python web框架-tornado
Web框架中的各个知识点:
Python的Web框架Tornado的源码
Python开发一个完善的MVC框架
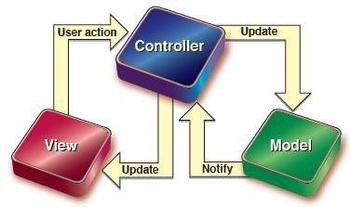
MVC模式
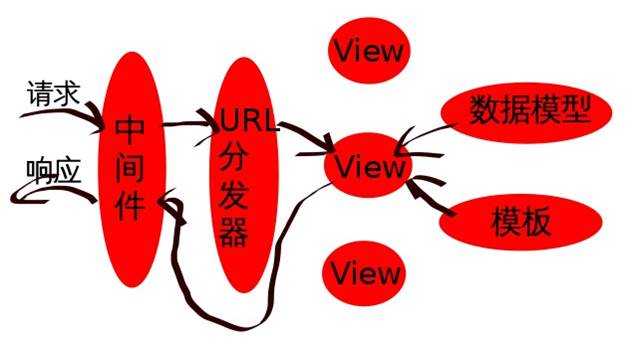
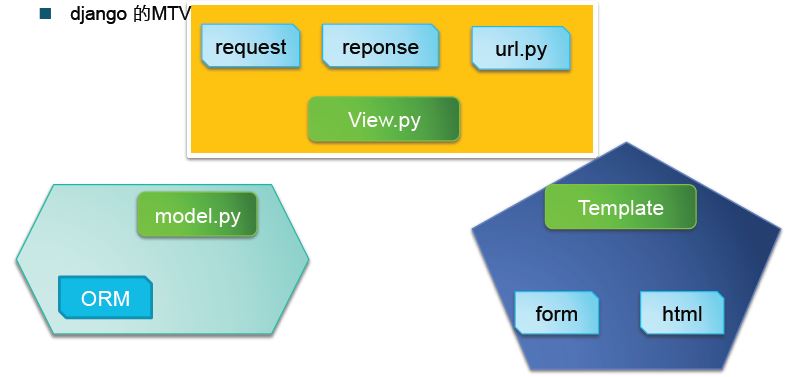
MTV模式
- M 代表模型(Model):负责业务对象和数据库的关系映射(ORM)。
- T 代表模板 (Template):负责如何把页面展示给用户(html)。
- V 代表视图(View):负责业务逻辑,并在适当时候调用Model和Template。
- Web服务器(中间件)收到一个http请求
- Django在URLconf里查找对应的视图(View)函数来处理http请求
- 视图函数调用相应的数据模型来存取数据、调用相应的模板向用户展示页面
- 视图函数处理结束后返回一个http的响应给Web服务器
- Web服务器将响应发送给客户端

比如,开发者更改一个应用程序中的 URL 而不用影响到这个程序底层的实现。设计师可以改变 HTML页面的样式而不用接触Python代码。
数据库管理员可以重新命名数据表并且只需更改模型,无需从一大堆文件中进行查找和替换。
Web框架本质
对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。


#!/usr/bin/env python #coding:utf-8 import socket def handle_request(client): buf = client.recv(1024) client.send("HTTP/1.1 200 OK\r\n\r\n") client.send("Hello, Seven") def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('localhost',8080)) sock.listen(5) while True: connection, address = sock.accept() handle_request(connection) connection.close() if __name__ == '__main__': main()
运行脚本并在浏览器上访问http://127.0.0.1:8080 注意:对于上述的demo来说,我们没有对请求做分析,对所有的请求都做了相同的处理。 上述分析: 1、浏览器其实就是一个socket客户端,而web应用其实就是一个socket服务端,并且web应用在服务器上一直在监听某个端口。 2、当浏览器请求某个web应用时,需要指定服务器的IP(DNS解析)和端口建立一个socket连接。 3、建立链接后,web应用根据请求的不同,给用户返回相应的数据。 4、断开socket连接。(之所以说http是短链接,其实就是因为每次请求完成后,服务器就会断开socket链接
上述通过socket来实现了其本质,而对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。
应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。
不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。这样,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论对于服务器还是框架,都是不好的。
对服务器来说,需要支持各种不同框架,对框架来说,只有支持它的服务器才能被开发出的应用使用。这时候,标准化就变得尤为重要。我们可以设立一个标准,只要服务器程序支持这个标准,框架也支持这个标准,那么他们就可以配合使用。一旦标准确定,双方各自实现。这样,服务器可以支持更多支持标准的框架,框架也可以使用更多支持标准的服务器。
WSGI
WSGI(Web Server Gateway Interface)是一种规范,它定义了使用python编写的web app与web server之间接口格式,实现web app与web server间的解耦。
python标准库提供的独立WSGI服务器称为wsgiref。
#!/usr/bin/env python #coding:utf-8 from wsgiref.simple_server import make_server def RunServer(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return '<h1>Hello, web!</h1>' if __name__ == '__main__': httpd = make_server('', 8000, RunServer) print "Serving HTTP on port 8000..." httpd.serve_forever()
自定义Web框架
通过python标准库提供的wsgiref模块开发一个自己的Web框架。
#!/usr/bin/env python # -*- coding:utf-8 -*- from wsgiref.simple_server import make_server from jinja2 import Template def index(): # return 'index' # template = Template('Hello {{ name }}!') # result = template.render(name='John Doe') f = open('index.html') result = f.read() template = Template(result) data = template.render(name='John Doe', user_list=['alex', 'eric']) return data.encode('utf-8') def login(): # return 'login' f = open('login.html') data = f.read() return data def routers(): urlpatterns = ( ('/index/', index), ('/login/', login), ) return urlpatterns def run_server(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) url = environ['PATH_INFO'] urlpatterns = routers() func = None for item in urlpatterns: if item[0] == url: func = item[1] break if func: return func() else: return '404 not found' if __name__ == '__main__': httpd = make_server('', 8000, run_server) print "Serving HTTP on port 8000..." httpd.serve_forever()
如何给用户返回动态内容?
- 自定义一套特殊的语法,进行替换
- 使用开源工具jinja2,遵循其指定语法
遵循jinja2的语法规则,其内部会对指定的语法进行相应的替换,从而达到动态的返回内容,对于模板引擎的本质。
1 路由系统
路由系统其实就是 url 和 类 的对应关系,这里不同于其他框架,其他很多框架均是 url 对应 函数,Tornado中每个url对应的是一个类。
#!/usr/bin/env python # -*- coding:utf-8 -*- import tornado.ioloop import tornado.web class MainHandler(tornado.web.RequestHandler): def get(self): self.write("Hello, world") class StoryHandler(tornado.web.RequestHandler): def get(self, story_id): self.write("You requested the story " + story_id) class BuyHandler(tornado.web.RequestHandler): def get(self): self.write("buy.wupeiqi.com/index") application = tornado.web.Application([ (r"/index", MainHandler), (r"/story/([0-9]+)", StoryHandler), ]) application.add_handlers('buy.wupeiqi.com$', [ (r'/index',BuyHandler), ]) if __name__ == "__main__": application.listen(80) tornado.ioloop.IOLoop.instance().start()
2、模板引擎
Tornao中的模板语言和django中类似,模板引擎将模板文件载入内存,然后将数据嵌入其中,最终获取到一个完整的字符串,再将字符串返回给请求者。
Tornado 的模板支持“控制语句”和“表达语句”,控制语句是使用 {% 和 %} 包起来的 例如 {% if len(items) > 2 %}。表达语句是使用 {{ 和 }} 包起来的,例如 {{ items[0] }}。
控制语句和对应的 Python 语句的格式基本完全相同。我们支持 if、for、while 和 try,这些语句逻辑结束的位置需要用 {% end %} 做标记。还通过 extends 和 block 语句实现了模板继承。
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <h1>{{name}}</h1> <ul> {% for item in user_list %} <li>{{item}}</li> {% endfor %} </ul> </body> </html> index.html
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <form> <input type="text" /> <input type="text" /> <input type="submit" /> </form> </body> </html>
#!/usr/bin/env python # -*- coding:utf-8 -*- import tornado.ioloop import tornado.web class MainHandler(tornado.web.RequestHandler): def get(self): self.render('home/index.html') settings = { 'template_path': 'template', } application = tornado.web.Application([ (r"/index", MainHandler), ], **settings) if __name__ == "__main__": application.listen(80) tornado.ioloop.IOLoop.instance().start()
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<title>小男孩</title>
<link href="{{static_url("css/common.css")}}" rel="stylesheet" />
{% block CSS %}{% end %}
</head>
<body>
<div class="pg-header">
</div>
{% block RenderBody %}{% end %}
<script src="{{static_url("js/jquery-1.8.2.min.js")}}"></script>
{% block JavaScript %}{% end %}
</body>
</html>
layout.html
#!/usr/bin/env python # -*- coding:utf-8 -*- import tornado.ioloop import tornado.web class MainHandler(tornado.web.RequestHandler): def get(self): self.render('home/index.html') settings = { 'template_path': 'template', } application = tornado.web.Application([ (r"/index", MainHandler), ], **settings) if __name__ == "__main__": application.listen(80) tornado.ioloop.IOLoop.instance().start()
在模板中默认提供了一些函数、字段、类以供模板使用: escape: tornado.escape.xhtml_escape 的別名 xhtml_escape: tornado.escape.xhtml_escape 的別名 url_escape: tornado.escape.url_escape 的別名 json_encode: tornado.escape.json_encode 的別名 squeeze: tornado.escape.squeeze 的別名 linkify: tornado.escape.linkify 的別名 datetime: Python 的 datetime 模组 handler: 当前的 RequestHandler 对象 request: handler.request 的別名 current_user: handler.current_user 的別名 locale: handler.locale 的別名 _: handler.locale.translate 的別名 static_url: for handler.static_url 的別名 xsrf_form_html: handler.xsrf_form_html 的別名
https://github.com/tornadoweb/tornado/blob/master/tornado/template.py msgstr“”“一个将模板编译成Python代码的简单模板系统。 基本用法看起来像:: t = template.Template(“<html> {{myvalue}} </ html>”) print(t.generate(myvalue =“ XXX ”)) `Loader`是一个从根目录加载模板并缓存的类 编译模板:: loader = template.Loader(“/ home / btaylor”) print(loader.load(“test.html”)。generate(myvalue =“ XXX ”)) 我们将所有模板编译为原始Python。错误报告目前是...呃, 有趣。模板的语法:: ### base.html <HTML> <HEAD> <title> {%block title%}默认标题{%end%} </ title> </ HEAD> <BODY> <UL> {%学生在学生%} {%block student%} <li> {{escape(student.name)}} </ li> {% 结束 %} {% 结束 %} </ UL> </ BODY> </ HTML> ### bold.html {%extends“base.html”%} {%block title%}更大胆的标题{%end%} {%block student%} <li> <span style =“bold”> {{escape(student.name)}} </ span> </ li> {% 结束 %} 与大多数其他模板系统不同的是,我们不对其进行任何限制 你可以在你的语句中包含表达式。“if”和“for”块得到 完全转换成Python,所以你可以做复杂的表达式,如:: {如果学生的百分比(如果p.student和p.age> 23的话,则为p)%} <li> {{escape(student.name)}} </ li> {% 结束 %} 直接翻译到Python意味着您可以将函数应用于表达式 很容易,就像上面例子中的``escape()``函数一样。你可以通过 像任何其他变量一样运行到您的模板中 (在`.RequestHandler`中,覆盖`.RequestHandler.get_template_namespace`):: ### Python代码 def add(x,y): 返回x + y template.execute(添加=添加) ###模板 {{add(1,2)}} 我们提供函数`escape()<.xhtml_escape>`,`.url_escape()`, `.json_encode()`和`.squeeze()`默认为所有模板。 典型的应用程序不会创建`Template`或`Loader`实例 手,而是使用`〜.RequestHandler.render`和 `〜.RequestHandler.render_string`方法 `tornado.web.RequestHandler`,它自动加载模板 在``template_path```.Application`设置上。 以“_tt_”开头的变量名称由模板保留 系统,不应该被应用程序代码使用。 语法参考 ---------------- 模板表达式被双花括号包围:``{{...}}``。 内容可能是任何python表达式,这将被转义 到当前的autoescape设置并插入到输出中。其他 模板指令使用``%%}``。 要注释掉某个部分,以便将其从输出中省略,请将其包围 用`{#...#}``。 这些标签可能会被转义为“{{!”,``{%!``和``{#!`` 如果你需要在输出中包含一个文字``{{``,``{%``或``##````` ``{%apply * function *%} ... {%end%}`` 在``apply``之间的所有模板代码的输出中应用一个函数 和``end`` :: {%apply linkify%} {{name}}表示:{{message}} {%end%} 请注意,作为应用程序块的实现细节已经实现 作为嵌套函数,因此可能会与变量奇怪地交互 通过“{%set%}”设置,或使用“{%break%}”或“{%continue%}” 在循环内。 ``{%autoescape *函数*%}`` 设置当前文件的自动模式。这不会影响 其他文件,甚至是由“{%include%}”引用的文件。注意 自动转义也可以在`.Application`全局配置 或`Loader`。:: {%autoescape xhtml_escape%} {%autoescape无%} ``{%block * name *%} ... {%end%}`` 表示用于“{%extends%}”的已命名的可替换块。 父模板中的块将被内容替换 子模板中的同名块 <! - base.html - > <title> {%block title%}默认标题{%end%} </ title> <! - mypage.html - > {%extends“base.html”%} {%block title%}我的页面标题{%end%} ``{%comment ...%}`` 将从模板输出中删除的评论。注意 没有“{%end%}”标签; 评论来自单词``comment`` 到结尾的``````````标记。 `{%extends * filename *%}`` 从另一个模板继承。使用``extends``的模板应该是 包含一个或多个``block``标记来替换来自父项的内容 模板。子模板中的任何内容都不包含在“块”中 标签将被忽略。例如,请参阅“{%block%}”标签。 `{%for * var * in * expr *%} ... {%end%}`` 和python for``语句一样。``{%break%}``和 可以在循环内使用``%continue%}``。 ``{%from * x * import * y *%}`` 和python的``import``语句一样。 ``{%if * condition *%} ... {%elif * condition *%} ... {%else%} ... {%end%}` 条件语句 - 输出条件为的第一部分 真正。(“elif”和“else”部分是可选的) ``{%import * module *%}`` 和python的``import``语句一样。 ``{%include * filename *%}`` 包含另一个模板文件。包含的文件可以看到所有的本地 变量就好像它被直接复制到“include”的点一样 指令(“{%autoescape%}”指令是一个例外)。 或者,可以使用“{%module Template(filename,** kwargs)%}” 使用独立的名称空间包含另一个模板。 ``{%module * expr *%}`` 渲染一个`〜tornado.web.UIModule`。“UIModule”的输出是 没有逃脱:: {%module Template(“foo.html”,arg = 42)%} ``UIModules``是`tornado.web.RequestHandler`的一个特性 类(特别是它的“render”方法)并且不起作用 当模板系统在其他情况下自己使用时。 ``{%raw * expr *%}`` 输出给定表达式的结果而不自动转义。 ``{%set * x * = * y *%}`` 设置一个局部变量。 `%{%try%} ... {%%%} ... {%else%} ... {%finally%} ... {%end%}` 和python的``try``语句一样。 ``{while while * condition *%} ... {%end%}`` 和python的while语句一样。``{%break%}``和 可以在循环内使用``%continue%}``。 ``%{空白*模式*%}`` 为当前文件的其余部分设置空白模式 (或者直到下一个`{%whitespace%}`指令)。看到 `filter_whitespace`为可用的选项。新的龙卷风4.3。 “”” 从 __future__ 导入 absolute_import,division,print_function 导入日期时间 导入 linecache 导入 os.path 导入 posixpath 导入重新 导入线程 从龙卷风进口逃生 从 tornado.log 导入 app_log 从 tornado.util 导入 ObjectDict,exec_in,unicode_type,PY3 如果 PY3: 从 io 导入 StringIO 其他: 从 cStringIO 导入 StringIO _DEFAULT_AUTOESCAPE = “ xhtml_escape ” _UNSET = object() def filter_whitespace(mode,text): msgstr“” “根据”mode “在”text “中转换空格。” 可用的模式是: *``all``:返回所有未修改的空白。 *``single``:用一个空白符合连续的空格 性格,保留换行符。 *``oneline``:将所有运行的空白符合到一个空格中 字符,删除过程中的所有换行符。 .. versionadded :: 4.3 “”” 如果模式== '全部': 返回文本 elif mode == ' single ': text = re.sub(r “([ \ t ] +)” ,“ ”,text) text = re.sub(r “(\ s * \ n \ s *)”,“ \ n ”,text) 返回文本 elif模式== ' oneline ': return re.sub(r “(\ s +)”,“ ”,text) 其他: 引发 异常(“无效的空白模式%s ” %模式) 类 模板(对象): “”一个编译好的模板。 我们从给定的template_string编译成Python。你可以生成 使用generate()从变量中获取模板。 “”” #请注意构造函数的签名不是用提取的 #车博士因为_UNSET看起来像垃圾。改变时 #这个签名更新网站/ sphinx / template.rst也是。 def __init__(self,template_string,name = “ <string> ”,loader = None, compress_whitespace = _UNSET,autoescape = _UNSET, whitespace = None): “”“构建一个模板。 :arg str template_string:模板文件的内容。 :arg str name:从中加载模板的文件名 (用于错误消息)。 :arg tornado.template.BaseLoader loader:负责这个模板的`〜tornado.template.BaseLoader`, 用于解析``%include%}``和``{%extend%}`` 指令。 :arg bool compress_whitespace:自Tornado 4.3以来已弃用。 等同于“whitespace =”单个“”`如果为true和 如果为空,则全部为空格。 :arg str autoescape:模板中函数的名称 命名空间或“无”来默认禁用转义。 :arg str whitespace:一个字符串,指定对空白的处理; 看到`filter_whitespace`选项。 .. versionchanged :: 4.3 增加了“whitespace”参数; 不推荐使用``compress_whitespace``。 “”” self .name = escape.native_str(name) 如果 compress_whitespace 是 不是 _UNSET: #将不推荐使用的compress_whitespace(bool)转换为空格(str)。 如果空白是 不 无: 引发 异常(“不能设置空白和compress_whitespace ”) whitespace = “ single ” 如果 compress_whitespace else “ all ” 如果空白是 无: 如果 loader 和 loader.whitespace: whitespace = loader.whitespace 其他: #空格按文件名默认。 如果 name.endswith(“. html ”)或 name.endswith(“. js ”): whitespace = “单个” 其他: whitespace = “全部” #验证空白设置。 filter_whitespace(空格,' ') 如果 autoescape 是 不是 _UNSET: self .autoescape = autoescape elif loader: self .autoescape = loader.autoescape 其他: self .autoescape = _DEFAULT_AUTOESCAPE self .namespace = loader.namespace if loader else {} reader = _TemplateReader(name,escape.native_str(template_string), 空格) self .file = _File(self,_parse(reader,self)) 自 .CODE = 自 ._generate_python(装载机) self .loader = loader 尝试: #在python2.5下,这里使用的假文件名必须匹配 #下面__name__中使用的模块名称。 #在dont_inherit标志可防止template.py未来进口 #被应用到生成的代码。 self .compiled = compile( escape.to_unicode(self .code ), “ %S .generated.py ” % 自 .name.replace( ' ', ' _ '), “ exec ”, dont_inherit = True) 除 例外情况: formatted_code = _format_code(self .code).rstrip() app_log.error(“ %s code:\ n %s ”,self .name,formatted_code) 提高 def 生成(self,** kwargs): msgstr“”“用给定的参数生成这个模板。”“” namespace = { “逃生”:escape.xhtml_escape, “ xhtml_escape ”:escape.xhtml_escape, “ url_escape ”:escape.url_escape, “ json_encode ”:escape.json_encode, “挤”:逃避挤压, “ linkify ”:escape.linkify, “ datetime ”:datetime, “ _tt_utf8 ”:escape.utf8, #供内部使用 “ _tt_string_types ”:(unicode_type, bytes), # __name__和__loader__允许追溯机制,以找到 #生成的源代码。 “ __name__ ”: self .name.replace( '。', ' _ '), “ __loader__ ”:ObjectDict( get_source = lambda 名称: self .code), } namespace.update(self .namespace) namespace.update(kwargs) exec_in(self .compiled,namespace) execute = namespace [ “ _tt_execute ” ] #现在清除回溯模块的源数据缓存 #我们已经生成了一个新的模板(主要是为了这个模块的 #单元测试,其中不同的测试重用相同的名称)。 linecache.clearcache() 返回 execute() def _generate_python(self,loader): buffer = StringIO() 尝试: # named_blocks从名字到_NamedBlock对象映射 named_blocks = {} 祖先= 自我 ._get_ancestors(加载器) ancestors.reverse() 为祖先在祖先: ancestor.find_named_blocks(loader,named_blocks) writer = _CodeWriter(buffer,named_blocks,loader, 祖先[ 0 ] .template) 祖先[ 0 ]。生成(作家) return buffer.getvalue() 最后: buffer.close() def _get_ancestors(self,loader): ancestors = [ self .file] 对于大块的 自我 .file.body.chunks: 如果 isinstance(chunk,_ExtendsBlock): 如果 不是装载机: 引发 ParseError(“ {%extends%}”块发现,但没有“ “模板加载器”) template = loader.load(chunk.name,self .name) ancestors.extend(template._get_ancestors(装载机)) 归还祖先 class BaseLoader(object): msgstr“”“模板加载器的基类。” 您必须使用模板加载器来使用模板结构 “{%extends%}”和“{%include%}”。加载器缓存全部 第一次加载后的模板。 “”” def __init__(self,autoescape = _DEFAULT_AUTOESCAPE,namespace = None, whitespace = None): “”“构建一个模板加载器。 :arg str autoescape:模板中函数的名称 命名空间,如“xhtml_escape”或“None”禁用 自动转义默认情况下。 :arg dict namespace:要添加到默认模板的字典 名称空间或“无”。 :arg str whitespace:指定默认行为的字符串 模板中的空白 看到`filter_whitespace`选项。 对于以“.html”和“.js”结尾的文件,默认为“single” 其他文件的“全部”。 .. versionchanged :: 4.3 增加了“空白”参数。 “”” self .autoescape = autoescape self .namespace = namespace 或 {} 自我 .whitespace =空白 self .templates = {} # self.lock保护self.templates。这是一个重入锁 #因为模板可能会通过include或者其他模板加载 # `扩展`。请注意,由于GIL这个代码将是安全的 #即使没有锁,但可能会导致浪费工作多倍 #线程试图同时编译相同的模板。 self .lock = threading.RLock() def reset(self): msgstr“”“重置已编译模板的缓存。”“” 与 自我 .lock: self .templates = {} def resolve_path(self,name,parent_path = None): “”“将可能相对路径转换为绝对路径(内部使用)。”“” 引发 NotImplementedError() def load(self,name,parent_path = None): “”“加载模板”“” name = self .resolve_path(name,parent_path = parent_path) 与 自我 .lock: 如果名称不 以 自我 .templates: self .templates [name] = self ._create_template(name) 返回 self .templates [name] def _create_template(self,name): 引发 NotImplementedError() class Loader(BaseLoader): msgstr“”“从单个根目录加载的模板加载器。 “”” def __init__(self,root_directory,** kwargs): 超级(Loader,self)。__init__(** kwargs) self .root = os.path.abspath(root_directory) def resolve_path(self,name,parent_path = None): 如果 PARENT_PATH 和 不 parent_path.startswith( “ < ”)和 \ 不是 parent_path.startswith(“ / ”)和 \ 不是 name.startswith(“ / ”): current_path = os.path.join(self .root,parent_path) file_dir = os.path.dirname(os.path.abspath(current_path)) relative_path = os.path.abspath(os.path.join(file_dir,name)) 如果 relative_path.startswith(self .root): name = relative_path [ len(self .root)+ 1:] 返回名称 def _create_template(self,name): path = os.path.join(self .root,name) 与 开放(路径,“ RB ”)作为 F: template = Template(f.read(),name = name,loader = self) 返回模板 类 DictLoader(BaseLoader): msgstr“”“从字典中加载的模板加载器。”“” def __init__(self,dict,** kwargs): 超级(DictLoader,self)。__init__(** kwargs) 自我 .dict = dict def resolve_path(self,name,parent_path = None): 如果 PARENT_PATH 和 不 parent_path.startswith( “ < ”)和 \ 不是 parent_path.startswith(“ / ”)和 \ 不是 name.startswith(“ / ”): file_dir = posixpath.dirname(parent_path) name = posixpath.normpath(posixpath.join(file_dir,name)) 返回名称 def _create_template(self,name): 返回模板(self .dict [name],name = name,loader = self) 类 _Node(object): def each_child(self): return() def 生成(自我,作家): 引发 NotImplementedError() def find_named_blocks(self,loader,named_blocks): 对于孩子的 自我 .each_child(): child.find_named_blocks(loader,named_blocks) 类 _File(_Node): def __init__(self,template,body): 自 .template =模板 self .body = body self .line = 0 def 生成(自我,作家): writer.write_line(“ def _tt_execute():”,self .line) 用 writer.indent(): writer.write_line(“ _tt_buffer = [] ”,self .line) writer.write_line(“ _tt_append = _tt_buffer.append ”,self .line) self .body.generate(作家) write.write_line(“ return _tt_utf8('')。join(_tt_buffer)”,self .line) def each_child(self): 返回(self .body,) 类 _ChunkList(_Node): def __init__(self,chunk): 自我。Chunks =大块 def 生成(自我,作家): 对于大块的 自我 .chunks: chunk.generate(作家) def each_child(self): 回归 自我 .chunks 类 _NamedBlock(_Node): def __init__(self,name,body,template,line): self .name = name self .body = body 自 .template =模板 自 .line区段=线 def each_child(self): 返回(self .body,) def 生成(自我,作家): block = writer.named_blocks [ self .name] 用 writer.include(block.template,self .line): block.body.generate(作家) def find_named_blocks(self,loader,named_blocks): named_blocks [ self .name] = self _Node.find_named_blocks(self,loader,named_blocks) 类 _ExtendsBlock(_Node): def __init__(self,name): self .name = name 类 _IncludeBlock(_Node): def __init__(self,name,reader,line): self .name = name self .template_name = reader.name 自 .line区段=线 def find_named_blocks(self,loader,named_blocks): included = loader.load(self .name,self .template_name) included.file.find_named_blocks(loader,named_blocks) def 生成(自我,作家): included = writer.loader.load(self .name,self .template_name) 与 writer.include(包括,自我 .line): included.file.body.generate(作家) 类 _ApplyBlock(_Node): def __init__(self,method,line,body = None): self .method =方法 自 .line区段=线 self .body = body def each_child(self): 返回(self .body,) def 生成(自我,作家): method_name = “ _tt_apply %d ” % writer.apply_counter writer.apply_counter + = 1 writer.write_line(“ def %s():” % method_name,self .line) 用 writer.indent(): writer.write_line(“ _tt_buffer = [] ”,self .line) writer.write_line(“ _tt_append = _tt_buffer.append ”,self .line) self .body.generate(作家) write.write_line(“ return _tt_utf8('')。join(_tt_buffer)”,self .line) writer.write_line(“ _tt_append(_tt_utf8(%s(%s())))” %( 自我。方法,METHOD_NAME),自 .line区段) 类 _ControlBlock(_Node): def __init__(self,statement,line,body = None): self .statement =语句 自 .line区段=线 self .body = body def each_child(self): 返回(self .body,) def 生成(自我,作家): writer.write_line( “ %S:” % 自 .statement,自 .line区段) 用 writer.indent(): self .body.generate(作家) #以防万一身体空了 write.write_line(“ pass ”,self .line) 类 _IntermediateControlBlock(_Node): def __init__(self,statement,line): self .statement =语句 自 .line区段=线 def 生成(自我,作家): #以前的块是空的 write.write_line(“ pass ”,self .line) writer.write_line( “ %S:” % 自 .statement,自 .line区段,writer.indent_size()- 1) 类 _Statement(_Node): def __init__(self,statement,line): self .statement =语句 自 .line区段=线 def 生成(自我,作家): writer.write_line(自 .statement,自 .line区段) 类 _Expression(_Node): def __init__(self,expression,line,raw = False): 自 .expression =表达 自 .line区段=线 自我 .raw =原始 def 生成(自我,作家): writer.write_line( “ _tt_tmp = %S ” % 自 .expression,自 .line区段) writer.write_line(“ if isinstance(_tt_tmp,_tt_string_types):” “ _tt_tmp = _tt_utf8(_tt_tmp)”, self .line) writer.write_line(“ else:_tt_tmp = _tt_utf8(str(_tt_tmp))”,self .line) 如果 没有 自我。RAW 和 writer.current_template.autoescape 是 不 无: #在python3函数中像xhtml_escape返回unicode, #所以我们必须再次转换为utf8。 writer.write_line(“ _tt_tmp = _tt_utf8(%s(_tt_tmp))” % writer.current_template.autoescape,self .line) writer.write_line(“ _tt_append(_tt_tmp)”,self .line) 类 _Module(_Expression): def __init__(self,expression,line): 超级(_Module,self)。__init__(“ _tt_modules。” +表达式,行, raw = True) 类 _Text(_Node): def __init__(self,value,line,whitespace): 自我。价值=值 自 .line区段=线 自我 .whitespace =空白 def 生成(自我,作家): value = self .value #如果需要的话,压缩空格,以避免粗糙的启发式 #改变预先格式化的空白。 如果 “ <PRE> ” 未 在值: value = filter_whitespace(self .whitespace,value) 如果价值: writer.write_line(' _tt_append(%r)' % escape.utf8(value),self .line) class ParseError(Exception): “”“引发模板语法错误。 ``ParseError``实例具有``filename``和``lineno``属性 指出错误的位置。 .. versionchanged :: 4.3 增加了``filename``和``lineno``属性。 “”” def __init__(self,message,filename = None,lineno = 0): 自我 .message =消息 #名称“文件名”和“行号”是一致的选择 #与python SyntaxError。 self .filename =文件名 self .lineno = lineno def __str__(self): 返回 ' %s在%s:%d ' %(self .message,self .filename,self .lineno) 类 _CodeWriter(object): def __init__(self,file,named_blocks,loader,current_template): self .file = 文件 self .named_blocks = named_blocks self .loader = loader self .current_template = current_template self .apply_counter = 0 self .include_stack = [] self ._indent = 0 def indent_size(self): 返回 自我 ._indent def indent(self): 类 压头(物体): def __enter__(_): self ._indent + = 1 回报 自我 def __exit__(_,* args): assert self ._indent > 0 self ._indent - = 1 返回压头() def include(self,template,line): self .include_stack.append((self .current_template,line)) self .current_template = template 类 IncludeTemplate(object): def __enter__(_): 回报 自我 def __exit__(_,* args): self .current_template = self .include_stack.pop()[ 0 ] 返回 IncludeTemplate() def write_line(self,line,line_number,indent = None): 如果缩进是 None: indent = self ._indent line_comment = ' #%s:%d ' %(self .current_template.name,line_number) 如果 自我 .include_stack: ancestors = [ “ %s:%d ” %(tmpl.name,lineno) for(tmpl,lineno)in self .include_stack] line_comment + = '(via %s)' % ','. join(reversed(ancestors)) print(“ ” * indent + line + line_comment,file = self .file) class _TemplateReader(object): def __init__(self,name,text,whitespace): self .name = name self .text = text 自我 .whitespace =空白 self .line = 1 自我 .pos = 0 def find(self,needle,start = 0,end = None): 断言 start > = 0,开始 pos = self .pos 开始+ =正面 如果结束是 无: index = self .text.find(needle,start) 其他: 结束+ = pos 断言结束> =开始 index = self .text.find(needle,start,end) 如果 index != - 1: index - = pos 回报指数 def consume(self,count = None): 如果 count 是 None: count = len(self .text)- self .pos newpos = self .pos + count 自 .line区段+ = 自 .text.count( “ \ n ”,自 .POS,newpos) s = self .text [ self .pos:newpos] 自我 .pos = newpos 返回 s def remaining(self): return len(self .text)- self .pos def __len__(self): 返回 自我 .remaining() def __getitem__(self,key): 如果 类型(键)是 切片: size = len(self) 开始,停止,步骤= key.indices(大小) 如果启动是 None: start = self .pos 其他: 开始+ = 自我 .pos 如果停止是 不是 无: 停止+ = 自我 .pos return self .text [ slice(start,stop,step)] elif key < 0: 返回 自我 .text [key] 其他: 返回 self .text [ self .pos + key] def __str__(self): 返回 self .text [ self .pos:] def raise_parse_error(self,msg): 引发 ParseError(味精,自我。名称,自我。线) def _format_code(code): lines = code.splitlines() format = “ %%% d d %% s \ n ” % len(repr(len(lines)+ 1)) 返回 “ ” .join([ 格式 %(i + 1,行)为(i,行)在 枚举(行)]) def _parse(reader,template,in_block = None,in_loop = None): body = _ChunkList([]) 而 真: #找到下一个模板指令 卷曲= 0 而 真: curly = reader.find(“ { ”,curly) if curly == - 1 or curly + 1 == reader.remaining(): # EOF 如果 in_block: reader.raise_parse_error( “缺少%s的%%end%%block ” % in_block) body.chunks.append(_Text(reader.consume(),reader.line, reader.whitespace)) 返回机构 #如果第一个大括号不是特殊标记的开始, #开始从字符开始搜索 如果读取器[卷曲+ 1 ] 未 在(“ { ”,“%”,“#”): 卷曲+ = 1 继续 #当连续超过2个卷曲时,使用 #最内层的。这在生成语言时很有用 #像乳胶哪里花括号也是有意义 如果(卷曲+ 2 < reader.remaining()和 阅读器[curly + 1 ] == ' { ' 和 reader [curly + 2 ] == ' { '): 卷曲+ = 1 继续 打破 #在特殊标记之前附加任何文本 如果卷曲> 0: cons = reader.consume(卷曲) body.chunks.append(_Text(cons,reader.line, reader.whitespace)) start_brace = reader.consume(2) line = reader.line #模板指令可能被转义为“{{!” 要么 ”{%!”。 #在这种情况下输出大括号并使用“!”。 #这是特别有用的与jQuery模板, #也使用双括号。 如果 reader.remaining()和 reader [ 0 ] == “!”: reader.consume(1) body.chunks.append(_Text(start_brace,line, reader.whitespace)) 继续 #评论 如果 start_brace == “ {#”: end = reader.find(“#} ”) 如果结束== - 1: reader.raise_parse_error(“ Missing end comment#} ”) contents = reader.consume(end).strip() reader.consume(2) 继续 #表达 如果 start_brace == “ {{ ”: end = reader.find(“ }} ”) 如果结束== - 1: reader.raise_parse_error(“ Missing end expression }} ”) contents = reader.consume(end).strip() reader.consume(2) 如果 不是内容: reader.raise_parse_error(“空表达式”) body.chunks.append(_Expression(contents,line)) 继续 #座 assert start_brace == “ {%”,start_brace end = reader.find(“%} ”) 如果结束== - 1: reader.raise_parse_error(“ Missing end block%} ”) contents = reader.consume(end).strip() reader.consume(2) 如果 不是内容: reader.raise_parse_error(“空块标记({%%})”)) 运算符,空格,后缀= contents.partition(“ ”) suffix = suffix.strip() #中级(“其他”,“elif”等)块 intermediate_blocks = { “ else ”: set([ “ if ”, “ for ”, “ while ”, “ try ” ]), “ elif ”: set([ “ if ” ]), “ except ”: set([ “ try ” ]), “ finally ”: set([ “ try ” ]), } allowed_parents = intermediate_blocks.get(运算符) 如果 allowed_parents 是 不 无: 如果 不是 in_block: reader.raise_parse_error( “ %S外%s的块” % (operator,allowed_parents)) 如果 in_block 没有 在 allowed_parents: reader.raise_parse_error( “ %s块不能附加到%s块” % (operator,in_block)) body.chunks.append(_IntermediateControlBlock(contents,line)) 继续 #结束标记 elif运算符== “结束”: 如果 不是 in_block: reader.raise_parse_error(“ Extra {%end%} block ”) 返回机构 elif的操作者在(“延伸”,“包括”,“组”,“导入”,“从”, “评论”, “ autoescape ”, “空白”, “生”, “模块”): 如果 operator == “ comment ”: 继续 如果 operator == “ extends ”: suffix = suffix.strip(' “ ').strip(” ' “) 如果 不是后缀: reader.raise_parse_error(“扩展缺少的文件路径”) 块= _ExtendsBlock(后缀) ELIF运营商在(“进口”,“从”): 如果 不是后缀: reader.raise_parse_error(“导入缺少语句”) block = _Statement(contents,line) elif运算符== “包含”: suffix = suffix.strip(' “ ').strip(” ' “) 如果 不是后缀: reader.raise_parse_error(“包含缺少的文件路径”) block = _IncludeBlock(后缀,阅读器,行) elif运算符== “ set ”: 如果 不是后缀: reader.raise_parse_error(“设置缺失语句”) block = _Statement(后缀,行) elif运算符== “ autoescape ”: fn = suffix.strip() 如果 fn == “无”: fn = 无 template.autoescape = fn 继续 elif运算符== “空白”: mode = suffix.strip() #验证选定的模式 filter_whitespace(mode,' ') reader.whitespace = mode 继续 elif operator == “ raw ”: block = _Expression(后缀,行,raw = True) elif运算符== “模块”: block = _Module(后缀,行) body.chunks.append(块) 继续 ELIF操作中(“申请”,“块”,“尝试”,“如果”,“对”,“同时”): #递归地解析内部体 如果操作符在(“ for ”,“ while ”)中: block_body = _parse(reader,template,operator,operator) elif运算符== “ apply ”: #应用创建一个嵌套函数语法所以它不是 #在循环中。 block_body = _parse(reader,template,operator,None) 其他: block_body = _parse(reader,template,operator,in_loop) 如果 operator == “ apply ”: 如果 不是后缀: reader.raise_parse_error(“应用缺少的方法名称”) block = _ApplyBlock(后缀,行,block_body) elif运算符== “ block ”: 如果 不是后缀: reader.raise_parse_error(“ block missing name ”) block = _NamedBlock(后缀,block_body,模板,行) 其他: block = _ControlBlock(contents,line,block_body) body.chunks.append(块) 继续 ELIF运营商在(“破发”,“继续”): 如果 不是 in_loop: reader.raise_parse_error( “ %S外%s的块” % (operator,set([ “ for ”,“ while ” ]))) body.chunks.append(_Statement(contents,line)) 继续 其他: reader.raise_parse_error(“未知的操作符:%r ” %操作符)
tornado介绍
https://github.com/tornadoweb/tornado
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = "Flying" #tornado栗子 from tornado import web,ioloop,httpserver #逻辑模块 class MainPageHandler(web.RequestHandler): def get(self,*args,**kwargs): #self.write('welcome to python') self.render('index.html') class CreateHandler(web.RequestHandler): def get(self, *args, **kwargs): self.render('create.html') def post(self, *args, **kwargs): web=self.get_argument('web') web_tornado=self.get_argument('web_tornado') content=self.get_argument('content') print web,web_tornado,content #路由 application = web.Application([ (r"/index",MainPageHandler), (r"/",MainPageHandler), (r"/create",CreateHandler), ]) #socket 服务 if __name__ == '__main__': http_server = httpserver.HTTPServer(application) http_server.listen(9999) ioloop.IOLoop.current().start()
运行该脚本,依次执行: 创建一个Application对象,并把一个正则表达式'/'和类名MainHandler传入构造函数:tornado.web.Application(...) 执行Application对象的listen(...)方法,即:application.listen(9999) 执行IOLoop类的类的 start() 方法,即:tornado.ioloop.IOLoop.instance().start() 整个过程其实就是在创建一个socket服务端并监听9999端口,当请求到来时,根据请求中的url和请求方式(post、get或put等)来指定相应的类中的方法来处理本次请求,在上述demo中只为url为http://127.0.0.1:9999/index的请求指定了处理类MainHandler。所以,在浏览器上访问:http://127.0.0.1:9999/index,则服务器给浏览器就会返回 Hello,world ,否则返回 404: Not Found(tornado内部定义的值), 即完成一次http请求和响应。 由上述分析,我们将整个Web框架分为两大部分: 待请求阶段,即:创建服务端socket并监听端口 处理请求阶段,即:当有客户端连接时,接受请求,并根据请求的不同做出相应的相应
tornado请求阶段
tornado程序的源码分析


 浙公网安备 33010602011771号
浙公网安备 33010602011771号