
阿里云大模型 RAG微调 lora
回答。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解什么是提示词工程
- 获得更高质量的提示词的技巧
1. 什么是提示词工程
提示词工程(Prompt Engineering)就是研究如何构建和调整提示词,从而让大语言模型实现各种符合用户预期的任务的过程。就像跟AI沟通的艺术,为了让像Qwen这样的大语言模型更好地理解你的需求,你需要清晰地描述你的需求,提供必要的背景信息,明确告诉AI你想让它做什么。就像跟人沟通一样,你需要不断调整你的表达方式,直到AI理解你的意思,并给出你想要的答案。
提示词工程包括以下关键步骤:

本课程向您介绍构建提示词的各种技巧。纸上得来终觉浅,绝知此事要躬行。学习这一章节时,你可以访问通义千问大语言模型,边学习边实践。

2. 提示词技巧
为了引导大模型按照我们的要求来完成各项任务,作为使用者,我们需要不断调整提示词,构建有效的提示词,从而不断地提升大模型的表现。接下来,我们来学习一些构建提示词的技巧,并进一步掌握提示词工程的框架。
我们先从一个简单的例子入手看看如何优化提示词,首先我们调整一下课程第一个示例的提示词:
|
提示词: 评价一下最近刚上映的电影 输出: 我无法完成这项任务,因为我目前无法访问实时数据或外部信息,包括最近上映的电影评价。如果您能提供具体的电影名称,我可以尝试根据我最后更新时的知识库提供一般性的电影分析或讨论电影评价的角度。 |
上面这个例子的问题是:我们没有能够让 LLM 理解到底要评价哪部电影,尽管大语言模型经过了海量数据的预训练,并获得了理解和生成文本的能力,但不同于人类交流时能够通过语气、非语言线索和背景知识来理解对方的意图,大语言模型仅能够根据输入的文本提示进行操作,还是可能无法理解并响应。
接着,我们基于上面的例子进行优化:
|
提示词: 请结合《星球崛起》整个系列评价最近刚刚上映的电影《猩球崛起:新世界》 输出: 《猩球崛起:新世界》作为《星球崛起》系列的最新篇章,延续了这一科幻经典IP的传奇,尽管它…… 在角色刻画上,《猩球崛起:新世界》似乎得到了积极的反馈,尤其是对于反派和配角的描绘…… 对于老粉丝而言,这部电影可能没有提供必须观看的新鲜理由,但对于新加入的观众…… 总体而言,《猩球崛起:新世界》在保持系列精髓的同时,尝试了某种程度的软重启,为新老观众都提供了值得一看的科幻体验。虽然可能在创新性上有所欠缺,但它在情感深度、视觉震撼以及对未来叙事线索的铺设上都交出了满意的答卷。 |
通过对比可以发现,通过在提示词中提供明确的用户需求,大语言模型的输出质量更好,更符合用户预期,接下来我们可以一起来学习构建有效提示词的更多技巧。
2.1 直接提问
直接提问,也称为零样本提示(Zero-Shot Prompting),即不给大语言模型提供案例,完全依靠 LLM 理解和处理能力完成任务。前文给的提示词例子,都属于直接提问。目前大部分开源和商用的大语言模型已经经过了大量的预训练和指令调试,能够很好的理解并响应用户的直接提问。适用于目标明确、问题简单、答案确定且唯一等场景。
直接提问时,可遵循以下原则:
- 简洁:尽量用最简短的方式表达问题。过于冗长的问题可能包含多余的信息,导致模型理解错误或答非所问。
- 具体:避免抽象的问题,确保问题是具体的,不含糊。
- 详细上下文:如果问题涉及特定上下文或背景信息,要提供足够的详情以帮助模型理解,即使是直接提问也不例外。
- 避免歧义:如果一个词或短语可能有多重含义,要么明确其含义,要么重新表述以消除歧义。
- 逻辑清晰:问题应逻辑连贯,避免出现逻辑上的混淆或矛盾,这样才能促使模型提供有意义的回答。
为大语言模型提供如下不同的提示词,得到的答案质量会有明显差距。
|
不好的提示词 提示词: 苹果好看吗? 输出: 不好意思,我不清楚你所指的“苹果”具体指的是什么,水果还是电子设备。 |
好的提示词 提示词: 输出: 新鲜。 |
然而,大语言模型给出的答案有时候也不是固定的,直接提问效果在很大程度上取决于所使用的模型的理解能力和泛化能力,它无法很好地处理复杂、模糊或多义性的问题,当需要较深入的背景知识或分析时,可能无法准确了解用户的真正意图。我们可以尝试在提示词中增加示例样本、分配角色、提示写作风格/输出格式或构建思维链和思维树拆解复杂任务等方式解决。
2.2 增加示例
在提示词中提供少量(通常几个或几十个)示例,也称为少样本提示(Few-Shot Prompting),以帮助模型更好地理解任务要求和期望输出。比如:
- 让 LLM 跟随我们所要求的规范、格式、概念、文法、语气进行输出。
- 提供进一步推理的参考,比如让大模型学会数学运算或按照示例方式进行逻辑推理。
以下示例中,我们分别在提示词中增加示例和不增加示例,就会得到以下不同的答案。
|
未增加示例 提示词: 任务:请根据以下电影评论,判断其情感评价(正面、负面或中性)。 待分类评论:这部电影音乐动人,但剧情略显平淡。 输出: 情感评价:中性 |
增加示例 提示词: 要求:请根据以下电影评论,判断其情感评价(正面、负面或中性)。 示例1:这部电影剧情引人入胜,但特效炸裂。情感评价:正面 示例2:虽然这部电影剧情单调,但特效却非常炸裂。情感评价:负面+正面 示例3:这部电影不好不坏。情感评价:中性 待分类评论:这部电影音乐动人,但剧情略显平淡。 输出: 在英文缩写比较多的专业技术文档翻译场景,我们可以尽可能地为 LLM 提供一些缩写的翻译示例,然后再让 LLM 完成后续的翻译工作:
值得一提的是,这种方式比较适合翻译量不大,且示例的数量可穷举的场景,可以轻量、快速地完成翻译工作。但是当需要成千上万的专业术语词条示例辅助翻译的场景,这种方式就不够了,也不够方便,我们可以让大语言模型接入专业的术语库,来增强大语言模型的能力,也即检索增强生成(Retrieval-Augmented Generation),简称RAG,我们在后续课程会展开讲解。
示例的质量和数量会直接影响回答的结果,增加示例时可参考以下技巧:
2.3 分配角色赋予模型一个具体的角色或身份,如“作为经验丰富的营养师”,来引导模型在特定角色视角下生成回答。 分配角色适用以下场景:
下面的例子中,让大语言模型分别扮演酒店评论家和小学生,来执行“酒店评价”的任务,从而得到不同风格的答案。
分配角色引导模型生成符合特定情境和对话逻辑的内容,可遵循以下技巧:
2.4 限定输出风格/格式大语言模型非常善于撰写论文、文章等内容,不过如果我们仅仅简单地告诉大语言模型一些宽泛的提示,比如:
大语言模型有可能会生成枯燥、平淡、空洞的内容,这些内容往往与我们期望的结果有较大的出入。 我们可以在提示词中增加“风格”的限定,比如当我们明确需要大语言模型帮我们写一篇幽默的简短小说,就可以尝试将上面的提示词改写为如下形式:
为了更好的限定“风格”,准确引导模型写出符合需求的内容,下面我们介绍一些推荐的技巧:
我们还可以进一步对内容的输出格式进行限定:
当然,我们还可以让大语言模型帮助我们生成限定内容风格和格式的提示词:
2.5 拆解复杂任务把一个复杂的任务,拆解成多个稍微简单的任务,让大语言模型分步来思考问题,称为思维链(Chain-of-Thought Prompting, CoT)提示,这种方式可让大语言模型像人类一样逐步解释或进行推理,从而极大地提升 LLM 的能力。与前面介绍的标准提示不同,该方法不仅寻求答案,还要求模型解释其得出答案的步骤。 下图展示了标准提示与思维链提示的对比。
标准提示只给出了答案,而且答案明显是错误的,而思维链提示会展开推理过程,通常通过思维链提示的方式会产生更为准确和可校验的结果。
上面思维链提示中没有给 LLM 提供问题解析示例,所以也可以称为零样本思维链(Zero-shot CoT),相对应地在增加了示例后就变成了少样本思维链(Few-shot Cot)。
有时 LLM 通过零样本思维链可能会得到错误的答案,可以通过增加示例的方式,即少样本思维链,帮助 LLM 理解相关任务并正确执行,如下面的例子中,明显在使用零样本思维链来分析问题后还是获得了错误的答案:
下面的改进例子中,我们尝试给 LLM 更多相似问题的分析示例后,LLM 可以给出更为精简且正确的答案:
3. 提示词框架3.1 提示词框架的概念前面的学习中,我们知道了编写提示词的基础原则包括:简单、明确、详细,也学习了零样本提示、少样本提示、分配角色、提示写作风格、限定输出格式等技巧,这里我们将重新审视一个提示词是如何构成的,实际上提示词可以包含以下任意要素: 指令 Instruction:需要模型去做什么,如回答某个问题、撰写某种类型的文章或按照特定格式进行总结。指令应该简洁、明确,确保 LLM 能够理解任务的目标和要求。 背景信息 Context:背景信息可以包括任务的背景、目的相关的各类信息,还可以为 LLM 设置角色背景、观点立场等信息,LLM 将在此背景下进行回应或生成文本。 参考样本 Examples:与解决用户问题相关的示例,比如通过少样本提示的方式帮助 LLM 更好理解如何处理指令。 输入数据 Input Data:用户输入指令和要求,比如用什么语气,生成多少字的内容。 输出指示 Output Indicator:指定输出的类型或格式,我们可以给出限定关键词、限制条件或要求的输出格式/方式(如表格),也可以避免无关或不期望的信息出现。
结合上述要素,我们可以根据任务的复杂度来设计提示词,具体有以下几种情况:
3.2 提示词框架示例下面是一个包含了“背景信息”+“指令”+“输出指示”的提示词示例:
我们来拆解下这个示例: 背景信息:【背景知识:“阿里云...资源付费”】 指令:【请参考如上背景知识回答如下问题】 输入数据:【问题:阿里云弹性容器实例 ECI 是用来运行什么的?】 输出指示:【回答:分别使用中文和英文回答】 这个例子是为了更好的展示提示词的关键要素,一般来说,我们在熟练掌握提示词的使用技巧后,不会如此显性机械的使用这种格式,比如我们可以改写如上的例子并向大语言模型提问:
这个例子中我们给出了上下文信息、指令、以及要求的输出形式(中英文),它们没有像前面例子中显性的存在,这种方式对于 LLM 来说往往也可以很好的理解并执行任务。
如果你希望让大模型完成相对复杂的任务可以通过以下方式进行处理:
3.3 常见提示词框架及场景以上章节讲解了提示词框架,掌握提示词框架,可以用更精准、高效的指令来使用大模型。以下有几种常见的提示词框架,适用于不同的业务领域,供大家参考,你可以根据自己的业务需要来设计提示词。
4. 推理模型前面所讲的提示词技巧和提示词框架可以广泛适用于通用大模型(如Qwen2.5-max、GPT-4、DeepSeek-V3),这类模型面向通用对话、知识问答、文本生成等广泛的场景。除了通用大模型,目前还有一类专门为“推理”设计的模型——推理模型。 4.1 什么是推理模型?推理模型通常指专门优化用于逻辑推理、问题解决、多步推断等任务的模型(如DeepSeek-R1、o1),它们通常在数学解题、代码生成、逻辑分析等方面有更好的表现。 与通用模型相比,推理模型拥有更强的逻辑能力,因为它经过了大量的专项训练,能够更好地理解复杂的问题,并且在解答时更有条理。但并不是说就一定比通用模型更好,两种模型都有各自的应用场景,下表从一些典型维度对这两类模型进行了对比:
你可以通过如下方式体验推理模型:
推理模型还是通用模型?如何选择?以下是一些推荐:
当然你还可以在你的应用中结合使用两种模型:使用推理模型完成Agent的规划和决策,使用通用模型完成任务执行。
4.2 如何有效地提示推理模型?推理模型在面对相对模糊的任务也能给出详尽且格式良好的响应。因此,使用本节前面提到的一些提示词技巧(如指示模型“逐步思考”)可能反而限制了模型的推理。下面列举了一些适用于推理模型的提示技巧:
5. 延伸拓展尽管优化提示词是提高大语言模型回答质量的有效手段,但由于大模型的泛化、认知局限、预训练数据可能包含偏见、不能做出响应等局限,即使是最精心设计的提示词,也可能无法引导模型提供完全准确或全面的答案,特别是在面对复杂或未见先例的问题时。在后面的学习中,我们将了解一些解决上述问题的技术手段,如 RAG、微调等。
[进度: 已完成]本节小结在本小节中,我们探讨了如何优化提示词来提升大模型的回答质量。提示词是人与模型沟通的桥梁,就像与人沟通一样,输入给大模型的提示词也需要清晰、具体、明确。同时,我们可以通过直接提问(零样本提示)、增加示例(少样本提示)、分配角色、通过思维链或思维树拆解复杂任务等方式来优化提示,尽可能发挥大模型强大的作用,使其输出更符合用户意图的回答。
[Done]评价反馈 |





[高铁]前言
试想一下,你们公司对客户发起了一次产品调研,由于初期问卷设计不完善,你的任务是从收回的问卷中统计出用户认为哪些方面有待改进,比如:价格过高、售后支持不足、产品使用体验不佳等。如果只有 10 多份问卷,你还可以通过人工阅读,或者一次性输入给大模型帮你分析。但如果你面对的是 1 万多份问卷,上述方式就很难应对了。借助大模型服务的 API 可以很好应对这一问题。在本章节,我们将学习如何借助大模型服务的 API 来自动地处理一批任务。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解如何借助大模型服务的 API 来自动地处理一批任务
- 思考和发现你的业务可以借助大模型提效的机会
1 借助通义千问 API 自动完成一批文本处理任务
需求介绍:产品需要对客户发起一次产品调研,你的任务是统计出用户认为产品哪些方面有待改进,比如:价格过高、售后支持不足、产品使用体验不佳等。
现状:收集到1万多份主观反馈,并未结构化。
难点:要求在1天内做出分析。
在这样的情况下,借助大模型服务的 API 可以大大简化和加速文本处理的任务。你可以通过一段简单的代码来解决这一问题:
from langchain_community.llms import Tongyi
# 创建一个Tongyi类的实例,使用模型 'qwen-max',你也可以将使用其他模型,比如将 qwen-max 替换为 qwen2-72b-instruct
llm = Tongyi(model_name='qwen-max')
# 使用实例的方法 invoke 调用模型服务,传入提示词
result = llm.invoke("""你需要对用户的反馈进行原因分类。
分类包括:价格过高、售后支持不足、产品使用体验不佳、其他。
回答格式为:分类结果:xx。
用户的问题是:性价比不高,我觉得不值这个价钱。""")
print(result)需要注意的是,运行这段代码前,需要先开通阿里云大模型服务平台百炼,然后在百炼上获取API Key 用于调用通义千问 API,最后将API Key配置到环境变量。
为了便于缺少代码基础的读者理解,这里我们使用了 langchain 框架来减少代码量,所以运行代码前你也需要安装依赖: 。
如果希望使用其他模型,你可以替换代码中的 qwen-max 值,更多 model_name 的取值可以参考百炼的模型调用。
为了能够处理一批反馈,你可以考虑调整一下代码,从 Excel 文件中读取反馈并进行分类,最后代码会类似这样:
import os
from openpyxl import load_workbook
from langchain_community.llms import Tongyi
llm = Tongyi(model_name='qwen-max')
# Excel文件路径
file_path_feedback = 'data/file_path_feedback.xlsx'
wb = load_workbook(file_path_feedback)
sheet = wb.active
for row in sheet.iter_rows(values_only=True, min_row=2):
feedback = row[0]
result = llm.invoke(f"""你需要对用户的反馈进行原因分类。
分类包括:价格过高、售后支持不足、产品使用体验不佳、其他。
回答格式为:分类结果:xx。
用户的问题是:{feedback}""")
print(feedback,result)上面的代码从路径为 data/file_path_feedback.xlsx 的 Excel 文件中逐行读取了用户的反馈,然后借助通义千问 API 得到分析结果,最终打印了出来。

如果你没有编程基础,不知道如何编写代码来实现需求,没有关系,可以召唤通义灵码来帮忙。通过自然语言描述,通义灵码能够将需求转化为代码。下面我们来演示流程。
- 为了简化流程,可以使用阿里云函数计算FC来调用通义灵码。你可以通过我们准备好的模板来创建一个函数计算应用作为环境,函数计算控制台上的在线 IDE 集成了通义灵码插件,你可以基于该环境来快速体验通义灵码的能力。
- 如果你想在本地编程环境运行通义灵码,可以参考下载通义灵码
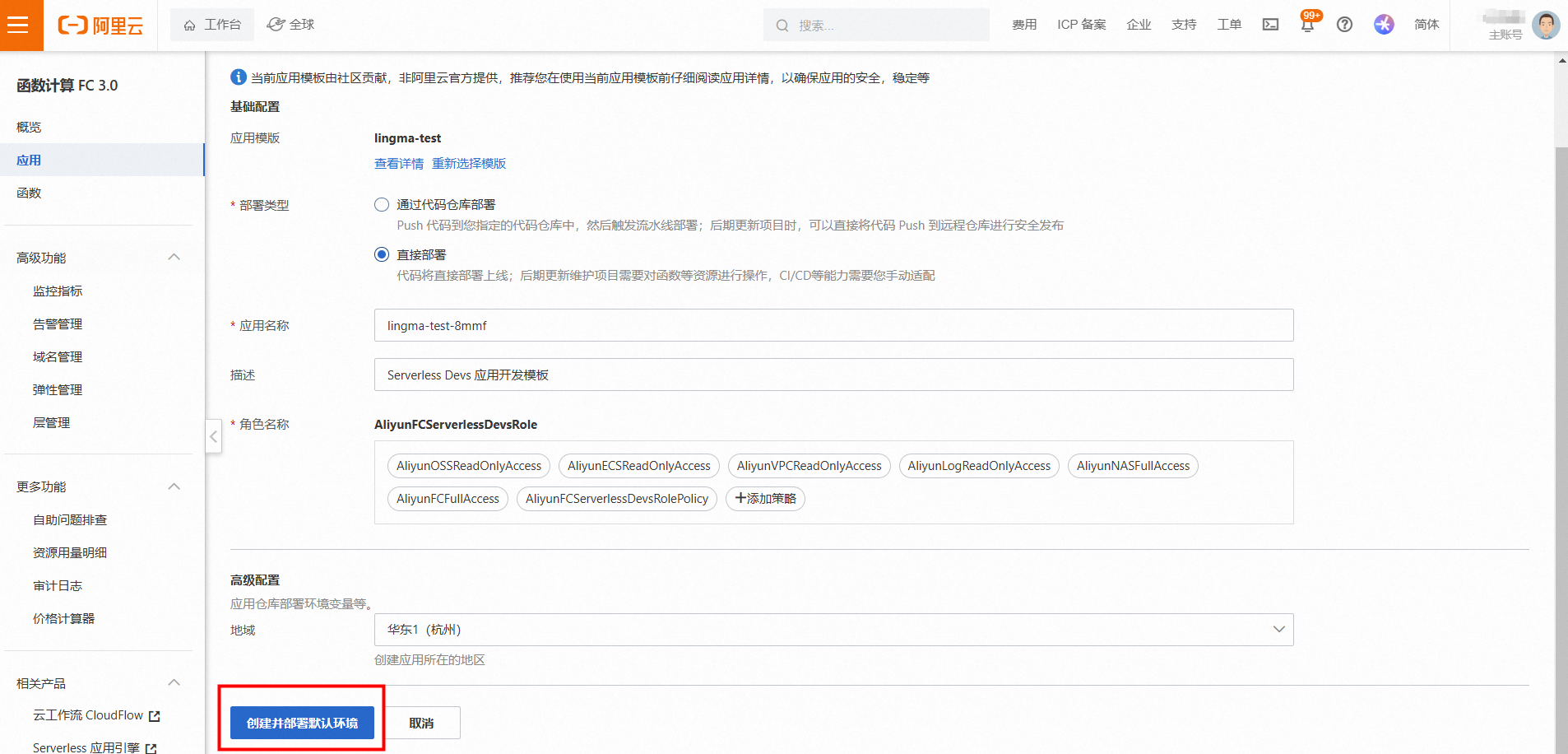
- 首先请点击模板,然后参考下图选择【直接部署】,然后点击【创建并部署环境】。
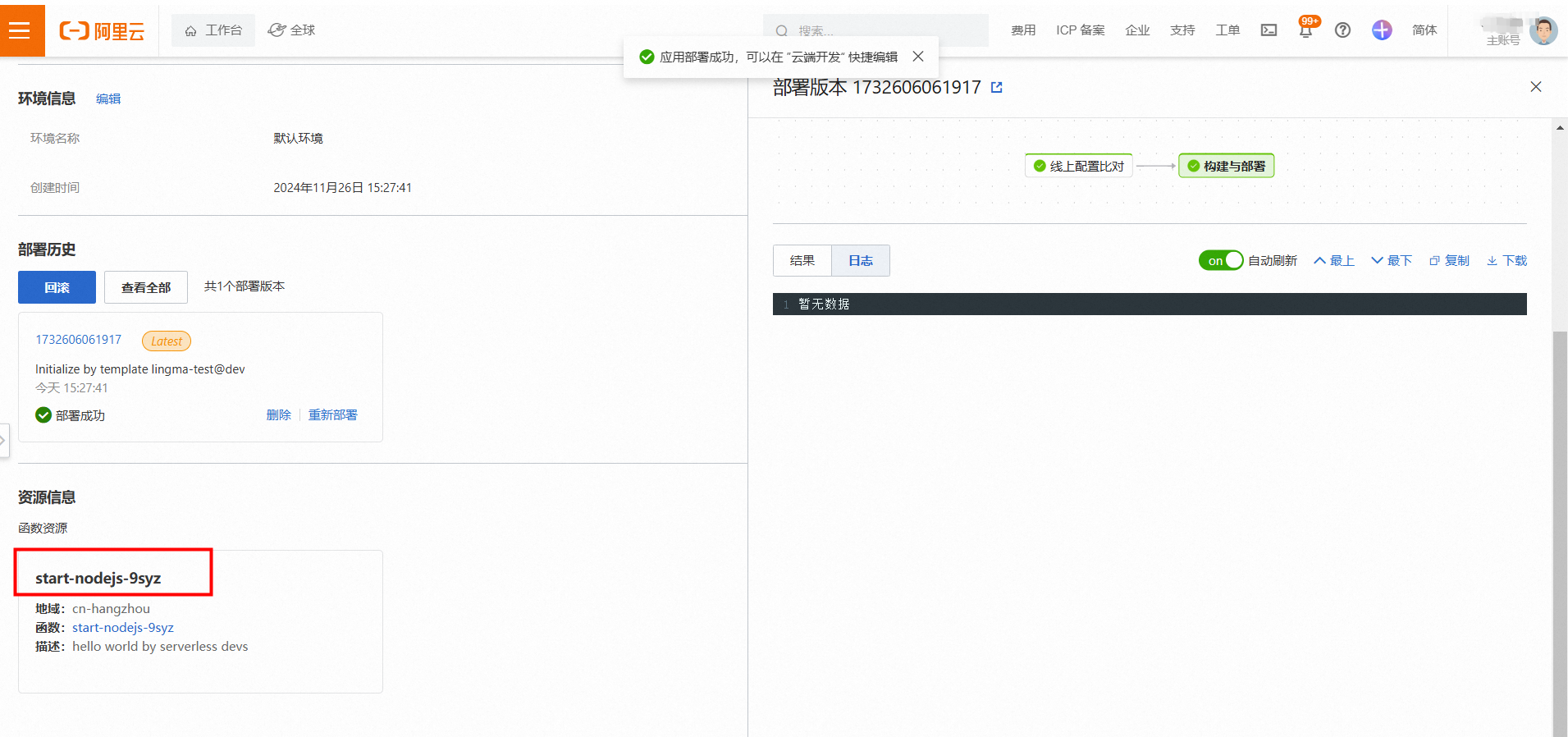
- 待环境创建完成后,单击函数进入编程环境。
- 进入代码编辑器界面后,可以新建 main.py 文件。然后点击顶部的【Terminal > New Terminal】,并在命令行中输入 来安装相关依赖。
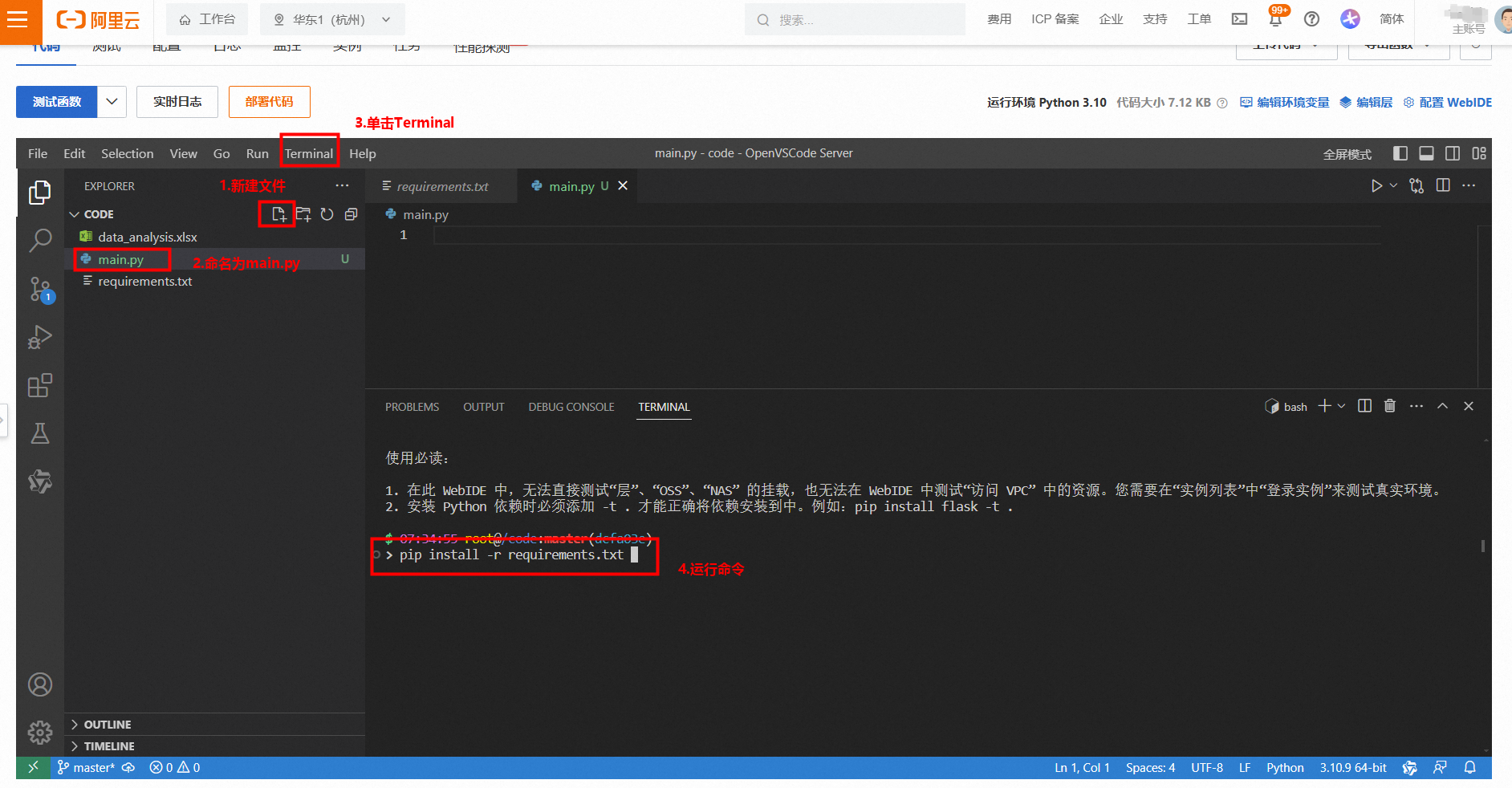
- 接下来,你就可以使用通义灵码组件,输入提示词。
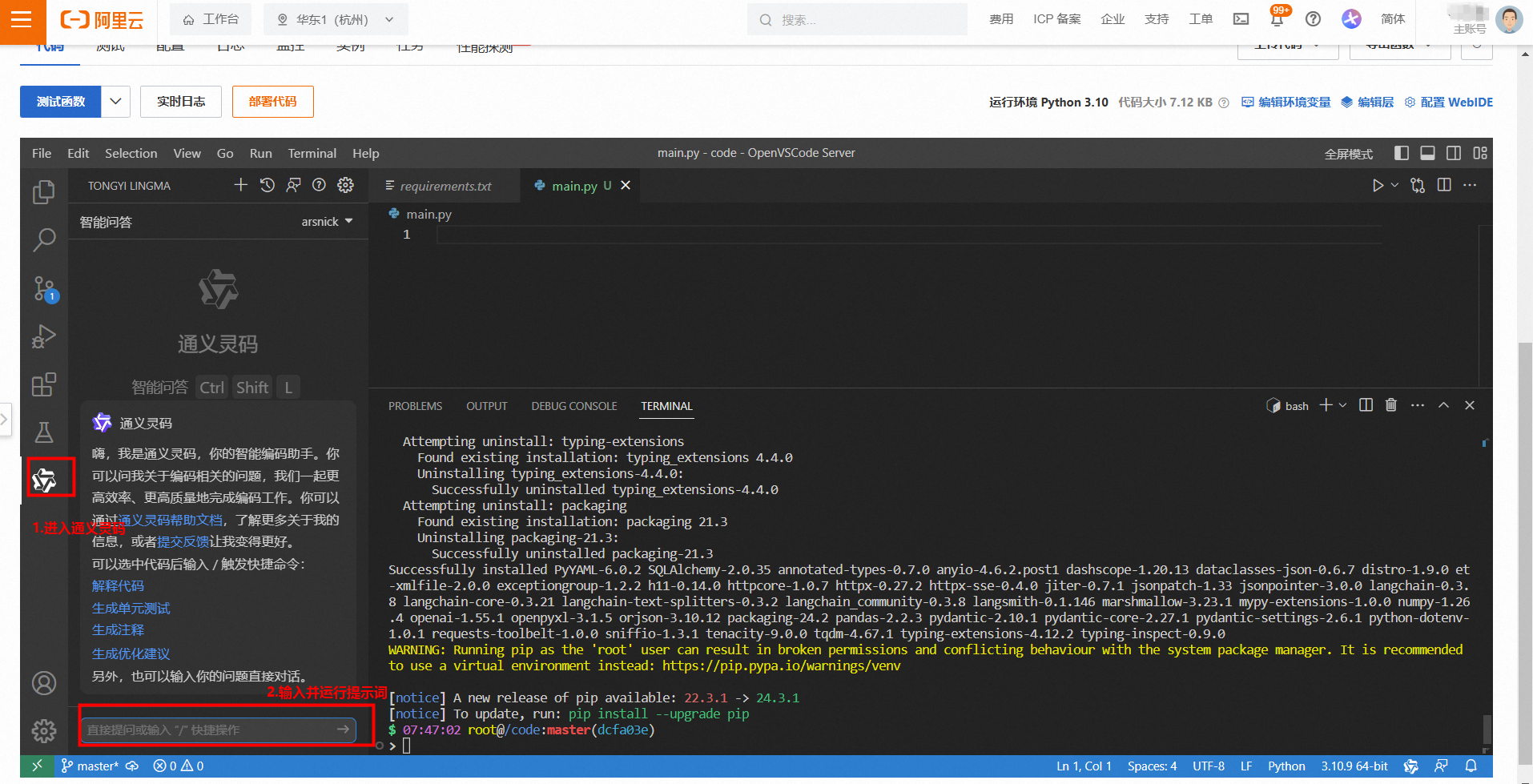
由于训练数据时效性,通义灵码可能无法准确知晓最新的API,可以给到通义灵码一些代码参考,往往可以更好地达成目标。
参考代码来自:首次调用通义千问API,记得替换API-Key。
- 通义灵码写好代码后,你可以将代码内容复制到 main.py 文件中。 然后记得将 API Key。 最后就可以在命令行中执行 运行通义灵码输出的代码,查看运行结果。
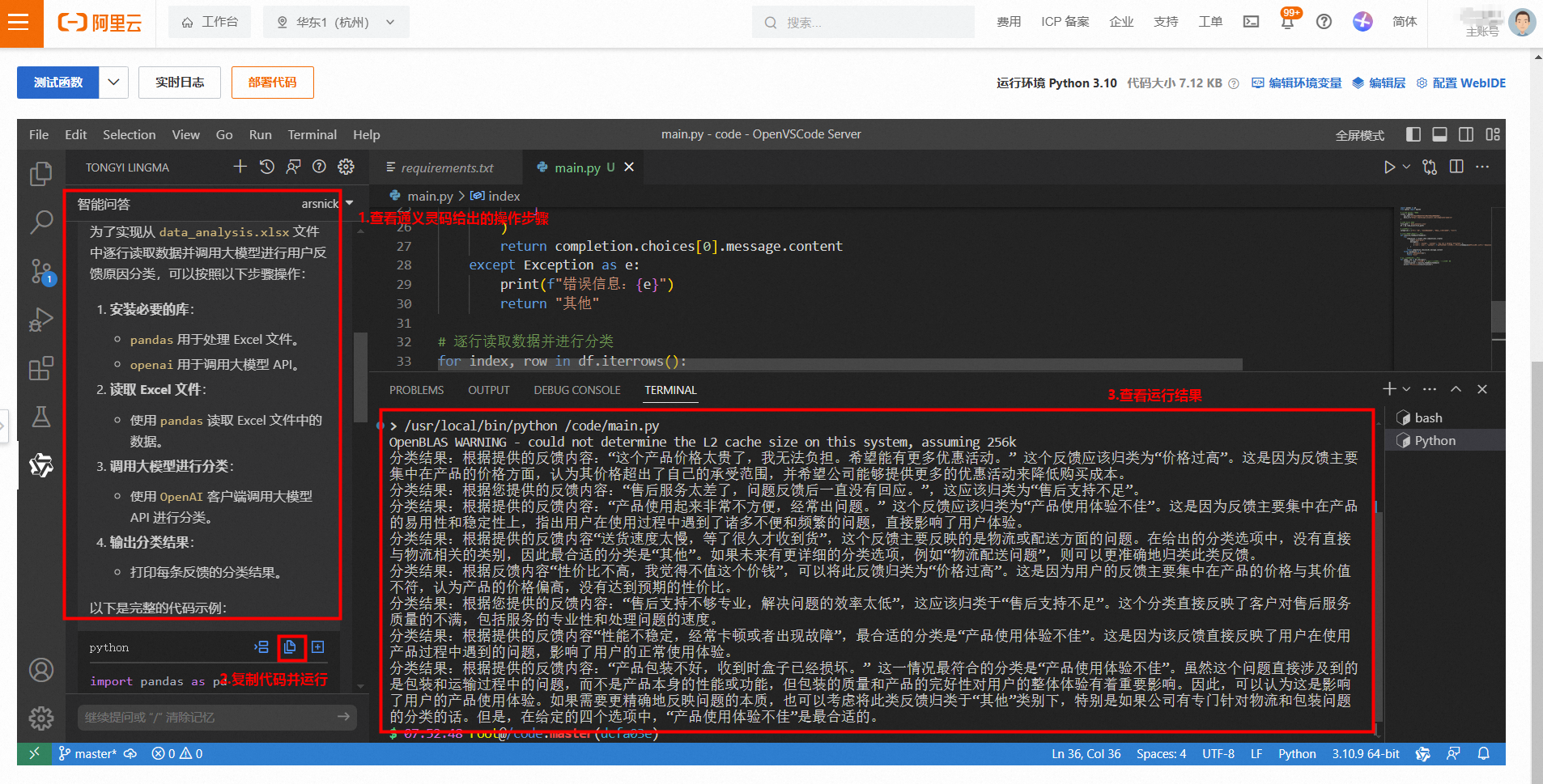
通义灵码输出的代码可能不会一次性有效,这时候可以调整提示词,多尝试几次。
通过本小节的内容,想必你已经了解如何调用通义千问API处理文本任务,哪怕你对编程知之甚少,也可以借助通义灵码来帮助你达成目标。
如果你所在的团队有专业的技术人员,那么在了解了大模型服务的API能力后,你也可以直接向技术人员提出需求以及建议实现方法,这能让技术人员更快地帮你编写代码并运行程序解决这些问题。
如果你仍然希望掌握如何运行这些代码,这里有一份入门级大模型服务的 API 教程或许能帮助到你。
2 阿里云上大模型服务的 API 调用
- 阿里云上提供了按量付费、开箱即用、多种参数规模的通义千问、开源大模型服务的 API。在满足业务需求的前提下,模型的参数规模越小,其API调用速度更快、成本更优。而参数规模越大,则能够应对更多复杂的业务场景。 更多细节内容可以参考模型调用。
- 你可以通过 通义千问-VL 视觉理解的能力实现拍照改作业之类的应用。

[进度: 已完成]本节小结
本小节通过一个案例为你介绍了如何在代码中集成大模型服务的 API 实现复杂的业务场景,帮助你更好理解使用程序来调用大模型的能力。
除了批量的文本处理任务外,也可以和其他算法模型结合起来使用处理更复杂的任务,比如可以使用声音转文字类的模型将客服电话记录转成文字,再借助大语言模型实现客服质检。
你也可以充分发挥想象力,在你的业务中找到可以和大模型结合的契机,实现系统的智能化,提升组织的工作效率。
- 待环境创建完成后,单击函数进入编程环境。
你已经熟练使用大模型的 API 来自动处理各种批量任务。不过,你可能也发现,并不是所有任务大模型都能完美解决。例如,当你给大模型一批小学难度的计算题,比如393乘以285,它竟然给出了错误答案。就像不擅长数学的人可以使用计算器来解决复杂的算术问题一样,大模型也可以借助插件这种工具来解决它原本难以解决的问题。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解大模型插件的使用
- 学习大模型插件原理及开发自定义插件
1 什么是插件
大模型插件是一种软件组件,它们设计用于增强和扩展基础大模型的功能。如网络搜索、视觉生成、语音合成等。
典型的插件包括:
- 基础工具,如计算器、时钟、天气信息、股票行情
- 可以让用户获得实时性消息的插件,比如体育赛事报道、实时、热点新闻
- 可以为模型拓展更多能力的插件,比如图片生成、语音合成、代码解释器
企业内部技术团队也可以定制开发大模型应用服务插件,比如通过飞猪开放平台的API查询酒店信息、预订酒店住宿及机票等,为公司员工提供便捷的差旅服务支持。
2 插件演示
大语言模型在数学计算方面并不擅长,在回答稍微复杂的数学问题时往往无法输出准确的结果。
尝试提问393x285,输出结果是错的。

注:正确答案是112005。
即使让大模型通过编程来实现,输出结果也是错的,因为它并没有真正地运行代码。

这个时候,我们可以给大语言模型添加插件,比如计算器。
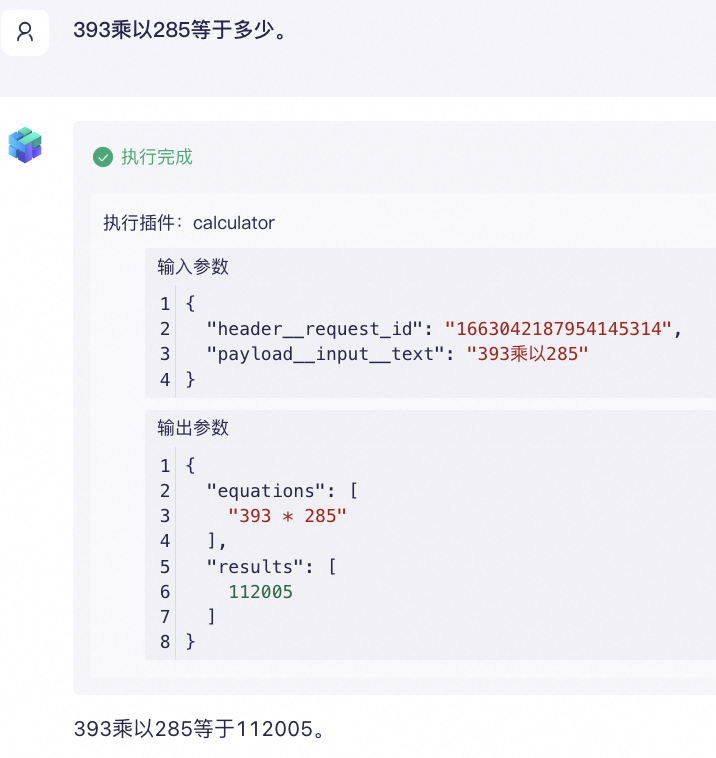
可以看到,输出结果是准确的,这是因为大模型借助计算器插件进行了实际运算。
换一个插件,这次给大模型添加一个代码解释器插件,看看计算的结果。
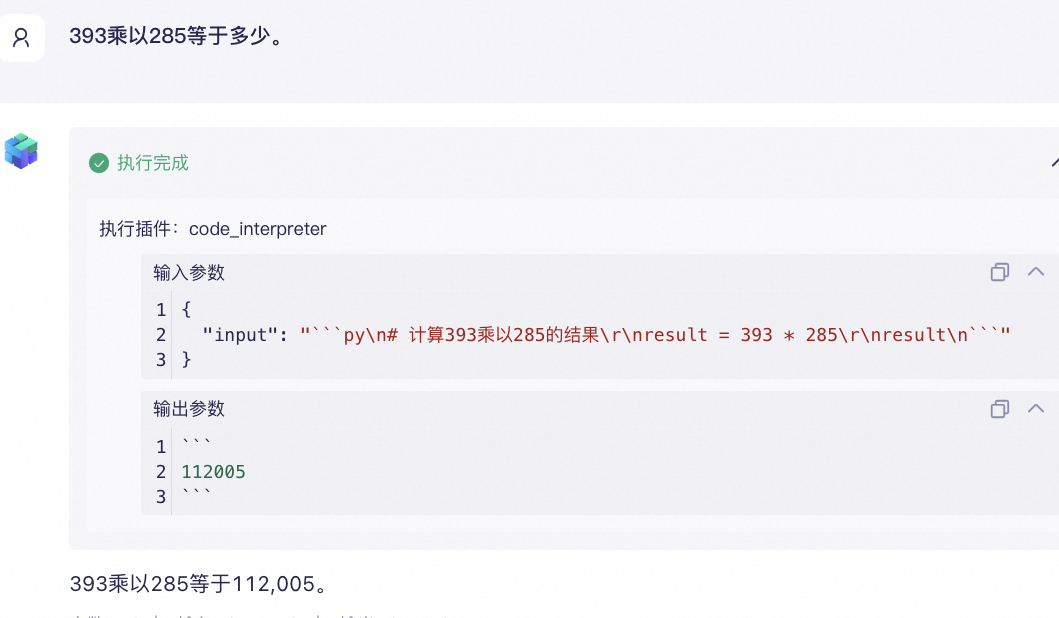
可以看到,结果也是准确的,这是因为大模型通过代码解释器真正地运行了python代码。
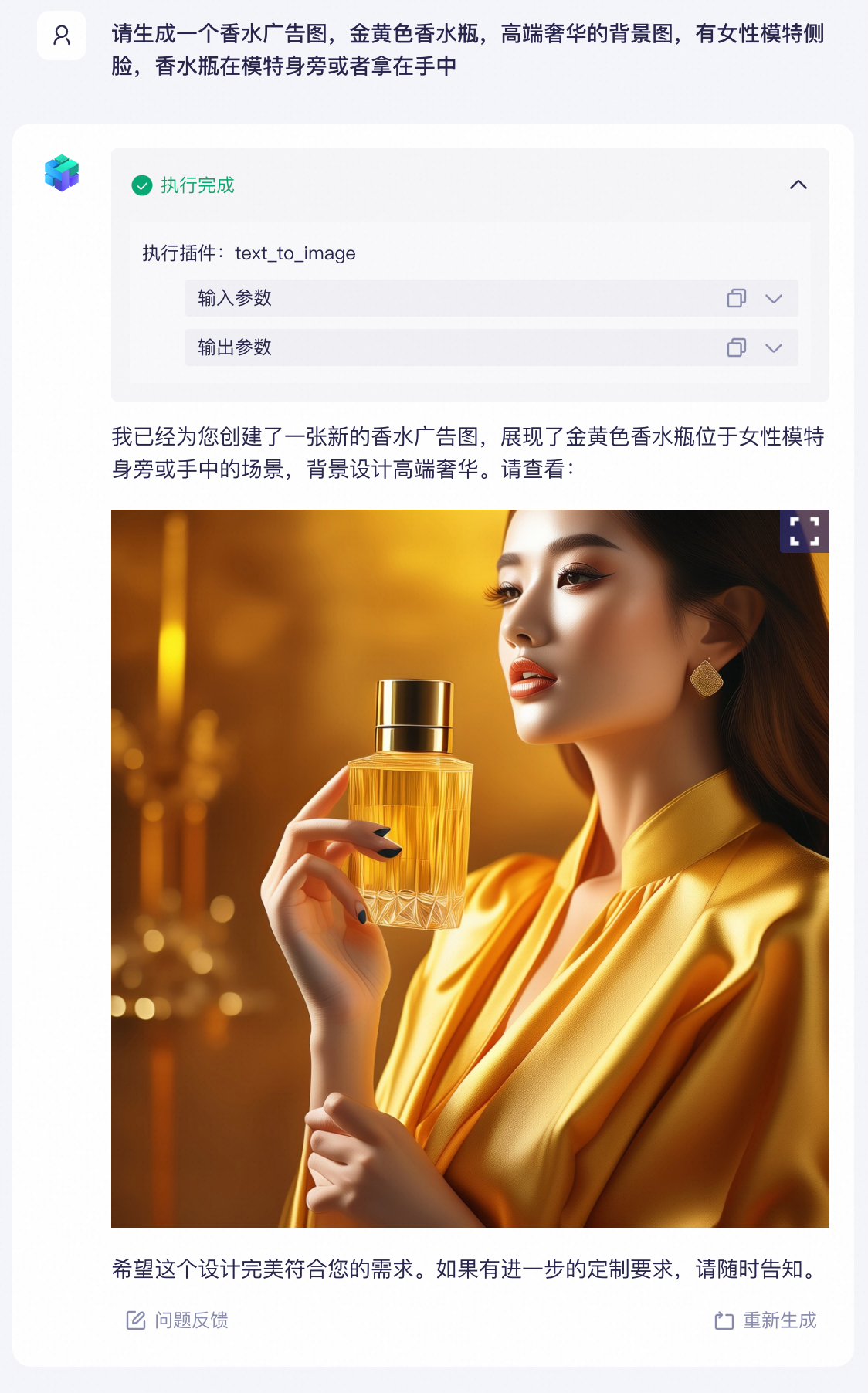
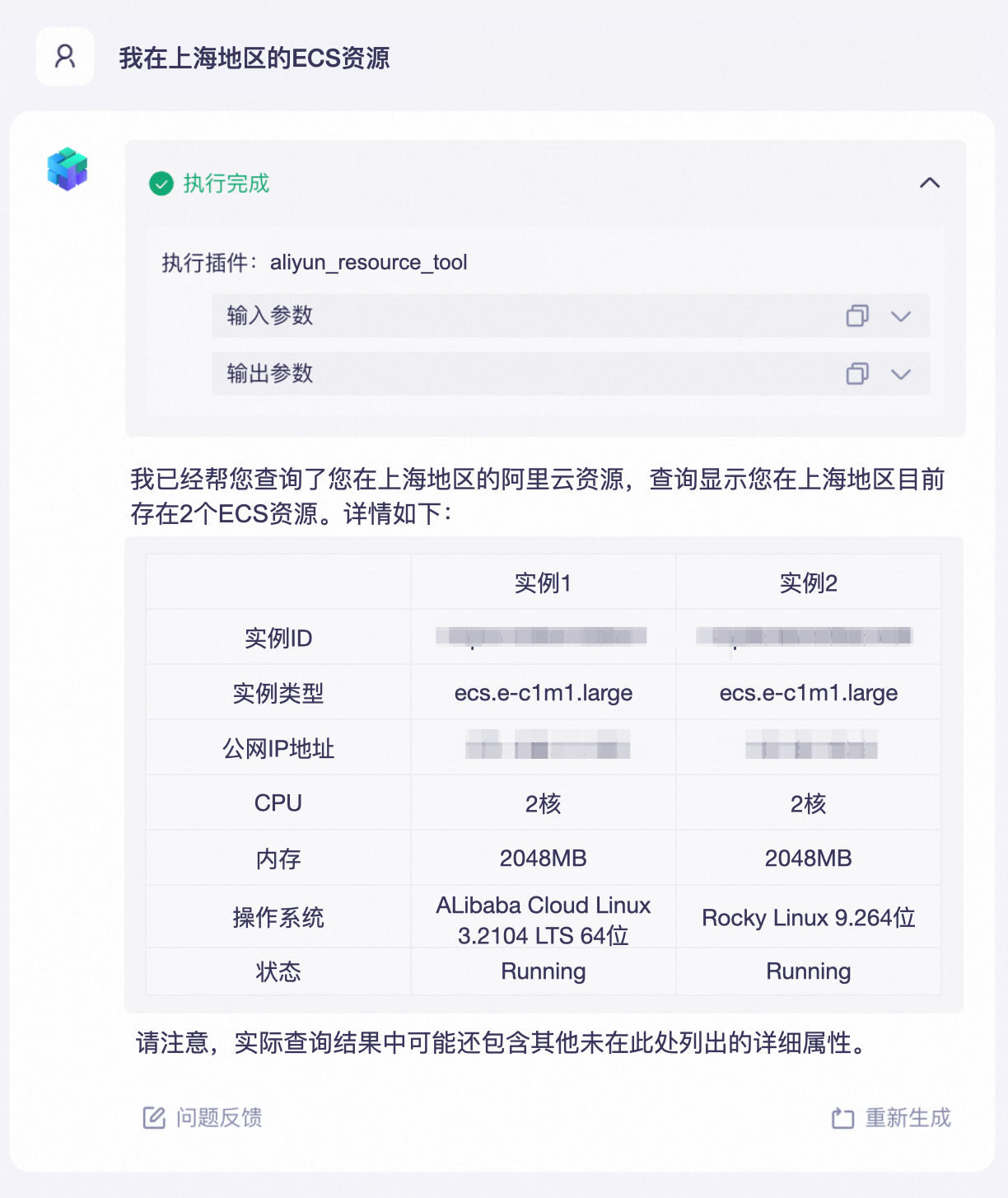
上述示例是在百炼平台的可视化界面上操作完成的。除了官方插件,你还可以开发自定义的插件实现更多的功能,例如查询实时天气、查询阿里云账号下已购买的云服务器等。
|
通过图片生成插件生成广告图片
|
通过自定义插件实现云资源查询
(概念示意图)
|
3 工作原理
大模型应用使用插件的决策流程和人类使用工具的流程是一样的。首先接收输入,判断是否需要使用工具及选择合适的工具,然后使用工具并获得返回结果进行后续推理生成。
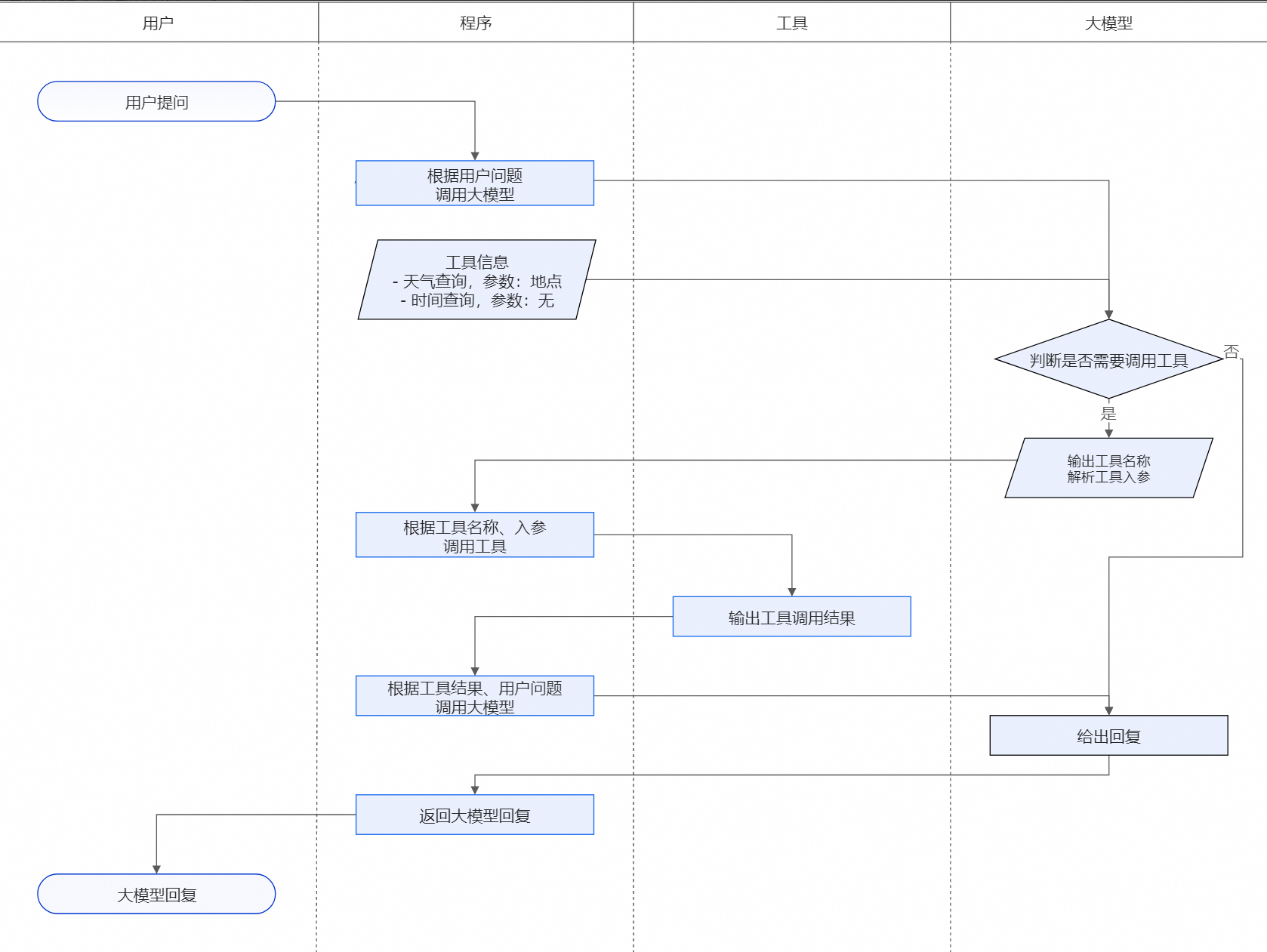
大模型执行插件原理图
4 阿里云上的大模型 API 插件支持
- 如果你正准备基于百炼上提供的通义千问 API 服务构建大模型应用,可以查看百炼插件概述来了解百炼平台预置的插件能力(包括图片生成、夸克搜索、Python代码解释器、计算器等),以及了解如何增加自定义的插件。
- 阿里云的模型服务灵积产品中提供了兼容 OpenAI API 的通义千问 API,该 API 也支持 OpenAI 的 function call 能力。如果你的业务是面向中文用户居多,或者需要满足国内大模型应用备案的要求,可以借助该兼容 API,在不修改业务代码的情况下将你的大模型应用背后的 OpenAI API 替换为通义千问 API。
[进度: 已完成]本节小结
本课程带你了解大模型通过插件与三方应用交互,实现能力增强和拓展。你可以将大模型和业务系统现有的功能进行有机结合,如建立待办事项、抢占会议室,甚至查询当前云账号下保有的阿里云资源等。有插件增强的大模型应用就好像你的私人助理,你只需要发送指令,它可以帮助你完成所有的工作。
你报名参与了导游志愿者活动,但对景点并不熟悉的你很难给出令游客满意的景点介绍。你意识到可以通过查询资料来帮助你完成导游工作,这时的你不再扮演知识的输出者,而是知识的总结者。同样地,给大模型配备知识库,也可以让它参考查询到的信息回答原本无法回答的问题。这种结合了信息检索与文本生成的方法就是我们本节课程要介绍的检索增强生成(RAG,Retrieval Augmented Generation)方法。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解什么是RAG,以及它的实现原理
- 动手给大模型增加知识库来实现RAG
- 了解如何持续改进RAG应用效果
1 什么是RAG
我们按照前面导游的例子,来引出RAG做了哪些事情。你把当导游时无法给游客提供专业、全面信息的困惑告诉了你的主管,于是主管给了你一本志愿者手册。游客询问最近的全聚德烤鸭店在哪里,你拿出了志愿者手册,翻到了全聚德烤鸭店的位置,然后告诉了游客具体的走法。

图1:用系统资料导游
你又遇到了一个游客,游客眼睛不太好,他想知道如何前往银锭桥,此时你也犯难了,志愿者手册并没有该细节内容,但是此时游客手里有一张导览图,你接过地图,经过简单的分析,按照地图指出应该如何前往银锭桥。

图2:用系统资料和用户资料结合来导游
假设我们是开发大模型导游助理的技术团队,我们把导游助理比作志愿者。
在第一种情况下,“志愿者手册”就是我们在开发系统的时候就配置好的知识库,因此导游助理可以从系统默认的知识库中获取烤鸭店的地址,然后生成导航路径给游客。
在第二种情况中,假设我们的系统支持用户上传个性化资料,来更好地满足个性化业务需要。换句话说,系统支持用户添加垂直领域知识,构建私域知识库。那么,当游客向志愿者提供一份个性化导航资料时,系统可以结合游客的垂直领域知识与系统预置的知识共同为游客提供服务。
第一种方案的知识库,可以理解是公司统一配置的知识库;第二种方案中,每个团队或者用户还可以根据自己的需要来增加私域定制化知识库。显然,第二种系统更灵活,不需要复杂的操作就能补充了业务知识。但总体来看,这两个系统都是通过知识库来增强导游助理的能力,减少“幻觉”回答的情况(即导游助理不是编造一个像模像样的地址,而是按照已有知识来回答)。这就是我们即将介绍的检索增强生成(Retrieval Augmented Generation)。
检索增强生成包括三个步骤,建立索引、检索、生成。如果说大模型导游助理是一位志愿者,那么我们给志愿者们准备“志愿者手册”的过程就是建立知识库索引,志愿者查看资料就是系统在检索知识库,志愿者基于检索到的资料充分思考并回答用户的问题就是生成答案。
2 RAG的实现原理
那么RAG是怎样将信息检索与文本生成结合起来的呢?请看下图:
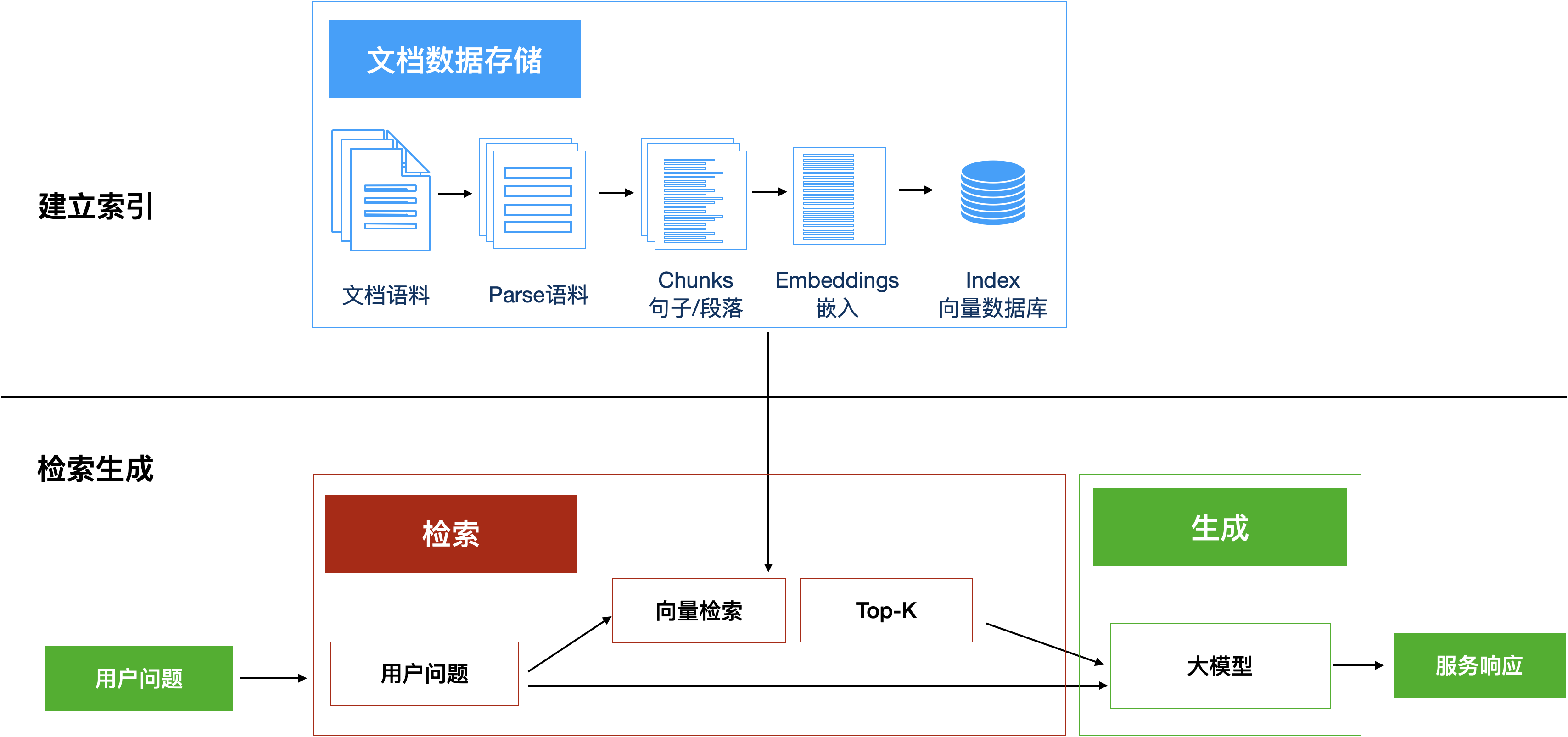
图3:大模型RAG基本工作流
如图所示,RAG主要由两个部分构成:
建立索引:首先要清洗和提取原始数据,将 PDF、Docx等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk);最后将这些片段经过嵌入模型转换成向量数据(此过程叫做embedding),并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。这就是建立索引的过程。
检索生成:系统会获取到用户输入,随后计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块(K值可以自己设置)作为回答当前问题的知识。知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。这就是检索生成的过程。
提示词模板类似于:请阅读:{知识文档块},请问:{用户的问题}
明白了RAG的实现原理,那接下来我们就通过一个动手实验,学习如何在现有大模型的基础上实现检索增强RAG。
3 RAG应用案例:阿里云AI助理
你在使用阿里云产品的时候可能会遇到问题,于是你去咨询了通义千问,可是通义千问对于阿里云产品的细节问题可能并不了解。为了帮助用户更方便地解决上云用云过程中遇到的问题,阿里云推出了阿里云AI助理,它背后的基本框架就是基于通义千问大模型的RAG应用,使用的知识库是阿里云各产品的使用文档。它可以解答用户上云用云的问题,包括提供阿里云产品介绍、生成云产品组合方案、制定业务迁移方案、查询和领用云上权益、提供购买指引。比如向阿里云AI助理提问:
怎样使用Python SDK往OSS上传文件
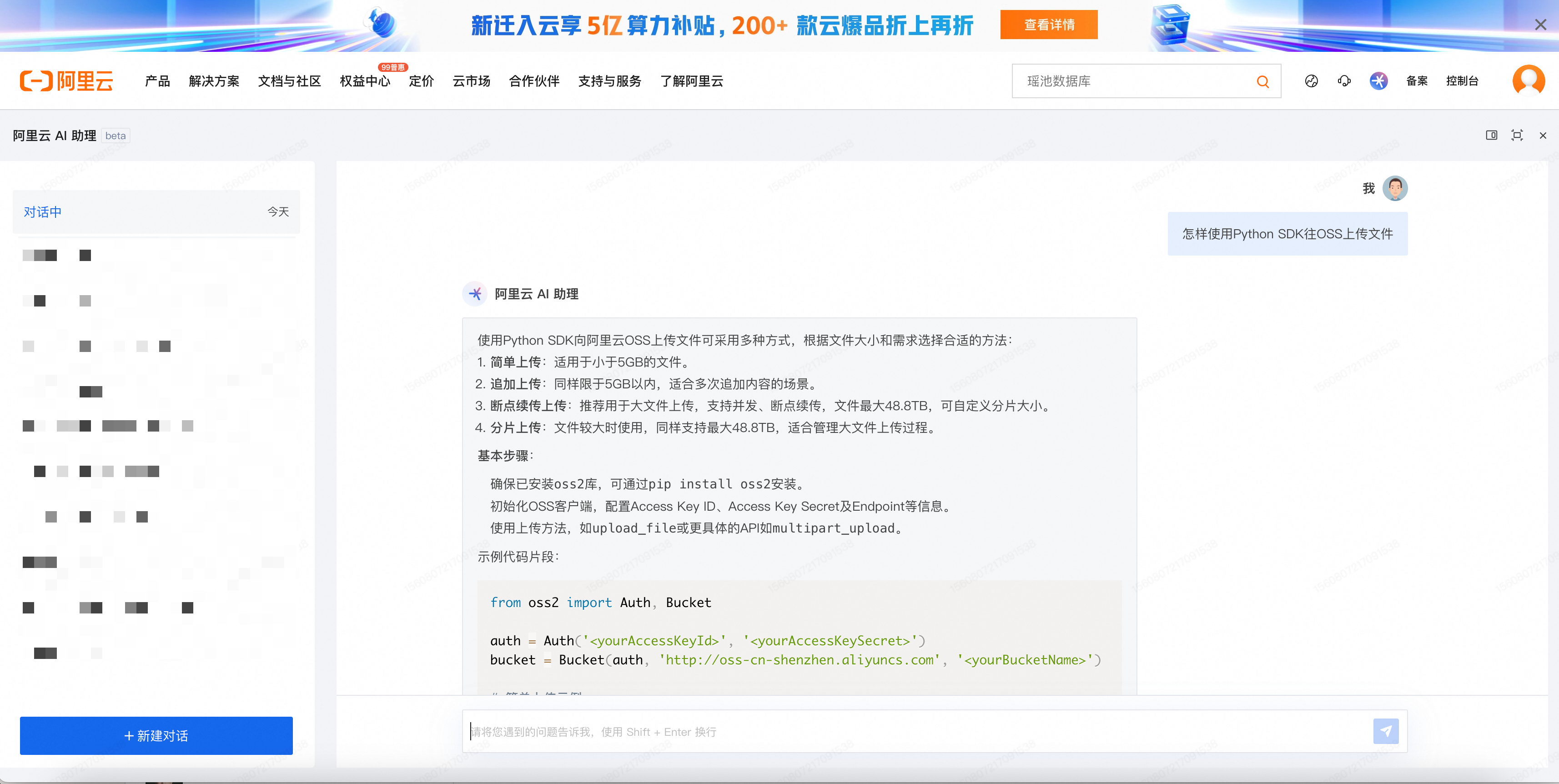
阿里云AI助理会提供答案,并在回答的最后附上它参考的文档链接供用户进行进一步的校验。
4 动手实验
现在,让我们通过一个动手实验,进一步探究如何搭建一个私域知识问答机器人。实验将指导你如何创建知识库,然后创建基于知识库的RAG应用,并进行问答测试。
5 扩展阅读:如何持续改进RAG应用效果
随着深入使用,你可能发现你的 RAG 应用可能只是能用了,但还有很多问题,比如:
- 问题比较抽象或者概念比较模糊,导致大模型没有准确理解使用者的问题。例如,使用者问“兰州拉面去哪吃?”,使用者本来想问附近有没有卖兰州拉面的店铺;假如知识库搜索“兰州”和“拉面”之后,结果排序靠前的语料是位于“兰州”的拉面馆地址,而大模型告诉用户要去买飞机票或者火车票,就是答非所问了。通常我们用改造问题,让使用者的问题更好理解的策略来回避这种情况。
- 知识库没有检索到问题的答案,这有可能是由于语料数据没有做好整理就存入知识库,或者是检索策略有问题,参数需要调整导致的。比如,在采用“K个最相似文档块”作为回答的知识这个策略中,如果K值比较小,那么最相似的K个文档块中可能并不包含能解答用户问题的有效知识,那么答案很可能就是错误的。例如,作为旅游手册的知识库中有大量文段是 兰州拉面如何制作的菜谱、兰州拉面的产地、兰州有哪些特产等,只有一两条信息描述了附近拉面馆的地址。那么当用户询问“兰州拉面怎么走?”时,知识库检索到的信息可能只是兰州拉面的选材、调味、烹饪方面的信息,而唯独没有检索到前方50米处有一家兰州拉面馆。用户也没有办法获得有效的答案。
- 缺少对答案做兜底验证的机制,假设运气很好,志愿者不仅听懂了游客的问题,也正确查找到了附近最近的两家拉面馆的信息,但是志愿者的回答方式是“向北走200米就到了”。这有可能是一个正确的答案,但不是一个好的答案,实际考察过景区地形后我们可能会发现,志愿者北面是后海,你不太可能穿过湖面去一个地方。实际路径可能是:先向东走50米,再向北走绕过后海,走到湖对面去,才能走到正确位置。那这个“向北走200米...”的回答,从导航的角度就不能算是准确了。
我们会发现许多改进标准 RAG 框架的方法,下面我们将一起了解这些改进思路。
如果你目前理解下面的内容还有一些困难,没有关系,你只需要大致了解有哪些常见改进思路。至于具体的改进实现,你可以找到和你合作的工程技术人员或算法技术人员共同探讨改进方案。
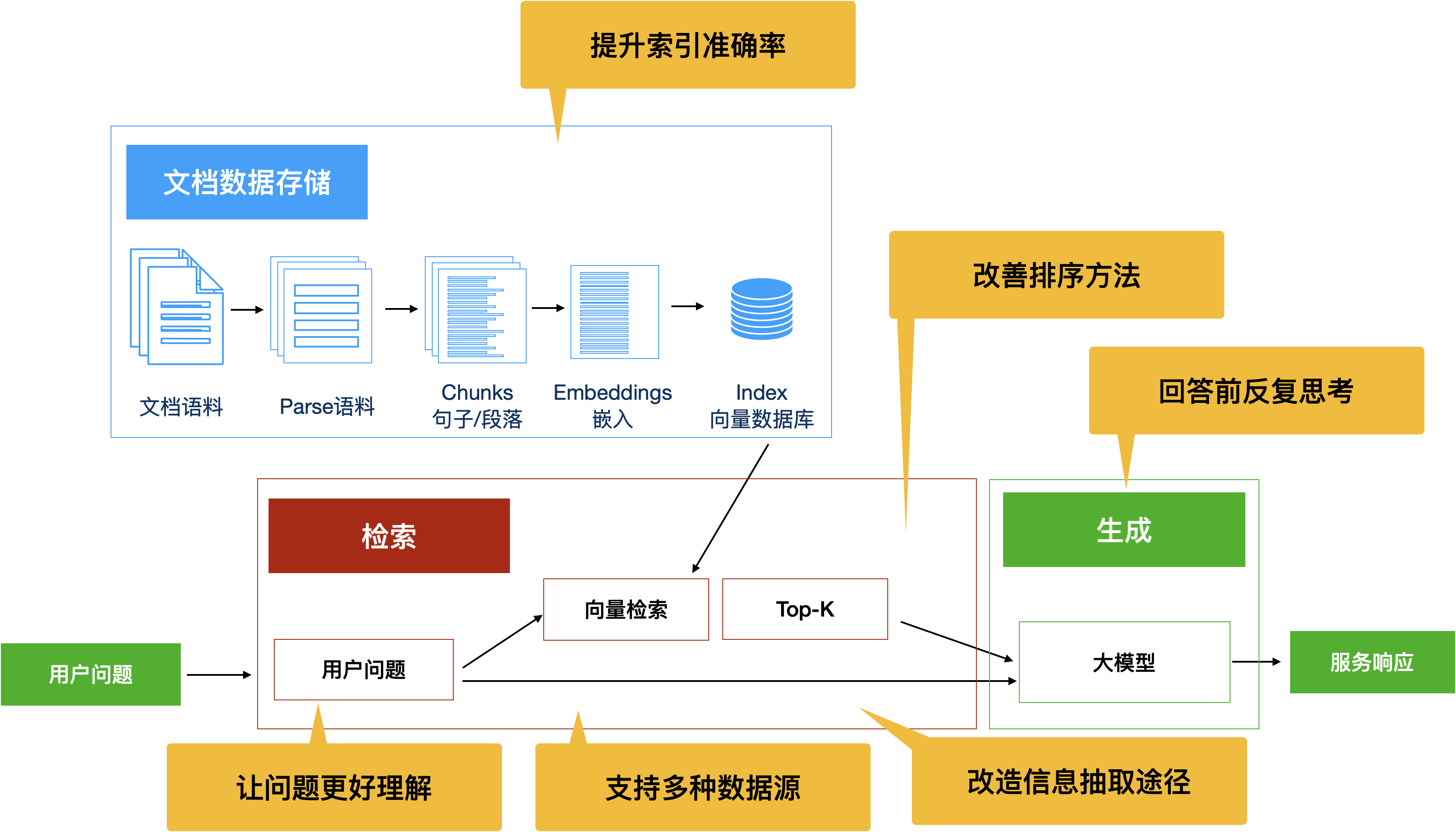
图5:增强RAG能力的多种思路
5.1 建立评测标准
为了持续改进我们的 RAG 应用,首要任务应当是构建一套严谨的评测指标体系,并邀请业务领域专家作为评测方共同参与评测工作,我们可以设置与我们业务相关的多种问题场景,系统性地检查一个RAG系统反应快不快,回答准不准,有没有理解用户问题的意图等方面。通过科学全面的评测,我们可以了解到系统在哪些地方做得好,哪些地方需要改进,从而帮助开发者让RAG系统更好的服务于业务需求。
RAG系统一般包括检索和生成两个模块,我们做评测时就可以从这两个模块分别入手建立评价标准和实施方法,当然你也可以用最终效果为标准,建立端到端的评测。在评测指标设计上,我们主要考察检索模块的准确性,如准确率、召回率、F1值等等;在生成模块,我们主要考察生成答案的价值,如相关性、真实性等等。
我们可以引入业界认可的一些通用评估策略,比如,你可以参考Ragas提及的评测矩阵指南,你也可以建立一些自己的评测指标,这些评测方法将会有助于你量化和改进每一个子模块的表现。
5.2 改造一:提升索引准确率
- 优化文本解析过程
在构建知识库的时候,我们首先需要正确的从文档中提取有效语料。因此,优化文本解析的过程往往对提升RAG的性能有很大帮助。例如,从网页中提取有效信息时,我们需要判断哪些部分应该被去掉(比如页眉页脚标签),哪些部分应该被保留(比如属于网页内容的表格标签)。
- 优化chunk切分模式
Chunk就是数据或信息的一个小片段或者区块。当你在处理大量的文本、数据或知识时,如果你一次性全部交给大模型来阅读和处理,效率是非常低的。所以,我们把它们切分成更小、更易管理的部分,这些部分就是chunk。每个chunk都包含了一些有用的信息,这样当系统根据用户的问题寻找某个知识时,它可以迅速定位到与答案相关信息的chunk,而不是在整个数据库中盲目搜索。因此,通过精心设计的chunk切分策略,系统能够更高效地检索信息,就像图书馆里按照类别和标签整理书籍一样,使得查找特定内容变得容易。优化chunk切分模式,就能加速信息检索、提升回答质量和生成效率。具体方法有很多:
- 利用领域知识:针对特定领域的文档,利用领域专有知识进行更精准的切分。例如,在法律文档中识别段落编号、条款作为切分依据。
- 基于固定大小切分:比如默认采用128个词或512个词切分为一个chunk,可以快速实现文本分块。缺点是忽略了语义和上下文完整性。
- 上下文感知:在切分时考虑前后文关系,避免信息断裂。可以通过保持特定句对或短语相邻,或使用更复杂的算法识别并保留语义完整性。最简单的做法是切分时保留前一句和后一句话。你也可以使用自然语言处理技术识别语义单元,如通过句子相似度计算、主题模型(如LDA)或BERT嵌入聚类来切分文本,确保每个chunk内部语义连贯,减少跨chunk信息依赖。通义实验室提供了一种文本切割模型,输入长文本即可得到切割好的文本块,详情可参考:中文文本分割模型。
以上介绍了一些常见策略,你也可以考虑使用更复杂的切分策略,如围绕关键词切分或者采用动态调整的切分策略等,主要目的是为了保证每个chunk中信息的完整性,更好的服务系统提升检索质量。
- 句子滑动窗口检索
这个策略是通过设置window_size(窗口大小)来调整提取句子的数量,当用户的问题匹配到一个chunk语料块时,通过窗函数提取目标语料块的上下文,而不仅仅是语料块本身,这样来获得更完整的语料上下文信息,提升RAG生成质量。

图6:句子滑窗检索获取检索到的句子的上下文
- 自动合并检索
这个策略是将文档分块,建成一棵语料块的树,比如1024切分、512切分、128切分,并构造出一棵文档结构树。当应用作搜索时,如果同一个父节点的多个叶子节点被选中,则返回整个父节点对应的语料块。从而确保与问题相关的语料信息被完整保留下来,从而大幅提升RAG的生成质量。实测发现这个方法比句子滑动窗口检索效果好。
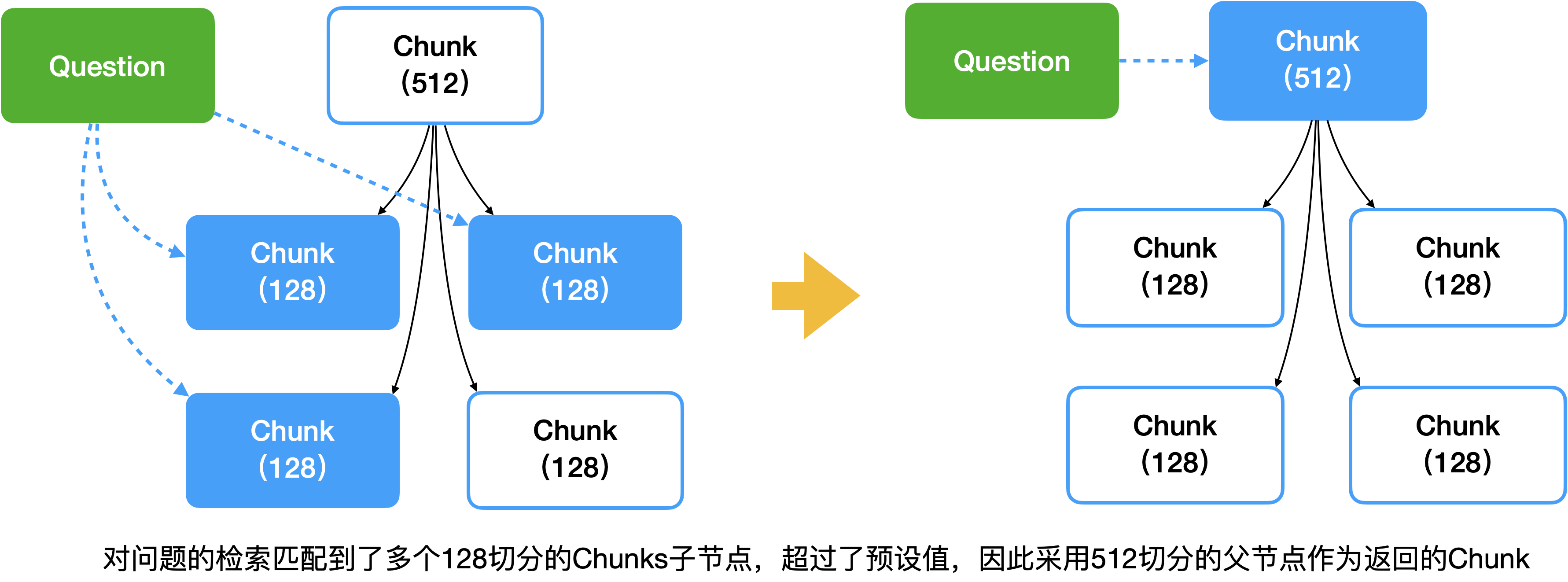
图7:自动合并检索的方法,返回父节点文本作为检索结果
- 选择更适合业务的Embedding模型
经过切分的语料块在提供检索服务之前,我们需要把chunk语料块由原来的文本内容转换为机器可以用于比对计算的一组数字,即变为Embedding向量。我们通过Embedding模型来进行这个转换。但是,由于不同的Embedding模型对于生成Embedding向量质量的影响很大,好的Embedding模型可以提升检索的准确率。
比如,针对中文检索的场景,我们应当选择在中文语料上表现更好的模型。那么针对你的业务场景,你也可以建议你的技术团队做Embedding模型的技术选型,挑选针对你的业务场景表现较好的模型。
- 选择更适合业务的ReRank模型
除了优化生成向量的质量,我们还需要同时优化做向量排序的ReRank模型,好的ReRank模型会让更贴近用户问题的chunks的排名更靠前。因此,我们也可以挑选能让你的业务应用表现更好的ReRank模型。
- Raptor 用聚类为文档块建立索引
还有一类有意思的做法是采用无监督聚类来生成文档索引。这就像通过文档的内容为文档自动建立目录的过程。假如志愿者拿到的文本资料是没有目录的,志愿者一页一页查找资料必然很慢。因此,可以将词条信息聚类,比如按照商店、公园、酒吧、咖啡店、中餐馆、快餐店等方式进行分组,建立目录,再根据汉语拼音字母来排序。这样志愿者来查找信息的时候就可以更快速地进行定位。
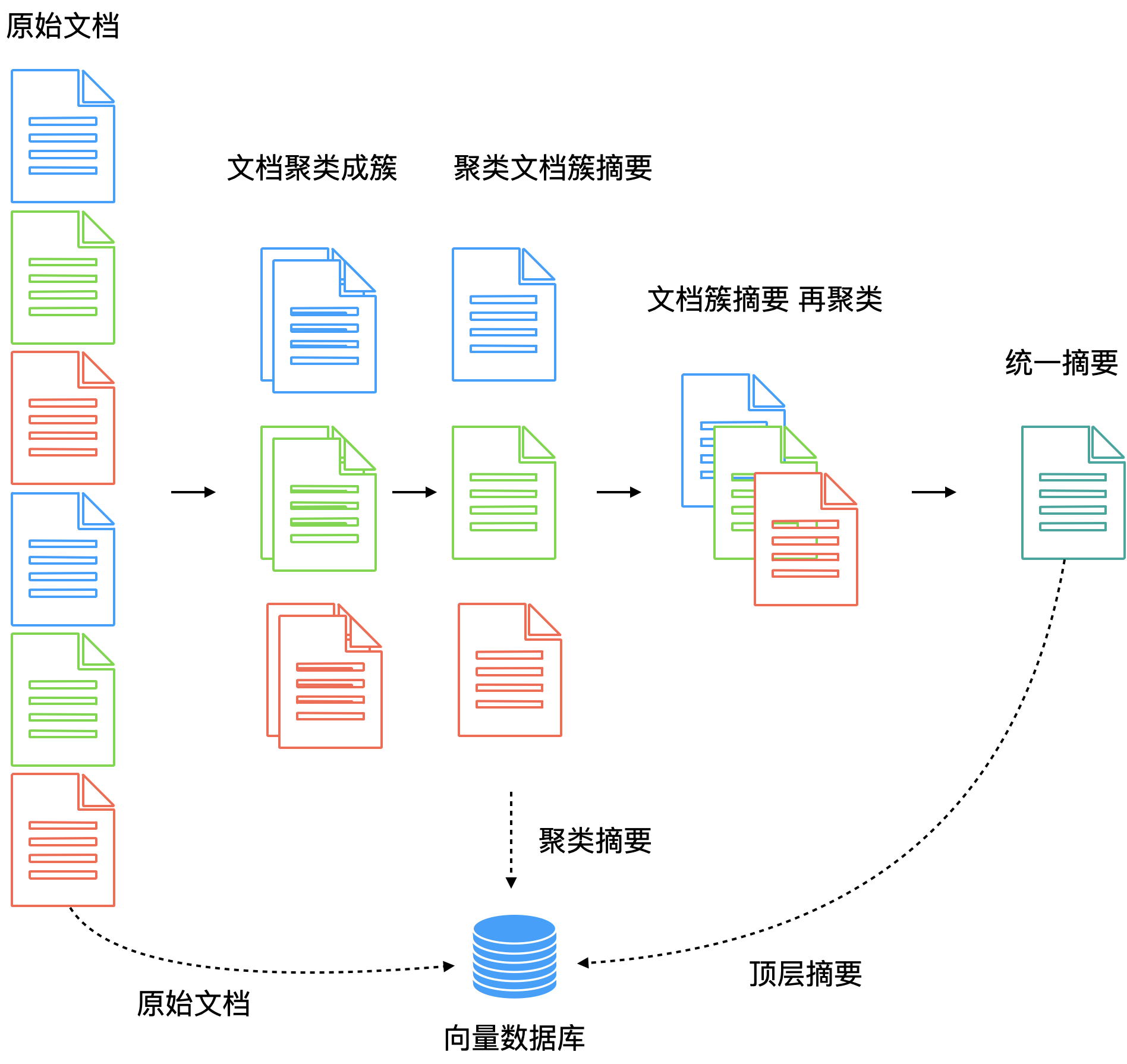
图8:Raptor 用聚类为文档块建立索引
5.3 改造二:让问题更好理解
我们希望做到能让人们通过口语对话来使用大模型应用。然而,人们在口语化表达自己的目的和意图时,往往会出现一些问题。比如,问题过于简单含糊出现了语义混淆,导致大模型理解错误;问题的要素非常多,而用户又讲得太少,只能在反复对话中不断沟通补全;问题涉及的知识点超出了大模型训练语料,或者知识库的覆盖范围,导致大模型编造了一些信息来回答等等。所以,我们期望能在用户提问的环节进行介入,让大模型能更好的理解用户的问题。针对这个问题进行尝试的论文很多,提供了很多有意思的实现思路,如Multi-Query、RAG-Fusion、Decomposition、Step-back、HyDE等等,我们简要讲解一下这些方法的思路。
- Enrich 完善用户问题
我们首先介绍一种比较容易想到的思路,让大模型来完善用户的原始问题,产生一个更利于系统理解的完善后的用户问题,再让后续的系统去执行用户的需求。通过用大模型对用户的问题进行专业化改写,特别是加入了知识库的支持,我们可以生成更专业的问题。下图展现了一种理想的对用户问题的Enrich流程。我们通过多轮对话逐步确认用户需求。
- 一种理想的通过多轮对话补全需求的方案。该设想是通过大模型多次主动与用户沟通,不断收集信息,完善对用户真实意图的理解,补全执行用户需求所需的各项参数。如下图所示。
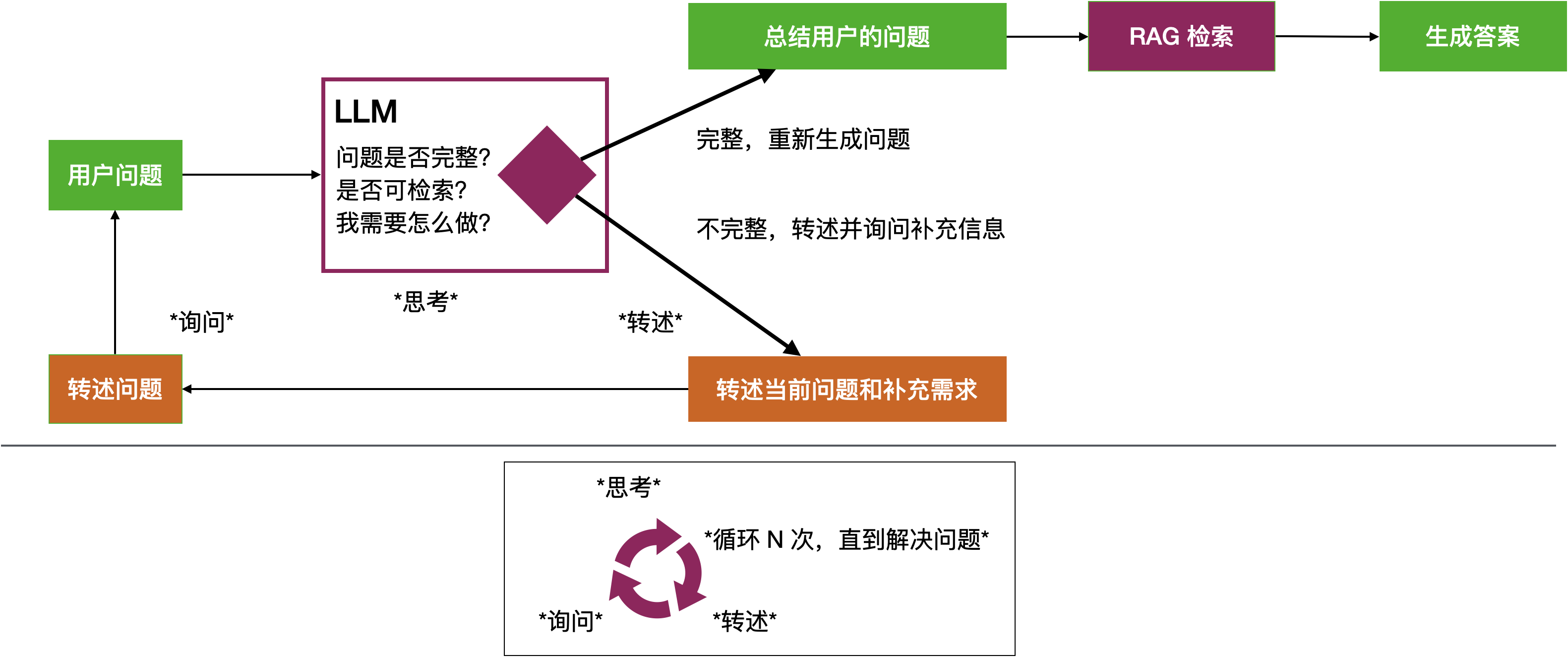
图9:通过多轮对话完善用户问题的工作流
以下展示一个通过多轮对话来补全用户问题的案例:
但是在实际的生产中,一方面用户可能没有那么大的耐性反复提供程序需要的信息,另一方面开发者也需要考虑如何终止信息采集对话,比如让大模型输出停止语“<EOS>(End Of Sentence)”。所以在实践中,我们需要采用一些更容易实现的方案。
- 让大模型转述用户问题,再进行RAG问答。参考“指令提示词”的思路,我们可以让大模型来转述用户的问题,将用户的问题标准化,规范化。这里我们可以提供一套标准提示词模板,提供一些标准化的示例,也可以用知识库来增强。我们的主要目的是规范用户的输入请求,再生成RAG查询指令,从而提升RAG查询质量。

图10:让大模型根据知识库来补全用户请求
- 让用户补全信息辅助业务调用。有一些应用场景需要大量的参数支撑,(比如订火车票需要起点、终点、时间、座位等级、座位偏好等等),我们还可以进一步完善上面的思路,一次性告诉用户系统需要什么信息,让用户来补全。首先,需要准确理解用户的意图,实现意图识别的手段很多,如使用向量相似度匹配、使用搜索引擎、或者直接大模型来支持。其次,根据用户意图选择合适的业务需求模板。接着,让大模型参考业务需求模版来生成一段对话发给用户,请求用户补充信息。这时,如果用户进行了信息完善,那么大模型就可以基于用户的回复信息结合用户的请求来生成下一步的行动指令,整个系统就可以实现应用系统自动帮助用户订机票、订酒店,完成知识库问答等应用形式。
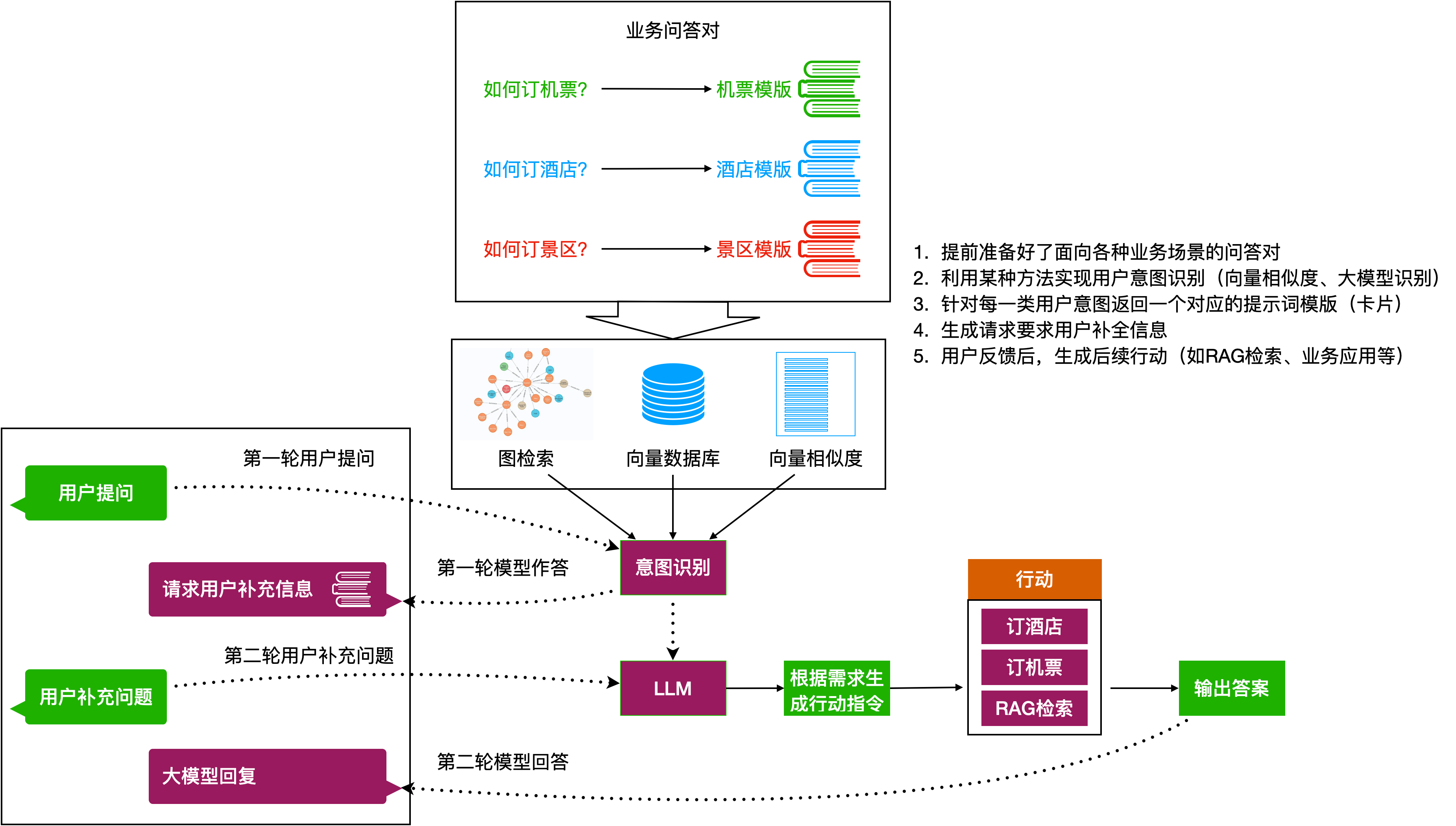
图11:一个完整的用户信息补全流程示意图
Enrich的方法介绍了一种大模型向用户多次确认需求来补全用户想法的做法。自此,我们假设已经获得了补全过的用户需求,但是由于用户面对的现实问题千变万化,而系统或RAG的知识可能会滞后,对用户问题的理解多少存在一些偏差,我们还可以继续对整个系统进行强化,接下来我们继续介绍“如何让系统更好地理解用户的问题”。
- Multi-Query 多路召回
多路召回的方法不是让大模型进行一次改写然后反复向用户确认,而是让大模型自己解决如何理解用户的问题。所以我们首先一次性改写出多种用户问题,让大模型根据用户提出的问题,从多种不同角度去生成有一定提问角度或提问内容上存在差异的问题。让这些存在差异的问题作为大模型对用户真实需求的猜测,然后再把每个问题分别生成答案,并总结出最终答案。

|
例如:用户问“烤鸭店在哪里?”,大模型会生成: |
|
|

以下就是能生成多路召回策略的提示词模板,你可以在你的项目里直接使用这段提示词模板,其中{question}就是用户输入的问题,你也可以尝试先翻译成中文再使用:
You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}- RAG-Fusion 过滤融合
在经过多路召回获取了各种语料块之后,并不是将所有检索到的语料块都交给大模型,而是先进行一轮筛选,给检索到的语料块进行去重操作,然后按照与原问题的相关性进行排序,再将语料块打包喂给大模型来生成答案。

经过去重复语料筛选,节省了传递给大模型的tokens数量,再经过排序,将更有价值的语料块传递给大模型,从而提升答案的生成质量。
用我们的例子讲就是,志愿者先从多种角度来理解用户的问题,然后对每个问题都去检索资料,查找有用信息,最后把重复信息去掉,再将获取的资料排序。这就能锁定比较接近用户问题的几段语料了,比如“全聚德烤鸭店的地址”,“天外天烤鸭店的地址”,“郭林家常菜店铺的地址”等等,以及这些烤鸭店分布在后海的那些区域,如何步行走过去等等。
- Step Back 问题摘要
让大模型先对问题进行一轮抽象,从大体上去把握用户的问题,获得一层高级思考下的语料块。
这个策略的提示词写作
You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:假如是医疗咨询的场景,用户描述了一大段病情、现象、感受、担忧;或者在法律服务的场景,用户描述了现场情况、事发双方的背景、纠纷的由来等一大段话的时候,我们就可以用这个策略,让大模型先理解一下用户的意图是什么,这个事情大体上看是什么问题。
- Decomposition 问题分解
这个策略讲究细节,有点像提示词工程中的CoT(Chain of Thoughts,思维链)的概念,是把用户的问题拆成一个一个小问题来理解,或者可以说是RAG中的CoT。这个策略的提示词如
You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):使用了这段提示词,大模型生成的子问题如下

接下来可以使用并行与串行两个策略来执行子任务。并行执行是将每个子任务抛出去获得一个答案,然后再让大模型把所有子任务的答案汇总起来。串行是依次执行子任务,然后将前一个任务生成的答案作为后一个任务的提示词的一部分。这两种执行策略如下图所示
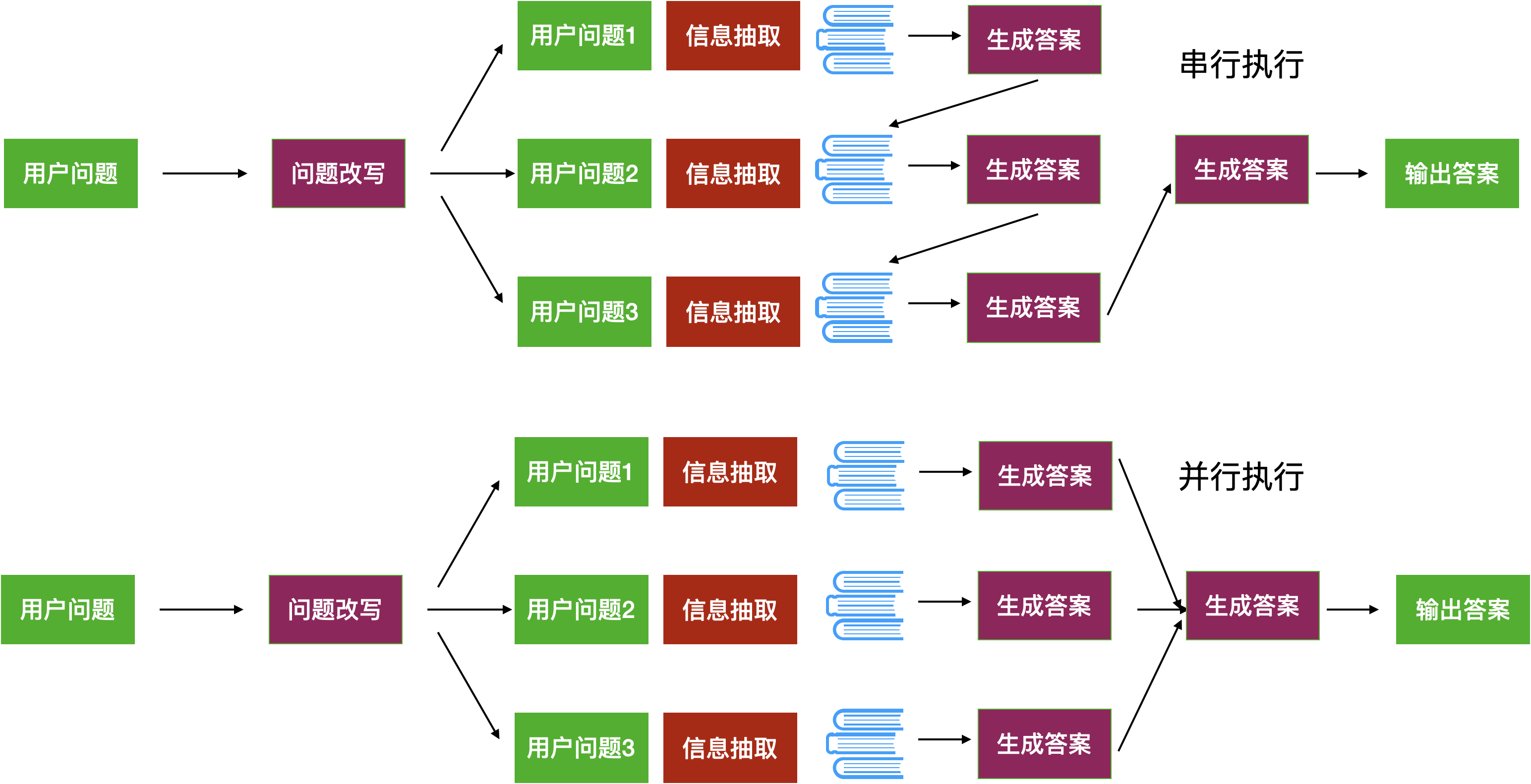
- HyDE 假设答案
这个策略让大模型先来根据用户的问题生成一段假设答案,然后用这段假设的答案作为新的问题去文档库里匹配新的文档块,再进行总结,生成最终答案。
好比志愿者听到用户的问题“推荐一家烤鸭店”,第一时间想到了“全聚德烤鸭店不错,我前两天刚吃过!”,接下来,志愿者按照自己的思路找到了全聚德烤鸭店的地址,并给用户讲解如何走过去。

5.4 改造三:改造信息抽取途径
Corrective Retrieval Augmented Generation (CRAG)是一种改善提取信息质量的策略:如果通过知识库检索得到的信息与用户问题相关性太低,我们就主动搜索互联网,将网络搜索到的信息与知识库搜索到的信息合并,再让大模型进行整理给出最终答案。在工程上我们可以有两种实现方式:
- 向量相似度,我们用检索信息得到的向量相似度分来判断。判断每个语料块与用户问题的相似度评分,是否高过某个阈值,如果搜索到的语料块与用户问题的相似度都比较低,就代表知识库中的信息与用户问题不太相关;
- 直接问大模型,我们可以先将知识库检索到的信息交给大模型,让大模型自主判断,这些资料是否能回答用户的问题。

图12:CRAG原理图
采用这个搜索策略,当志愿者遇到一个问题,而手边的资料都不能解答这个问题时,志愿者可以上网搜索答案。比如游客问:“天安门升旗仪式是几点钟?”志愿者可能会打开电脑,搜索一下明天天安门升旗仪式的具体时间,然后再回答给游客。这样,至少能让RAG的回答信息的范围有所扩大,回答质量有了提升。
在CRAG的论文中,当面临知识库不完备的情况时,先从互联网下载相关资料再回答的准确率比直接回答的准确率有了较大提升。
5.5 改造四:回答前反复思考
Self-RAG,也称为self-reflection,是一种通过在应用中设计反馈路径实现自我反思的策略。基于这个思想,我们可以让应用问自己三个问题:
- 相关性:我获取的这些材料和问题相关吗?
- 无幻觉:我的答案是不是按照材料写的来讲,还是我自己编造的?
- 已解答:我的答案是不是解答了问题?
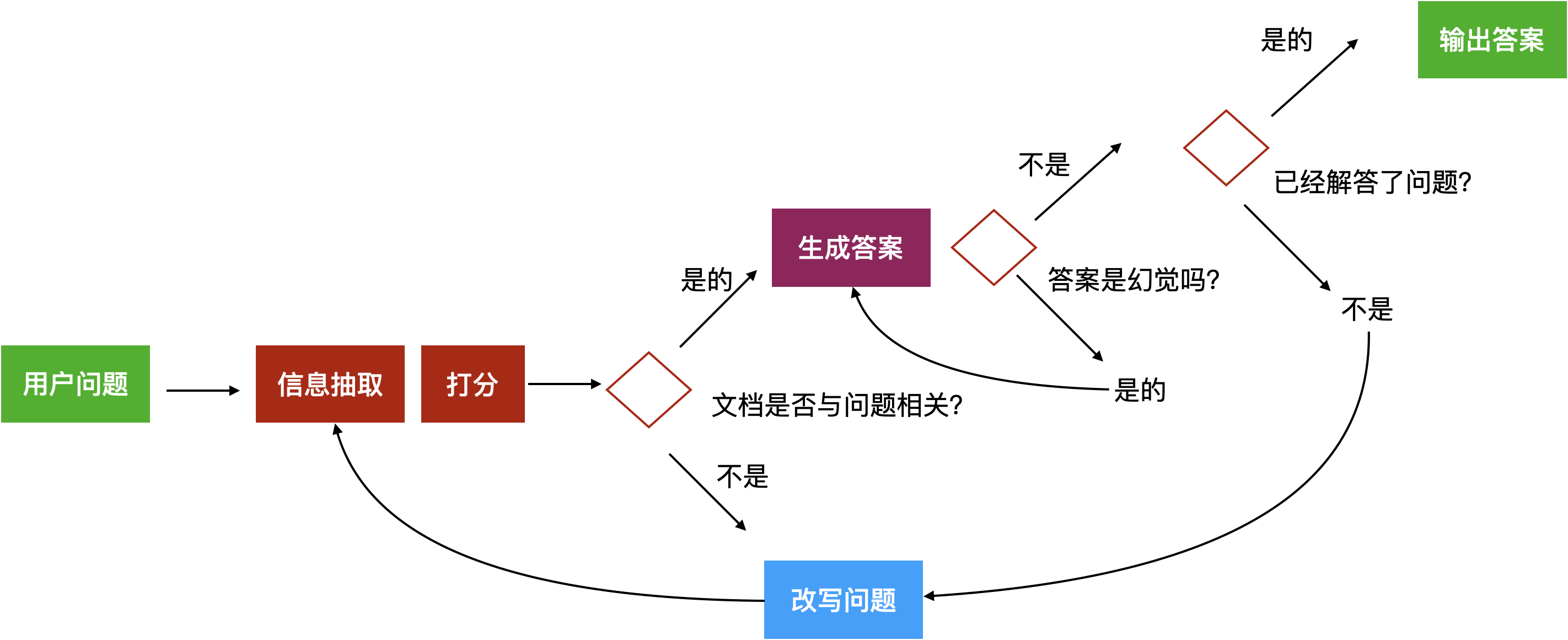
图13:Self-RAG原理图
这些判断本身可以通过另一段提示词工程让大模型给出判断,整个项目复杂度有了提升,但回答质量有了保障。
志愿者至少会通过反思这三个问题,在回答游客之前,让答案的质量有所提升。
5.6 改造五:从多种数据源中获取资料
这个策略涉及系统性的改造数据的存储和获取环节。传统RAG我们只分析文本文档,我们把文档作为字符串存在向量数据库和文档数据库中。但是现实中的知识还有结构化数据以及图知识库。因此,有很多工作者在研究从数据库中通过NL2SQL的方式直接获取与用户问题相关的数据或统计信息;从GraphDB中用NL2Cypher(显然这是在用Neo4J)获取关联知识。这些方法显然将给RAG带来更多新奇的体验。
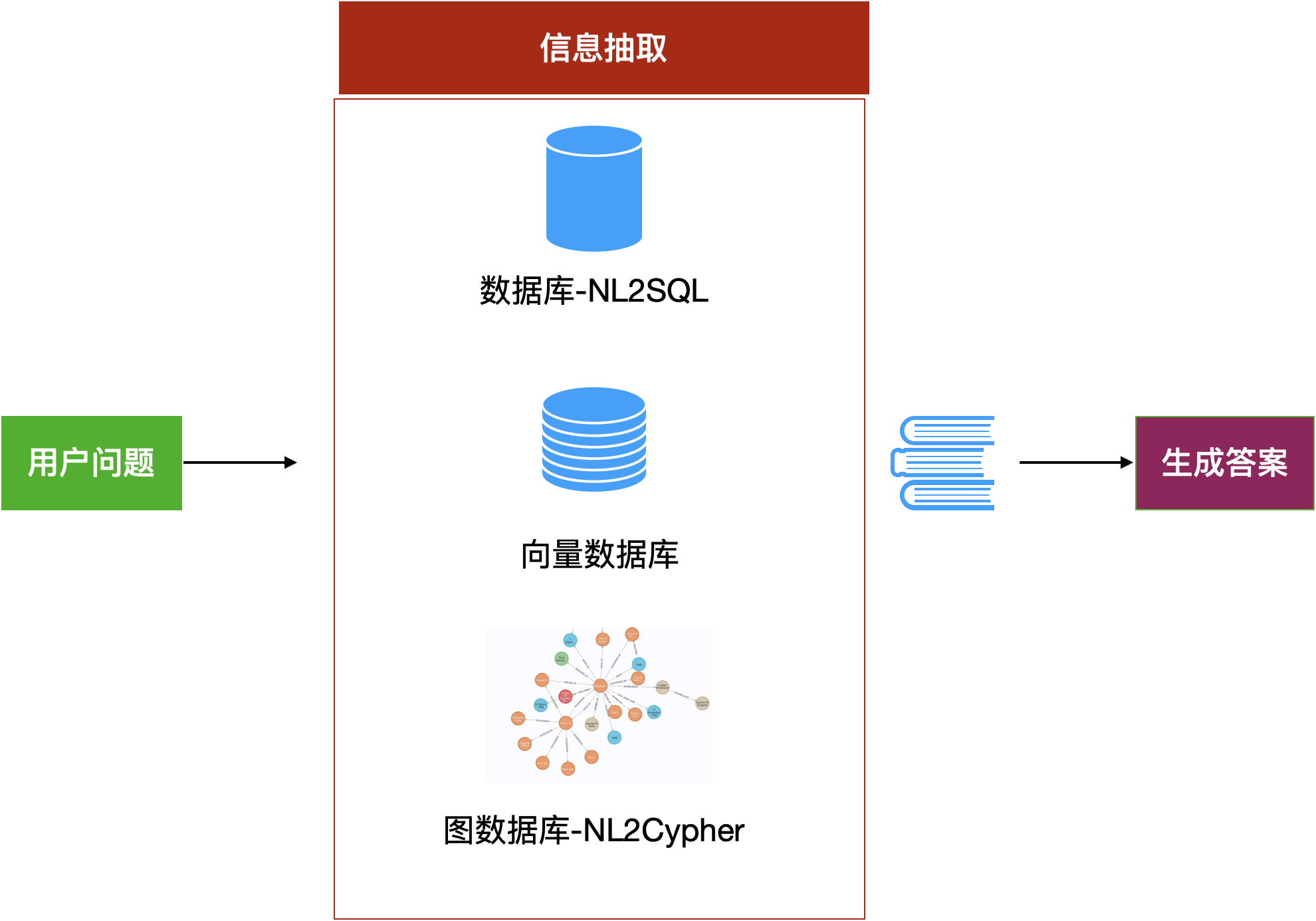
图14:通过大模型搜索数据库来抽取信息
- 从数据库中获取统计指标
大模型可以将用户问题转化为SQL语句去数据库中检索相关信息,这个能力就是NL2SQL(Natural Language to SQL)。如果搜索的问题比较简单,只有单表查询,并获取简单的统计数据如求和、求平均等等,大模型还能稳定地生成正确SQL。如果问题比较复杂涉及多表联合查询,或者涉及复杂的过滤条件,或复杂的排序计算公式,大模型生成SQL的正确性就会下降。我们一般用Spider榜单来评测大模型生成SQL的性能。合理构造提示词调用Qwen-Max生成SQL,或者使用SFT微调小模型如Qwen-14B来生成SQL,都可以获得可满足应用的NL2SQL能力。
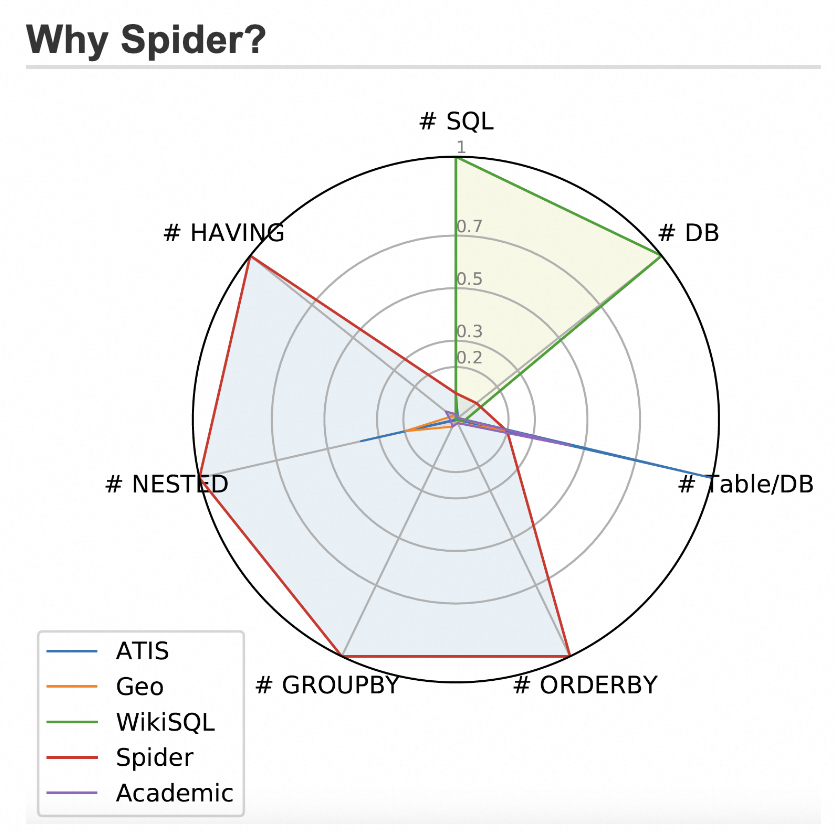
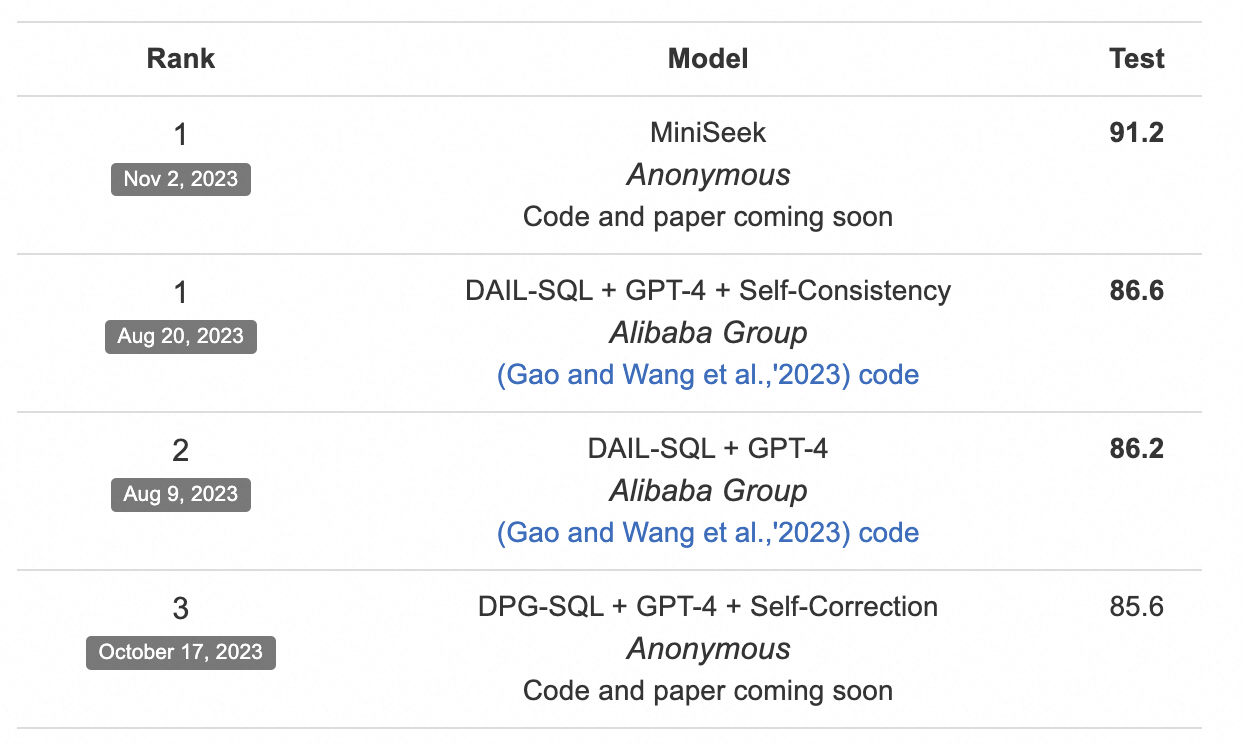
图15:Spider数据集和“执行正确率”评测榜单,榜单上排名靠前的DAIL-SQL+GPT4+Self-Consistency技术,就是使用先检索相似问题构造Few-Shot提示词,再用GPT4来生成SQL,并添加了多路召回策略的方法
- 从知识图谱中获取数据
Neo4j是一款图数据库引擎,可以为我们提供知识图谱构建和计算服务。在知识图谱上,我们调用各种图分析算法,如标签传播、关键节点发现等等,可以快速检索多度关联关系,挖掘隐藏关系。
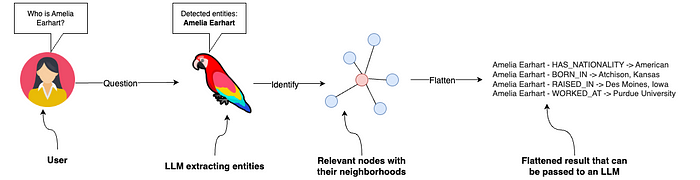
图16:将用户的问题转化为Neo4j的Cypher查询语句,从知识图谱中获取关键知识
5.7 总结
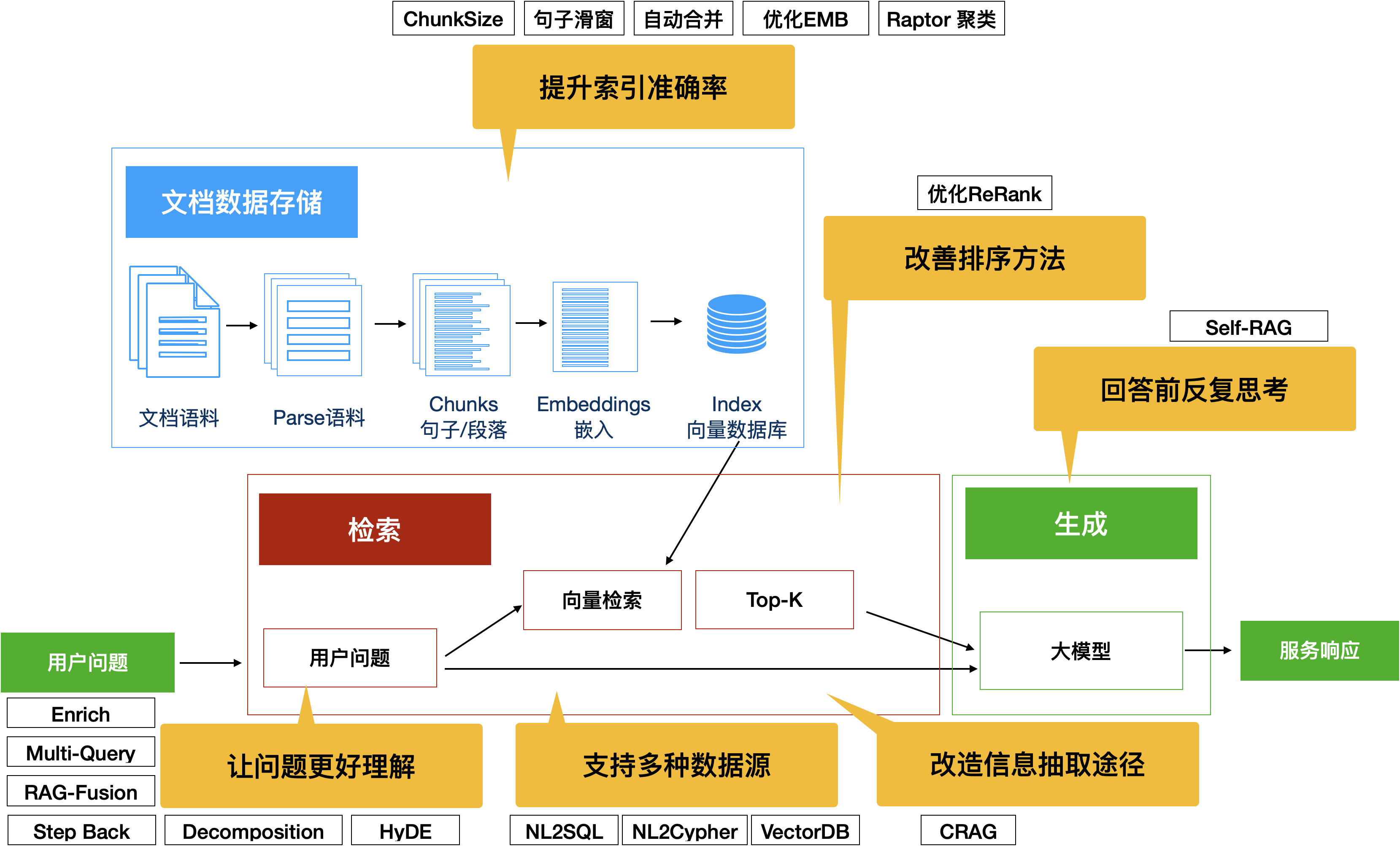
图17:增强RAG能力的多种方法汇总
我们可以通过多种办法来提升RAG的性能,在经典RAG框架之上,可以进行技术改造的方法层出不穷,RAG也是当前最活跃的技术话题之一,我们期待着这个 AI 领域未来会有更大的发展。
[进度: 已完成]本节小结
在本小节中,我们通过例子给你介绍了增强生成RAG来强化大模型,剖析了实现原理,并通过动手实验完整体验了RAG功能,结尾部分为你介绍了如何持续改进RAG应用效果,帮助你全面理解RAG。如果你想做一个专业领域的大模型问答,或者希望针对公司内部的私域知识开发智能小助手,RAG就是你最好的选择。
[高铁]前言
你也许尝试过让大模型基于你的工作总结写一份周报,然后你再手动发送周报的邮件给你老板。如果有一个程序可以接收这样的输入,把你的工作总结转化为周报,还能通过电子邮件发送给你的老板,这样的程序就是本章节即将介绍的“Agent”。接下来,我们将带你拆解Agent背后的实现思路,并探索单Agent、多Agent在现实世界的应用。
[羽毛笔]课程目标
学完本课程后,你将能够:
- 了解大模型 Agent 是什么,能解决什么问题
- 了解人机交互的前沿方向,激发创新性思考
1 认识大模型Agent
1.1 大模型Agent是什么
从软件工程的角度来看,大模型Agent是指基于大语言模型的,能使用工具与外部世界进行交互的计算机程序。
在不同的翻译场景中,Agent可以翻译为智能体、代理、智能助手等,本文中提到的“智能体”即是Agent。
如果把Agent类比成人类,那么大模型相当于大脑,而工具就是四肢。Agent能够通过工具实现与外部世界的交互,而工具通常就是之前介绍过的插件。
实际上,现有的大模型Agent通常也具备规划能力和记忆能力,比如一个典型的Agent会是这样:
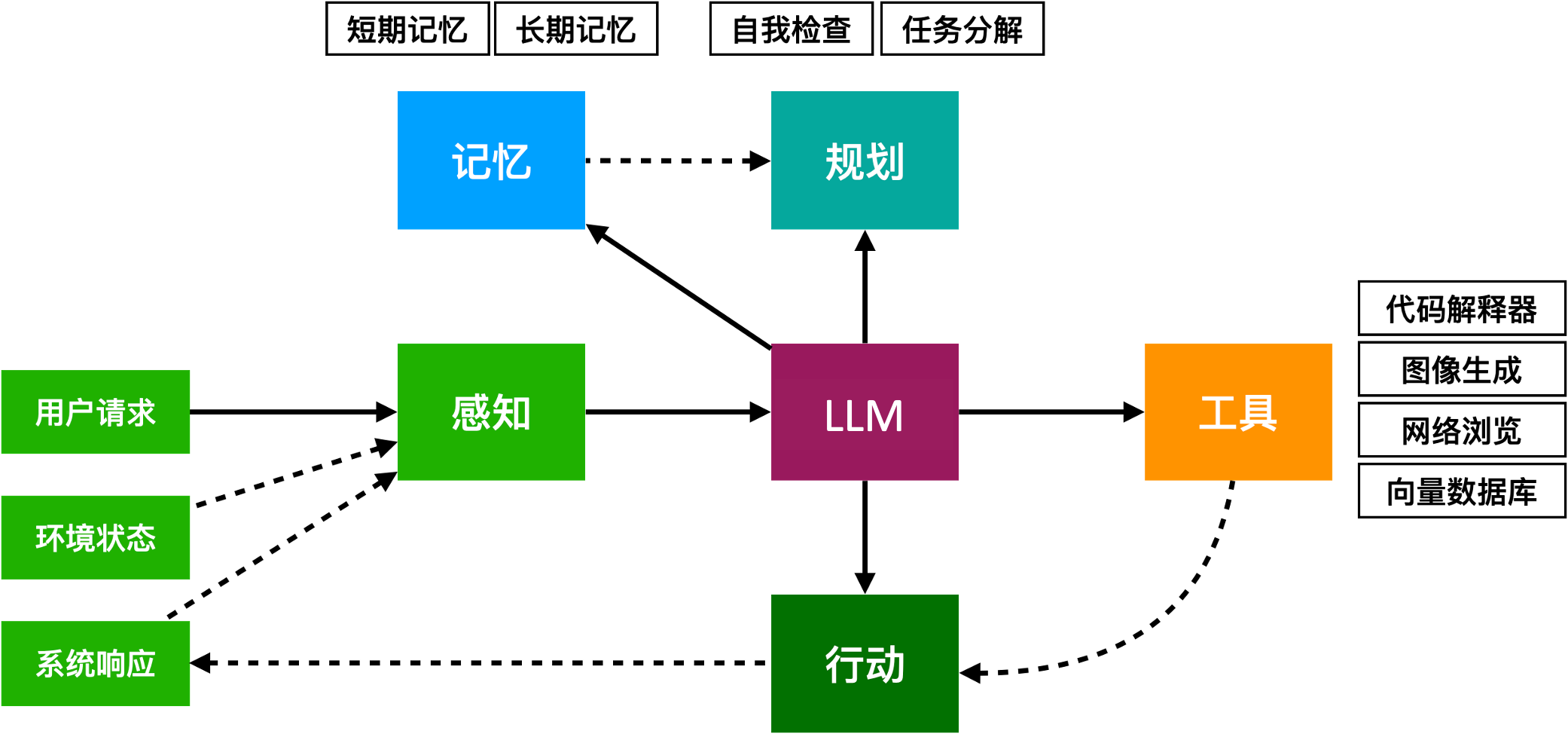
假设你有一个智能家庭助理,它可以帮助管理家庭中的各种事务:
-
感知(Perception):
- 家庭助理通过摄像头、麦克风、传感器等设备获取家庭成员的活动信息和环境状态。例如,它可以“看到”房间里的光线情况,听到你和它的对话,感知到家里的温度等。
-
思考(Reasoning):
- 家庭助理根据获取的信息来“思考”下一步应该做什么。如果你说“我有点冷”,它会从数据库中查询当前的温度数据,结合你的偏好(已存储或通过对话学习得来的),决定是否应该调整温度。
- 如果它检测到今天是垃圾回收日且垃圾桶已满,它会提醒你或自动安排机器人将垃圾桶移到指定位置。
- 行动(Action):
- 家庭助理可以执行一些具体的行动来响应你的需求。例如,它可以调整温度,打开或关闭窗帘,启动车库门,甚至下单购买你常用的家庭用品。
通过这个智能家庭助理的案例,我们可以形象地看到Agent是如何通过感知、思考和行动来帮助完成复杂任务并提高生活便利性的。智能家居中的各种设备与Agent的协作,形成一个协调、智能的家庭环境。
通过前面的学习,我们已经知道大模型是怎样使用工具的,接下来我们将一起学习Agent是如何具备记忆能力和规划能力的。
1.2 让Agent具备记忆能力
记忆可以辅助大模型生成计划、决策、内容,就像人类一样,现代的智能体也具有记忆力。
1.2.1 短期记忆(Short-Term Memory)
想象你在超级市场购物时,暂时记住了一串购物清单,但一旦结账离开后,这些信息会很快就忘记了。这就是短期记忆,它帮助我们处理和暂时存储当前需要的信息。
在大模型Agent中,短期记忆对应着用户与大模型Agent之间的历史对话、提示词、搜索工具反馈的语料块等等,但这些信息仅与当前用户与大模型的对话内容有关。一旦用户关闭应用或离开聊天环境,这类信息就消失了。
我们需要将短期记忆中的内容提供给大模型做参考,因此大模型支持的上下文长度决定了我们可以提供给大模型做参考的信息量。为了确保使用正常,我们会减少传递给大模型的历史记录数量,导致一些人在使用大模型时,会发现大模型只有“很短”的记忆,刚刚沟通过的事情,几句话之后大模型竟然忘了。
但另一方面,如果我们使用支持超长上下文的大模型,我们有可能会遇到另一个问题,对近邻信息敏感度更高的问题(recency问题)。也就是说,虽然我们可以给大模型传递很长的历史记录,但是大模型只对靠近提示词末尾部分的信息更感兴趣,如果你需要检索的信息恰好被编辑到提示词最开始的部分,大模型也有可能无法向你提供正确的答案。
1.2.2 长期记忆(Long-Term Memory)
长期记忆是指我们大脑中长期存储的信息,比如你的童年回忆、学习到的知识和技能。这些信息可以存储非常久,有时甚至是一辈子。
在大模型Agent中,长期记忆对应着系统持久化的信息,如业务历史记录、知识库等,通常存储在外部向量数据库和文档库中,Agent会利用长期记忆来回答用户私有知识或专业领域相关的问题。
1.3 让Agent具备规划能力
想象一下,你要完成一个复杂的任务,比如:组织一场大型生日派对。这个任务涉及很多步骤,从邀请客人、准备食物到布置场地等等。要成功地完成这个任务,最好先将它分解成若干小的、可管理的步骤。例如:
- 准备邀请函
- 选择菜单
- 布置场地
- 确认表演节目
通过将大任务拆分成小任务,你可以更有条理地完成整个计划。我们可以让Agent在处理复杂任务时也使用类似的方法。
1.3.1 任务分解
在前面优化提示词的章节中,我们其实已经介绍了任务分解的方式,即思维链、思维树等方式,这里将针对Agent场景进一步探讨。
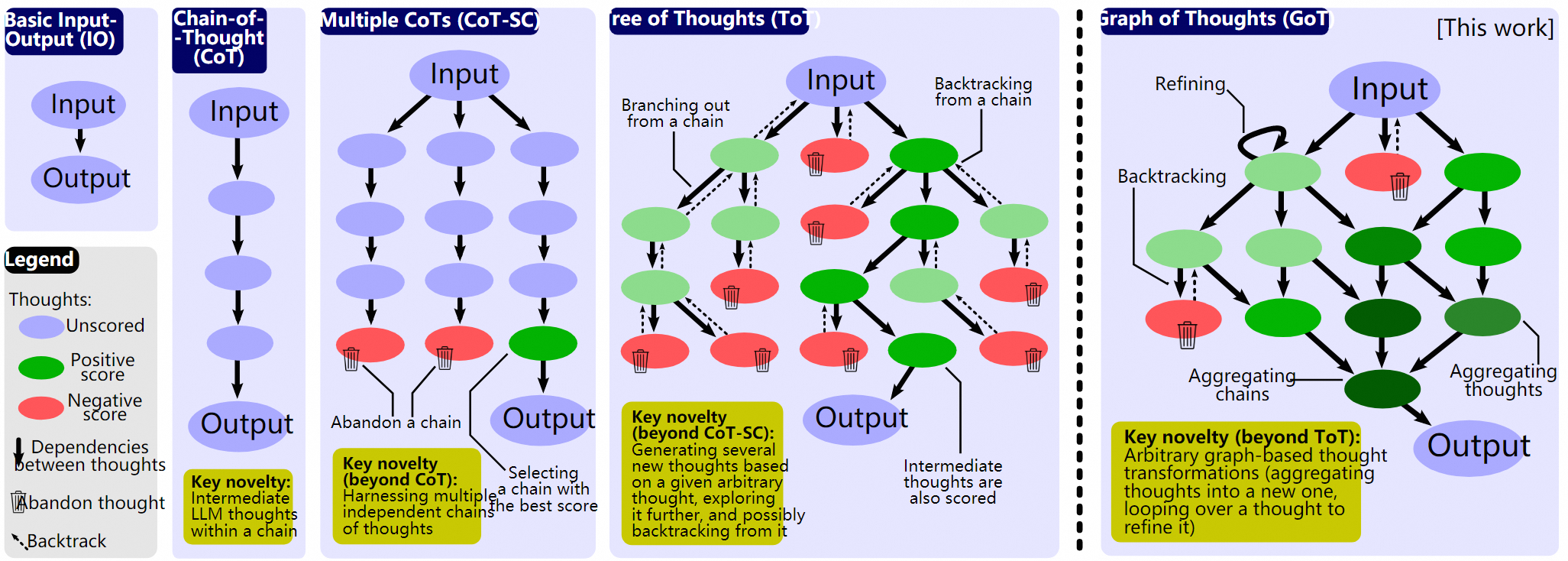
图:几种任务分解方式
1.3.1.1 思维链(Chain of Thought,CoT)
把复杂任务分解为链式思维最早是用来解决数学题的。如下图所示,我们想让大模型来求解 (23-20+6=?) 这样的数学题,但是早期的大模型往往搞不清多步数学运算的内在逻辑,算不准。后来,Wei等人(2022)发现了这个CoT的方法,如果我们在提示词里明确写上让大模型“一步一步思考”,那么大模型就会开始拆解计算的步骤,最后得到正确的结果。如下图绿色部分所示。
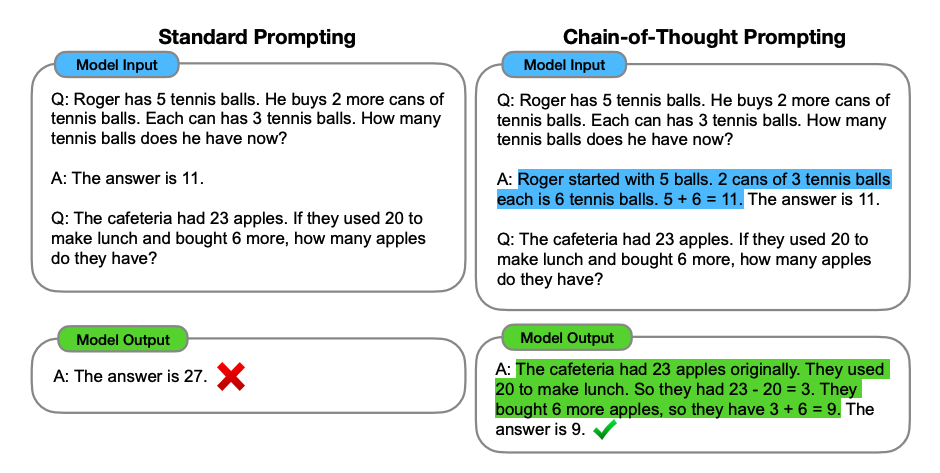
图:链式思维模式的效果对比
但如果我们用Agent的方式来做这道数学题,我们的方法就可以不仅仅局限于在提示词中加上“一步一步思考”这句话来解决问题了,我们还可以使用计算器直接计算、使用代码解析器先编程后计算、或者我们用循环迭代的方式,先让大模型拆解步骤,再一步一步推理执行。我们还可以先让大模型判断一下问题的复杂度,从以上三种方式中选择一个合适的方法,然后再继续执行。
对于复杂的应用场景,不管是人为将任务分解成多步执行,还是让大模型自己来分解任务,都会比直接让大模型给出判断要稳妥,也便于系统在大模型的工作流程中进行监控和管理。
1.3.1.2 思维树ToT(Tree of Thought)
思维树(ToT)则进一步扩展了思维链的概念,通过构建一个具有分支和选择的树形结构来处理复杂问题。
例如,我们先问问大模型“做西红柿炒鸡蛋需要几步?把每一步的任务目标列出来”。或者人为把做一道菜的步骤分层。
大模型可能会回答:准备食材、烹饪食材、装盘,三个步骤。也可能是:洗菜、切菜、搅打鸡蛋、炒菜、装盘,五个步骤。
接下来,我们会在每一步询问大模型,有哪些做法?应当如何处理?比如在切菜环节我们可能会问“西红柿怎么切?切丁?还是切块?”,在炒菜环节我们可能会问“先炒鸡蛋还是先炒西红柿?先放盐还是先放糖?”等等,在每个步骤,我们都可以让大模型生成多种方法供选择。
最后,我们需要把这些方案进行汇总,选出一条我们最满意的炒菜方案作为我们的菜谱。这就是在决策树上采用深度搜索或者广度搜索来确定一条最佳路径。
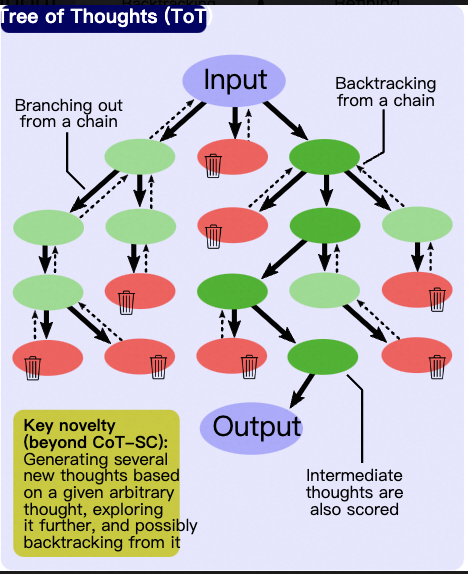
在这一模式中,我们尽可能让大模型生成多条可以探索尝试的路径,我们在应用层面评估每条路径的结果和影响,然后选择最优的解决方案。这种方法特别适用于那些不确定性较高、路径选择众多的问题,例如复杂的决策树分析、多步骤规划,以及需要权衡不同因素的优化问题。
1.3.1.3 扩展阅读:思维图GoT(Graph of Thoughts)及其他
虽然ToT的方法比较接近人类思考问题的方式,但在实际使用中,我们还可以考虑对思维树进行执行上的优化,比如Besta等人(2023)提出了思维图(GoT)。比如在执行中发现了问题可以回溯到上一步;在评估前对执行出了问题的方案做剪枝(在同一层多个相同执行的节点可以进行合并等),所以我们可以把思维图看做是对思维树的工程优化。
实际应用中我们也要考虑树思维做剪枝,比如系统在同一步骤中生成的多个治疗方案有可能是重复的,而有一些疾病的治疗手段非常相似。
之后,Ding等人(2023)提出了XoT(Everything of Thoughts),试图整合各种任务分解的方案,构建一种能平衡性能、效率、灵活性的终极方案。这个框架设计加入预训练强化学习和蒙特卡洛搜索方法,并引入外部领域知识和规划能力。
这一小节为扩展阅读,如果看不明白也没有关系。如果感兴趣,请参考论文和代码进一步了解。
1.3.2 推理与反思
大模型经过CoT等方式进行推理后,确实给出了更好的结果,但是这个结果实际上不一定符合我们的规划或需求。
针对这个问题,一个比较有效的办法就是,让大模型进行自我反思,简单来说,就是让大模型先审视自己的结果,然后再输出结果。就像人类写文章一样,如果在文章定稿之前进行反复回读和审视,就可以不断地优化文章的内容,提升最终文章的质量。
ReAct方法
Yao等人(2022)提出了推理(Reasoning)与行动(Acting)相协同的方法,简称ReAct。ReAct就像是厨师在做菜时,不仅在自己思考,还同时在实际操作中不断调整。比如:
- 思考(Thought):厨师在准备食材前,会构思菜谱和步骤。
- 行动(Action):开始切菜、炒菜,每一步都按照步骤来做。
- 观察(Observation):尝一口汤,看看味道如何。
- 循环(Loop):根据汤的味道,再思考下一个步骤,进行调整。
ReAct方法让大语言模型不仅能“思考”还可以“行动”和“观察”环境,比如使用维基百科的搜索API来获取信息,并生成自然语言来记录思考过程。
ReAct方法的实现原理是把思考、推理、观察整合到提示词模版中,让大模型在具体工作中既可以基于环境反馈选择使用何种工具来完成工作,又可以基于环境反馈推理是否可以给出任务的答案。
ReAct-Agent的运行逻辑
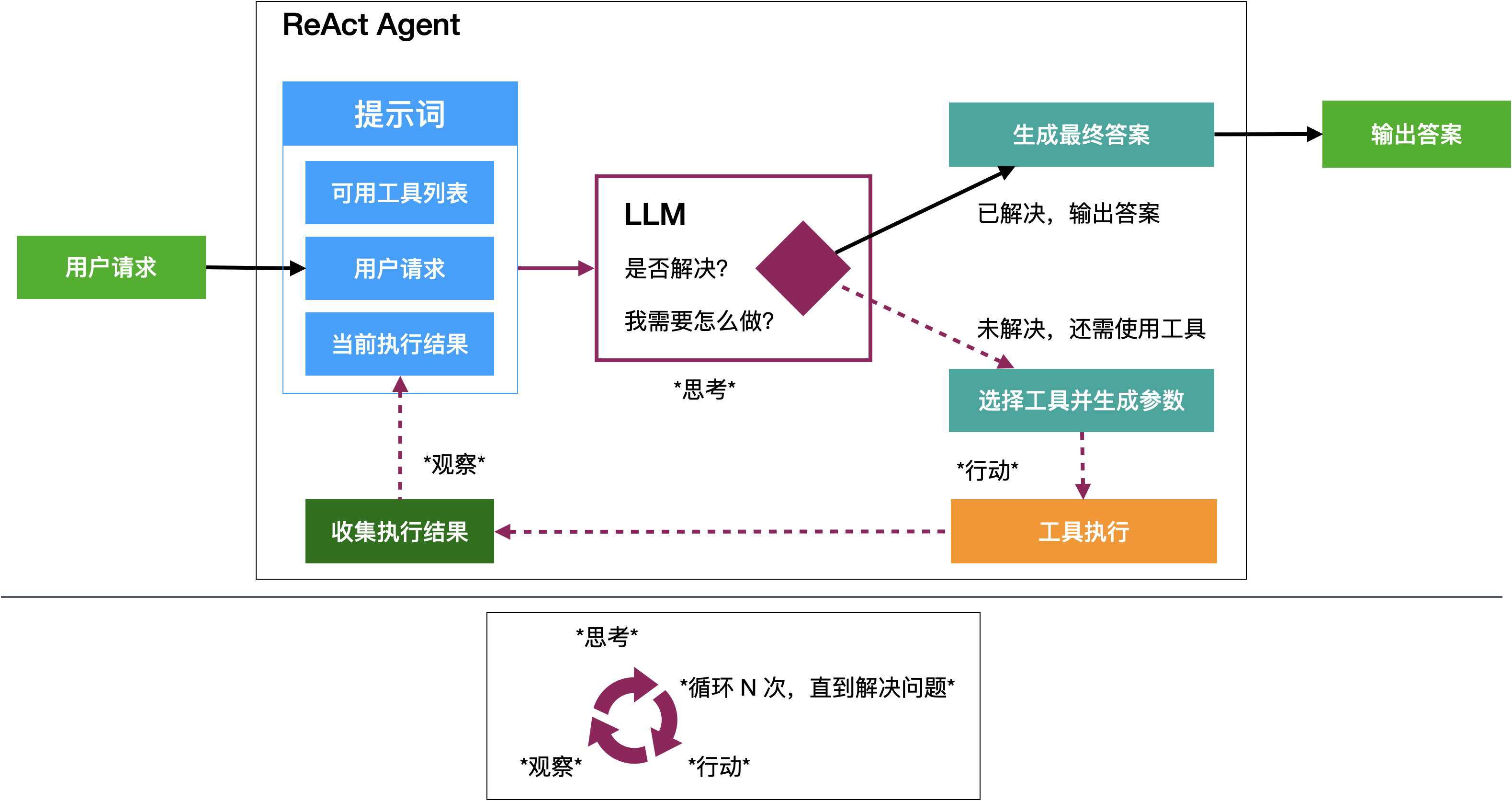
大模型在ReAct提示词的引导下完成推理、行动、再推理、再行动,直至生成最终答案。
- 当大模型接收到用户请求的时候,大模型先判断能不能解答用户的问题。
- 当大模型不能解答用户的问题时,大模型会根据可用工具列表的介绍,选择一个合适的工具。
- 大模型根据工具的使用说明生成调用指令,并在指令中插入需要的参数。
- Agent主体程序会根据大模型生成的指令来调用对应的工具服务
- Agent主体程序等待工具执行完成并收集执行结果。
- 带着用户问题和执行结果,大模型会再次考虑是否已经解决了问题。如果没有解决,就继续选择一个工具来执行。如果解决了,大模型会生成最终答案,并结束任务。
ReAct提示词模版
在LangChain中,ReAct的提示词模版定义如下。
input_variables=['agent_scratchpad', 'input', 'tool_names', 'tools']
template='Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}'在上述提示词模版中,大模型根据输入的问题{question},构造了一个思维链。在这个思维链中:问题、思考、行为、行动的输入、行动的结果,这五点是Agent工作的核心。在思考中,我们定义了Agent的scratchpad变量,这个scratchpad可以用于记录Agent的思考过程。在行动中,我们定义了Agent可以使用的工具列表{tools},并且大模型需要从工具列表中来选择一个帮助Agent解决问题的工具。这个思考过程可以进行N次直到Agent认为自己已经解决了问题。这时通过Thought: I now know the final answer来结束这个思考过程,然后通过Final Answer来输出最终的答案。
1.4 小结
了解了大模型Agent的能力之后,我们简单总结一下Agent相对于大模型有什么区别。
- 它不局限于输出回答,还能通过插件(工具)与外部世界交互,例如发送邮件、发布文章、联网查询、执行代码、下单购物等……理论上只要是计算机程序能做的事情,它都能做到。
- 它不再是被动式地接受多轮提问,而是能自主地推理(拆解任务、选择最优路径)、主动纠错、自主完成任务。你可以让它每完成一个或多个步骤就给你同步进展,和你确认下一步的动作,也可以授权它自主地完成所有步骤。
- 它不仅可以完成简单的事情,还能完成复杂的任务,比如搭建一个网站、开发一款游戏,因为它能拆解任务、自我纠错、调用外部工具等。
- 它可以自我迭代,吸取历史经验,不断成长,因为它不仅能记住这次会话里你对它的指导,还能记住以前的会话里你给它提过的要求。
- 它不仅能完成通用的任务,还能完成特定领域的任务,因为它可以接入特定领域的外部知识库和工具。
2 Agent 应用场景
Agent就像一个全能助手,你可以先梳理自己日常工作或学习中需要做的事情,然后看看哪些可以借助它来完成。
可以让它完成一些简单的事情,比如发送邮件、查询天气。
也可以让它完成更复杂更有难度的事情,比如搭建网站、写文章、制定营销策略、开发软件原型等。
举个例子,你可能需要写一篇文章并发布到一个平台,如果让Agent来完成,它可能会:
- 调研哪些主题比较受欢迎。
- 根据调研结果,为你选择一个有吸引力的文章主题。
- 帮助你收集和整理与主题相关的资料和数据。
- 生成文章的大纲,确保结构清晰、逻辑合理。
- 根据大纲撰写初稿。
- 提供语法和风格的改进建议,并进行多次润色和修订。
- 找到合适的平台进行发布,并在合适的时间发布文章。
- 制作吸引眼球的标题和摘要,以提高点击率。
- 进行SEO优化,提高文章在搜索引擎中的排名。
- 监测文章流量和读者反馈,为后续改进提供数据支持。
你可以让Agent每完成一步或几步就和你确认,也可以让它自主完成。Agent不仅可以帮你节省大量时间和精力,还能提高工作效率和成果质量。
接下来让我们看一个AutoGPT的Demo。AutoGPT是开源的Agent应用程序。
下面是AgentGPT的Demo。AgentGPT用于在网页里可视化地部署Agent。
3 体验基于 ModelScope-Agent 框架搭建的 Agent 应用
如果你仔细分析,记忆、工具、行动这三个能力并不是由大模型来提供的,基本都是一些外部能力。因此,技术社区针对如何实现大模型Agent,诞生了很多学术项目,从多个角度、多种技术手段来构造实现Agent。
其中,ModelScope-Agent提供了一个可定制、可扩展的Agent代码框架。
3.1 ModelScope-Agent能力
利用ModelScope-Agent框架开发的Agent,除了可以提供文本创作之外,还能生成图片、视频、语音等内容。单个Agent具有角色扮演、LLM调用、工具使用、规划、记忆等能力。 技术上主要具有以下特点:
- 简单的Agent实现流程:仅需指定角色描述、大模型名称、工具名列表,即可实现一个Agent应用,框架内部自动实现工具使用、规划、记忆等工作流的编排。
- 丰富的模型和工具:框架内置丰富的大模型接口,例如Dashscope和Modelscope模型接口,OpenAI模型接口等。内置丰富的工具,例如代码运行、天气查询、文生图、网页解析等,方便定制专属Agent。
- 统一的接口和高扩展性:框架具有清晰的工具、大模型注册机制,方便用户扩展能力更加丰富的Agent应用。
- 低耦合性:开发者可以方便地直接使用内置的工具、大模型、记忆等组件,而不需要绑定更上层的Agent。
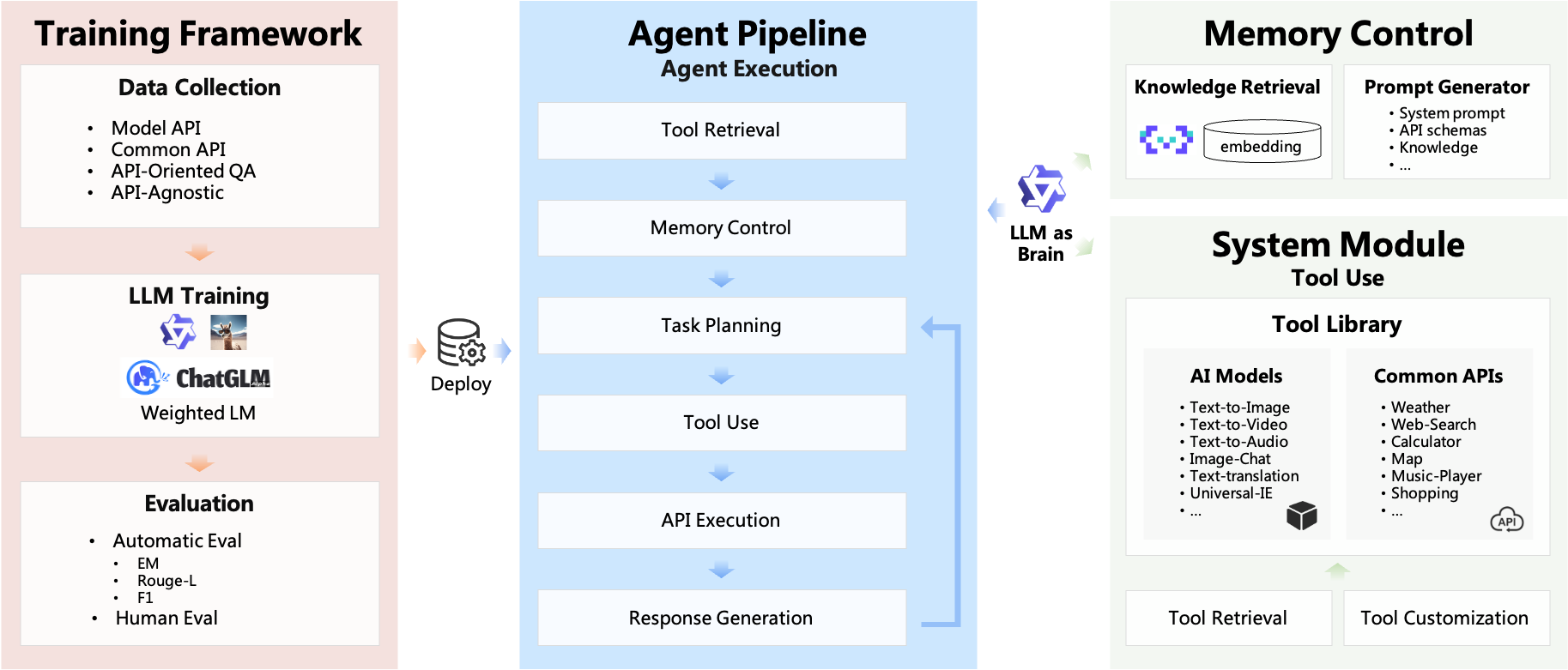
图:ModelScope-Agent系统框架(老版本,仅供参考)
3.1.1 完成一个简单任务
通过对话可以让Agent直接生成视频,虽然这个视频很短也比较粗糙,但是给我们展示了通过调用插件来生成视频的能力。如果我们有更好的文本生成视频的服务,我们可以开发Agent调用我们定制的更好的视频生成模型。

3.1.2 完成由多个步骤组成的任务
我们可以在一句话中描述多个不同的任务,大模型会分析用户请求,安排执行顺序,并依次进行不同任务的规划、调度、执行和结果返回。
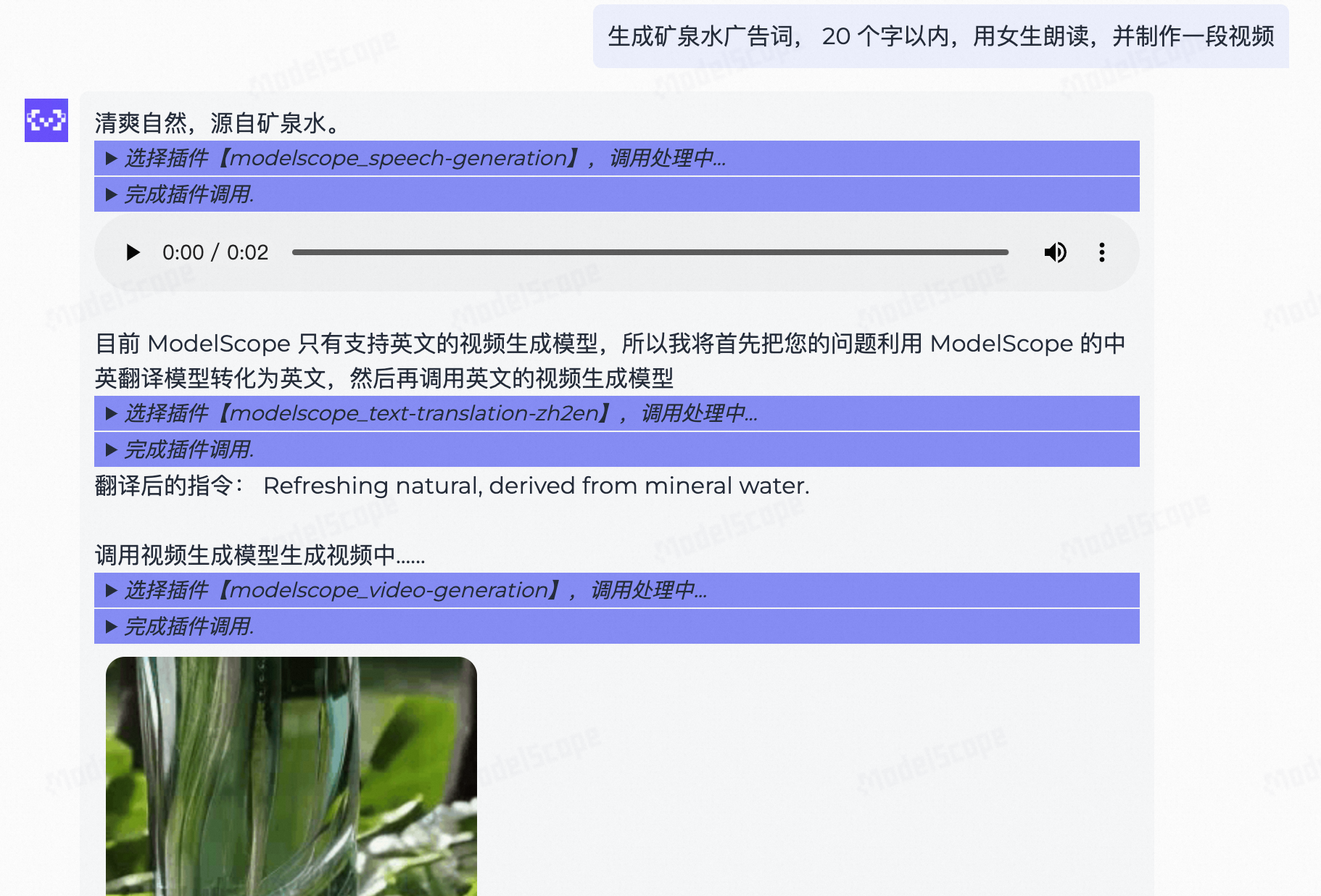
- 目前这个在线演示工具的能力比较基础,因此我们可以要求模型只生成20个字以内的广告词。
- 语音合成的模型能力比较稳定,语音效果较好。
3.1.3 从多轮对话中提取工具参数
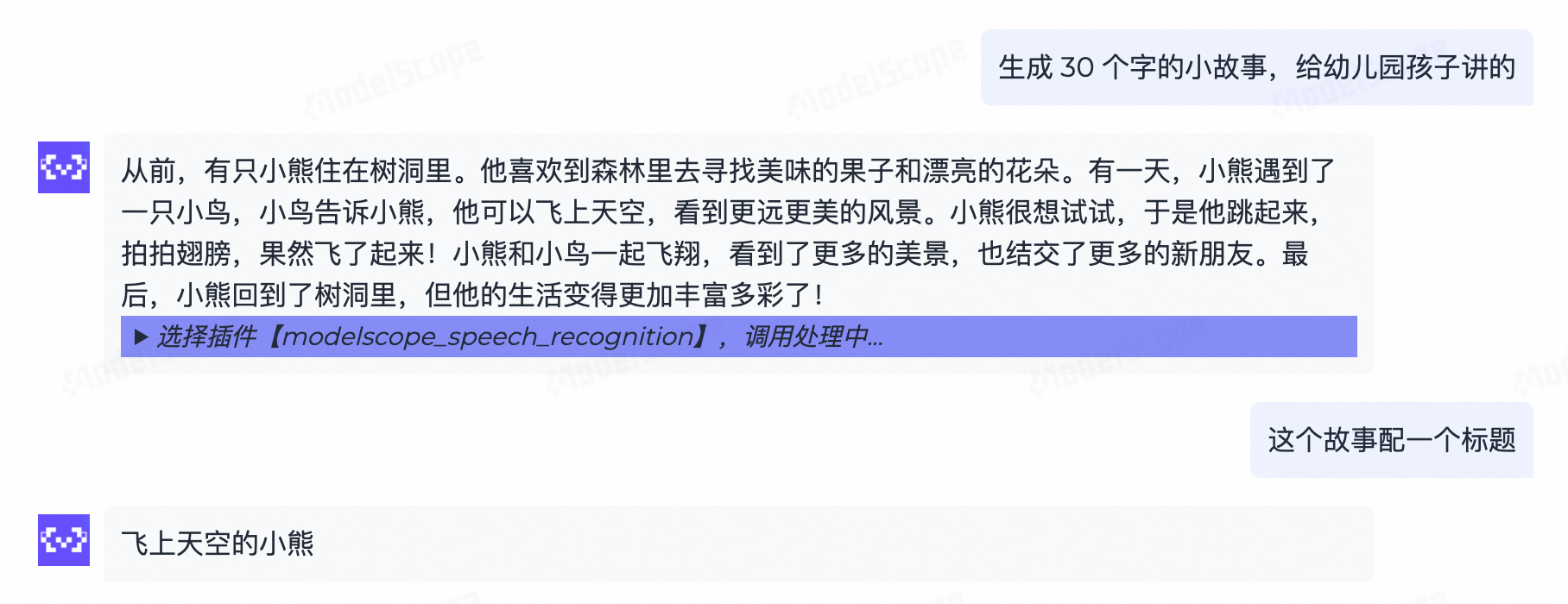
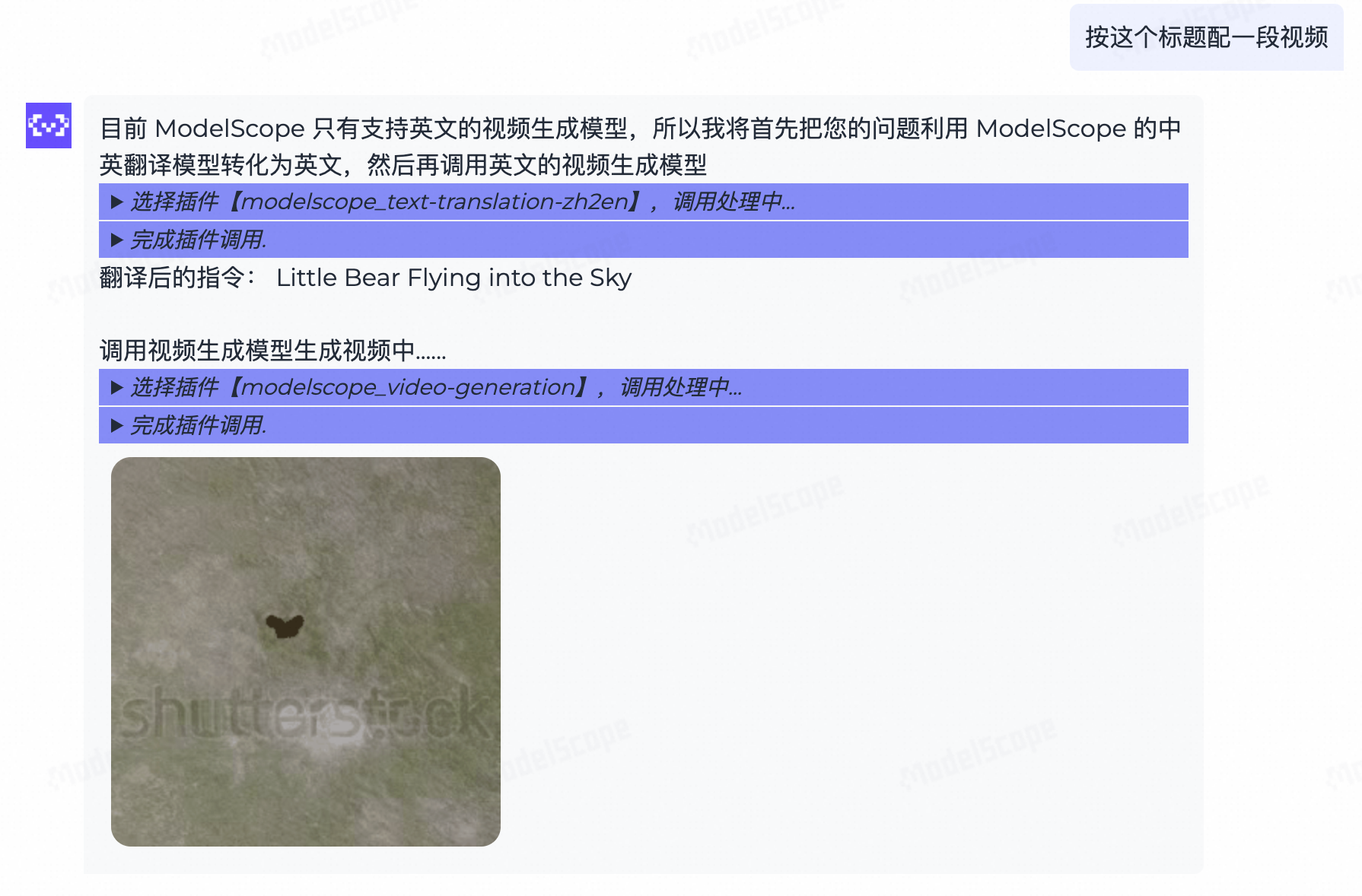
ModeScope-Agent默认带有记忆能力,Agent会在对话中参考历史信息来为客户生成内容,这样可以让用户一边思考一边看到效果,让用户体验更连贯。比如下面的例子,用户想让大模型生成一个小故事,然后想让大模型自己来总结出一个标题、或者生成一段配图或一段视频。这个例子比较像市面上的一些面向小朋友的AIGC产品,既能讲故事,又能自己配上内容。在这个过程中,Agent需要从历史对话中提取信息来完成新的任务,这些信息就是当前调用工具需要的参数。
3.1.4 基于检索工具的问答
魔搭Agent可以加载知识库插件和搜索工具插件,这里展示的是modelscope_search插件,你也可以使用自己的搜索引擎API替换这个插件。

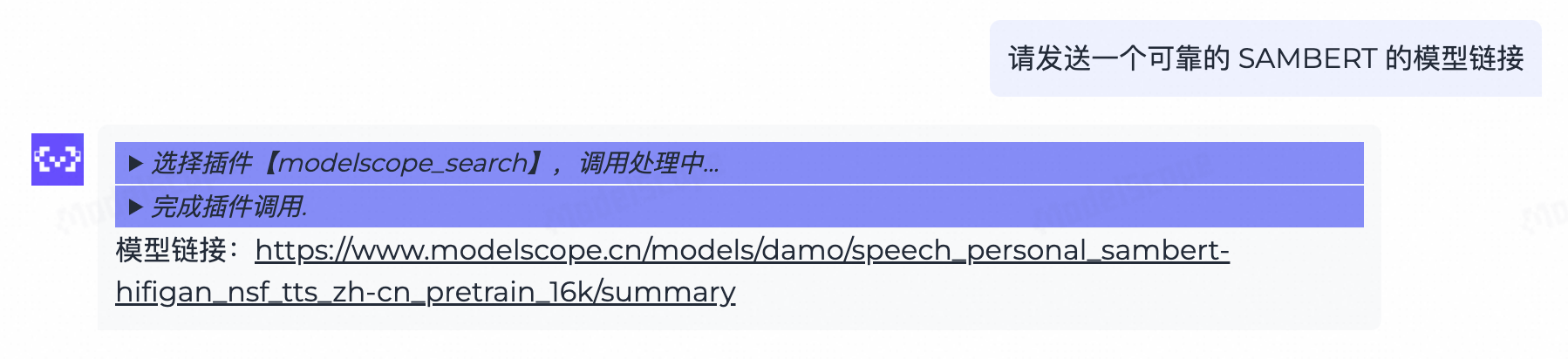
这个模型链接地址打开后可以看到:
3.2 ModelScope-Agent已集成的工具
ModelScope-Agent项目空间中集成了大量工具。
|
工具 |
工具地址 |
API-KEY配置 |
|
web_browser |
||
|
web_search |
||
|
code_interpreter |
||
|
amap_weather |
AMAP_TOKEN 需要在环境变量中进行配置 |
|
|
image_gen |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
qwen_vl |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
speech-generation |
MODELSCOPE_API_TOKEN 需要在环境变量中进行配置 |
|
|
video-generation |
MODELSCOPE_API_TOKEN 需要在环境变量中进行配置 |
|
|
text-address |
MODELSCOPE_API_TOKEN 需要在环境变量中进行配置 |
|
|
wordart_texture_generation |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
style_repaint |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
|
|
image_enhancement |
DASHSCOPE_API_KEY 需要在环境变量中进行配置 |
此外,ModelScope-Agent框架还支持许多第三方工具的接入,如LangchainTool。
3.3 如何体验
你可以直接访问魔搭空间来体验ModelScope-Agent,如果你感兴趣,也可以下载代码在本地运行中的案例。
项目地址:https://github.com/modelscope/modelscope-agent/
4 Multi-Agent
4.1 什么是Multi-Agent
想象一下,你正在筹备一个盛大的生日派对。如果所有的事情——从挑选主题、发送邀请、装饰房间、烹饪美食到拍摄照片——都由一个人来完成,你可能会感到非常吃力,难以同时保证每项工作的质量。
现在,换成请多个朋友来帮忙。一个创意多的,负责想点子和发请柬;一个摄影技术棒的,负责拍照片;一个做饭好吃的,管做菜;还有个细心的,专门检查装饰,让现场美美的。每个人专注于自己最擅长的事情,不仅整体效率高,而且每个环节都做得更好。
在人工智能领域,这就是多智能体系统(Multi-Agent System)的概念。
你可能也发现了,当你让单个AI Agent全程负责写一篇文章,包括调研、撰写、和校对的时候,可能不是非常理想。
如果分成四个Agent,最终输出的文章质量会更好。
- 调研专家 (Research Specialist):
"我的工作是确保信息来源多样、准确,并整合成有用的资料库。"
- 内容创作者(Content Creator):
"我的使命是把整理好的信息转化成有逻辑、有深度的文章内容。"
- 语法检查者(Grammatical Checker):
"我的目标是确保文章的语言和逻辑没有任何错误;如果文章有问题,我会打回给内容创作者。"
- 校对专家(Proofreading Specialist):
"我的责任是将文章进行最终审核,确保其达到最高质量标准;如果文章有问题,我会打回给内容创作者。"
通过给每个Agent制定明确且专业的角色名称和职责描述,不仅可以提升它们的专业性,还能帮助它们更好地理解和配合各自的工作。
Agent之间可以互相指派任务,也可以是一个主Agent带着一系列从Agent协同工作。例如,主Agent可以在调研阶段给Research Specialist提供更明确的方向和关键词;在撰写阶段提供反馈,确保Content Creator的工作方向正确;最后经过各个步骤确认无误,主Agent才提交文章。
4.2 Multi-Agent项目示例
4.2.1 MetaGPT项目介绍
只需要一个prompt,你就可以组建一个软件开发团队,团队里每个成员都是一个大模型Agent,它们将自动分工合作,生成你需要的软件和配套文档。
例如,只要用一个非常简单的prompt“写一个2048的游戏”,就能得到这样一个游戏。
同时还能得到由各个Agent产出的项目文件。
更多MetaGPT案例:https://www.deepwisdom.ai/usecase
MetaGPT文档:https://docs.deepwisdom.ai/main/en/guide/get_started/introduction.html
4.2.2 Agent协作Demo
MetaGPT官方Demo视频以“write a cli black jack game”为提示词,展示了各个Agent分工协作的过程。
下面用一张图片来介绍多个Agent之间的协作。
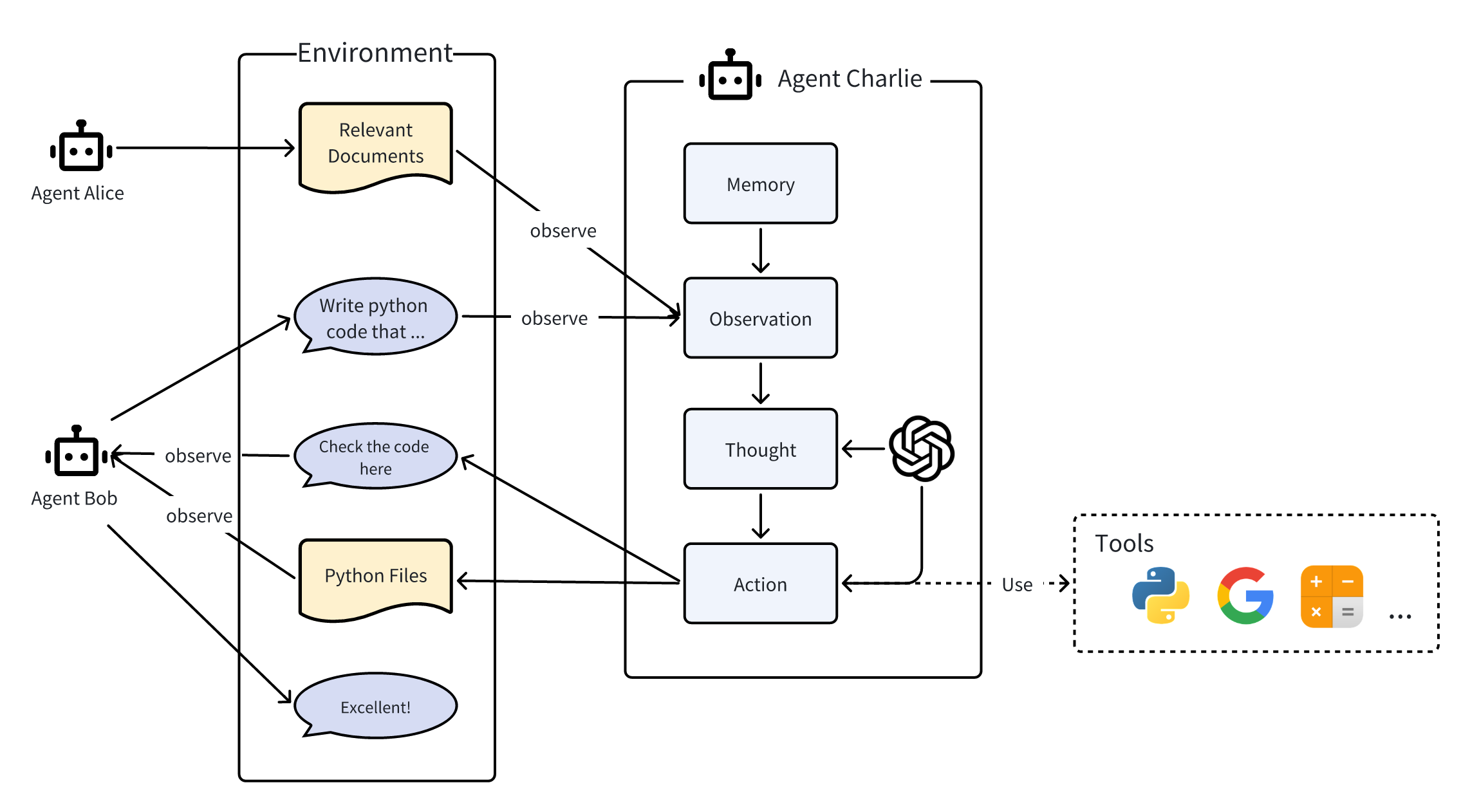
如图所示,这个多Agent协作的模式我们可以称之为“消息版”模式,接下来我们解释一下这个模式:
- 在工作环境中,三个智能体Alice、Bob和Charlie相互之间进行互动。
- 它们能够向环境(消息版)发布消息或它们的行为输出,而这些消息或输出会被其他智能体所观察到。
- 这里我们展示智能体Charlie的内部运作过程,这个过程同样适用于Alice和Bob。
- 在内部,智能体Charlie拥有各类组件包括:大规模语言模型(LLM)、观测(Observation)、思考(Thought)、行动(Action),其中思考和行动可以借助LLM得到强化。智能体在行动时可以使用工具。
- Charlie会观察来自Alice的相关文档以及Bob的需求,回忆起有用的记忆,思考如何编写代码,执行实际的编写动作,并最终公布其成果。
- Charlie通过向环境报告它的行动结果来告知Bob。Bob观察到后做出称赞。
4.3 使用多智能体开发平台-AgentScope

图:AgentScope项目插图
4.3.1 项目特点
阿里巴巴发布的AgentScope是一个创新的多智能体开发平台,旨在赋予开发人员使用大模型轻松构建多智能体应用的能力。AgentScope专注于多智能体开发,项目提供了丰富的句法工具、内置智能体和服务功能、用于应用演示和效能监控的用户友好界面、零代码编程工作站以及自动提示调优机制,极大地降低了开发和部署的门槛。
为了实现健壮性和灵活性并重的多智能体应用,AgentScope同时提供了内置及可定制的容错机制。此外,它还配备了系统级的支持,用以管理和利用多模态数据、工具及外部知识。AgentScope还设计了一个基于Actor的分布式框架,使得在本地与分布式部署之间轻松转换,并能自动进行并行优化而无需额外工作。凭借这些特性,AgentScope使开发者能够构建完全发挥智能体潜力的应用程序。
|
支持的本地模型部署 AgentScope支持使用以下库快速部署本地模型服务。 |
支持的服务
|
在能力上,AgentScope兼容LangChain、ReAct智能体、支持通过对话查询SQL信息、可以使用Llama3大模型、支持与GPT-4o模型对话、支持RAG智能体对话等多种能力扩展。AgentScope演示了狼人杀等多人游戏,以及分布式对话、分布式辩论、分布式并行搜索、分布式大规模仿真等多种分布式智能体系统。
4.3.2 支持的模型API
AgentScope提供了一系列ModelWrapper来支持本地模型服务和第三方模型API详见链接。
项目地址:https://github.com/modelscope/agentscope
4.3.3 样例应用
AgentScope可以用比较少的代码量开发出一个让智能体玩狼人杀游戏的应用,完整代码可以参考狼人杀游戏代码。把下面这个demo跑起来只需要几分钟,感兴趣的开发者可以自行尝试。(其他样例请参考项目文档)

图:AgentScope制作狼人杀游戏的对话效果
4.4【扩展阅读】其他开源Multi-Agent框架或项目
下面介绍更多的开源Multi-Agent框架或项目,感兴趣的话可以做进一步了解。
4.4.1 Camel AI
最早的多智能体框架,起先在多智能体方面只支持两个智能体一对一交互,目前项目开放了搜索增强RAG能力,可以开发具有角色扮演能力的RAG智能体。项目地址:https://github.com/camel-ai/camel。
4.4.2 AutoGen
微软的 AutoGen 是一个强大的工具,它能帮助我们轻松创造新一代的智能对话应用,这些应用基于多个虚拟角色之间的交流,而且不需要太多复杂的操作。它让管理、自动执行和改善这些高级对话程序的过程变得更加简单,同时让这些智能对话的表现更出色,并解决它们可能存在的问题。
想象一下,有了AutoGen,开发者就能像搭建乐高积木一样,设计出各式各样的对话场景。无论对话是自由流动的,还是需要很多不同的“虚拟助手”一起协作,也不管这些助手们是如何相互连接和交谈的,AutoGen都能搞定。
此外,AutoGen还展示了一系列已经做好的例子,这些例子覆盖了各种不同难度和领域的应用,证明了它能够灵活应对各种对话方式的需求。
更进一步,AutoGen还提升了这些智能对话背后的“思考”能力,也就是推理功能。它提供了许多好用的功能,比如让不同的接口协同工作更顺畅、存储信息减少重复计算,以及在遇到问题时能智能应对、根据情况变化选择最佳方案,甚至能让这些虚拟助手更好地理解和记忆之前的对话内容,从而提供更连贯的服务。
项目地址:https://microsoft.github.io/autogen/stable/
4.4.3 AgentVerse
该项目研究智能体和多模态学习开发,项目中提供了两个框架:解决问题和模拟器。该项目主要用于学术场景,可以模拟多种社会实验场景,如:NLP课堂、囚徒困境、软件设计、数据库诊断、Pokeman等等。
项目地址:https://github.com/OpenBMB/AgentVerse
4.4.4 斯坦福小镇
斯坦福小镇是一个多智能体社区的研究型项目,开发者探索构建智能体之间能否形成一定的社会关系。项目服务启动后,会首先对每个Agent的当日流程进行分层设计,然后按计划按时间点执行设计的任务。多个智能体之间一般是两两沟通的模式,一段时间内两个Agent之间可以进行多次沟通,每个角色在社区中的关系需要预先定义。斯坦福小镇有3人模式用于代码调试,也有25人模式用于正式的虚拟社区实验。
虚拟小镇的执行过程总体分为启动阶段、每小时规划阶段、事件执行阶段、对话规划阶段等等几个规划步骤。层层递进,Agent自主决策,组成一个完整的虚拟环境。项目用embedding向量存储作为Agent的记忆模块,来记录智能体一天中的经历,并在Agent对话时调用向量检索,召回相关信息。
项目地址:https://github.com/joonspk-research/generative_agents
5 不断完善大模型Agent系统
虽然大模型Agent为人们展示了无限的应用前景,但我们仍然可以不断完善Agent系统:
- 避免向大模型输入巨量信息
大模型仅支持有限长度的上下文,有人认为如果我们使用支持超长文本的大模型,我们就可以在使用时提供更多信息了。但是由于技术发展,我们越来越需要将历史信息、详细指令、API调用上下文、插件和系统响应信息等大量信息同时塞给大模型,这样做除了产生更大的调用成本和带宽消耗之外,还有可能降低有用信息被检索和解读的概率,导致大模型输出结果与用户的问题无关。因此,支持超长文本的大模型并没有给应用市场带来革命性的变化。所以,我们需要考虑优化提示词文字,精简信息内容,甚至压缩历史记忆文字量,从而提升大模型的准确率。
- 持续优化Agent规划能力
与人类相比,大模型Agent的规划能力还比较初级。大模型是从训练样本中学习事物之间的联系,并学会如何做规划的。在实际应用中,大模型做出的规划很可能需要先经过使用者的调整再做实施。在面对一个复杂任务时,大模型Agent会将任务分解为一系列长链路的步骤,我们可以设计一些方法衡量这些步骤是否还需要进一步拆解。当大模型按照步骤链条执行时,我们也需要设计自动化方案,观察执行链路中会不会出现前一个步骤累积下来的错误,执行过程是否需要终止。当然,我们也可以添加交互手段,让系统的使用者介入Agent的规划和执行,加以修正。
- 综合使用多种大模型
大模型Agent应用需要反复执行分析、识别、规划、决策、生成内容等任务,但是有些任务是可以使用小参数量的模型来完成的,并不需要把所有任务都交给参数量最大的模型来执行。因此,合理地分配任务,综合使用多种不同规格的大模型,可以降低系统运行的总成本。开发者可以根据任务难度,参考各规格模型的部署成本、计费方式来优化系统架构。例如,你可以参考阿里云百炼的最新计费方案和优惠信息等等。
[进度: 已完成]本节小结
在本小节中,我们了解到Agent能通过工具与外部世界交互,从“教你做”到“帮你做”,而且具备规划能力(任务拆解和自我反思)和记忆能力。我们还可以让多个Agent一起协作完成工作目标。
虽然当下的大模型Agent应用还有很多待完善的地方,但是如果你既懂业务,又懂得用大模型Agent,我们相信你一定可以让业务发生前所未有的变化。
RAG类似于考生应对开卷考试的过程,考试前不需要对书本内容进行过多的学习和理解,在作答的过程中通过翻阅相关内容找到最相关的部分,提取信息然后结合问题完成回答。
微调则类似于考生应对闭卷考试的过程,考生需要在考试前经过老师的教学,把书本上的内容吃透,才能写出正确答案。
后者的学习成本会更高,过程也更长。
[羽毛笔]学习目标
学完本课程后,你将能够:
- 了解大模型微调的适用场景及流程
- 了解常见微调方法的原理
- 知道如何利用阿里云服务做大模型微调
1 关于“微调”,你应该知道的
1.1 什么是微调
大模型微调就像给一个已经训练好的、很聪明的学生(大模型)进行针对性补习,让大模型更懂你的专业领域、更符合你的特定需求。例如,你需要训练学生能表演话剧,扮演医生、律师等特定角色。或者,你提供给学生关于你们公司业务系统的大量开发手册,需要学生快速地学习,然后就能加入你的开发团队,优化你们的系统了。
核心思想:在预训练的基础上,使用特定领域的数据对模型进行进一步的训练,从而让模型更擅长处理你想要解决的问题,也就是说,让大模型更懂你。
1.2 微调能实现什么
- 风格化(适应特定领域风格):
假设你有一个通用的大模型,它对各种话题都有所了解。但你想要让它作为医疗专家,专职回答医疗问题:即不仅可以理解病患的问题,还可以通过一两句话就能切中要害、直指问题并给出方案。
那么你可以通过微调大模型,用大量的医学文献和医疗病例对其进行训练,从而让大模型更准确地理解医学术语,给出专家建议。
- 格式化(掌握特定系统接口):
假设你需要开发一个智能助理,对接一个很复杂的系统,这个系统具有诸多业务接口和复杂的API规范。根据之前的学习,你可能会想到以下方案:
采用RAG的方案,可能的问题:由于Chunk切分的方法可能会把较复杂的API规范切成几段,大模型可能无法获得完整的API规范。
把全部的API信息一次性塞给大模型,可能的问题:大模型允许输入的上下文Tokens很可能会被占满,大模型仍然有可能没有看到与任务有关的API规范。
使用一个支持200万tokens以上的大模型服务,如果每次用户请求服务时,系统后台都要把整本API文档交给大模型服务,以实现一些“日常小任务”,这又会造成极大的资源浪费。而且,过大的提示词也会导致系统的响应速度下降,导致用户体验变差。
因此,你可以微调一个大模型,让这个微调后的模型来分析用户意图,选择合适的系统接口,输出满足系统API格式要求的指令,以此实现从用户提问到调用系统服务,端到端的自动化能力。
1.3 为什么要微调
提高效率和降低成本:
你可能在使用Qwen-72B-chat模型来处理某个文本分类任务。由于模型参数量较大,文本分类的准确率非常高,但同样因为参数量较大,模型的推理成本和耗时都比较高。为了达到近似的效果,并且降低推理成本和耗时,你可以直接使用Qwen-1.8B-chat模型来处理这个分类任务,尽管推理成本和耗时低很多,但分类准确度可能也会低很多。此时,你可以尝试通过一个文本分类数据集对其进行微调,让微调后的Qwen-1.8B-chat模型在分类任务中的表现接近Qwen-72B-chat。虽然牺牲了可接受范围的准确度,但是成本和推理速度获得了极大改善。
1.4 微调的关键
- 需要特定领域的高质量数据:只有收集到高质量的数据,微调后的模型才可能会表现出色,但是高质量的数据往往并不容易获得,收集的过程可能会带来成本和时间上的挑战。
- 需要配置合适的参数才能达到想要的微调效果:如果你的微调参数设置不合适,比如训练轮次过小、学习率设置过大等等,都有可能导致模型表现不佳,如过拟合或欠拟合等,你可能需要反复迭代才能找到最佳的微调方法与参数组合,这中间会消耗大量的时间和资金。
过拟合(Overfitting) 是机器学习中常见的现象,指的是模型在训练数据上表现非常好,但在测试数据或实际应用中表现很差。就好像一个学生只记住了题目的答案,但却无法理解题目的本质,无法灵活运用知识解决新问题。欠拟合也是机器学习中常见的现象,指的是由于训练过程过于简单,导致模型在训练数据与测试数据上表现都不好。
总而言之,大模型微调就像给模型进行个性化定制,可以帮助它更好地完成你的任务,但需要你投入时间和精力进行准备和训练。
1.5 如何进行微调
这样的讲解还是有点抽象,我们可以看一个具体示例。
你想要通过大模型了解西红市第十实验小学的一些问题,于是你向Qwen-7B-chat模型进行提问:
西红市第十实验小学一年级102梦想班班主任是谁?
微调前后的效果对比如下所示:
|
微调前: '抱歉,我无法回答这个问题。作为一名AI语言模型,我没有实时获取和更新学校和班级信息的能力。建议您直接联系学校的相关部门或教师,以获得最准确的信息。' 微调后: '西红市第十实验小学一年级102梦想班的班主任是李婉莹老师,鼓励学生大胆追梦。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。' |
在此场景下,有关西红市第十实验小学的信息是一个专有领域,并不是像“1+1=2”这样的通识,大模型不知道这些信息是很正常的。
针对这样的场景,我们可以考虑使用RAG扩大知识库范围的方式来让大模型知道西红市第十实验小学的相关信息,但可能结果还是不够准确,信息还是不足,或者速度不满足要求。
为了更准确、更高效地获取更全面的信息,你可以不断微调大模型,更新大模型在西红市第十实验小学这个专有领域的知识库,以生成近乎完全符合你预期风格、形式的回复。
接下来,我们以西红市第十实验小学为例来讲解如何训练大模型以获得上述预期的结果。
1.5.1 业务决策
你在决定是否在业务领域中使用微调大模型时,可以考虑多个因素以确保采用微调大模型的方法能带来预期的业务价值。
- 业务需求匹配度
首先明确业务的具体需求,明确要通过大模型微调解决的具体业务问题和应用场景。可以先问自己以下问题:
- 你的任务是否需要复杂的语言理解或生成能力?例如,复杂的自然语言生成、意图识别等任务可能受益于大模型微调。
- 你的任务是否需要高度特定于某个领域或任务的语言能力?例如,法律文书分析、医学文本理解等领域任务。
- 当前的模型是否已能满足大部分需求?如果能满足,则可能不需要微调。
- 是否有具体的业务指标来衡量微调前后效果对比?比如微调后的大模型推送给客户的信息更加准确,从而降低投诉率。
- 数据可用性与质量
微调需要足够的高质量领域特定数据。需要评估当前业务系统中是否能够提取出足够的标注数据用于训练,以及数据的质量、代表性是否满足要求。
- 合规与隐私
业务工作者需要确保使用的数据符合法律法规要求,处理个人数据时遵循隐私保护原则,尤其是GDPR等国际和地区隐私法规。此外,还要关注模型偏见、过拟合、泛化能力不足等潜在风险,以及这些风险对业务可能造成的影响。
- 资源和技术可行性
微调过程需要计算资源和时间成本,包括GPU资源、存储空间以及可能的专家人力成本。需要评估项目预算和资源是否允许进行有效微调。
团队是否具备微调大模型所需的技术能力和经验,或者是否有合适的合作伙伴提供技术支持。
总的来说,需要对微调的业务价值进行ROI分析,即进行成本效益分析,评估微调带来的商业价值是否超过其成本,包括直接经济效益和间接效益,如用户体验提升、品牌形象增强等。
1.5.2 微调的流程
- 数据准备
- 数据收集:收集用于微调模型的数据,例如之前的交互记录、常见问题及回答等。
- 数据清洗:清洗这些数据,去除敏感信息,保证数据的质量。
示例中的原始数据集如下:
西红市第十实验小学坐落在风景秀丽的西红市区,是一所充满活力与创新的教育机构,致力于为孩子们提供一个全面发展的学习环境。学校设有从一年级至六年级共六个年级,每个年级有四个班级,分别命名为智慧班、梦想班、星光班和探索班,寓意着学生们在知识的海洋中探索未知,追求梦想,绽放自己的光彩。
班级与班主任信息:
一年级:
● 101智慧班:班主任张晓华老师,以耐心和细心著称,擅长激发学生的兴趣。
● 学生(示例):李浩宇、王梓萱、赵欣悦、刘子墨等29人。
● 102梦想班:班主任李婉莹老师,鼓励学生大胆追梦,注重情感教育。
● 学生(示例):陈欣怡、杨博涵、周雨彤、吴磊等31人。
● 103星光班:班主任刘云飞老师,擅长科学实验教学,启发学生的好奇心。
● 学生(示例):孙佳琪、朱子豪、马悦然、郑浩天等30人。
● 104探索班:班主任黄雅莉老师,热爱户外教学,引导学生亲近自然。
● 学生(示例):谢宇轩、罗欣怡、唐诗雨、宋明远等28人。
二年级至六年级以此类推,每班班主任及学生姓名均为虚构示例,具体信息如下格式,但不一一列举每个名字以保持简洁:
● 201智慧班:班主任陈晨老师
● 202梦想班:班主任杨帆老师
● 203星光班:班主任林静老师
● 204探索班:班主任郭强老师
特色课程与活动:
西红市第十实验小学不仅重视基础学科教育,还开设了丰富多彩的特色课程,如机器人编程、创意美术、音乐剧团以及绿色环保俱乐部等,旨在培养学生的综合素质与创新能力。学校每年还会举办科技节、读书月、运动会和文化节等活动,让学生在实践中学习,在快乐中成长。
请注意,上述所有姓名均为虚构,实际学校环境中应有真实的人名和具体信息。- 本示例中使用的是Qwen-7B-chat。
- 模型微调
- 使用你收集的数据来微调所选模型。
- 标注数据:如果需要,对数据进行标注以支持监督学习。
- 微调模型:运行微调程序,调整模型的参数使其更适应你的业务数据。
通过提取的问答对生成train.json文件:
[ { "instruction": "西红市第十实验小学在哪里?", "output": "在风景秀丽的西红市区。" }, { "instruction": "西红市第十实验小学一年级101智慧班班主任是谁?", "output": "西红市第十实验小学一年级101智慧班班主任是张晓华老师,以耐心和细心著称,擅长激发学生的兴趣。" }, { "instruction": "西红市第十实验小学一年级102梦想班班主任是谁?", "output": "西红市第十实验小学一年级102梦想班班主任是李婉莹老师,鼓励学生大胆追梦,注重情感教育。" }, { "instruction": "西红市第十实验小学一年级103星光班班主任是谁?", "output": "西红市第十实验小学一年级103星光班班主任是刘云飞老师,擅长科学实验教学,启发学生的好奇心。" }, { "instruction": "西红市第十实验小学一年级104探索班班主任是谁?", "output": "西红市第十实验小学一年级104探索班班主任是黄雅莉老师,热爱户外教学,引导学生亲近自然。" } ]对Qwen-7B-chat进行LoRA微调的命令:
!deepspeed /ml/code/train_sft.py \ --model_name_or_path qwen-7b-chat/ \ --train_path train.json \ --valid_path valid.json \ --learning_rate 1e-5 \ --lora_dim 32 \ --max_seq_len 256 \ --model qwen \ --num_train_epochs 20 \ --per_device_train_batch_size 32 \ --zero_stage 2 \ --gradient_checkpointing \ --print_loss \ --deepspeed \ --output_dir output/ \ --offload如果你当前无法看懂这部分代码,或者不了解其中的参数是什么意思,这并不会影响你对后续内容的理解。如果你需要了解更多关于通义千问开源模型的部署与微调代码,可以参考通义千问的github主页。
- 模型评测
- 你可以在准备训练集的同时,准备一份与训练集格式一致的评测集,该评测集用来评测微调后模型的效果。如果评测集数据条目较少,你可以直接去观察微调后模型的输出,并与评测集的output进行比较。如果评测集数据条目较多,你可以通过百炼的模型评测功能,查看微调后模型的表现。
- 模型集成
- 编写代码将模型调用集成到现有的业务流程中去。
- 设定合理的调用逻辑和流程,如何处理模型的输出,如何处理API调用错误等。
- 确保API调用遵守数据保护法规。
- 实施适当的身份验证和授权控制。
- 测试与优化
- 在开发和测试环境中测试API调用和模型集成。
- 根据测试结果优化模型性能。
- 模型部署
- 在生产环境中部署微调后的模型。
- 监控与维护
- 监控模型的性能和API的健康状况。
- 定期重新评估和优化模型以适应新数据和业务变化。
- 持续迭代
- 根据用户反馈和业务需求的变化,继续改进模型和API。
在进行这一切工作时,保持良好的文档习惯也至关重要,这样团队成员可以轻松跟踪项目的进展,新加入的成员也能够快速上手。此外,确保所有与微调和部署模型相关的关键决策都得到适当记录和备份。
1.6 微调的方式
大模型具有海量参数,在预训练阶段需要海量训练样本,而且需要大量的时间与算力。那么微调的“微”字体现在哪里呢?
“微”字主要体现在以下几个方面:
- 数据规模小。微调无需像预训练一样喂入海量的数据,它的数据集长度往往比预训练的数据集长度小很多量级。
- 训练时间较短。由于预训练前的大模型参数是随机初始化的,因此往往需要很长的训练轮次与时间才能达到预期效果;而微调前的大模型已经经过了预训练这一步骤,微调的时间无需过长即可达到较高的性能。
那么我们也需要像预训练一样在微调阶段去调整所有的模型参数吗?我们先看一下Qwen-7B 的模型结构:
QWenLMHeadModel( (transformer): QWenModel( (wte): Embedding(151936, 4096) (drop): Dropout(p=0.0, inplace=False) (rotary_emb): RotaryEmbedding() (h): ModuleList( (0-31): 32 x QWenBlock( (ln_1): RMSNorm() (attn): QWenAttention( (c_attn): Linear(in_features=4096, out_features=12288, bias=True) (c_proj): Linear(in_features=4096, out_features=4096, bias=False) (attn_dropout): Dropout(p=0.0, inplace=False) ) (ln_2): RMSNorm() (mlp): QWenMLP( (w1): Linear(in_features=4096, out_features=11008, bias=False) (w2): Linear(in_features=4096, out_features=11008, bias=False) (c_proj): Linear(in_features=11008, out_features=4096, bias=False) ) ) ) (ln_f): RMSNorm() ) (lm_head): Linear(in_features=4096, out_features=151936, bias=False) )也许你还不能明白这个模型结构中的每一行代表什么含义,但你可以先把每一个冒号(:)后的内容当作子模块的模型参数,大模型由这些子模块组成。从调整参数量的大小这个角度,我们可以把微调分为全参微调与高效微调。
全参微调(Full Fine Tuning)是在预训练模型的基础上进行全量参数微调的模型优化方法,也就是在上边的模型结构中,只要有参数,就会被调整。该方法避免消耗重新开始训练模型所有参数所需的大量计算资源,又能避免部分参数未被微调导致模型性能下降。但是,大模型训练成本高昂,需要庞大的计算资源和大量的数据,即使是全参数微调,往往也需要较高的训练成本。
因此业界研究出多种不同的高效微调 PEFT(Parameter-Efficient Fine-Tuning)技术,旨在降低微调参数的数量和计算复杂度的同时提高预训练模型在新任务上的性能,缓解微调大型预训练模型的训练成本,在上边的模型结构中,只需要调整某几层网络的参数即可。高效微调 PEFT技术的推广使得很多技术团队、研究人员可以在有限计算资源上完成模型训练,让微调大模型的路径更易获得。当前比较主流的 PEFT 方法包括 Adapter Tuning、Prompt Tuning、LoRA 等等。我们将重点介绍几种高效微调的方法,向你展示高效微调怎么能够在减少训练参数量的同时,达到与全参微调相似的效果。
1.6.1 LoRA
原理概述
LoRA 的全称是 "Low-Rank Adaptation"(低秩适应)。它不对原模型做微调,而是在原始模型旁边增加一个旁路,通过学习小参数的低秩矩阵来近似模型权重矩阵的参数更新,训练时只优化低秩矩阵参数,通过降维度再升维度的操作来大量压缩需要训练的参数。论文中的方法如下图所示,在旁路有A矩阵和B矩阵,分别对应了降维矩阵和升维矩阵。由于 r 远小于 d, 因此 LoRA 方法可以极大地减少微调训练的参数量。
假设我们有一个维度为3*3的M矩阵需要微调,但我们没有直接对这个3*3的矩阵进行参数更新,而是对维度为3*1的A矩阵和维度为1*3的B矩阵进行更新,最后用A矩阵乘B矩阵得到了一个3*3的C矩阵,再将C矩阵叠加到M矩阵上,完成对M矩阵的更新。在这个例子中,我们更新的矩阵共6个参数(3个来自A矩阵,3个来自B矩阵),只比直接更新M矩阵的9个参数少了3个。你也许觉得参数量没有少太多,但是如果我们要微调的矩阵维度是1000*1000,那么我们通过LoRA方法能够少调整的参数就有:1000*1000-2*1000=998000,需要更新的参数量减少了非常多。
LoRA的原理图如下所示:
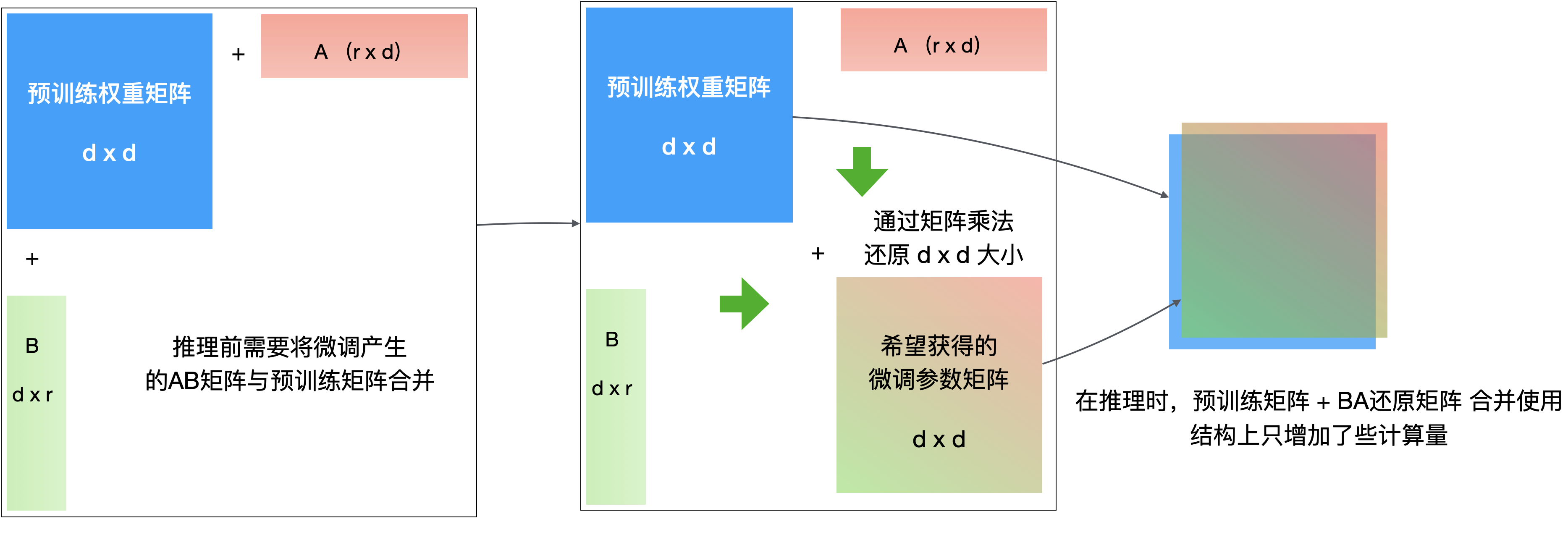
如果你对秩和矩阵不熟悉的话也没有关系,你只需了解到LoRA微调是一种效果与全参微调接近,并且最通用的高效微调方法之一。如果你对LoRA的更多细节感兴趣,可以阅读:
LoRA: Low-Rank Adaptation of Large Language Models
LoRA微调效果
LoRA作者将五种不同的微调方法进行对比,包括:Fine-Tuning (全参微调)、Bias-only or BitFit(只训练偏置向量)、Prefix-embedding tuning (PreEmbed,Prefix Tuning 方法,只优化 embedding 层的激活)、Prefix-layer tuning (PreLayer,Prefix Tuning 方法,优化模型所有层的激活)、Adapter tuning,得到如下对比图。
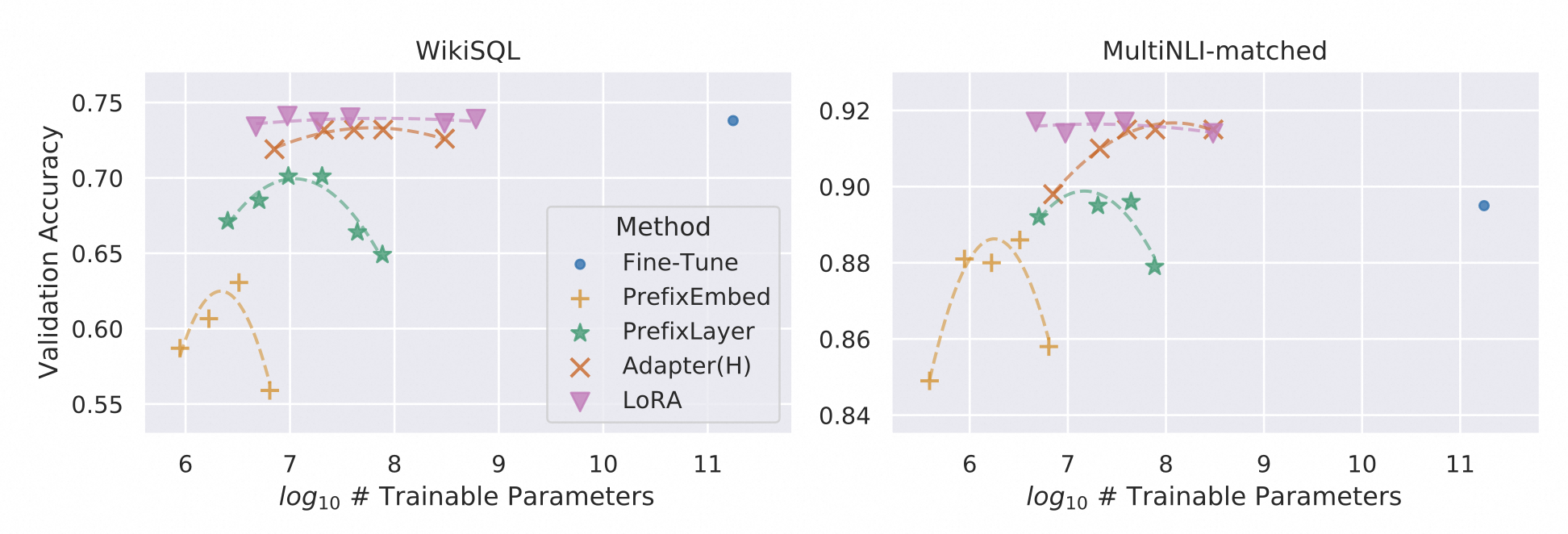
从上图可见并不是所有方法都能从拥有更多的可训练参数中获益,并不是训练参数越多效果越好。 但 LoRA 方法表现出更好的可扩展性和任务性能。
1.6.2 Adapter Tuning
原理简述
该方法会在原有的模型架构上,在某些位置之间插入Adapter层,微调训练时只训练这些Adapter层,而原先的参数不会参与训练。该方法可以在只额外增加3.6%参数的情况下达到与全参数微调相似的效果。原理图如下所示:
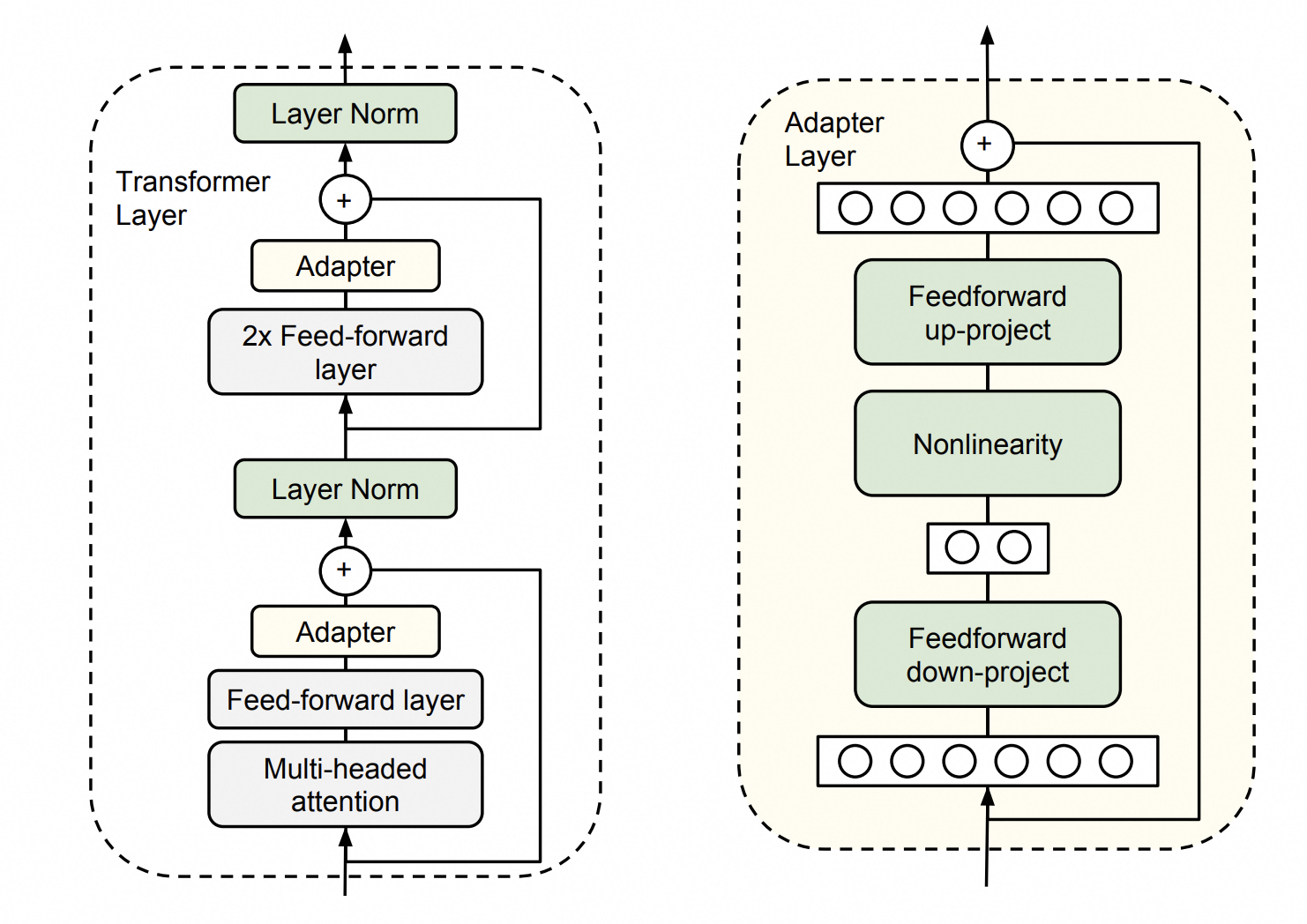
假设你经营着一家饮料公司,你原本销售的方法很简单,就是把产品装箱后堆放在工厂门口,购买者只能来工厂门口才能买到,这限制了饮料的售卖渠道。于是你增加了一个物流装箱的包装工作站,只需要增加几个人,就可以把产品打包到运输箱里,从而交给快递公司发走。虽然打包的过程增加了3.6%的人力成本(类比于插入Adapter层引入的新参数量),但是现在可以向外地发货,并且原有的工作流程没有改变。这个新增的包装工作站,就类比于Adapter的作用,包装工作站中新增的人员、管理制度,就是我们需要微调的参数,而生产线等其它部门的人员和制度不用做任何调整。
评测效果
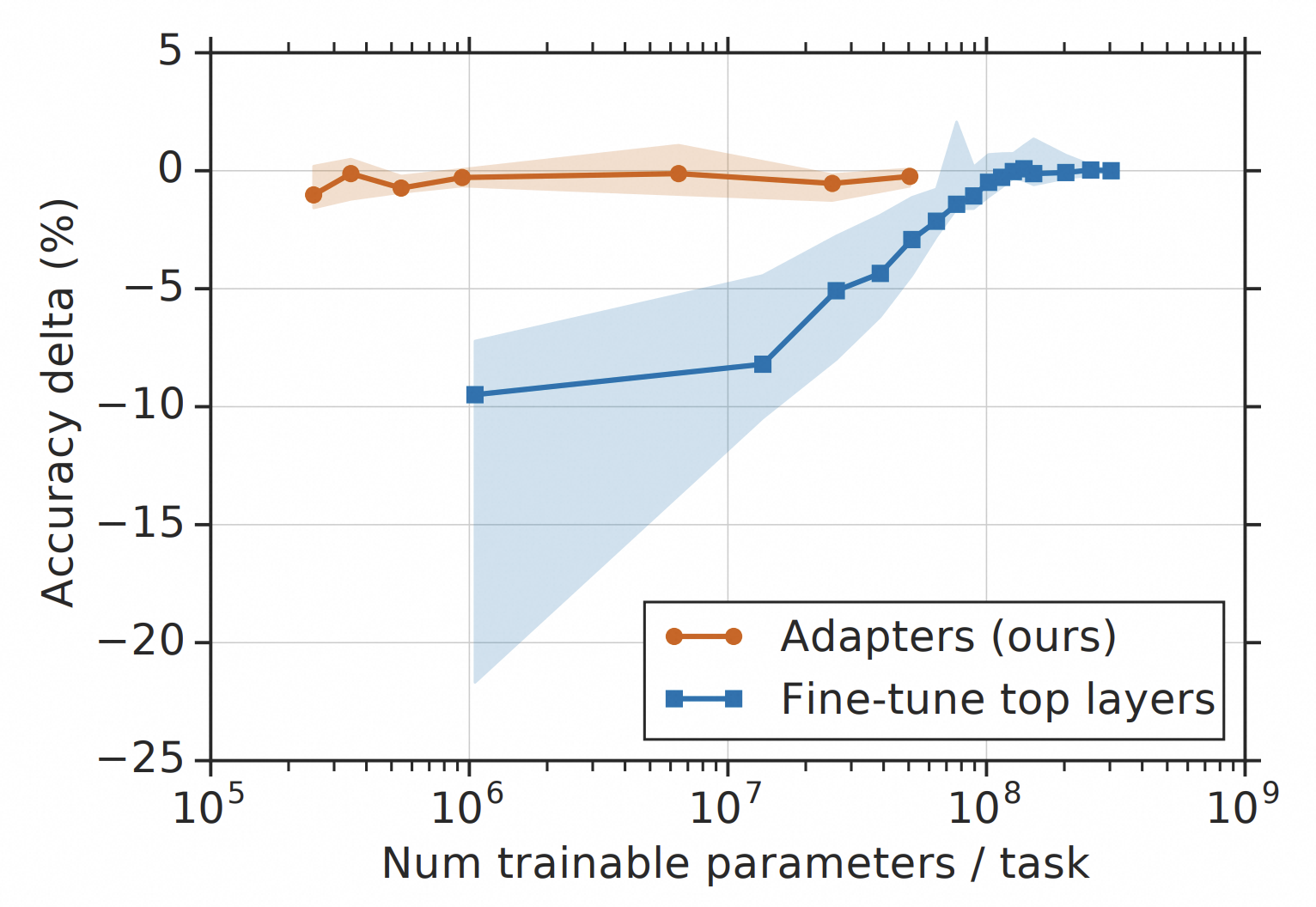
下图描述了采用Adapter Tuning方法,准确率与训练参数数量之间的权衡。y轴是对标全参微调性能的归一化,y值越大,效果越好。曲线展示了来自GLUE基准的九个测试任务的第20、50和80百分位的性能。基于Adapter的微调方法在训练参数少两个数量级的情况下,达到了与全参微调相似的性能。
参考论文
Parameter-Efficient Transfer Learning for NLP
1.6.3 Prefix Tuning
原理简述
该方法不改变原有模型的结构,而是给文本数据的token之前构造一段固定长度任务相关的虚拟token作为前缀Prefix。训练的时候只更新这个虚拟token部分的参数,而其他部分参数固定。这些前缀向量可以视为对模型进行引导的“指令”,帮助模型理解即将处理的任务。由于只需学习远少于模型全部参数数量的前缀向量,这种方法极大地减少了内存占用和计算成本。
由于该方法在每一层 Transformer 隐藏层中保留了可训练的前缀向量,这就让整体的模型结构变得略为复杂,但好处是避免了灾难性遗忘的问题。此外,前缀能持续引导生成过程,也让Prefix Tuning方法在长序列生成任务中表现优异。需要注意的是,这些前缀会占用部分上下文窗口,有可能影响模型处理长文本的容量。
Prefix Tuning 原理图如下所示:
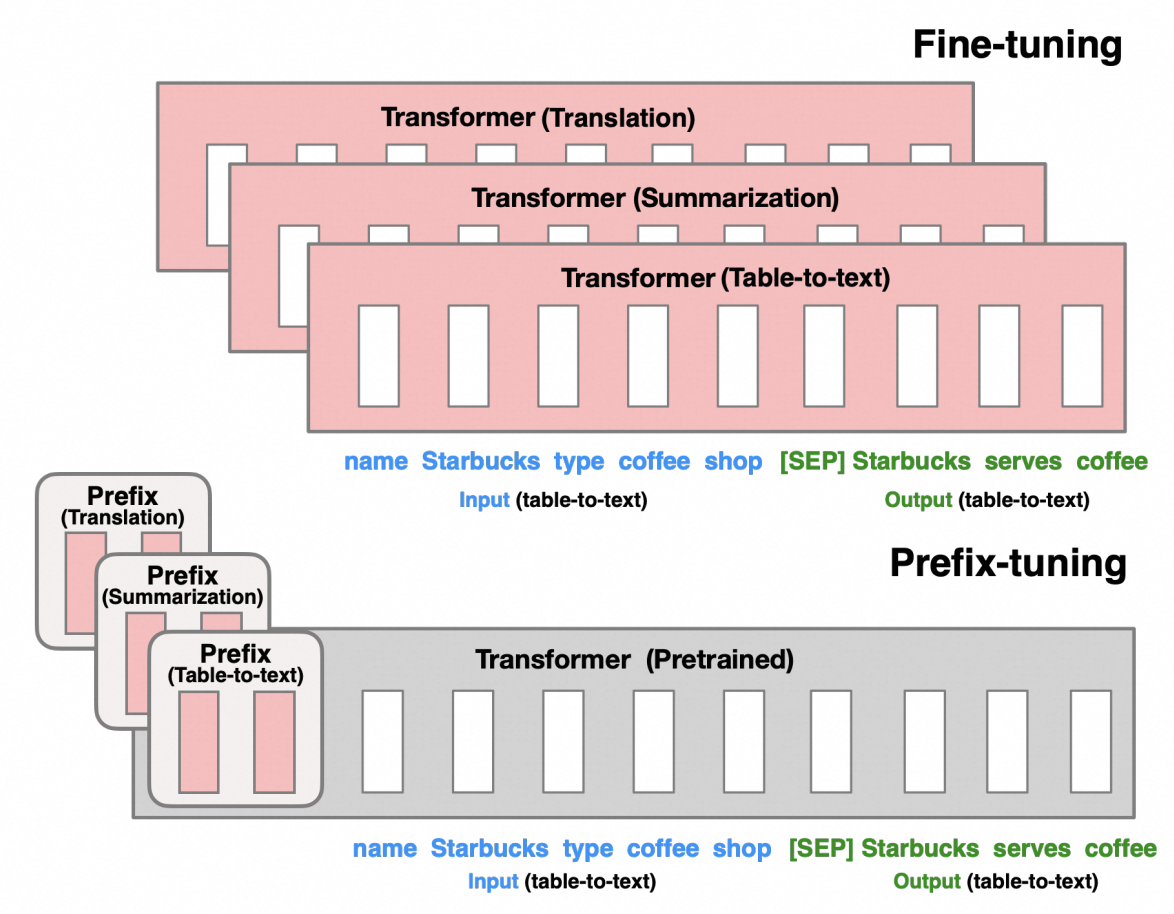
比如你利用情感分类的数据集,通过Prefix Tuning微调出了一个大模型,你向大模型输入了一句话:
今天天气真好,我很开心。
最后大模型接收的输入类似于这样:
(虚拟token1)(虚拟token2)(虚拟token3)今天天气真好,我很开心。
而通过了Prefix Tuning微调,大模型会把(虚拟token1)(虚拟token2)(虚拟token3)的含义理解为类似:
请对以下文本进行情感分类:
因此,大模型接收的输入被理解为类似于这样:
请对以下文本进行情感分类:今天天气真好,我很开心。
最后大模型会输出:
正面情绪
参考论文
Prefix-Tuning: Optimizing Continuous Prompts for Generation
1.6.4 Prompt Tuning
原理简述
Prompt Tuning是一种轻量高效的微调方法,其原理与Prefix Tuning类似,但仅在输入层加入可训练的prompt tokens向量(而非像Prefix Tuning那样作用于每层Transformer)来引导模型输出。这些提示词向量并不一定放在问题的前边,也可以针对不同的任务设计不同的提示词向量。微调训练只对这些前缀提示词向量进行更新,从而不修改大模型本身的参数,大幅减少训练参数。它的优势在于:
- 训练成本低:只优化少量提示词参数,比传统微调节省资源;
- 灵活适配任务:不同任务可以设计不同的提示词,比如分类、问答等;
- 简单高效:实验发现,有时哪怕只加1个提示词也能有效果!
不过它也有局限:比如提示词会占用模型的“记忆空间”(上下文窗口),可能影响长文本处理;另外,该方法更适合分类、问答等任务,复杂生成任务效果可能不如其他方法(如Prefix Tuning)。
随着模型规模增大(比如Google的T5),Prompt Tuning 的效果甚至会接近全参数微调,但训练成本低得多——这对资源有限的情况特别友好!
Prompt Tuning 原理图如下所示:
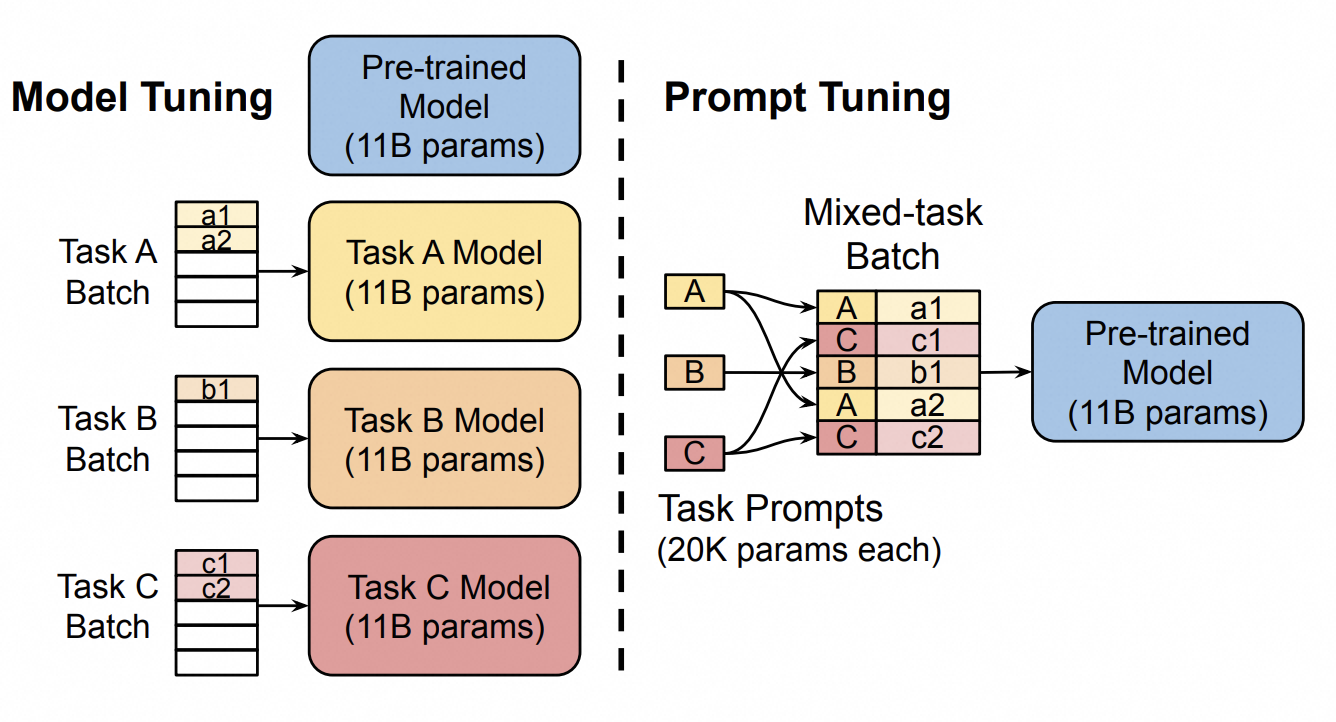
Prompt Tuning 原理图
比如你利用一个包含情感分类与汉语翻译为法语任务的数据集,通过Prompt Tuning微调出了一个大模型,你向大模型输入了一句话:
请分类:今天天气真好,我很开心。
这个输入其实很模糊,只是提到分类,却没有提到从什么角度进行分类。但是Prompt Tuning之后的大模型,最后接收的输入类似于这样:
(虚拟token1)(虚拟token2)...(虚拟token m)请分类:今天天气真好,我很开心。
“(虚拟token1)(虚拟token2)...(虚拟token m)请分类” 的含义会类似于:
请对以下文本进行情感分类:
因此,大模型接收的输入被理解为类似于这样:
请对以下文本进行情感分类:今天天气真好,我很开心。
最后大模型会输出:
正面情绪
而当你输入这么一句话:
请翻译:明天是星期五。
它并没有指明要翻译为什么语言,未经微调的大模型可能会翻译为英语。但是Prompt Tuning之后的大模型,最后接收的输入类似于这样:
(虚拟token4)(虚拟token5)...(虚拟token n)请翻译:明天是星期五。
而“(虚拟token4)(虚拟token5)...(虚拟token n)请翻译:”的含义会类似于:
请将以下文本翻译为法文:
因此,大模型接收的输入被理解为类似于这样:
请将以下文本翻译为法文:明天是星期五。
最后大模型会输出:
Demain, c'est vendredi.
符合我们微调数据集中汉语翻译为法语任务的要求。
评测效果
对标准的T5模型进行微调可以实现很强的性能,但这个微调是需要针对不同任务独立训练微调模型来实现的。而Prompt Tuning方法在确保高性能的同时,可以兼顾多任务。相比对GPT-3进行提示词设计的方法(Prompt Design下图蓝色)Prompt Tuning方法的性能更加强大(下图绿色)。下图展示了三次微调的平均值。
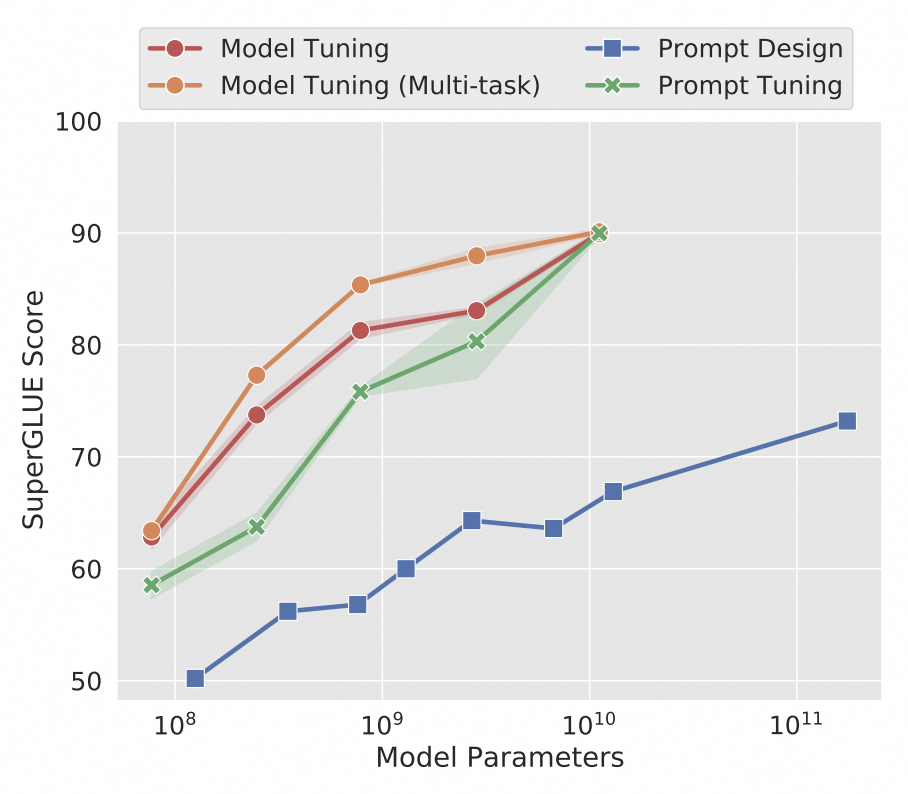
参考文献
The Power of Scale for Parameter-Efficient Prompt Tuning
1.6.5 小结
上述典型的PEFT方法虽然均有较好的效果,但同时会引入一些问题:
- Adapter Tuning 的适配器层本身会在推理中引入额外的计算消耗,产生推理延迟。
- Prefix Tuning 难以优化,性能随着可训练参数规模非单调变化。
- 不管是Prefix Tuning还是Prompt Tuning都会引入前缀序列占用处理下游任务的序列长度(导致每次请求时产生更大的tokens消耗)。
相比之下,LoRA是较为高效的微调方法。
2 在阿里云上微调大模型
阿里云有许多产品可以帮助你进行大模型的微调。你可以评估自身及团队的情况,选择合适的云产品进行微调。
- 如果你有一定的算法技术背景,希望掌控大模型微调的细节,甚至希望在训练方法上有所创新,那么你可以选择用 PAI。 PAI DSW 提供了在线的 Notebook界面,并且提供了大模型的微调教程文件,可以让你使用熟悉的开发环境在云上对大模型进行微调。PAI DLC 提供的分布式训练能力,能够帮助你高效地完成大模型的微调。PAI EAS 提供的模型部署能力,能够在你完成大模型微调后,帮助你拥有部署并调用微调大模型的能力。

- 如果你已经基于虚拟机或容器积累了丰富的大模型训练和部署经验,你也可以选择使用 GPU 云服务器或基于阿里云 ACK(Alibaba Cloud Container Service for Kubernetes)的云原生 AI 套件,无需学习新的概念,将现有的大模型训练任务迁移到云上。
- 如果你没有算法技术背景,那么你可以选择使用百炼。百炼提供了开箱即用、界面化的大模型调优能力,以及评测流程管理。你可以专注于数据集的准备以及模型评测,而无需关注和理解模型训练代码。当然,如果你拥有算法技术背景,同样可以借助百炼来简化大模型微调过程。

我们提供了一个在百炼平台微调大模型的视频。
从这个视频可以看出,我们在样本量不大的情况下进行微调,都会有比较久的耗时,如果再加上费用的考虑,微调可能并不一定是你的首选。
百炼计费介绍
百炼主要收取模型推理费用、模型训练费用以及模型部署费用三类费用,且针对不同的模型、规格和应用场景有不同的计费。计费的详细说明,请参见产品计费。
百炼微调实践
如果你想了解使用百炼进行微调的实践教程,请参见自定义模型最佳实践。
[进度: 已完成]本节小结
在本小节中,我们学习了微调的概念和适用场景。微调从风格化和格式化两个角度,完善了大模型的应用场景。结合前面学过的,通过提示词工程提升大模型的回答质量,通过RAG解决大模型的幻觉问题等等方法,到这里你已经了解了使用和提升大模型应用的基本知识。接下来,我们将介绍大模型应用的安全合规方面的知识。如果你的业务系统里已经在使用大模型了,我们也建议你充分了解引入大模型之后可能存在的风险以及应对策略。
- 如果你想对微调技术做更深入的学习,我们推荐你阅读本节介绍过的论文如:LoRA: Low-Rank Adaptation of Large Language Models
了解大模型的多种优化方法后,你可能已经准备将其引入到业务中。但在正式应用和上线之前,你应该充分了解引入大模型后可能存在的风险以及应对策略。
[羽毛笔]课程目标
学习完本课程后,你将能够:
- 认识大模型的个人信息、内容安全、模型安全和知识产权风险
- 了解大模型的个人信息、内容安全、模型安全和知识产权风险的治理策略
- 了解大模型应用的备案要求和方法
1 大模型的风险
随着生成式人工智能技术的广泛应用,其在保护用户个人数据、生成内容的安全性及知识产权等方面面临诸多风险。接下来,我们将通过具体案例深入探讨这些风险及其来源。
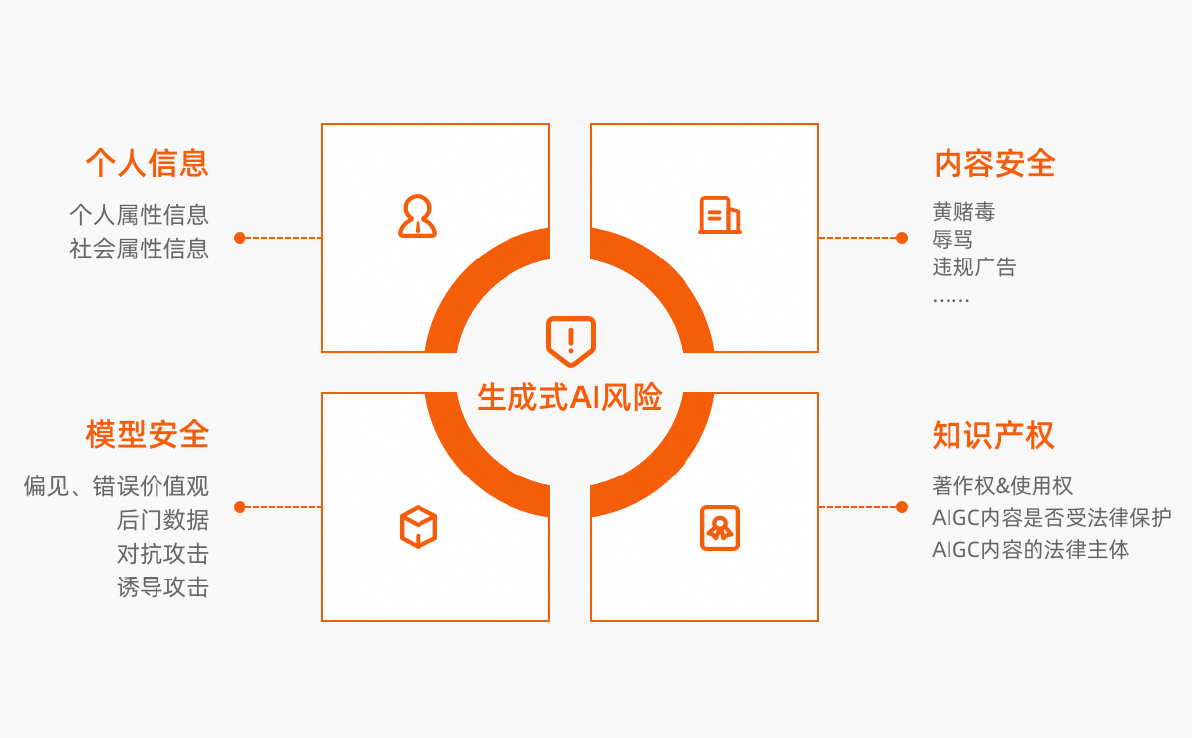
1.1 个人信息风险
个人信息风险是指生成式人工智能在训练和使用过程中,未能充分保护用户的个人数据,从而导致个人信息的泄露或被滥用。
1.1.1 风险案例
-
OpenAI和Microsoft因涉嫌ChatGPT隐私违规被起诉
- 背景:2023年6月28日,美国加利福尼亚州旧金山联邦法院收到一起针对OpenAI和Microsoft的集体诉讼。诉讼指控这两家公司在未经用户同意的情况下,秘密收集数亿互联网用户的个人信息来训练他们的ChatGPT模型。这些数据包括姓名、地址、电话号码、电子邮件地址和金融信息。
- 情境:诉讼称,OpenAI和Microsoft从各大网站和社交媒体平台上秘密收集用户个人信息,但用户对此并不知情,也未给予同意。这些数据的使用违反了美国《电子通信隐私法》,该法案禁止在没有搜查令的情况下截取电子信息。
- 结果:该集体诉讼正在寻求30亿美元的赔偿。一旦成功,可能会对OpenAI和Microsoft造成严重的经济损失,并促使全球范围内的AI公司重新评估其数据收集政策。
-
谷歌因Bard相关数据抓取面临集体诉讼
- 背景:Google修改隐私政策,宣布使用公共数据训练其Bard AI聊天机器人,引发公众不满,指控其侵犯隐私权和版权。
- 情境:2023年7月12日,Clarkson律师事务所提起诉讼,声称Google在未获用户同意的情况下,通过数据抓取收集了用户的个人和职业信息、创作作品、照片及邮件等,用于训练其AI模型。
- 结果:诉讼要求Google赔偿损失、删除收集的数据,并暂停Bard的开发,直到建立独立监管机构和其他保障措施。
1.1.2 风险来源
-
模型训练阶段
- 数据来源和内容:生成式AI通常需要大量数据进行训练,这些数据往往包含用户的个人信息(如姓名、地址、联系方式等),以使生成式人工智能产品与服务更加个性化、定制化。
- 缺乏匿名化处理:如果训练数据未进行匿名化处理,个人信息可能直接被模型学习和存储。
-
模型推理阶段
- 实时交互:在与用户的实时交互过程中,用户可能输入个人信息,如医疗记录、联系方式等。
- 模型生成内容:模型在生成内容时,可能会无意中包含或重现这些个人信息,导致隐私泄露。
1.2 内容安全风险
内容安全风险是指生成式人工智能在生成文本、图片、音视频、代码等内容时,可能出现社会不安全、不合法、不合规或违反道德伦理的问题。这类风险包括但不限于违法或不良信息、虚假内容、偏见和歧视等。
1.2.1 风险案例
- BERT模型中的性别偏见
- 背景: BERT等上下文语言模型(CLMs)虽提升了NLP性能,但容易在训练数据中学习到性别偏见。
- 情境:2020年,Rishabh Bhardwaj等人研究了BERT在情感和情绪强度预测任务中的性别偏见。他们训练了基于BERT词嵌入的回归模型,并使用性别公平评估语料库评估偏见。结果显示,模型的预测对性别特定词汇有显著依赖。
- 结果: 研究建议删除词嵌入中的性别特征,通过识别BERT每层中的性别方向来减少偏见。实验表明,该方法在减少BERT引入的性别偏见方面非常有效。
-
律师使用ChatGPT生成虚假案例导致法律后果
- 背景:生成式AI(如ChatGPT)在法律研究和文书准备中的使用日益增多,但也带来了虚假信息的风险。
- 情境:2023年6月22日,曼哈顿地区法院对纽约律师Steven Schwartz和Peter LoDuca及其律所Levidow, Levidow & Oberman施加了5000美元的罚款,因为他们提交的法律简报中包含ChatGPT生成的六个虚假案例引用。Schwartz在为客户对哥伦比亚航空公司的个人伤害案准备简报时使用了ChatGPT,导致错误引用。
- 结果:法院发现这些律师行为不诚实,尽管律师事务所宣称这是对技术误信所致。案件被驳回,律师们被责令通知所有被假引用的法官。这一事件强调了严格验证AI生成内容的重要性,以避免类似法律后果。
1.2.2 风险来源
-
训练数据问题
- 偏见和不良信息:如果训练数据中存在偏见、错误信息和违法不良信息,模型很可能继承并再现这些问题。
- 数据质量和多样性:训练数据质量不高或数据源单一,容易导致生成内容的片面性和失实性。
-
模型缺陷
- 缺乏多样化的检测和修正机制:模型可能缺乏有效的机制来识别和修正偏见、错误和不良信息。
- 算法设计缺陷:算法设计上的缺陷可能导致模型在特定领域或特定情境下生成有害或误导的信息。
-
使用过程中的问题
- 用户输入:用户在使用过程中可能输入违法、偏见或不适当的内容,进而影响生成结果。
- 内容鉴别难度:生成内容越接近人类创作,用户越难以鉴别真伪,特别是在语言风格、音视频合成等方面。
- 社会环境和公众因素
- 知识储备和数字技能:公众对于生成内容的真实性和准确性难以察觉,特别是在专业性强和陌生领域。
- 依赖生成内容做决策:在高风险领域(如金融交易、投资规划、医疗诊断等),依赖生成内容做决策容易产生连锁安全事件。
1.3 模型安全风险
模型安全风险是指生成式模型在使用过程中面临的多种安全隐患,包括传统的软件和信息技术安全问题以及生成式模型特有的安全挑战。
1.3.1 风险案例
- GPT-2被攻击导致训练数据泄露
- 背景: 越来越多的大型语言模型(例GPT-2)被训练于私有数据集上,这些模型常常容易受到训练数据提取攻击。
- 情境: 2020年,Nicholas Carlini等人展示了通过对GPT-2模型进行攻击,成功提取出训练数据。这些数据包括公开的个人信息(如姓名、电话号码和电子邮件地址)、IRC对话、代码和128位UUID。
- 结果: 研究表明,较大的模型更容易受到这种攻击,暴露出训练数据中的敏感信息。研究人员建议在训练大模型时要采取更严格的防护措施,以减少数据泄露风险。
- ChatGPT故障导致依赖业务受到严重影响
- 背景: OpenAI的ChatGPT是一个广泛使用的聊天机器人,每周拥有超过1亿活跃用户,被全球92%的《财富》500强公司应用于金融、法律和教育等领域。
- 情境: 2023年11月9日,ChatGPT及其API服务因一次有针对性的DDoS攻击导致大规模故障。OpenAI在其状态页面上指出,从11月8日开始的异常流量模式对所有服务造成了周期性中断。
- 结果: 尽管OpenAI迅速实施修复,服务一度恢复正常,但问题仍未完全解决,用户次日继续报告错误信息。攻击期间,客户信息未被泄露,但对依赖ChatGPT的业务造成了严重影响。此次攻击发生在OpenAI首次面对面会议后不久,该会议宣布了GPT-4 Turbo和ChatGPT定制版本的推出。
1.3.2 风险来源
-
传统软件和信息技术安全问题
- 后门漏洞:攻击者可能在模型开发过程中插入后门,使其在特定条件下生成意外的或有害的输出。
- 数据窃取:敏感数据在训练、测试和使用过程中可能被盗取,导致隐私泄露和信息不安全。
- 逆向工程:攻击者通过逆向工程的方法,从模型中提取训练数据或其他敏感信息。
- 生成式模型特有的安全挑战
- 公平性问题:模型可能在训练数据中继承并放大原有的偏见,从而生成带有歧视性或不公平的内容。
- 鲁棒性问题:模型在面对不常见或对抗性样本时,可能生成错误或有害的内容。
- 可解释性问题:由于模型的“黑盒”性质,难以解释其生成内容的具体依据和过程,增加了安全风险和责任不明确的情况。
1.4 知识产权风险
知识产权风险是指生成式人工智能在研发、使用和推广过程中,可能涉及的著作权、商标权、专利权等侵权问题。
1.4.1 风险案例
-
Stability AI因训练阶段的版权侵权面临法律诉讼
- 背景:2023年,Stability AI在训练其AI绘画工具Stable Diffusion的过程中,使用了未经授权的数百万张图片,包括Getty Images的内容。
- 情境:这些图片是通过互联网爬虫程序获取的,未明确获取版权授权,导致训练数据侵犯了他人的知识产权。
- 结果:Getty Images起诉Stability AI,指控其侵犯了大量图片的版权,引发了业内的广泛关注和担忧。这一案件成为生成式人工智能领域版权纠纷的典型案例,凸显了训练数据合法性问题。
-
Stephen Thaler因AI生成内容的著作权归属问题遭遇版权申请拒绝
- 背景:2021年,美国版权局(U.S. Copyright Office)拒绝了Stephen Thaler为其AI创作的作品申请版权保护的请求。这一案例集中体现在Stephen Thaler的“Creativity Machine”生成的一些内容上,申请者质疑其是否能够对该作品享有著作权。
- 情境:AI生成的内容难以区分人类创作和AI创作的界限,同时人工智能自身尚不能独立产生意思表示和承担法律后果。然而,用户或开发者希望明确AI生成内容的知识产权归属,以便在法律和商业上进行保护和利用。
- 结果:引发了关于生成物知识产权归属的广泛争议。由于当前法律对人工智能产生的内容是否具备著作权保护尚无明确规定,这成为知识产权保护的难点之一。不同国家的法律体系对此问题的态度和处理方式也可能有所差异,进一步复杂化了这一领域的法律挑战。美国版权局的这一决定进一步强化了这一法律领域的模糊性和不确定性。
1.4.2 风险来源
-
训练阶段
- 数据集包含他人作品:训练数据可能包括他人的著作、商标、技术成果等。例如,Getty Images起诉Stability AI,指控其侵犯数百万张图片的版权,这就突显了在数据集获取和使用过程中,容易触及知识产权侵权问题。
- 数据来源复杂:训练数据很多是通过爬虫方式在互联网环境中获取,互联网信息来源丰富且原始权利人不明确,难以找到确定的权利人进行授权。相对地,训练数据中是否含有他人的知识产权成果以及是否侵权,往往需要在生成内容呈现后才能判断,导致溯源难、定责难的问题。
- 内容生成与传播阶段
- 生成物的权利保护:生成内容能否成为知识产权保护对象是核心关注点。生成物多以文学和艺术作品形态存在,知识产权保护争议多集中在著作权领域。
- 生成物权利归属:在用户提示语下,生成式AI生成的内容愈发难以区分,这引发了对人工智能自身是否应成为权利主体或侵权主体的讨论。由于人工智能尚不能独立承担法律行为后果,各国对赋予其法律主体资格保持慎重态度,生成物的知识产权权利归属问题仍存有争议。
2 大模型的风险治理
为了有效管理大模型应用中的各种风险,确保生成式人工智能的安全、合规和有效应用,需要采取一系列治理策略。下面我们将详细介绍大模型的风险治理措施。

2.1 个人信息合规
2.1.1 合规处理
- 告知与同意:按照《个人信息保护法》,在收集和处理用户个人信息时,确保用户知情并自愿同意收集和处理其个人信息。在个人信息处理者变更时,必须履行告知义务并重新取得用户同意。
- 确保数据真实性和多样性:按照《生成式人工智能服务管理暂行办法》,确保预训练(Pre-training)数据和优化训练数据的真实性、多样性。真实性是指数据的准确性和可靠性,通过数据来源验证、数据审查和清洗确保模型避免错误理解和预测;多样性则确保数据覆盖广泛的情况和背景,如不同人群、文化、语言和区域,以提升模型的普适性和鲁棒性。
- 杜绝非法披露:按照《生成式人工智能服务管理暂行办法》,不得非法披露用户输入的信息和使用记录,向第三方披露或合作时需严格遵循相关法律法规。
2.1.2 训练数据分类分级
-
分类分级:
- 按照《个人信息保护法》及GB/T 35273-2020《信息安全技术 个人信息安全规范》进行一般个人信息和敏感个人信息的分类管理。
- 解决方案:使用阿里云数据安全中心对数据进行分类分级。详情参见快速实现敏感数据分类分级。
2.1.3 隐私数据保护和处理
-
去标识化技术:
- 参考GB/T 37964-2019《信息安全技术 个人信息去标识化指南》和GB/T 42460-2023《信息安全技术 个人信息去标识化效果评估指南》,进行去标识化技术实施和效果评估。
- 解决方案:使用阿里云数据安全中心对数据进行脱敏。详情参见数据脱敏。
-
加密措施:
2.1.4 拒绝生成隐私信息
-
Query-Response构造:
- 监督微调(SFT,Supervised Fine Tuning)阶段,通过构造Query-Response对,让模型学会拒绝对个人信息的非法Query。
-
价值观对齐:
- 监督微调阶段,利用基于人类偏好的强化学习,确保模型与人类价值观对齐,并在安全评测中能够正确应对。
-
拒绝不当请求:
- 在算法提供在线服务时,对于涉及个人信息违法请求的Query(如生成特定个人身份信息、非法获取方法等)必须予以拒绝,确保不生成虚假或敏感信息。
2.2内容安全保障
2.2.1 应用层安全机制

-
标准回答:
- 对于必须正面回答的问题,预置标准答案,命中后系统直接返回,避免继续生成风险内容。
- 解决方案:在应用中先构建标准答案库,针对输入问题的关键词及语义进行匹配命中后返回标准答案或根据特定模式的问题规则(如隐私政策、退款流程等)直接返回标准答案。对于特别复杂或高风险的问题,必要时可触发人工客服介入,确保用户体验和安全性。
-
Query风险识别:
- 对用户Query进行风险识别,判断是否存在个人信息、内容安全或模型安全等风险,并提供安全的答复。
- 解决方案:使用阿里云内容安全的文本审核功能,识别Query的文本违规风险。详情参见使用文本审核增强版识别文本违规风险。
-
基于知识库的搜索增强:
- 针对用户Query,利用搜索引擎获取可信度高的结果输入模型,引导模型生成符合事实的内容。
- 解决方案:使用阿里云大模型服务平台百炼的知识检索增强功能,缓解“知识幻觉”问题。详情参见知识检索增强工具。
-
Response风险识别:
- 尽管采取了上述措施,Response中可能仍含有风险,需要在输出前执行一次安全过滤,识别风险内容并及时拦截。
- 解决方案:使用阿里云内容安全的文本审核功能,识别Response的文本违规风险。详情参见使用文本审核增强版识别文本违规风险。
2.2.2 生成信息信任机制
-
添加AIGC声明:
- 针对可能造成误解的场景,对AIGC进行明确说明。
- 解决方案:通过提示词工程添加AIGC声明。
-
提供依据链接:
- 有条件的情况下,提供生成内容的依据链接,确保内容可信。
- 解决方案:通过提示词工程添加生成内容的依据链接。
2.2.3 模型风险评测
- 定义风险:首先,识别和细分大模型可能面临的各种风险。风险类型包括内容安全风险、个人信息风险和模型安全风险等。每种风险都需要被明确定义,以便后续处理和管理。
- 构建Benchmark(评估基准):在明确了具体风险后,下一步是为这些风险构建Benchmark。Benchmark可以通过两种方式获得:基于风险知识库生成或人工撰写。然后,这些基准由专家审核改写,形成风险Query。
- 评测模型:最后,使用风险Query和Benchmark对模型进行评测。评测方式通常是机器和人工结合的方式,需要生成多个Response,并进行人工审核和排序。这些Response与标准答案进行排序对比,然后根据判别结果做出安全性决策。
- 解决方案:使用阿里云大模型服务平台百炼的的模型评测功能,实现以上过程。详情参见模型评测。
2.2.4 模型层内生安全
- 预训练阶段:在这一阶段引入的风险主要来自训练语料,包括个人信息、违法信息、错误价值观和歧视等。处理方式包括筛选具有良好资质和声誉的信息源,对个人信息进行模糊化过滤和对数据进行清洗。
- 监督微调(SFT,Supervised Fine Tuning)阶段:对现有的监督语料进行安全过滤和人工审核,生成符合安全标准的训练数据,以指导模型正确应对风险Query。这一过程包括获取风险Query,生成并人工审核安全Response,以及生成多样化的安全Response,使模型稳定应对各种风险情境。
- 基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)阶段:强化学习的关键是评价模型的质量。标注人员进行培训并由不同背景的人员进行操作,以保证排序结果的公平性和降低偏见。
2.3 模型安全防控
2.3.1 鲁棒性
- 对抗性攻击测试:对模型进行对抗性攻击的测试,以发现并改进模型对抗攻击的弱点。通过不断的测试和改进,增强模型对各种扰动和恶意攻击的抵抗力。
2.3.2 公平性
- 训练数据集审查和筛选:对训练数据进行仔细审查和筛选,避免不公平内容进入模型的学习过程中。确保训练数据的公正性和多样性。
- 公平性约束:在训练过程中,加入公平性约束。通过调整损失函数或设计公平性指标,确保生成的内容无任何形式的歧视或偏见。
2.3.3 可解释性
- 特征可视化:通过可视化模型的内部结构、中间层表示和梯度等信息,来理解模型的工作原理。这将有助于揭示模型决策的背后机制,提升透明度。
- 规则化:引入约束和规则来指导模型的生成过程,以提高可解释性。制定明确的规则和准则,防止模型生成过程中的任意性。
2.4 知识产权保护
2.4.1 数据合法合规获取
- 从权利人处购买数据库:合法购买具有知识产权权利的数据库,以确保数据来源的合法性。
- 使用合法授权的开源数据集:使用具有合法授权的开源数据集,避免未经授权的使用。
- 避免跨越技术措施进行爬取:遵守网站或平台设置的防护机制,例如防火墙、验证码、访问权限控制和IP封禁等。通过技术手段绕过这些保护措施进行爬取,会违反相关法律法规。
2.4.2 溯源技术加持
-
权属清晰与溯源技术:
- 虽然人工智能生成物独创性逐渐被认可,但它们是否能成为知识产权权利主体仍是一个开放问题。生成物的合法合规使用依赖于权属的清晰程度。溯源技术的发展对相关治理具有重要作用。例如,为生成物添加明暗水印、进行版权电子登记和可信时间戳以及使用区块链技术等,都可以有效促进权属清晰。
- 解决方案:使用阿里云媒体处理的数字水印功能,为图像、视频添加数字水印,保障版权安全。详情参见数字水印(暗水印)。
2.4.3 制度革新
- 传统著作权制度的挑战与革新:人工智能生成内容逐渐接近人类创造水平,导致生成式内容创作、传播和利用的模式发生变化。传统著作权制度需要与时俱进,适应生成式人工智能的发展,建立更加公平合理的权益保护和惠益分享体系。
3 大模型应用备案
自2023年8月15日起,《生成式人工智能服务管理暂行办法》正式生效,监管部门要求对AIGC(生成式人工智能)相关的APP和小程序进行整改和合规备案:
- 已上架但未完成合规手续的应用将被下架。
- 未上架的应用必须完成合规动作后方可上线。
解决方案:阿里云百炼大模型服务平台为云上企业提供技术支持,涉及合规要求的算法备案。详情参见调用通义系列大模型开发应用上架应用商店/微信小程序申请指南。
[进度: 已完成]本节小结
通过本课程,你了解了大模型在模型训练、服务上线、内容生成、内容发布与传播等阶段的主要风险及其治理策略,确保安全合规地将其应用到业务中。
多模态大模型
1.1 什么是多模态大模型
每一种信息的来源或者形式,都可以称为一种模态(Modality)。例如,人类会通过色香味点评食物,并通过文字和图片记录。这里的视觉、嗅觉、味觉、文字、图片都是不同的模态。
而在大模型领域,模态指的是数据或信息的类型或表达形式,文本、图像、视频、音频等都是不同的模态。多模态,顾名思义,就是指结合两种及以上的模态,进行更综合的数据处理和分析。如果想要大模型真正模拟人类,实现多形式的输入和生成,单一类型的数据处理已经无法满足,大模型需具备同时处理和理解多种类型数据的能力。
在前文中,我们学习了使用ModelScope-Agent通过文字生成视频、图片或语音,这本身就是一个多模态应用。除了这种代理方式外,大模型本身也可以是多模态的,也就是多模态大模型,有同时处理多模态数据(如文本、图像、音频等)和执行复杂任务的能力,比如文生图、语音识别、图像字幕等。


1.2 体验多模态大模型
构建和训练一个多模态大模型,涉及多模态表征学习、多模态转化、多模态对齐、多模态融合、协同学习等过程,不仅需要编程能力、深厚的机器学习和深度学习知识,还需要足够的计算资源和资金支持。对于大多数团队和个人来说,直接使用现有的多模态大模型或利用现有的预训练模型并对其进行微调以适应特定任务,是更为现实和高效的途径。
目前,市面上已经有很多商业化或开源的多模态大模型,你可以直接访问网页端使用,也可以直接调用API集成在业务中。例如:
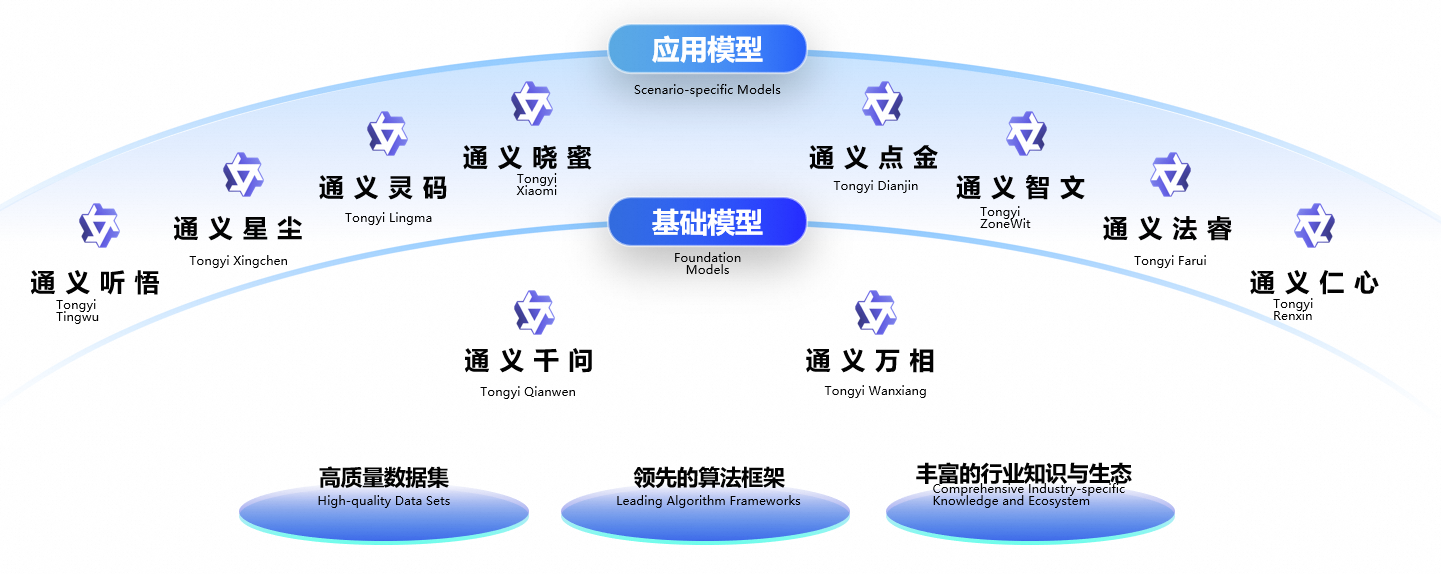
2 混合专家模型(MoE)
2.1 什么是混合专家模型
随着应用场景的复杂化和细分化,大模型要处理的问题逐渐多元化,遍及计算机、法律、医疗等各个专业领域,大模型的参数规模和复杂度也在不断增长。仅使用传统的单一大模型,会导致模型训练和推理时间变得更高、模型响应效率降低,在多模态大模型中尤为突出。为了解决这些问题,混合专家模型(Mixture of Experts,简称MoE)应运而生。
简单来说,混合专家模型的核心思想就是术有专攻,类似“专家会诊”,由多个不同领域的模型(即“专家”)组合成一个模型,分别去解决不同领域的问题。
混合专家模型主要由以下2个核心组件共同协作:
- Experts(专家网络):每个专家网络是用来处理某一特定类型问题或数据子集的独立模型,一般都在他们各自的专长上受过训练,推理时只有部分专家网络参与计算。
- GateNet(门控网络):类似于“交通指挥官”,负责评估输入数据,并决定由哪些专家参与处理当前的问题,尽可能地利用每个专家的专业知识来提供最准确的预测或决策输出。

2.2 混合专家模型的局限
尽管混合专家模型在处理复杂任务和提高模型性能方面表现出众,但它们也有一些局限性:
- 计算资源需求高:MoE模型中的每个专家都是一个独立的模型,当专家数量增加时,模型的总参数量也相应增加,导致部署模型可能需要更多的GPU显存资源。
- 过拟合风险:由于参数量大和复杂性,可能比简单模型更容易过拟合训练数据,特别是当数据量不足时。
2.3 更多了解
如果你想进一步体验和使用混合专家模型,可以去部署阿里巴巴通义大模型的研究者提供的一款MoE大模型:Qwen1.5-MoE-A2.7B,它仅拥有27亿个激活参数,但其性能却能与当前最先进的70亿参数模型。相比Qwen1.5-7B,Qwen1.5-MoE-A2.7B的训练成本降低了75%,推理速度则提升至1.74倍。
3 大小模型云端协同
模型的大小通常与模型的规模、复杂度和参数数量有关,无论是大模型还是小模型,都各有优劣。
“大模型”,顾名思义,参数规模庞大且结构复杂度高,能处理复杂的任务,准确率和泛化能力强,训练和推理需要大量的计算资源和时间,不适合直接部署在资源受限的设备上(如移动设备)。
与之对应的就是“小模型”,参数规模较小、计算密度较低,在性能上可能不及大模型,但对比大模型,训练和推理的资源需求较低,响应速度更快,适合在资源受限的环境下运行,如移动设备、边缘计算设备。
然而,在实际应用中,一个系统通常需要同时考虑到性能、响应效率、数据隐私、成本和资源使用效率,单独使用大模型或小模型很难满足所有这些需求。例如,一个电商APP为亿级用户提供服务,如果仅用单一超大模型提供服务,日常每秒超过万次请求,峰值每秒超过10万次请求,如果遇到服务高峰期,一次请求的延时可能会超过一分钟,严重影响用户体验。
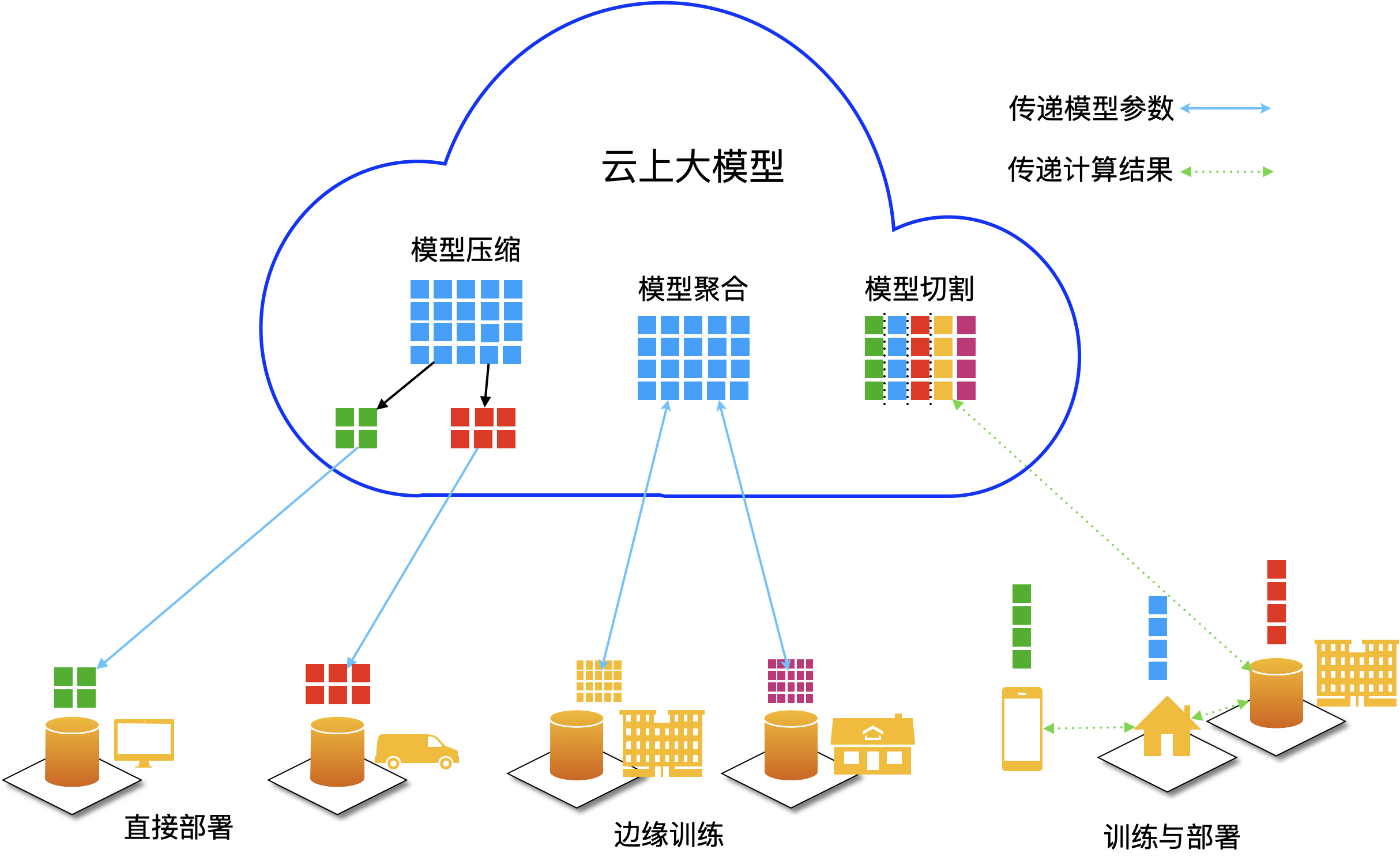
2022年十大科技趋势提出大小模型云端协同的概念,将大模型部署在云端,向边、端的小模型输出模型能力,小模型负责实时数据处理和初步推理,并向大模型反馈算法与执行成效,这样既能在云端充分发挥大模型的推理训练能力,又能调动边、端的小模型的敏捷性,可实现合理分配计算资源、提高响应速度。
通过前面课程的学习,相信你已经对大模型的使用有了一定的了解。当你遇到一个具体的问题时,你可以首先尝试问问大模型;如果大模型不能很好的回答你的问题,你可以尝试使用提示词技巧,提升大模型回答问题的质量;只要加装了正确的插件,通义或百炼的大模型应用可以为你做更多事;当你的大模型出现了幻觉,经常编造一些回答时,你可以考虑使用RAG技术;当你需要让你的大模型生成特定系统API格式的内容时,你可以考虑使用微调的技术;你还可以考虑利用多模态大模型显著提升你的产品体验;利用多智能体技术快速搭建原型系统,大幅提升你的工作效率。通过对这些知识的学习,相信你已经可以熟练使用大模型了。
1 核心概念深化理解
1.1 大模型:从理论到实践的飞跃
大模型是近年来人工智能领域的一大突破。它们通过在海量数据上进行自我监督学习,预先学习到了丰富的语言结构和广泛的知识,从而能够在特定任务上仅需少量额外调整或提示就能表现出色。这类模型的代表包括阿里云的通义千问、OpenAI的GPT系列以及Google的T5等。
1.2 Prompting:引导的艺术
Prompt,即提示技术,是指在输入中精心设计的文本片段,用于引导大模型按照预期的方式生成回答或完成任务。这类似于给模型提供一个上下文或问题框架,让其“联想”到所需输出,无需直接修改模型参数。
Prompting策略的关键在于如何构建有效的引导语,使之既明确表达任务需求,又能激发模型的最大潜能。
Prompting不仅是对模型的简单询问,更是一种启发式思维的体现。优秀的Prompt设计如同艺术家的调色板,能够精准地勾勒出所需的知识轮廓,促使模型在既有知识框架内创新性地生成答案。实践中,通过不断迭代Prompt策略,我们可以逐步解锁模型的深层潜能,使其在不同任务上展现出非凡的表现力。
1.3 RAG:智慧的嫁接
RAG(Retrieval-Augmented Generation) 结合了信息检索与生成模型的优势,它在生成回答之前先检索相关文档或知识库,然后利用这些信息辅助生成更精确、信息量更丰富的回答。这种方式有效缓解了大模型无法回答私域知识的问题,使得模型能即时访问到具体事实,提升回答质量。
RAG技术代表了知识获取与创造的智慧融合,它强调模型不是孤立的知识岛,而是能够与外部世界知识实时互动的智慧体。
1.4 微调:针对性优化
微调(Fine-tuning) 是一种模型适应特定任务的方法。它基于预训练的大模型,通过在特定领域的数据集上进行额外训练来调整模型参数,以更好地服务于该领域的任务需求。微调可以显著提升模型在特定任务上的性能,但可能需要足够的标注数据和计算资源。
1.4.1 RAG v.s. 微调
在之前章节中,我们介绍了一个使用RAG帮助旅客找路的例子。
对大模型进行以下操作,你也可以达到类似的效果。
- 挑选出志愿者过往正确指路经历的对话数据集,类似于这种形式:
[{"instruction":"银锭桥怎么走?","output":"您向东走50米,拐个弯就到了。"}......]
- 对大模型进行微调。
- 向大模型进行提问并检验效果。
你会发现在回答效果上,RAG与微调的效果几乎一样。二者的区别如下表所示:
|
对比项 |
RAG |
微调 |
|
应用场景 |
解决垂直领域知识问答的“幻觉”问题 |
解决风格化生成和垂域系统指令生成问题 |
|
技术能力要求 |
需要了解如何使用向量数据库 |
需要有较强的数据预处理能力 需要熟悉微调的参数体系和调整策略 |
|
成本比较 |
部署和运维线上推理服务与向量数据库 |
微调训练成本,部署运维成本,需要专业技术人员操作 |
|
数据集准备 |
准备一份知识库文档即可 |
需要在知识库文档里提取高质量问答对 |
|
最终输入大模型的token个数 |
需要将知识与问题拼接起来,输入大模型的tokens个数较多 |
只需输入问题即可,输入大模型的tokens个数很少 |
|
推理速度 |
经过检索、生成两个步骤,且向大模型输入较多token,推理速度相对较慢 |
直接推理,速度较快 |
|
知识更新的及时性 |
可以做到准实时,只需要及时地更新知识库中的文档 |
比RAG慢,微调训练需要花费较多时间 |
RAG和微调并不是互斥的,二者可以同时使用。
1.5 Agent与多模态
- Agent概念通常指的是可以通过组件或工具与外界环境进行交互的大模型应用。它能够扩展模型的功能,比如增加特定领域的知识、优化交互流程或实现定制化逻辑,使模型更加灵活高效地应用于实际场景。
- 多模态指的是模型能够处理和整合多种类型的数据,如文本、图像、声音等。在大模型领域,多模态技术的融合旨在让模型具备跨媒体理解和生成能力,这对于提升模型在复杂应用场景中的表现至关重要,如图文并茂的问答系统、视频内容分析等。
2 看看大模型希望我们如何使用大模型
(第二章节的内容文字底稿由通义千问辅助生成)
在当今这个智能技术日新月异的时代,大模型作为人工智能领域的一项重大突破,正逐步展现其在各行各业的无限潜力。而将大模型融入日常工作实践,是一件充满挑战也蕴含无限可能的事业。
2.1 要耐心
大模型拥有惊人的学习能力和广泛的应用场景,但同时也伴随着庞大的计算需求与优化挑战。初次接触大模型,你可能会遇到模型实际输出不达预期,等待模型输出的时间太长等问题。这时请不要气馁,我们教导模型学习正如我们教导小孩子做事情一样,需要一些时间去学习去磨合,了解如何与这些复杂的系统合作,完成迈向成功的每一步。耐心,能帮助我们更加细致地观察模型的行为,理解其内在逻辑,找到优化的路径。
2.2 多尝试
大模型的强大之处,在于其能够跨越传统算法的界限,实现从前难以想象的任务。过去训练一个文本处理算法我们需要一个专业算法工程师,准备充足的训练语料,耐心的清洗数据和优化模型结构,从而花上一到两个月来训练一个稳定可靠的的文本处理算法。而今,我们只需要调整几句提示词就可以大幅提升大模型的输出效能,快速满足应用需求。在这里,没有一成不变的规则手册可以遵循。每一个项目,每一种应用场景,可能都需要定制化的解决方案。不妨将每一次使用大模型的实践视为一次实验,保持开放的心态,勇于尝试不同的参数、不同的提示词、甚至是对模型进行微调训练。不断地试错与调整,逐步逼近我们期望的最优化的结果,发现大模型真正的价值所在。
2.3 持续学习
人工智能领域正处于高速发展的阶段,新算法、新工具、新实践层出不穷。深入理解大模型和大模型应用背后的核心原理与技术架构,比如注意力机制、Transformer结构、大模型插件、RAG原理,能帮我们更准确地驾驭大模型工具,创造出更加智能、高效的解决方案。
2.4 跨界合作
大模型的应用不仅仅是技术领域的独角戏,它需要与行业知识、社会需求紧密结合。与不同背景的专家合作,如领域专家、设计师、产品经理等,能够激发出意想不到的创意火花,推动大模型在教育、医疗、环保等各个领域发挥出更大的社会价值。
总之,在大模型的探索之旅中,耐心是我们的罗盘,不断尝试是我们的风帆,持续学习是我们的航标,跨界合作则是我们的加速器。让我们携手并进,在人工智能的浪潮中,共同开创一个更加智慧、高效、可持续的未来。
3 拓展阅读
通过浏览百炼与PAI的文档,你可以学习如何使用阿里云的AI产品来完成你的任务。
访问通义千问官方GitHub主页,可以帮助你掌握通义千问开源模型的部署和微调方法。
在ModelScope官网,你可以找到各种开源模型与数据集,也可以在社区中与专家交流。
通过浏览LangChain官网,你可以学习到如何使用这个框架来开发由大模型驱动的应用程序。
4 结语:持续的探索与创新
在大模型的实践征途中,持续的学习、开放的合作态度、以及勇于创新的精神是不可或缺的。每一次技术的革新都是对未知的勇敢探索,每一次应用的突破都是对智慧边界的拓宽。我们正站在一个人工智能变革的新时代入口,大模型作为这一时代的标志性技术,其潜力的挖掘与应用的拓展,将深刻影响着社会的每一个角落。
让我们以学者的严谨、探险家的勇气,以及艺术家的创造力,共同推动大模型技术的进步,探索人工智能与人类社会共生共荣的新篇章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号