


通过插件增强大模型的能力
你已经熟练使用大模型的 API 来自动处理各种批量任务。不过,你可能也发现,并不是所有任务大模型都能完美解决。例如,当你给大模型一批小学难度的计算题,比如393乘以285,它竟然给出了错误答案。就像不擅长数学的人可以使用计算器来解决复杂的算术问题一样,大模型也可以借助插件这种工具来解决它原本难以解决的问题。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解大模型插件的使用
- 学习大模型插件原理及开发自定义插件
1 什么是插件
大模型插件是一种软件组件,它们设计用于增强和扩展基础大模型的功能。如网络搜索、视觉生成、语音合成等。
典型的插件包括:
- 基础工具,如计算器、时钟、天气信息、股票行情
- 可以让用户获得实时性消息的插件,比如体育赛事报道、实时、热点新闻
- 可以为模型拓展更多能力的插件,比如图片生成、语音合成、代码解释器
企业内部技术团队也可以定制开发大模型应用服务插件,比如通过飞猪开放平台的API查询酒店信息、预订酒店住宿及机票等,为公司员工提供便捷的差旅服务支持。
2 插件演示
大语言模型在数学计算方面并不擅长,在回答稍微复杂的数学问题时往往无法输出准确的结果。
尝试提问393x285,输出结果是错的。

注:正确答案是112005。
即使让大模型通过编程来实现,输出结果也是错的,因为它并没有真正地运行代码。

这个时候,我们可以给大语言模型添加插件,比如计算器。
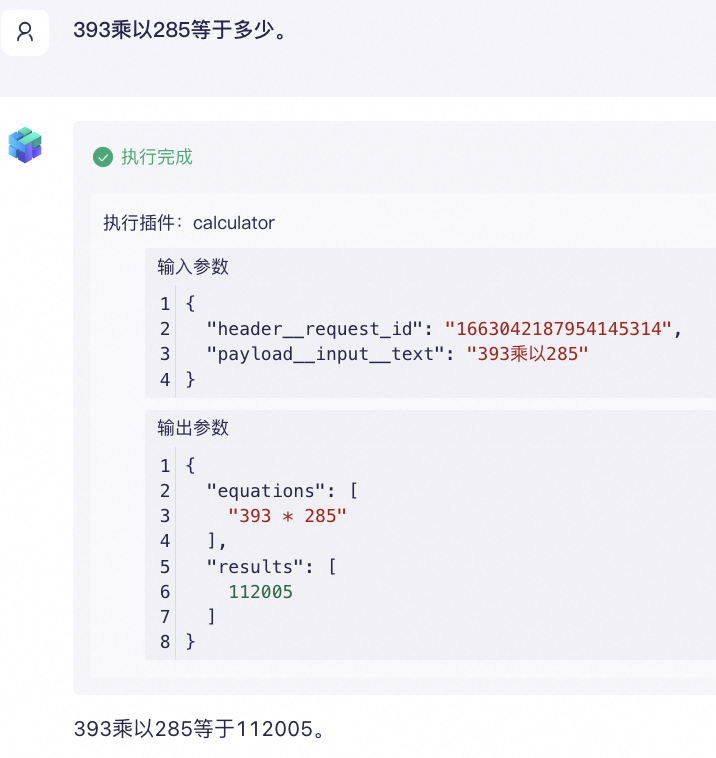
可以看到,输出结果是准确的,这是因为大模型借助计算器插件进行了实际运算。
换一个插件,这次给大模型添加一个代码解释器插件,看看计算的结果。
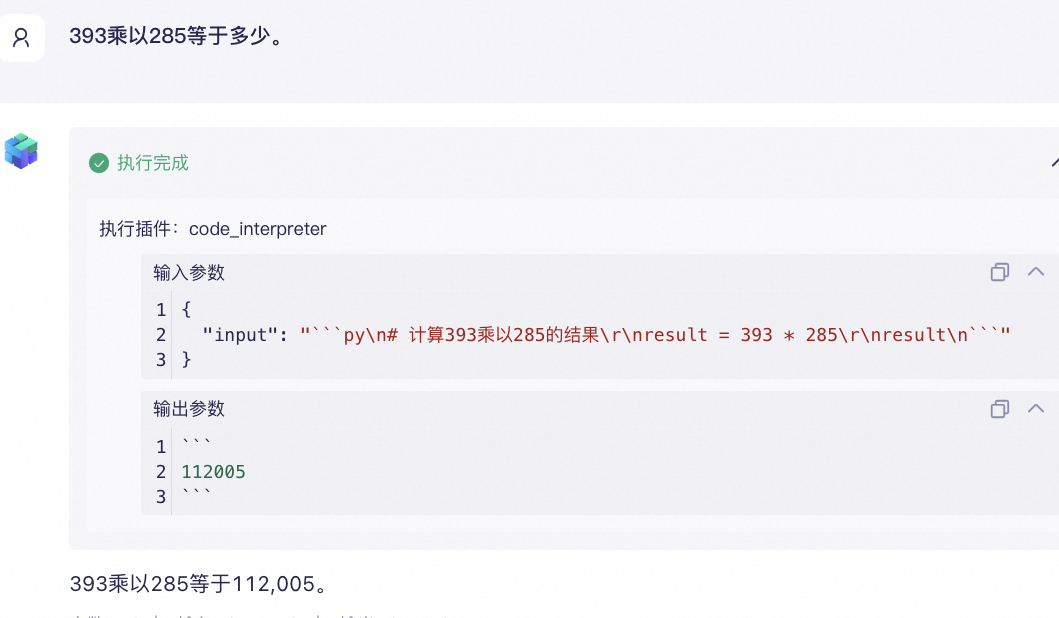
可以看到,结果也是准确的,这是因为大模型通过代码解释器真正地运行了python代码。
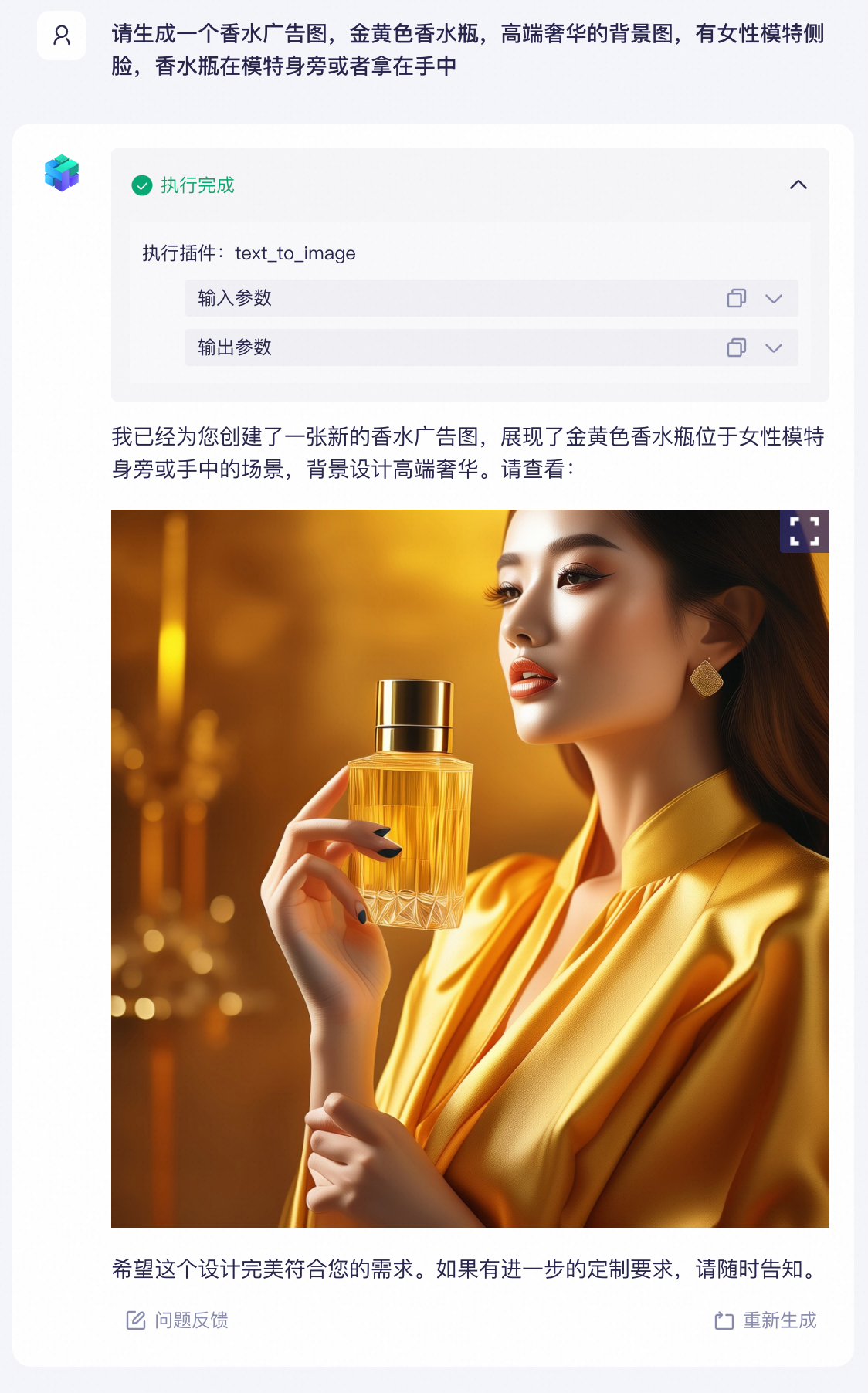
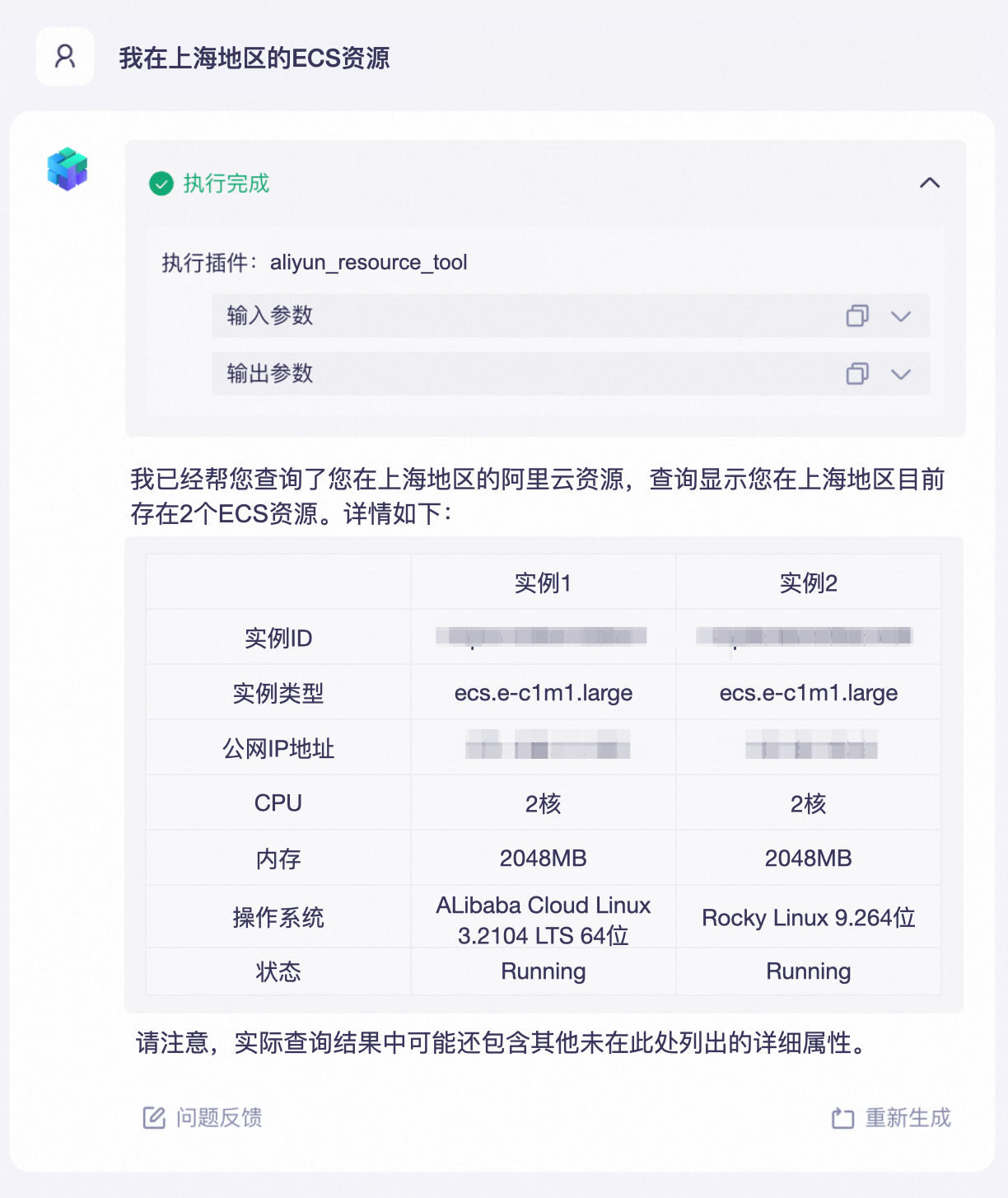
上述示例是在百炼平台的可视化界面上操作完成的。除了官方插件,你还可以开发自定义的插件实现更多的功能,例如查询实时天气、查询阿里云账号下已购买的云服务器等。
|
通过图片生成插件生成广告图片
|
通过自定义插件实现云资源查询
(概念示意图)
|
3 工作原理
大模型应用使用插件的决策流程和人类使用工具的流程是一样的。首先接收输入,判断是否需要使用工具及选择合适的工具,然后使用工具并获得返回结果进行后续推理生成。
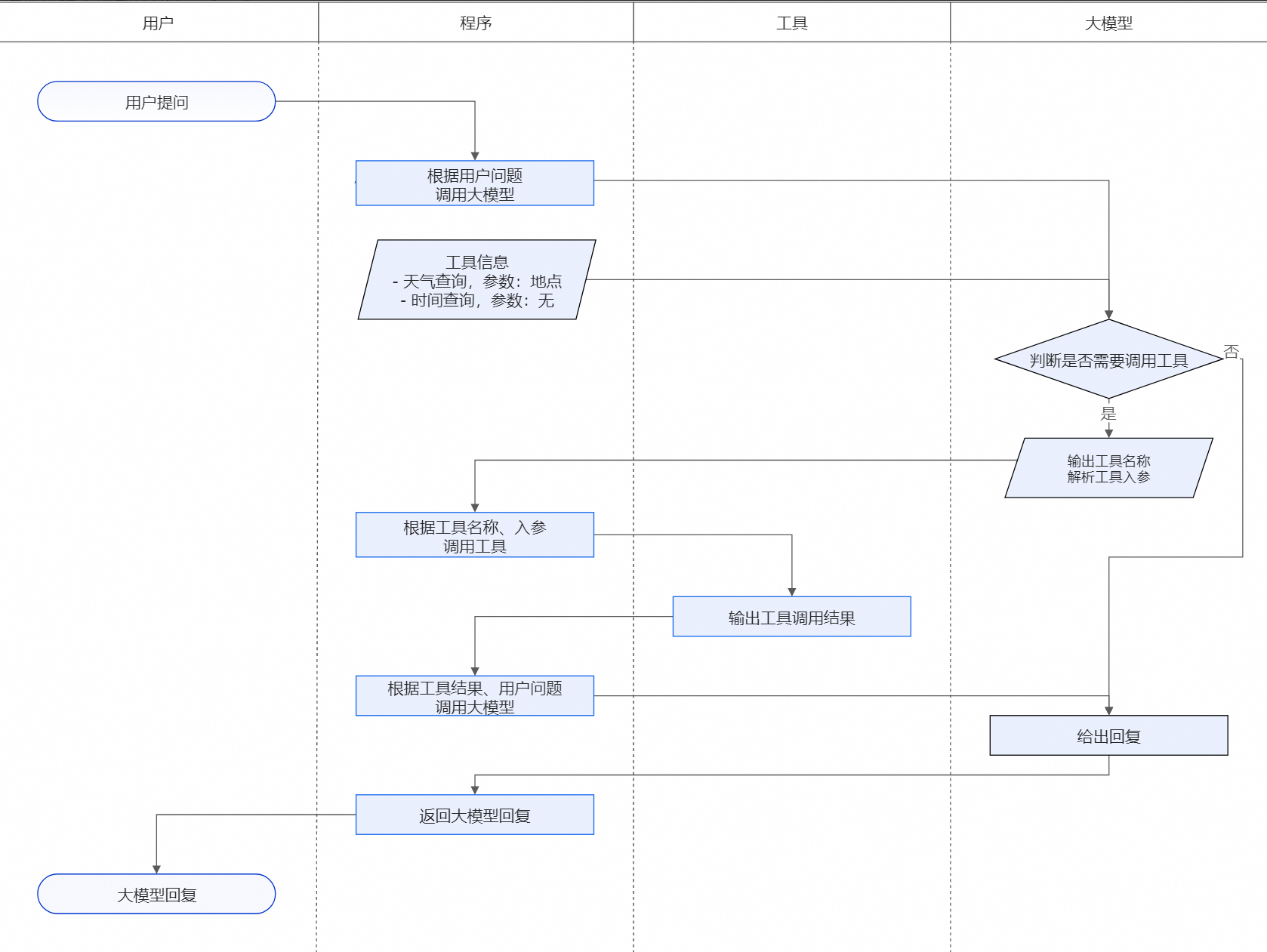
大模型执行插件原理图
4 阿里云上的大模型 API 插件支持
- 如果你正准备基于百炼上提供的通义千问 API 服务构建大模型应用,可以查看百炼插件概述来了解百炼平台预置的插件能力(包括图片生成、夸克搜索、Python代码解释器、计算器等),以及了解如何增加自定义的插件。
- 阿里云的模型服务灵积产品中提供了兼容 OpenAI API 的通义千问 API,该 API 也支持 OpenAI 的 function call 能力。如果你的业务是面向中文用户居多,或者需要满足国内大模型应用备案的要求,可以借助该兼容 API,在不修改业务代码的情况下将你的大模型应用背后的 OpenAI API 替换为通义千问 API。
[进度: 已完成]本节小结
本课程带你了解大模型通过插件与三方应用交互,实现能力增强和拓展。你可以将大模型和业务系统现有的功能进行有机结合,如建立待办事项、抢占会议室,甚至查询当前云账号下保有的阿里云资源等。有插件增强的大模型应用就好像你的私人助理,你只需要发送指令,它可以帮助你完成所有的工作。
你报名参与了导游志愿者活动,但对景点并不熟悉的你很难给出令游客满意的景点介绍。你意识到可以通过查询资料来帮助你完成导游工作,这时的你不再扮演知识的输出者,而是知识的总结者。同样地,给大模型配备知识库,也可以让它参考查询到的信息回答原本无法回答的问题。这种结合了信息检索与文本生成的方法就是我们本节课程要介绍的检索增强生成(RAG,Retrieval Augmented Generation)方法。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解什么是RAG,以及它的实现原理
- 动手给大模型增加知识库来实现RAG
- 了解如何持续改进RAG应用效果
1 什么是RAG
我们按照前面导游的例子,来引出RAG做了哪些事情。你把当导游时无法给游客提供专业、全面信息的困惑告诉了你的主管,于是主管给了你一本志愿者手册。游客询问最近的全聚德烤鸭店在哪里,你拿出了志愿者手册,翻到了全聚德烤鸭店的位置,然后告诉了游客具体的走法。

图1:用系统资料导游
你又遇到了一个游客,游客眼睛不太好,他想知道如何前往银锭桥,此时你也犯难了,志愿者手册并没有该细节内容,但是此时游客手里有一张导览图,你接过地图,经过简单的分析,按照地图指出应该如何前往银锭桥。

图2:用系统资料和用户资料结合来导游
假设我们是开发大模型导游助理的技术团队,我们把导游助理比作志愿者。
在第一种情况下,“志愿者手册”就是我们在开发系统的时候就配置好的知识库,因此导游助理可以从系统默认的知识库中获取烤鸭店的地址,然后生成导航路径给游客。
在第二种情况中,假设我们的系统支持用户上传个性化资料,来更好地满足个性化业务需要。换句话说,系统支持用户添加垂直领域知识,构建私域知识库。那么,当游客向志愿者提供一份个性化导航资料时,系统可以结合游客的垂直领域知识与系统预置的知识共同为游客提供服务。
第一种方案的知识库,可以理解是公司统一配置的知识库;第二种方案中,每个团队或者用户还可以根据自己的需要来增加私域定制化知识库。显然,第二种系统更灵活,不需要复杂的操作就能补充了业务知识。但总体来看,这两个系统都是通过知识库来增强导游助理的能力,减少“幻觉”回答的情况(即导游助理不是编造一个像模像样的地址,而是按照已有知识来回答)。这就是我们即将介绍的检索增强生成(Retrieval Augmented Generation)。
检索增强生成包括三个步骤,建立索引、检索、生成。如果说大模型导游助理是一位志愿者,那么我们给志愿者们准备“志愿者手册”的过程就是建立知识库索引,志愿者查看资料就是系统在检索知识库,志愿者基于检索到的资料充分思考并回答用户的问题就是生成答案。
2 RAG的实现原理
那么RAG是怎样将信息检索与文本生成结合起来的呢?请看下图:
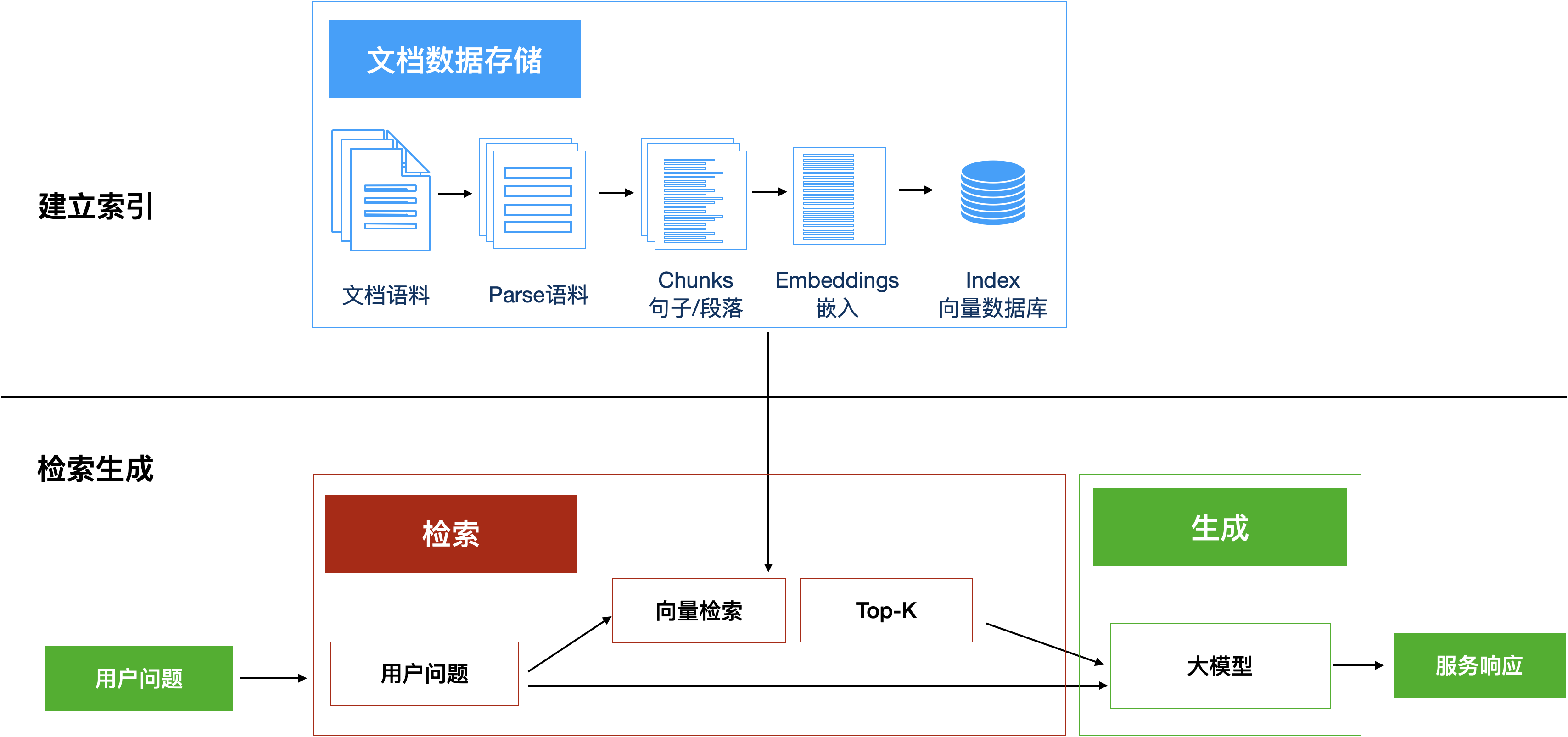
图3:大模型RAG基本工作流
如图所示,RAG主要由两个部分构成:
建立索引:首先要清洗和提取原始数据,将 PDF、Docx等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk);最后将这些片段经过嵌入模型转换成向量数据(此过程叫做embedding),并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。这就是建立索引的过程。
检索生成:系统会获取到用户输入,随后计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块(K值可以自己设置)作为回答当前问题的知识。知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。这就是检索生成的过程。
提示词模板类似于:请阅读:{知识文档块},请问:{用户的问题}
明白了RAG的实现原理,那接下来我们就通过一个动手实验,学习如何在现有大模型的基础上实现检索增强RAG。
3 RAG应用案例:阿里云AI助理
你在使用阿里云产品的时候可能会遇到问题,于是你去咨询了通义千问,可是通义千问对于阿里云产品的细节问题可能并不了解。为了帮助用户更方便地解决上云用云过程中遇到的问题,阿里云推出了阿里云AI助理,它背后的基本框架就是基于通义千问大模型的RAG应用,使用的知识库是阿里云各产品的使用文档。它可以解答用户上云用云的问题,包括提供阿里云产品介绍、生成云产品组合方案、制定业务迁移方案、查询和领用云上权益、提供购买指引。比如向阿里云AI助理提问:
怎样使用Python SDK往OSS上传文件
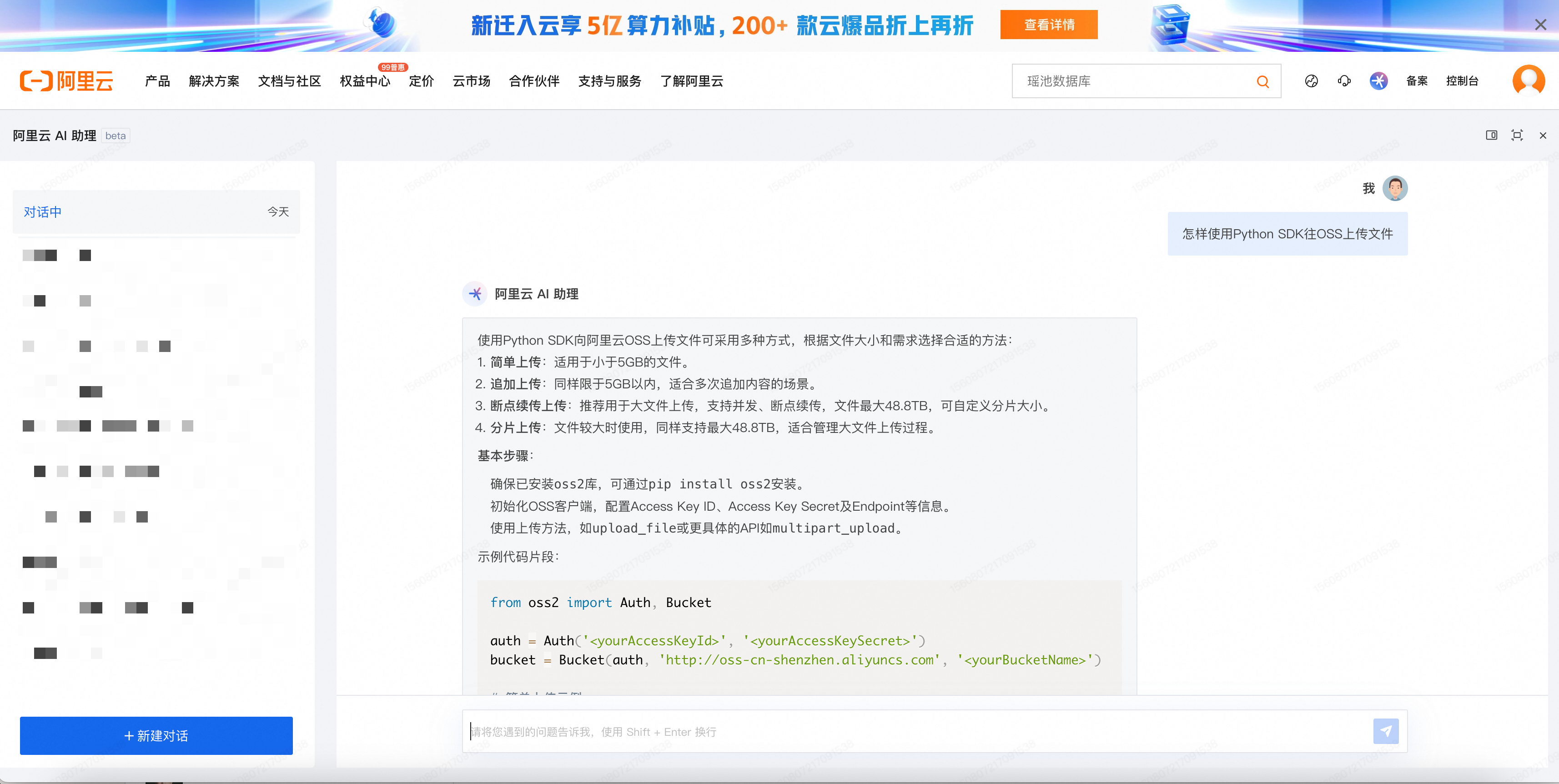
阿里云AI助理会提供答案,并在回答的最后附上它参考的文档链接供用户进行进一步的校验。
4 动手实验
现在,让我们通过一个动手实验,进一步探究如何搭建一个私域知识问答机器人。实验将指导你如何创建知识库,然后创建基于知识库的RAG应用,并进行问答测试。
5 扩展阅读:如何持续改进RAG应用效果
随着深入使用,你可能发现你的 RAG 应用可能只是能用了,但还有很多问题,比如:
- 问题比较抽象或者概念比较模糊,导致大模型没有准确理解使用者的问题。例如,使用者问“兰州拉面去哪吃?”,使用者本来想问附近有没有卖兰州拉面的店铺;假如知识库搜索“兰州”和“拉面”之后,结果排序靠前的语料是位于“兰州”的拉面馆地址,而大模型告诉用户要去买飞机票或者火车票,就是答非所问了。通常我们用改造问题,让使用者的问题更好理解的策略来回避这种情况。
- 知识库没有检索到问题的答案,这有可能是由于语料数据没有做好整理就存入知识库,或者是检索策略有问题,参数需要调整导致的。比如,在采用“K个最相似文档块”作为回答的知识这个策略中,如果K值比较小,那么最相似的K个文档块中可能并不包含能解答用户问题的有效知识,那么答案很可能就是错误的。例如,作为旅游手册的知识库中有大量文段是 兰州拉面如何制作的菜谱、兰州拉面的产地、兰州有哪些特产等,只有一两条信息描述了附近拉面馆的地址。那么当用户询问“兰州拉面怎么走?”时,知识库检索到的信息可能只是兰州拉面的选材、调味、烹饪方面的信息,而唯独没有检索到前方50米处有一家兰州拉面馆。用户也没有办法获得有效的答案。
- 缺少对答案做兜底验证的机制,假设运气很好,志愿者不仅听懂了游客的问题,也正确查找到了附近最近的两家拉面馆的信息,但是志愿者的回答方式是“向北走200米就到了”。这有可能是一个正确的答案,但不是一个好的答案,实际考察过景区地形后我们可能会发现,志愿者北面是后海,你不太可能穿过湖面去一个地方。实际路径可能是:先向东走50米,再向北走绕过后海,走到湖对面去,才能走到正确位置。那这个“向北走200米...”的回答,从导航的角度就不能算是准确了。
我们会发现许多改进标准 RAG 框架的方法,下面我们将一起了解这些改进思路。
如果你目前理解下面的内容还有一些困难,没有关系,你只需要大致了解有哪些常见改进思路。至于具体的改进实现,你可以找到和你合作的工程技术人员或算法技术人员共同探讨改进方案。
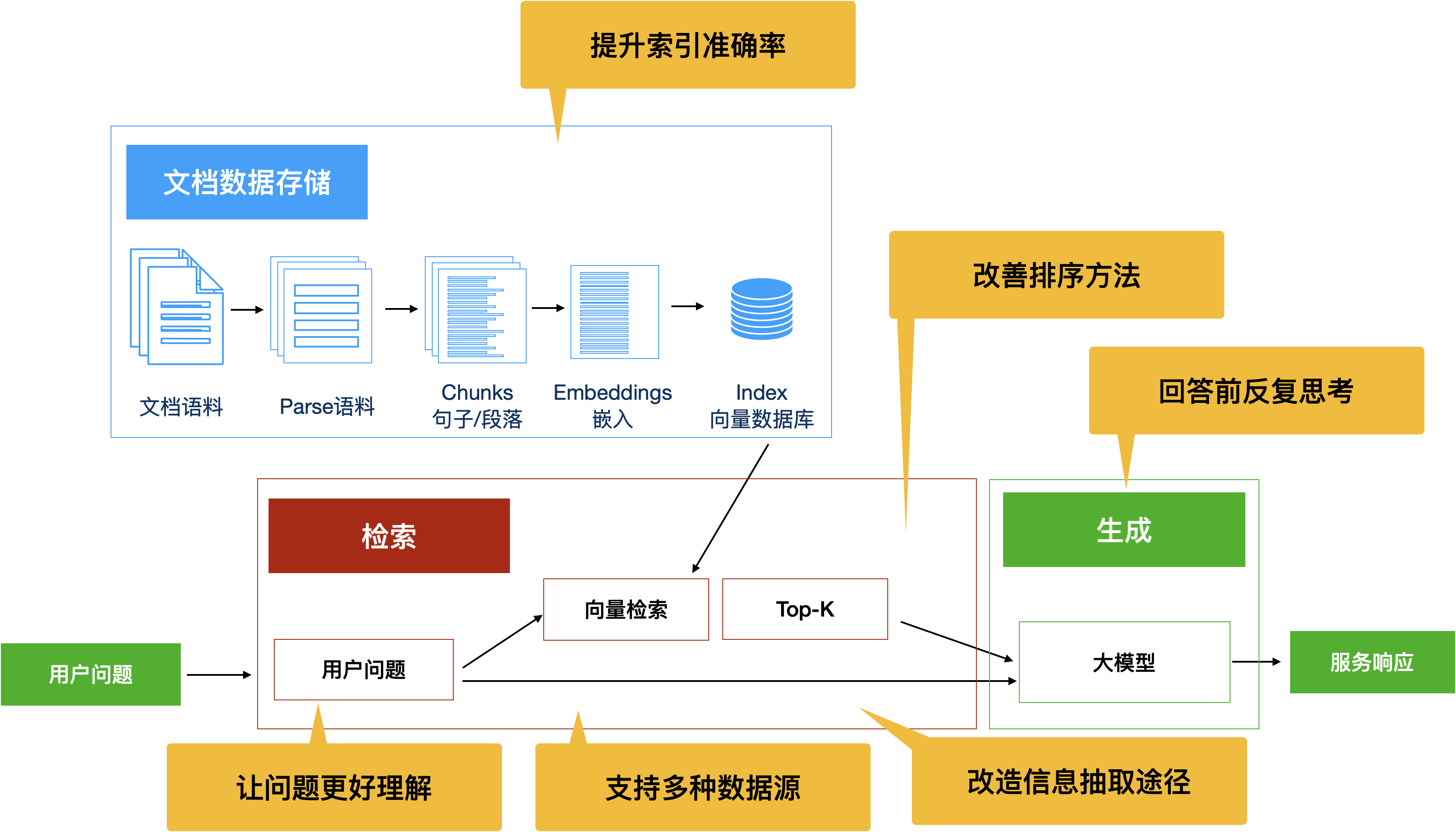
图5:增强RAG能力的多种思路
5.1 建立评测标准
为了持续改进我们的 RAG 应用,首要任务应当是构建一套严谨的评测指标体系,并邀请业务领域专家作为评测方共同参与评测工作,我们可以设置与我们业务相关的多种问题场景,系统性地检查一个RAG系统反应快不快,回答准不准,有没有理解用户问题的意图等方面。通过科学全面的评测,我们可以了解到系统在哪些地方做得好,哪些地方需要改进,从而帮助开发者让RAG系统更好的服务于业务需求。
RAG系统一般包括检索和生成两个模块,我们做评测时就可以从这两个模块分别入手建立评价标准和实施方法,当然你也可以用最终效果为标准,建立端到端的评测。在评测指标设计上,我们主要考察检索模块的准确性,如准确率、召回率、F1值等等;在生成模块,我们主要考察生成答案的价值,如相关性、真实性等等。
我们可以引入业界认可的一些通用评估策略,比如,你可以参考Ragas提及的评测矩阵指南,你也可以建立一些自己的评测指标,这些评测方法将会有助于你量化和改进每一个子模块的表现。
5.2 改造一:提升索引准确率
- 优化文本解析过程
在构建知识库的时候,我们首先需要正确的从文档中提取有效语料。因此,优化文本解析的过程往往对提升RAG的性能有很大帮助。例如,从网页中提取有效信息时,我们需要判断哪些部分应该被去掉(比如页眉页脚标签),哪些部分应该被保留(比如属于网页内容的表格标签)。
- 优化chunk切分模式
Chunk就是数据或信息的一个小片段或者区块。当你在处理大量的文本、数据或知识时,如果你一次性全部交给大模型来阅读和处理,效率是非常低的。所以,我们把它们切分成更小、更易管理的部分,这些部分就是chunk。每个chunk都包含了一些有用的信息,这样当系统根据用户的问题寻找某个知识时,它可以迅速定位到与答案相关信息的chunk,而不是在整个数据库中盲目搜索。因此,通过精心设计的chunk切分策略,系统能够更高效地检索信息,就像图书馆里按照类别和标签整理书籍一样,使得查找特定内容变得容易。优化chunk切分模式,就能加速信息检索、提升回答质量和生成效率。具体方法有很多:
- 利用领域知识:针对特定领域的文档,利用领域专有知识进行更精准的切分。例如,在法律文档中识别段落编号、条款作为切分依据。
- 基于固定大小切分:比如默认采用128个词或512个词切分为一个chunk,可以快速实现文本分块。缺点是忽略了语义和上下文完整性。
- 上下文感知:在切分时考虑前后文关系,避免信息断裂。可以通过保持特定句对或短语相邻,或使用更复杂的算法识别并保留语义完整性。最简单的做法是切分时保留前一句和后一句话。你也可以使用自然语言处理技术识别语义单元,如通过句子相似度计算、主题模型(如LDA)或BERT嵌入聚类来切分文本,确保每个chunk内部语义连贯,减少跨chunk信息依赖。通义实验室提供了一种文本切割模型,输入长文本即可得到切割好的文本块,详情可参考:中文文本分割模型。
以上介绍了一些常见策略,你也可以考虑使用更复杂的切分策略,如围绕关键词切分或者采用动态调整的切分策略等,主要目的是为了保证每个chunk中信息的完整性,更好的服务系统提升检索质量。
- 句子滑动窗口检索
这个策略是通过设置window_size(窗口大小)来调整提取句子的数量,当用户的问题匹配到一个chunk语料块时,通过窗函数提取目标语料块的上下文,而不仅仅是语料块本身,这样来获得更完整的语料上下文信息,提升RAG生成质量。

图6:句子滑窗检索获取检索到的句子的上下文
- 自动合并检索
这个策略是将文档分块,建成一棵语料块的树,比如1024切分、512切分、128切分,并构造出一棵文档结构树。当应用作搜索时,如果同一个父节点的多个叶子节点被选中,则返回整个父节点对应的语料块。从而确保与问题相关的语料信息被完整保留下来,从而大幅提升RAG的生成质量。实测发现这个方法比句子滑动窗口检索效果好。
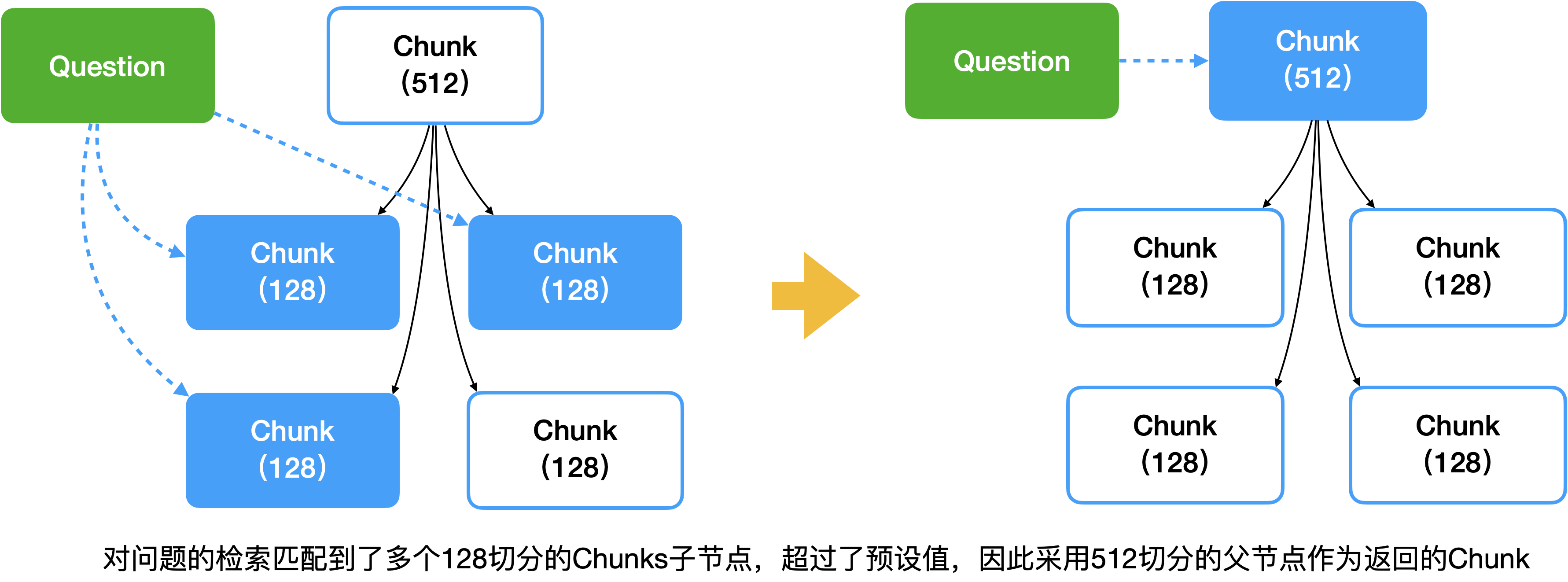
图7:自动合并检索的方法,返回父节点文本作为检索结果
- 选择更适合业务的Embedding模型
经过切分的语料块在提供检索服务之前,我们需要把chunk语料块由原来的文本内容转换为机器可以用于比对计算的一组数字,即变为Embedding向量。我们通过Embedding模型来进行这个转换。但是,由于不同的Embedding模型对于生成Embedding向量质量的影响很大,好的Embedding模型可以提升检索的准确率。
比如,针对中文检索的场景,我们应当选择在中文语料上表现更好的模型。那么针对你的业务场景,你也可以建议你的技术团队做Embedding模型的技术选型,挑选针对你的业务场景表现较好的模型。
- 选择更适合业务的ReRank模型
除了优化生成向量的质量,我们还需要同时优化做向量排序的ReRank模型,好的ReRank模型会让更贴近用户问题的chunks的排名更靠前。因此,我们也可以挑选能让你的业务应用表现更好的ReRank模型。
- Raptor 用聚类为文档块建立索引
还有一类有意思的做法是采用无监督聚类来生成文档索引。这就像通过文档的内容为文档自动建立目录的过程。假如志愿者拿到的文本资料是没有目录的,志愿者一页一页查找资料必然很慢。因此,可以将词条信息聚类,比如按照商店、公园、酒吧、咖啡店、中餐馆、快餐店等方式进行分组,建立目录,再根据汉语拼音字母来排序。这样志愿者来查找信息的时候就可以更快速地进行定位。
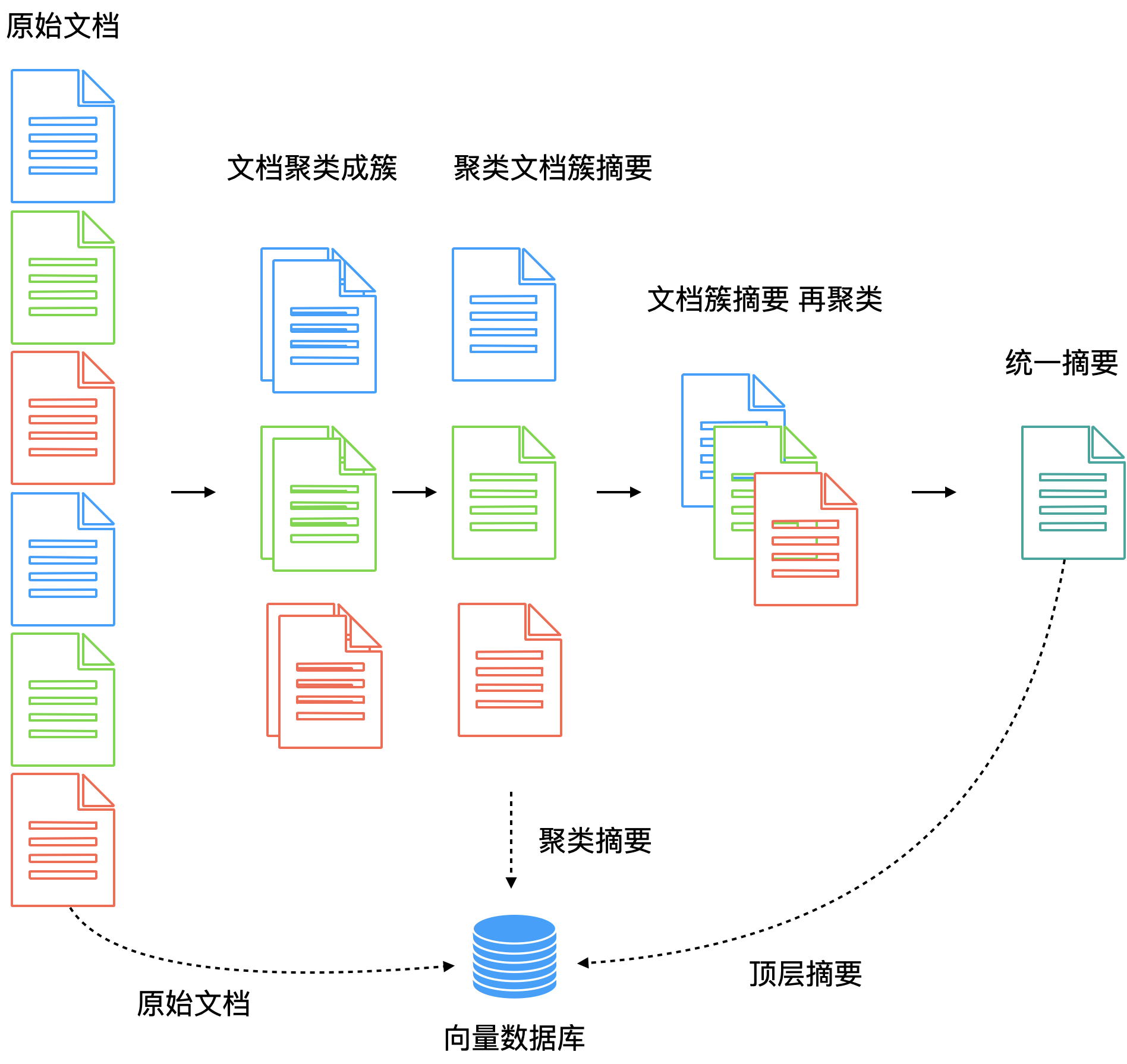
图8:Raptor 用聚类为文档块建立索引
5.3 改造二:让问题更好理解
我们希望做到能让人们通过口语对话来使用大模型应用。然而,人们在口语化表达自己的目的和意图时,往往会出现一些问题。比如,问题过于简单含糊出现了语义混淆,导致大模型理解错误;问题的要素非常多,而用户又讲得太少,只能在反复对话中不断沟通补全;问题涉及的知识点超出了大模型训练语料,或者知识库的覆盖范围,导致大模型编造了一些信息来回答等等。所以,我们期望能在用户提问的环节进行介入,让大模型能更好的理解用户的问题。针对这个问题进行尝试的论文很多,提供了很多有意思的实现思路,如Multi-Query、RAG-Fusion、Decomposition、Step-back、HyDE等等,我们简要讲解一下这些方法的思路。
- Enrich 完善用户问题
我们首先介绍一种比较容易想到的思路,让大模型来完善用户的原始问题,产生一个更利于系统理解的完善后的用户问题,再让后续的系统去执行用户的需求。通过用大模型对用户的问题进行专业化改写,特别是加入了知识库的支持,我们可以生成更专业的问题。下图展现了一种理想的对用户问题的Enrich流程。我们通过多轮对话逐步确认用户需求。
- 一种理想的通过多轮对话补全需求的方案。该设想是通过大模型多次主动与用户沟通,不断收集信息,完善对用户真实意图的理解,补全执行用户需求所需的各项参数。如下图所示。
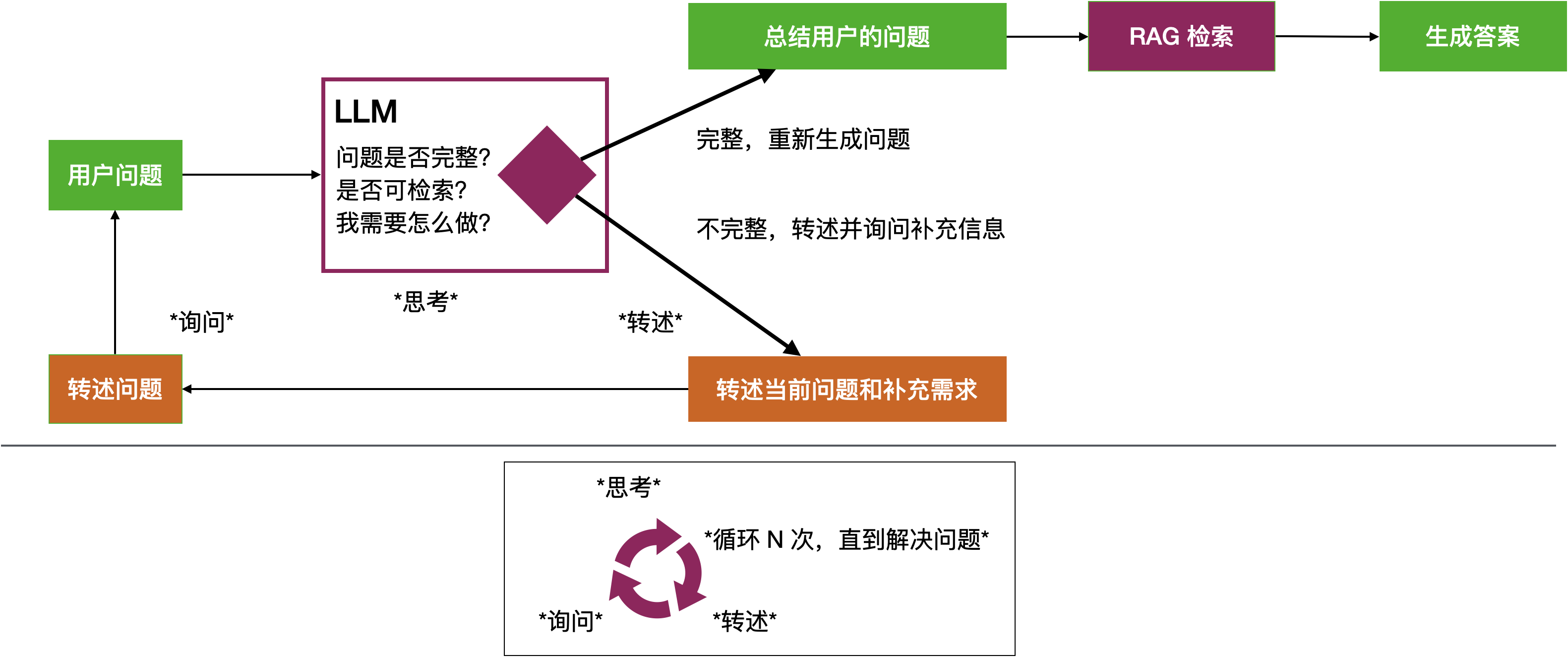
图9:通过多轮对话完善用户问题的工作流
以下展示一个通过多轮对话来补全用户问题的案例:
但是在实际的生产中,一方面用户可能没有那么大的耐性反复提供程序需要的信息,另一方面开发者也需要考虑如何终止信息采集对话,比如让大模型输出停止语“<EOS>(End Of Sentence)”。所以在实践中,我们需要采用一些更容易实现的方案。
- 让大模型转述用户问题,再进行RAG问答。参考“指令提示词”的思路,我们可以让大模型来转述用户的问题,将用户的问题标准化,规范化。这里我们可以提供一套标准提示词模板,提供一些标准化的示例,也可以用知识库来增强。我们的主要目的是规范用户的输入请求,再生成RAG查询指令,从而提升RAG查询质量。

图10:让大模型根据知识库来补全用户请求
- 让用户补全信息辅助业务调用。有一些应用场景需要大量的参数支撑,(比如订火车票需要起点、终点、时间、座位等级、座位偏好等等),我们还可以进一步完善上面的思路,一次性告诉用户系统需要什么信息,让用户来补全。首先,需要准确理解用户的意图,实现意图识别的手段很多,如使用向量相似度匹配、使用搜索引擎、或者直接大模型来支持。其次,根据用户意图选择合适的业务需求模板。接着,让大模型参考业务需求模版来生成一段对话发给用户,请求用户补充信息。这时,如果用户进行了信息完善,那么大模型就可以基于用户的回复信息结合用户的请求来生成下一步的行动指令,整个系统就可以实现应用系统自动帮助用户订机票、订酒店,完成知识库问答等应用形式。
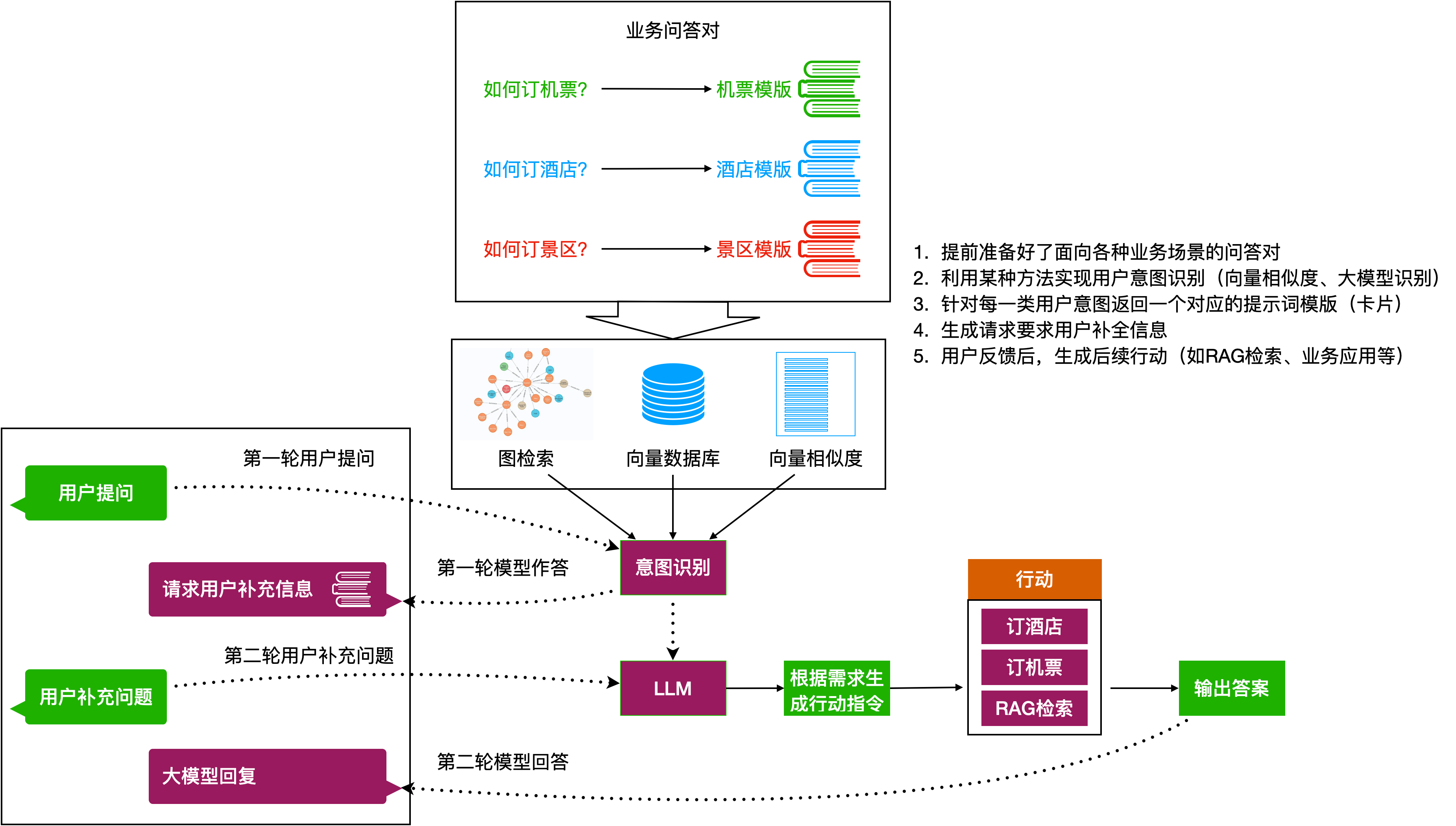
图11:一个完整的用户信息补全流程示意图
Enrich的方法介绍了一种大模型向用户多次确认需求来补全用户想法的做法。自此,我们假设已经获得了补全过的用户需求,但是由于用户面对的现实问题千变万化,而系统或RAG的知识可能会滞后,对用户问题的理解多少存在一些偏差,我们还可以继续对整个系统进行强化,接下来我们继续介绍“如何让系统更好地理解用户的问题”。
- Multi-Query 多路召回
多路召回的方法不是让大模型进行一次改写然后反复向用户确认,而是让大模型自己解决如何理解用户的问题。所以我们首先一次性改写出多种用户问题,让大模型根据用户提出的问题,从多种不同角度去生成有一定提问角度或提问内容上存在差异的问题。让这些存在差异的问题作为大模型对用户真实需求的猜测,然后再把每个问题分别生成答案,并总结出最终答案。

|
例如:用户问“烤鸭店在哪里?”,大模型会生成: |
|
|

以下就是能生成多路召回策略的提示词模板,你可以在你的项目里直接使用这段提示词模板,其中{question}就是用户输入的问题,你也可以尝试先翻译成中文再使用:
You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}- RAG-Fusion 过滤融合
在经过多路召回获取了各种语料块之后,并不是将所有检索到的语料块都交给大模型,而是先进行一轮筛选,给检索到的语料块进行去重操作,然后按照与原问题的相关性进行排序,再将语料块打包喂给大模型来生成答案。

经过去重复语料筛选,节省了传递给大模型的tokens数量,再经过排序,将更有价值的语料块传递给大模型,从而提升答案的生成质量。
用我们的例子讲就是,志愿者先从多种角度来理解用户的问题,然后对每个问题都去检索资料,查找有用信息,最后把重复信息去掉,再将获取的资料排序。这就能锁定比较接近用户问题的几段语料了,比如“全聚德烤鸭店的地址”,“天外天烤鸭店的地址”,“郭林家常菜店铺的地址”等等,以及这些烤鸭店分布在后海的那些区域,如何步行走过去等等。
- Step Back 问题摘要
让大模型先对问题进行一轮抽象,从大体上去把握用户的问题,获得一层高级思考下的语料块。
这个策略的提示词写作
You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:假如是医疗咨询的场景,用户描述了一大段病情、现象、感受、担忧;或者在法律服务的场景,用户描述了现场情况、事发双方的背景、纠纷的由来等一大段话的时候,我们就可以用这个策略,让大模型先理解一下用户的意图是什么,这个事情大体上看是什么问题。
- Decomposition 问题分解
这个策略讲究细节,有点像提示词工程中的CoT(Chain of Thoughts,思维链)的概念,是把用户的问题拆成一个一个小问题来理解,或者可以说是RAG中的CoT。这个策略的提示词如
You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):使用了这段提示词,大模型生成的子问题如下

接下来可以使用并行与串行两个策略来执行子任务。并行执行是将每个子任务抛出去获得一个答案,然后再让大模型把所有子任务的答案汇总起来。串行是依次执行子任务,然后将前一个任务生成的答案作为后一个任务的提示词的一部分。这两种执行策略如下图所示
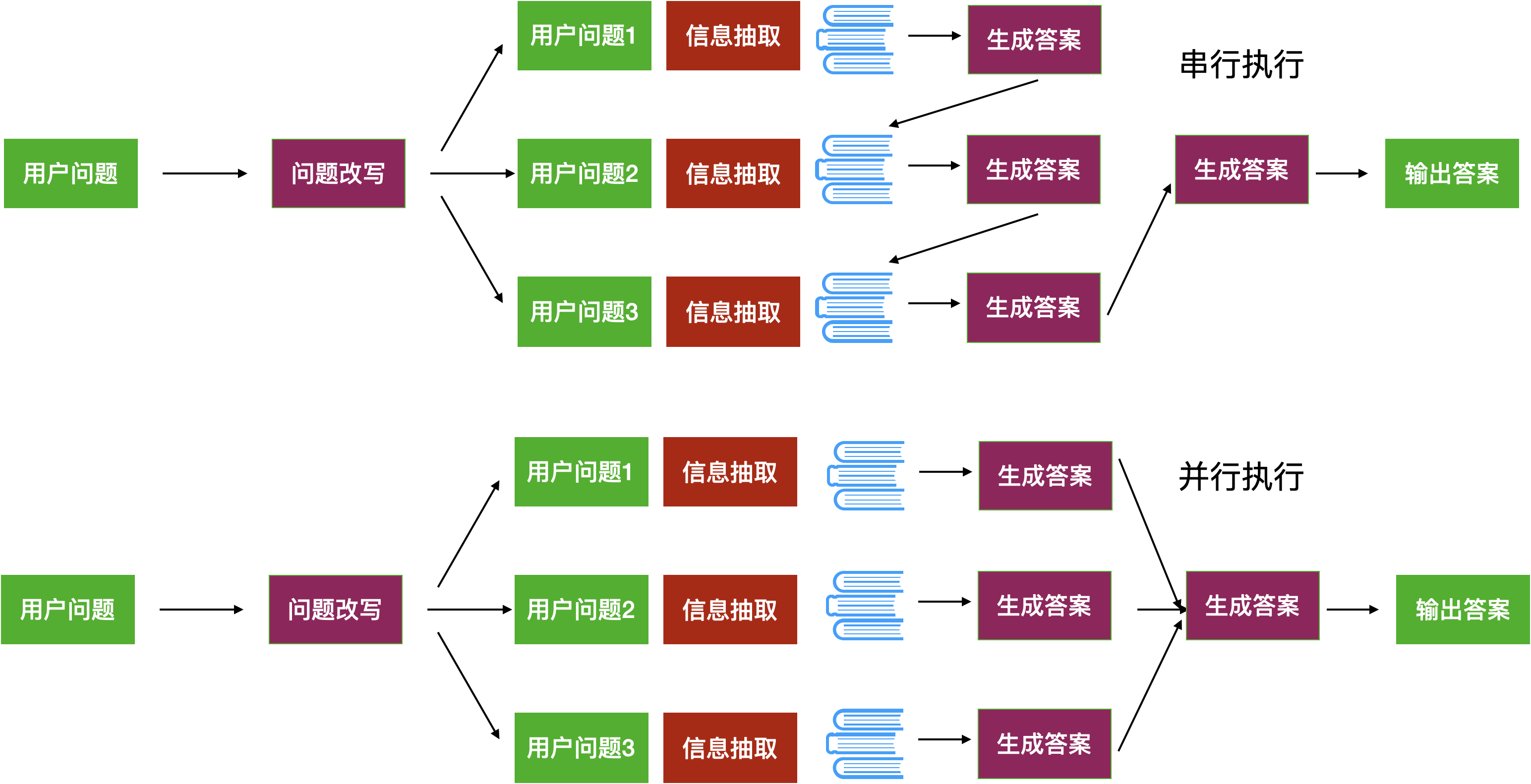
- HyDE 假设答案
这个策略让大模型先来根据用户的问题生成一段假设答案,然后用这段假设的答案作为新的问题去文档库里匹配新的文档块,再进行总结,生成最终答案。
好比志愿者听到用户的问题“推荐一家烤鸭店”,第一时间想到了“全聚德烤鸭店不错,我前两天刚吃过!”,接下来,志愿者按照自己的思路找到了全聚德烤鸭店的地址,并给用户讲解如何走过去。

5.4 改造三:改造信息抽取途径
Corrective Retrieval Augmented Generation (CRAG)是一种改善提取信息质量的策略:如果通过知识库检索得到的信息与用户问题相关性太低,我们就主动搜索互联网,将网络搜索到的信息与知识库搜索到的信息合并,再让大模型进行整理给出最终答案。在工程上我们可以有两种实现方式:
- 向量相似度,我们用检索信息得到的向量相似度分来判断。判断每个语料块与用户问题的相似度评分,是否高过某个阈值,如果搜索到的语料块与用户问题的相似度都比较低,就代表知识库中的信息与用户问题不太相关;
- 直接问大模型,我们可以先将知识库检索到的信息交给大模型,让大模型自主判断,这些资料是否能回答用户的问题。

图12:CRAG原理图
采用这个搜索策略,当志愿者遇到一个问题,而手边的资料都不能解答这个问题时,志愿者可以上网搜索答案。比如游客问:“天安门升旗仪式是几点钟?”志愿者可能会打开电脑,搜索一下明天天安门升旗仪式的具体时间,然后再回答给游客。这样,至少能让RAG的回答信息的范围有所扩大,回答质量有了提升。
在CRAG的论文中,当面临知识库不完备的情况时,先从互联网下载相关资料再回答的准确率比直接回答的准确率有了较大提升。
5.5 改造四:回答前反复思考
Self-RAG,也称为self-reflection,是一种通过在应用中设计反馈路径实现自我反思的策略。基于这个思想,我们可以让应用问自己三个问题:
- 相关性:我获取的这些材料和问题相关吗?
- 无幻觉:我的答案是不是按照材料写的来讲,还是我自己编造的?
- 已解答:我的答案是不是解答了问题?
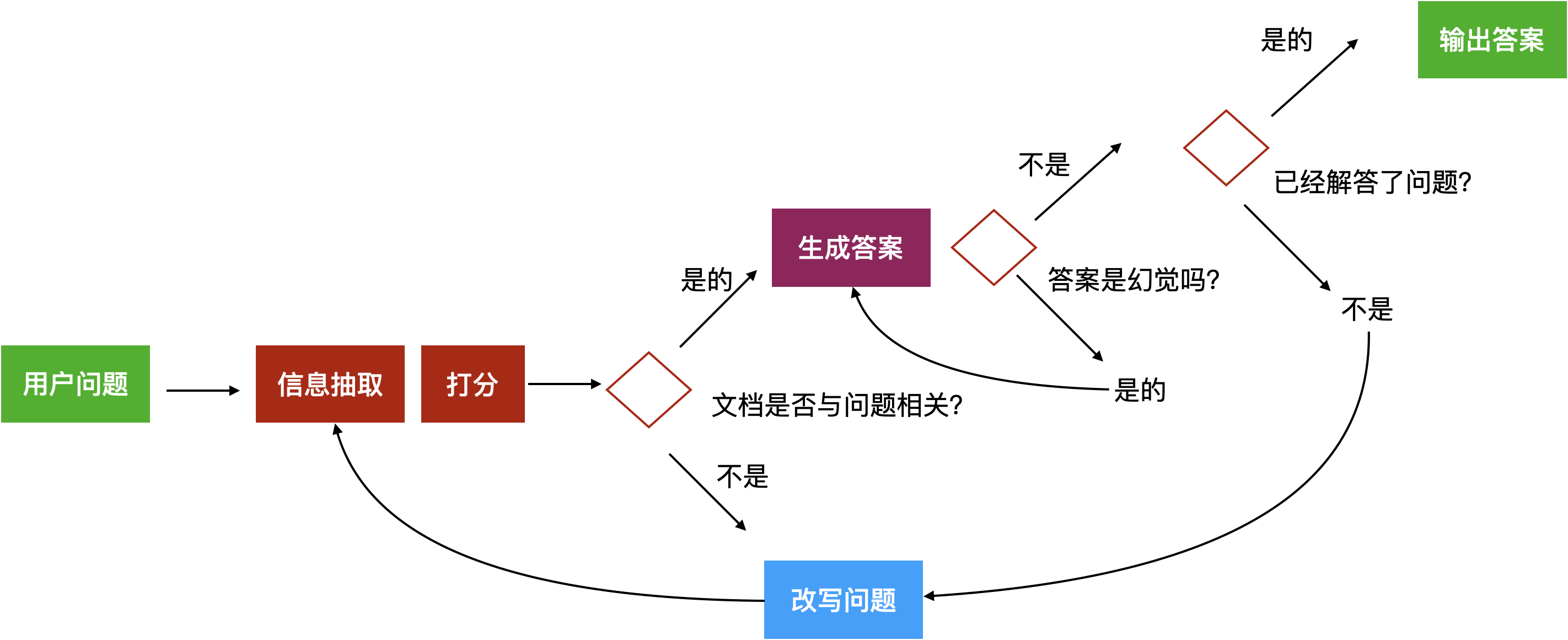
图13:Self-RAG原理图
这些判断本身可以通过另一段提示词工程让大模型给出判断,整个项目复杂度有了提升,但回答质量有了保障。
志愿者至少会通过反思这三个问题,在回答游客之前,让答案的质量有所提升。
5.6 改造五:从多种数据源中获取资料
这个策略涉及系统性的改造数据的存储和获取环节。传统RAG我们只分析文本文档,我们把文档作为字符串存在向量数据库和文档数据库中。但是现实中的知识还有结构化数据以及图知识库。因此,有很多工作者在研究从数据库中通过NL2SQL的方式直接获取与用户问题相关的数据或统计信息;从GraphDB中用NL2Cypher(显然这是在用Neo4J)获取关联知识。这些方法显然将给RAG带来更多新奇的体验。
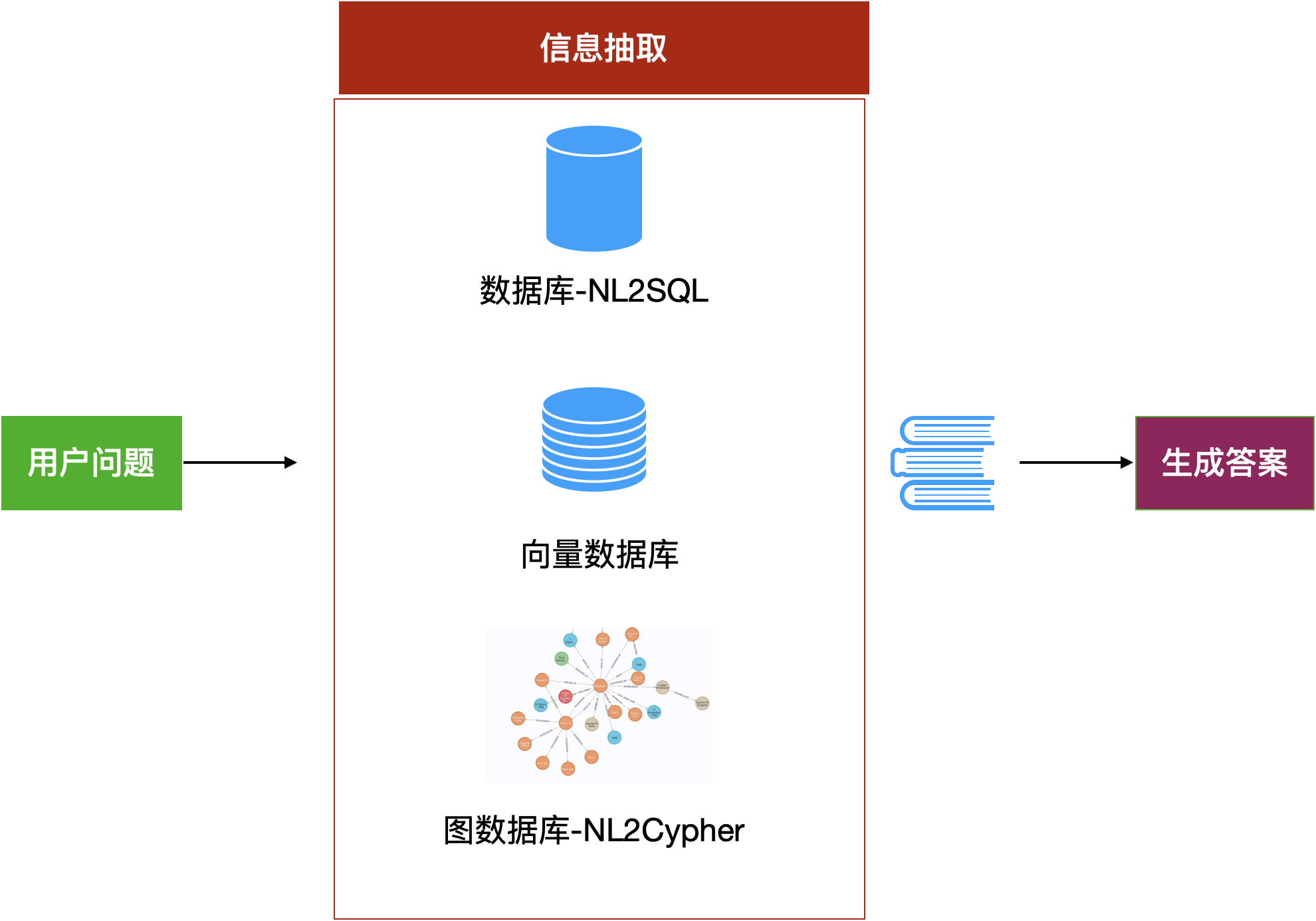
图14:通过大模型搜索数据库来抽取信息
- 从数据库中获取统计指标
大模型可以将用户问题转化为SQL语句去数据库中检索相关信息,这个能力就是NL2SQL(Natural Language to SQL)。如果搜索的问题比较简单,只有单表查询,并获取简单的统计数据如求和、求平均等等,大模型还能稳定地生成正确SQL。如果问题比较复杂涉及多表联合查询,或者涉及复杂的过滤条件,或复杂的排序计算公式,大模型生成SQL的正确性就会下降。我们一般用Spider榜单来评测大模型生成SQL的性能。合理构造提示词调用Qwen-Max生成SQL,或者使用SFT微调小模型如Qwen-14B来生成SQL,都可以获得可满足应用的NL2SQL能力。
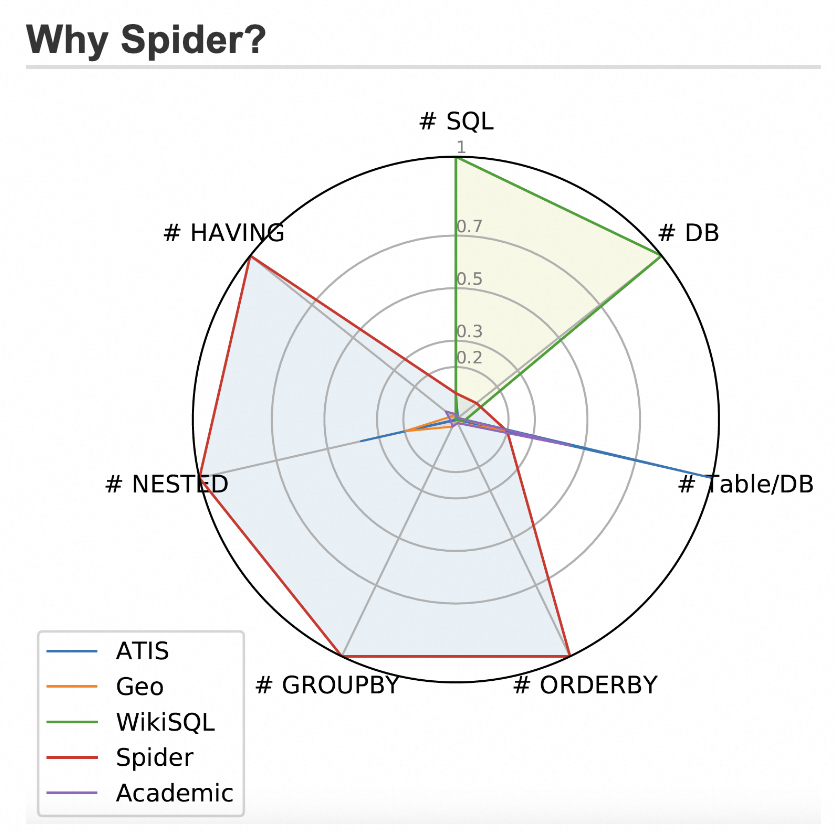
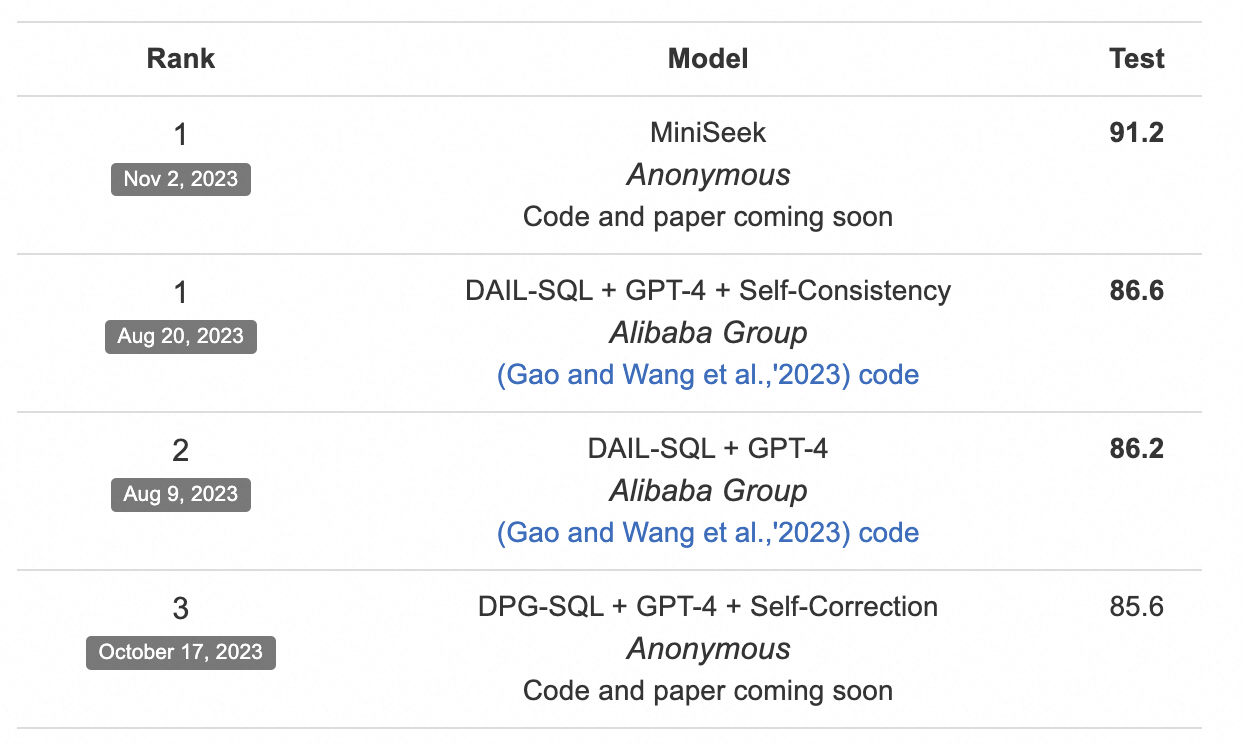
图15:Spider数据集和“执行正确率”评测榜单,榜单上排名靠前的DAIL-SQL+GPT4+Self-Consistency技术,就是使用先检索相似问题构造Few-Shot提示词,再用GPT4来生成SQL,并添加了多路召回策略的方法
- 从知识图谱中获取数据
Neo4j是一款图数据库引擎,可以为我们提供知识图谱构建和计算服务。在知识图谱上,我们调用各种图分析算法,如标签传播、关键节点发现等等,可以快速检索多度关联关系,挖掘隐藏关系。
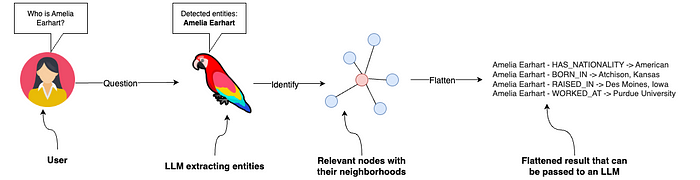
图16:将用户的问题转化为Neo4j的Cypher查询语句,从知识图谱中获取关键知识
5.7 总结
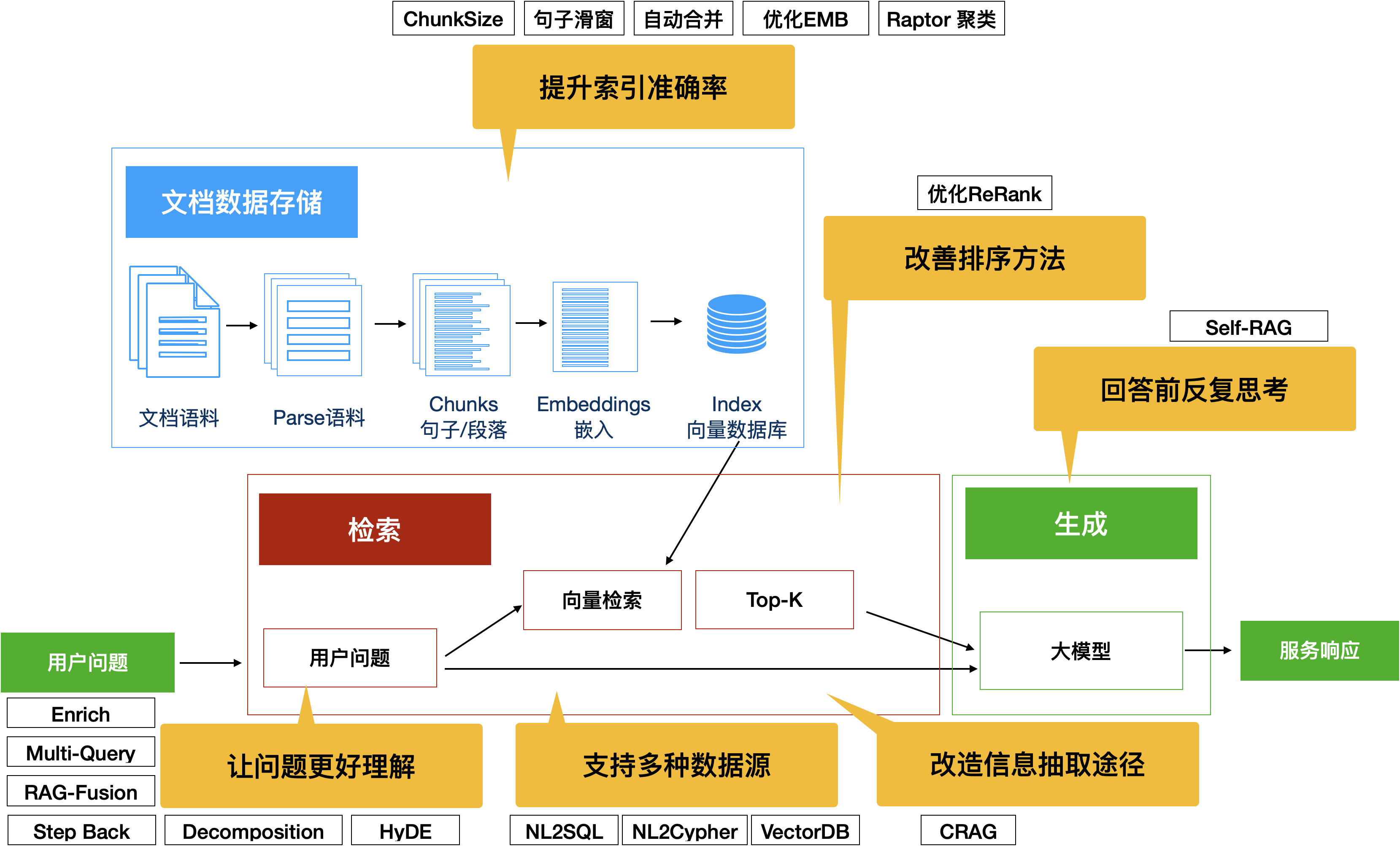
图17:增强RAG能力的多种方法汇总
我们可以通过多种办法来提升RAG的性能,在经典RAG框架之上,可以进行技术改造的方法层出不穷,RAG也是当前最活跃的技术话题之一,我们期待着这个 AI 领域未来会有更大的发展。
[进度: 已完成]本节小结
在本小节中,我们通过例子给你介绍了增强生成RAG来强化大模型,剖析了实现原理,并通过动手实验完整体验了RAG功能,结尾部分为你介绍了如何持续改进RAG应用效果,帮助你全面理解RAG。如果你想做一个专业领域的大模型问答,或者希望针对公司内部的私域知识开发智能小助手,RAG就是你最好的选择。
你也许尝试过让大模型基于你的工作总结写一份周报,然后你再手动发送周报的邮件给你老板。如果有一个程序可以接收这样的输入,把你的工作总结转化为周报,还能通过电子邮件发送给你的老板,这样的程序就是本章节即将介绍的“Agent”。接下来,我们将带你拆解Agent背后的实现思路,并探索单Agent、多Agent在现实世界的应用。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解大模型 Agent 是什么,能解决什么问题
- 了解人机交互的前沿方向,激发创新性思考
1 认识大模型Agent
1.1 大模型Agent是什么
从软件工程的角度来看,大模型Agent是指基于大语言模型的,能使用工具与外部世界进行交互的计算机程序。
在不同的翻译场景中,Agent可以翻译为智能体、代理、智能助手等,本文中提到的“智能体”即是Agent。
如果把Agent类比成人类,那么大模型相当于大脑,而工具就是四肢。Agent能够通过工具实现与外部世界的交互,而工具通常就是之前介绍过的插件。
实际上,现有的大模型Agent通常也具备规划能力和记忆能力,比如一个典型的Agent会是这样:
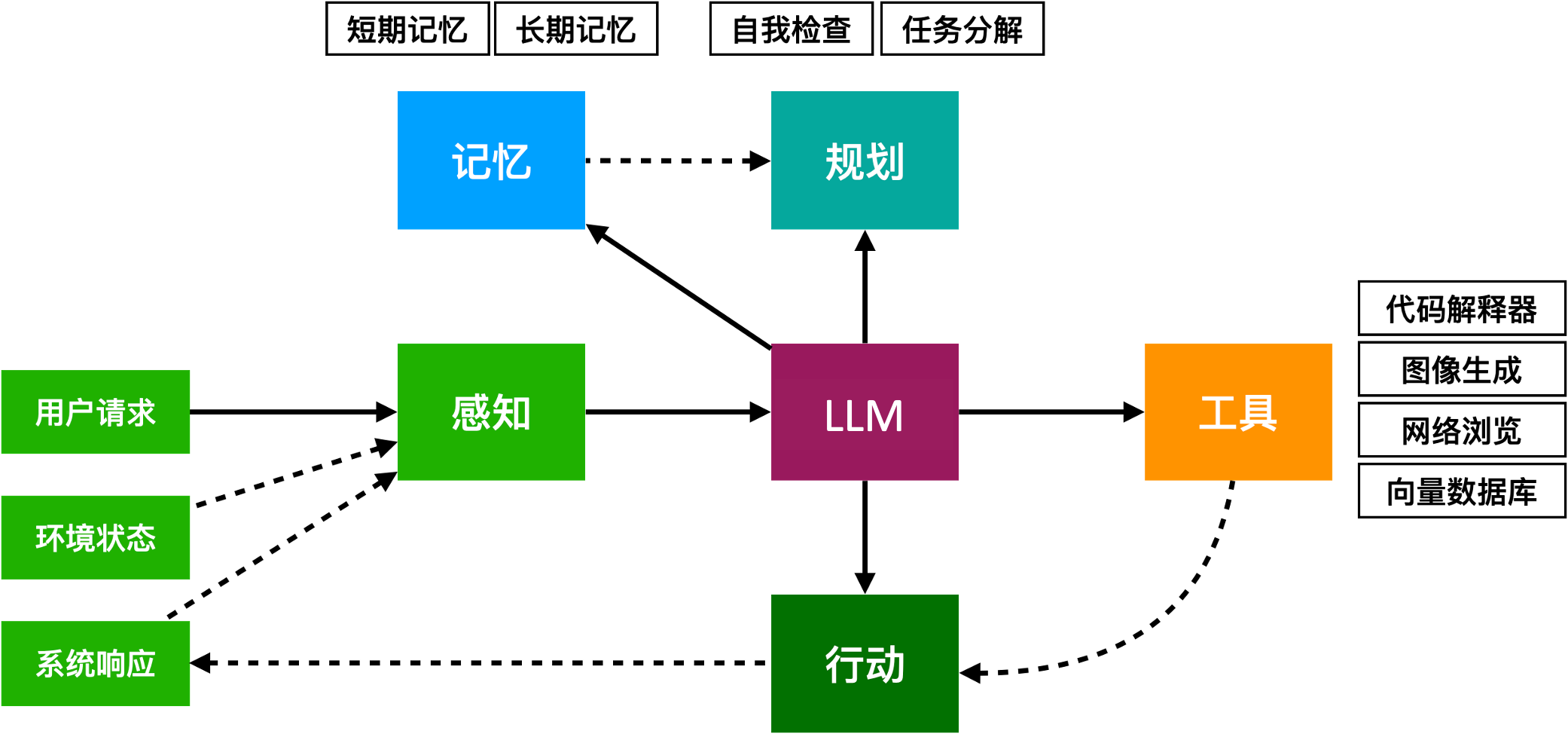
假设你有一个智能家庭助理,它可以帮助管理家庭中的各种事务:
-
感知(Perception):
- 家庭助理通过摄像头、麦克风、传感器等设备获取家庭成员的活动信息和环境状态。例如,它可以“看到”房间里的光线情况,听到你和它的对话,感知到家里的温度等。
-
思考(Reasoning):
- 家庭助理根据获取的信息来“思考”下一步应该做什么。如果你说“我有点冷”,它会从数据库中查询当前的温度数据,结合你的偏好(已存储或通过对话学习得来的),决定是否应该调整温度。
- 如果它检测到今天是垃圾回收日且垃圾桶已满,它会提醒你或自动安排机器人将垃圾桶移到指定位置。
- 行动(Action):
- 家庭助理可以执行一些具体的行动来响应你的需求。例如,它可以调整温度,打开或关闭窗帘,启动车库门,甚至下单购买你常用的家庭用品。
通过这个智能家庭助理的案例,我们可以形象地看到Agent是如何通过感知、思考和行动来帮助完成复杂任务并提高生活便利性的。智能家居中的各种设备与Agent的协作,形成一个协调、智能的家庭环境。
通过前面的学习,我们已经知道大模型是怎样使用工具的,接下来我们将一起学习Agent是如何具备记忆能力和规划能力的。
1.2 让Agent具备记忆能力
记忆可以辅助大模型生成计划、决策、内容,就像人类一样,现代的智能体也具有记忆力。
1.2.1 短期记忆(Short-Term Memory)
想象你在超级市场购物时,暂时记住了一串购物清单,但一旦结账离开后,这些信息会很快就忘记了。这就是短期记忆,它帮助我们处理和暂时存储当前需要的信息。
在大模型Agent中,短期记忆对应着用户与大模型Agent之间的历史对话、提示词、搜索工具反馈的语料块等等,但这些信息仅与当前用户与大模型的对话内容有关。一旦用户关闭应用或离开聊天环境,这类信息就消失了。
我们需要将短期记忆中的内容提供给大模型做参考,因此大模型支持的上下文长度决定了我们可以提供给大模型做参考的信息量。为了确保使用正常,我们会减少传递给大模型的历史记录数量,导致一些人在使用大模型时,会发现大模型只有“很短”的记忆,刚刚沟通过的事情,几句话之后大模型竟然忘了。
但另一方面,如果我们使用支持超长上下文的大模型,我们有可能会遇到另一个问题,对近邻信息敏感度更高的问题(recency问题)。也就是说,虽然我们可以给大模型传递很长的历史记录,但是大模型只对靠近提示词末尾部分的信息更感兴趣,如果你需要检索的信息恰好被编辑到提示词最开始的部分,大模型也有可能无法向你提供正确的答案。
1.2.2 长期记忆(Long-Term Memory)
长期记忆是指我们大脑中长期存储的信息,比如你的童年回忆、学习到的知识和技能。这些信息可以存储非常久,有时甚至是一辈子。
在大模型Agent中,长期记忆对应着系统持久化的信息,如业务历史记录、知识库等,通常存储在外部向量数据库和文档库中,Agent会利用长期记忆来回答用户私有知识或专业领域相关的问题。
1.3 让Agent具备规划能力
想象一下,你要完成一个复杂的任务,比如:组织一场大型生日派对。这个任务涉及很多步骤,从邀请客人、准备食物到布置场地等等。要成功地完成这个任务,最好先将它分解成若干小的、可管理的步骤。例如:
- 准备邀请函
- 选择菜单
- 布置场地
- 确认表演节目
通过将大任务拆分成小任务,你可以更有条理地完成整个计划。我们可以让Agent在处理复杂任务时也使用类似的方法。
1.3.1 任务分解
在前面优化提示词的章节中,我们其实已经介绍了任务分解的方式,即思维链、思维树等方式,这里将针对Agent场景进一步探讨。
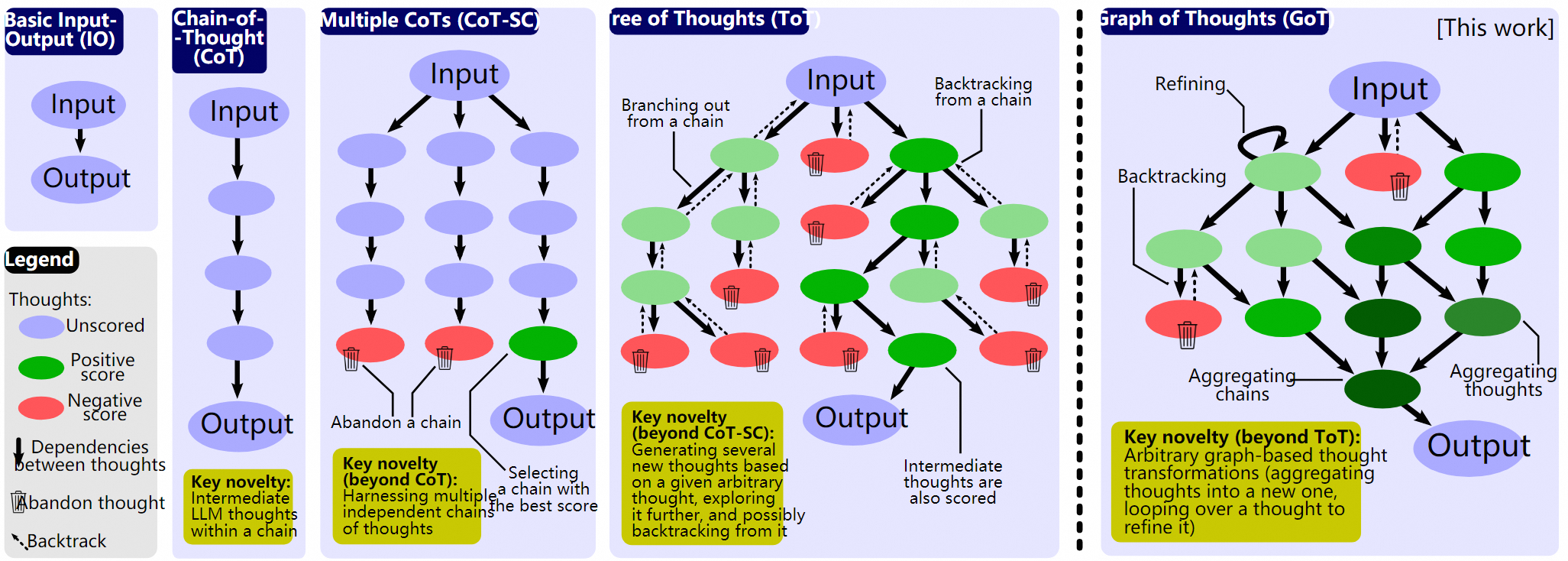
图:几种任务分解方式
1.3.1.1 思维链(Chain of Thought,CoT)
把复杂任务分解为链式思维最早是用来解决数学题的。如下图所示,我们想让大模型来求解 (23-20+6=?) 这样的数学题,但是早期的大模型往往搞不清多步数学运算的内在逻辑,算不准。后来,Wei等人(2022)发现了这个CoT的方法,如果我们在提示词里明确写上让大模型“一步一步思考”,那么大模型就会开始拆解计算的步骤,最后得到正确的结果。如下图绿色部分所示。
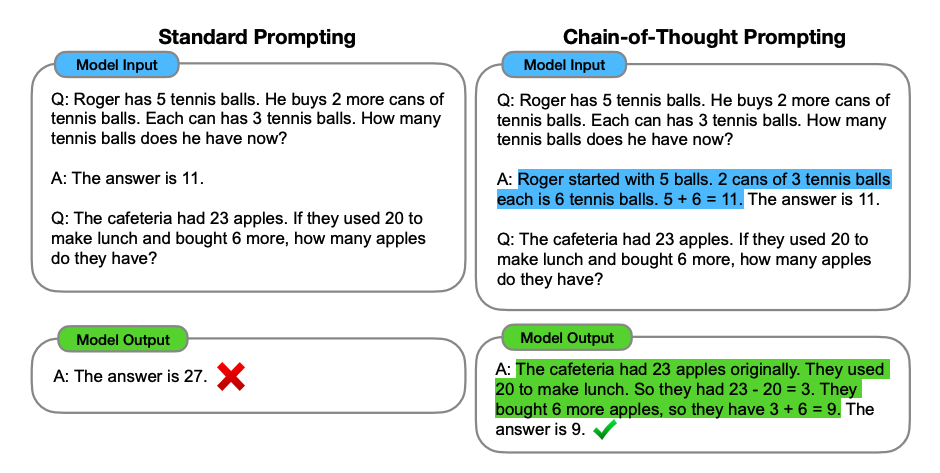
图:链式思维模式的效果对比
但如果我们用Agent的方式来做这道数学题,我们的方法就可以不仅仅局限于在提示词中加上“一步一步思考”这句话来解决问题了,我们还可以使用计算器直接计算、使用代码解析器先编程后计算、或者我们用循环迭代的方式,先让大模型拆解步骤,再一步一步推理执行。我们还可以先让大模型判断一下问题的复杂度,从以上三种方式中选择一个合适的方法,然后再继续执行。
对于复杂的应用场景,不管是人为将任务分解成多步执行,还是让大模型自己来分解任务,都会比直接让大模型给出判断要稳妥,也便于系统在大模型的工作流程中进行监控和管理。
1.3.1.2 思维树ToT(Tree of Thought)
思维树(ToT)则进一步扩展了思维链的概念,通过构建一个具有分支和选择的树形结构来处理复杂问题。
例如,我们先问问大模型“做西红柿炒鸡蛋需要几步?把每一步的任务目标列出来”。或者人为把做一道菜的步骤分层。
大模型可能会回答:准备食材、烹饪食材、装盘,三个步骤。也可能是:洗菜、切菜、搅打鸡蛋、炒菜、装盘,五个步骤。
接下来,我们会在每一步询问大模型,有哪些做法?应当如何处理?比如在切菜环节我们可能会问“西红柿怎么切?切丁?还是切块?”,在炒菜环节我们可能会问“先炒鸡蛋还是先炒西红柿?先放盐还是先放糖?”等等,在每个步骤,我们都可以让大模型生成多种方法供选择。
最后,我们需要把这些方案进行汇总,选出一条我们最满意的炒菜方案作为我们的菜谱。这就是在决策树上采用深度搜索或者广度搜索来确定一条最佳路径。
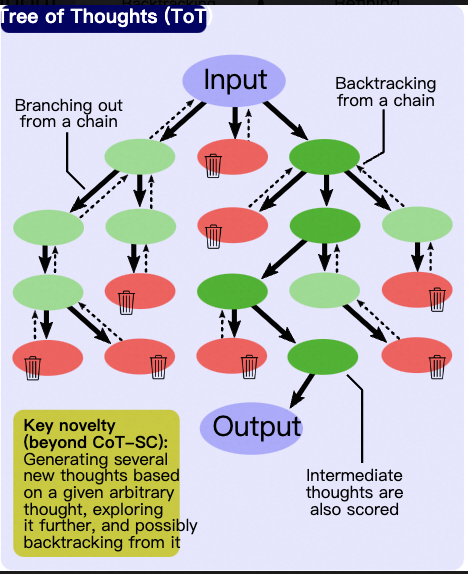
在这一模式中,我们尽可能让大模型生成多条可以探索尝试的路径,我们在应用层面评估每条路径的结果和影响,然后选择最优的解决方案。这种方法特别适用于那些不确定性较高、路径选择众多的问题,例如复杂的决策树分析、多步骤规划,以及需要权衡不同因素的优化问题。
1.3.1.3 扩展阅读:思维图GoT(Graph of Thoughts)及其他
虽然ToT的方法比较接近人类思考问题的方式,但在实际使用中,我们还可以考虑对思维树进行执行上的优化,比如Besta等人(2023)提出了思维图(GoT)。比如在执行中发现了问题可以回溯到上一步;在评估前对执行出了问题的方案做剪枝(在同一层多个相同执行的节点可以进行合并等),所以我们可以把思维图看做是对思维树的工程优化。
实际应用中我们也要考虑树思维做剪枝,比如系统在同一步骤中生成的多个治疗方案有可能是重复的,而有一些疾病的治疗手段非常相似。
之后,Ding等人(2023)提出了XoT(Everything of Thoughts),试图整合各种任务分解的方案,构建一种能平衡性能、效率、灵活性的终极方案。这个框架设计加入预训练强化学习和蒙特卡洛搜索方法,并引入外部领域知识和规划能力。
这一小节为扩展阅读,如果看不明白也没有关系。如果感兴趣,请参考论文和代码进一步了解。
1.3.2 推理与反思
大模型经过CoT等方式进行推理后,确实给出了更好的结果,但是这个结果实际上不一定符合我们的规划或需求。
针对这个问题,一个比较有效的办法就是,让大模型进行自我反思,简单来说,就是让大模型先审视自己的结果,然后再输出结果。就像人类写文章一样,如果在文章定稿之前进行反复回读和审视,就可以不断地优化文章的内容,提升最终文章的质量。
ReAct方法
Yao等人(2022)提出了推理(Reasoning)与行动(Acting)相协同的方法,简称ReAct。ReAct就像是厨师在做菜时,不仅在自己思考,还同时在实际操作中不断调整。比如:
- 思考(Thought):厨师在准备食材前,会构思菜谱和步骤。
- 行动(Action):开始切菜、炒菜,每一步都按照步骤来做。
- 观察(Observation):尝一口汤,看看味道如何。
- 循环(Loop):根据汤的味道,再思考下一个步骤,进行调整。
ReAct方法让大语言模型不仅能“思考”还可以“行动”和“观察”环境,比如使用维基百科的搜索API来获取信息,并生成自然语言来记录思考过程。
ReAct方法的实现原理是把思考、推理、观察整合到提示词模版中,让大模型在具体工作中既可以基于环境反馈选择使用何种工具来完成工作,又可以基于环境反馈推理是否可以给出任务的答案。
ReAct-Agent的运行逻辑
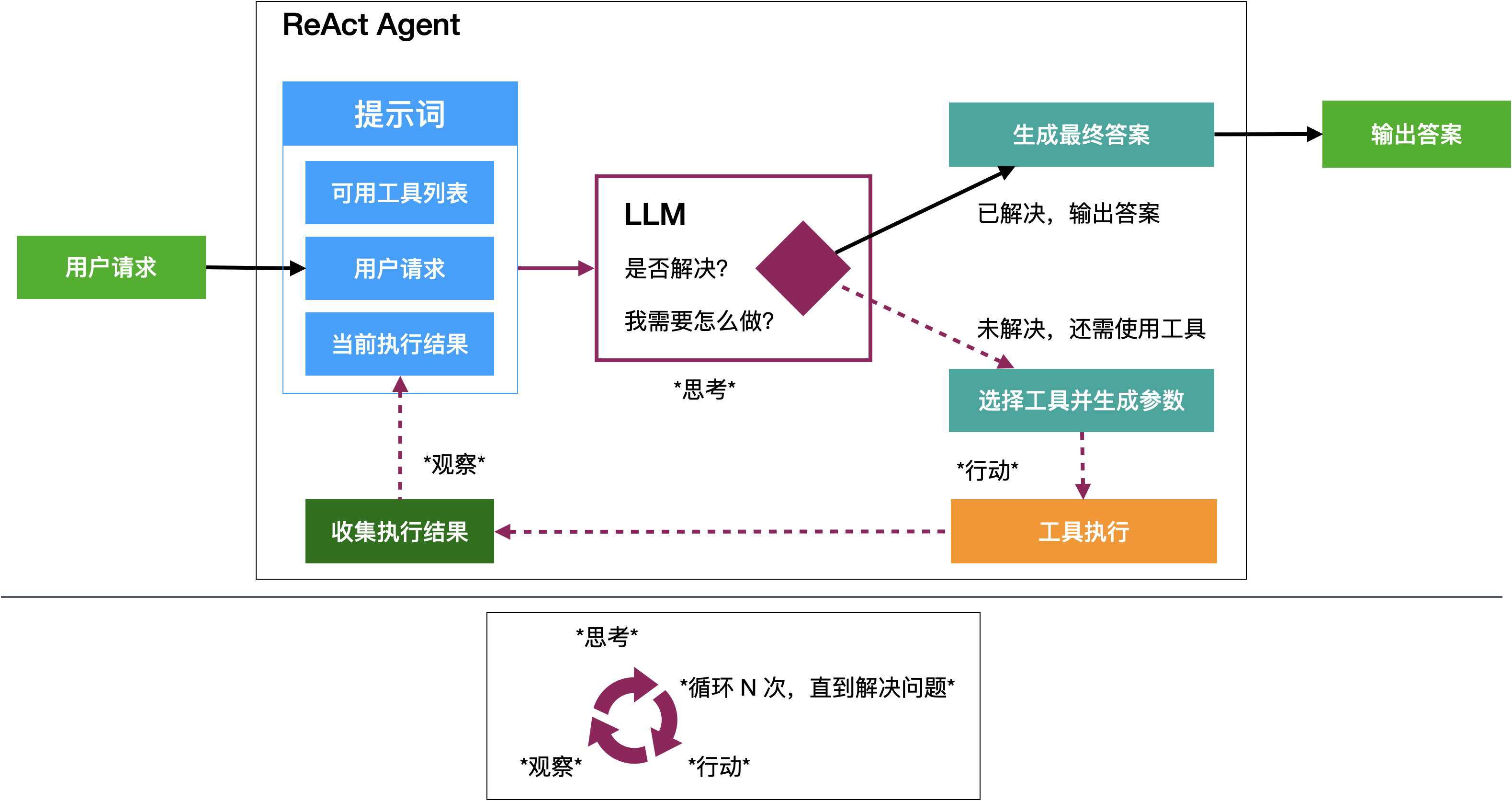
大模型在ReAct提示词的引导下完成推理、行动、再推理、再行动,直至生成最终答案。
- 当大模型接收到用户请求的时候,大模型先判断能不能解答用户的问题。
- 当大模型不能解答用户的问题时,大模型会根据可用工具列表的介绍,选择一个合适的工具。
- 大模型根据工具的使用说明生成调用指令,并在指令中插入需要的参数。
- Agent主体程序会根据大模型生成的指令来调用对应的工具服务
- Agent主体程序等待工具执行完成并收集执行结果。
- 带着用户问题和执行结果,大模型会再次考虑是否已经解决了问题。如果没有解决,就继续选择一个工具来执行。如果解决了,大模型会生成最终答案,并结束任务。
ReAct提示词模版
在LangChain中,ReAct的提示词模版定义如下。
input_variables=['agent_scratchpad', 'input', 'tool_names', 'tools']
template='Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}'在上述提示词模版中,大模型根据输入的问题{question},构造了一个思维链。在这个思维链中:问题、思考、行为、行动的输入、行动的结果,这五点是Agent工作的核心。在思考中,我们定义了Agent的scratchpad变量,这个scratchpad可以用于记录Agent的思考过程。在行动中,我们定义了Agent可以使用的工具列表{tools},并且大模型需要从工具列表中来选择一个帮助Agent解决问题的工具。这个思考过程可以进行N次直到Agent认为自己已经解决了问题。这时通过Thought: I now know the final answer来结束这个思考过程,然后通过Final Answer来输出最终的答案。
1.4 小结
了解了大模型Agent的能力之后,我们简单总结一下Agent相对于大模型有什么区别。
- 它不局限于输出回答,还能通过插件(工具)与外部世界交互,例如发送邮件、发布文章、联网查询、执行代码、下单购物等……理论上只要是计算机程序能做的事情,它都能做到。
- 它不再是被动式地接受多轮提问,而是能自主地推理(拆解任务、选择最优路径)、主动纠错、自主完成任务。你可以让它每完成一个或多个步骤就给你同步进展,和你确认下一步的动作,也可以授权它自主地完成所有步骤。
- 它不仅可以完成简单的事情,还能完成复杂的任务,比如搭建一个网站、开发一款游戏,因为它能拆解任务、自我纠错、调用外部工具等。
- 它可以自我迭代,吸取历史经验,不断成长,因为它不仅能记住这次会话里你对它的指导,还能记住以前的会话里你给它提过的要求。
- 它不仅能完成通用的任务,还能完成特定领域的任务,因为它可以接入特定领域的外部知识库和工具。
2 Agent 应用场景
Agent就像一个全能助手,你可以先梳理自己日常工作或学习中需要做的事情,然后看看哪些可以借助它来完成。
可以让它完成一些简单的事情,比如发送邮件、查询天气。
也可以让它完成更复杂更有难度的事情,比如搭建网站、写文章、制定营销策略、开发软件原型等。
举个例子,你可能需要写一篇文章并发布到一个平台,如果让Agent来完成,它可能会:
- 调研哪些主题比较受欢迎。
- 根据调研结果,为你选择一个有吸引力的文章主题。
- 帮助你收集和整理与主题相关的资料和数据。
- 生成文章的大纲,确保结构清晰、逻辑合理。
- 根据大纲撰写初稿。
- 提供语法和风格的改进建议,并进行多次润色和修订。
- 找到合适的平台进行发布,并在合适的时间发布文章。
- 制作吸引眼球的标题和摘要,以提高点击率。
- 进行SEO优化,提高文章在搜索引擎中的排名。
- 监测文章流量和读者反馈,为后续改进提供数据支持。
你可以让Agent每完成一步或几步就和你确认,也可以让它自主完成。Agent不仅可以帮你节省大量时间和精力,还能提高工作效率和成果质量。
接下来让我们看一个AutoGPT的Demo。AutoGPT是开源的Agent应用程序。
下面是AgentGPT的Demo。AgentGPT用于在网页里可视化地部署Agent。
3 体验基于 ModelScope-Agent 框架搭建的 Agent 应用
如果你仔细分析,记忆、工具、行动这三个能力并不是由大模型来提供的,基本都是一些外部能力。因此,技术社区针对如何实现大模型Agent,诞生了很多学术项目,从多个角度、多种技术手段来构造实现Agent。
其中,ModelScope-Agent提供了一个可定制、可扩展的Agent代码框架。
3.1 ModelScope-Agent能力
利用ModelScope-Agent框架开发的Agent,除了可以提供文本创作之外,还能生成图片、视频、语音等内容。单个Agent具有角色扮演、LLM调用、工具使用、规划、记忆等能力。 技术上主要具有以下特点:
- 简单的Agent实现流程:仅需指定角色描述、大模型名称、工具名列表,即可实现一个Agent应用,框架内部自动实现工具使用、规划、记忆等工作流的编排。
- 丰富的模型和工具:框架内置丰富的大模型接口,例如Dashscope和Modelscope模型接口,OpenAI模型接口等。内置丰富的工具,例如代码运行、天气查询、文生图、网页解析等,方便定制专属Agent。
- 统一的接口和高扩展性:框架具有清晰的工具、大模型注册机制,方便用户扩展能力更加丰富的Agent应用。
- 低耦合性:开发者可以方便地直接使用内置的工具、大模型、记忆等组件,而不需要绑定更上层的Agent。
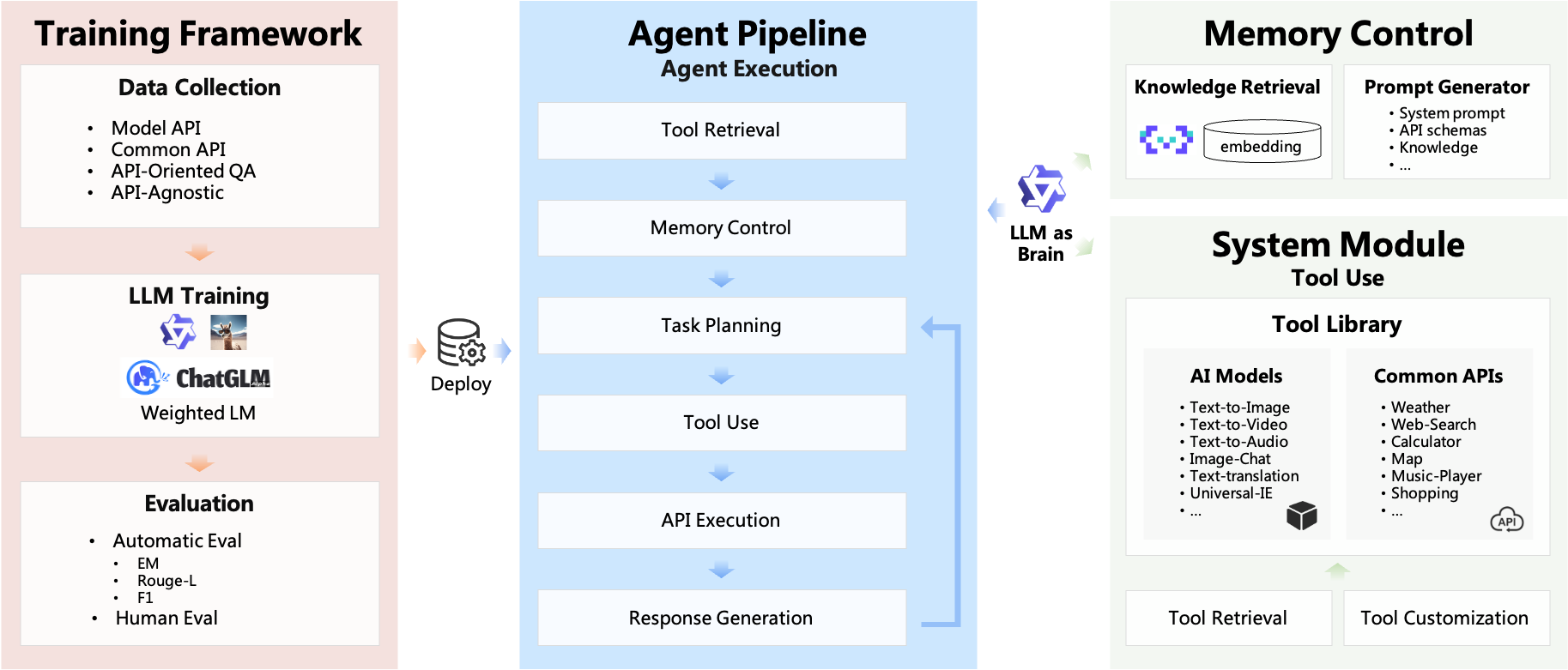
图:ModelScope-Agent系统框架(老版本,仅供参考)
3.1.1 完成一个简单任务
通过对话可以让Agent直接生成视频,虽然这个视频很短也比较粗糙,但是给我们展示了通过调用插件来生成视频的能力。如果我们有更好的文本生成视频的服务,我们可以开发Agent调用我们定制的更好的视频生成模型。

3.1.2 完成由多个步骤组成的任务
我们可以在一句话中描述多个不同的任务,大模型会分析用户请求,安排执行顺序,并依次进行不同任务的规划、调度、执行和结果返回。
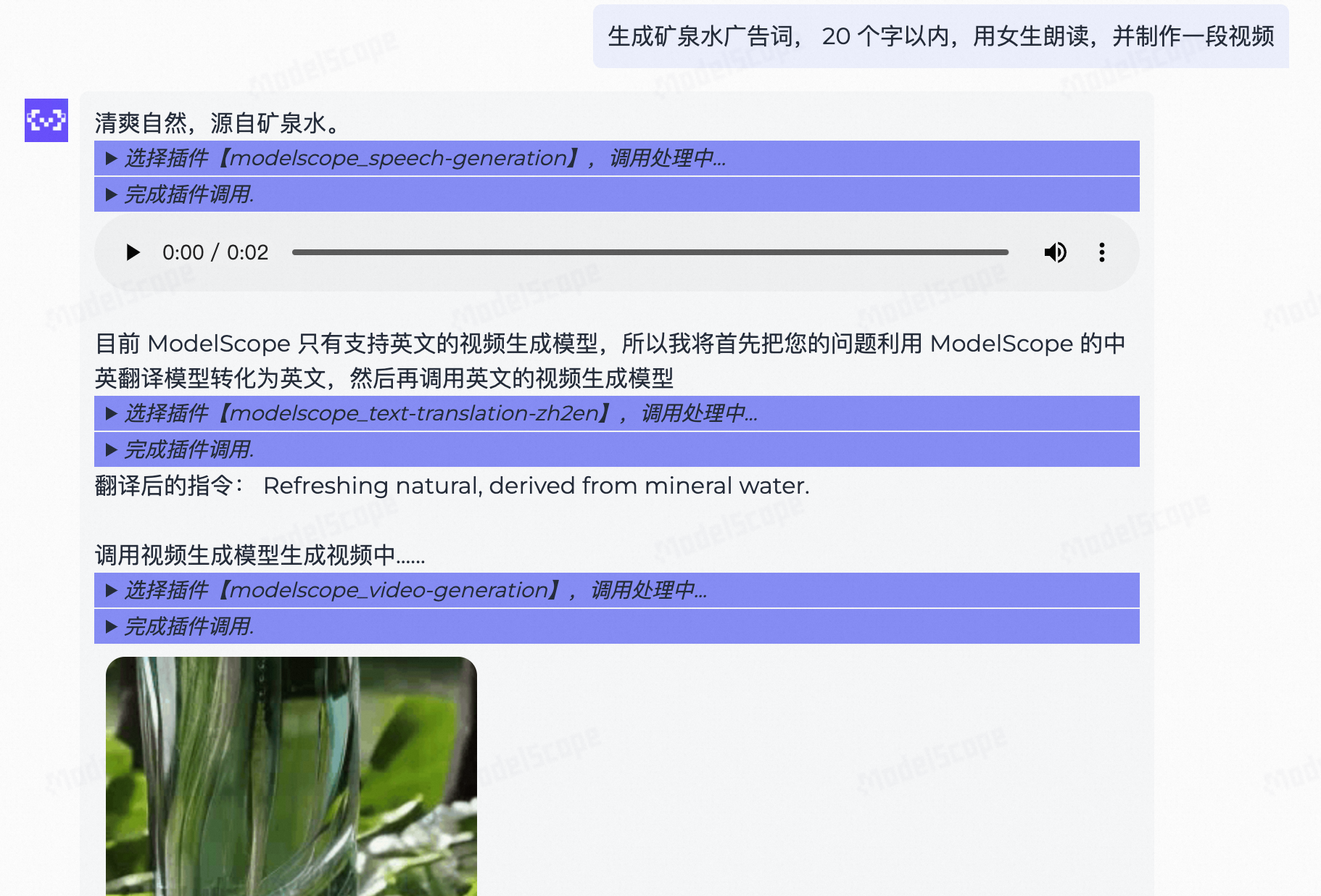
- 目前这个在线演示工具的能力比较基础,因此我们可以要求模型只生成20个字以内的广告词。
- 语音合成的模型能力比较稳定,语音效果较好。
3.1.3 从多轮对话中提取工具参数
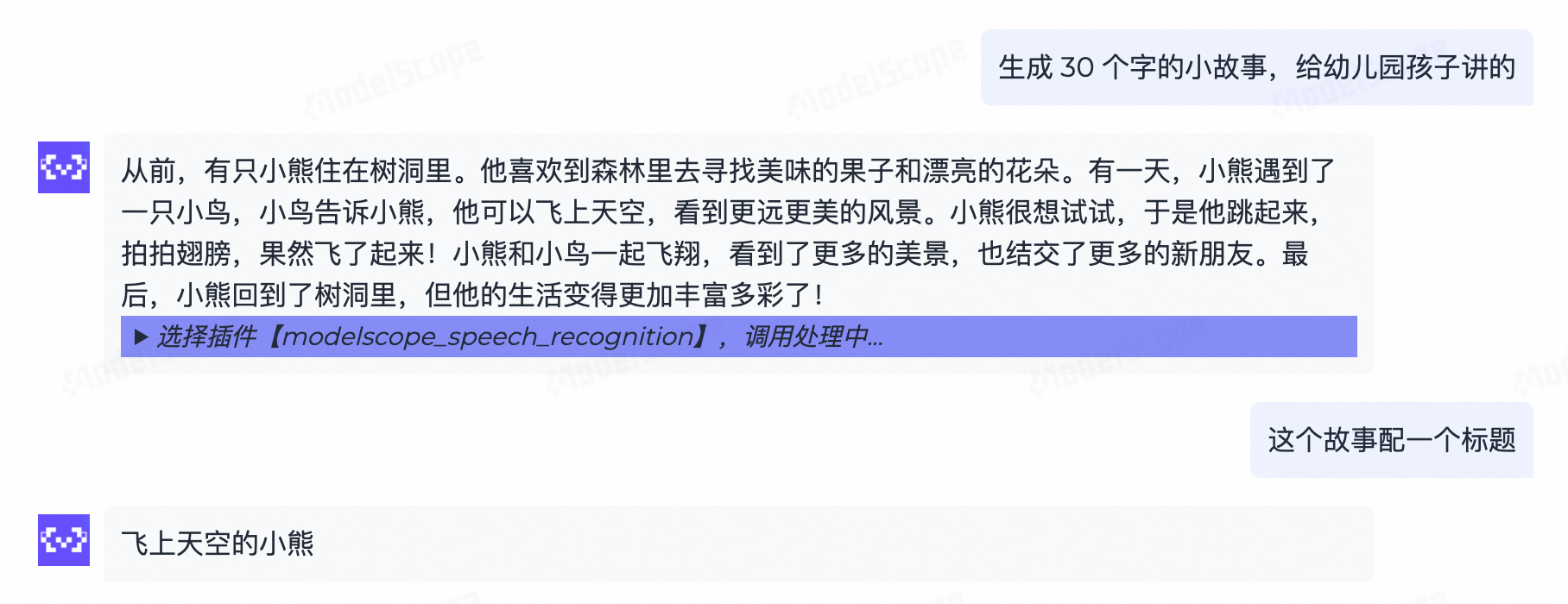
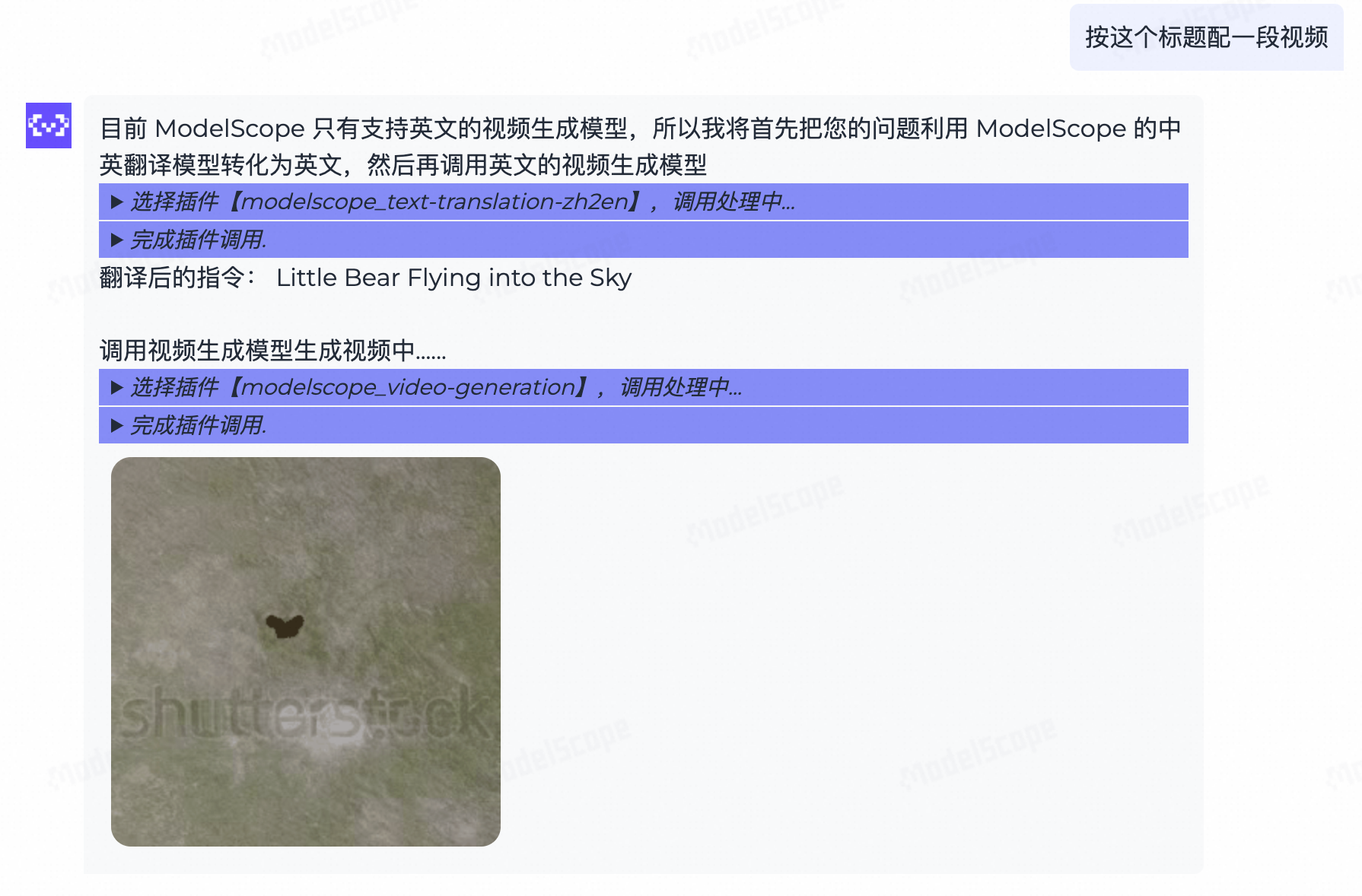
ModeScope-Agent默认带有记忆能力,Agent会在对话中参考历史信息来为客户生成内容,这样可以让用户一边思考一边看到效果,让用户体验更连贯。比如下面的例子,用户想让大模型生成一个小故事,然后想让大模型自己来总结出一个标题、或者生成一段配图或一段视频。这个例子比较像市面上的一些面向小朋友的AIGC产品,既能讲故事,又能自己配上内容。在这个过程中,Agent需要从历史对话中提取信息来完成新的任务,这些信息就是当前调用工具需要的参数。
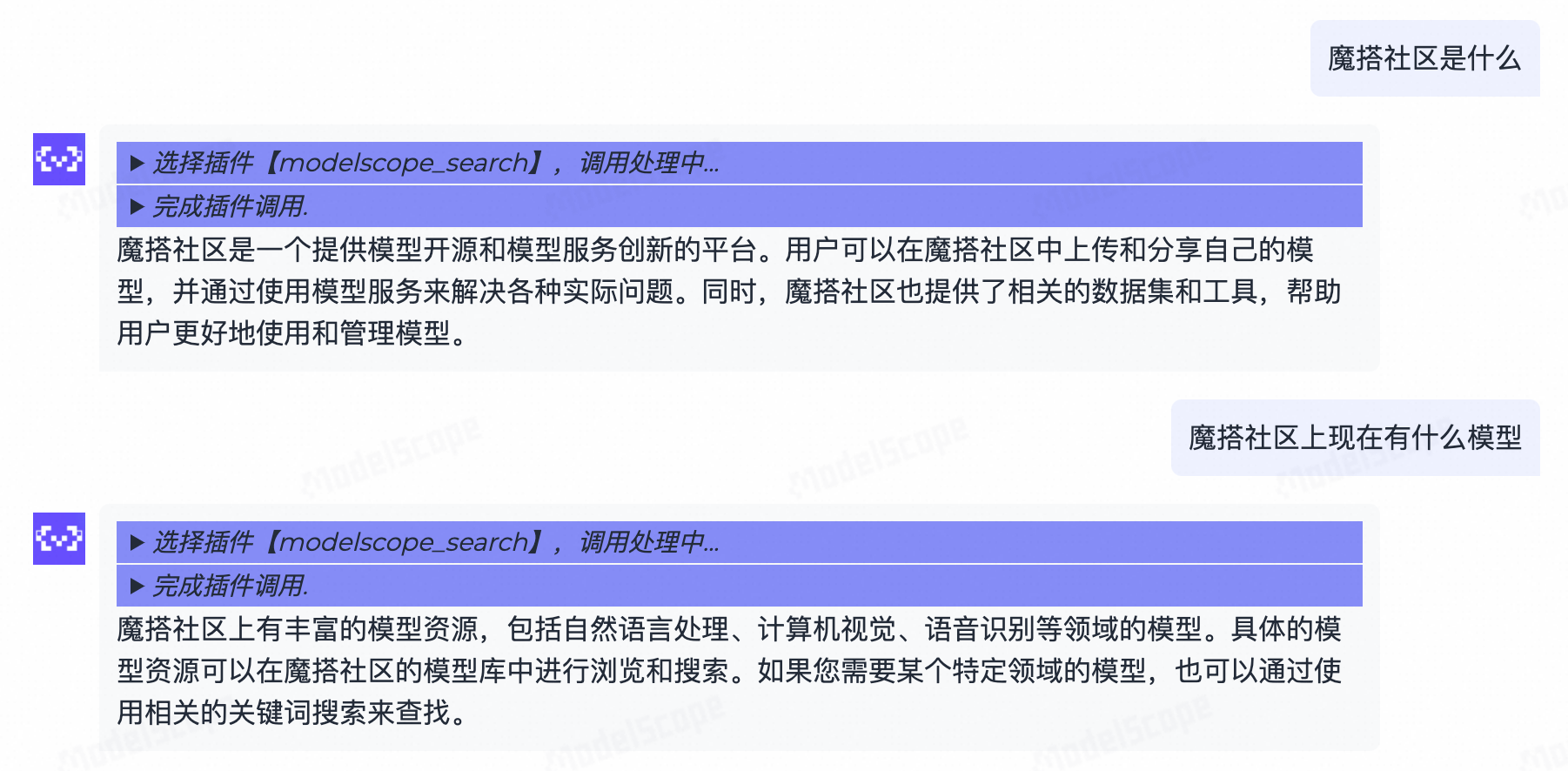
3.1.4 基于检索工具的问答
魔搭Agent可以加载知识库插件和搜索工具插件,这里展示的是modelscope_search插件,你也可以使用自己的搜索引擎API替换这个插件。

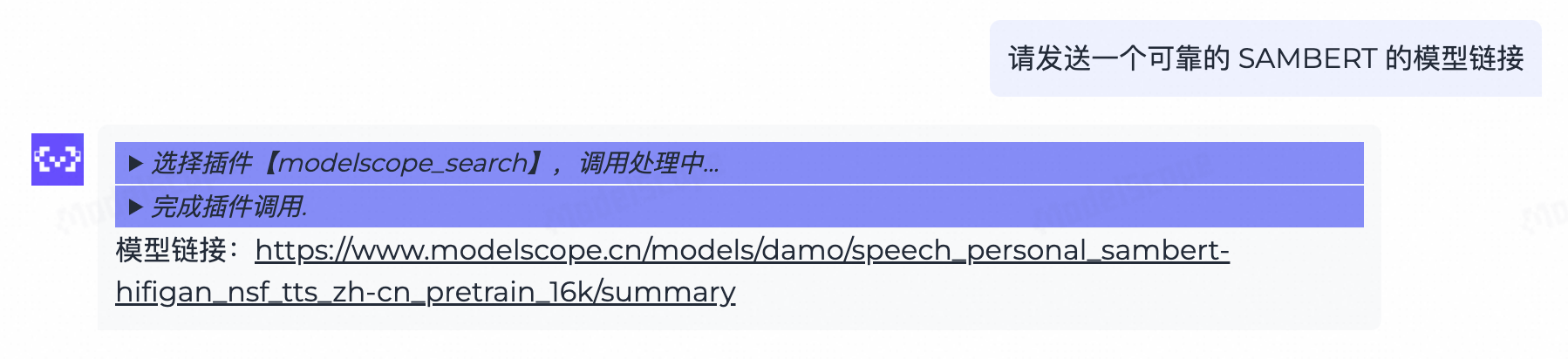
这个模型链接地址打开后可以看到:
3.2 ModelScope-Agent已集成的工具
ModelScope-Agent项目空间中集成了大量工具。
|
工具 |
工具地址 |
API-KEY配置 |
|
web_browser |
||
|
web_search |
||
|
code_interpreter |
||
|
amap_weather |
AMAP_TOKEN 需要在环境变量中进行配置 |
|
|
image_gen |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
qwen_vl |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
speech-generation |
MODELSCOPE_API_TOKEN 需要在环境变量中进行配置 |
|
|
video-generation |
MODELSCOPE_API_TOKEN 需要在环境变量中进行配置 |
|
|
text-address |
MODELSCOPE_API_TOKEN 需要在环境变量中进行配置 |
|
|
wordart_texture_generation |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
style_repaint |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
image_enhancement |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
此外,ModelScope-Agent框架还支持许多第三方工具的接入,如LangchainTool。
3.3 如何体验
你可以直接访问魔搭空间来体验ModelScope-Agent,如果你感兴趣,也可以下载代码在本地运行中的案例。
项目地址:https://github.com/modelscope/modelscope-agent/
4 Multi-Agent
4.1 什么是Multi-Agent
想象一下,你正在筹备一个盛大的生日派对。如果所有的事情——从挑选主题、发送邀请、装饰房间、烹饪美食到拍摄照片——都由一个人来完成,你可能会感到非常吃力,难以同时保证每项工作的质量。
现在,换成请多个朋友来帮忙。一个创意多的,负责想点子和发请柬;一个摄影技术棒的,负责拍照片;一个做饭好吃的,管做菜;还有个细心的,专门检查装饰,让现场美美的。每个人专注于自己最擅长的事情,不仅整体效率高,而且每个环节都做得更好。
在人工智能领域,这就是多智能体系统(Multi-Agent System)的概念。
你可能也发现了,当你让单个AI Agent全程负责写一篇文章,包括调研、撰写、和校对的时候,可能不是非常理想。
如果分成四个Agent,最终输出的文章质量会更好。
- 调研专家 (Research Specialist):
"我的工作是确保信息来源多样、准确,并整合成有用的资料库。"
- 内容创作者(Content Creator):
"我的使命是把整理好的信息转化成有逻辑、有深度的文章内容。"
- 语法检查者(Grammatical Checker):
"我的目标是确保文章的语言和逻辑没有任何错误;如果文章有问题,我会打回给内容创作者。"
- 校对专家(Proofreading Specialist):
"我的责任是将文章进行最终审核,确保其达到最高质量标准;如果文章有问题,我会打回给内容创作者。"
通过给每个Agent制定明确且专业的角色名称和职责描述,不仅可以提升它们的专业性,还能帮助它们更好地理解和配合各自的工作。
Agent之间可以互相指派任务,也可以是一个主Agent带着一系列从Agent协同工作。例如,主Agent可以在调研阶段给Research Specialist提供更明确的方向和关键词;在撰写阶段提供反馈,确保Content Creator的工作方向正确;最后经过各个步骤确认无误,主Agent才提交文章。
4.2 Multi-Agent项目示例
4.2.1 MetaGPT项目介绍
只需要一个prompt,你就可以组建一个软件开发团队,团队里每个成员都是一个大模型Agent,它们将自动分工合作,生成你需要的软件和配套文档。
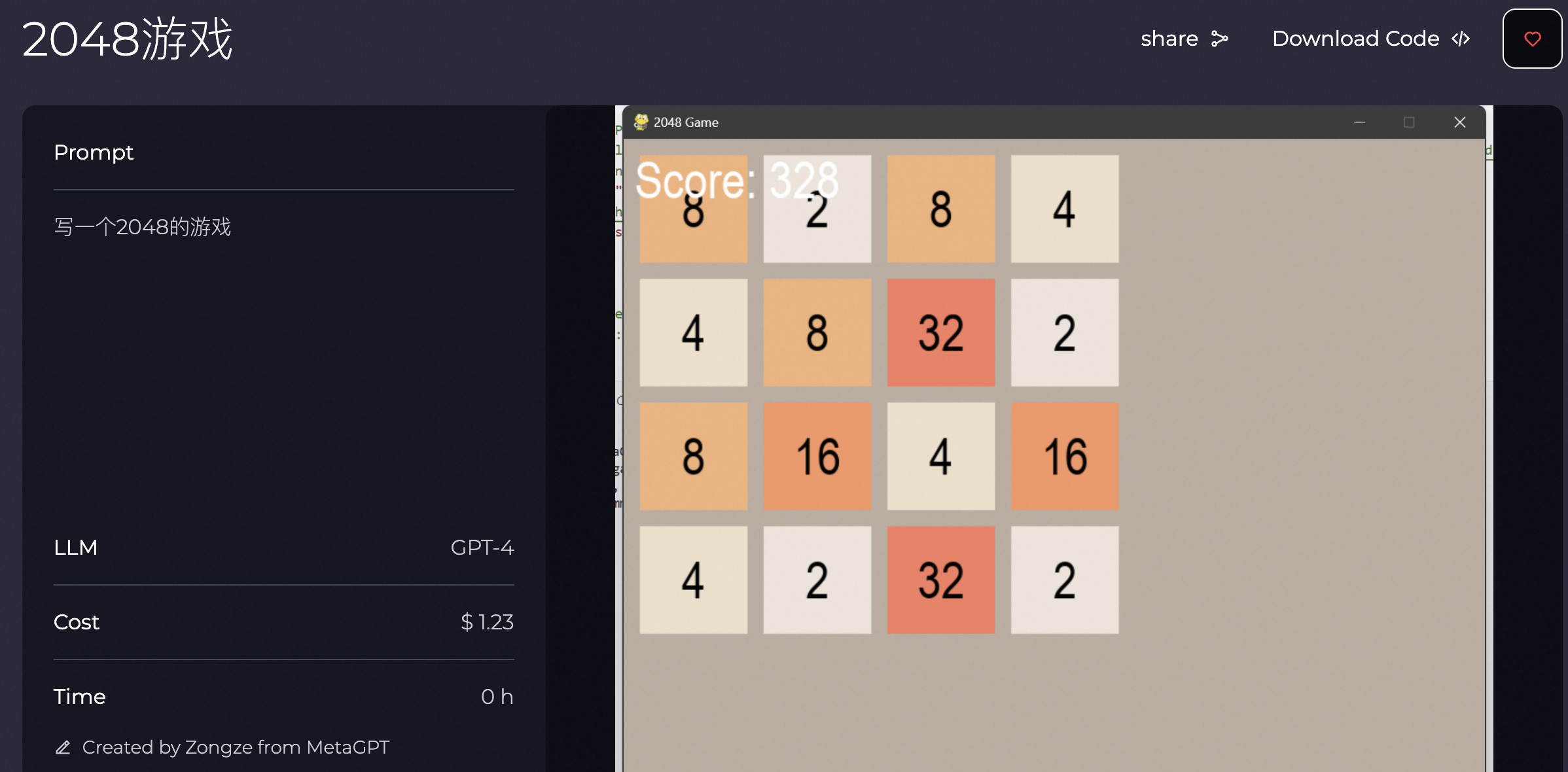
例如,只要用一个非常简单的prompt“写一个2048的游戏”,就能得到这样一个游戏。
同时还能得到由各个Agent产出的项目文件。
更多MetaGPT案例:https://www.deepwisdom.ai/usecase
MetaGPT文档:https://docs.deepwisdom.ai/main/en/guide/get_started/introduction.html
4.2.2 Agent协作Demo
MetaGPT官方Demo视频以“write a cli black jack game”为提示词,展示了各个Agent分工协作的过程。
下面用一张图片来介绍多个Agent之间的协作。
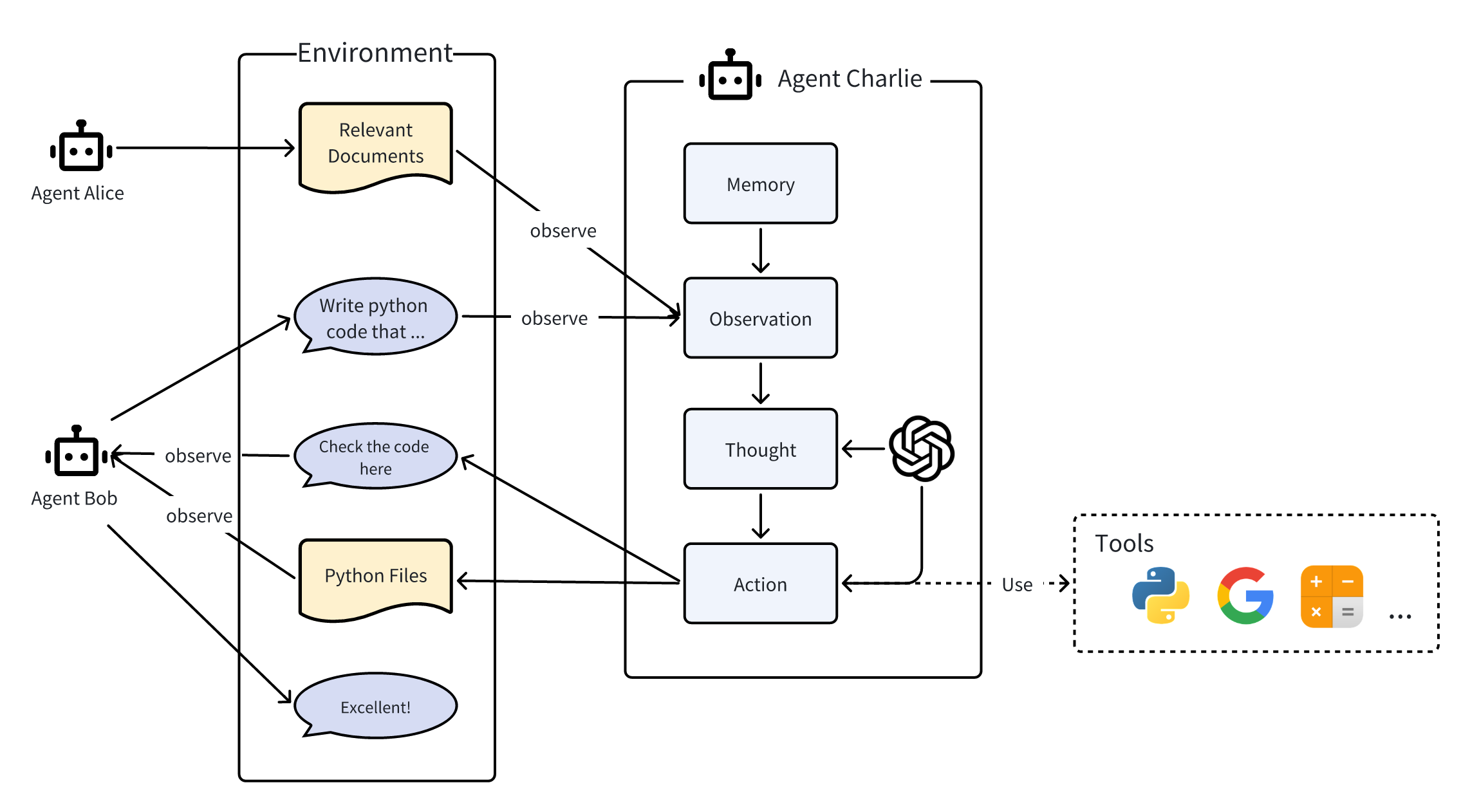
如图所示,这个多Agent协作的模式我们可以称之为“消息版”模式,接下来我们解释一下这个模式:
- 在工作环境中,三个智能体Alice、Bob和Charlie相互之间进行互动。
- 它们能够向环境(消息版)发布消息或它们的行为输出,而这些消息或输出会被其他智能体所观察到。
- 这里我们展示智能体Charlie的内部运作过程,这个过程同样适用于Alice和Bob。
- 在内部,智能体Charlie拥有各类组件包括:大规模语言模型(LLM)、观测(Observation)、思考(Thought)、行动(Action),其中思考和行动可以借助LLM得到强化。智能体在行动时可以使用工具。
- Charlie会观察来自Alice的相关文档以及Bob的需求,回忆起有用的记忆,思考如何编写代码,执行实际的编写动作,并最终公布其成果。
- Charlie通过向环境报告它的行动结果来告知Bob。Bob观察到后做出称赞。
4.3 使用多智能体开发平台-AgentScope

图:AgentScope项目插图
4.3.1 项目特点
阿里巴巴发布的AgentScope是一个创新的多智能体开发平台,旨在赋予开发人员使用大模型轻松构建多智能体应用的能力。AgentScope专注于多智能体开发,项目提供了丰富的句法工具、内置智能体和服务功能、用于应用演示和效能监控的用户友好界面、零代码编程工作站以及自动提示调优机制,极大地降低了开发和部署的门槛。
为了实现健壮性和灵活性并重的多智能体应用,AgentScope同时提供了内置及可定制的容错机制。此外,它还配备了系统级的支持,用以管理和利用多模态数据、工具及外部知识。AgentScope还设计了一个基于Actor的分布式框架,使得在本地与分布式部署之间轻松转换,并能自动进行并行优化而无需额外工作。凭借这些特性,AgentScope使开发者能够构建完全发挥智能体潜力的应用程序。
|
支持的本地模型部署 AgentScope支持使用以下库快速部署本地模型服务。 |
支持的服务
|
在能力上,AgentScope兼容LangChain、ReAct智能体、支持通过对话查询SQL信息、可以使用Llama3大模型、支持与GPT-4o模型对话、支持RAG智能体对话等多种能力扩展。AgentScope演示了狼人杀等多人游戏,以及分布式对话、分布式辩论、分布式并行搜索、分布式大规模仿真等多种分布式智能体系统。
4.3.2 支持的模型API
AgentScope提供了一系列ModelWrapper来支持本地模型服务和第三方模型API详见链接。
项目地址:https://github.com/modelscope/agentscope
4.3.3 样例应用
AgentScope可以用比较少的代码量开发出一个让智能体玩狼人杀游戏的应用,完整代码可以参考狼人杀游戏代码。把下面这个demo跑起来只需要几分钟,感兴趣的开发者可以自行尝试。(其他样例请参考项目文档)

图:AgentScope制作狼人杀游戏的对话效果
4.4【扩展阅读】其他开源Multi-Agent框架或项目
下面介绍更多的开源Multi-Agent框架或项目,感兴趣的话可以做进一步了解。
4.4.1 Camel AI
最早的多智能体框架,起先在多智能体方面只支持两个智能体一对一交互,目前项目开放了搜索增强RAG能力,可以开发具有角色扮演能力的RAG智能体。项目地址:https://github.com/camel-ai/camel。
4.4.2 AutoGen
微软的 AutoGen 是一个强大的工具,它能帮助我们轻松创造新一代的智能对话应用,这些应用基于多个虚拟角色之间的交流,而且不需要太多复杂的操作。它让管理、自动执行和改善这些高级对话程序的过程变得更加简单,同时让这些智能对话的表现更出色,并解决它们可能存在的问题。
想象一下,有了AutoGen,开发者就能像搭建乐高积木一样,设计出各式各样的对话场景。无论对话是自由流动的,还是需要很多不同的“虚拟助手”一起协作,也不管这些助手们是如何相互连接和交谈的,AutoGen都能搞定。
此外,AutoGen还展示了一系列已经做好的例子,这些例子覆盖了各种不同难度和领域的应用,证明了它能够灵活应对各种对话方式的需求。
更进一步,AutoGen还提升了这些智能对话背后的“思考”能力,也就是推理功能。它提供了许多好用的功能,比如让不同的接口协同工作更顺畅、存储信息减少重复计算,以及在遇到问题时能智能应对、根据情况变化选择最佳方案,甚至能让这些虚拟助手更好地理解和记忆之前的对话内容,从而提供更连贯的服务。
项目地址:https://microsoft.github.io/autogen/stable/
4.4.3 AgentVerse
该项目研究智能体和多模态学习开发,项目中提供了两个框架:解决问题和模拟器。该项目主要用于学术场景,可以模拟多种社会实验场景,如:NLP课堂、囚徒困境、软件设计、数据库诊断、Pokeman等等。
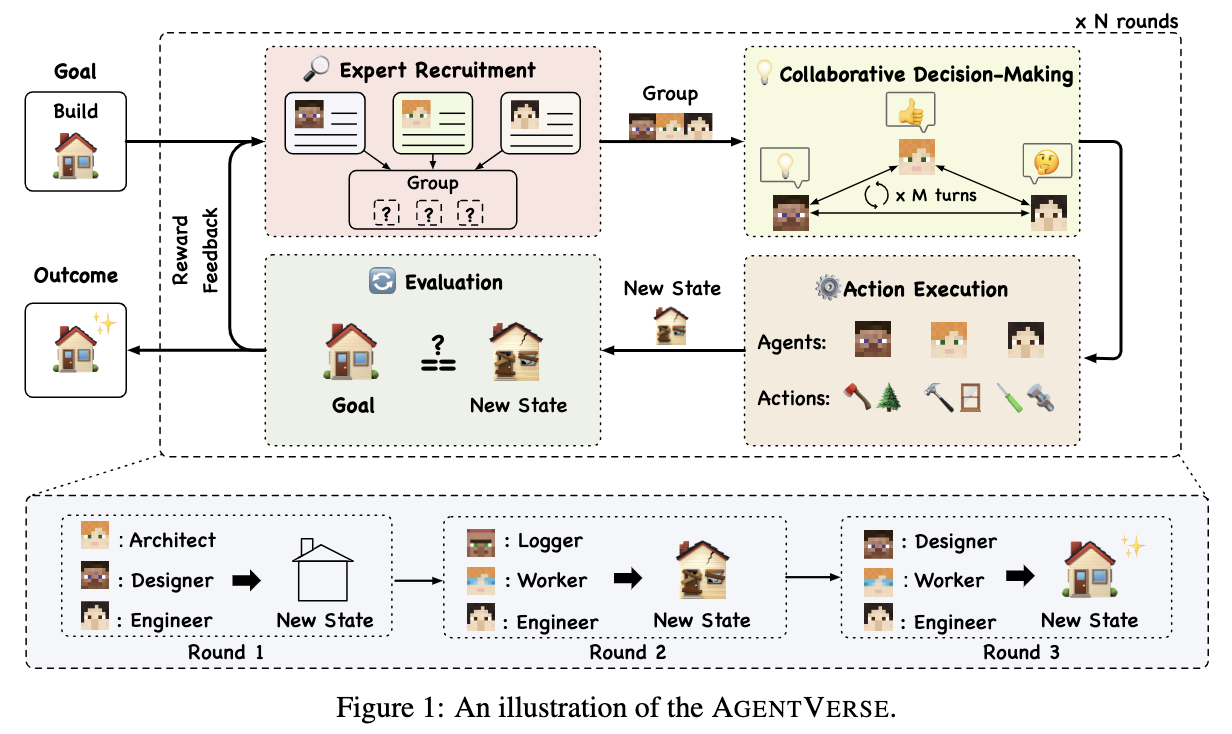
项目地址:https://github.com/OpenBMB/AgentVerse
4.4.4 斯坦福小镇
斯坦福小镇是一个多智能体社区的研究型项目,开发者探索构建智能体之间能否形成一定的社会关系。项目服务启动后,会首先对每个Agent的当日流程进行分层设计,然后按计划按时间点执行设计的任务。多个智能体之间一般是两两沟通的模式,一段时间内两个Agent之间可以进行多次沟通,每个角色在社区中的关系需要预先定义。斯坦福小镇有3人模式用于代码调试,也有25人模式用于正式的虚拟社区实验。
虚拟小镇的执行过程总体分为启动阶段、每小时规划阶段、事件执行阶段、对话规划阶段等等几个规划步骤。层层递进,Agent自主决策,组成一个完整的虚拟环境。项目用embedding向量存储作为Agent的记忆模块,来记录智能体一天中的经历,并在Agent对话时调用向量检索,召回相关信息。
项目地址:https://github.com/joonspk-research/generative_agents
5 不断完善大模型Agent系统
虽然大模型Agent为人们展示了无限的应用前景,但我们仍然可以不断完善Agent系统:
- 避免向大模型输入巨量信息
大模型仅支持有限长度的上下文,有人认为如果我们使用支持超长文本的大模型,我们就可以在使用时提供更多信息了。但是由于技术发展,我们越来越需要将历史信息、详细指令、API调用上下文、插件和系统响应信息等大量信息同时塞给大模型,这样做除了产生更大的调用成本和带宽消耗之外,还有可能降低有用信息被检索和解读的概率,导致大模型输出结果与用户的问题无关。因此,支持超长文本的大模型并没有给应用市场带来革命性的变化。所以,我们需要考虑优化提示词文字,精简信息内容,甚至压缩历史记忆文字量,从而提升大模型的准确率。
- 持续优化Agent规划能力
与人类相比,大模型Agent的规划能力还比较初级。大模型是从训练样本中学习事物之间的联系,并学会如何做规划的。在实际应用中,大模型做出的规划很可能需要先经过使用者的调整再做实施。在面对一个复杂任务时,大模型Agent会将任务分解为一系列长链路的步骤,我们可以设计一些方法衡量这些步骤是否还需要进一步拆解。当大模型按照步骤链条执行时,我们也需要设计自动化方案,观察执行链路中会不会出现前一个步骤累积下来的错误,执行过程是否需要终止。当然,我们也可以添加交互手段,让系统的使用者介入Agent的规划和执行,加以修正。
- 综合使用多种大模型
大模型Agent应用需要反复执行分析、识别、规划、决策、生成内容等任务,但是有些任务是可以使用小参数量的模型来完成的,并不需要把所有任务都交给参数量最大的模型来执行。因此,合理地分配任务,综合使用多种不同规格的大模型,可以降低系统运行的总成本。开发者可以根据任务难度,参考各规格模型的部署成本、计费方式来优化系统架构。例如,你可以参考阿里云百炼的最新计费方案和优惠信息等等。
[进度: 已完成]本节小结
在本小节中,我们了解到Agent能通过工具与外部世界交互,从“教你做”到“帮你做”,而且具备规划能力(任务拆解和自我反思)和记忆能力。我们还可以让多个Agent一起协作完成工作目标。
虽然当下的大模型Agent应用还有很多待完善的地方,但是如果你既懂业务,又懂得用大模型Agent,我们相信你一定可以让业务发生前所未有的变化。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号