Scala 学习笔记
网络上整理的资料:
https://www.cnblogs.com/fxjwind/p/3338829.html
http://qiujj.com/static/Scala-Handbook.htm
http://docs.scala-lang.org/ , Scala官方文档
http://www.scala-lang.org/api/current/#package, 参考手册
http://twitter.github.io/effectivescala/index-cn.html, Effective Scala
原文链接:
https://blog.csdn.net/qq_34291505/article/details/86744581
Scala : 函数式编程
用“var”修饰的变量,可以重新赋予新的值,并且把原值抛弃。在后续重新赋值时,就不用再写“var”了。
而用“val”修饰的变量,则禁止被重新赋值
在首次定义变量时,就必须赋予具体的值来初始化
Scala提倡定义val类型的变量,因为它是函数式编程,而函数式编程的思想之一就是传入函数的参数不应该被改变
第三章 Scala的基本类型
Scala的基本类型
Byte 8-bit有符号整数,补码表示,范围是 到
Short 16-bit有符号整数,补码表示,范围是 到
Int 32-bit有符号整数,补码表示,范围是 到
Long 64-bit有符号整数,补码表示,范围是 到
Char 16-bit字符,Unicode编码,范围是 0 到
String 字符串
Float 32-bit单精度浮点数,符合IEEE 754标准
Double 64-bit双精度浮点数,符合IEEE 754标准
Boolean 布尔值,其值为true或者false
在定义变量时,应该指明变量的类型,如果要显式声明变量的类型,或者无法推断时,则只需在变量名后面加上一个冒号“ : ”
scala> val x: Int = 123
x: Int = 123
scala> val y: String = "123"
y: String = 123
scala> val z: Double = 1.2
z: Double = 1.2
整数字面量
默认情况下推断为Int类型
浮点数字面量
类型默认是Double类型
注意,Double类型的字面量不能赋给Float类型的变量。虽然Float允许扩展成Double类型,但是会发生精度损失
val b = -3.2f
字符与字符串字面量
以单引号' '包起来的一个字符,采用Unicode编码
字符串就是用双引号" "包起来的字符序列,长度任意,允许掺杂转义字符。此外,也可以用前后各三个双引号""" """包起来,这样字符串里也能出现双引号,而且转义字符不会被解读(类似于Python r)
scala> val d = '\\'
d: Char = \
scala> val b = """So long \u0041 String \\\'\"!"""
b: String = So long A String \\\'\"!
字符串插值
表达式可以被嵌入在字符串字面量中并被求值,
第一种形式是s插值器,即在字符串的双引号前加一个s,从美元符号开始到首个非标识符字符(字母、数字、下划线和操作符的组合称为标识符,以及反引号对` `包起来的字符串)的部分会被当作表达式,如果有非标识符字符,就必须放在花括号里,且左花括号要紧跟美元符号
第二种形式是raw插值器,它与s插值器类似,只不过不识别转义字符
第三种形式是f插值器,允许给内嵌的表达式加上printf风格的指令,指令放在表达式之后并以百分号开始
scala> raw"\\\\"
res2: String = \\\\
scala> printf(f"${math.Pi}%.5f")
3.14159
第四章 Scala基础——函数及其几种形式
Scala的函数定义以“def”开头。
接着是用圆括号“( )”包起来的参数列表。在参数列表里,多个参数用逗号隔开,并且每个参数名后面要紧跟一个冒号以及显式声明的参数类型,因为编译器在编译期间无法推断出入参类型。写完参数列表后,应该紧跟一个冒号,再添加函数返回结果的类型。最后,再写一个等号“=”,等号后面是用花括号“{ }”包起来的函数体。
用“def”开始函数定义 | 函数名 | | 参数及参数类型 | | | 函数返回结果的类型 | | | | 等号 | | | | | def max(x: Int, y: Int): Int = { if(x > y) x else | y | } | | 花括号里定义函数体
建议一行只写一条完整的语句,句末分号省略,让编译器自动推断
函数的返回结果
编译器会自动为函数体里的最后一个表达式加上“return”,将其作为返回结果。建议不要显式声明“return”,这会引发warning
返回结果有一个特殊的类型——Unit,表示没有值返回。
等号与函数体
当函数的返回类型没有显式声明时,那么这个等号可以省略,但是返回类型一定会被推断成Unit类型,不管有没有值返回
函数的返回类型显式声明时,则无论如何都不能省略等号。建议写代码时不要省略等号
------------- 有等号省返回类型就会推断类型。
------------- 没有等号一定是Unit
无参函数
如果一个函数没有参数,那么可以写一个空括号作参数列表,也可以不写。如果有空括号,那么调用时可以写也可以不写空括号
方法
方法其实就是定义在class、object、trait里面的函数
嵌套函数
局部函数可以直接使用外层函数的参数,也可以直接使用外层函数的内部变量
函数字面量
可以把一个函数当参数传递给另一个函数,也可以让一个函数返回一个函数,亦可以把函数赋给一个变量,又或者像定义一个值那样在函数里定义别的函数(即前述的嵌套函数)
函数字面量是一种匿名函数的形式,它可以存储在变量里、成为函数参数或者当作函数返回值,其定义形式为:
(参数1: 参数1类型, 参数2: 参数2类型, ...) => { 函数体 }
通常,函数字面量会赋给一个变量,这样就能通过“变量名(参数)”的形式来使用函数字面量,在参数类型可以被推断的情况下,可以省略类型,并且参数只有一个时,圆括号也可以省略。
函数字面量的形式可以更精简,即只保留函数体,并用下划线“_”作为占位符来代替参数。在参数类型不明确时,需要在下划线后面显式声明其类型。多个占位符代表多个参数
scala> val f = (_: Int) + (_: Int) f: (Int, Int) => Int = $$Lambda$1072/1534177037@fb42c1c scala> f(1, 2) res0: Int = 3
scala> val add = (x: Int) => { (y: Int) => x + y }
add: Int => (Int => Int) = $$Lambda$1192/1767705308@55456711
scala> add(1)(10)
res0: Int = 11
x=1,y=10
scala> def aFunc(f: Int => Int) = f(1) + 1
aFunc: (f: Int => Int)Int
scala> aFunc(x => x + 1)
res1: Int = 3
部分应用函数
有一个函数定义为“def max(...) ...”,若想要把这个函数存储在某个变量里,不能直接写成“val x = max”的形式,而必须像函数调用那样,给出一部分参数,故而称作部分应用函数(如果参数全给了,就成了函数调用)
scala> def sum(x: Int, y: Int, z: Int) = x + y + z sum: (x: Int, y: Int, z: Int)Int scala> val a = sum(1, 2, 3) a: Int = 6 scala> val b = sum(1, _: Int, 3) b: Int => Int = $$Lambda$1204/1037479646@5b0bfe86 scala> b(2) res0: Int = 6 scala> val c = sum _ c: (Int, Int, Int) => Int = $$Lambda$1208/1853277442@5e4c26a1 scala> c(1, 2, 3) res1: Int = 6 ————————————————
一个参数都不给的部分应用函数,只需要在函数名后面给一个下划线即可,注意函数名和下划线之间必须有空格
如果部分应用函数一个参数都没有给出,比如例子中的c,那么在需要该函数作入参的地方,下划线也可以省略
scala> def needSum(f: (Int, Int, Int) => Int) = f(1, 2, 3)
needSum: (f: (Int, Int, Int) => Int)Int
scala> needSum(sum)
res3: Int = 6
闭包
一个函数除了可以使用它的参数外,还能使用定义在函数以外的其他变量. 使用自由变量的函数称为闭包。
闭包捕获的自由变量,后续若新建同名的自由变量来覆盖前面的定义,新自由变量与已创建的闭包无关
如果闭包捕获的自由变量本身是一个可变对象(例如var类型变量),那么闭包会随之改变
函数的特殊调用形式
具名参数
调用时显式声明参数名并给其赋值
默认参数值
调用函数时缺省了这个参数,那么就会使用定义时给的默认值
重复参数
函数的最后一个参数标记为重复参数,其形式为在最后一个参数的类型后面加上星号“*”, (---- python 中的可变长度参数)
类型为“T*”的参数的实际类型是“Array[T]”,即若干个T类型对象构成的数组。但不可将arrary 作为参数传入,而应该一个一个传入。除非用“变量名: _*”的形式告诉编译器把数组元素一个一个地传入
def addMany(msg: String, num: Int*) =
addMany("sum = ", 1, 2, 3)
addMany("sum = ", Array(1, 2, 3): _*)
柯里化
Scala有一个独特的语法——柯里化,也就是一个函数可以有任意个参数列表
def addCurry(x: Int)(y: Int)(z: Int) = x + y + z
传名参数
无参函数,那么通常的类型表示法是“() => 函数的返回类型”
传名参数的类型表示法是“=> 函数的返回类型”
调用该函数时,传递进去的函数字面量则可以只写“函数体”
// 传名参数的用法,注意因为去掉了空括号,所以调用predicate时不能有括号 def byNameAssert(predicate: => Boolean) = if(assertionEnabled && !predicate) throw new AssertionError // 传名参数版本的调用,看上去更自然 byNameAssert(5 > 3)
def xxx(f: T => U, ...) ...”或 “def xxx(...): T => U”的代码,要理解前者表示需要传入一个函数作为参数,后者表示函数返回的对象是一个函数
第五章 Scala基础——类和对象
一个类就是一个类型,不同的类就是不同的类型
val或var类型的变量,它们被称为“字段”;还可以定义“def”函数,它们被称为“方法”;
字段也叫“实例变量”,因为每个被构造出来的对象都有其自己的字段
用new构造出来的对象可以赋给变量
val类型的变量只能与初始化时的对象绑定,不能再被赋予新的对象。一旦对象与变量绑定了,便可以通过“变量名.成员”的方式来多次访问对象的成员
Scala的类成员默认都是公有的,没有“public”这个关键字。如果不想某个成员被外部访问,则可以在前面加上关键字“private”来修饰
类的构造方法
主构造方法
Scala则不需要显式定义构造方法 ,而是把类内部非字段、非方法的代码都当作“主构造方法”。
类名后面可以定义若干个参数列表,用于接收参数,这些参数将在构造对象时用于初始化字段并传递给主构造方法使用
scala> class Students(n: String) { | val name = n | println("A student named " + n + " has been registered.") | } defined class Students scala> val stu = new Students("Tom")
辅助构造方法
辅助构造方法都是以“def this(......)”来开头的
而且第一步行为必须是调用该类的另一个构造方法,即第一条语句必须是“this(......)”——要么是主构造方法,要么是之前的另一个辅助构造方法。这种规则的结果就是任何构造方法最终都会调用该类的主构造方法,使得主构造方法成为类的单一入口。
scala> class Students(n: String) { | val name = n | def this() = this("None") | println("A student named " + n + " has been registered.") | } defined class Students scala> val stu = new Students
无析构函数
私有主构造方法
在类名与类的参数列表之间加上关键字“private”,那么主构造方法就是私有的,只能被内部定义访问,外部代码构造对象时就不能通过主构造方法进行
class Students private (n: String, m: Int)
val stu = new Students("Bill", 90) ---------------- error
val stu = new Students("Bill') ----------------correct
重写toString方法
类的toString方法,这个方法返回一个字符串,并在构造完一个对象时被自动调用,返回结果交给解释器打印.这个方法是继承来的,要重写它必须在前面加上关键字“override”
scala> class Students(n: String) {
| val name = n
| override def toString = "A student named " + n + "."
| }
defined class Students
————————————————
方法重载
重载是一个类里有多个不同版本的同名方法,重写是子类覆盖定义了超类的某个方法
方法虽然同名,但是它们是不同的,因为函数真正的特征标是它的参数,而不是函数名或返回类型
类参数
在类参数前加上val或var来修饰,这样就会在类的内部会生成一个与参数同名的公有字段
除此之外,还可以加上关键字private、protected或override来表明字段的权限
scala> class Students(val name: String, var score: Int) { | def exam(s: Int) = score = s | override def toString = name + "'s score is " + score + "." | } defined class Students
单例对象与伴生对象
除了用new可以构造一个对象,也可以用“object”开头定义一个对象。它类似于类的定义,只不过不能像类那样有参数,也没有构造方法
object定义的对象只能有这一个,故而得名“单例对象”。
如果某个单例对象和某个类同名,那么单例对象称为这个类的“伴生对象”,同样,类称为这个单例对象的“伴生类”。伴生类和伴生对象必须在同一个文件里,而且两者可以互访对方所有成员
Scala的做法是把类内所有的静态变量从类里移除,转而集中定义在伴生对象里,让静态变量属于伴生对象这个独一无二的对象。
单例对象里面可以定义字段和方法。Scala允许在类里定义别的类和单例对象,所以单例对象也可以包含别的类和单例对象的定义
单例对象除了用作伴生对象,通常也可以用于打包某方面功能的函数系列成为一个工具集,或者包含主函数成为程序的入口
每个单例对象有自己独特的类型,即object.type
工厂对象与工厂方法
义一个方法专门用来构造某一个类的对象,那么这种方法就称为“工厂方法”。包含这些工厂方法集合的单例对象,也就叫“工厂对象”
通常,工厂方法会定义在伴生对象里。
使用工厂方法的好处是可以不用直接使用new来实例化对象,改用方法调用,而且方法名可以是任意的,这样对外隐藏了类的实现细节
// students.scala class Students(val name: String, var score: Int) { def exam(s: Int) = score = s override def toString = name + "'s score is " + score + "." } object Students { def registerStu(name: String, score: Int) = new Students(name, score) }
apply方法
apply,如果定义了这个方法,那么既可以显式调用——“对象.apply(参数)” ,也可以隐式调用——“对象(参数)”。隐式调用时,编译器会自动插入缺失的“.apply”。
通常,在伴生对象里定义名为apply的工厂方法,就能通过“伴生对象名(参数)”来构造一个对象
也常常在类里定义一个与类相关的、具有特定行为的apply方法,让使用者可以隐式调用,进而隐藏相应的实现细节
// students2.scala class Students2(val name: String, var score: Int) { def apply(s: Int) = score = s def display() = println("Current score is " + score + ".") override def toString = name + "'s score is " + score + "." } object Students2 { def apply(name: String, score: Int) = new Students2(name, score) }
scala> val stu2 = Students2("Jack", 60)
stu2: Students2 = Jack's score is 60.
scala> stu2(80)
scala> stu2.display
Current score is 80.
主函数
主函数是Scala程序唯一的入口
要提供这样的入口,则必须在某个单例对象里定义一个名为“main”的函数,而且该函数只有一个参数,类型为字符串数组Array[String],函数的返回类型是Unit
// students2.scala class Students2(val name: String, var score: Int) { def apply(s: Int) = score = s def display() = println("Current score is " + score + ".") override def toString = name + "'s score is " + score + "." } object Students2 { def apply(name: String, score: Int) = new Students2(name, score) } // main.scala object Start { def main(args: Array[String]) = { try { val score = args(1).toInt val s = Students2(args(0), score) println(s.toString) } catch { case ex: ArrayIndexOutOfBoundsException => println("Arguments are deficient!") case ex: NumberFormatException => println("Second argument must be a Int!") } } }
使用命令“scalac students2.scala main.scala”将两个文件编译后,就能用命令“scala Start 参数1 参数2”来运行程序
第六章 Scala基础——操作符即方法
Scala并不存在操作符的概念,这些所谓的操作符,例如算术运算的加减乘除,逻辑运算的与或非,比较运算的大于小于等等,其实都是定义在“class Int”、“class Double”等类里的成员方法
表达式“1 + 2”的真正形式应该是“1.+(2)”
Scala里任何类定义的成员方法都是操作符,而且方法调用都能写成操作符的形式:去掉句点符号,并且方法参数只有一个时可以省略圆括号。
前缀操作符
前缀操作符只有“+”、“-”、“!”和“~”四个,相对应的方法名分别是“unary_+”、“unary_-”、“unary_!”和“unary_~”
中缀操作符
两个操作数中的一个是调用该方法的对象,一个是传入该方法的参数,参数那一边没有数量限制,只是多个参数需要放在圆括号里。Scala规定,以冒号“ : ”结尾的操作符,其右操作数是调用该方法的对象,其余操作符都是把左操作数当调用该方法的对象
后缀操作符
对象的相等性
让“==”和“!=”比较自然相等性
为了比较引用相等性,Scala提供了“eq”和“ne”方法
第七章 Scala基础——类继承
通过在类的参数列表后面加上关键字“extends”和被继承类的类名,就完成了一个继承的过程。被继承的类称为“超类”或者“父类”,而派生出来的类称为“子类”
最顶层的类通常也叫“基类”
调用超类的构造方法
class 子类(子类对外接收的参数) extends 超类(子类给超类的参数)
Scala只允许主构造方法调用超类的构造方法,而这种写法就是子类的主构造方法在调用超类的构造方法
重写超类的成员
通常,超类的成员都会被子类继承,除了两种成员:一是超类中用“private”修饰的私有成员,二是被子类重写的成员。
scala> class Metal {
| val state = "solid"
| }
defined class Metal
scala> class Mercury extends Metal {
| override val state = "liquid"
| }
defined class Mercury
关键字“override”是必须具备的,这是为了防止意外的重写
不可重写的成员
超类成员在开头用关键字“final”修饰,那么子类就只能继承,而不能重写。
“final”也可以用于修饰class,那么这个类就禁止被其他类继承。
无参方法与字段
Scala允许超类的无参方法被子类重写为字段,但是字段不能反过来被重写为无参方法,而且方法的返回类型必须和字段的类型一致
字段与方法的区别在于:字段一旦被初始化之后,就会被保存在内存中,以后每次调用都只需直接读取内存即可;方法不会占用内存空间,但是每次调用都需要执行一遍程序段,速度比字段要慢。因此,到底定义成无参方法还是字段,就是在速度和内存之间折衷
同处一个命名空间的定义类型,在同一个作用域内不能以相同的名字同时出现。例如,同一个类里不能同时出现同名的字段、无参方法和单例对象
以下错误
scala> class A { | val a = 10 | object a | }
子类型多态与动态绑定
类型为超类的变量可以指向子类的对象,这一现象被称为子类型多态,也是面向对象的多态之一
调用的方法要运行哪个版本,是由变量指向的对象来决定的
抽象类
里包含了没有具体定义的成员——没有初始化的字段或没有函数体的方法,那么这个类就是抽象类,必须用关键字“abstract”修饰。相应的成员称为抽象成员,不需要“abstract”的修饰
因为存在抽象成员,所以这个类不可能构造出具体的对象
抽象类“声明”了抽象成员,却没有立即“定义”它。如果子类补齐了抽象成员的相关定义,就称子类“实现”了超类的抽象成员。子类实现超类的抽象成员时,关键字“override”可写可不写
关于多重继承
Scala没有多重继承,也就是说,在“extends”后面只能有一个类,
多重继承不好用,但是它实现的功能在某些时候又不可或缺。为此,Scala专门设计了“特质”
Scala类的层次结构
最顶部的类是抽象类Any,它是所有类的超类。Any类定义了几个成员方法,如下表所示:
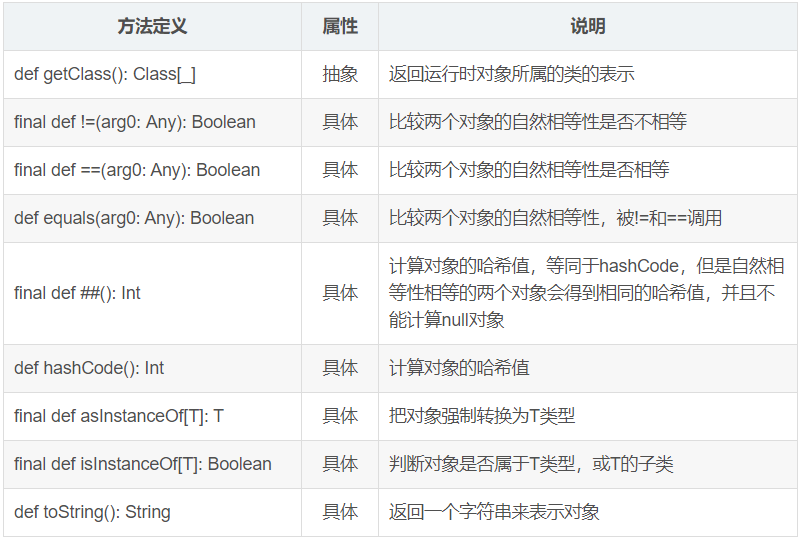
不能出现同名的方法,若确实需要自定义版本,则记得带上“override”
第八章 Scala基础——特质
Scala没有多重继承,为了提高代码复用率,故而创造了新的编程概念——特质。
用关键字“trait”为开头来定义的,它与单例对象很像,两者都不能有入参。但是,单例对象天生就是具体的,特质天生就是抽象的,
某个类混入一个特质后,就包含了特质的所有公有成员,而且也可以用“override”来重写特质的成员。
Scala只允许继承自一个类,但是对特质的混入数量却没有限制,故而可用于替代多重继承语法。
要混入一个特质,可以使用关键字“extends”。但如果“extends”已经被占用了,比如已经拿去继承一个类或混入一个特质,那么后续则通过关键字“with”来混入其他特质。
scala> class A { | val a = "Class A" | } defined class A scala> trait B { | val b = "Trait B" | } defined trait B scala> trait C { | def c = "Trait C" | } defined trait C scala> object D extends A with B with C defined object D scala> D.a res0: String = Class A scala> D.b res1: String = Trait B scala> D.c res2: String = Trait C
特质的层次
特质也可以继承自其他类,或混入任意个特质,这样该特质就是关键字“extends”引入的那个类/特质的子特质
特质对混入有一个限制条件:那就是要混入该特质的类/单例对象/特质,它的超类必须是待混入特质的超类,或者是待混入特质的超类的子类。
scala> class A defined class A scala> class B extends A defined class B scala> class C defined class C scala> trait D extends A defined trait D scala> trait E extends B defined trait E scala> class Test1 extends D defined class Test1 scala> class Test2 extends A with D defined class Test2 scala> class Test3 extends B with D defined class Test3 scala> class Test4 extends C with D <console>:13: error: illegal inheritance; superclass C is not a subclass of the superclass A of the mixin trait D class Test4 extends C with D ^ scala> class Test5 extends A with E <console>:13: error: illegal inheritance; superclass A is not a subclass of the superclass B of the mixin trait E class Test5 extends A with E
类Test1直接混入特质D,这样隐式继承自D的超类——类A,所以合法。类Test2和Test3分别继承自类A和A的子类,所以也允许混入特质D。类Test4的超类是C,而C与A没有任何关系,所以非法。类Test5的超类是A,特质E的超类是B,尽管类A是类B的超类,这也仍然是非法的。
混入特质的类/单例对象/特质,其超类必须是待混入特质的超类或超类的子类。
混入特质的简便方法
new Trait1 with Trait2 ... { definition }
这其实是定义了一个匿名类,这个匿名类混入了这些特质,并且花括号内是该匿名类的定义。然后使用new构造了这个匿名类的一个对象,其等效的代码就是:
class AnonymousClass extends Trait1 with Trait2 ... { definition }
new AnonymousClass
特质的线性化叠加计算
多重继承一个很明显的问题是,当子类调用超类的方法时,若多个超类都有该方法的不同实现,那么需要附加额外的语法来确定具体调用哪个版本
Scala的特质则是采取一种线性化的规则来调用特质中的方法
在特质里,“super”调用是动态绑定的。也就是说,按特质本身的定义,无法确定super调用的具体行为;直到特质混入某个类或别的特质,有了具体的超类方法,才能确定super的行为。这是实现线性化的基础。
太复杂了,如果用到参考:https://blog.csdn.net/qq_34291505/article/details/86773401
第九章 Scala基础——包和导入
包是以关键字“package”为开头来定义的。可以用花括号把包的范围包起来
在包里,可以定义class、object和trait,也可以定义别的package。
如果编译一个包文件,那么会在当前路径下生成一个与包名相同的文件夹,文件夹里是包内class、object和trait编译后生成的文件
如果多个文件的顶层包的包名相同,那么编译后的文件会放在同一个文件夹内。
包的层次和精确代码访问 (了解,最好用import)
包里还可以定义包,所以包也有层次结构
包也可以通过句点符号来按路径层次访问
Scala的包是嵌套的
为了访问不同文件最顶层包的内容,Scala定义了一个隐式的顶层包“_root_”
// launch.scala package launch { class Booster3 } // bobsrockets.scala package bobsrockets { package navigation { package launch { class Booster1 } class MissionControl { val booster1 = new launch.Booster1 val booster2 = new bobsrockets.launch.Booster2 val booster3 = new _root_.launch.Booster3 } } package launch { class Booster2 }
import导入
如果每次都按精确访问方式来编程,则显得过于繁琐和复杂
Scala的import有三点灵活性:
①可以出现在代码的任意位置,而不仅仅是开头。
②除了导入包内所含的内容,还能导入对象(单例对象和new构造的对象都可以)和包自身,甚至函数的参数都能作为对象来导入。
③可以重命名或隐藏某些成员。
package A { package B { class M } package C { object N }
通过语句“import A.B”就能把包B导入。当要访问M时,只需要写“B.M”而不需要完整的路径。通过“import A.B.M”和“import A.C.N”就分别导入了类M和对象N。此时访问它们只需要写M和N即可。
路径最后的元素可以放在花括号里,这样就能导入一个或多个元素,例如通过“import A.{B, C}”就导入了两个包
如果要导入所有的元素,则使用下划线。例如“import A._”或“import A.{_}”就把包B和C都导入了
如果写成“import A.{B => packageB}”,就是在导入包B的同时重命名为“packageB”
如果写成“import A.{B => _, _}”,就是把包B进行隐藏,而导入A的其他元素
自引用
Scala有一个关键字“this”,用于指代对象自己
访问修饰符
包、类和对象的成员都可以标上访问修饰符“private”和“protected”
用“private”修饰的成员是私有的,只能被包含它的包、类或对象的内部代码访问
用“protected”修饰的成员是受保护的,除了能被包含它的包、类或对象的内部代码访问,还能被子类访问(只有类才有子类)
还可以加上限定词。假设X指代某个包、类或对象,那么private[X]和protected[X]就是在不加限定词的基础上,把访问权限扩大到X的内部。
X还能是自引用关键字“this”
用private[this]和protected[this]修饰的成员x,只能通过“this.x”的方式来访问。
伴生对象和伴生类共享访问权限,即两者可以互访对方的所有私有成员。在伴生对象里使用“protected”没有意义,因为伴生对象没有子类。特质使用“private”和“protected”修饰成员也没有意义
包对象
包对象用关键字组合“package object”为开头来定义,其名称与关联的包名相同,有点类似伴生类与伴生对象的关系。
包对象不是包,也不是对象,它会被编译成名为“package.class”的文件,该文件位于与它关联的包的对应文件夹里。为了保持路径同步,建议定义包对象的文件命名为“package.scala”,并和定义关联包的文件放在同一个目录下
第十章 Scala基础——集合
Scala里常见的集合有:数组、列表、集、映射、序列、元组、数组缓冲和列表缓冲
数组
Scala的数组类名为Array。Array是一个具体的类,因此可以通过new来构造一个数组对象。但是所有元素的类型必须一致。
new Array[T](n)
方括号里的T表示元素的类型,它可以显式声明,也可以通过传入给构造方法的对象来自动推断。圆括号里的n代表元素个数,它必须是一个非负整数,如果n等于0则表示空数组
Scala的数组下标却是写在圆括号里。
Array的伴生对象里还定义了一个apply工厂方法, 也可以用下面的方式定义:
val charArray = Array('a', 'b', 'c')
列表
往头部增加新元素也是消耗定长时间,但是对尾部进行操作则需要线性化的时间
列表也是定长的,且每个元素的类型相同、不可再重新赋值,有点像不可写入的数组
val intList = List(1, 1, 10, -5)
列表定义了一个名为“::”的方法,在列表头部添加新元素。注意,这会构造一个新的列表对象,而不是直接修改旧列表,因为列表是不可变的
1 :: List(2, 3)
还有一个名字相近的方法——:::,它用于拼接左、右两个列表,返回新的列表:
List(1, 2) ::: List(2, 1)
Nil,它表示空列表
1 :: 2 :: 3 :: Nil
数组缓冲与列表缓冲
因为列表往尾部添加元素很慢,所以一种可行方案是先往列表头部添加,再把列表整体翻转
通过“ArrayBuffer/ListBuffer += value”可以往缓冲的尾部添加元素,通过“value +=: ArrayBuffer/ListBuffer”可以往缓冲的头部添加元素,但只能通过“ArrayBuffer/ListBuffer -= value”往缓冲的尾部删去第一个符合的元素。往尾部增加或删除元素时,元素数量可以不只一个
在数组缓冲和列表缓冲的头部、尾部都能添加、删去元素,并且耗时是固定的,只不过数组缓冲要比数组慢一些。
scala> import scala.collection.mutable.{ArrayBuffer, ListBuffer} import scala.collection.mutable.{ArrayBuffer, ListBuffer} scala> val ab = new ArrayBuffer[Int]() ab: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer() scala> ab += 10 res0: ab.type = ArrayBuffer(10) scala> -10 +=: ab res1: ab.type = ArrayBuffer(-10, 10) scala> ab -= -10 res2: ab.type = ArrayBuffer(10) scala> val lb = new ListBuffer[String]() lb: scala.collection.mutable.ListBuffer[String] = ListBuffer() scala> lb += ("abc", "oops", "good") res3: lb.type = ListBuffer(abc, oops, good) scala> lb -= "abc" res4: lb.type = ListBuffer(oops, good) scala> "scala" +=: lb res5: lb.type = ListBuffer(scala, oops, good)
以通过方法“toArray”或“toList”把缓冲的数据构造成一个数组或列表对象。注意,这是构造一个新的对象,原有缓冲仍然存在
元组
和列表一样也是不可变的。元组的特点是可以包含不同类型的对象。其字面量写法是在圆括号里编写用逗号间隔的元素。
元组最常用的地方是作为函数的返回值。由于函数只有一个返回语句,但如果想返回多个表达式或对象,就可以把它们包在一个元组里返回。
只能通过“_1”、“_2”......这样来访问每个元素。注意第一个元素就是“_1”,不是“_0”。
val t = ("God", 'A', 2333)
t: (String, Char, Int) = (God,A,2333)
scala> t._1
res0: String = God
可以显式地通过“new TupleX(元组元素)”来构造,Tuple1、Tuple2、Tuple3......Tuple22。元组最多只能包含22个元素
映射
映射并不是一个类,而是一个特质。所以无法用new构建映射对象,只能通过伴生对象里的apply工厂方法来构造映射类型的对象。
val map = Map(1 -> "+", 2 -> "-", 3 -> "*", 4 -> "/")
val tupleMap = Map(('a', 'A'), ('b', 'B'))
也可以导入scala.collection.mutable包里的可变映射,这样就能动态地增加、删除键-值对。可变映射的名字也叫“Map”
集
集和映射一样,也是一个特质,也只能通过apply工厂方法构建对象。集只能包含字面值不相同的同类型元素
传入了重复参数,那么会过滤掉多余的
默认情况下,使用的也是不可变集,scala.collection.mutable包里也有同名的可变集。
序列
序列Seq也是一个特质,数组和列表都混入了这个特质
序列可遍历、可迭代,也就是能用从0开始的下标索引,也可用于循环。序列也是包含一组相同类型的元素,并且不可变
集合的常用方法
map
scala> Array("apple", "orange", "pear").map(_ + "s")
res0: Array[String] = Array(apples, oranges, pears)
foreach
scala> var sum = 0
sum: Int = 0
scala> Set(1, -2, 234).foreach(sum += _)
zip
zip方法把两个可迭代的集合一一对应,构成若干个对偶。如果其中一个集合比另一个长,则忽略多余的元素
scala> List(1, 2, 3) zip Array('1', '2', '3')
res0: List[(Int, Char)] = List((1,1), (2,2), (3,3))
scala> List(1, 2, 3) zip Set("good", "OK")
res1: List[(Int, String)] = List((1,good), (2,OK))
第十一章 Scala基础——内建控制结构
if表达式
if......else if......else。 条件用(),多个表达式,则应该放进花括号里
while循环
for表达式与for循环
seq代表一个序列。换句话说,能放进for表达式里的对象,必须是一个可迭代的集合。比如常用的列表(List)、数组(Array)、映射(Map)、区间(Range)、迭代器(Iterator)、流(Stream)和所有的集(Set),它们都混入了特质Iterable
for { p <- persons // 一个生成器 n = p.name // 一个定义 if(n startsWith "To") // 一个过滤器 } yield n
seq是由“生成器”、“定义”和“过滤器”三条语句组成,以分号隔开,或者放在花括号里让编译器自动推断分号
生成器“p <- persons”的右侧就是一个可迭代的集合对象,把它的每个元素逐一拿出来与左侧的模式进行匹配,左侧的p是一个无需定义的变量名,它构成了变量模式,也就是简单地指向persons的每个元素。
定义并不常用,比如这里的定义就可有可无
过滤器则是一个if语句,只有if后面的表达式为true时,生成器的元素才会继续向后传递,否则就丢弃该元素。
每个for表达式都以生成器开始。如果一个for表达式中有多个生成器,那么出现在后面的生成器比出现在前面的生成器变得更频繁,
如果只想把每个元素应用到一个Unit类型的表达式,那么就是一个“for循环”,而不再是一个“for表达式”。关键字“yield”也可以省略。
for(x <- 1 to 100) sum += x
用try表达式处理异常
抛出一个异常
scala> throw new IllegalArgumentException
java.lang.IllegalArgumentException
... 28 elided
scala> throw new RuntimeException("RuntimeError")
java.lang.RuntimeException: RuntimeError
... 28 elided
try-catch
try后面可以用花括号包含任意条代码,当这些代码产生异常时被catch捕获
finally
ry表达式的完整形式是“try-catch-finally”。不管有没有异常产生,finally里的代码一定会执行。通常finally语句块都是执行一些清理工作,比如关闭文件。
match表达式
match表达式的作用相当于“switch”,也就是把作用对象与定义的模式逐个比较,按匹配的模式执行相应的操作。在详细了解模式匹配之前
def something(x: String) = x match {
| case "Apple" => println("Fruit!")
| case "Tomato" => println("Vegetable!")
| case "Cola" => println("Beverage!")
| case _ => println("Huh?")
| }
关于continue和break
Scala并没有引入它们。而且,Scala并不提倡使用循环,可以通过函数的递归调用达到相同的效果
如果实在想用,那么Scala的标准库里提供了break方法。通过“import scala.util.control.Breaks._”可以导入Breaks类,该类定义了一个名为“break”的方法。
变量的作用域
Scala变量作用范围很明确,边界就是花括号。
第十二章 Scala进阶——模式匹配
样例类与样例对象
定义类时,若在最前面加上关键字“case”,那么这个类就被称为样例类
Scala的编译器会自动对样例类添加一些语法便利:
①添加一个与类同名的工厂方法。也就是说,可以通过“类名(参数)”来构造对象,而不需要“new 类名(参数)”,使得代码看起来更加自然。
②参数列表的每个参数都隐式地获得了一个val前缀。也就是说,类内部会自动添加与参数同名的公有字段。
③会自动以“自然”的方式实现toString、hashCode和equals方法。
④添加一个copy方法,用于构造与旧对象只有某些字段不同的新对象,只需通过传入具名参数和缺省参数实现。比如objectA.copy(arg0 = 10)会创建一个只有arg0为10、其余成员与objectA完全一样的新对象
scala> case class Students(name: String, score: Int) defined class Students scala> val stu1 = Students("Alice", 100) stu1: Students = Students(Alice,100) scala> stu1.name res0: String = Alice scala> stu1.score res1: Int = 100 scala> val stu3 = stu1.copy(name = "Bob") stu3: Students = Students(Bob,100)
样例类最大的好处是支持模式匹配
样例对象与样例类很像,也是定义单例对象时在最前面加上关键字“case”
模式匹配
选择器 match { 可选分支 }
选择器就是待匹配的对象,花括号里是一系列以关键字“case”开头的“可选分支”。每个可选分支都包括一个模式以及一个或多个表达式,如果模式匹配成功,就执行相应的表达式,最后返回结果。
case 模式 => 表达式
模式的种类
通配模式
通配模式用下划线“_”表示,它会匹配任何对象,通常放在末尾用于缺省、捕获所有可选路径,相当于switch的default。如果某个模式需要忽略局部特性,也可以用下划线代替。
scala> def test(x: Any) = x match { | case List(1, 2, _) => true | case _ => false | } test: (x: Any)Boolean scala> test(List(1, 2, 3)) res0: Boolean = true scala> test(List(1, 2, 10)) res1: Boolean = true scala> test(List(1, 2)) res2: Boolean = false
常量模式
scala> def test2(x: Any) = x match { | case 5 => "five" | case true => "truth" | case "hello" => "hi!" | case Nil => "the empty list" | case _ => "something else" | } test2: (x: Any)String scala> test2(List()) res0: String = the empty list scala> test2(5) res1: String = five scala> test2(true) res2: String = truth scala> test2("hello") res3: String = hi!
变量模式
变量模式就是一个变量名,它可以匹配任何对象,这一点与通配模式一样。但是,变量模式还会把该变量名与匹配成功的输入对象绑定,
scala> def test3(x: Any) = x match { | case 0 => "Zero!" | case somethingElse => "Not Zero: " + somethingElse | } test3: (x: Any)String scala> test3(0) res0: String = Zero! scala> test3(List(0)) res1: String = Not Zero: List(0)
有时候,常量模式看上去也是一个变量名
①如果常量是某个对象的字段,可以加上限定词如this.a或object.a等来表示这是一个常量。②用反引号` `把名称包起来,编译器就会把它解读成常量,这也是绕开关键字与自定义标识符冲突的方法。
构造方法模式
样例类的构造方法作为模式,其形式为“名称(模式)”。假设这里的“名称”指定的是一个样例类的名字
scala> case class A(x: Int) defined class A scala> case class B(x: String, y: Int, z: A) defined class B scala> def test5(x: Any) = x match { | case B("abc", e, A(10)) => e + 1 | case _ => | }
序列模式
序列类型也可以用于模式匹配,比如List或Array。下划线“_”或变量模式可以指出不关心的元素。把“_*”放在最后可以匹配任意元素个数。
scala> def test6(x: Any) = x match { | case Array(1, _*) => "OK!" | case _ => "Oops!" | } test6: (x: Any)String scala> test6(Array(1, 2, 3)) res0: String = OK! scala> test6(1) res1: String = Oops! ————————————————
元组模式
在圆括号里可以包含任意模式。形如(a, b, c)的模式可以匹配任意的三元组
scala> def test7(x: Any) = x match { | case (1, e, "OK") => "OK, e = " + e | case _ => "Oops!" | } test7: (x: Any)String scala> test7(1, 10, "OK") res0: String = OK, e = 10
带类型的模式
模式定义时,也可以声明具体的数据类型
scala> def test8(x: Any) = x match { | case s: String => s.length | case m: Map[_, _] => m.size | case _ => -1 | } test8: (x: Any)Int
变量绑定
除了变量模式可以使用变量外,还可以对任何其他模式添加变量,构成变量绑定模式。其形式为“变量名 @ 模式”
scala> def test9(x: Any) = x match { | case (1, 2, e @ 3) => e | case _ => 0 | } test9: (x: Any)Int scala> test9(1, 2, 3) res0: Int = 3
模式守卫
模式守卫出现在模式之后,是一条用if开头的语句。模式守卫可以是任意的布尔表达式,通常会引用到模式中的变量。如果存在模式守卫,那么必须模式守卫返回true,模式匹配才算成功。
case i: Int if i > 0 => ??? // 只匹配正整数 case s: String if s(0) == 'a' => ??? // 只匹配以字母'a'开头的字符串 case (x, y) if x == y => ??? // 只匹配两个元素相等的二元组
密封类
如果在“class”前面加上关键字“sealed”,那么这个类就称为密封类。密封类只能在同一个文件中定义子类,不能在文件之外被别的类继承
对继承自密封类的样例类做匹配,编译器会用警告信息标示出缺失的组合。如果确实不需要覆盖所有组合,又不想用通配模式来避免编译器发出警告,可以在选择器后面添加“@unchecked”注解
scala> sealed abstract class Expr defined class Expr scala> case class Var(name: String) extends Expr defined class Var scala> case class Number(num: Double) extends Expr defined class Number scala> case class UnOp(operator: String, arg: Expr) extends Expr defined class UnOp scala> case class BinOp(operator: String, left: Expr, right: Expr) extends Expr defined class BinOp scala> def describe(e: Expr): String = e match { | case Number(_) => "a number" | case Var(_) => "a variable" | } <console>:16: warning: match may not be exhaustive. It would fail on the following inputs: BinOp(_, _, _), UnOp(_, _) def describe(e: Expr): String = e match { ^ describe: (e: Expr)String scala> def describe(e: Expr): String = e match { | case Number(_) => "a number" | case Var(_) => "a variable" | case _ => throw new RuntimeException // Should not happen | } describe: (e: Expr)String scala> def describe(e: Expr): String = (e: @unchecked) match { | case Number(_) => "a number" | case Var(_) => "a variable" | } describe: (e: Expr)String
可选值
一是每条case分支可能返回不同类型的值,导致函数的返回值或变量的类型不好确定,该如何把它们统一起来?二是通配模式下,常常不需要返回一个值,但什么都不写又不太好。要解决这两个问题,Scala提供了一个新的语法——可选值。
可选值就是类型为Option[T]的一个值。其中,Option是标准库里的一个密封抽象类
Option类有一个子类:Some类。通过“Some(x)”可以构造一个Some的对象,其中参数x是一个具体的值。根据x的类型,可选值的类型会发生改变。例如,Some(10)的类型是Option[Int],Some("10")的类型是Option[String]。由于Some对象需要一个具体的参数值,所以这部分可选值用于表示“有值”。
Option类还有一个子对象:None。它的类型是Option[Nothing],是所有Option[T]类型的子类,代表“无值”。也就是说,Option类型代表要么是一个具体的值,要么无值。Some(x)常作为case语句的返回值
模式匹配的另类用法
可以通过“val/var 对象名(模式) = 值”的方式来使用模式匹配,常常用于定义变量。这里的“对象名”是指提取器,即某个单例对象,列表、数组、映射、元组等常用集合的伴生对象都是提取器。
scala> val Array(x, y, _*) = Array(-1, 1, 233) x: Int = -1 y: Int = 1 scala> val a :: 10 :: _ = List(999, 10) a: Int = 999 scala> val capitals = Map("China" -> "Beijing", "America" -> "Washington", "Britain" -> "London") capitals: scala.collection.immutable.Map[String,String] = Map(China -> Beijing, America -> Washington, Britain -> London)
偏函数
函数也是一个对象,那么必然属于某一种类型。为了标记函数的类型,Scala提供了一系列特质:Function0、Function1、Function2……Function22来表示参数为0、1、2……22个的函数。
还有一个特殊的函数特质:偏函数PartialFunction。偏函数的作用在于划分一个输入参数的可行域,在可行域内对入参执行一种操作,在可行域之外对入参执行其他操作。
偏函数有两个抽象方法需要实现:apply和isDefinedAt。其中,isDefinedAt用于判断入参是否在可行域内,是的话就返回true,否则返回false;apply是偏函数的函数体,用于对入参执行操作。使用偏函数之前,应该先用isDefinedAt判断入参是否合法,否则可能会出现异常。
val isInt1: PartialFunction[Any, String] = {
case x: Int => x + " is a Int."
}
// 相当于
val isInt2 = new PartialFunction[Any, String] {
def apply(x: Any) = x.asInstanceOf[Int] + " is a Int."
def isDefinedAt(x: Any) = x.isInstanceOf[Int]
}
第十三章 Scala进阶——类型参数化
泛型是一种重要的多态,称为“全类型多态”或“参数多态”。在某些容器类里,通常需要存储其它类型的对象,但是具体是什么类型,事先并不知道
var类型的字段
如果在类中定义了一个var类型的字段,那么编译器会隐式地把这个变量限制成private[this]的访问权限,同时隐式地定义一个名为“变量名”的getter方法,和一个名为“变量名_=”的setter方法。
class A { var aInt: Int = _ } // 相当于 class A { // 这个变量名“a”是随意取的,只要不与两个方法名冲突即可 private[this] var a: Int = _ // getter,方法名与原来的变量名相同 def aInt: Int = a // setter,注意名字里的“_=” def aInt_=(x: Int) = a = x }
字段与方法没有必然联系。如果定义了“var a”这样的语句,那么必然有隐式的“a”和“a_=”方法,并且无法显式修改这两个方法(名字冲突);如果自定义了“b”和“b_=”这样的方法,却不一定要相应的var字段与之对应,这两个方法也可以操作类内的其他成员
class A { private[this] var a: Int = _ // 默认的getter和setter def originalValue: Int = a def originalValue_=(x: Int) = a = x // 自定义的getter和setter,且没有对应的var字段 def tenfoldValue: Int = a * 10 def tenfoldValue_=(x: Int) = a = x / 10 }
scala> val a = new A a: A = A@19dac2d6 scala> a.originalValue = 1 a.originalValue: Int = 1 scala> a.originalValue res0: Int = 1 scala> a.tenfoldValue res1: Int = 10 scala> a.tenfoldValue = 1000 a.tenfoldValue: Int = 1000 scala> a.originalValue res2: Int = 100
类型构造器
scala> abstract class A[T] {
| val a: T
| }
defined class A
“A”是一个类,但它不是一个类型,因为它接收一个类型参数。A也被称为“类型构造器”,因为它可以接收一个类型参数来构造一个类型,就像普通类的构造方法接收值参数构造实例对象一样。比如A[Int]是一种类型,A[String]是另一种类型,等等。也可以说A是一个泛型的类。在指明类型时,不能像普通类那样只写一个类名,而必须在方括号里给出具体的类型参数
型变注解
像A[T]这样的类型构造器,它们的类型参数T可以是协变的、逆变的或者不变的,这被称为类型参数的“型变”。“A[+T]”表示类A在类型参数T上是协变的,“A[-T]”表示类A在类型参数T上是逆变的。其中,类型参数的前缀“+”和“-”被称为型变注解,没有就是不变的。
如果类型S是类型T的子类型,那么协变表示A[S]也是A[T]的子类型,而逆变表示A[T]反而是A[S]的子类型,不变则表示A[S]和A[T]是两种没有任何关系的不同类型。
检查型变注解
类型系统设计要满足“里氏替换原则”:在任何需要类型为T的对象的地方,都能用类型为T的子类型的对象替换。里氏替换原则的依据是子类型多态。类型为超类的变量是可以指向类型为子类的对象,因为子类继承了超类所有非私有成员,能在超类中使用的成员,一般在子类中均可用
假设类型T是类型S的超类,如果类型参数是协变的,导致A[T]也是A[S]的超类,那么“val a: A[T] = new A[S]”就合法。此时,如果类A内部的某个方法funcA的入参的类型也是这个协变类型参数,那么方法调用“a.funcA(b: T)”就会出错,因为a实际指向的是一个子类对象,子类对象的方法funcA接收的入参的类型是S,而子类S不能指向超类T,所以传入的b不能被接收。
类型构造器的继承关系
上界和下界
对于类型构造器A[+T],倘若没有别的手段,很显然它的方法的参数不能泛化,因为协变的类型参数不能用作函数的入参类型。如果要泛化参数,必须借助额外的类型参数,那么这个类型参数该怎么定义呢?因为可能存在“val x: A[超类] = new A[子类]”这样的定义,导致方法的入参类型会是T的超类,所以,额外的类型参数必须是T的超类。Scala提供了一个语法——下界,其形式为“U >: T”,表示U必须是T的超类,或者是T本身
方法的类型参数
类和特质能一开始声明类型参数外,方法也可以带有类型参数。如果方法仅仅使用了包含它的类或特质已声明的类型参数,那么方法自己就没必要写出类型参数。如果出现了包含它的类或特质未声明的类型参数,则必须写在方法的类型参数里。
对象私有数据
第十四章 Scala进阶——抽象成员
类可以用“abstract”修饰变成抽象的,特质天生就是抽象的,所以抽象类和特质里可以包含抽象成员,也就是没有完整定义的成员。Scala有四种抽象成员:抽象val字段、抽象var字段、抽象方法和抽象类型,
trait Abstract { type T // 抽象类型 def transform(x: T): T // 抽象方法 val initial: T // 抽象val字段 var current: T // 抽象var字段 }
存在不可初始化的字段和类型,或者没有函数体的方法,所以抽象类和特质不能直接用new构造实例。抽象成员的本意,就是让更具体的子类或子对象来实现它们
class Concrete extends Abstract { type T = String def transform(x: String) = x + x val initial = "hi" var current = initial }
抽象var字段与抽象val字段类似,但是是一个可被重新赋值的字段。与前一章讲解的具体var字段类似,抽象var字段会被编译器隐式地展开成抽象setter和抽象getter方法,但是不会在当前抽象类或特质中生成一个“private[this] var”字段
初始化抽象val字段
抽象val字段有时会承担超类参数的职能:它们允许程序员在子类中提供那些在超类中缺失的细节。这对特质尤其重要,因为特质没有构造方法,参数化通常都是通过子类实现抽象val字段来完成
要在具体的类中混入这个特质,就必须实现它的两个抽象val字段
new RationalTrait { val numerArg = 1 val denomArg = 2 }
第十五章 Scala进阶——隐式转换与隐式参数
考虑如下场景:假设编写了一个向量类MyVector,并且包含了一些向量的基本操作。因为向量可以与标量做数乘运算,所以需要一个计算数乘的方法“ * ”,它应该接收一个类型为基本值类的参数。在向量对象myVec调用该方法时,可以写成诸如“myVec * 2”的形式。在数学上,反过来写“2 * myVec”也是可行的,但是在程序里却行不通。因为操作符的左边是调用对象,反过来写就表示Int对象“2”是方法的调用者,但是Int类里并没有这种方法。
Scala则是采取名为“隐式转换”的策略,也就是把本来属于Int类的对象“2”转换类型,变成MyVector类的对象,这样它就能使用数乘方法。隐式转换属于隐式定义的一种,隐式定义就是那些程序员事先写好的定义,然后允许编译器隐式地插入这些定义来解决类型错误。
隐式定义的规则
①标记规则。只有用关键字“implicit”标记的定义才能被编译器隐式使用,任何函数、变量或单例对象都可以被标记
②作用域规则。Scala编译器只会考虑在当前作用域内的隐式定义,否则,所有隐式定义都是全局可见的将会使得程序异常复杂甚至出错。隐式定义在当前作用域必须是“单个标识符”,即编译器不会展开成“A.convert(x) + y”的形式。如果想用A.convert,那么必须先用“import A.convert”导入才行,然后被展开成“convert(x) + y”的形式。单个标识符规则有一个例外,就是编译器会在与隐式转换相关的源类型和目标类型的伴生对象里查找隐式定义。因此,常在伴生对象中定义隐式转换,而不用在需要时显式导入
③每次一个规则。编译器只会插入一个隐式定义,不会出现“convert1(convert2(x)) + y”这种嵌套的形式,但是可以让隐式定义包含隐式参数来绕开这个限制
④显式优先原则。如果显式定义能通过类型检查,就不必进行隐式转换。因此,总是可以把隐式定义变成显式的,这样代码变长但是歧义变少。用显式还是隐式,需要取舍。
隐式地转换到期望类型
Scala的编译器对于类型检查比较严格,比如把一个浮点数赋值给整数变量,通常情况下人们可能希望通过截断小数部分来完成赋值,但是Scala在默认情况下是不允许这种丢失精度的转换的
但是用户可能并不关心精度问题,确实需要这样一种赋值操作,那么就可以通过定义一个隐式转换来完成
scala> import scala.language.implicitConversions import scala.language.implicitConversions scala> implicit def doubleToInt(x: Double) = x.toInt doubleToInt: (x: Double)Int scala> val i: Int = 1.5 i: Int = 1 ————————————————
隐式地转换接收端
接收端就是指调用方法或字段的那个对象,也就是调用对象在非法的情况下,被隐式转换变成了合法的对象,这是隐式转换最常用的地方。
scala> class MyInt(val i: Int) defined class MyInt scala> 1.i <console>:12: error: value i is not a member of Int 1.i ^ scala> implicit def intToMy(x: Int) = new MyInt(x) intToMy: (x: Int)MyInt scala> 1.i res0: Int = 1
隐式类
隐式类是一个以关键字“implicit”开头的类,用于简化富包装类的编写。它不能是样例类,并且主构造方法有且仅有一个参数。此外,隐式类只能位于某个单例对象、类或特质里,不能单独出现在顶层。隐式类的特点就是让编译器在相同层次下自动生成一个与类名相同的隐式转换,该转换接收一个与隐式类的主构造方法相同的参数,并用这个参数构造一个隐式类的实例对象来返回

 浙公网安备 33010602011771号
浙公网安备 33010602011771号