


Stable Diffusion WebUI 工具相关的基础知识
本章节概览
通过本章节的知识学习,可以了解到 Stable Diffusion WebUI 工具相关的基础知识
●
理解AIGC文生图技术基础
○
掌握扩散模型(Diffusion Model)的核心原理
●
熟悉Stable Diffusion WebUI工具的使用
○
掌握Checkpoint底模型的选择策略
○
运用LoRA模型实现风格/内容微调
○
操作ControlNet实现精准控制
●
参数调优与提示词工程
○
设计高效提示词结构
○
调节采样步数(细节质量)、去噪强度(图像重构度)、分辨率(显存消耗平衡)等关键参数
●
高级功能应用
○
图生图局部重绘
○
批量处理与提示词反推
○
Tiled Diffusion/VAE技术实现大尺寸图像生成优化
●
PAI ArtLab平台的行业应用能力
○
覆盖教育、建筑、企业、游戏等多领域
学习目标达成
学员将具备从基础原理认知到高阶操作的全链路能力,可独立完成:
●
根据需求选择适配模型
●
通过参数调校实现创意表达与技术约束的平衡
●
解决高分辨率图像生成、复杂场景控制等工程难题
●
构建标准化工作流(批量处理/风格迁移/精细化编辑)
课时1. AIGC通识
1.
文生图的核心技术基础是什么?
扩散模型(Diffusion Model)在近年来的图像生成技术中扮演了重要的角色,尽管卷积神经网络(CNN)和生成对抗网络(GAN)等技术也有各自的应用。扩散模型的基本思想是通过不断地将噪声加入到数据中,然后学习如何逐步去除这些噪声以重建数据。这种方法的优点在于它能够在高维空间中非常精细地控制生成过程,从而生成质量极高的图像。相比于GAN,扩散模型不需要通过对抗两个网络而是通过合理的去噪过程来优化图像质量,这使得它在处理复杂条件生成任务时表现得更为稳定和强大。GAN虽在很多应用中表现不凡,但容易受到训练不稳定以及模式崩溃的问题。而扩散模型具备更好的训练稳定性及细节生成能力,是当前文生图领域中的关键技术基础。
2.
扩散模型在图像生成中的基本原理是什么?
扩散模型的基本原理是通过一个逆过程将简单的方式生成的数据逐步去噪复原。在训练过程中,该模型首先学习如何将数据转化为噪声数据,并在这个过程中引入了一个时间反响机制用于控制去噪的程度。训练好的模型能够在给定初始噪声的条件下,逐步消除噪音直至还原出高质量的图像。在此过程中,模型使用一种称为马尔可夫链的机制,逐步地从一组潜在分布中采样,确保每一步输出均为合理转化。这一过程的去噪能力使得生成的图像具备极高的质量和细节表现。因优秀控制能力,这种方法不仅适用于较为简单的图像生成任务,也适用于复杂的多模态任务(如图文转换)。
3.
CFG Scale(引导因子)的参数控制文生图生成时的什么特性?
CFG Scale(Classifier-Free Guidance Scale)是控制生成图像中模型对输入文本指导程度的一个重要参数。当CFG Scale值较低时,模型生成的图像较为多样化,自由发挥成分较多,而较高的CFG Scale将引导模型生成更接近输入提示词的图像。高CFG Scale虽能确保生成图像忠实于输入提示,但可能也会限制图像的创造性,导致生成结果相对保守。因此,对于图像生成任务来说,在CFG Scale上找到一个合适的平衡点,既能保证图像的创意性,又能最大化地符合提示词的指引,是提升图像生成质量的关键。通过调节CFG Scale,创作者可以更灵活地控制生成图像的倾向,适应不同的应用需求。
4.
扩散模型相比生成对抗网络(GAN)的主要优势是什么?
扩散模型提供了多个方面的优势,尤其在生成高质量和细节丰富的图像方面,相比于生成对抗网络(GAN)更具潜力。首先,扩散模型在训练过程中更为稳定。GAN在对抗性训练中存在模式崩溃问题,需要小心调整两个网络的平衡。扩散模型则省去了对抗过程,只需依照去噪训练即可。其次,扩散模型能从完整的数据分布中抽样,降低了生成模式局限的问题,能合理重建出复杂细节。更重要的是,扩散模型因其去噪过程的透明性,生成的图片在细节和结构方面表现得更加细腻和真实。尽管其计算成本相对较大,但最终呈现出的图像水准在很多应用中显著优于GAN,特别是在对细节要求严苛的图像生成任务中,无论是在艺术创作还是医学图像分析等领域都有广泛应用。
5.
在 AIGC 文生图系统中,为提高生成图像质量,可以通过什么方式优化提示词?
在文生图生成过程中,清晰、详细的提示词能够显著提高生成图像的分辨率与质量。为了达到这一效果,添加具体的形容词和名词是优化提示词的有效策略。丰富的描述词能够给生成模型提供更明确的视觉意向,保证输出图像的准确性。尤其是在艺术表现或者场景模拟中,详细地描述关乎画面的色彩、光照以及材质等多个方面。此外,提示词不仅需要包括具体的对象及其特征描述,还应注意逻辑的流畅性和结构的完整性,避免歧义。通过不断实验调整提示词的复杂程度及其细节,可以帮助优化生成结果,并提升对复杂任务的适应性和细节处理能力,从而最大限度地实现创作者的意图。
6.
Stable Diffusion 模型的文本输入通过什么技术转化为图像生成的潜在空间?
在Stable Diffusion模型中,文本嵌入(Text Embedding)起着关键作用,它将原始文本输入转化为潜在空间的向量表示。这些向量不仅捕捉文本的语义信息,还为图像生成提供了结构化指导。通过使用预训练的语言模型(如BERT或GPT),文本嵌入能够精确地传递语义细节,确保扩散模型生成的图像符合文本描述的语义要求。在这个过程中,文本特征被映射到一个高维潜在空间。模型在这个空间中进行方向性和尺度性调整,以实现从文本到图像的准确转换。通过这种转换,扩散模型能够有效整合文本上下文和细节信息,生成更为精细和准确的图像,从而提升生成结果的可信度和质量。
7.
在文生图任务中,如何生成高分辨率图像而不降低细节质量?
生成高分辨率图像时,维持细节质量是AI生成图像的一个关键挑战。Hi-Res Fix技术通过双阶段生成方案,在初步生成低分辨率图像后,通过模型的逐步细化,实现细节的保真强化。在第一阶段中,模型以较低的分辨率生成初步图像框架,并确定图像的大体形态;而在第二阶段,利用专门设计的超级分辨任务模块对图像进行细化,添加深度细节,提升图像的最终分辨率。该过程充分利用了上下文信息和细节纹理的增强机制,确保生成结果不仅具备高分辨率,还能保持良好的细节表现。这种方法特别适用于需要高质量打印输出或超大尺寸显示的图像任务,将生成效率和输出质量有效结合。
8.
文生图技术的常见应用场景包括哪些?
文生图技术在许多创造性和设计性领域得到了广泛应用,改善和加速了多个行业的工作流程。包含但不仅限于以下场景:
●
市场营销:根据不同客户群体的需求,为营销团队快速生成具有针对性的视觉创意内容,从而提高广告设计的吸引力,增强客户参与度和转化率。
●
影视和游戏制作:通过加速影视和游戏中场景、角色的概念设计过程,AIGC文生图模型为设计师提供了丰富的参考图像和源源不断的设计灵感,使得创意过程更加高效。
●
教育和培训:将复杂的教学内容直观地转化为易于理解的图像,助力教学过程,从而提高学习效率。同时,它还能生成特定场景或环境的图像,应用于职业培训和模拟。
●
室内设计和家居装修:设计师可利用AIGC文生图模型快速生成室内或家装设计草图,从而更全面地探索设计概念并提升最终设计效果。
●
社交媒体和娱乐应用:AIGC文生图模型能够生成具有互动性和娱乐性的社交媒体传播图像,从而提升用户参与度,创造更具吸引力的内容体验。
●
电商和产品展示:通过生成逼真的产品展示图,AIGC文生图模型帮助小型企业在产品尚未实物拍照时实现在线展示和销售,加速产品推广和市场适应过程。
文生图技术通过将文本和图像结合,极大地丰富了各个领域的创造力和生产力,使得非专业人士也能够参与到图像创作中。这些应用不仅提高了工作效率,还为用户和创作者提供了全新的表达方式和互动体验。
9.
在 AIGC 文生图领域,未来技术发展的关键方向都有哪些?在AIGC(人工智能生成内容)中文本到图像生成领域,未来技术发展的关键方向包含但不限于以下几个方面:
●
模型复杂性与效率:
○
开发者可以探索更高效的算法以平衡复杂性与效率。为设计师提供优化后的模型工具,使其能够便捷地生成高质量图像。
●
多模态融合:
○
提升模型在处理多模态数据(文本、图像、音频等)之间转换的能力。未来的发展可能会涉及更加紧密地结合不同模态的信息,以生成更具现实感和上下文理解的图像。
●
内容控制与定制化:
○
提供更高水平的控制机制以满足用户对于生成内容的个性化需求。增强用户指定风格、色彩、情感等具体特征的能力将是一个重要课题。
●
语义理解与内容一致性:
○
提高模型对于文本内容的深层次理解,以确保生成的图像与输入文本在语义上的一致性。这将涉及自然语言处理与计算机视觉技术的深度融合。
●
实时生成与交互性:
○
实现实时生成图像的能力使用户可以得到即时的反馈,这对于需要快速迭代和即时创作的应用场景非常重要,提高实时交互能力将是一个挑战。
●
数据隐私与安全:
○
在生成过程中保护用户数据的隐私,设计安全的生成框架以防止信息泄露和滥用。
●
生成质量评估指标:
○
构建更加完善的评估指标及评估工具,以量化生成内容的质量,比如图像的真实性和与文本描述的对应性。提供检测生成内容质量与一致性的功能,支持更精准的质量调控。
通过在这些方向上的研究和发展,AIGC在文生图领域将能提供更为丰富和多样化的解决方案,推动相关产业和应用场景的革新。
10.
在 AIGC 文生图生成过程中,"采样步数"的增加通常会如何影响生成结果?
在基于人工智能生成内容(AIGC)的“文生图”生成过程中,采样方法是影响生成结果质量的重要因素之一。特别是采样步数(Sampling Steps)的设定,对于生成图片的质量和细节呈现有显著的影响。采样步数指的是在从模型的潜在空间中提取图像过程中,所进行的迭代次数。在多种生成对抗网络(GAN)和扩散模型(Diffusion Models)中,采样步数代表了从随机噪声到高质量图像的逐步变换过程。
增加采样步数通常会有几个主要效果:
●
提升生成图像的细节和质量:更多的采样步数允许模型有更多的机会细化图像细节,从而提高图像的清晰度和逼真度,生成的图像更具复杂性和精细度。
●
减少图像中的噪声:在低采样步数的情况下,生成的图像可能包含较多的噪声和伪影,显得粗糙和不真实。增加采样步数能让这些不必要的细节被平滑掉,使得最终图像更加干净和自然。
●
更好的多样性和可靠性:更多的采样步数还意味着图像生成过程中有更多的探索空间和可能性,这往往能带来更丰富的图像内容和避免模式崩溃(mode collapse)的风险。
●
延长计算时间:需要注意的是,增加采样步数也会相应增加生成图像所需的计算时间和资源消耗。在实际应用中,通常需要在生成质量和计算资源之间找到平衡点,以确保在可接受的时间内完成高质量图像的生成。
课时2. 设计底模型的应用-Stable Diffusion底模型(Checkpoint)

1.
Stable Diffusion 模型介绍
Stable Diffusion 是 Stability AI 开发的图像 AI 大模型,它能够根据文本描述生成图像,也能根据文本提示修改现有图像。Stable Diffusion 底模型(checkpoint),一般也称为底模型、大模型或主模型。目前除了官方Stable Diffusion 底模型,例如:Stable Diffusion v1.5 Model/Stable Diffusion v2.1 Model/Stable Diffusion XL base 1.0 Model等,也有用户在官方底模型的基础上训练和融合好的其他风格的模型,里面集合了模型参数和权重等,出图的风格、画风相对已经固定,也可以直接用于生成图片。底模型也是生图的基础,针对设计需求选择相应的底模型也是生图质量的重要环节。
2.
如何选择合适的Checkpoint版本
我们在使用开源社区提供的模型的时候,一般会选择使用最新的版本,因为最新版本的Checkpoint模型一般都会包含对之前版本中的bug修复,以及各种性能和功能的改进。这对生成图像的质量和处理速度带来显著提升。另外,随着技术的发展,算法的优化使得最新版本更能满足当前的需求和新型应用场景。
3.
Stable Diffusion模型是如何生成图像的?
通过逐步去噪恢复图像。Stable Diffusion模型通过对一系列的噪声图像进行反向扩散,逐步去噪以恢复出原始图像。这种方法不仅提高了图像生成的质量,还大大增加了生成图像的多样性和复杂度。
4.
Stable Diffusion模型主要由哪些组件构成?
噪声生成器、潜在空间编码器、解码器、反向扩散过程。这些组件协作工作,通过先生成噪声,再对噪声进行编码和解码,最后通过反向扩散过程生成图像。这种分布式的处理方式使得模型在生成高质量图像时具备很高的灵活性和可扩展性。
5.
为什么在Stable Diffusion模型中需要一个反向扩散过程?
用于从噪声中逐步重建图像。反向扩散过程是Stable Diffusion模型的核心,它通过不断减小噪声,逐步重建出清晰的高质量图像。这个过程本质上是一种逐步优化的过程,使得最终生成的图像更加接近目标分布。
6.
Stable Diffusion模型的核心思想是什么?
使用扩散过程模拟概率分布并生成图像,通过模拟图像生成过程中的概率分布,利用扩散过程生成图像。这种方法既能生成高质量的图像,又能以比较少的参数量达到比较好的效果,是深度学习图像生成领域的重要技术之一。
7.
Stable Diffusion模型通常采用哪种类型的神经网络架构来实现图像生成?
卷积神经网络(CNN)。卷积神经网络通过其局部连接和共享权重特性,能够高效地处理图像数据,提取图像中的局部特征。这使得CNN成为实现图像生成任务的主要架构之一。
8.
在实际应用中,Stable Diffusion模型主要被用于哪些领域?
图像生成与编辑。Stable Diffusion模型由于其优异的图像生成能力,在图像生成与编辑上有着广泛的应用,如图像修复、图像超分辨率、风格转换等多个领域。
9.
checkpoint常见的训练方法是什么?
DreamBooth是基于扩散模型(Diffusion Model)的微调技术,其核心是通过少量示例图像(3-5张)对预训练扩散模型进行微调,使模型能够生成包含特定主题(如个人宠物、特定风格)的图像生成的模型允许被应用,再去生成特定的主题、对象和风格的图像。技术实现上,DreamBooth通常在预先训练好的大型生成模型(如Stable Diffusion)的基础上进行操作,它允许用户,通过提供具有某种特定标识的部分示例图像,对模型进行个性化调整并生成模型。用户可以结合微调后的模型,生成含有该示例图像特征的的新图像。优势包括:定制化生成图像、相对简单高效、适用性广泛、相对于需要复杂代码操作的模型来说对于用户更友好。局限性包括:容易过拟合或欠拟合、泛化性不好控制、文件较大存储效率低。


10.
checkpoint模型的作用和意义
●
提高生成图像的质量:Checkpoint模型是通过微调训练的模型,在训练过程中针对特定任务或数据集进行优化,所以使用此微调后的模型能够精细地捕捉生成内容的细节,可以指导生成更高质量精美的图片。
●
适应性与定制化:通过微调,Checkpoint模型能够更好地指导不同的图像类型的生成需求,实现较高的个性化定制。例如,模型是根据特定的艺术风格、主题或内容进行微调训练的,那也就可以指导最终的图像生成更具备独特风格。
●
扩展性与灵活性:Stable Diffusion WebUI框架支持在基础模型上灵活选择不同的Checkpoint底模型,提供了很大程度的扩展性。用户可以按需选择最适合生成内容的Checkpoint底模型,实现所需的图像生成效果。
课时3. 设计风格模型的应用-LoRA模型
LoRA的全称是 Low-Rank Adaptation of Large Language Models,可以在不改变底模的情况下利用少量数据进行训练,达到风格化调整,支持特定对象生成与细节控制。Lora模型是在主模型的基础上训练出来的,Lora模型也需要搭配主模型使用,无法单独生成图片。
●
格式: 通常以.safetensors 为后缀。
●
应用: 必须搭配Stable Diffusion模型使用,不可独立生图。
●
版本:同时使用多个LoRA模型时,需要区分LoRA模型版本,不同版本之间的模型不通用。比如1.5版本的LoRA和XL版本的LoRA同时使用无法生效。
1.
LoRA模型类型
●
风格化LoRA:通过使用此类LoRA快速改变生成对象的风格,此类LoRA往往更注重风格而非内容物。
●
通用型LoRA:在风格和内容物间达到平衡,是既包含内容物又包含风格的综合性LoRA。
2.
LORA的选择标准
●
泛化性 指在训练集上的经验性能是否会在未知数据集上表现出差不多的性能
●
图像准确性 生成内容物与训练数据集的内容是否具有良好的相关性
●
语义准确性 通过提示词准确调用部分内容的能力
3.
LoRA 的主要功能
LoRA 的主要功能是允许在不改变原始模型参数的情况下进行微调,以适应特定任务或风格。这一技术的核心价值在于保存原始模型的完整性和通用性,同时能够在特定任务上展现出良好性能。LoRA 通过在原始模型的参数上施加一个低秩矩阵来实现这种微调,极大地减少了参数量的增加,使得在存储和计算资源上更加高效。
4.
高质量数据集的选择标准
在选择训练 LoRA 模型的数据集时,高质量的标准主要包括图像的清晰度、风格一致性以及与目标任务的相关性。这是因为训练数据集需要为模型提供足够的信息来学会特定风格或任务需求,而低质量或者混杂的样本可能会导致模型的学习偏离预期。此外,数据集的标注质量和内容多样性也很关键,尤其是在需要捕捉复杂特征或风格的任务中。
5.
在 SD WebUI 中影响生成风格的参数调整
在 SD WebUI 中,影响生成图像风格的一个关键因素是 LoRA 权重的调整。权重决定了微调模型对原始模型特性的影响程度。合理的权重设置(如“lora:model_name:0.8”中的 0.8)能够平衡原始模型的通用性与 LoRA 模型的特定性,以达到理想的输出风格。需要注意的是,权重过高可能会导致风格过于偏激,失去原始模型的优点。
6.
LoRA 的适用场景
LoRA 最适合用于微调基础模型,以生成特定艺术风格或专注于某个小型领域。这种应用较适合需要快速适应变化但不牺牲原模型性能的场景,如艺术作品生成、特定领域的文本风格调整等。LoRA 的优势是可以在较小的计算成本和存储开销下实现高度定制化和个性化的模型输出。
7.
多个 LoRA 模型的负载管理
当同时使用多个 LoRA 模型时,应确保每个模型的权重设置合理以避免过高的叠加。过高的权重叠加可能会导致不同特征相互冲突,生成结果失真。合理的做法是为每个 LoRA 设定一个适中的权重,并逐步调整以观察其对生成结果的影响,使得多个 LoRA 模型能够在不同特征间找到一个平衡点,实现和谐共存。
课时4. 文生图
简介
AI绘图本质,是用户向模型传递信息的过程。而文生图的核心原理,在于通过深度学习模型,使其能够依据文本描述生成对应的图像。我们通常通过绘制图形来创建图像,而如今的 AI 绘画则借助文本信息来理解内容,并依靠强大的模型和计算能力,自动生成与之匹配的图像。如果仅仅借助文字来设定图像内容,图像画面会具备一定的随机性,针对同样一组文字信息,模型也会一定程度跟人一样有不同的“想象”。所以有时你可能会很快得到理想结果,但通常需要耐心多次生成。那么,如何提升图片生成的准确度呢?答案在于使用更多精细的提示词,以丰富的画面描述来增强生成效果。
提示词
●
什么是提示词:
○
Stable Diffusion 模型是一个基于深度学习的文本到图像的生成模型,其能力是基于训练模型所依赖的大量的图像和图像对应的文本描述的训练数据。在 Stable Diffusion WebUI 中,可以通过提示词的功能,给AI模型下发生成图像内容的指令。精心设计的提示词,可以引导模型生成更精确或者更相关的特定图像。
○
正向提示词:
■
正向提示词是指直接描述你希望生成图像的特定场景、主题或风格的关键词。在使用 Stable Diffusion WebUI 进行图像生成时,正向提示词的设置至关重要,因为它们直接影响模型理解和合成图像的方向。以下是一些有关正向提示词设置的专业建议:
●
语义指导:提示词在图像生成中的作用是提供语义指导,这意味着选择具体且直观的词汇能够有效传达生成意图。例如,使用“sunset over the ocean”可以比单词“sun”更精准地生成一个海上日落的场景。
●
风格关键词:通过在提示词中加入艺术家或风格的关键词(例如“in the style of Van Gogh”),可以生成具有该风格特征的图像。这种方法结合语境和风格化元素,是创造个性化作品的重要工具。
●
简洁性与清晰性:保持提示词的简洁和明了,使用描述性形容词和名词组合,这样可以避免不必要的歧义。例如,“a futuristic cityscape under a purple sky”比“city sky futuristic”更清晰。
●
长文本处理:尽量避免冗长的描述,以免影响模型的解析效率。选择关键和高效的词语组合。
●
结构:常见的通用范式: 前缀(画质词+画风词+镜头效果+光照效果) + 主体(人物&对象+姿势+服装+道具) + 场景(环境+细节)
●
权重:为了强调某些特定元素,可以在提示词中添加权重值,在 Stable Diffusion 中,权重有助于调整模型的注意力分配,确保关键元素突出显示。例如使用“beautiful::2”来突出“beautiful”这个词。可以将想要强调的提示词括起来,在提示词后面增加冒号和权重值,例如(beautiful:1.3),权重取值范围推荐(0.4~1.6)权重过低容易被忽略,权重过高容易过拟合导致图片畸形;也可以直接使用小括号来叠加权重,每增加一层相当于提高1.1倍权重,例如:(((cute)))。
○
反向提示词:
■
反向提示词(也称为负面提示)用于告诉模型哪些元素不应该出现在生成的图像中。它们是优化生成结果、避免出现不需要特征的强大工具。在Stable Diffusion中用于指示模型在生成图像时避免特定元素、风格或特征的出现。这些提示旨在消除用户不希望看到的内容,确保生成结果符合预期,具体应用包括:
●
应用场景:利用反向提示词来排除具体的风格、颜色、或对象。例如,为了避免生成背景中的车辆,可以在负面提示中加入“car”或“vehicle”。
●
优化图像质量:在提示词中包含负面元素(例如“不模糊”,“无噪点”)可以帮助提升图像的清晰度和整体质量,尤其是在细节表现上。
●
处理复杂场景:负面提示词在多元素的复杂场景生成中发挥重要作用,可以减少或去除不必要的部分,提高生成的准确性。例如,避免一个卡通风格中出现现代现实元素。
●
排除特定对象:如在生成“森林”时添加“-苔藓”,以避免画面中出现苔藓。
●
规避特定风格:如想得到写实作品时,可使用“-卡通”、“-漫画”等提示,防止生成图像偏向动漫风格。
●
抑制不良属性:用于去除不良视觉效果,如“-丑陋”、“-变形”,确保生成图像美观和谐。
●
控制构图与姿态:如在生成人物坐姿时,使用“-身体背对观众”来强调希望人物正面面对观者。
○
在使用这些提示词时,用户应该根据实际需求进行组合和调试,不断调整权重和描述以达到最佳效果。这需要对提示词效果的敏感性和反复试验。合理的正负提示词调整不仅提升了图像生成质量,还可以帮助用户更好地驾驭 Stable Diffusion 的创作能力,满足多样化的艺术需求。
●
提示词形式
○
单词
○
词组
○
句子
●
提示词符号语法及权重
○
分割语法:英文逗号
○
提示词权重:
■
cloud, (trees)——( )1.1
■
cloud, {trees}——{ }1.05
■
cloud, [trees]——[ ]0.91
○
加强提示词权重:
■
(cloud), {trees}
■
((cloud)), {{trees}}
■
(cloud:1.5), (building:1.3)
●
(cloud) 等于(cloud:1.1)
●
{cloud}等于(cloud:1.05)
●
((cloud))等于(cloud:1.21)
○
减弱提示词权重:
■
[cloud], [trees]
■
((cloud)), {{trees}}
■
(cloud:1.5), (building:1.3)
●
[cloud] 等于(cloud:0.91)
●
[[cloud]] 等于(cloud:0.83)
○
混合提示词:
■
混合两个提示词:[cloud|trees]
■
调整混合时的权重:[cloud|(trees:1.2)]
○
分布绘制
■
[cloud:20] 提示词cloud在20步开始
■
[cloud::20] 提示词cloud在20步结束
■
[[cloud::20]:5]提示词cloud在5步开始在20步结束
■
[cloud:trees:20]前20步画cloud,后20步画trees
○
色彩/元素的融合
■
cloud AND trees, 大写AND可以对不同颜色不同元素加强关联性
○
独立计算
■
white cloud BREAK trees,可以避免提示词内容污染
参数
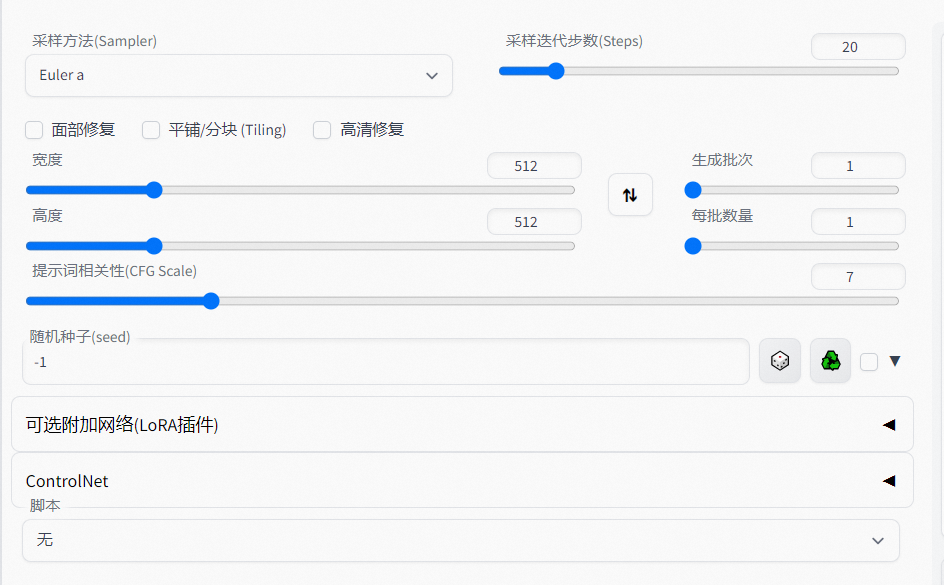
●
在使用 Stable Diffusion WebUI 的文生图功能时,理解和调整 Generation 模块中的各个参数对于生成高质量的图像至关重要。下面是对这些参数的深入解析和调整指南,以帮助用户更好地掌握生成过程:
●
CFG Scale(引导因子)
○
定义:CFG Scale 控制的是生成图像对提示词的依赖程度。值越高,生成的图像越更严格地遵循提示词,但可能会导致图像失去灵活性和自然性;值低时,图像可能会偏离提示词。
○
调整建议:根据生成的图像需求调整 CFG Scale。如果生成结果不够符合提示词,可以尝试提高该值;反之,如希望图像更自然或探索意外创意,降低该值。
●
采样步数(Sampling Steps)
○
定义:Stable Diffusion的核心原理是利用扩散过程来创造、重建图像。简单来说,你可以想象这个模型像一位艺术家,但它不是直接画出一幅图画,而是通过一系列精心设计的步骤去除图像中的随机噪声,逐步提炼出清晰的内容。生成图片的迭代步数,每多一次迭代都会给AI更多的机会去对比prompt和当前结果,调整图片。更高的步数需要花费更多的时间计算,消耗更多的资源,但并不意味结果会更好,步数越大,图像细节越多,但是和采样模式相关联,例如Euler a大约在20~30步左右,可以更好的平衡速度与质量。
|
Sampling steps=20
|
Sampling steps=28
|
Sampling steps=36
|
Sampling steps=44
|
 |
 |
 |
 |
●
采样方法(Sampler)
○
定义:不同的采样算法会影响生成的速度和细节表现,目前并无最优的采样方法,要根据实际使用情况来选择合适的采样方法。euler a , dpm++ 2s a , dpm++ 2s a karras 三种采样器生成的整体构图较为相似;euler , dpm++ 2m , dpm++ 2m karras 三种采样器的整体构图比较相似;DDIM的构图风格比较不同,可根据自己的需求选择不同的采样模式,默认使用euler a即可。
|
Euler
|
 |
LMS
|
 |
|
Heun
|
 |
DPM2
|
 |
|
DPM 2 a
|
 |
DPM++ 2S a
|
 |
|
DPM++ 2M
|
 |
DPM++ 2S a Karras
|
 |
|
DPM++ 3M SDE Karras
|
 |
DPM++ 3M SDE Exponetial
|
 |
●
随机种子(seed):
○
参数值为-1表示每一次生成都是随机;若为其他任意数值(可为负数和小数),seed值一致,其他参数一致,模型一致,GPU一致,可以生成相同图片。
●
宽度&高度(width&height):
○
调整这个参数决定最终生成图像的比例大小。通常以宽度 x 高度的格式表示,如 512x512。分辨率越大细节越多,但一般不建议设置过大,对显存的消耗较大。
●
生成批次(batch count)
○
影响图片细节,不同批次生成的图片细节不同,数值越大,需要计算的时间越久。
●
每批数量(batch size)
○
每批同时生成的图片数量,对显存消耗较大。
●
提示词相关性(CFG Scale)
○
参数值越大,越接近prompt词,参数值越小,AI生成的自由创作空间越大。
|
CFG Scale=2.5
|
CFG Scale=5
|
CFG Scale=7.5
|
CFG Scale=10
|
 |
 |
 |
 |
●
面部修复(restore faces):
○
优化面部图像可勾选,头像是近角时勾选容易过度拟合出现虚化,适合在远角时勾选该选项。
|
without restore faces
|
with restore faces
|
 |
 |
●
高清修复(highres.fix)
○
使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数Scale latent在潜空间中对图像进行缩放。另一种方法是从潜在的表象中产生完整的图像,将其升级,然后将其移回潜在的空间。Denoising strength决定算法对图像内容的保留程度,在0处,什么都不会改变,而在1处,会得到一个不相关的图像。
课时5.图生图
1. 核心参数
●
底层模型
○
基础模型,决定图像生成的风格
●
提示词
○
与文生图功能相同,有正向提示词与反向提示词两部分,影响图像生成的内容
●
基础图像
○
在图生图功能区域,需要上传一张图像作为生成图像的基础。最终生成图像会基于用户上传的基础图像进行二次加工
●
其他图像
○
当用户使用图生图模块的重回蒙版等功能时候,还需要对应上传蒙版等辅助图像
●
去噪强度(Denoising Strength):
○
这是控制生成图像与输入图像相似程度的关键参数。设置为0时,生成的图像与输入图像完全相同;接近1时,生成的图像风格变化更大,能够更强烈地表现出提示词中的描述。
○
应用场景:对于需要高度真实感或细节丰富的图像,可以使用较低的去噪强度;而进行风格化处理或创造性改变时,可以增加去噪强度。
●
采样方法(Sampler):
○
不同的采样方法可能影响生成图像的质量和细节。常用的采样算法如DDIM和PLMS各有特色,可根据需求选择。
●
图像分辨率:
○
更高的分辨率通常会产生更多的细节,但也需要更高计算资源。使用较高分辨率的输入图像可提升最终输出的质量。
2. 风格化转换技巧
为了实现风格化的图像转换,可以综合运用以下策略:
●
使用提示词:在提示词中添加特定风格描述(如水彩风格)可引导AI在生成图像时注入期望风格。
●
调整去噪强度:结合较高的去噪强度,以便更自由地发挥风格转换的效果。
3. 保持高细节和丰富内容
在生成细节丰富的图像时,图像分辨率和采样步数的选择很关键。通过增加这些参数,模型可以在较长的步骤中逐渐提升图像的细节。
4. 控制生成效果的技巧
●
多参数调整:结合CFG Scale(Classifier-Free Guidance Scale)、去噪强度、采样步数等参数,可以在原图基础上实现局部变化和整体风格调整。
●
局部重绘(Inpainting):有针对性地调整图像某些部分,而不影响其他区域,可以通过局部重绘功能实现。
5. 输入图像在流程中的作用
●
输入图像在图生图过程中提供初始样本的作用,它决定生成图像的基础构图或内容。这个功能常用于风格转换、局部修改或分辨率增补等场景。
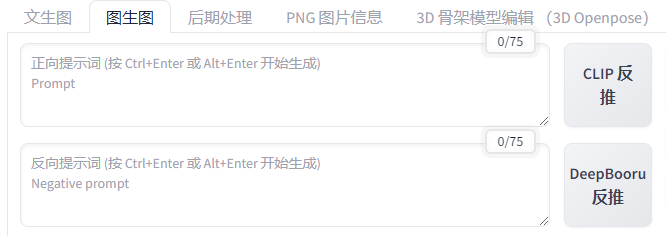
提示词反推
●
提示词反推
○
稳定扩散技术中,利用模型进行提示词反推的主要目标是根据输入图像自动生成相应的文本描述。这有助于理解和概括图像的主题、风格及内容,从而为文本到图像转换过程提供一个起点。主要用例包括:
■
内容描述:帮助用户更好地理解图像所表达的内容。
■
创作启发:提供独特的描述以激发新的创作灵感。
○
操作:
■
上传图片:单击选框上传图片。图片比例需要跟设定好的长宽一致,例如,512*512的图片需要上传1:1的图片。
■
选择模型:使用反推提示词CLIP/DeepBooru,或自己填写补充Prompt和Negative Prompt, 单击生成,即可生成一张基于已上传图片的新图片。
●
CLIP: 具体的输出信息,侧重于生成完整的句子描述,能够概括复杂场景和抽象概念。适用于需要详细描述和具象化表达的图像。CLIP(Contrastive Language–Image Pretraining)由 OpenAI 开发,结合了图像和文本数据进行训练,具备在图像和文本之间进行对比学习的能力。其核心思想是通过对比学习,识别出图像与文本对之间的高相关性。
●
DeepBooru: 基于标签的图像检索算法,以关键词形式呈现。
○
适用场景比较:CLIP 反推在抽象艺术场景中表现优良,因为它能提供概念性描述,而 DeepBooru 则在写实和具体对象识别(如动漫和纹理图像)中显示出更高的精度。
○
提示词反推影响因素:反推出高质量提示词的效果很大程度上依赖于输入图像的清晰度和特征表达。随着图像的复杂度增加,CLIP 模型需要更细致的特征提取和匹配能力。因此,对于复杂且信息量大的图像,可能需要额外的后处理步骤。
○
反推的主要应用和输出信息:通过 SD WebUI 的提示词反推功能,用户能够获取图像的语义描述或标签,帮助:更好地组织和检索图像资源。形成特定风格或主题图像的统一描述,促进重复使用和修改。
○
具体的输出信息包括:
■
文字描述:体现图像整体或局部特征的句子或短语。
■
标签列表:列出图像中主要内容的标签,方便用户进行快速识别和分类。
○
实际操作与建议
■
为了在实际操作中获得最佳结果,用户可以通过以下几方面进行调整和优化:
●
图像预处理:确保输入图像质量,包括分辨率和噪声控制。
●
模型参数调节:根据特定需求调整模型的 CFG Scale(上下文引导因子)等参数,以影响生成输出的风格和内容。
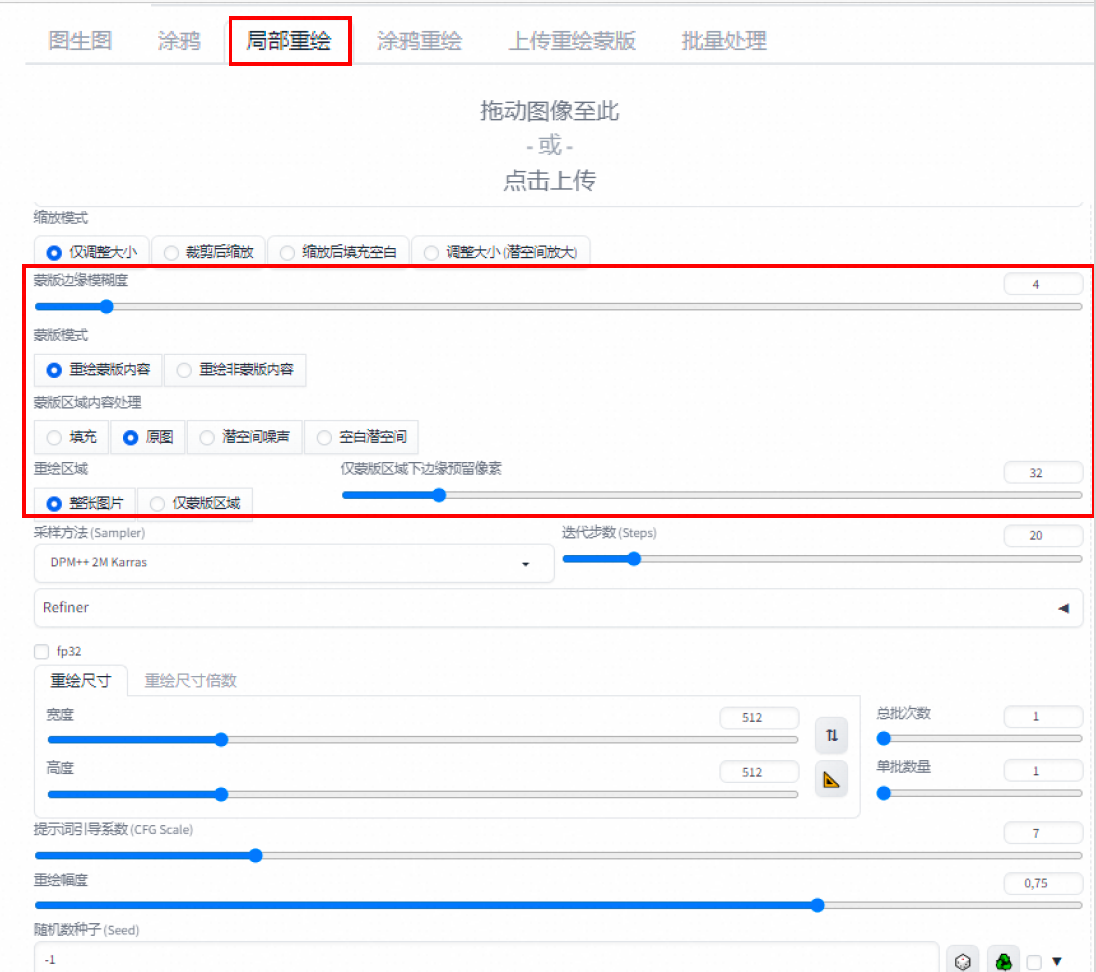
局部重绘
●
使用Stable Diffusion WebUI进行图生图的局部重绘功能是一个强大的工具,可以帮助用户对图像的特定区域进行修改,同时保持其余部分的完整性和风格一致性。以下是关于该功能的知识和操作细节:
○
确保自然过渡:在局部重绘中,如何确保修改后的区域与未修改区域的自然过渡是关键。一种有效的方法是使用遮罩羽化(Mask Blur)功能,适当调整Denoising Strength。羽化可以柔和化遮罩边缘,使新生成的区域与原有图像的过渡更自然。Denoising Strength的调整应确保新内容与原图相辅相成,而不是过于突兀。
○
避免风格断层:风格断层主要发生在新旧区域风格不一致时。避免这一问题的一个策略是保持提示词描述不变,并使用与初始图像相同的种子值。这确保了生成过程的稳定性和一致性。另外,确保CFG Scale适合,避免生成过程中过于依赖于对提示词的错误理解。
○
控制Denoising Strength:Denoising Strength的设置对于局部重绘的效果至关重要。如设置为1.0,则遮罩区域会完全重生,与原始图像脱离关系。此设置适用于需要完全变更的区域。相反,较低的Denoising Strength可以保留更多的原始细节,仅在局部进行细微调整。
○
提示词与遮罩一致性:在提示词与遮罩区域内容不一致的情况下,很可能导致内容风格不匹配。遮罩区域的生成会依据提示词进行,但需注意,与背景的风格统一性可能需要手动调整。这强调了在生成前仔细规划提示词以匹配所需修改区域内容的重要性。
○
大面积区域的精细修改:面对大面积区域,需要精细修改时,将遮罩区域拆分为较小的部分、逐步迭代修改是一个科学的方法。通过这样的方法,用户可以在每个步骤中调整提示词及其他参数,确保局部与整体的高度协调。这种分步优化也允许更多的手动干预,以确保最终结果的精致与一致性。
○
此外,可以尝试通过更多的技术组合来提高局部重绘的效果,如结合使用图像的其他编辑工具(如Photoshop)或利用额外的AI工具,丰富内容而不影响生成稳定性。
●
操作
●
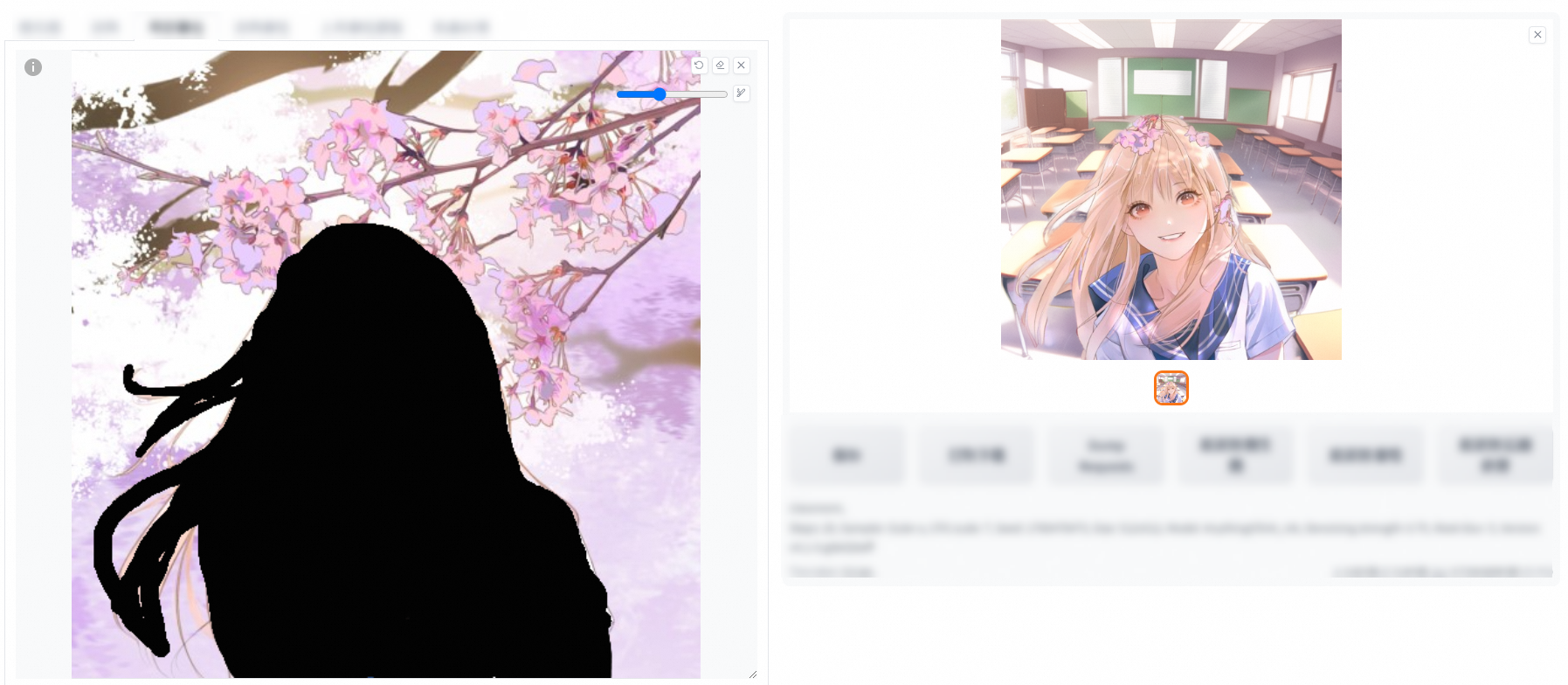
在原图上添加一个蒙版(将需要修改的部位涂黑),对蒙版或者非蒙版区域进行重绘操作。
○
重绘蒙版内容
■
在Prompt中加上想要修改成的内容,单击生成即可。例如,下图在原来的Prompt中增加了wears sweater。

○
重绘非蒙版内容
■
在Prompt中加上想要修改成的内容,单击生成即可完成。例如,下图在原来的Prompt中增加了classroom。
○
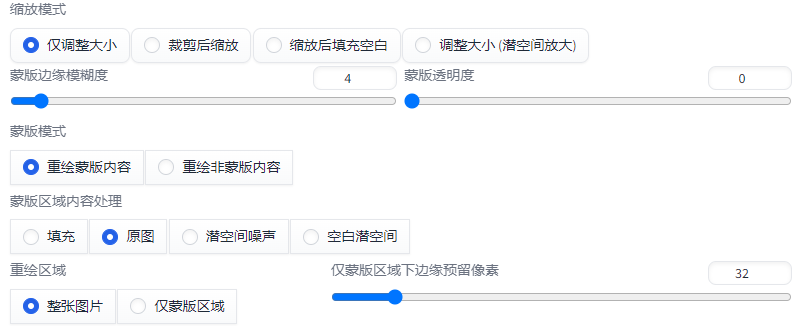
相关参数
■
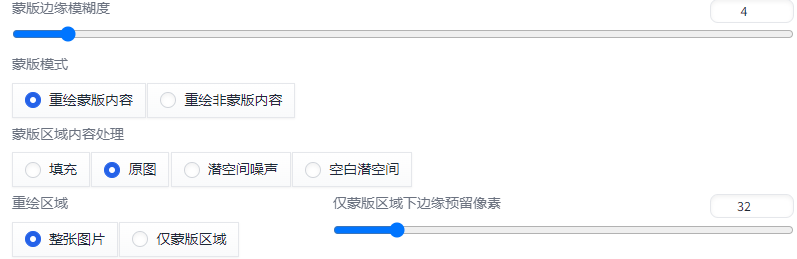
蒙版边缘模糊度:
●
设置重绘区域与原图的融合程度。太小会导致边缘衔接生硬,太大会导致蒙版不精确。默认为4。根据融合效果灵活调节。
■
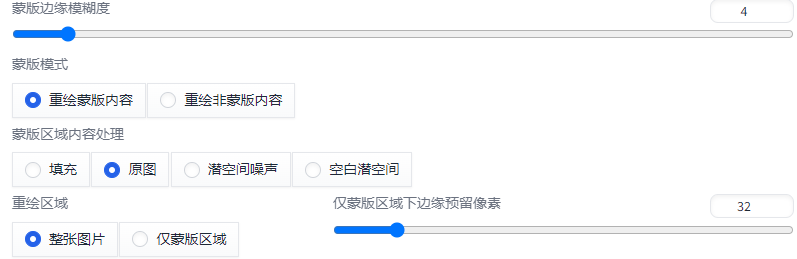
蒙版模式:
●
选择重绘蒙版区域还是剩余背景区域。
■
蒙版区域内容处理
●
填充: 使用经过高度模糊的蒙版边缘颜色(四周像素)进行填充。
●
原图: 以蒙版部分原有画面为基础进行重绘,和原图相关性最高。
●
潜空间噪声: 为蒙版区域添加噪声后再进行重绘。
●
空白潜空间: 将蒙版区域先变为白底图,然后添加噪声进行重绘。

■
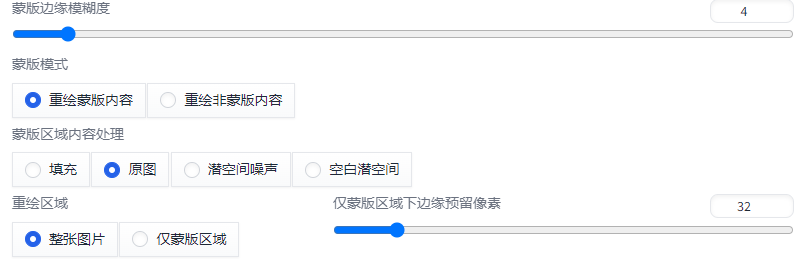
重绘区域
●
整张图片: 细节少。
●
仅蒙版区域:细节多,匹配程度低。
●
仅蒙版区域下边缘预留像素:用于控制重绘部分
●
蒙版区域尺寸= 蒙版在原图的比例*生成尺寸
■
蒙版透明度
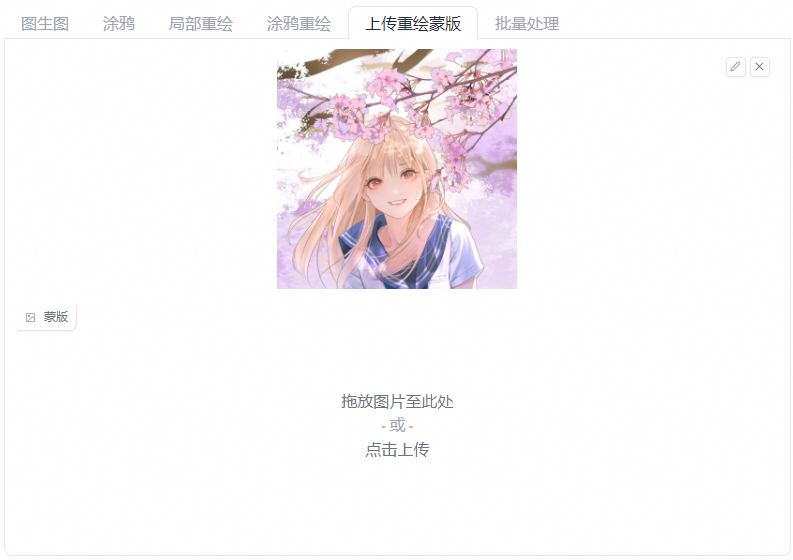
上传重绘蒙版
上传在外部工具(如Photoshop)中制作的蒙版进行遮罩操作,适用于对遮罩区域精细化程度有较高要求的用户。为实现这一效果,请将您预先制作完成的精细蒙版文件上传至下图的下半部分。
批量处理

批量处理img2img指定目录下的图片。需要建立三个文件夹,原图文件夹、输出图片的文件夹和放置蒙版的文件夹。
●
步骤:
> 建立文件夹
> 选择输入目录
> 选择输出目录
> 选择输入批量重绘蒙版目录(可选)
> 选择输入controlnet目录(可选)
> 勾选PNG图片信息
> 选择PNG图片信息目录(可选)
> 选择采用需要从PNG 图片中提取的参数
> 调节参数(可选)
> 输入提示词(可选)
> 生成
课时6. 高清修复
使用Stable Diffusion WebUI中的高清修复功能(Hi-Res Fix)可以显著提升生成图像的分辨率和细节质量。该功能尤其适合需要生成高细节、高分辨率图像的场景,如艺术作品、插图和复杂细节的场景处理。
Hi-Res Fix 的基本原理
Hi-Res Fix 的主要工作流程分两阶段的生成方式,通过“逐步生成”的方式工作,先快速生成一个基础版本再进行细化,确保了生成图像在高分辨率下仍然具有丰富的细节。具体的流程如下:
1.
初始低分辨率生成:首先使用目标分辨率的子集来生成低分辨率的图像。这一阶段关注的是图像整体结构和重要特征的捕捉。
2.
上采样和细节优化:将低分辨率的图像经过算法提升至更高的分辨率。这一步通过细化和加强图像的细节来优化视觉效果。通常,处理过程包括使用不同的采样方法来确保在此过程中图像的细节和质量保持尽可能的高。
关键参数设置
1.
采样方法(Sampler)和放大倍数:
●
采样方法决定了图像的细节实现方式,不同的采样方法可能会影响生成图像的纹理细腻程度和风格。
●
放大倍数决定了图像从低分辨率到高分辨率时的尺寸变化。选择过高的倍数(如超过3倍)可能导致细节的失真,而过低则可能无法达到所需的清晰度。
●
Denoising Strength:
●
该参数控制生成图像与原始输入图像(初始低分辨率图像)之间的变化程度。较高的 Denoising Strength 可以增加生成图像的细节和艺术风格,但可能导致偏离过多,而较低的值则保持对原始图像更高的忠实度。
生成质量影响因素
●
CFG Scale:在低分辨率生成阶段,CFG Scale 参数决定了模型对提示词的遵循程度。较高的值可以带来更精确的图像生成,然而也可能导致不自然的细节,尤其是在高分辨率下。
●
随机种子:不同的种子值会导致不同的图像输出,即便提示词和参数相同。适当选取固定的种子值可以实现图像的可重复性。
●
模型版本:不同版本的模型可能具有不同的基础训练数据和算法优化,对特定风格和细节的表现力也有所差异。
实践技巧
●
在启用 Hi-Res Fix 时,多尝试不同的采样方法和放大倍数组合,以找到适合当前项目需求的最佳设置。
●
当高放大倍数导致细节失真时,考虑降低 Denoising Strength 或调整 CFG Scale,以缓和失真的影响。
●
随时保存中间结果,特别是在测试不同参数组合时,这有助于快速回溯到较优的配置。
除了Hi-Res Fix,也可以利用其他技术辅助更精准的图像生成。"Tiled Diffusion" 可以通过将大图像分割成小块并分别进行处理,提升生成效率和质量。"Tiled VAE" 是一种变分自编码器技术,利用图像的分块来更好地捕捉局部特征。"ControlNet Tile" 则用于在深度学习模型中控制和引导生成图像的局部特性,从而实现更精确的图像生成。
Tiled Diffusion
Tiled Diffusion 是一种将图像分割成更小网格进行分别处理的技术。这种方法能够有效管理高分辨率图像生成时的计算资源,同时还可以通过更细致地控制每一块的生成过程来提高图像生成的质量。
●
网格大小选择的影响: 如题库所示,选择过小的网格大小可能导致图像拼接区域出现明显的失真或断层。这是因为较小的网格需要更频繁地进行边缘拼接,而这种拼接在高复杂度的图像细节中可能产生不连续性。
●
优化策略: 建议根据图像内容和分辨率选择适当大小的网格,以平衡计算资源和生成质量。可以通过实验获取最优设置。
Tiled VAE
Tiled VAE(变分自编码器)是专门为处理大分辨率图像而设计的技术,允许模型以分块的方式处理图像,以减少显存使用量。
●
作用: 主要用于提升大分辨率图像生成的效率。通过分块处理有效地减轻显存负载,同时确保每块图像的生成一致性。
●
应用场景: 在显存有限的硬件上运行大型模型时,Tiled VAE 显得尤为重要。它不仅确保生成的图像有高水平的细节,还可以通过调整网格大小进一步控制内存消耗。
ControlNet Tile
ControlNet 是一种控制条件网络,可用于高清修复和生成任务中的图像结构保持和细节增强。
●
输入图像的重要性: ControlNet Tile 使用输入图像来提供基础的结构信息,确保生成的高清图像与原始图像在构图上保持一致。这在复杂结构的图像生成中尤其关键。
●
风格与细节控制: 为了更好地控制生成图像的风格与细节,用户可以在提示词中加入具体的风格描述,并通过调整 Denoising Strength 来实现。适当的设置可以更好地引导模型在修复过程中保持风格一致性,同时避免丧失细节。
综合应用与优势
结合上述技术,使用 Tiled VAE 和 ControlNet Tile 相比传统高清修复有显著优势:
●
显存效率: 显著降低显存占用,使大分辨率图像生成不再局限于高配硬件。
●
一致性和细节保留: 能够在生成过程中保持整体图像的结构一致性和细节丰富性,适用于需要高品质输出的应用场景,如影视制作、摄影修图等。
在实际应用中,用户可以根据项目需求调整网格和参数设置,以达到最佳效果。在熟悉这些技术背后的原理后,开发和调优更复杂的图像生成和修复项目将变得更加得心应手。
课时7. Controlnet
ControlNet 的功能和用途
1.
精确控制生成图像:ControlNet 的设计初衷是通过控制输入图像的结构特征(如姿态、边缘或深度)来增强生成图像的真实性和一致性。这在如生成特定姿态的人物图像或复杂结构场景方面表现出色。
2.
多模式组合使用:在 ControlNet 中,可以组合不同的模式(如 Pose 和 Canny 模式)以获得更加细化的控制。例如,Pose 模式用于控制图像中人物的姿态,而 Canny 模式则用于定义图像的边缘。
操作流程和模式应用
●
模式输入和选择:
○
辅助图像输入:ControlNet 依赖辅助图像(如边缘图、深度图、姿态图)作为输入,以便对生成图像的各个方面进行详细控制。
○
模式选择和配置:需要根据需求选择合适的模式和相应的预处理器,如 OpenPose 用于姿态检测,MiDaS 用于深度图生成。
●
多模式控制权重:
○
通过调整每个模式的权重参数,可以均衡不同控制模式对最终生成结果的影响。权重越高,该模式对图像生成的影响就越大。
●
完美像素模式与预览:
○
完美像素模式:开启后,ControlNet 将根据输入自动调整预处理器分辨率以保证图像质量。
○
图像预览:在生成图像前提供预处理器处理结果的预览功能,以便用户调整和优化输出。
实际应用案例
1.
复杂人物姿态插画生成:利用 Pose 和 Scribble 模式组合,可以生成具有复杂姿态且风格化的插画,Pose 提供姿态信息,Scribble 则添加个人化的手绘风格。
2.
深度和结构的结合:Depth 和 Tile 模式组合用以设计建筑图像时,Depth 模式负责整体结构,Tile 模式强化局部细节,从而提高生成的视觉细腻度。
3.
材质和结构修改:通过 ControlNet 的 Tile、Softedge 和 t2iadaptercolor 模式组合,能在保留原始图像颜色和结构的基础上,调整并改变图像材质,比如将一幅照片转化为具有不同材质效果的作品。
注意事项
1.
选择合适的 Tile Size:在 Tile 模式下,Tile Size 过小可能导致生成的图像在拼接区域出现断层,因此需要根据图像需求合理设置。
2.
权重配比的调节:在涉及多个控制模型协同工作的情况下,应对各模型的权重进行精细调节,以确保特定细节如姿态或场景的主次关系得到理想呈现。
Controlnet界面介绍

●
Tab页签:生成一个内容可以同时叠加多个Controlnet,每切换到一个Tab页签,就是打开一个新的Controlnet面板
●
启用:选择启用这个Controlnet
●
低显存模式:电脑显存低于8GB以下选择开启这个选项
●
完美像素模式:自动计算最佳的预处理器分辨率
●
允许预览:允许查看Controlnet对上传草图处理的结果
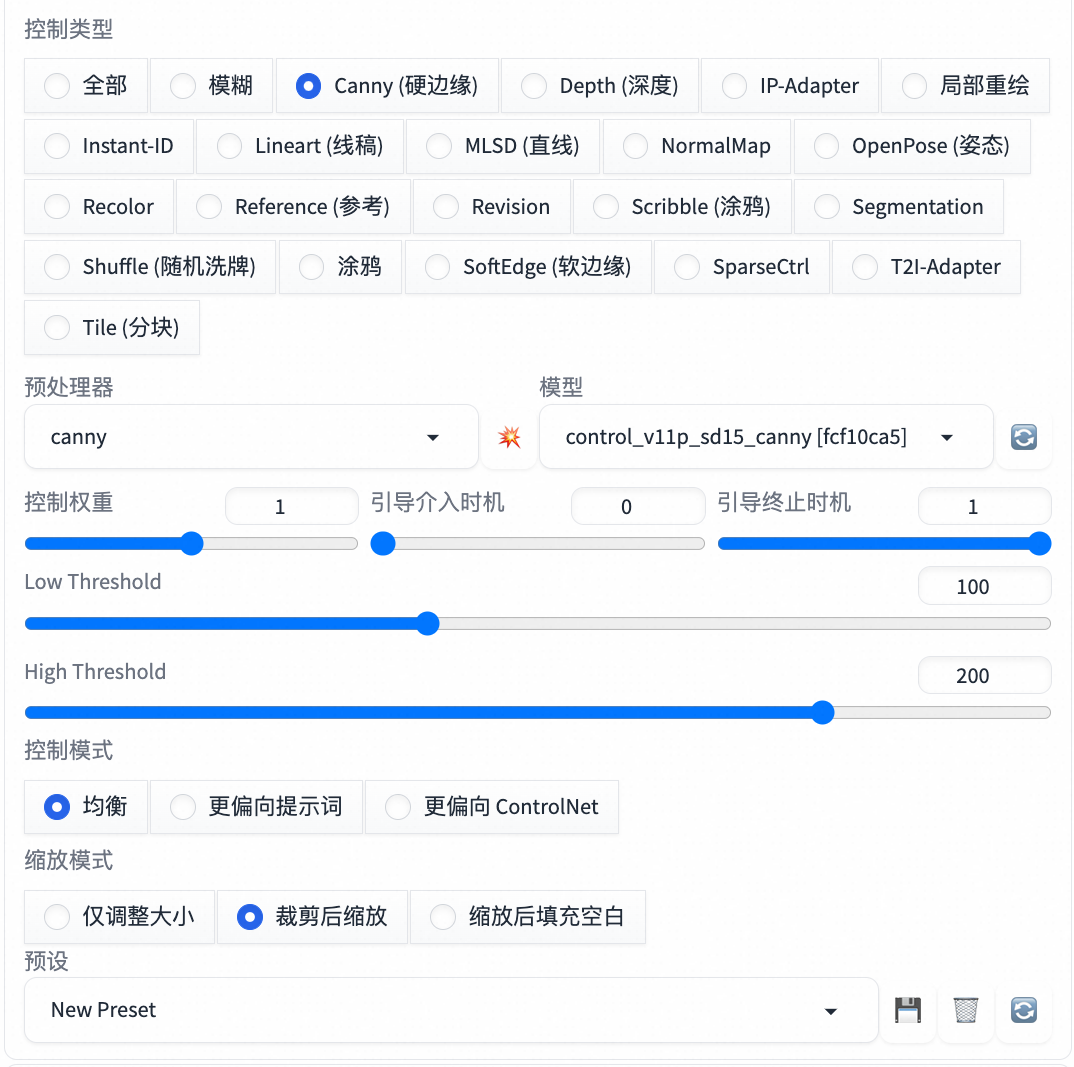


●
预处理器与模型:
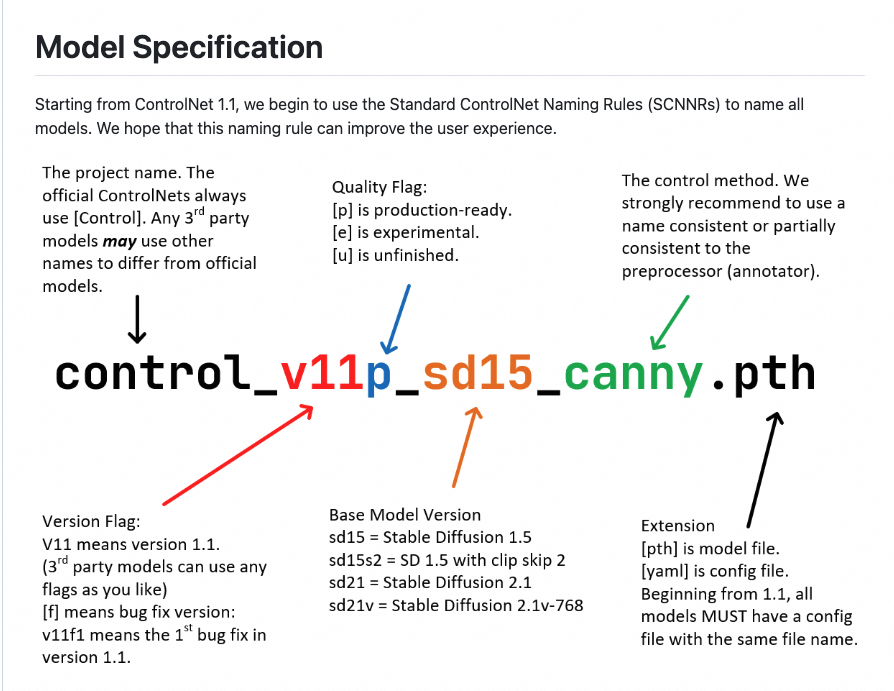
○
命名方式
■
v11:版本
■
p:正式版(production)
■
SD15:基于SD1.5的版本
■
canny:Controlnet的模型
■
.pth:文件后缀
●
控制类型:
○
轮廓类
■
Canny
●
canny:通过灰度变化检测图像中内容的边缘并提取硬边缘
●
invert:输入白底黑线图选择该预处理器进行反色
■
MLSD
●
mlsd:直线线条检测,得到黑色背景的白色直线图像
●
invert:输入白底黑线图选择该预处理器进行反色
■
Lineart
●
lineart_standard:标准线稿提取(白底黑线图)
●
lineart_realistic:真实线稿提取,适用于实景照片,效果图等复杂场景
●
lineart_coarse:粗略线稿提取,控制准确程度低于realistic,SD想象空间更大
●
invert:输入白底黑线图选择该预处理器进行反色
■
SoftEdge
●
softedge_hed :更高的图像质量
●
softedge_pidinet:更好的兼容性
■
Scribble
●
scribble_pidinet:手绘涂鸦,线条连贯性强,会丢掉部分细节
●
scribble_hed:合成涂鸦
●
scribble_xdog:强化边缘涂鸦,有可调参数区域,图像尺寸带来
●
invert:输入白底黑线图选择该预处理器进行反色
■
Segmentation
●
seg_ofade20k:语义分割预处理器,将图像转化为通道图
○
重绘类
■
Inpaint:根据用户输入的文本描述直接编辑图像
■
Shuffle
●
shuffle:将原有图像的颜色信息打乱,再重新排列同样的 像素去生成一个物品或其他场景
■
Recolor
●
recolor_intensity:提取图像特征信息时注重颜色的亮度
●
recolor_luminance:提取图像特征信息时注重颜色的亮度
○
参考类
■
Reference
●
reference_only:输入参考图进行风格迁移,建议参考权重=0.5
●
reference_adain+attn:自适应风格迁移模型,建议参考权重1.0
■
IP-Adapter
●
ip-adapter_clip_sd15:参考图像中的所有信息并还原或迁移
■
T2I-Adapter
●
t2ia_color_grid:参考原图的颜色生成图像
○
景深类
■
Depth
●
depth_leres++:拥有调节块的深度模型,排除的是深度信息
●
depth_midas:综合能力优秀的深度模型,近远景表现优秀
●
depth_zoe:近景能力优秀的深度模型,缺乏远景深度
■
NormalMap
●
normal_bae:倾向于在背景和前景中渲染细节
●
normal_midas:适合将主体与背景隔离
 ●
控制权重:生成图像时CN被应用的权重占比
○
如果叠加多个CN,每个CN的权重都要降低。
○
如果同时使用CN和LoRA,需要平衡各项功能的权重
|
 ●
控制模式:控制Promot和CN对结果的影响程度
|
 ●
缩放模式:图像尺寸不一致时的处理方式
|
 ●
预设:可以将设置好的参数保存为预设,下次使用的时候直接选择(保存/清空/刷新)
|
.登陆并开通
1.1>注册阿里云账号,支付宝扫码登录并完成实名认证:https://cn.aliyun.com/
1.2>二次检查是否已完成个人实名认证
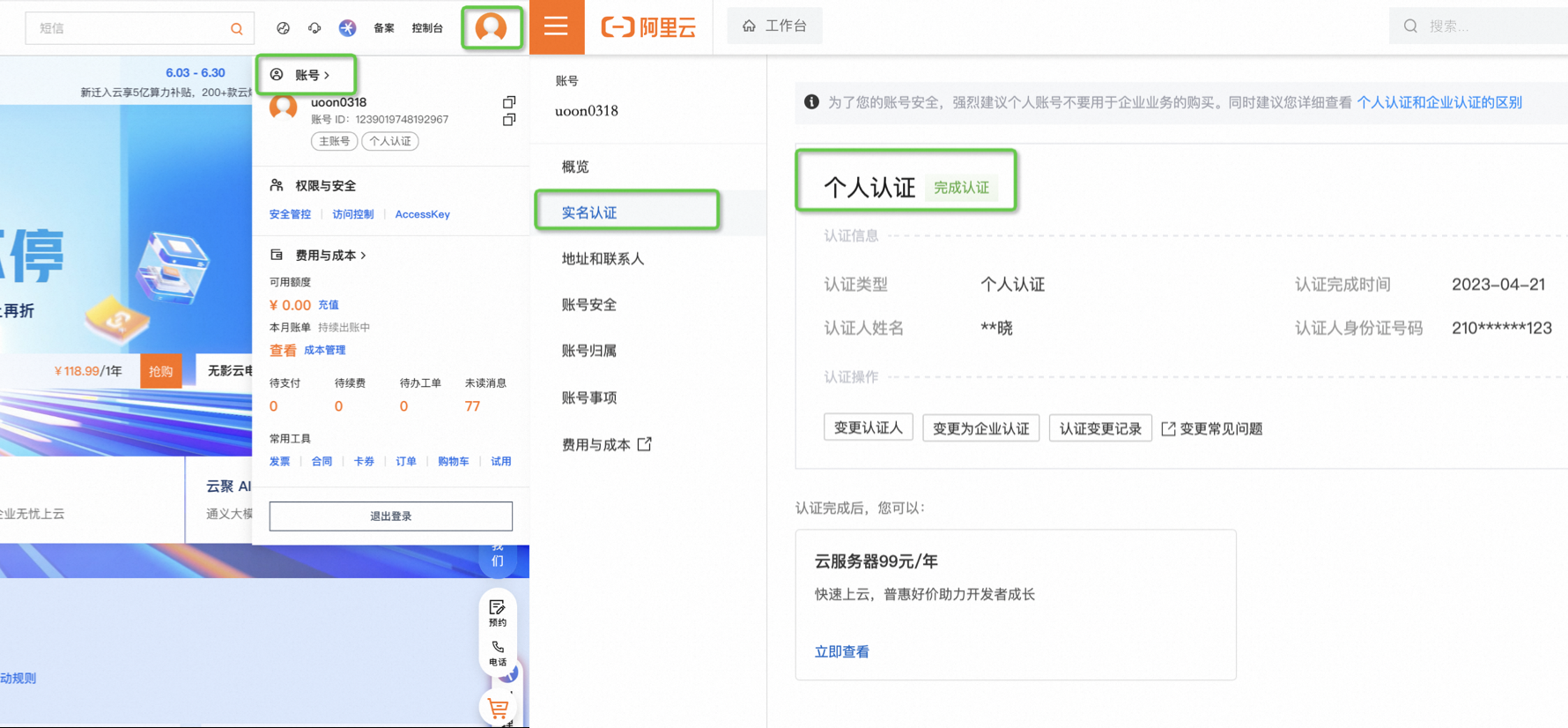
点击官网右上角头像,下拉面板中选择实名认证,再次检查是否已完成个人认证,没有完成的话再完成一下。
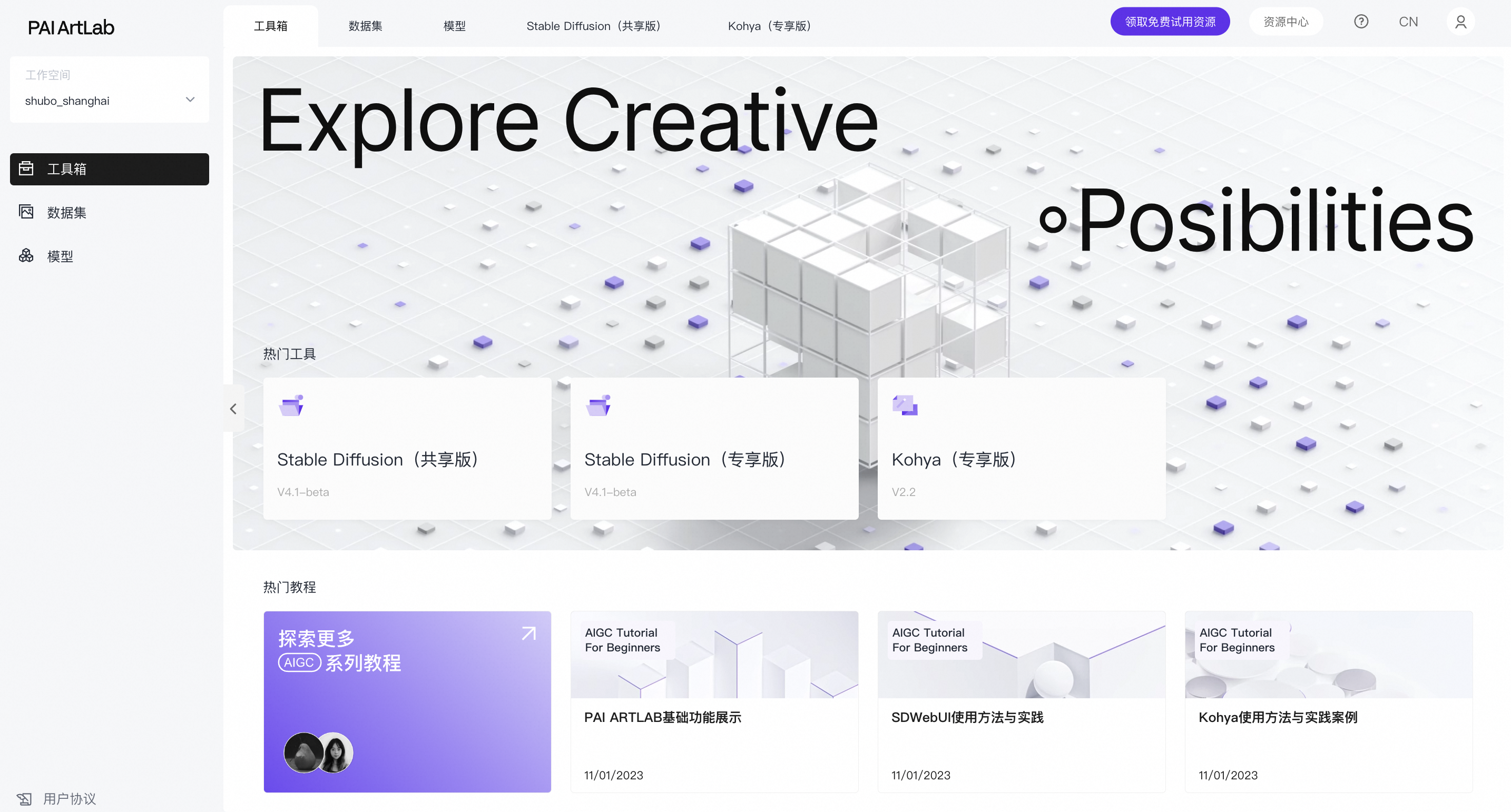
1.4>初次进入平台,依次点击三步,完成ArtLab平台开通与授权,

1.5>完成ArtLab平台开通与授权,进入到首页
2.资源检查-确保自己领取了阿里云免费试用资源或者代金券
|
2.1.提醒
1、免费试用方法有两种
a.确保自己完成免费试用资源领取(所有人都可以领)
b.确保自己完成云工开物代金券领取(仅仅学生可以领)
2、领取免费试用资源的同学,请务必检查,算力、存储与流量都必须都要领取
|
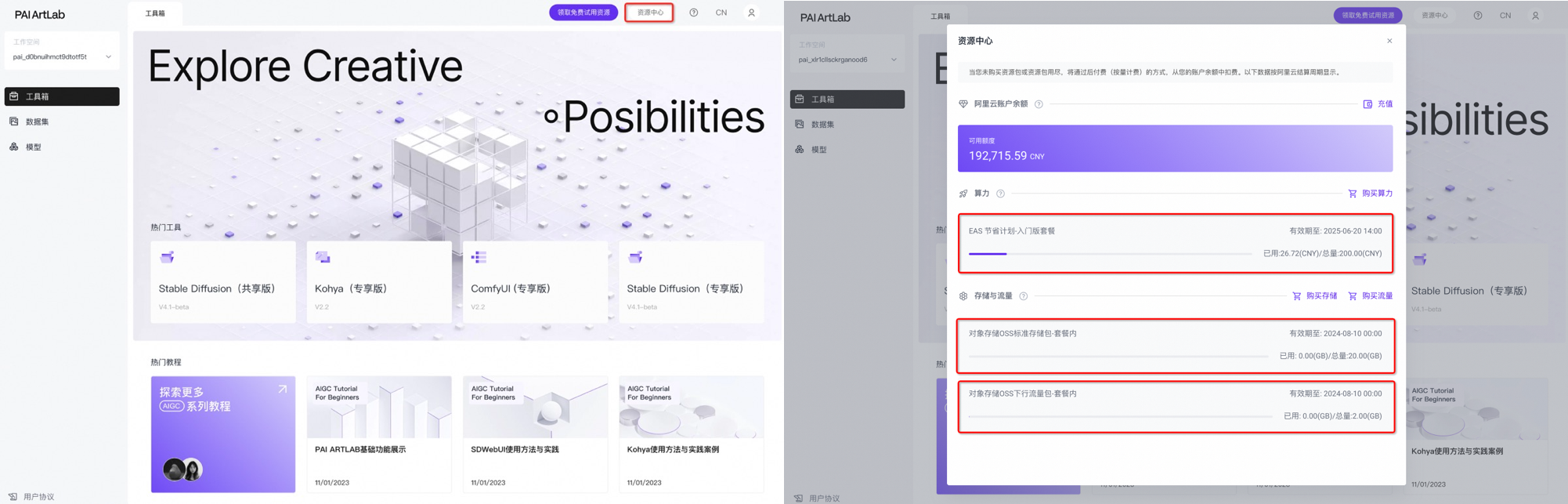
2.1>如何检查自己免费试用资源是否领取成功
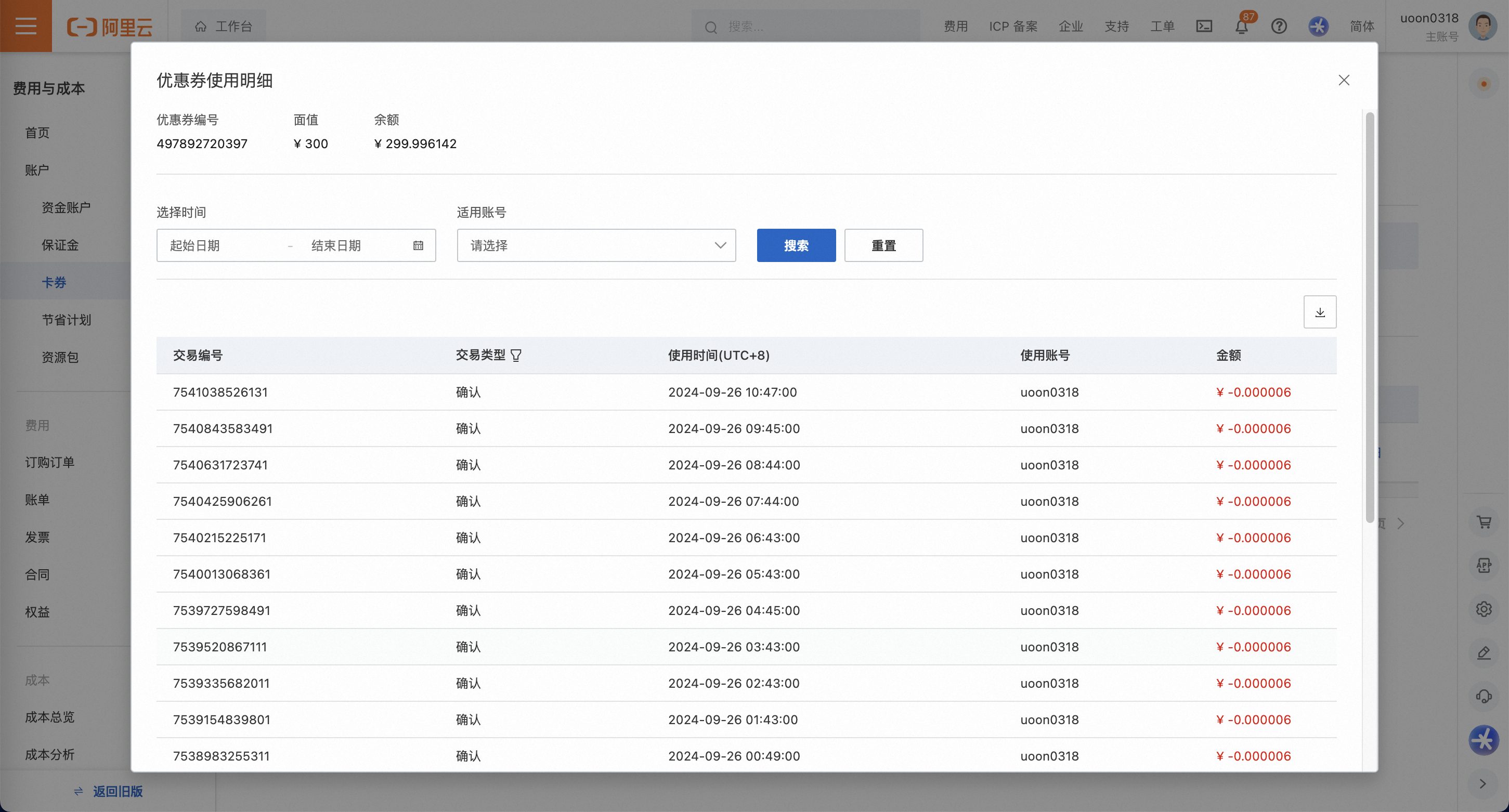
2.2>如何检查自己代金券是否领取成功
 |
 |
 |
 |
3.打开工具
3.1>打开SD共享版工具
来到首页工具箱,选择SD共享版工具卡片,点击卡片,启动工具(初次启动工具需要一些时间,请耐心等待)
4.文生图
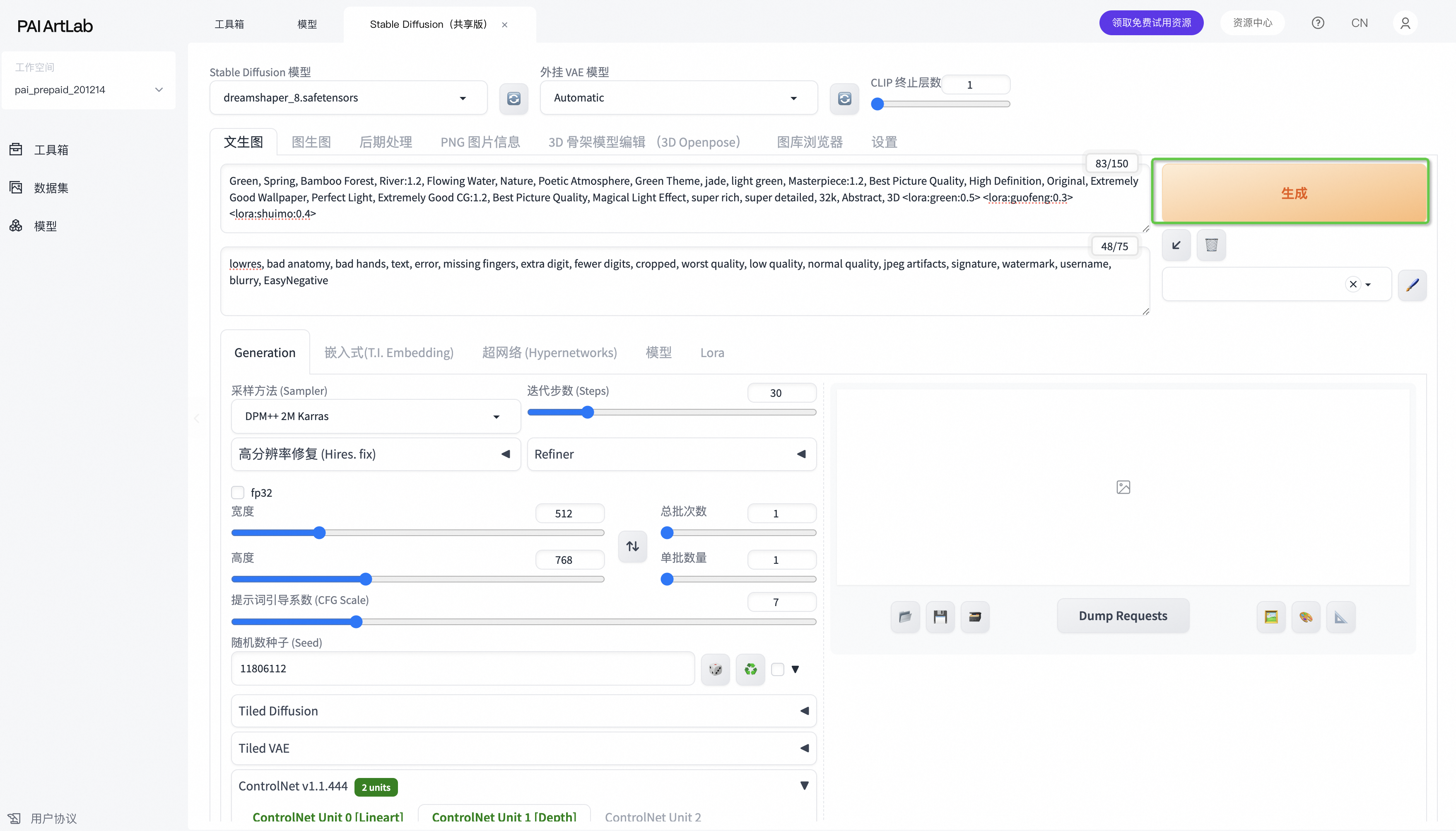
4.1>设计提示词-控制图像生成内容
🍃正向提示词(夏天):
Green, Spring, Bamboo Forest, River:1.2, Flowing Water, Nature, Poetic Atmosphere, Green Theme, jade, light green, Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, 3D<lora:shuimo:0.5> <lora:green:0.1> <lora:guofeng:0.8>
❄️正向提示词(冬天):
白色主题:snowy, snow mountain, White Theme, White color, Winter scenery, natural scenery, overlapping peaks, red rime:1:2, Forest, Nature, Poetic Atmosphere, Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, 3D <lora:shuimo:0.5> <lora:green:0.1> <lora:guofeng:0.8>
橙色主题:big snowflakes, snowstorm, snow mountain, white and orange Theme, white and orange color, Winter scenery, winter natural scenery, frosty overlapping peaks, orange rime:1:2, Forest, Nature, Poetic Atmosphere, Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, 3D <lora:shuimo:0.5> <lora:green:0.1> <lora:guofeng:0.8>
绿色主题:severe winter, wintertim forest, snowdrift, white and green theme, white and green color, winter scenery, winter natural scenery, frosty overlapping peaks, white rime:1:2, Forest, Nature, Poetic Atmosphere, Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, 3D <lora:shuimo:0.5> <lora:green:0.1> <lora:guofeng:0.8>
反向提示词:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry

提示词结构:
画面内容描述:Green, Spring, Bamboo Forest, River:1.2, Flowing Water, Nature, Poetic Atmosphere, Green Theme, jade, light green
提升画面质量:Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, 3D
调用LoRA模型 <lora:green:0.5> <lora:guofeng:0.3> <lora:shuimo:0.4>(调用LoRA模型,调整LoRA模型权重)
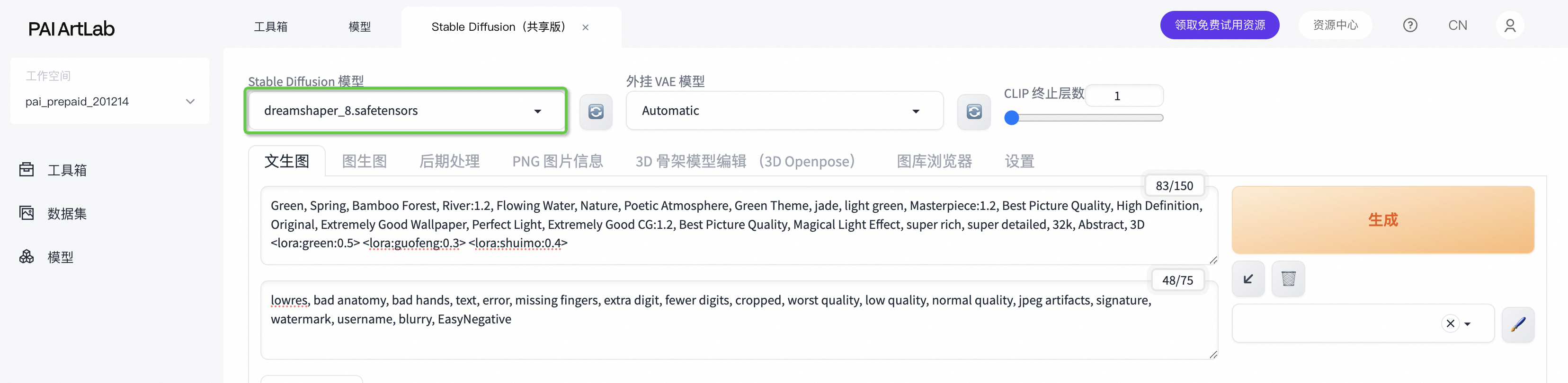
4.2>选择模型
选择Stable Diffusion (Checkpoint)模型:dreamshaper_8.safetensors
4.3>其他设置
●
迭代步数:30
●
采样方法:DPM++2M Karras
●
宽高:512*768
●
种子数有以下几个,大家可以自由选择:
○
随机种子:-1
○
994414790
○
2897581471
○
4112712676
○
460787179

4.4>最后点击生成
4.5>查看生成效果
我们可以通过调整提示词来改变生成画面的内容。(选择不同采样方法,更换不同模型,来改变画面效果)
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
5.Controlnet
5.1>下载素材图片
 |
 |
 |
 |
Controlnet1:选择用其中一种, Lineart (线稿)或者 Canny (硬边缘线条检测)
|
●
Controlnet1: Lineart (线稿)
○
选择Controlnet第一个tab选项
○
上传一张图片
○
依次选择绿色框内容,lineart 处理器coarse,ca49e26d, 权重0.3
○
调整好参数与选项后,最后再点击小爆炸按钮
 |
●
Controlnet1: Canny (硬边缘线条检测)
○
选择Controlnet第一个tab选项
○
上传一张图片
○
依次选择绿色框内容,lineart 处理器coarse,ca49e26d, 权重0.3
○
调整好参数与选项后,最后再点击小爆炸按钮
 |
Controlnet2:选择Depth(深度)
●
Controlnet2: Depth(深度)
○
选择Controlnet第二个tab
○
上传与上面同样的图片
○
依次选择绿色框内容, Depth 处理器zoe,132477ea,权重0.8
○
调整好参数与选项后,最后再点击小爆炸按钮

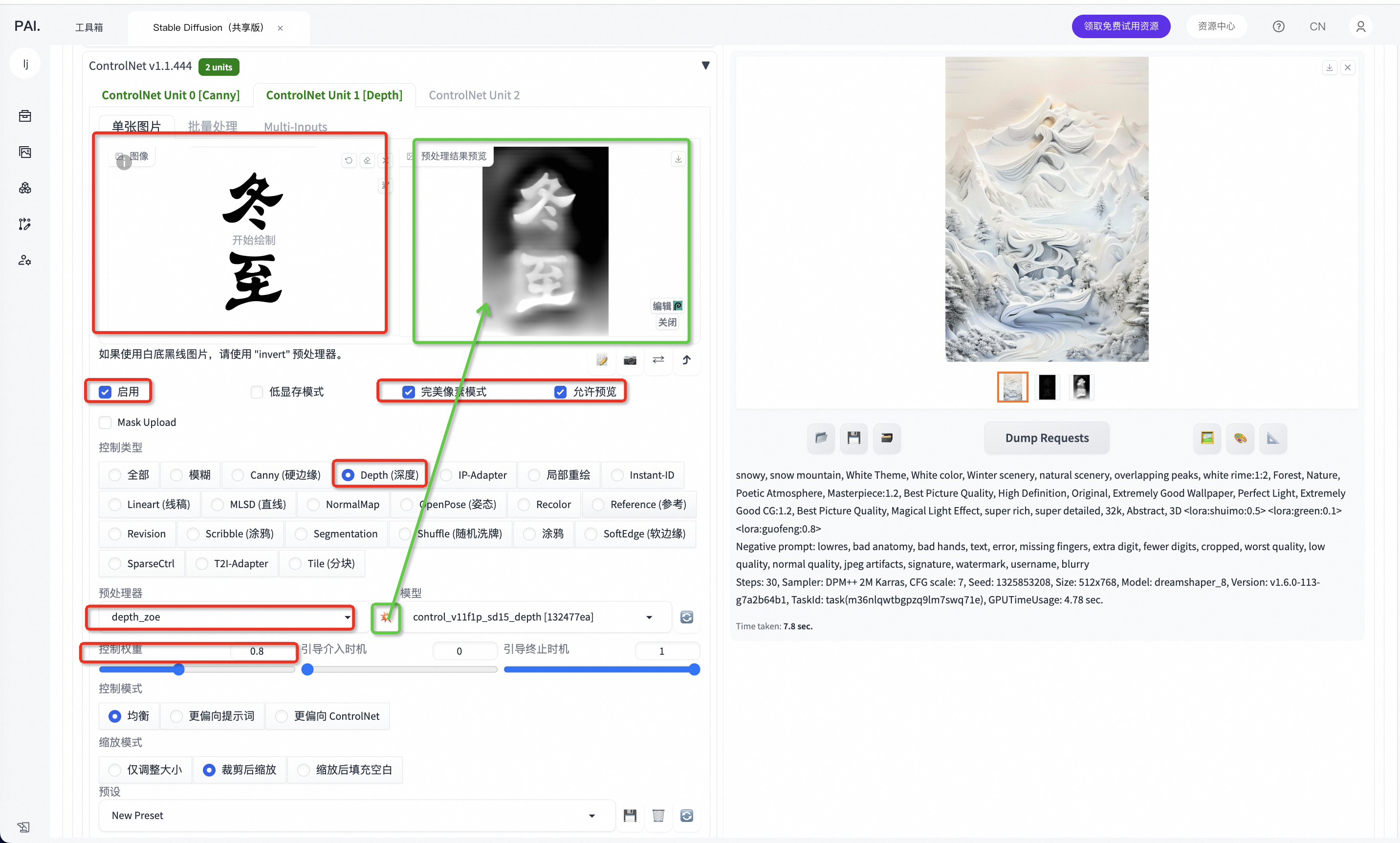
正向提示词可以微调:
snowy, snow mountain, White Theme, White color, Winter scenery, natural scenery, overlapping peaks, white rime:1:2, Forest, Nature, Poetic Atmosphere, Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, 3D <lora:shuimo:0.5> <lora:green:0.1> <lora:guofeng:0.8>
种子数可以微调:
●
-1
●
1325853208
●
2347708238
5.2>最后点击生成
我们也可以在生成时,适当调整提示词,选择不同的采样方法,更换不同模型,来改变我们的画面效果

 |
 |
 |
5.3>其他提示词和模型生图组合
在不改变参数情况下,我们可以靠输入不通提示词和调用不同的模型,来改变我们的生成结果。接下来,给大家几组提示词和模型的搭配,大家可以尝试使用不同的搭配来生成不同风格的图像。
|
组合1 >
Checkpoint:GhostMix
 Lora:huaniao 花鸟、Tangbohu Ink
 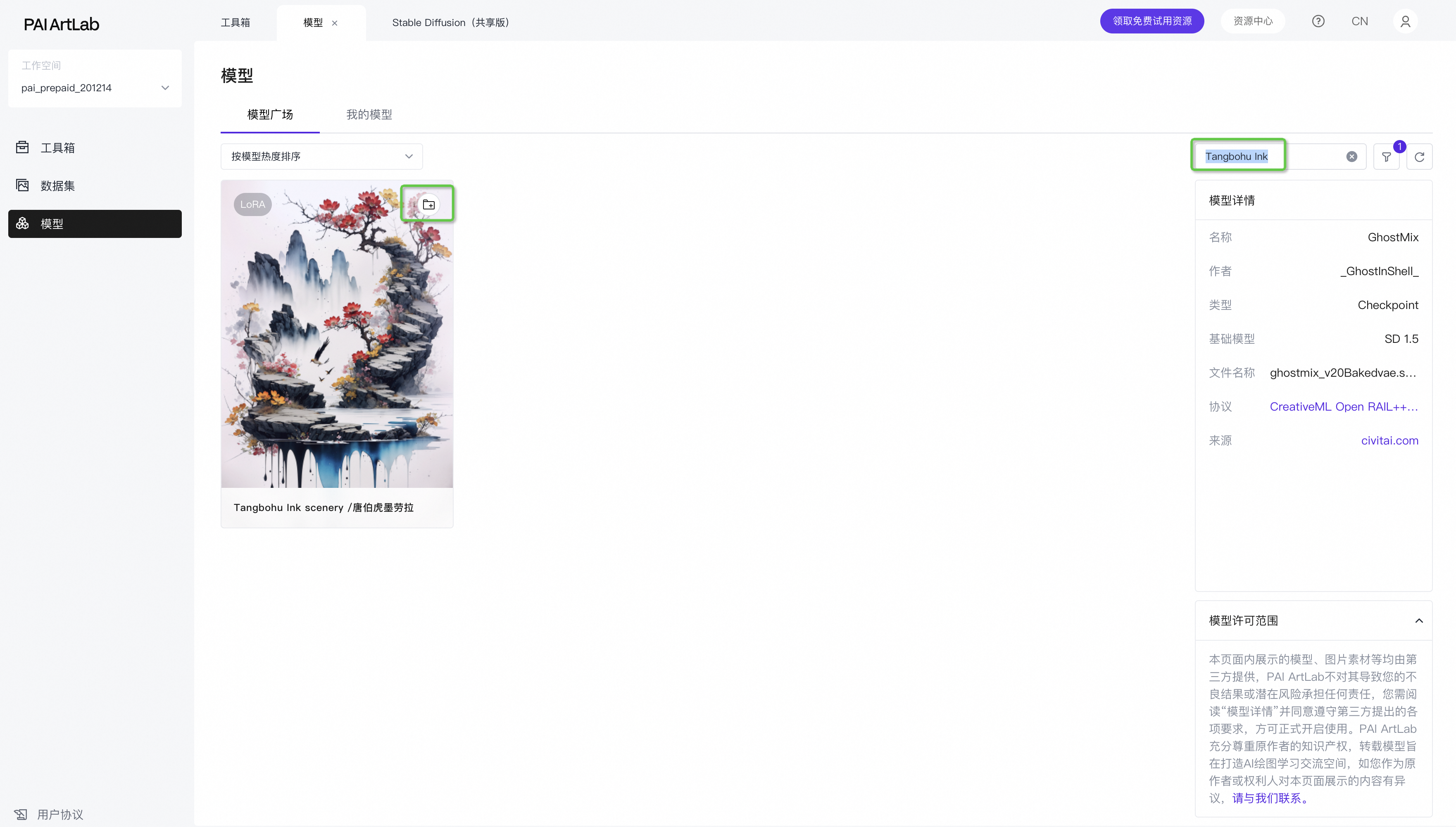 所有添加到“我的模型”的模型,需要在“我的模型”页面,点击“添加到共享版”
 再回到共享版刷新一下对应模型的刷新按键,即可看到最新添加的模型
提示词:
正向提示词:illustration,exquisite lines,minimalism,colorful:1.5, colorful theme,Summer:1.5, Blooming Flowers:2, huaniao, ink, scenery, tree, splash, mountain, Ancient Style Oil Painting, Mountains, Chinese Architecture,no humans, outdoors,scenery, sky, grass,traditional media, sky, cloud(extremely detailed CG unity 8k wallpaper:1.1), (panorama:1.4), Masterpiece:1.2, Best Picture Quality, High Definition, Original, Extremely Good Wallpaper, Perfect Light, Extremely Good CG:1.2, Best Picture Quality, Magical Light Effect, super rich, super detailed, 32k, Abstract, <lora:chuanyugudai:0.8> <lora:inklora:0.3> <lora:huaniao:0.3>
负向提示词:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry, EasyNegative, (NSFW:1.2),(logo:1.2),text,(blurry:1.1),(low quality:1.1),bad anatomy,(lowres:1.1),normal quality,(monochrome:1.2),(grayscale:1.2),(worstquality:1.2),signature,bad proportions,username,water,
提示词相关性:10
|
生成效果 >
 |
|
组合2 >
Checkpoint:Blazing Drive
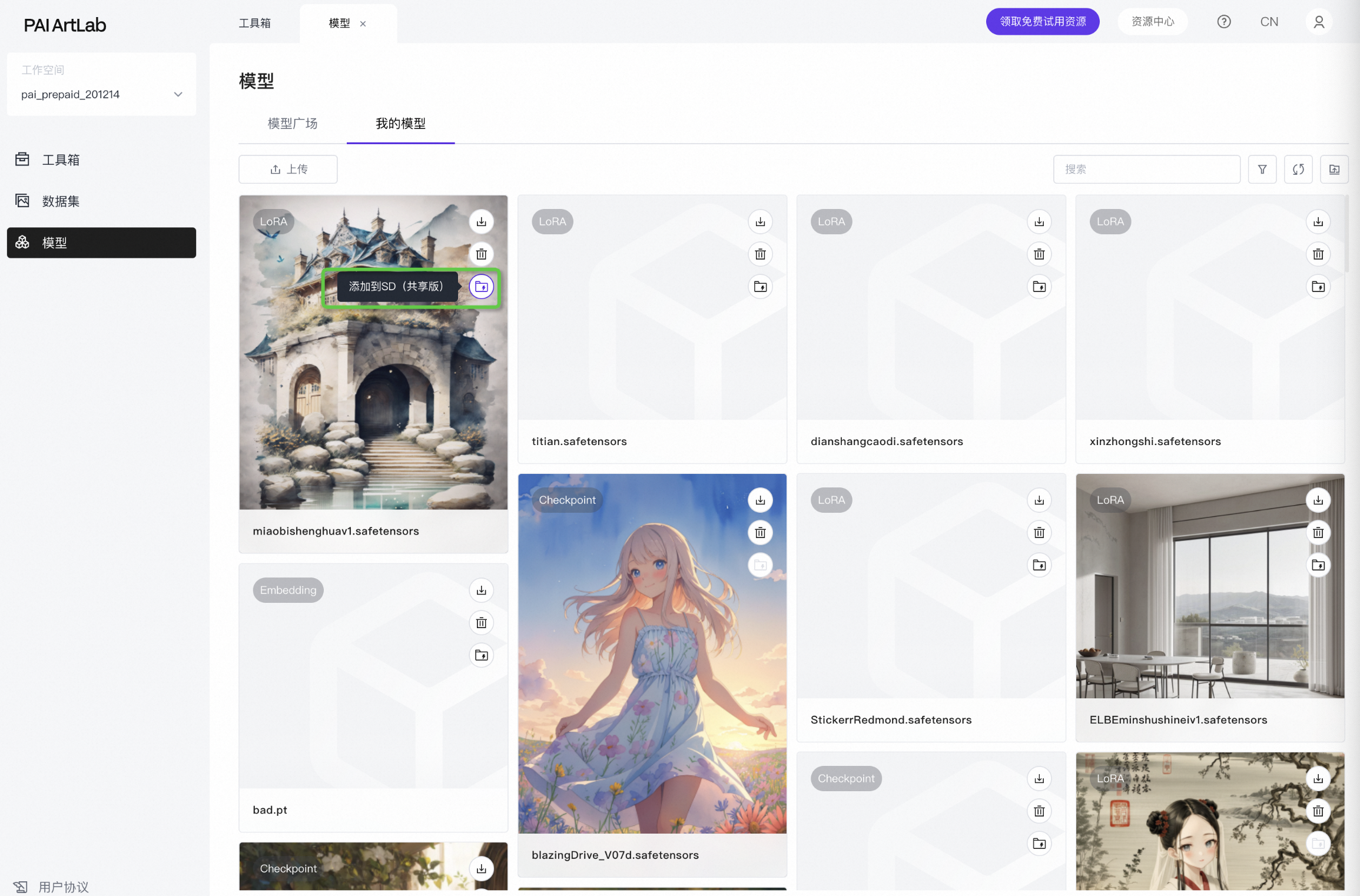
 Lora:yeshousecai、chouxiangfengge、duanwujie
   所有添加到“我的模型”的模型,需要在“我的模型”页面,点击“添加到共享版”
 再回到共享版刷新一下对应模型的刷新按键,即可看到最新添加的模型
提示词:
正向提示词:flower,outdoors,sky,day,cloud,blue_sky,no_humans,cloudy_sky,grass,scenery,pink_flower, mountain,purple_flower,field,house,flower_field,mountainous_horizon,windmill, <lora:yeshousecai:0.6> <lora:chouxiangfengge-huancaizhongshichouxiang-ZSCX:0.5> <lora:duanwujie_yiqihualongzhou_v1.0:0.4>
负向提示词:blurry, noisy, deformed, flat, low contrast, unrealistic, oversaturated, underexposed, EasyNegativeV2, nsfw
Seed:2405616265
|
生成效果 >
 |
|
组合3 >
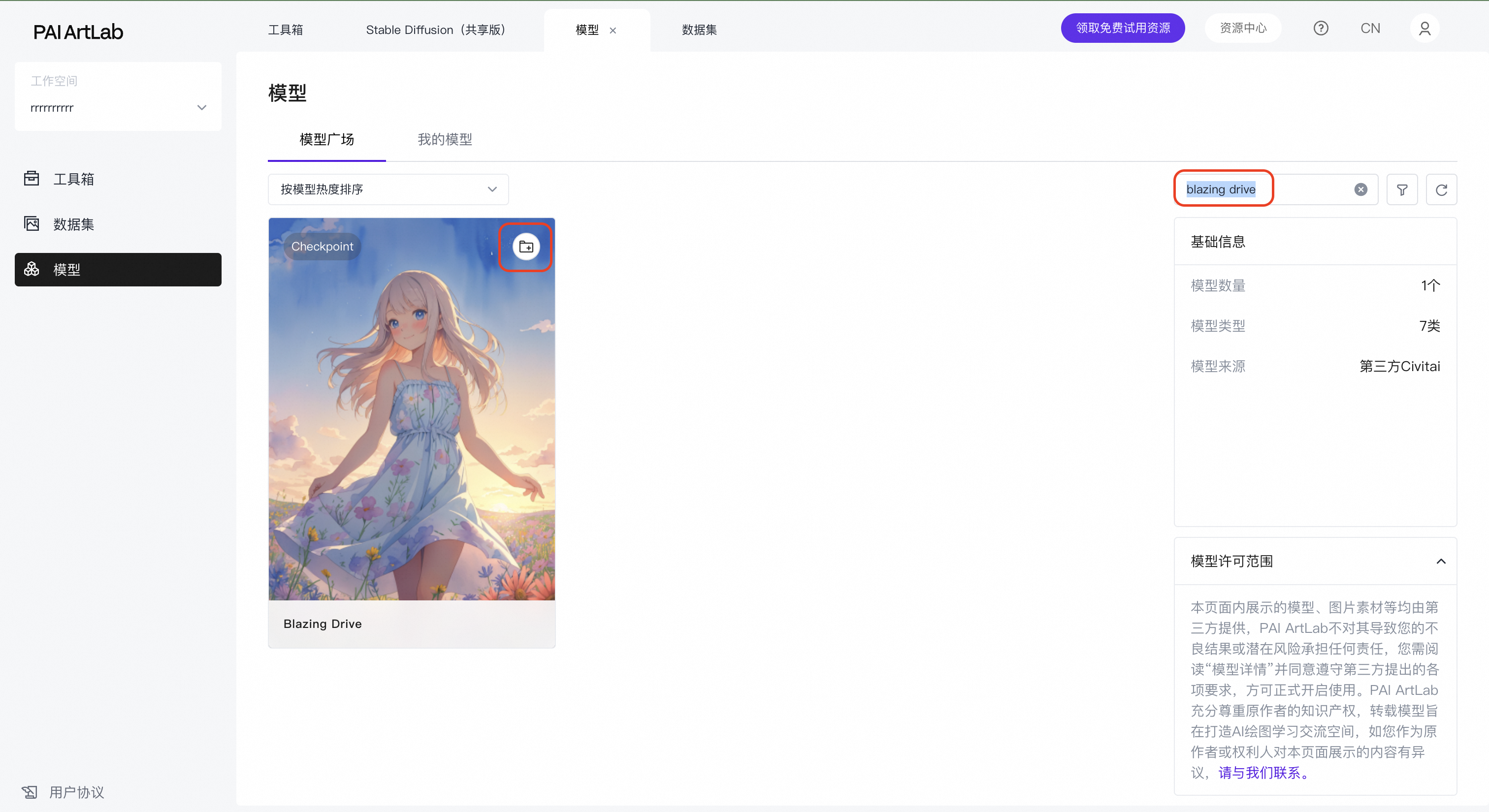
Checkpoint:Blazing Drive
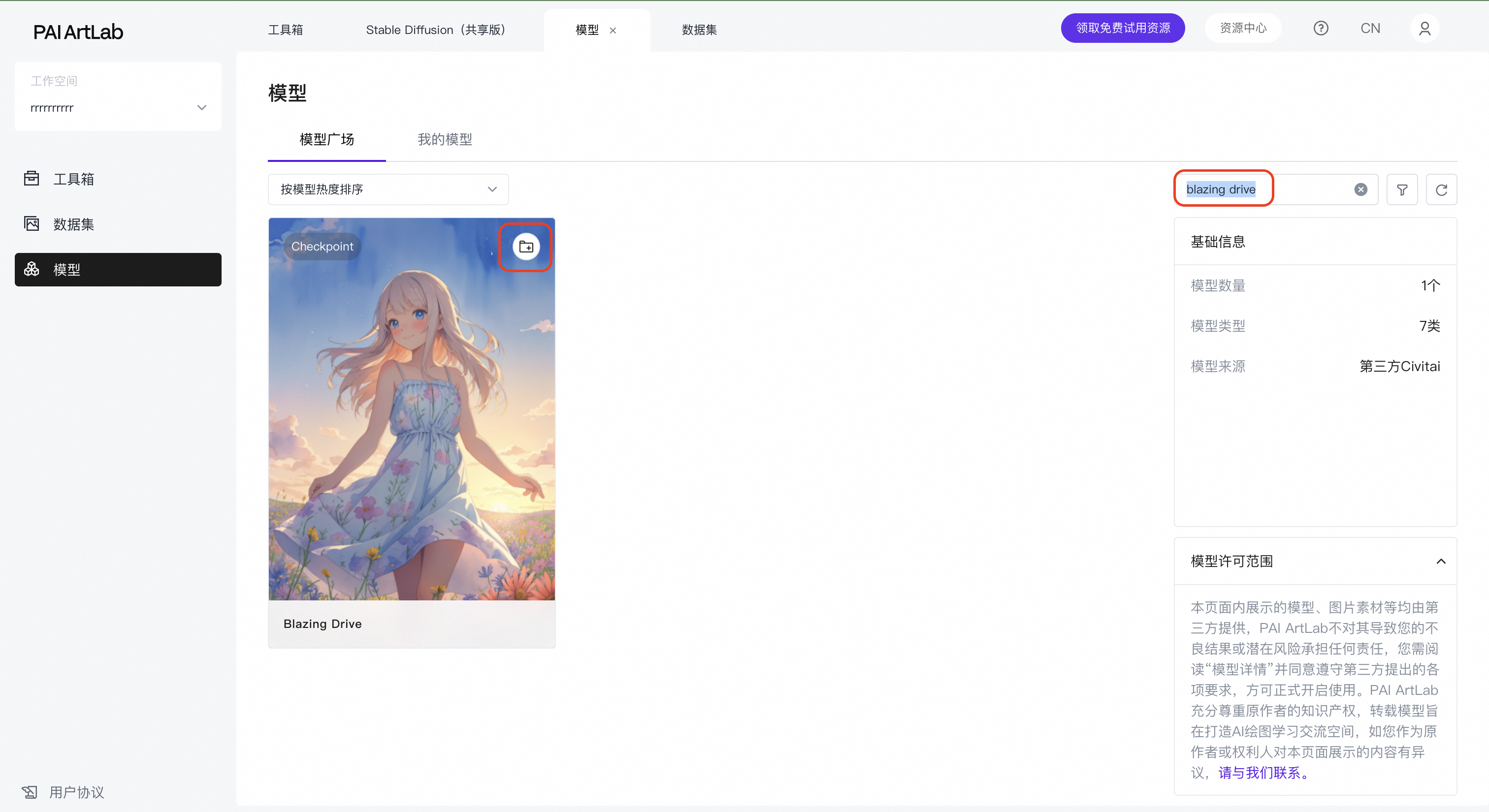 Lora:shuimo、wuxia、tangbohu_xia
   提示词:
正向提示词:The summer solstice of the Chinese solar term, Bright color,and in the busy spring of farming, all things in the world revive and thrive. In the sky, there is a beautiful rainbow, wood, green rice fields, many small animals, (water droplets: 1.2), green grasslands, ponds, on the ground, butterflies, ladybugs, plants, water, flowers, leaves, lakes, no one, the background is the earth,masterpiece, the best quality, wide-angle lens,<lora:shuimo:0.3> <lora:wuxia2:0.4> <lora:tangbohu_xia:0.5>
负向提示词:EasyNegative,low quality
Seed:3335238013
|
生成效果 >
    |
6.图生图-高清修复
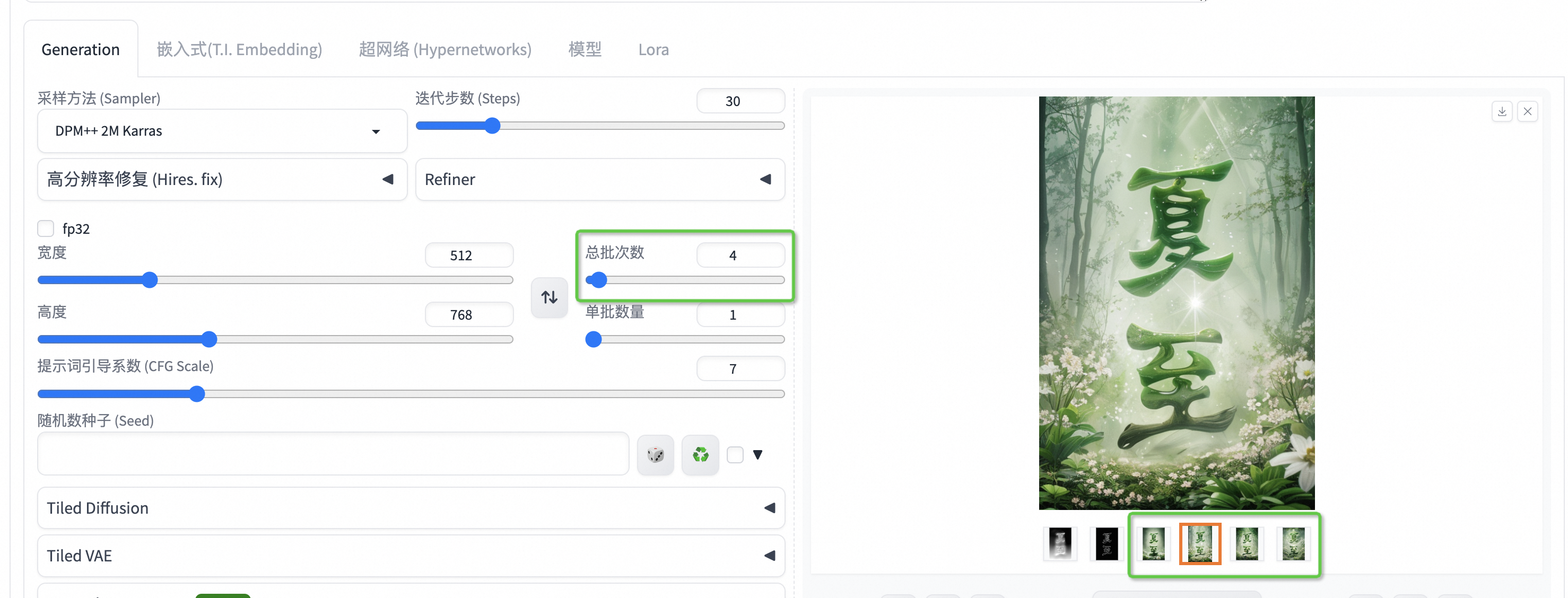
6.1>单修改总批次4-6,每次多生成几张
6.2>发送至“图生图”
选择一张自己满意的图,发送至“图生图”
也可以选择“png信息”,从本地上传一张之前生成的图片进来,再“发送至图生图”
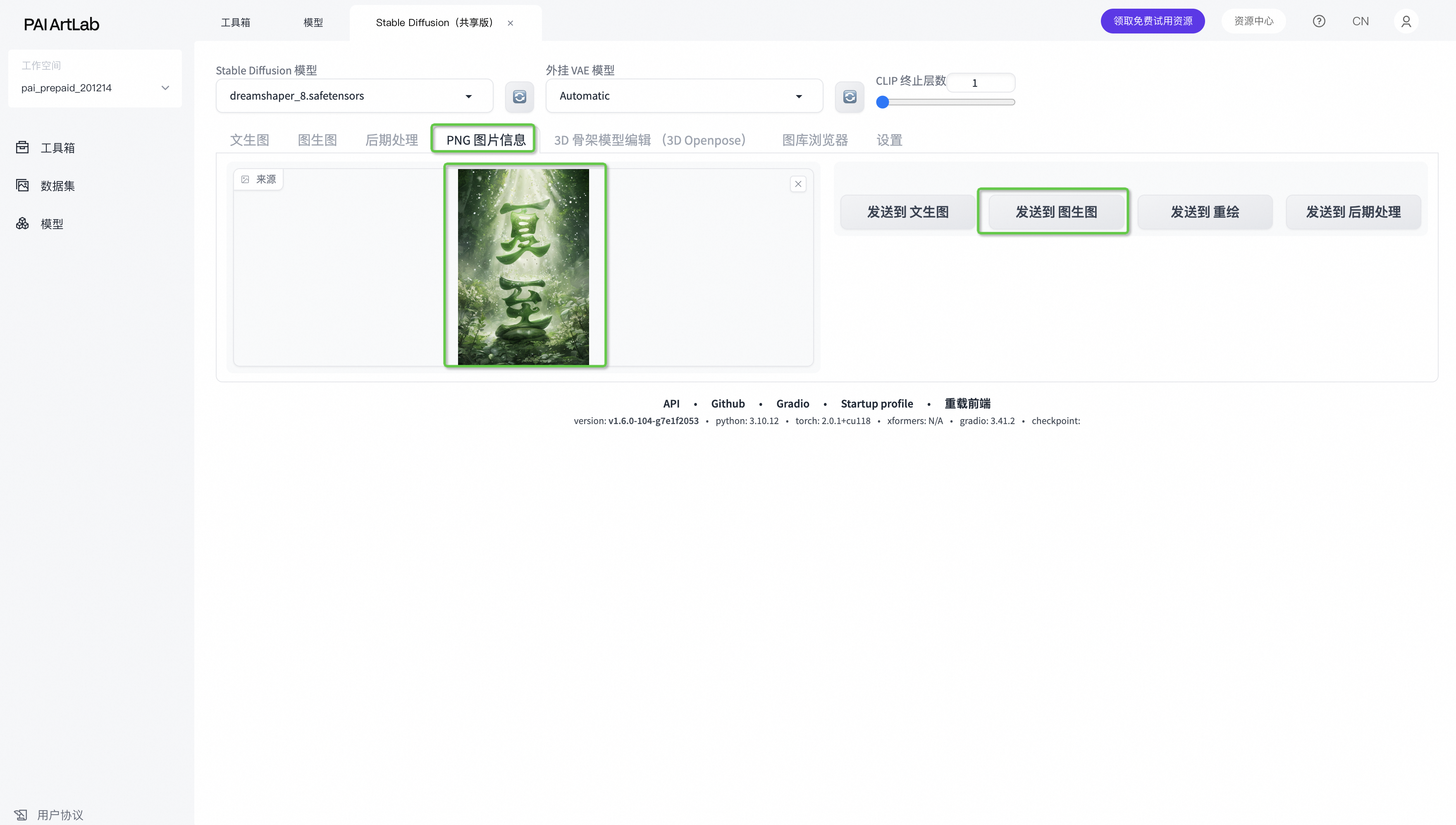
发送的图会包含之前你生成这张图的所有信息
设置controlnet:Tile 处理器resample 权重0.8
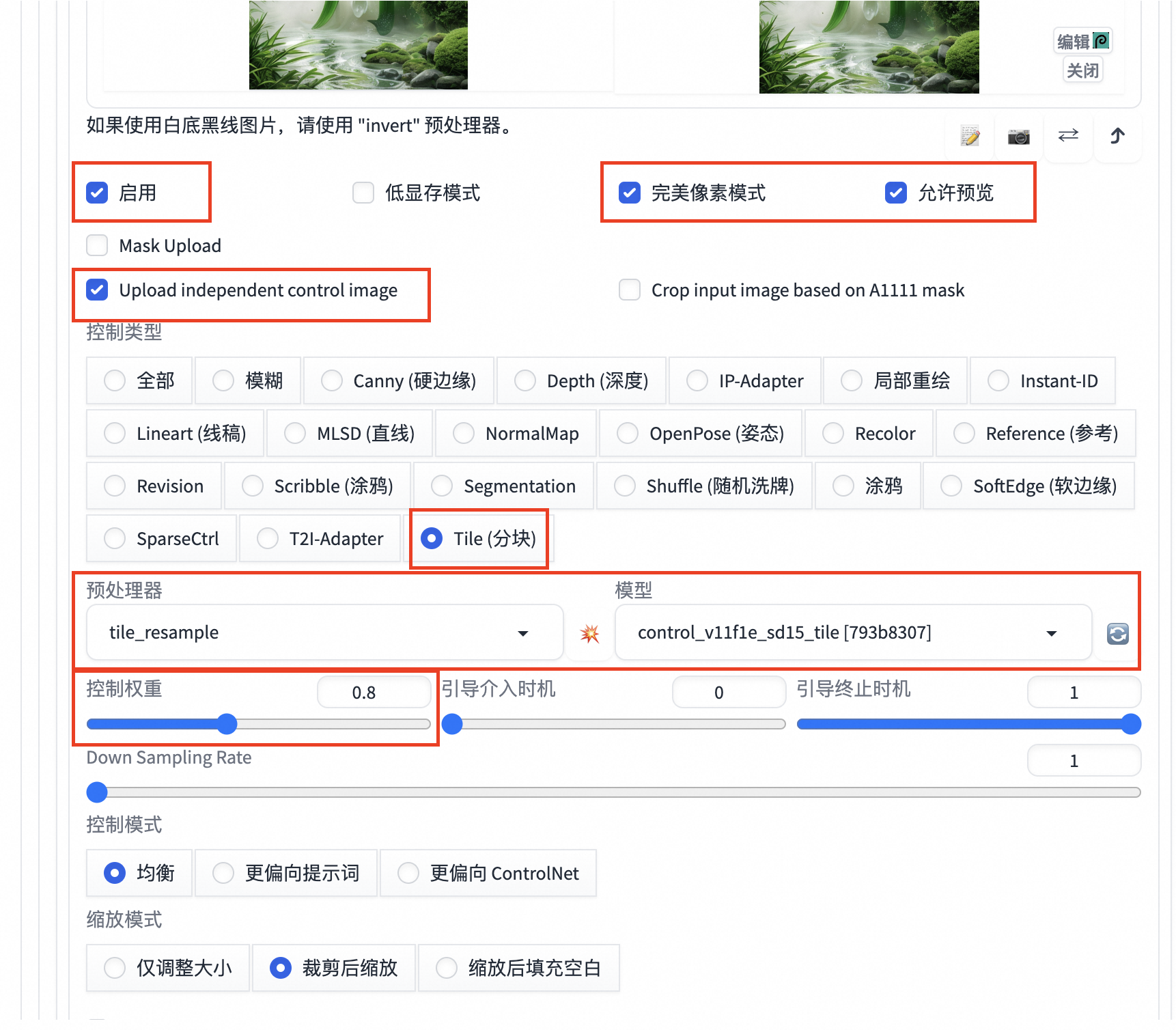
选择放大脚本
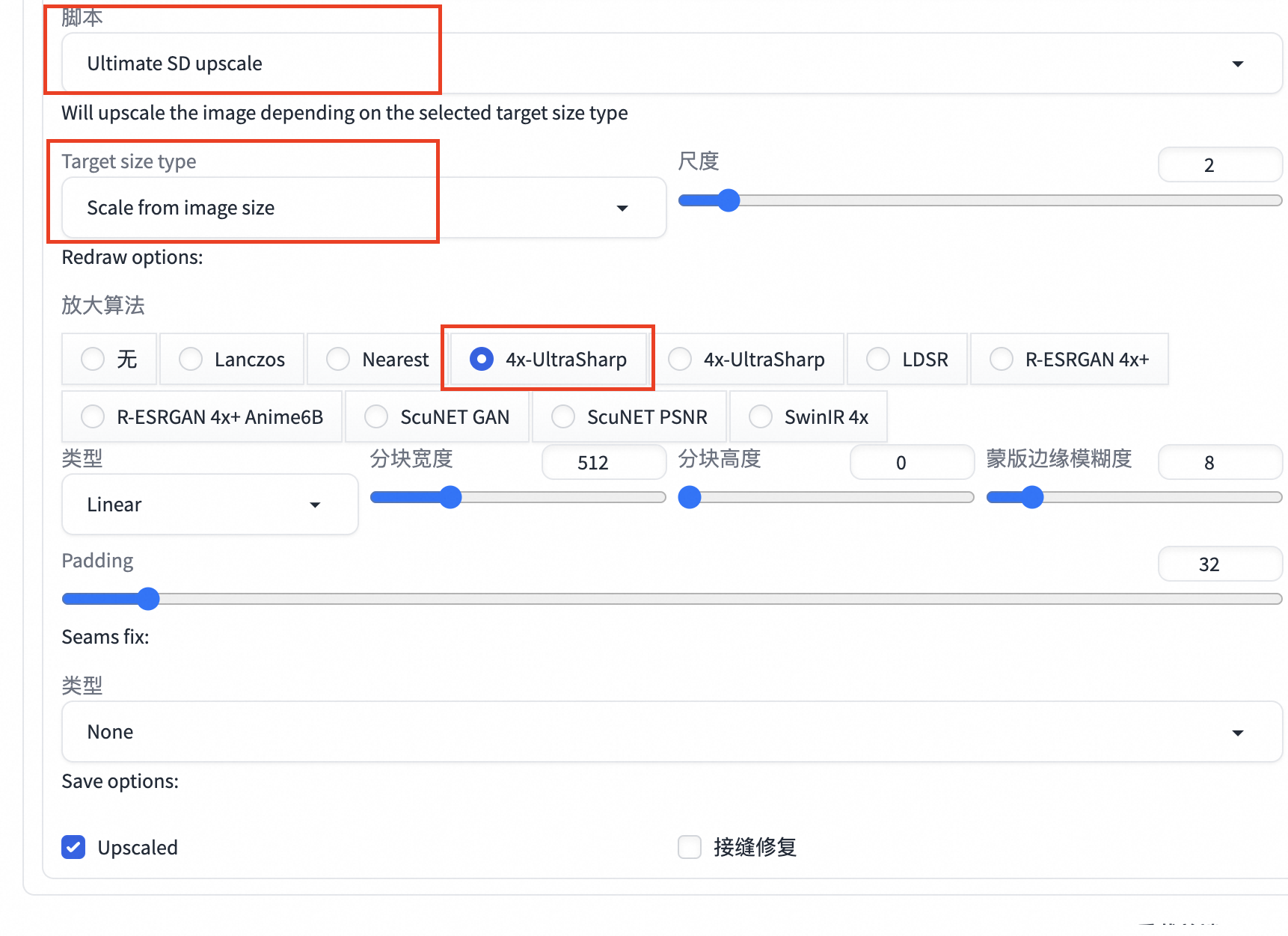
6.3>点击生成,查看生成效果

本章节概览
通过本章节的知识学习,可以了解到
●
平台工具能力
○
提供ComfyUI、Stable Diffusion WebUI、Kohya核心工具,支持文生图、图生图及节点式工作流搭建;
●
平台专区模块以及如何使用对应专区功能
○
数据集
○
模型
○
工作流
○
应用
●
高校学生基于PAI ArtLab平台实现的项目案例
○
浙江大学-艺术与考古学院《中国历代绘画大系-图像数据的生成式人工智能研究》
○
北京服装学院-《面向服装AIGC的设计语言研究》
○
...
●
企业基于PAI ArtLab平台实现的项目案例
○
阿里云企业活动-510节日
○
阿里云人像写真活动打卡-奥运海报生成
○
...
●
PAI ArtLab平台的行业应用能力
○
覆盖教育、建筑、企业、游戏等多领域
学习目标达成
学员将掌握以下AIGC行业知识及对平台工具的基础操作能力
●
掌握主流AIGC工具操作
○
运用ComfyUI搭建节点式工作流
○
运用Stable Diffusion WebUI完成文生图、图生图及动图生成
○
通过Kohya实现数据集标注与模型微调训练
●
熟悉平台核心功能模块
○
理解数据集、模型、工作流、应用四大专区的功能,包括数据集批量打标、模型传输与管理等操作。
●
了解实践跨行业项目案例及企业案例
○
如:浙江大学《中国历代绘画大系-图像数据的生成式AI研究》
○
如:阿里云510节日活动
●
拓展行业场景应用认知
○
了解AIGC在教育、游戏、电商等领域的应用,如服装设计研究(北京服装学院案例[)、三维产品图标生成(阿里云设计中心案例)等
PAI ArtLab 一站式AIGC设计平台
●
背景:
○
图像生成大模型可以快速地生成高质量的视觉内容,大大缩短设计周期。PAI 作为阿里云专为企业和开发者打造的一站式机器学习平台,推出PAI ArtLab 一站式AIGC设计平台
■
无需部署、开箱即用
■
灵活易用、支持定制
●
产品功能:
○
支持云端ComfyUI、Stable Diffusion、Kohya等主流文生图与模型训练工具
○
提供应用、数据集、模型、工作流专区,构建AI绘图等AIGC全场景能力
○
支持AI绘画教学,多账号统一管理和授权等企业级能力
●
适用用户:
○
寻求使用 AI 加速生产力,但无编程基础的设计师
○
寻求使用 AI 加速生产力,但无 GPU 资源的设计师
○
寻求快速生成优质图片的业务人员



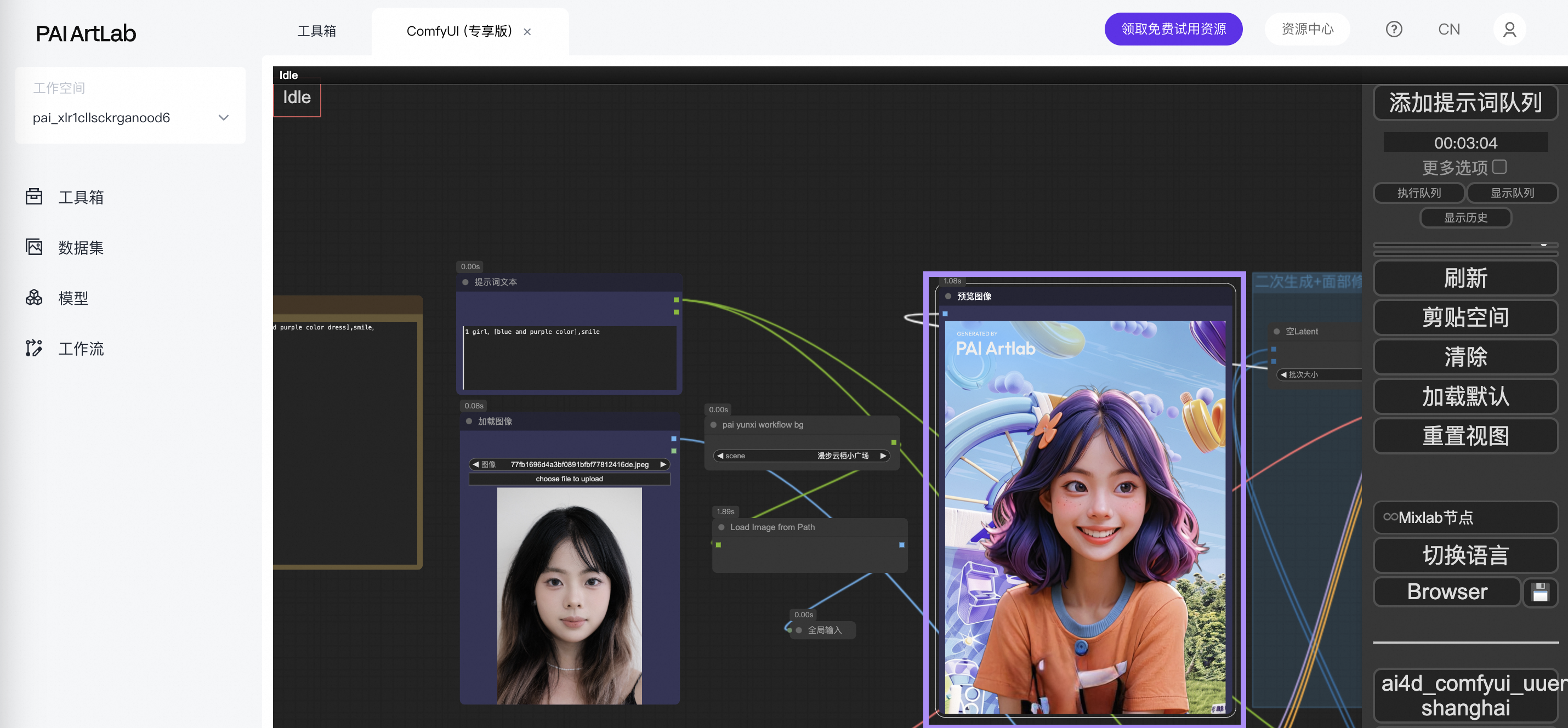
Stable Diffusion WebUI
支持文生图、图生图和动图生成等

Stable Diffusion WebUI 部分案例
中国美术学院-工业设计学院
 |
 |
浙江理工大学
 |
 |
 |
 |
阿里云安全-企业营销设计
 |
 |
 |
 |
Kohya
支持数据集图像标注、智能批量生成与微调模型训练等
Kohya工具部分案例
小天才
 |
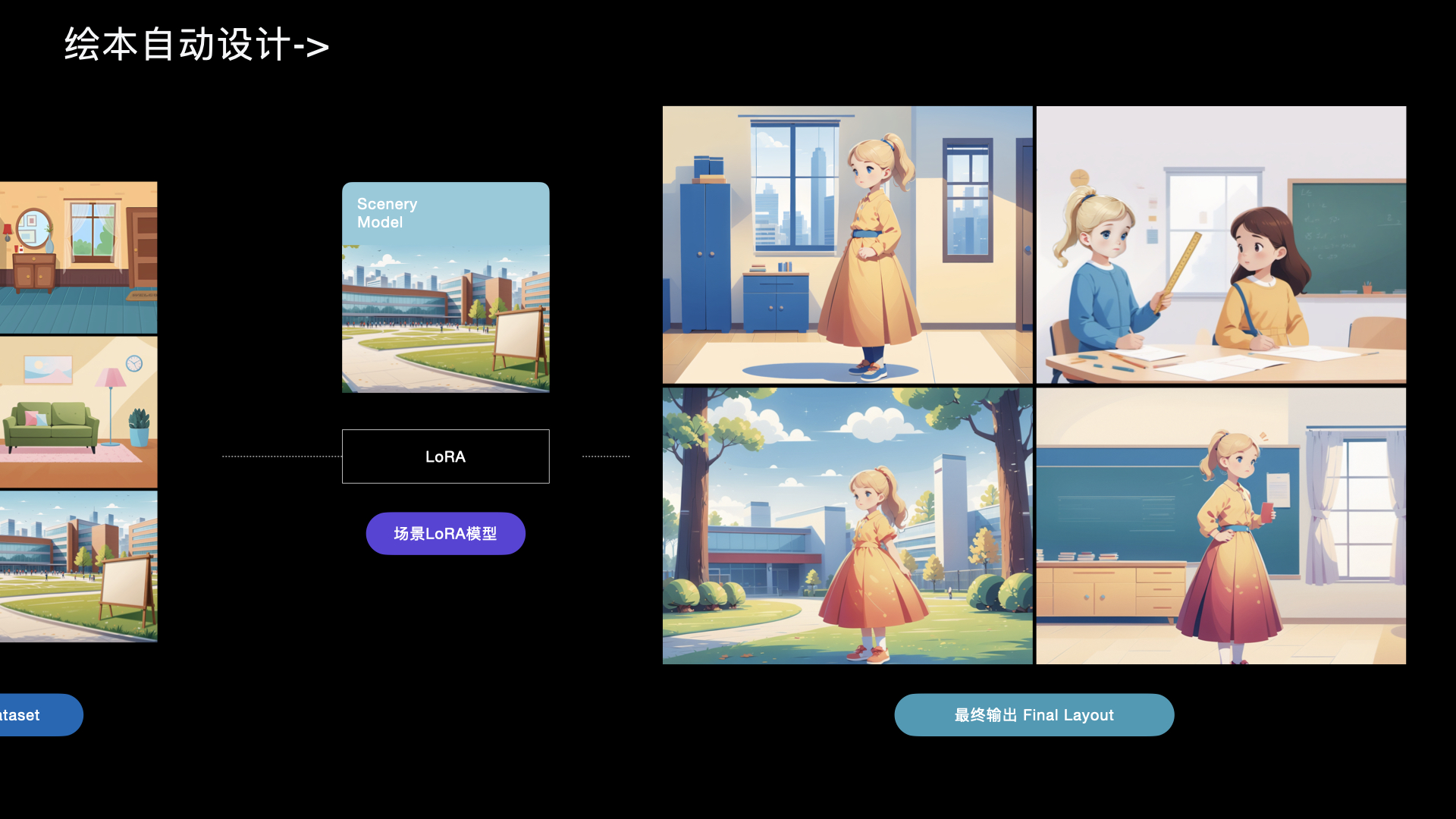 |
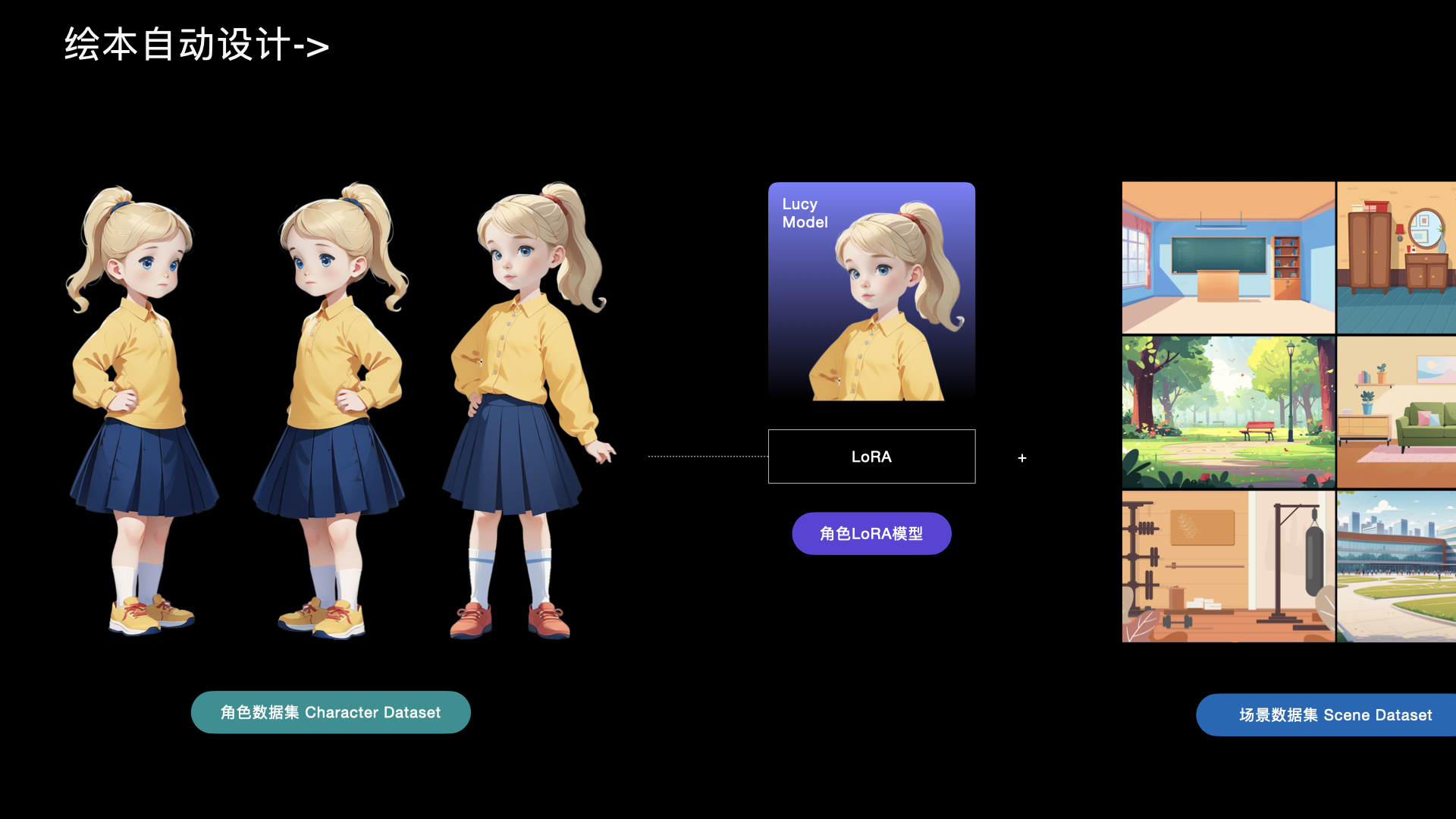
阿里云设计中心三维产品图标训练与生成
 |
 |
 |
 |
ComfyUI
支持搭建节点式工作流,支持文生图、图生图和动图生成等
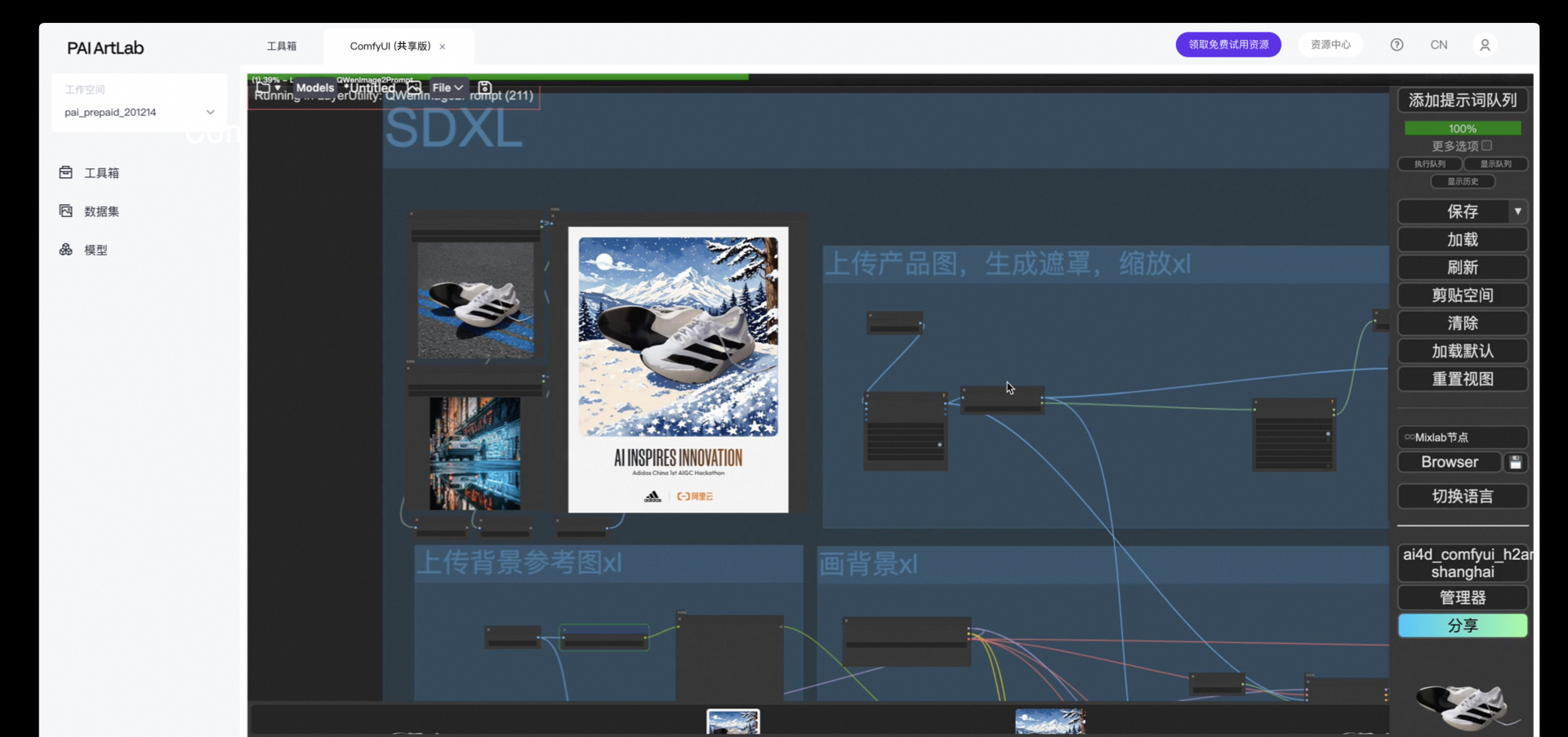
ComfyUI工具部分使用案例
品牌-市场传播--阿里云510节日
 |
 |
品牌-市场传播--阿里云企业符号
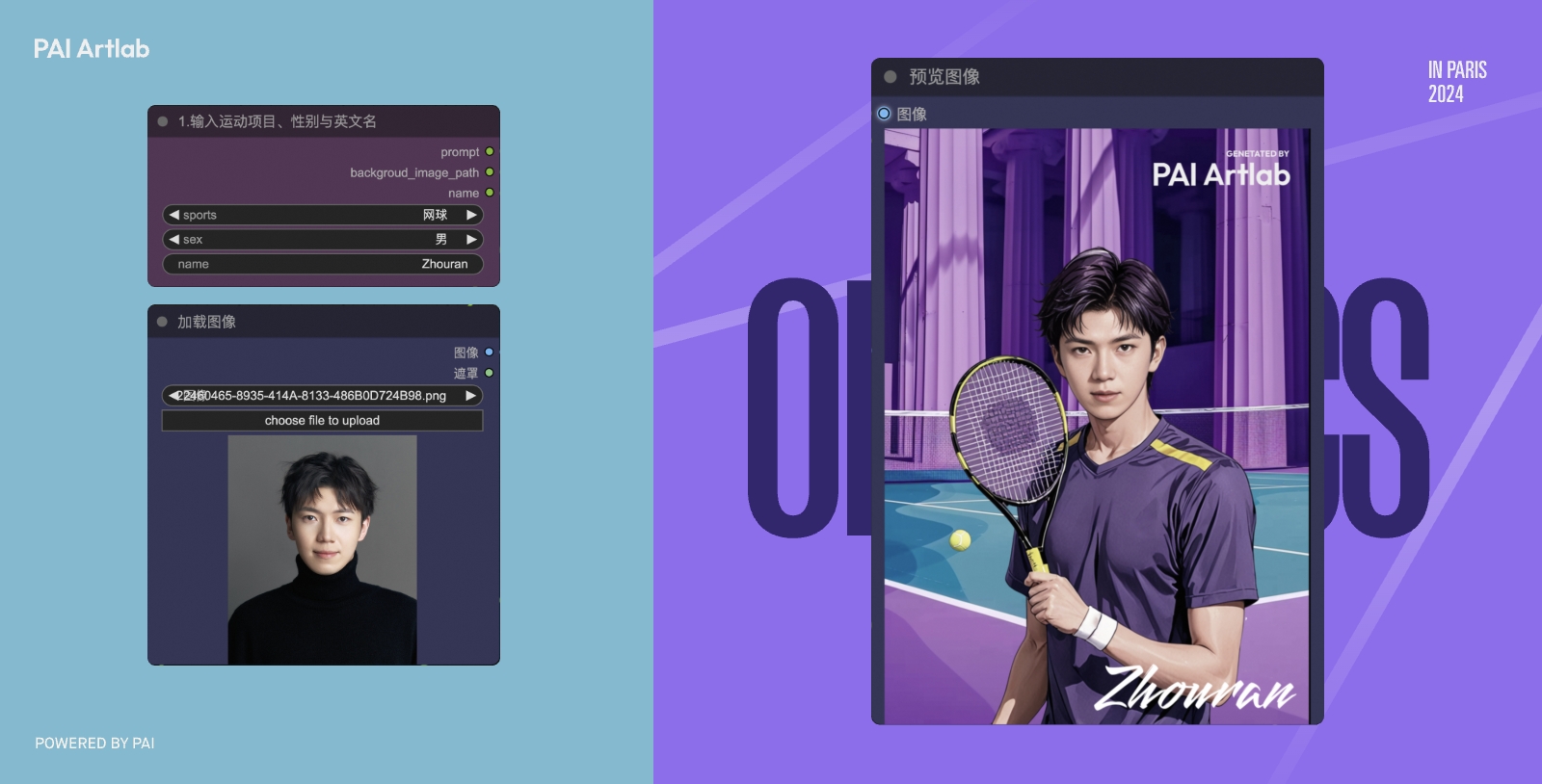
一键生成企业专属风格海报
基于上传Logo线稿图,一键生成可定制风格、可自定义Logo与标语的企业风格海报
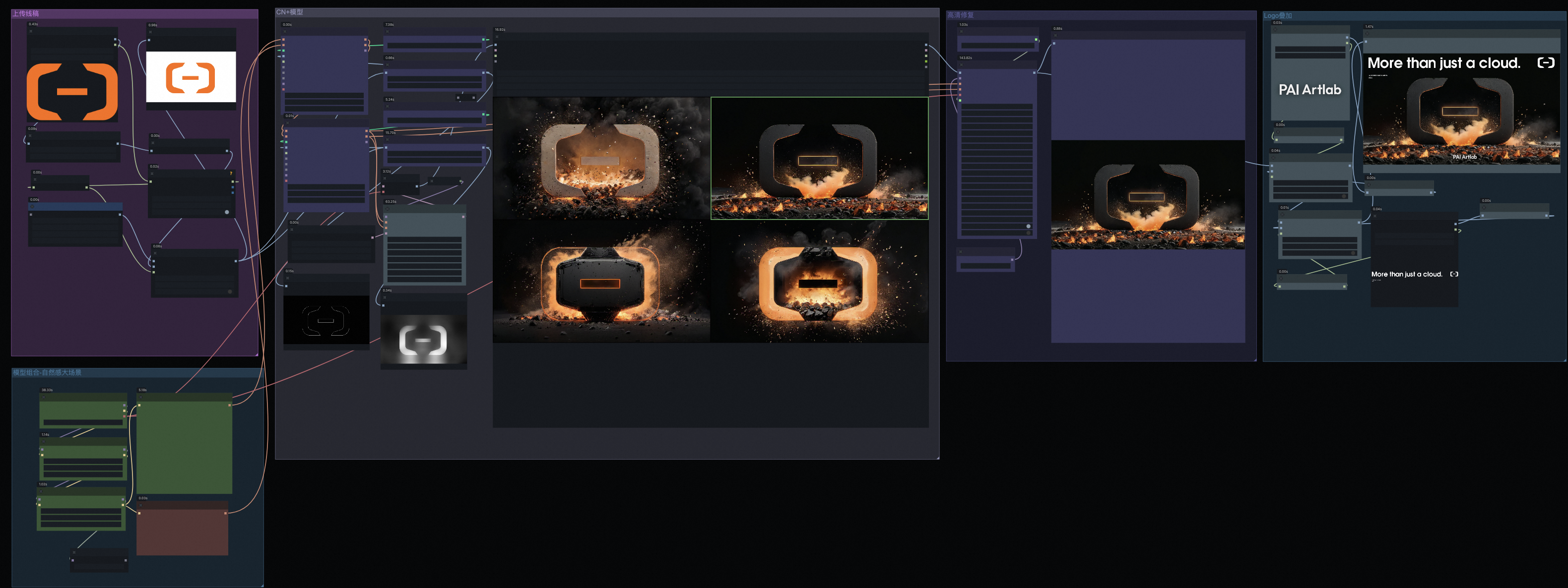
|
上传线稿
 |
生成结果
 |
游戏-产品设计
 |
 |
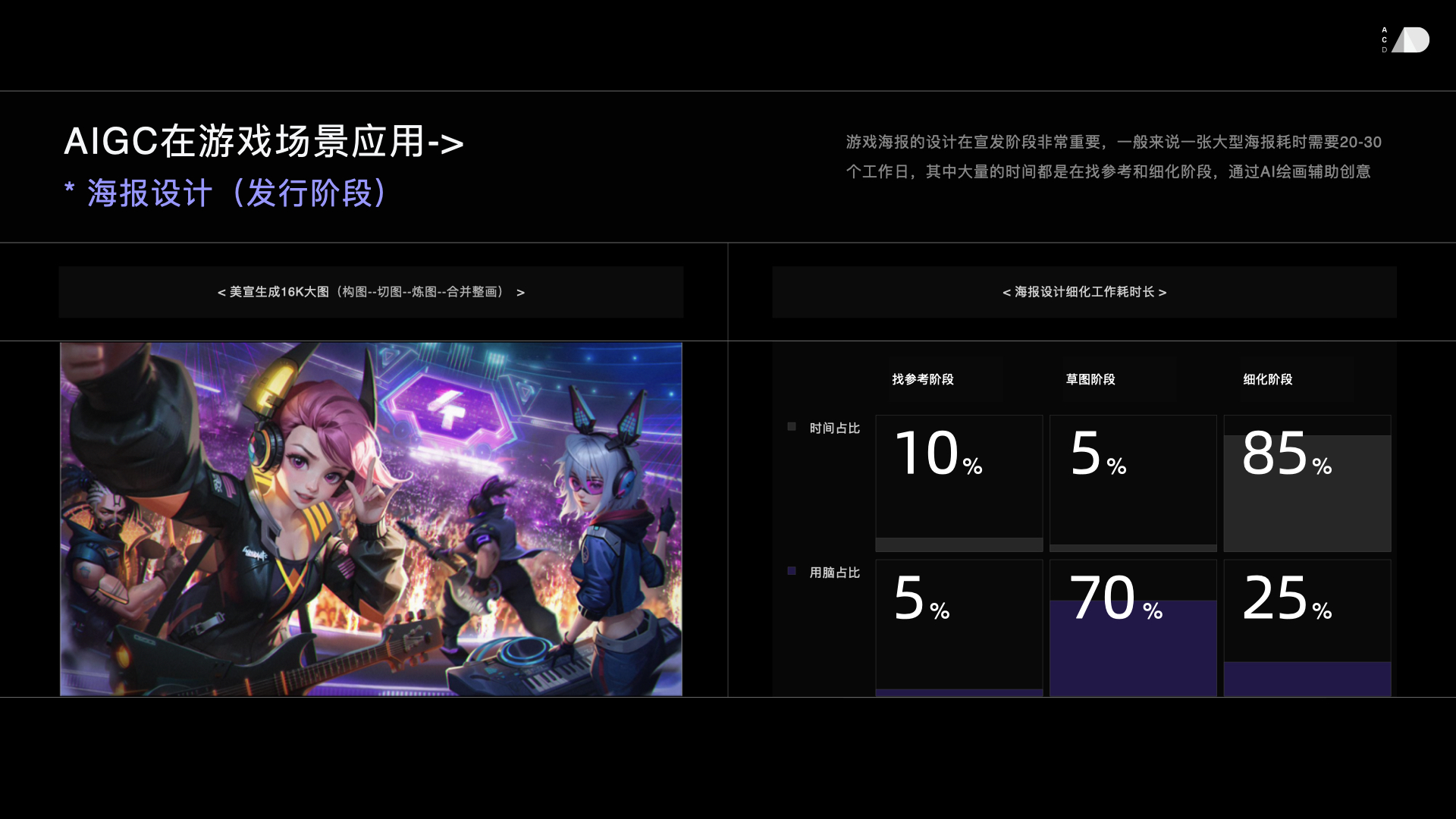 |
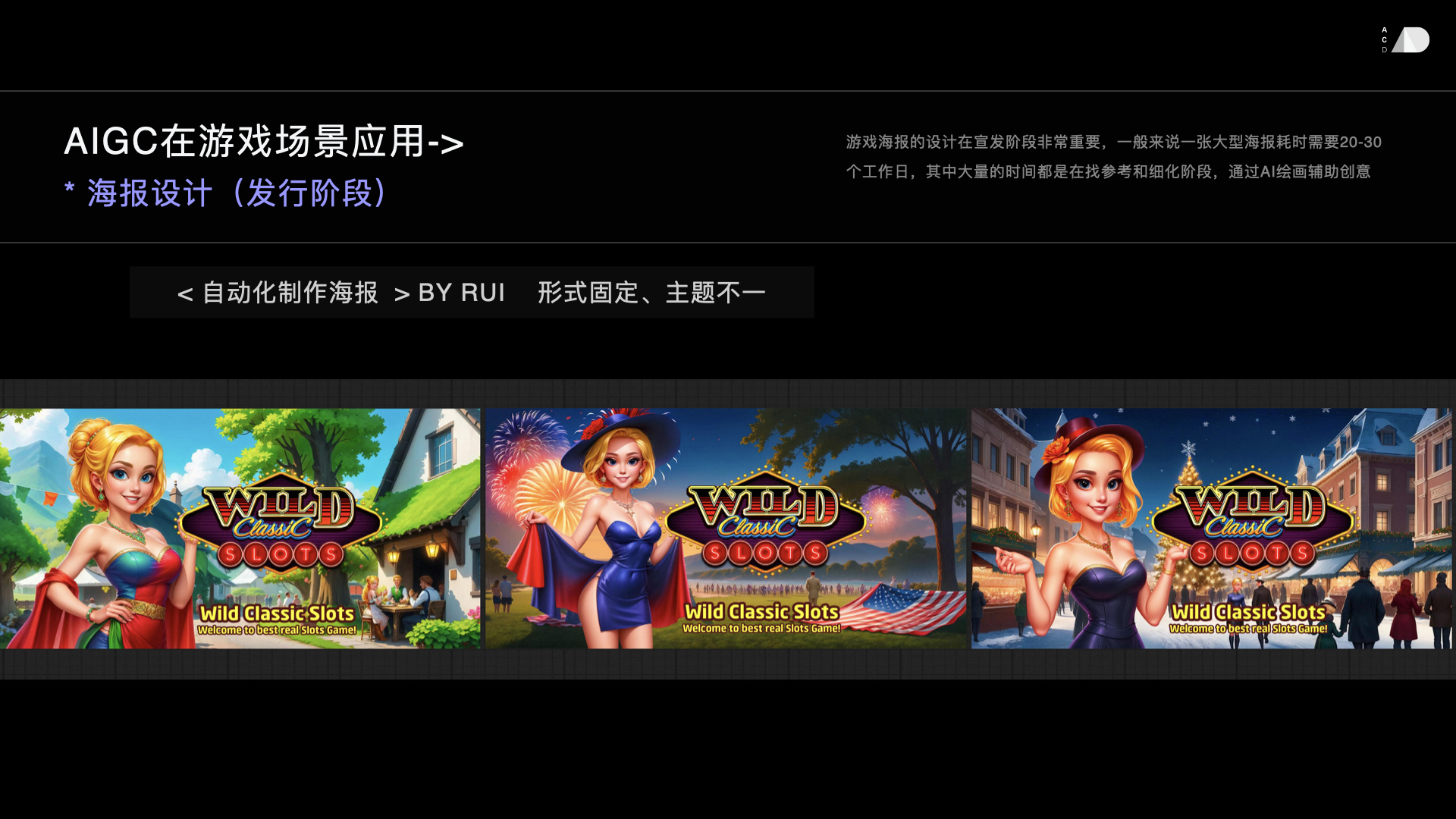 |
品牌-互动营销











电商-商品展示
|
输入图
测试原图均为AI生成,仅做效果参考
 |
输出图
 |
输出图
 |
|
输入图
测试原图均为AI生成,仅做效果参考
 |
输出图
 |
输出图
 |
|
输入图
测试原图均为AI生成,仅做效果参考
 |
输出图
 |
输出图
 |
ComfyUI教程
数据集
模型训练所需要的数据集图像的预处理


数据集创建与上传
数据集批量智能打标
模型训练
LoRA风格模型训练及生图基础操作

模型

模型广场使用教程
专享版工具使用模型方法
点击模型卡片上的按钮,添加到“我的模型”
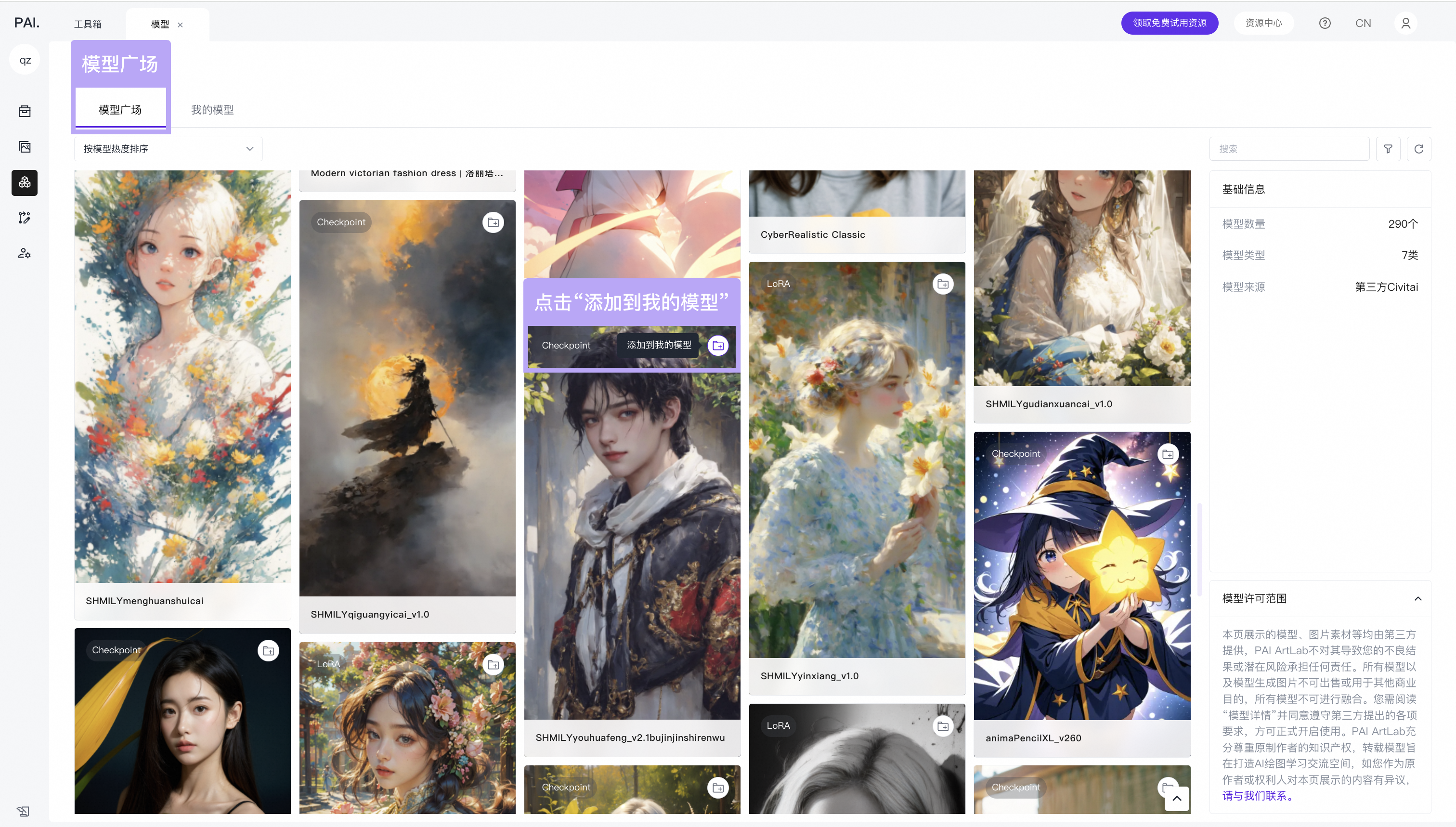
等待模型传输成功至100%
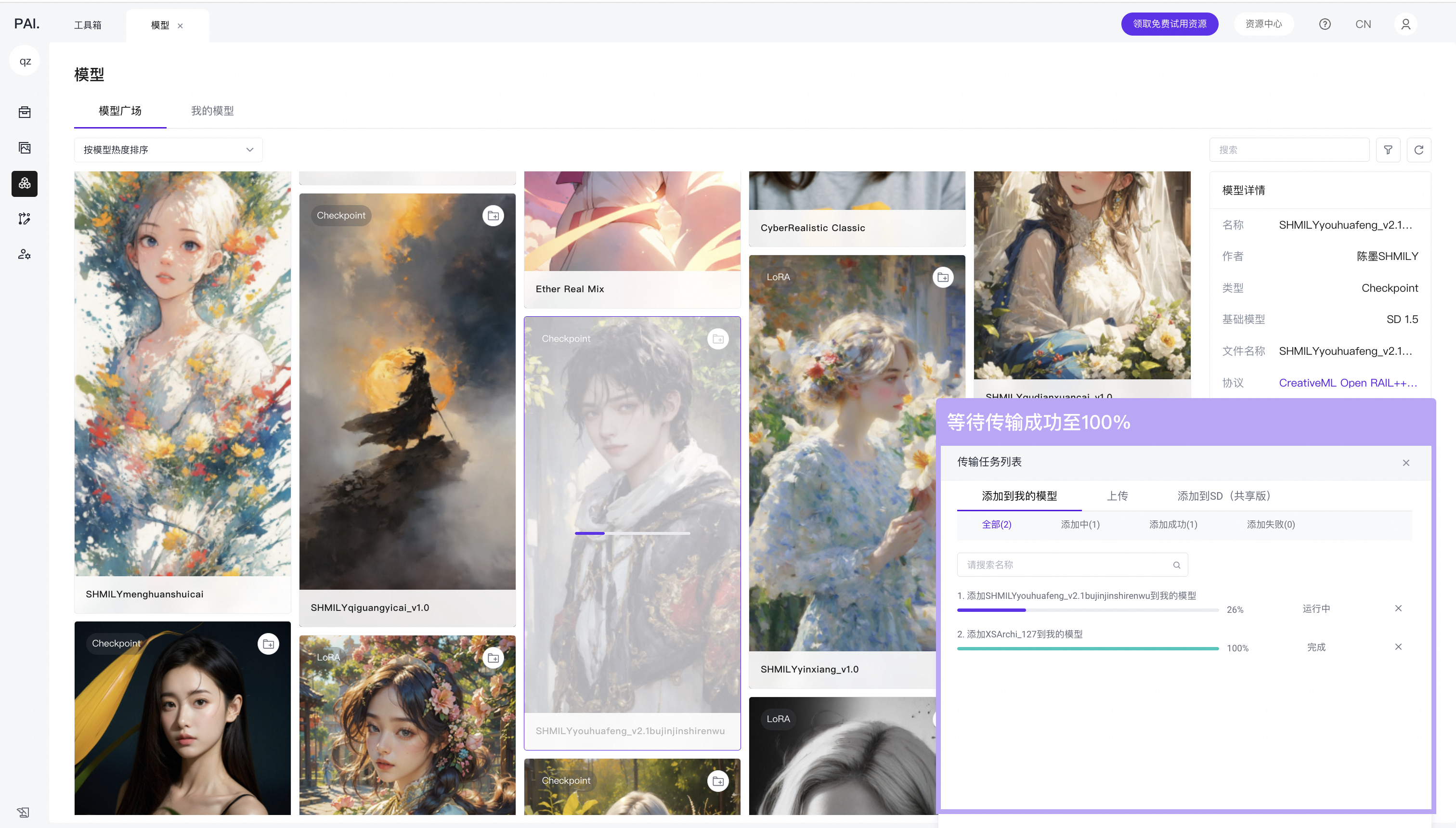
然后刷新共享版工具对应的模型区域即可找到模型
工作流
工作流教程
应用



 浙公网安备 33010602011771号
浙公网安备 33010602011771号