面向对象第一单元总结
第一次作业总结
第一单元希望我们能够建立面向对象程序的认识
总结分析,通过第一次作业,我建立了一个面向对象程序的框架,包括了理论课所述的三个关键模块:输入处理、主控、核心数据管理
任务概览
对一个简单的,含双层括号的表达式进行展开化简
思路分析
首先确定处理输入的大致流程如下:
我的顶层数据结构设计如下:
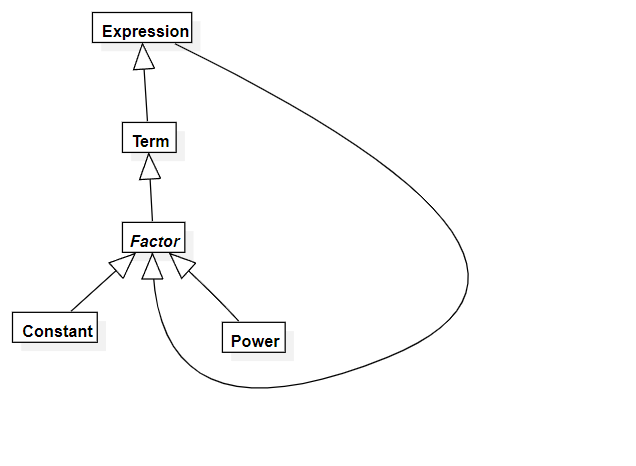
- 其中
Expression类是Term的容器,其中容纳很多不同的项 Term类是Factor的容器,其中容纳着很多因子- 因子分为三种,分别是
Constant常数因子、Power幂因子和Expression表达式因子,可以看出这样的数据结构设计天然支持了多层括号嵌套
我的输入处理逻辑如下:
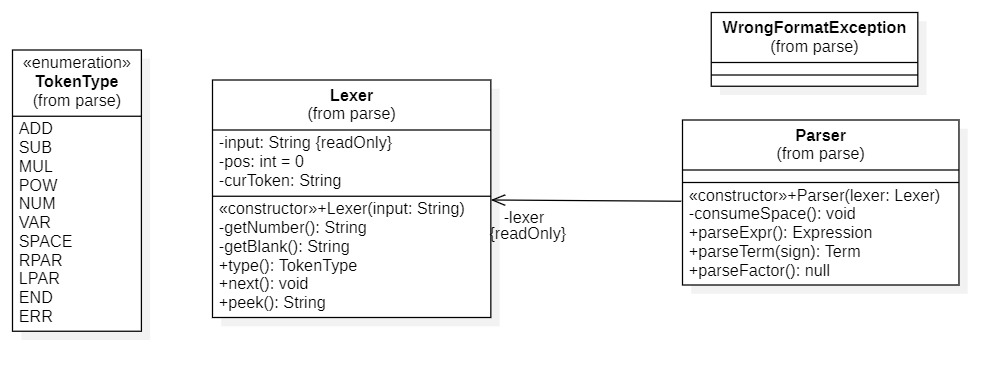
- 采用典型的递归下降法进行解析
Lexer是词法分析器,负责把表达式拆分成为各种Token,Token的种类由TokenType定义Parser通过获取Lexer解析得到的Token构造上述的数据结构,如果读到词法错误则返回WrongFormatException- 然后把构造得到的
Expression交还给Main主操作逻辑进行展开化简调用
整体类图如下:
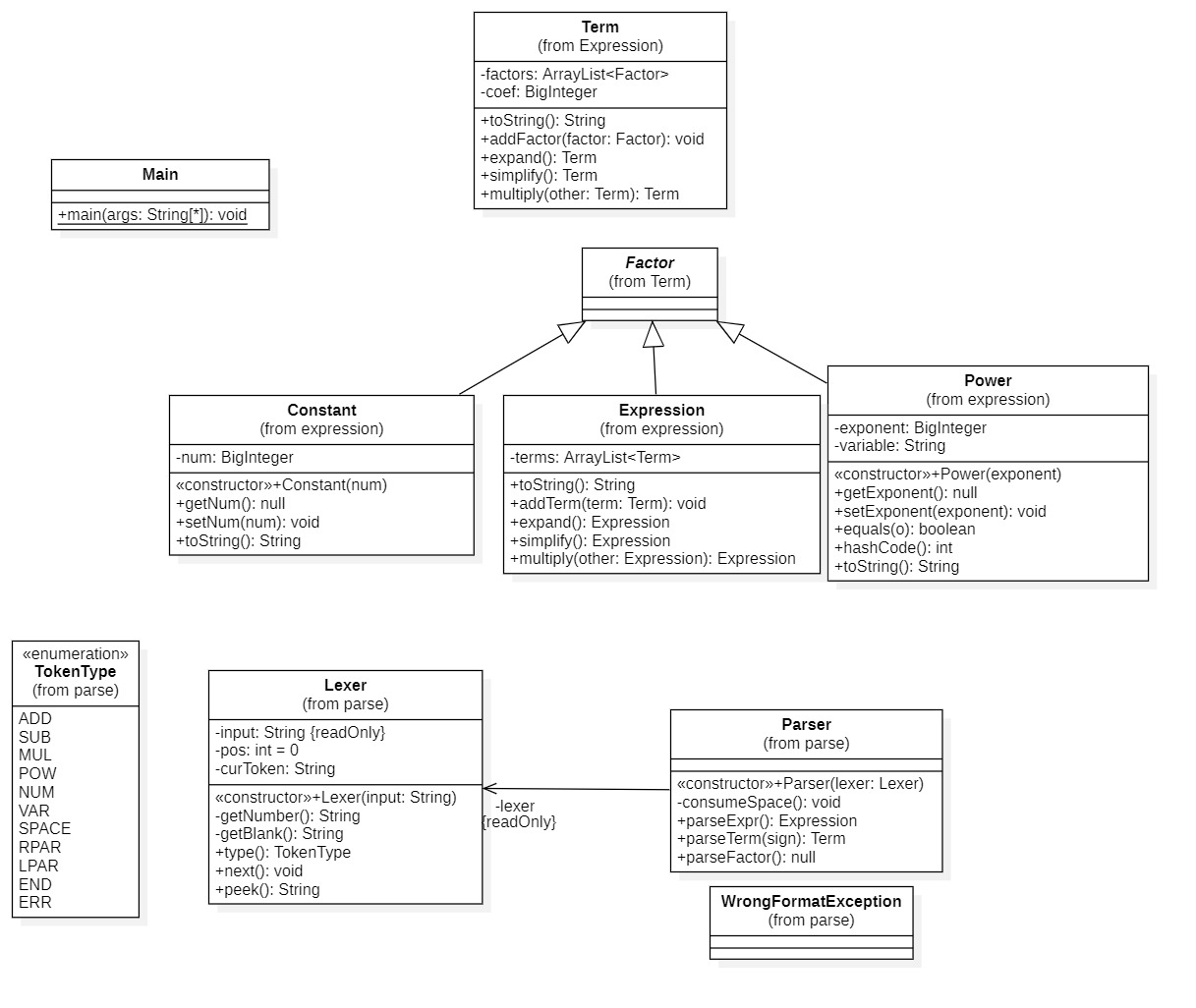 svg)
svg)
关于展开和化简的处理方法,我的思路是:
- 对于每一个
Expression型和Term型对象,均为其定义一个expand()方法和simplify()方法,实现这一个表达式的展开和化简 - 为了下面的处理方便,我首先对于
Expression型和Term型对象,定义了$\mathrm{Expression} \times \mathrm{Expression} \((返回一个新的`Expression`)和\)\mathrm{Term} \times \mathrm{Term}$(返回一个Expression) - 展开的过程完全模拟人手算多项式展开的过程
- 对于Expression的展开,我们先对每一项进行展开,然后进行拆包合并,之所以要拆包是因为可能
Term返回的结果是一个表达式,但是却被包装成了Expression(Term(Expression(terms))),我们想要的是最内层的terms,因此需要拆包 - 对于Term的展开,假设某一项为\(2\times x^2\times(x+1)^2\times x^5\)
- 首先提取出所有不是表达式因子的因子,合成一个新的表达式因子,即变成\((2x^2\times x^5)\times(x+1)^2\)
- 这样项中仅仅只会剩下表达式因子,对每个表达式递归调用展开
- 然后利用表达式乘法得到一个新的表达式,将其包装成
Term(Expression(terms))的形式返回即可
- 由于第一次作业结果仅含幂因子和常数因子,为此我采用了最简单暴力的合并方式
- 对于每一项,寻找所有的
Constant因子,将其删去,合并入Term.coef - 对于每一项,寻找所有的
Power因子,将其删去,将其exponent相加,最后若\(\mathrm{exponent}>0\)则加入一个新的Power因子 - 对于表达式,首先化简每一项,重写
Term.equals(),使两个Term相等的充要条件为相同幂函数的\(\mathrm{exponent}\)相等 - 用一个两层循环寻找相同的
Term合并,并将系数相加
- 对于每一项,寻找所有的
关于表达式的输出方法:
- 对于每一种数据结构中的类,我们都重写其
toString()方法 - 通过
toString()的相互调用实现表达式打印,例如Expression类的toString()方法会调用Term的toString()打印项,然后在项之间加入+和-号 - 如果表达式作为因子出现在内层(本次作业并没有这一项要求),需要在表达式外面套一层括号(这也为我在第三次作业中出现bug埋下伏笔)
优化技巧
- 首先最容易想到的优化就是把
x**2简化为x*x输出(这也为我在第三次作业中出现bug埋下伏笔,请记住在形式化描述中x**2是一个因子,但是x*x是一个项,必须套在表达式里面出现,所以在某些情况下x*x外侧需要套上括号) - 项中出现0,则全项均为0;项的系数+1/-1时无需输出;表达式中含有许多项时,为0的项不用输出
- 一个不是很容易想到,但是也不难实现的优化是:在表达式的输出中,我们总是尽量选择使得第一项的系数为正的输出,这样会少输出一个字符,其实实现就是在输出之前先循环判断有没有系数为正的项
int firstOutput;
for (int i = 0; i < terms.size(); i++) {
if (terms.get(i).getCoef().compareTo(BigInteger.ZERO) > 0) {
firstOutput = i;
break;
}
}
if (firstOutput != -1) {
sb.append(terms.get(firstOutput).toString());
} else {
firstOutput = 0;
sb.append(terms.get(firstOutput).toString());
}
测试方案和Bug分析
强测互测中均未被发现Bug,简要说一说发现的他人的Bug,互测房间中出现的唯一Bug就是如果结果为0时输出为空,这一点仔细思考后不难发现
强测性能分得分100,说明优化做的还是较为充分的
关于测试,自己写一个评测程序既有利于自己的测试,也有利于在互测房间中发现其它人的Bug(),下面简要分享一下评测程序的写法:
-
Python有方便的sympy符号计算库,因此选择通过Python实现 -
由于本次作业输出唯一,因此不用采用
eval()选点取值运算,直接expand().simplify()之后比较字符串是否相同即可 -
生成测试数据可以一样采用递归下降的方法,通过
\[生成表达式\rightarrow生成项\rightarrow 生成因子 \rightarrow选择一种因子 \left \{ \begin{array}{**lr**} \mathrm{Const}常数, & \\ \mathrm{Power}幂函数因子,\\ \mathrm{Expression}表达式因子(又回去了..), recursion\_depth < 1 & \end{array} \right. \]从而生成一个合法的表达式字串,然后交给
sympy.sympify()解析化简就好,通过改变一些参数(如项数,指数大小,递归深度)可以生成不同复杂度的数据,但是随机数据的缺点是很难得到一些极限数据
量化指标评估
圈复杂度(Cyclomatic Complexity)是衡量计算机程序复杂程度的一种措施。它根据程序从开始到结束的线性独立路径的数量计算得来的,圈复杂度越高,代码就越难复杂难维护
ev(G) 基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
iv(G) 模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G) 是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
利用IDE自带的MetricsReload插件可以得到代码的圈复杂度如下:
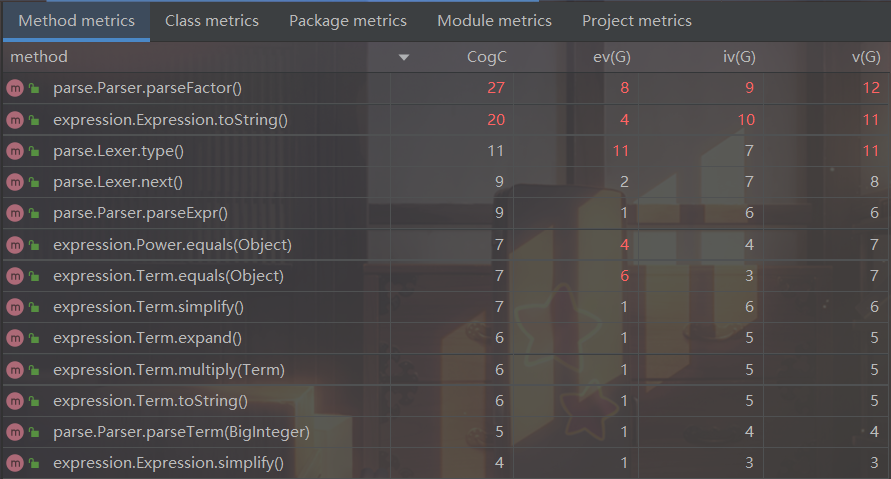
从表中可以看出,parseFactor()方法的圈复杂度最大,这是由于递归下降时对Factor的处理将各类Factor均放在了一个方法中处理的缘故,另外Expression.toString()方法的复杂度也明显过大,这是由于在toString()中处理较多的特殊情况所致,事实上,最后一次作业中出现的小Bug就是toString导致的
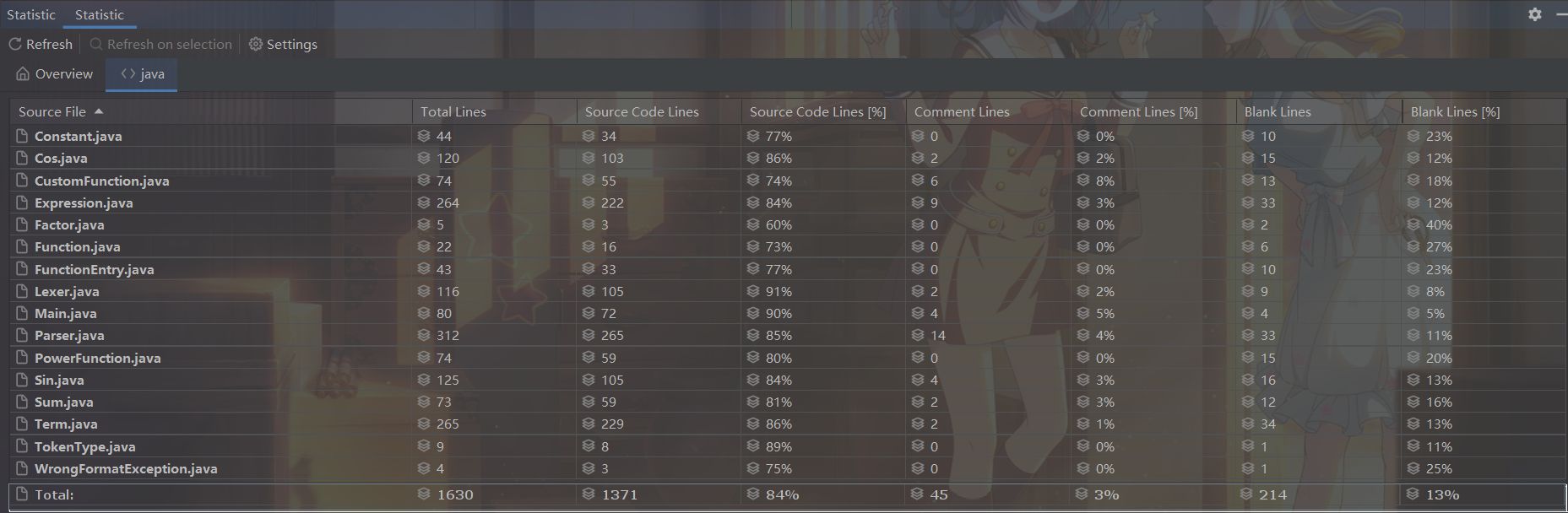
另外利用Statistic插件统计代码行数如下:
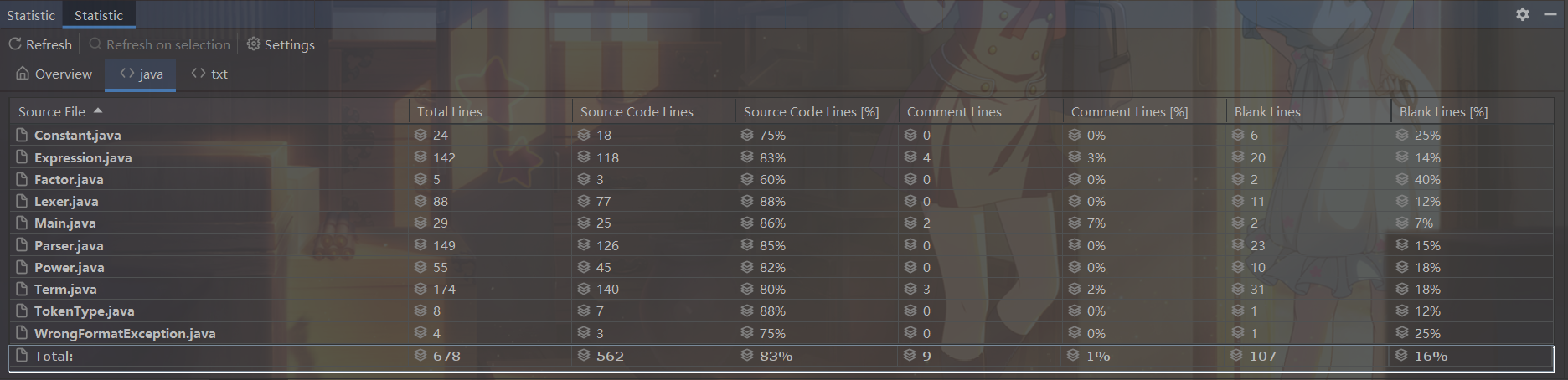
可以看出总代码量并非很大,两个关键类Expression和Term主要负责化简和展开逻辑,所以代码行数最多,这也在正常范围内,Parser类由于需要实现各种语素的解析,代码行数也较多,考虑下一次作业进行分拆
第二次作业总结
总结分析,通过第二次作业,程序设计方面值得反思的是,在进行迭代开发时,一个好的可扩展的架构是非常重要的,关于语言特性方面,而且需要去深刻理解Java中的深拷贝浅拷贝的不同,以及其带来不同效果
任务概览
对一个支持自定义函数、求和函数和三角函数,包含嵌套括号的表达式进行展开化简
与上次作业的难度相比有了质的飞跃,支持了许多复杂的功能
思路分析
上次作业虽然没有被hack,但是自测时发现运行效率很差,甚至无法在规定时间内展开\((1+x)^{100}\),究其原因,可能是先展开后化简的逻辑导致表达式内的项过多,简单暴力的合并算法的时间复杂度很差,因此这次作业我把执行逻辑改成了:
即在递归展开的过程中,每当展开出一个表达式就立刻进行化简,然后合并。最后再进行一次特殊的三角化简,专门处理类似于\(sin^2(x)+cos^2(x)=1\)的情况
为了支持新增的各种函数,我的顶层数据结构变为:
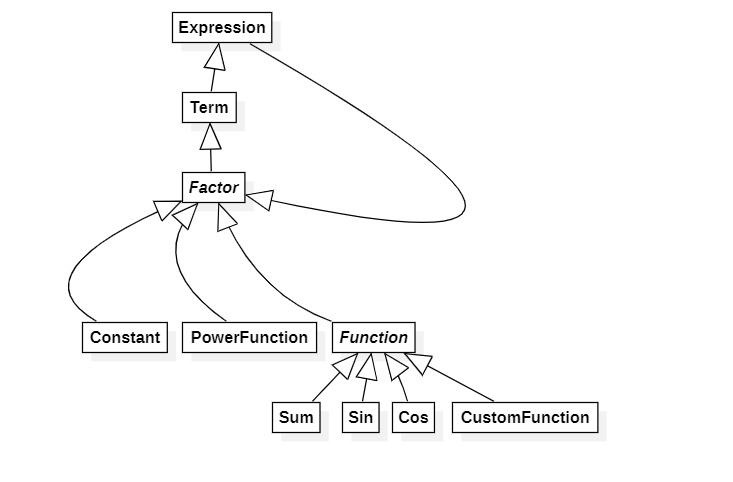
- 函数因子也是一种因子,我将所有函数抽象为
Function(但是看上去没啥用) Sum,Sin,Cos,CustomFunction都是新增函数,我让他们间接继承了Factor(先继承Function),它们需要实现calculate()方法,展开化简,并返回一个表达式(但是最后Sin和Cos写的是返回Sin和Cos)Factor变成七选一,其余没什么变化
输入解析部分变化并不大,只需要添加对sum, sin, cos, f, g, h等函数的解析部分即可,因此示意图和类图就不再放出
总的类图如下:
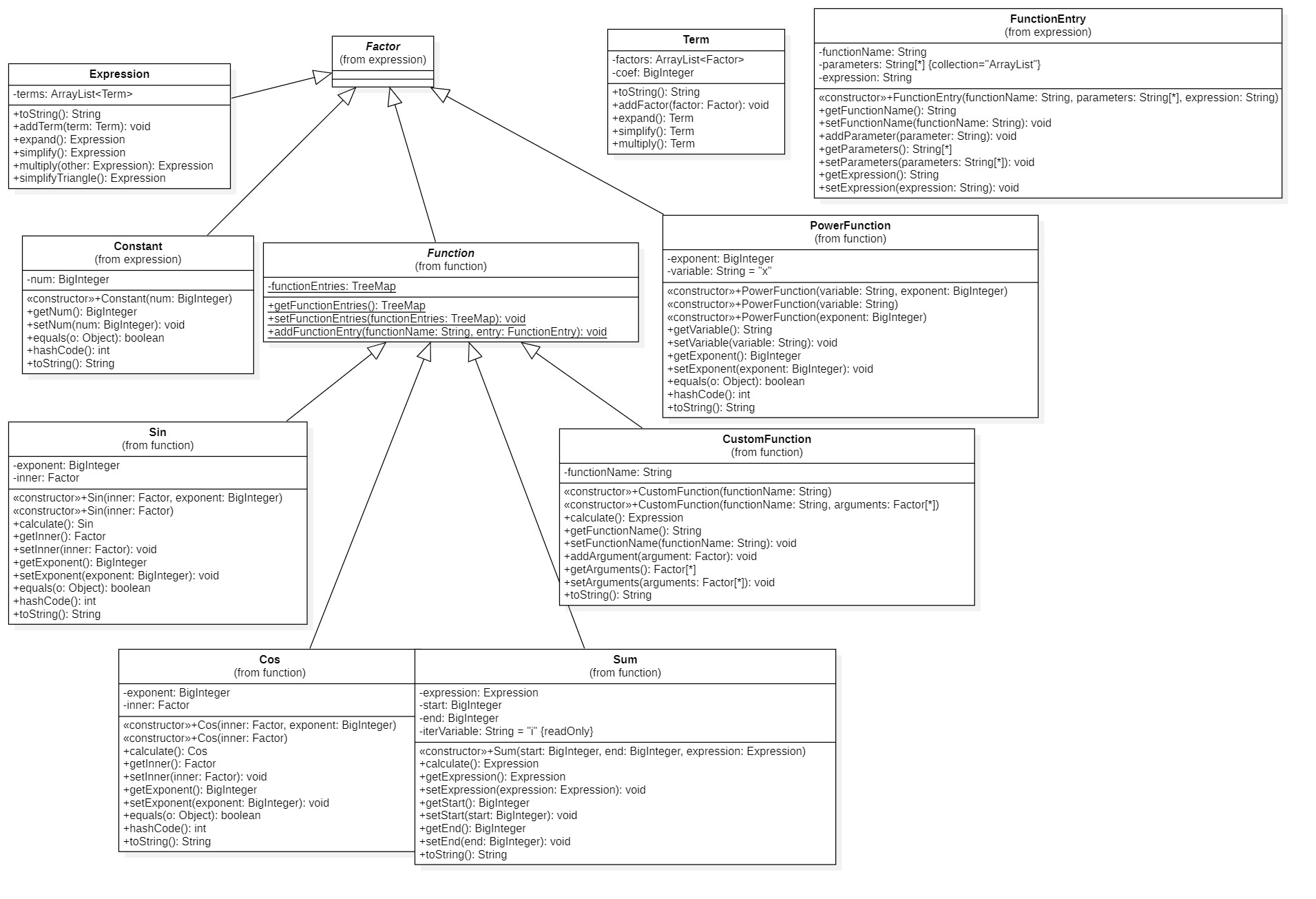
对于新增函数的处理:
-
每一种函数都继承
Function类,本意是想将函数抽象成含有函数名name和参数列表parameters的类,然后每个类分别实现calculate()方法,返回展开函数得到的Expression,但是本次作业和下次作业对函数的规定是死的,最终也没有采纳这种做法 -
对于
Sin和Cos类,由于内部只能有幂因子或常数因子,所以calculate方法只是对常数做了少许处理,例如\(\mathrm{sin}^2(-2)=\mathrm{sin}^2(2)\)和\(\mathrm{cos}(-2)=\mathrm{cos}(2)\)等优化,因此返回值仍然是Sin和Cos类型,这使得第三次作业时,我对这一部分进行了彻底的重写 -
对于
Sum类,我使用了字符串直接替换的方法处理int i; for (i = start; i.compareTo(end) <= 0; i = i.add(BigInteger.ONE)) { String exprString = expression.toString(); System.out.println(exprString); String tempString = exprString.replace("sin", "~"); exprString = tempString.replace(iterVariable, "(" + i + ")"); Lexer lexer = new Lexer(exprString.replace("~", "sin")); Parser parser = new Parser(lexer); Expression stepExpression = parser.parseExpr(); ans.addTerm(stepExpression.getTerms()); ans = ans.expand().simplify(); }这样做需要注意的是:
sin里面也含有i,因此不能简单直接做字符串替换;其次可能sum的调用是sum(i, 1, 10, i**2),因此这时不能直接直接把i换成常数,需要先在外面套一层括号再进行操作但是字符串替换不优雅,而且很容易引入Bug(第三次作业的Bug就是源自这里),所以一个更好的解决方案应该是顺着已建立的数据结构进行递归的代入(
-
对于
CustomFunction自定义函数类,我在Function类里维护一张static的函数调用表functionEntries,包括函数名,函数体和函数形式参数,然后在表达式解析时解析函数的函数名和实参,CustomFunction的calculate()方法也是利用字符串替换的方法,直接用实参外面套上一层括号替换形参,然后对表达式进行再解析,然后展开化简得到结果- 这里的一个坑点是函数的形参未必是以
x, y, z的顺序给出,因此替换时也要考虑顺序无关,我的做法是把x, y, z分别替换成~, !, @然后再带入,这样就不会出现问题
- 这里的一个坑点是函数的形参未必是以
优化技巧
对合并同类项的优化,这次学习了讨论区分享的优秀做法,利用HashMap进行合并同类型:
- 由于是在第一次的基础上修改,因此没有在一开始就把数据存入
HashMap中,我的做法是:
- 实际操作中,各项的合并很容易,IDE可以直接生成
hashCode和equals方法,HashMap随即“天然”支持了合并各项的操作 - 但是这样处理因子就不行,\(x^2\)和\(x^5\)在合并同类项时不可合并,但是在同一项中作为因子可以相乘
- 我的做法是:为每一种因子规定一个标准(standard),
getStandard()方法可以给出各种因子的标准,例如sin(x**2)**2的标准就是sin(x**2),x**2和x**5的标准都是x**1,让因子的标准参与进行哈希碰撞,遇到可以合并的则将指数相加 - 由于第一次的设计中
Term和Expression均有simplify()方法,直接修改对应方法即可,体会到了设计架构解耦带来的好处
我在Term的simplify()方法中花了大量的篇幅去优化\(\mathrm{sin}(0)=0, \mathrm{cos}(0)=1\),但他们放在函数的calculate()方法中反而更为合适,这是设计不太好的地方
最后为Expression类单独添加了三角优化(属于是灵机一动),这个方法有种投机取巧的感觉,所以我索性把它挂在了simplify()外面,(以防出了问题好删掉),单独提了一个simplifyTriangle()方法
基本思路是记原表达式为\(O\);遍历一遍,遇到一个\(\mathrm{sin}\),如果幂次高于2,那么我们取出其中一个\(\mathrm{sin}^2\)把它替换成\(1-\mathrm{cos}^2\),然后重新展开化简,记得到的表达式为\(S\);再遍历一遍\(O\),如果遇到一个\(\mathrm{cos}\),如果幂次高于2,那么我们取出其中一个\(\mathrm{cos}^2\)把它替换成\(1-\mathrm{sin}^2\),然后重新展开化简,记得到的表达式为\(C\)
最后输出\(length(O), length(S), length(C)\)中最小的那个表达式
这样做竟然能顺利化简强测的所有情况()
然后用这种看似不靠谱的方法强测拿到100...
测试方案和Bug分析
强测互测中均未被发现Bug,简要说一说发现的他人的Bug,一种是三角函数的疏忽,如\(\mathrm{sin}^2(-1)=-\mathrm{sin}(1)\)错误,还有的是第一次遗留的0输出空串的错误,还有两人出现了下面我自测时测得的Bug
关于测试:自测时找到了一个隐藏很深的Bug,就是\(\mathrm{sin}^0(0) = 0\),这是通过随机生成的复杂大数据逐步化简找到的问题,细节需要多注意,特别是这种需要特判的问题;测试一定要细致,大规模数据之前要先手测小数据,确保程序的每种执行情况都是对的
互测策略:利用评测程序狂轰滥炸,得到错误数据后缩小范围
量化指标评估
圈复杂度如下图,全线飘红,显然设计的不是很好~
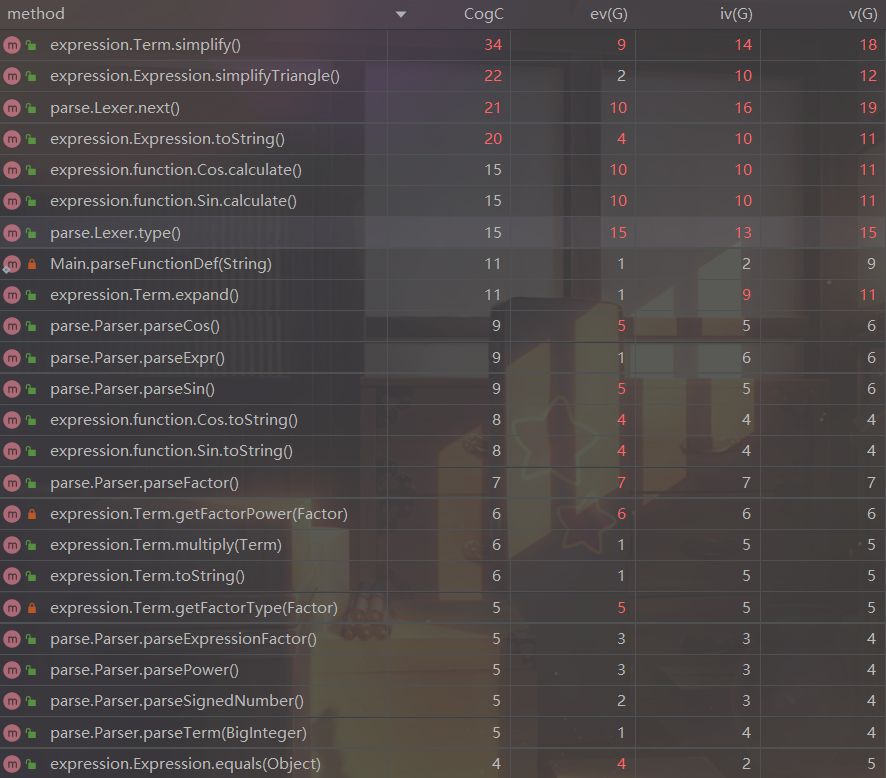
最大的问题Term.simplify()前面已经之处,在里面加入了不合理功能,以至于其复杂度都很高
其次是Expression.simplifyTriangle(),这是最后加入的优化函数,仅仅作为外挂优化函数存在,可以考虑建一个静态工具类存放这些方法
Lexer和Parser两个由于采用了递归下降法,复杂度高是必然的,而且近乎无解的,因为递归下降方法中,所有解析函数其实都是层层嵌套、互相耦合的,相互调用,才能完成表达式的解析
Expression.toString()又是一个遗留问题,我把所有的输出时优化都放在toString()里,也只能是这样的解决方案了
为了方便省事,我把getStandard()方法全部集成到了Term类内部,于是乎出现了下面这样的代码:
private Factor getFactorType(Factor e) {
if (e instanceof Constant) {
return new Constant(((Constant) e).getNum());
} else if (e instanceof PowerFunction) {
return new PowerFunction(((PowerFunction) e).getVariable(), BigInteger.ONE);
} else if (e instanceof Sin) {
return new Sin(((Sin) e).getInner());
} else if (e instanceof Cos) {
return new Cos(((Cos) e).getInner());
} else {
return null;
}
}
感觉非常丑陋,更好的做法应该是我设想的那样,在每个Factor的子类中定义getStandard()方法,获取自身的标准
反思一下:对Java的继承和抽象还是不够熟练,三次作业都没有使用接口,感觉在动手之前思考规划的还不够,有很多可以被抽象提取出来的方法,比如expand(), simplify(), calculate()都没有提取
还有开发的时候不是很理解深浅拷贝,为了安全,直接全部都深拷贝了新的对象,可能会浪费大量内存吧()
但是有一点很好,就是类的功能定义很清晰,耦合度不是很高,每个类都在做自己的事情,例如Parser就是在解析,没有插手任何化简和展开的功能,在互测房间中我看到有的同学在解析时就把\(cos(0)\)替换成了1,把\((1+x)^2\)替换成了\((x+1)(x+1)\),直接把sum(i, 1, 10, i)替换为1+2+3+...+10,这样Parser做了不属于自己的功能,可读性不高,而且后续迭代和增量开发较难,Bug容易出现
代码行数达到惊人的1300+,写了许多无用的getter和setter,又是一个顶层设计不周全的体现
第三次作业总结
任务概览
对一个支持自定义函数、求和函数和三角函数,包含嵌套括号的表达式进行展开化简
三角函数里支持嵌入表达式因子,函数支持嵌套调用
思路分析
上一次其实我就已经支持了函数嵌套调用的功能(因为反正就是对字符串做的替换再解析),因此这一次我着重去重写了Sin和Cos的calculate函数
本周大部分精力花在了sin和cos的拆包化简上,但是最后收效甚微,不如去做一些二倍角公式之类的化简
-
Constant- 提出符号:\(sin^3(-1) = -sin^3(1)\),但指数为偶数不需要提
-
Power- 拆
Power:\(\mathrm{sin}(x^1) = \mathrm{sin}x\),可能需要考虑符号 - 化
Power为Constant:\(\mathrm{sin}(x^0) = \mathrm{sin}(1)\)
- 拆
-
Termfactors为空:\(\mathrm{sin}(C * [empty]) = \mathrm{sin}C\)\(\mathrm{sin}(x^1) = \mathrm{sin}x\),可能需要考虑符号- 拆
Term:\(\mathrm{sin}(1*[x^{\mathrm{exp}}]) = \mathrm{sin}(x^{\mathrm{exp}})\)\(\mathrm{sin}(x^1) = \mathrm{sin}x\),可能需要考虑符号 - 拆
Term和Power:\(\mathrm{sin}(1*[x^{\mathrm{1}}]) = \mathrm{sin}(x)\)\(\mathrm{sin}(x^1) = \mathrm{sin}x\),可能需要考虑符号
-
Expression-
terms为空:\(\mathrm{sin}((C*[empty])) = \mathrm{sin}C\) -
terms只有一项 \((T_0)\)- Powers 为空 \(T_0 = C * [empty] \rightarrow \mathrm{sin}(T_0) = \mathrm{sin}C\)
- 系数为 1,而且 Powers 只有一项 \(T_0 = 1 * [x^{\mathrm{exp}}] \rightarrow \mathrm{sin}(T_0) = \mathrm{sin}(x^{\mathrm{exp}})\)
- 系数为 -1,而且 Powers 只有一项 \(T_0 = -1 * [x^{\mathrm{exp}}] \rightarrow \mathrm{sin}(T_0) = -\mathrm{sin}(x^{\mathrm{exp}})\)
-
这些规则需要去写大量的if进行判断,很难验证会不会出错
整体数据结构与上一次作业相似,但是作为作业的规定动作,我把类图放出来:
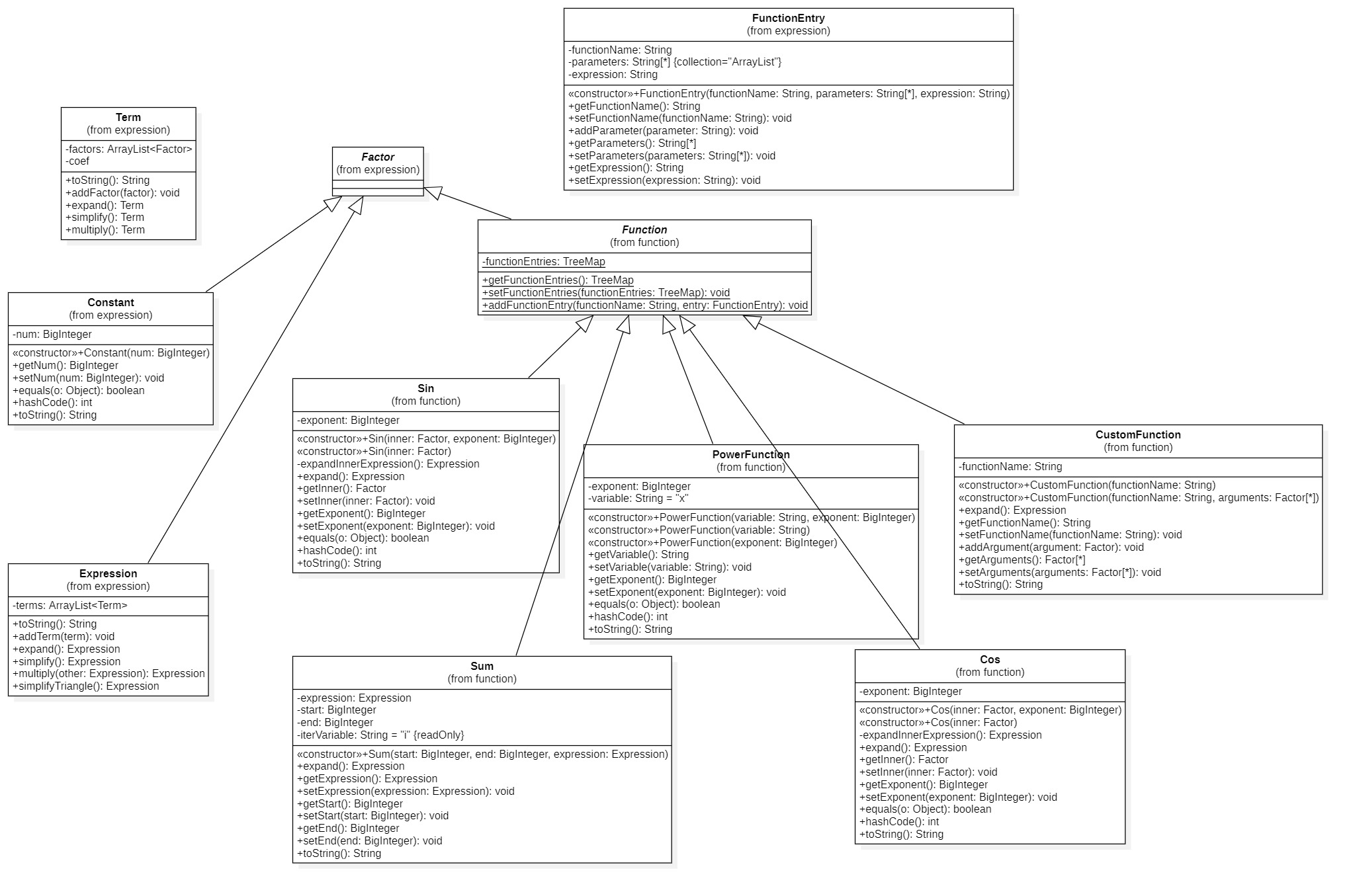
虽然类图越来越复杂,但是其基本逻辑还是源自于我第一次作业的数据结构设计,所以可以说刚开始的设计还不错,但是后面迭代开发迭代的越来越丑陋了...
这次最大的改变就是重写了Sin.expand()和Cos.expand()
优化技巧
- 三角化简:二倍角公式、和差化积公式等...(但是没有做)
- 形如\(\mathrm{sin}(\mathrm{sin}(-x))=-\mathrm{sin}(\mathrm{sin}(x))\)的优化,可能对合并同类项有好处
Bug分析
互测时被发现一个Bug,被同房间人hack两次
| Bug | 所在类 | 所在方法 | 原因 |
|---|---|---|---|
sum(i, 1, 10, sin(i**2))会抛出WrongFormatException |
Sin |
toString |
考虑不周 |
在中测时已经注意到了形如1;f(x)=x**2;sin(f(x))会出现问题,这是由于CustomFunction.toString()会在这时返回x*x,但是sin(x*x)并不是合法的输出,因此会显示我的程序输出错误的答案,本来这里已经通过特判解决了问题,但是却忽视了i*i会产生一样的错误
出现Bug的方法圈复杂度反而不大,与设计架构无太大关系,应只是自身考虑不周所致,修复Bug也仅需要添加一行代码即可
发现了同屋人的其它Bug有:
sum(i, <一个大于int的数字>, <一个大于int的数字>+1, i)会爆sum(i, -1, -2, i)会报错或错误输出(没有考虑到sum不累加的情况)sin(sin((-x)))输出sin(sin(x)),嵌套函数提出符号出错sin((-x))**2输出-sin(sin(x))**2,提出符号忽视指数影响
这次没有写评测程序,hack他人主要依靠自己调试的经验和阅读代码,但是可能本次作业较为复杂,大家的Bug也挺多的
量化指标评估
圈复杂度如下:
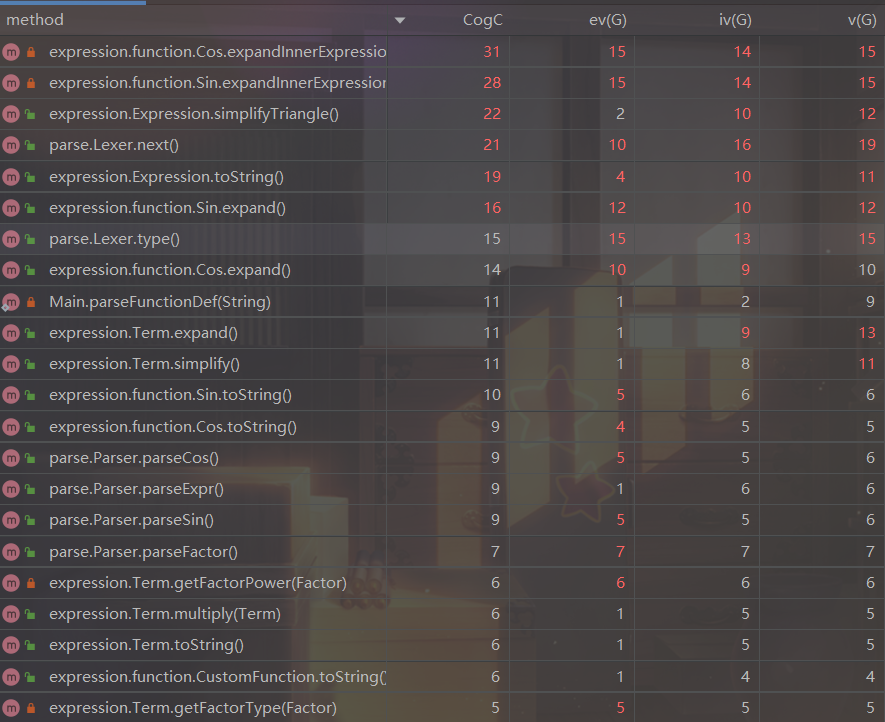
可以看到我在思路分析里列举的展开内部表达式的Sin.expandInnerExpression()和Cos.expandInnerExpression()复杂度非常高,因为这两个方法在拆包时本身就需要考虑许多情况,因此if很多,执行情况也很多,也更容易出Bug,所以我对这两个方法做了非常详尽的测试,尽可能枚举了所有情况
Expression.simplifyTriangle()本次没有做任何改动,因此还是很复杂
与上次作业相比,Term.expand()去掉了许多不属于Term的功能,因此复杂度降了下来
综合三次作业,复杂度一直很高的是Lexer.next()和Expression.toString(),本次作业也没做任何改动
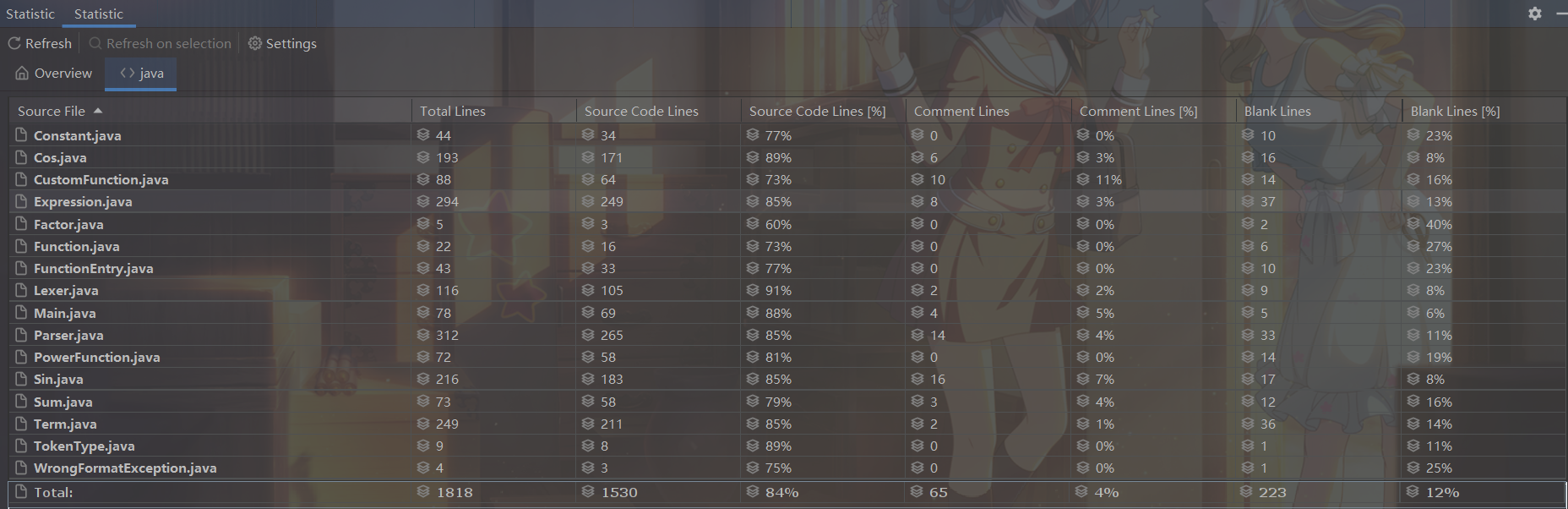
代码量与上次作业相比,主要增加的就是Sin.expandInnerExpression()和Cos.expandInnerExpression(),因此也没有做什么大的变化
第一单元总结
经验与教训
- Pre重要,至少可以教会我什么是类,什么是方法,类可以用来干啥
- 用面向对象的思想去思考,先想再写,重写部分代码不难,就是害怕架构出了问题需要重新设计
- 设计架构要预留好以后更新功能的空间
- 要善用讨论区
- 自动评测机和随机数据生成非常重要
- 注重细节,学会测试方法
设计迭代总结
- 第一次作业的设计可以说是数据结构指导的,之前就已经了解到第一单元是与表达式相关的处理,因此很自然的把表达式拆开按照项和因子进行组织,而因子中可以递归出现项则完成了表达式嵌套的任务
- 第二次作业的设计则不尽如人意,主要是再变量带入部分使用了完全的字符串替换处理,破坏了原有的表达式树的结构,而且再解析一次表达式的做法也不优雅,容易出现隐蔽的解析错误(所以我强制在代入项外面加上一层括号),而且直接导致了第三次出现Bug。但是整体的数据结构设计依然是树状的,有规律可循的,方法安排也较为恰当,可以说基本符合了面向对象的要求,用类管理数据
- 第三次作业则没有敢有太大的动作,只能在第二次的基础上尽力修修补补,避免出现上面所说的因为字符串替换而出现的Bug,但是很不幸还是没能考虑周全
心得体会
本次作业是第一次用Java完成一个小规模的项目,最大的收获是对于 Java 的了解更加深入透彻。体会到了用容器去替代数组能够更好的管理各项数据。初步了解了面向对象程序架构设计理念,不足之处是并没有像提示中所说在程序中利用工厂模式。
此外了解了递归下降法,递归下降的理念简单,实现非常巧妙,而功能非常强大,理论上可以解决任何能用形式化语言描述的予以解析问题?
除此之外,我也深刻认识到一个好的架构可以起到事半功倍的效果,但是自己并没有胆量去进行彻底的重构(也有可能是自己的设计可以缝缝补补,没有重构的必要)。
无论是为了自己测试,还是hack他人,评测机的编写以及数据的构造也是这门课程的一个重要部分,理论课上讲的测试要尽可能早开始,甚至测试指导开发的说法,我在本单元也有所体会,因为我对测试数据生成器正好和我的解析部分相反,正是按照递归下降的原理在生成数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号