 | 2.48 | 16.5 | 108.0 | 3.30 | 3.93 | 0.32 | 1.86 | 8.700000 | 1.23 | 2.82 | 1680.0 | 0 |
| 19 | 13.64 | 3.10 | 2.56 | 15.2 | 116.0 | 2.70 | 3.03 | 0.17 | 1.66 | 5.100000 | 0.96 | 3.36 | 845.0 | 0 |
| 20 | 14.06 | 1.63 | 2.28 | 16.0 | 126.0 | 3.00 | 3.17 | 0.24 | 2.10 | 5.650000 | 1.09 | 3.71 | 780.0 | 0 |
| 21 | 12.93 | 3.80 | 2.65 | 18.6 | 102.0 | 2.41 | 2.41 | 0.25 | 1.98 | 4.500000 | 1.03 | 3.52 | 770.0 | 0 |
| 22 | 13.71 | 1.86 | 2.36 | 16.6 | 101.0 | 2.61 | 2.88 | 0.27 | 1.69 | 3.800000 | 1.11 | 4.00 | 1035.0 | 0 |
| 23 | 12.85 | 1.60 | 2.52 | 17.8 | 95.0 | 2.48 | 2.37 | 0.26 | 1.46 | 3.930000 | 1.09 | 3.63 | 1015.0 | 0 |
| 24 | 13.50 | 1.81 | 2.61 | 20.0 | 96.0 | 2.53 | 2.61 | 0.28 | 1.66 | 3.520000 | 1.12 | 3.82 | 845.0 | 0 |
| 25 | 13.05 | 2.05 | 3.22 | 25.0 | 124.0 | 2.63 | 2.68 | 0.47 | 1.92 | 3.580000 | 1.13 | 3.20 | 830.0 | 0 |
| 26 | 13.39 | 1.77 | 2.62 | 16.1 | 93.0 | 2.85 | 2.94 | 0.34 | 1.45 | 4.800000 | 0.92 | 3.22 | 1195.0 | 0 |
| 27 | 13.30 | 1.72 | 2.14 | 17.0 | 94.0 | 2.40 | 2.19 | 0.27 | 1.35 | 3.950000 | 1.02 | 2.77 | 1285.0 | 0 |
| 28 | 13.87 | 1.90 | 2.80 | 19.4 | 107.0 | 2.95 | 2.97 | 0.37 | 1.76 | 4.500000 | 1.25 | 3.40 | 915.0 | 0 |
| 29 | 14.02 | 1.68 | 2.21 | 16.0 | 96.0 | 2.65 | 2.33 | 0.26 | 1.98 | 4.700000 | 1.04 | 3.59 | 1035.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 148 | 13.32 | 3.24 | 2.38 | 21.5 | 92.0 | 1.93 | 0.76 | 0.45 | 1.25 | 8.420000 | 0.55 | 1.62 | 650.0 | 2 |
| 149 | 13.08 | 3.90 | 2.36 | 21.5 | 113.0 | 1.41 | 1.39 | 0.34 | 1.14 | 9.400000 | 0.57 | 1.33 | 550.0 | 2 |
| 150 | 13.50 | 3.12 | 2.62 | 24.0 | 123.0 | 1.40 | 1.57 | 0.22 | 1.25 | 8.600000 | 0.59 | 1.30 | 500.0 | 2 |
| 151 | 12.79 | 2.67 | 2.48 | 22.0 | 112.0 | 1.48 | 1.36 | 0.24 | 1.26 | 10.800000 | 0.48 | 1.47 | 480.0 | 2 |
| 152 | 13.11 | 1.90 | 2.75 | 25.5 | 116.0 | 2.20 | 1.28 | 0.26 | 1.56 | 7.100000 | 0.61 | 1.33 | 425.0 | 2 |
| 153 | 13.23 | 3.30 | 2.28 | 18.5 | 98.0 | 1.80 | 0.83 | 0.61 | 1.87 | 10.520000 | 0.56 | 1.51 | 675.0 | 2 |
| 154 | 12.58 | 1.29 | 2.10 | 20.0 | 103.0 | 1.48 | 0.58 | 0.53 | 1.40 | 7.600000 | 0.58 | 1.55 | 640.0 | 2 |
| 155 | 13.17 | 5.19 | 2.32 | 22.0 | 93.0 | 1.74 | 0.63 | 0.61 | 1.55 | 7.900000 | 0.60 | 1.48 | 725.0 | 2 |
| 156 | 13.84 | 4.12 | 2.38 | 19.5 | 89.0 | 1.80 | 0.83 | 0.48 | 1.56 | 9.010000 | 0.57 | 1.64 | 480.0 | 2 |
| 157 | 12.45 | 3.03 | 2.64 | 27.0 | 97.0 | 1.90 | 0.58 | 0.63 | 1.14 | 7.500000 | 0.67 | 1.73 | 880.0 | 2 |
| 158 | 14.34 | 1.68 | 2.70 | 25.0 | 98.0 | 2.80 | 1.31 | 0.53 | 2.70 | 13.000000 | 0.57 | 1.96 | 660.0 | 2 |
| 159 | 13.48 | 1.67 | 2.64 | 22.5 | 89.0 | 2.60 | 1.10 | 0.52 | 2.29 | 11.750000 | 0.57 | 1.78 | 620.0 | 2 |
| 160 | 12.36 | 3.83 | 2.38 | 21.0 | 88.0 | 2.30 | 0.92 | 0.50 | 1.04 | 7.650000 | 0.56 | 1.58 | 520.0 | 2 |
| 161 | 13.69 | 3.26 | 2.54 | 20.0 | 107.0 | 1.83 | 0.56 | 0.50 | 0.80 | 5.880000 | 0.96 | 1.82 | 680.0 | 2 |
| 162 | 12.85 | 3.27 | 2.58 | 22.0 | 106.0 | 1.65 | 0.60 | 0.60 | 0.96 | 5.580000 | 0.87 | 2.11 | 570.0 | 2 |
| 163 | 12.96 | 3.45 | 2.35 | 18.5 | 106.0 | 1.39 | 0.70 | 0.40 | 0.94 | 5.280000 | 0.68 | 1.75 | 675.0 | 2 |
| 164 | 13.78 | 2.76 | 2.30 | 22.0 | 90.0 | 1.35 | 0.68 | 0.41 | 1.03 | 9.580000 | 0.70 | 1.68 | 615.0 | 2 |
| 165 | 13.73 | 4.36 | 2.26 | 22.5 | 88.0 | 1.28 | 0.47 | 0.52 | 1.15 | 6.620000 | 0.78 | 1.75 | 520.0 | 2 |
| 166 | 13.45 | 3.70 | 2.60 | 23.0 | 111.0 | 1.70 | 0.92 | 0.43 | 1.46 | 10.680000 | 0.85 | 1.56 | 695.0 | 2 |
| 167 | 12.82 | 3.37 | 2.30 | 19.5 | 88.0 | 1.48 | 0.66 | 0.40 | 0.97 | 10.260000 | 0.72 | 1.75 | 685.0 | 2 |
| 168 | 13.58 | 2.58 | 2.69 | 24.5 | 105.0 | 1.55 | 0.84 | 0.39 | 1.54 | 8.660000 | 0.74 | 1.80 | 750.0 | 2 |
| 169 | 13.40 | 4.60 | 2.86 | 25.0 | 112.0 | 1.98 | 0.96 | 0.27 | 1.11 | 8.500000 | 0.67 | 1.92 | 630.0 | 2 |
| 170 | 12.20 | 3.03 | 2.32 | 19.0 | 96.0 | 1.25 | 0.49 | 0.40 | 0.73 | 5.500000 | 0.66 | 1.83 | 510.0 | 2 |
| 171 | 12.77 | 2.39 | 2.28 | 19.5 | 86.0 | 1.39 | 0.51 | 0.48 | 0.64 | 9.899999 | 0.57 | 1.63 | 470.0 | 2 |
| 172 | 14.16 | 2.51 | 2.48 | 20.0 | 91.0 | 1.68 | 0.70 | 0.44 | 1.24 | 9.700000 | 0.62 | 1.71 | 660.0 | 2 |
| 173 | 13.71 | 5.65 | 2.45 | 20.5 | 95.0 | 1.68 | 0.61 | 0.52 | 1.06 | 7.700000 | 0.64 | 1.74 | 740.0 | 2 |
| 174 | 13.40 | 3.91 | 2.48 | 23.0 | 102.0 | 1.80 | 0.75 | 0.43 | 1.41 | 7.300000 | 0.70 | 1.56 | 750.0 | 2 |
| 175 | 13.27 | 4.28 | 2.26 | 20.0 | 120.0 | 1.59 | 0.69 | 0.43 | 1.35 | 10.200000 | 0.59 | 1.56 | 835.0 | 2 |
| 176 | 13.17 | 2.59 | 2.37 | 20.0 | 120.0 | 1.65 | 0.68 | 0.53 | 1.46 | 9.300000 | 0.60 | 1.62 | 840.0 | 2 |
| 177 | 14.13 | 4.10 | 2.74 | 24.5 | 96.0 | 2.05 | 0.76 | 0.56 | 1.35 | 9.200000 | 0.61 | 1.60 | 560.0 | 2 |
178 rows × 14 columns
In [8]:
wine.feature_names # 特征名字
Out[8]:
['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
In [9]:
wine.target_names
Out[9]:
array(['class_0', 'class_1', 'class_2'], dtype='<U7')
In [10]:
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) # 对数据集以7:3的比例进行进行切分
In [11]:
Xtrain.shape # 训练集的数据大小
Out[11]:
(124, 13)
In [12]:
wine.data.shape # 全部数据集的数据大小:178行,13个标签
Out[12]:
(178, 13)
In [13]:
clf = tree.DecisionTreeClassifier(criterion="entropy") # 实例化
clf = clf.fit(Xtrain, Ytrain) # 训练模型
score = clf.score(Xtest, Ytest) # 执行模型,得出精确度
In [14]:
score
Out[14]:
0.8333333333333334
In [17]:
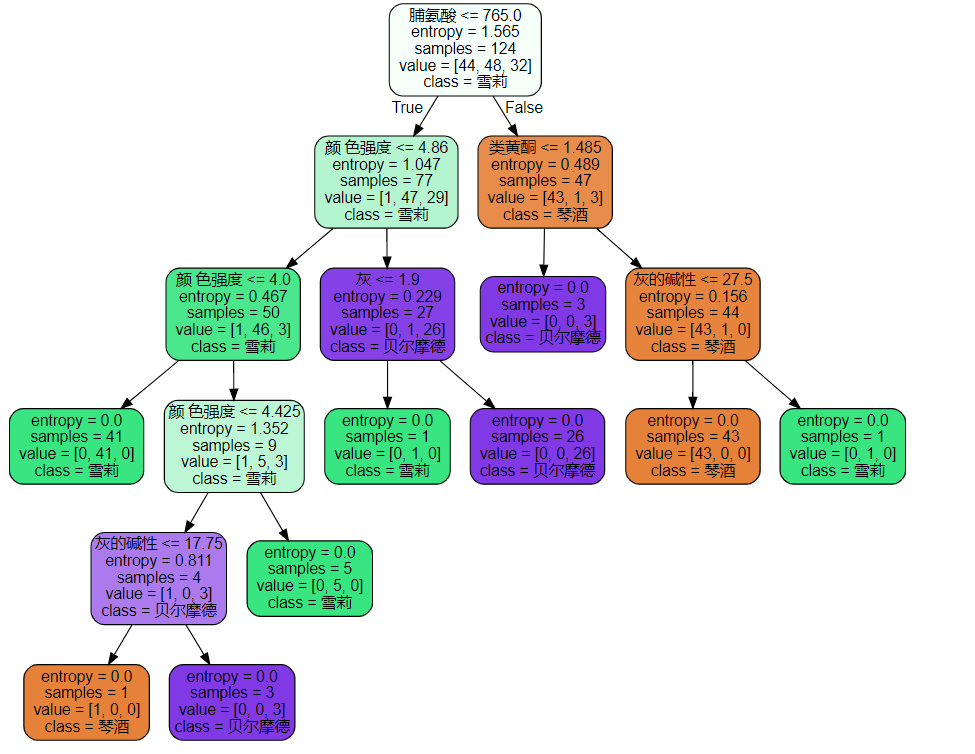
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜 色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
,out_file=None
)
graph = graphviz.Source(dot_data)
graph
Out[17]:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号