
Stable Diffusion WebUI详细使用指南
Stable Diffusion WebUI(AUTOMATIC1111,简称A1111)是一个为高级用户设计的图形用户界面(GUI),它提供了丰富的功能和灵活性,以满足复杂和高级的图像生成需求。由于其强大的功能和社区的活跃参与,A1111成为了Stable Diffusion模型事实上的标准GUI,并且是新功能和实验性工具的首选发布平台。
- 本指南可以作为一步步跟随的教程,帮助你从基础开始学习如何使用A1111。通过实际操作的例子,你可以逐步了解每个功能的作用和配置方法。
- 当你已经熟悉了基本操作后,你可以将这个指南作为快速参考手册。在需要使用特定功能或解决特定问题时,可以快速查阅相关内容。
- 在学习过程中,示例是非常重要的。通过观察和实践示例,你可以更清晰地理解每个设置的效果和用途。
下载并安装Stable Diffusion WebUI
这个就不多讲了,大家登上github,拷贝下来直接启动就行了。但是确保你有大于8G的显存,否则在使用中会非常慢,并且可能会出现某些功能无法使用的问题。
txt2img
当您首次启动GUI时,您会看到txt2img标签。这个标签执行了Stable Diffusion的最基本功能:将文本提示转换成图像。
基本用法
如果你是第一次使用webUI,那么下面这几个参数是你一定需要注意的:
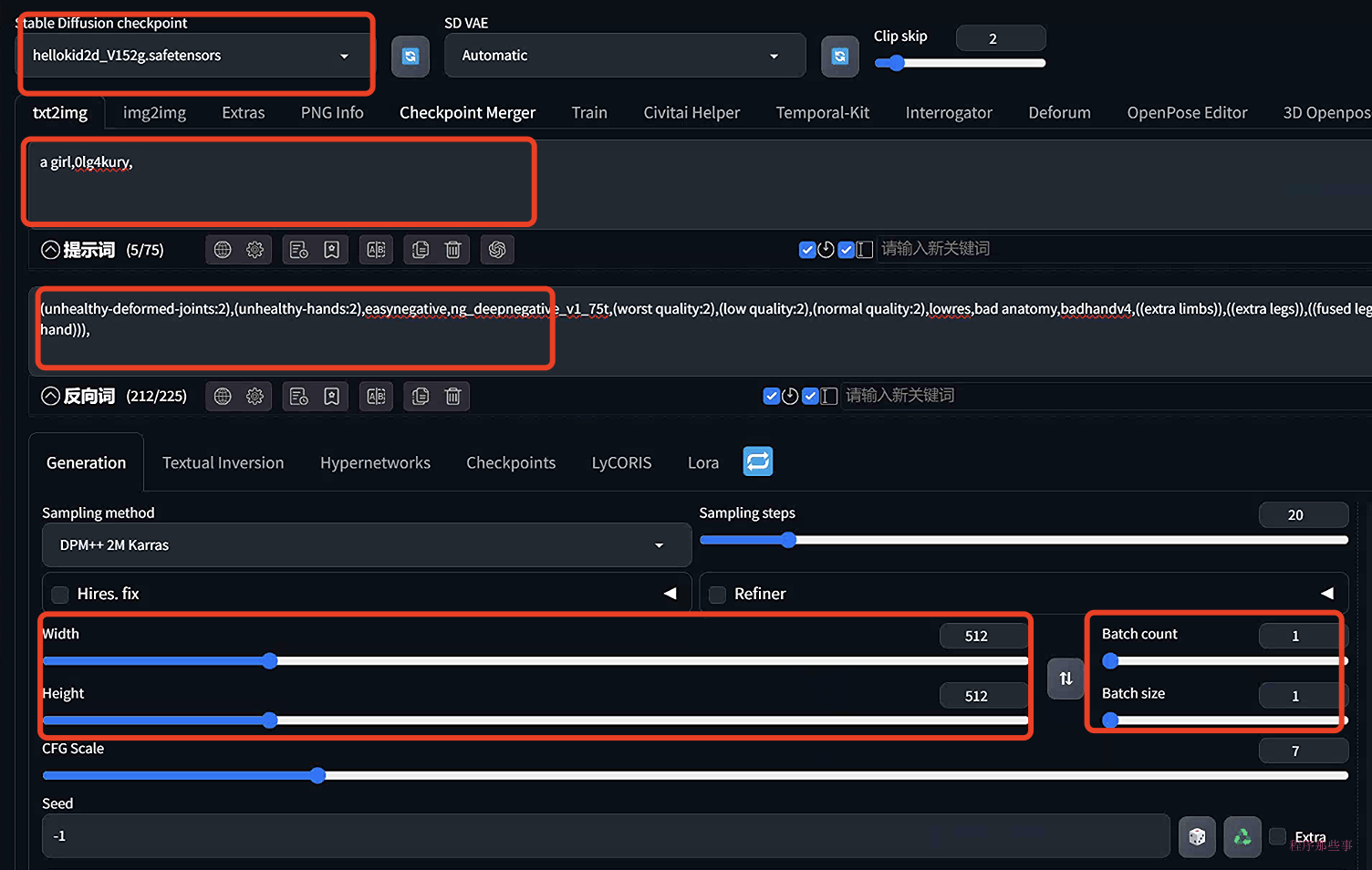
首先是checkpoint,这个模型决定了你图片的基础风格。
你可以在提示词部分,输入你希望生成的图片描述。在反向提示词部分,可以输入你不想在图片上看到的内容。
宽度和高度:输出图像的尺寸。当使用v1模型时,您应该将至少一边设置为512像素。例如,将宽度设置为512,高度设置为768,以获得一个2:3的纵向图像。
批处理大小:每次生成的图像数量。在测试提示时,您至少想生成几个图像,因为每个图像都会有所不同。最后,点击生成按钮。稍等片刻,您就会得到您的图像!

图像生成参数
在上面生成图像的底部,我们可以看到一些关于图片生成的具体信息,具体到上面的例子,我们得到了下面的图片生成参数:
Prompt: a girl,0lg4kury,
Negative prompt: (unhealthy-deformed-joints:2),(unhealthy-hands:2),easynegative,ng_deepnegative_v1_75t,(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,badhandv4,((extra limbs)),((extra legs)),((fused legs)),((extra arms)),((fused arms)),normal quality,((monochrome)),((grayscale)),((watermark)),uneven eyes,lazy eye,bad-hands-5,(((mutated hand))),
Steps: 20,Sampler: DPM++ 2M Karras,
CFG scale: 7,
Seed: 1650696303,
Size: 512x512,
Clip skip: 2
采样步骤:去噪过程的采样步骤数。步数越多越好,但也需要更长时间。25步适用于大多数情况。
宽度和高度:输出图像的尺寸。对于v1模型,您应该至少将一侧设置为512像素。例如,将宽度设置为512,高度设置为768,以获得一个2:3的竖向图像。使用v2-768px模型时,应至少将一侧设置为768。
批次计数:运行图像生成管道的次数。
批次大小:每次运行管道生成的图像数量。生成的图像总数等于批次计数乘以批次大小。通常您会更改批次大小,因为这样更快。只有在遇到内存问题时才会更改批次计数。
CFG scale:分类器无指导比例**是一个参数,用于控制模型应该多大程度上遵循您的提示。
1 - 大部分忽略您的提示。
3 - 更具创造性。
7 - 在遵循提示和自由之间取得良好的平衡。
15 - 更加遵循提示。
30 - 严格遵循提示。
seed
seed:是在潜在空间中用于生成初始随机张量的种子值。从实际情况来看,它可以控制图像的内容。
每个生成的图像都有自己的种子值。如果在webUI中把seed设置为-1,它将使用一个随机的种子值。固定种子的一个常见原因是为了固定图像的内容并调整提示。比如说,我使用以下提示生成了一张图像。
a girl in the photo,0lg4kury,dresses,in the city,

我觉得这张照片不错,但是我还想给她添加点东西,比如手镯。那么我们要做的就是在图片下面找到它的seed,然后规定这个值,再在prompt中添加bracelet:

可以看到它的seed值是1721867153, 我们把这个值复制到种子值输入框中。或者使用回收按钮来复制种子值。

现在在提示中添加术语“手镯”
a girl in the photo,0lg4kury,dresses,in the city,bracelet
我们会得到下面的图片:

人物和场景大体上是没有变化的,只不过这次给人物多加了一个手镯。
extra seed
勾选 extra 选项将显示额外种子菜单。
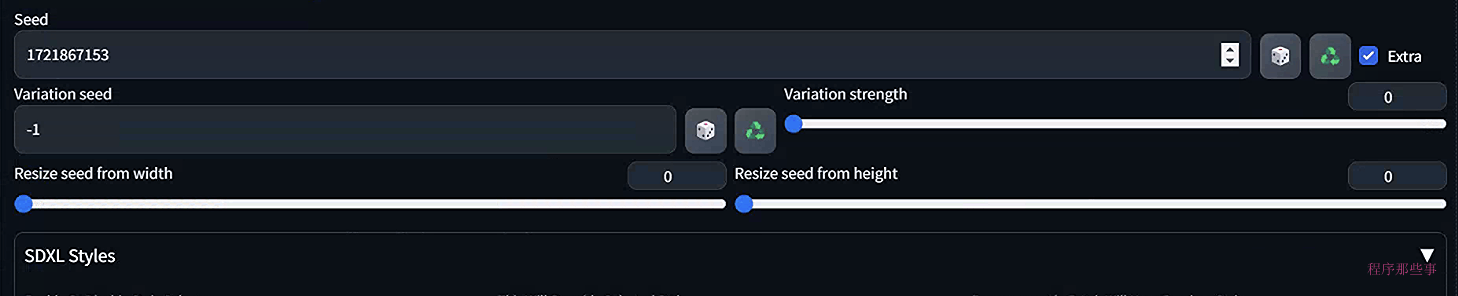
这个extra seed是做什么用的呢?
在上面界面上,你可以看到有两个非常重要的变量,分别是Variation seed和Varation strength。
Variation seed: 你想要使用的额外种子数值。
Varation strength: 表示的是在 种子 和 变化种子 之间的插值程度。将其设置为0表示使用 种子 的数值。将其设置为1使用 变化种子 数值。
可能朋友们还是不明白这个参数到底是做什么,那么我们来举个例子。
上面我们已经生成了一张图片了,他的seed是1721867153,那么我们修改这个seed,改成1721867155,再生成一张图片:

因为seed改变了,所以这两幅图片的差距有点大了。
extra seed的作用就是可以给我们一个合并这两个图的方法。
你想要生成这两张图片的混合图像。你将种子设为1721867153,变化种子设为1721867155,并调整变化强度在0和1之间。在下面的实验中,变化强度允许你在两个种子之间产生图像内容的过渡。当变化强度从0增加到1时,女孩的姿势和背景逐渐改变。

即使使用相同的种子,如果更改图像大小,图像也会发生显著变化。
还是这个seed:1721867153。 如果我现在把长宽变成:512x768,看看生成的图片:

人脸修复
SD webUI提供了一个人脸修复的选项,可以专门用于修复人脸上的缺陷。以下是一些示例,展示了修复前后的效果。
修复前:

修复后:

对比看看,效果还是很明显的。
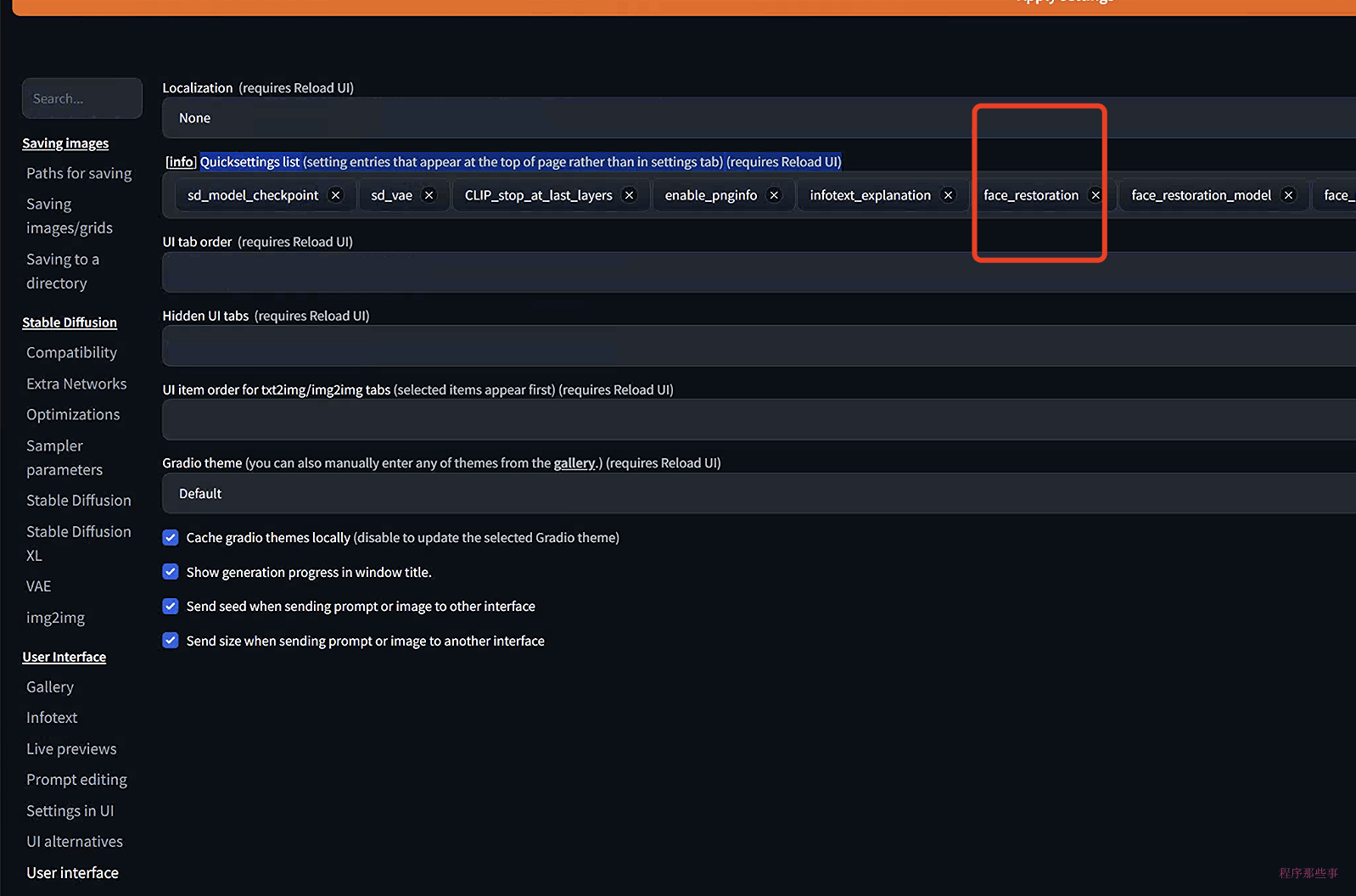
等等,有同学会问了,restore face? 有这个选项吗? 我怎么没看到?
别急,在使用之前你需要到settings--> user interface ->Quicksettings list 中把face_restoration加上去:
加完之后,重启UI,回到txt2img选项卡。勾选Restore Faces。人脸修复模型将应用于您生成的每张图片。
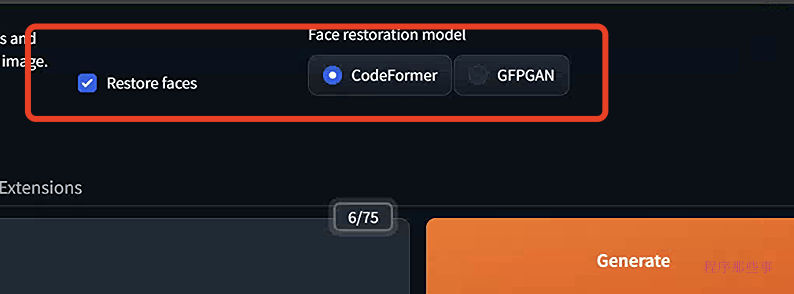
如果发现应用影响了人脸上的风格,您可以选择关闭人脸修复。
Tiling
您可以使用Stable Diffusion WebUI创建类似壁纸的重复图案。
要启用tiling,我们还是在settings--> user interface ->Quicksettings list 中把tiling加上去:
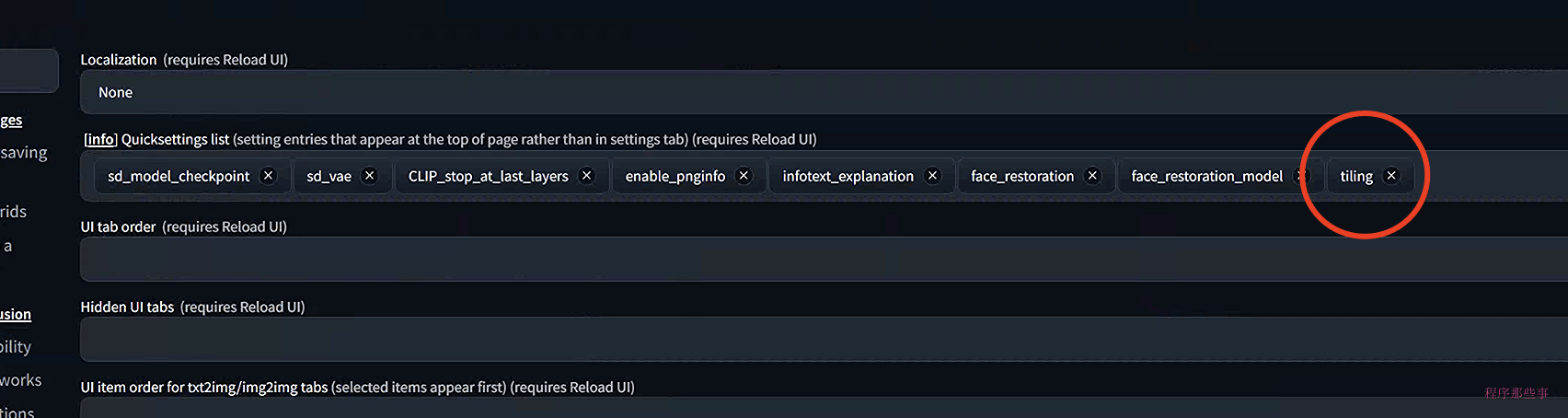
现在我们在text2img选项中就可以看到tiling这个选项了,勾选上它,然后画一下花,看看什么效果:

可以看到这幅画是一个完美的平铺图片,你可以从上下左右任何方向拼接这个图片,都可以得到完美的图像。
当然,生成的图片可以是任何东西,比如无尽的阶梯:

快来发挥你的创意吧,创造你想要的图片吧。
高清修复Hires.fix.
高分辨率修复(High-Resolution Upscaling)是一个在图像生成领域常见的概念,特别是在使用稳定扩散模型时。这个选项的目的是为了克服模型原生输出分辨率的限制,从而生成更大尺寸、更高质量的图像。
稳定扩散模型默认的输出分辨率通常是512像素(对于某些v2型号是768像素)。这个限制是由模型的设计和训练数据集决定的。对于一些应用场景,如打印、大尺寸展示或者高清屏幕显示,这样的分辨率可能不够用。
为什么不直接设置更高的原生分辨率?直接提高模型的原生输出分辨率(例如,将宽度和高度设置为1024像素)可能会导致一些问题,比如构图失真或者生成异常图像(例如,图像中出现多余的头或其他元素)。这是因为模型在训练过程中学习到了特定的输出尺寸,直接改变这个尺寸可能会导致模型无法正确地映射图像特征到新的分辨率上。
我们先看下hires.fix的一些参数设置:

upscaler上采样器:上采样器是图像处理中用于放大图像的工具。有很多采样器可以选择。
其中latent是一种比较特殊的采样器,它在所谓的“潜在空间”中工作。潜在空间是一个数学概念,用于表示图像生成模型在生成图像之前所处的中间状态。这类上采样器在图像生成的采样步骤之后应用,即在模型已经根据文本提示生成了一个初步的图像表示后,再对其进行放大处理。潜在上采样器的选项通常包括各种基于数学和机器学习原理的方法,它们可以在不改变图像构图的情况下增加图像的尺寸。
高清步骤:仅适用于latent采样器。它指的是在放大潜在图像后进行的额外采样步骤的数量。更多的高清步骤意味着模型将有更多的机会细化图像的细节,可能产生更清晰、更高质量的图像。
去噪强度:仅适用于latent采样器。它控制了在执行高清采样步骤之前添加到潜在图像的噪声。添加一定量的噪声可以帮助模型更好地学习和恢复图像的细节。太低可能无法有效恢复细节,太高则可能导致图像中出现不必要的伪影或失真。
与传统的上采样器(如ESRGAN)相比,潜在上采样器不容易产生上采样伪影。这些伪影可能包括锐化过度、边缘不自然等现象,它们会影响图像的视觉质量。由于潜在上采样器是在图像生成的后期阶段工作,它能够保持与原始稳定扩散模型生成的图像的风格一致性。这意味着放大后的图像将更忠实于原始艺术风格和视觉特征。潜在上采样器在潜在空间中进行操作,这是一个中间表示,允许在不直接修改像素值的情况下对图像进行调整。这种方法可以更自然地处理图像的细节和结构。
但是潜在上采样器可能会在一定程度上改变原始图像。这种变化的程度取决于去噪强度的设置。较高的去噪强度可能会导致图像细节的丢失或模糊,而较低的去噪强度可能无法充分恢复图像的清晰度。
放大因子控制图像将放大多少倍。例如,将其设置为2会将一个512x768像素的图像放大为1024x1536像素。
图像操作按钮
在生成图像之后,你会发现一排按钮,用于对生成的图像执行各种功能。
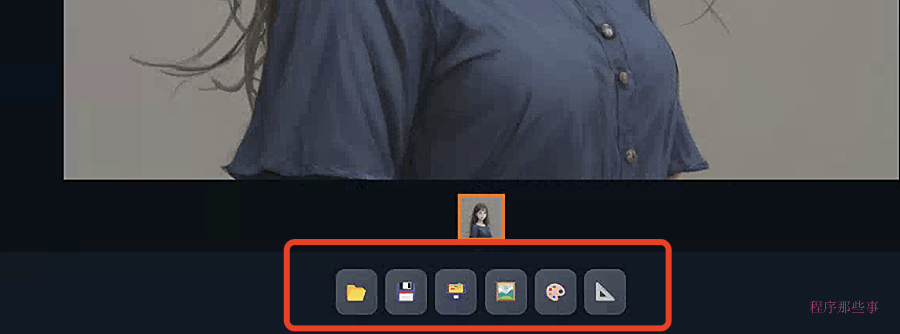
打开文件夹: 打开图像输出文件夹。可能并非适用于所有系统。
保存: 保存一张图像。点击后,按钮下方将显示下载链接。如果选择图像网格,将保存所有图像。
压缩: 压缩图像以便下载。
发送到img2img: 将选定的图像发送到img2img选项卡。
发送到修复: 将选定的图像发送到img2img选项卡中的修复选项。
发送到额外功能: 将选定的图像发送到额外功能选项卡。
Img2img
img2img的作用就是从一张图片来创建另外一张图片。
下面是基本的使用步骤:
步骤1:将基本图像拖放到img2img页面上的img2img标签中。
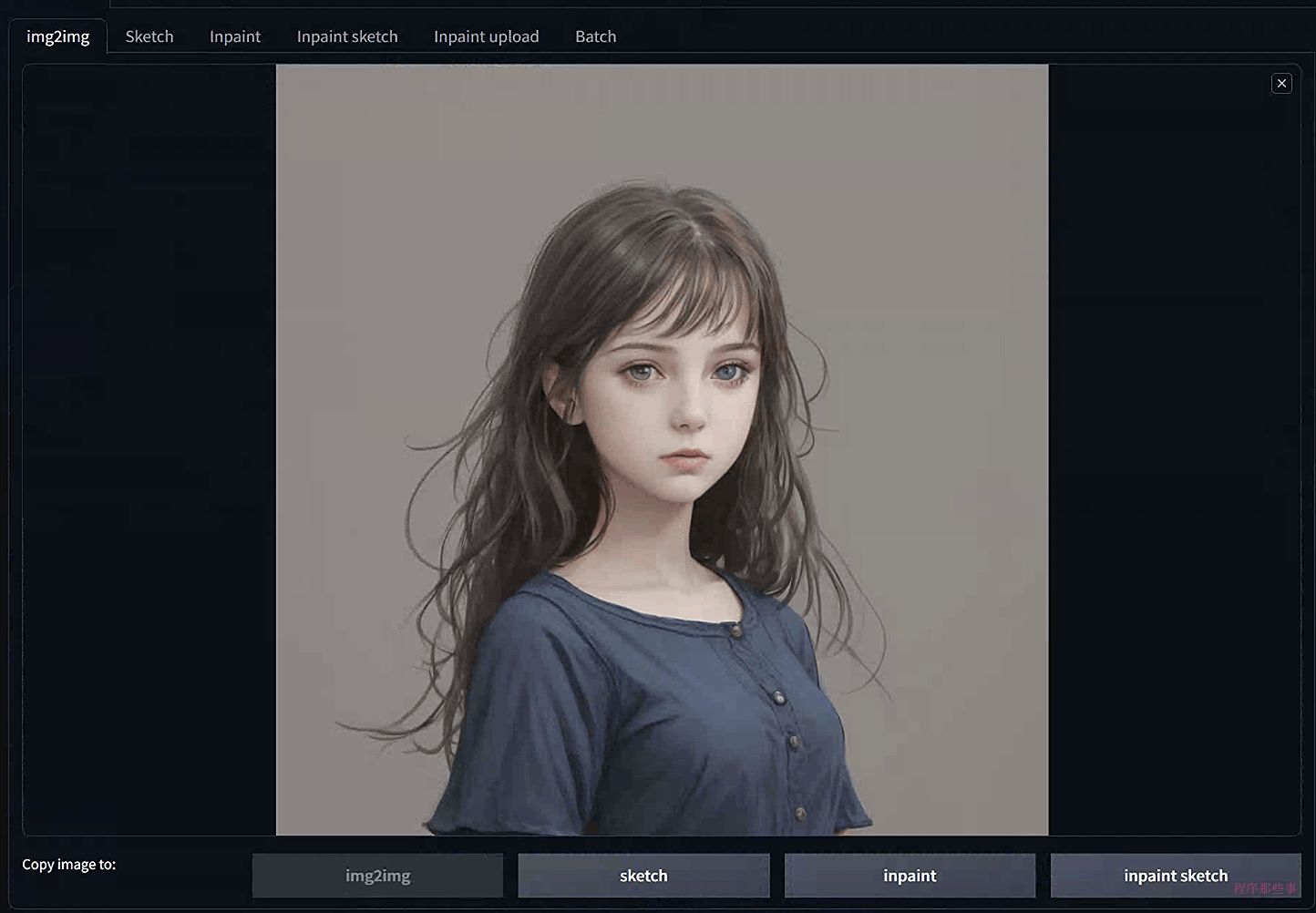
步骤2:调整宽度或高度,使新图像具有相同的宽高比。您应该在图像画布中看到一个矩形框,表示宽高比。
步骤3:设置采样方法和采样步数。通常使用DPM++ 2M Karass和20步。
步骤4:将批处理大小设置为4。一次多生成几张图可以挑选出你更满意的图片。
步骤5:为新图像编写提示。我将使用以下提示: a girl, sea。
步骤6:点击生成按钮生成图像。调整去噪强度并重复。不同的去噪强度可以生成不同的图片。
这是0.75的去噪强度:

这是0.5的去噪强度

可以看到0.75中人物已经发生了变化,但是在0.5中,人物基本上是保持不变的,同时我们还把背景换成了大海。
img2img页面里面的许多设置与txt2img是一致的。但是添加了一些新的选项:
Resize mode:如果新图像的宽高比与输入图像不同,有几种方法可以解决差异。现在我的原图是1024x1024,现在我想生成的图是768x1024。
- Just resize将按比例缩放输入图像以适应新图像尺寸。它会拉伸或挤压图像。可以看到图片发生了挤压。

-
Crop and resize将新图像画布适应到输入图像中。不适合的部分将被移除。原始图像的宽高比将被保留。

-
Resize and fill将输入图像适应到新图像画布中。多余的部分将填充为输入图像的平均颜色。宽高比将被保留。

-
Just resize (latent upscale)类似于Just resize,但缩放是在潜在空间中进行的。可以使用大于0.5的去噪强度以避免模糊图像。
去噪强度:控制图像的变化程度。如果设置为0,则不会发生任何变化。如果设置为1,则新图像与输入图像无关。0.75是一个不错的平衡点,你可以自行进行探索。
sketch
webUI中的sketch的作用是把素描图转换成真实的图片。
步骤1:转到img2img页面上的素描选项卡。
步骤2:将背景图像上传到画布上。
步骤3:写一个提示:a girl
步骤5:点击生成。
当然,素描的作用不限于此,我们还可以对图片进行创意的修改。
比如现在我有这样一幅图片:

这是一个美女,我想把她的衣服变成一个V领的可以可以呢?
在sketch界面,我们选择吸管工具,吸取皮肤的颜色,然后涂抹到衣服上,点击生成,看看效果:
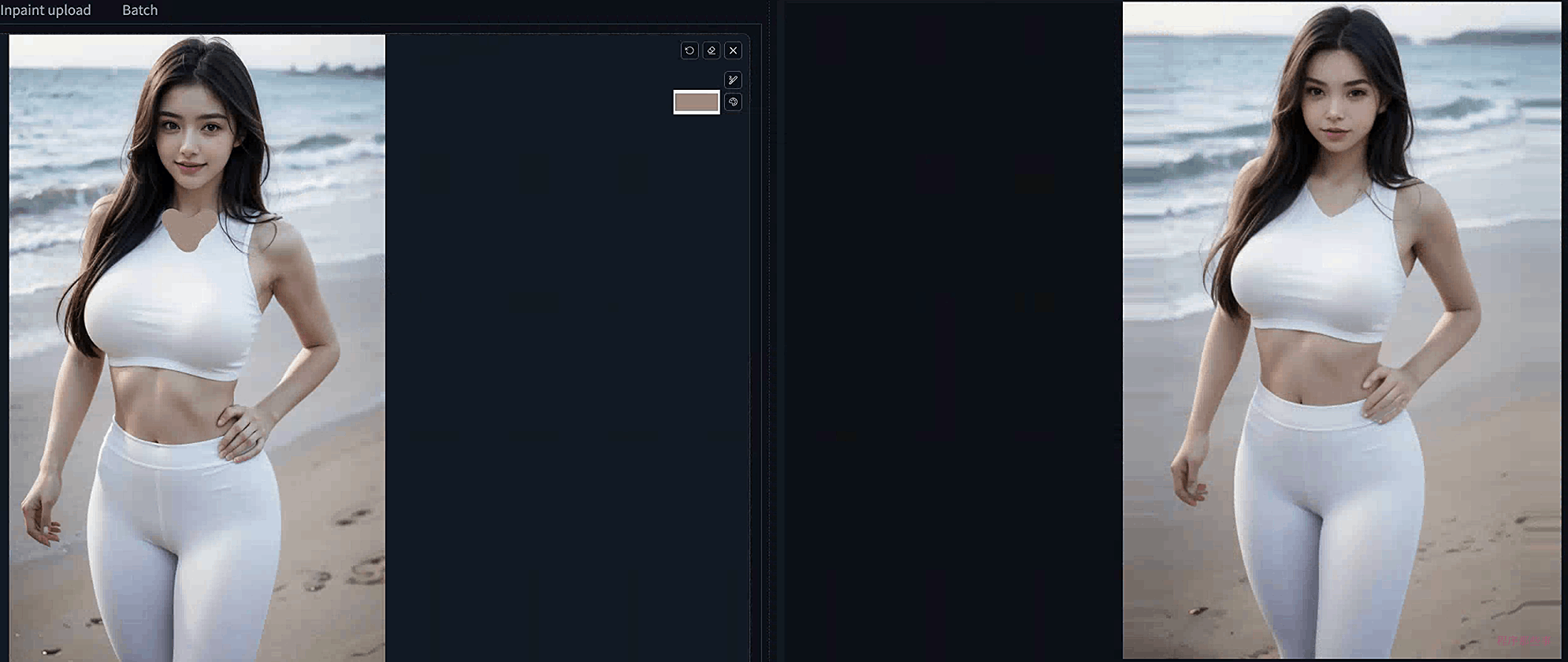
Inpaint
在img2img选项卡中,也许最常用的功能就是图像修复。
如果你在txt2img选项卡中生成了一张喜欢的图像,但出现了一点小瑕疵,你想要重新生成它。那么就可以把这张图片发送到Img2Img中。
假设你在txt2img选项卡中生成了下面的图像。然后你想给这个图片上加上个项链,那么可以在需要项链的位置添加上mask,提示词添加:necklace。点击生成看看效果:
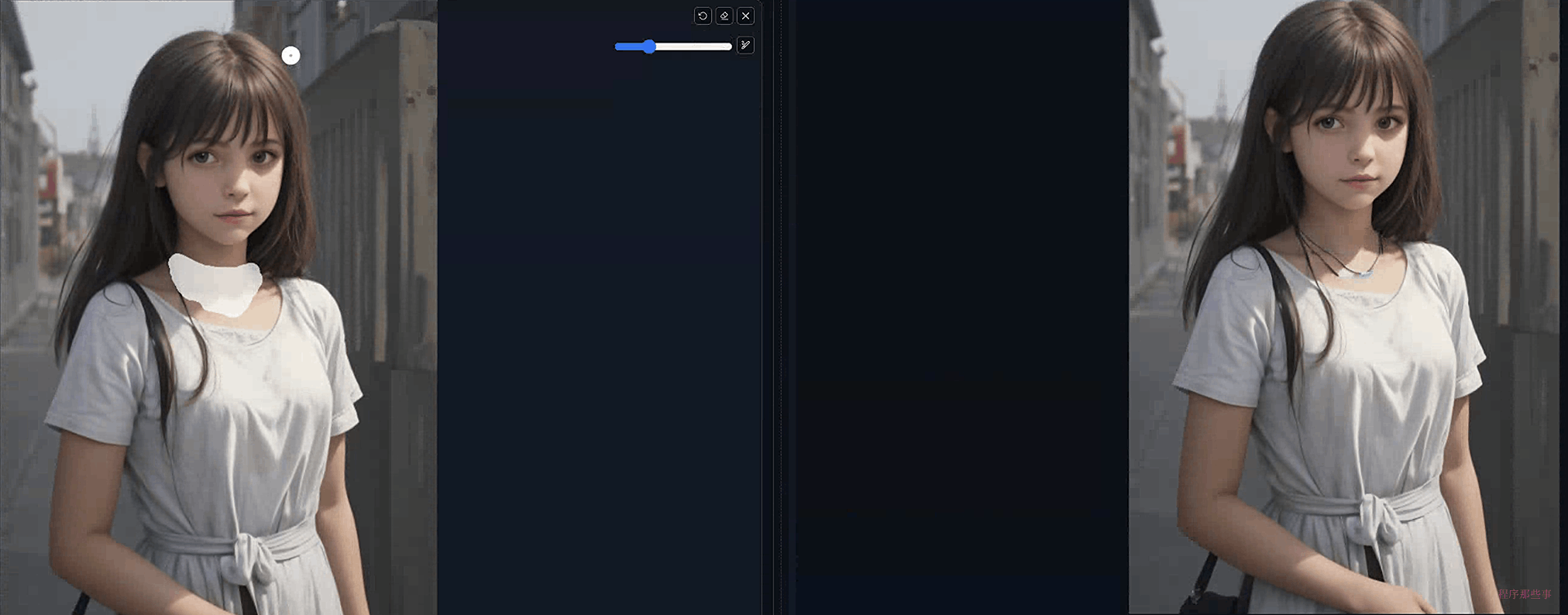
是不是很棒。你已经得到了你想要的效果。
当然,你可以通过调整降噪强度来观察不同数值对最后结果的变化。
在修复图像中进行缩放和平移
在修复图像的小区域时是否遇到困难?将鼠标悬停在左上角的信息图标上,即可查看缩放和平移的键盘快捷键。

-
Alt + 滚轮 / Opt + 滚轮:进行放大和缩小。
-
Ctrl + 滚轮:调整画笔大小。
-
R:重置缩放。
-
S:进入/退出全屏模式。
-
按住F键并移动鼠标进行平移。
这些快捷键在Sketch和 Inpaint Sketch中同样适用。
Inpaint sketch
Inpaint sketch结合了Inpaint和sketch功能。它让你可以像在sketch标签页中那样绘画,但只影响mask部分的区域。其他的区域保持不变。还是刚刚的例子:
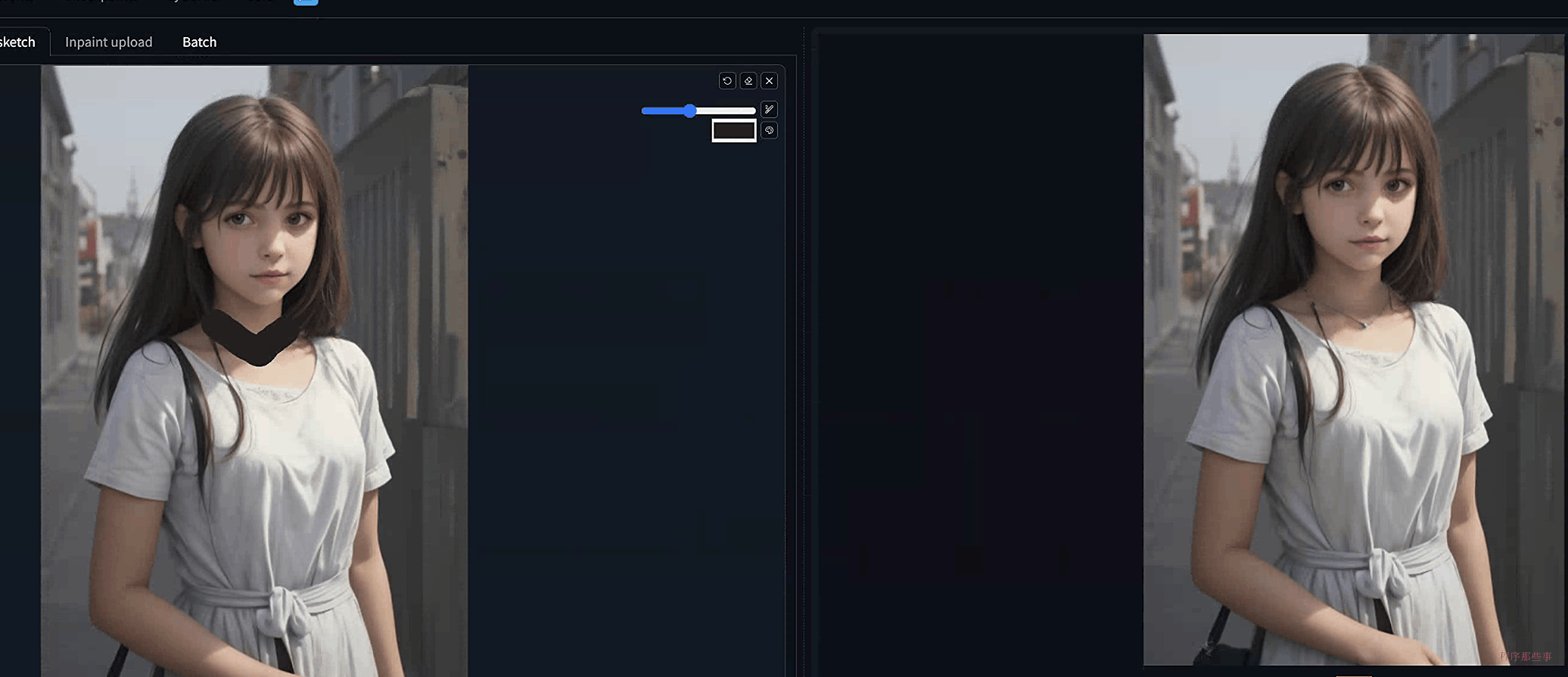
Inpaint upload
Inpaint upload功能允许您上传一个独立的蒙版文件,而不是手动绘制它。
Batch
使用批处理可以对多张图片进行修复或进行图像转换。
从图像中获取Promot
Interogate CLIP 按钮会对您上传到 img2img 选项卡的图像进行猜测,并生成提示。当您想生成一个不知道提示词的图像时,这将非常有用。
步骤 1:转到 img2img 页面。
步骤 2:将图像上传到 img2img 选项卡。
步骤 3:点击 Interrogate CLIP 按钮。

在提示文本框中会显示这个图片的提示词。
Interrogate DeepBooru 按钮提供类似的功能,但它是专为动漫图像设计的。
图像放大
之前我们在文生图里面提到了有一个Hire.fix的功能可以实现图像放大的效果。
如果不是在文生图中,webUI也提供了一个非常有用的图像放大功能。你可以在Extras tab中找到它。
基本用法
按照以下步骤来放大图像。
步骤1:导航到extras页面。
步骤2:上传图像到图像画布。
步骤3:在调整大小标签下设置按比例缩放因子。新图像将会按比例放大。
步骤4:选择Upscaler 1。比较通用AI图像放大器是R-ESRGAN 4x+。
步骤5:点击生成。您应该在右边得到一张新的图像。
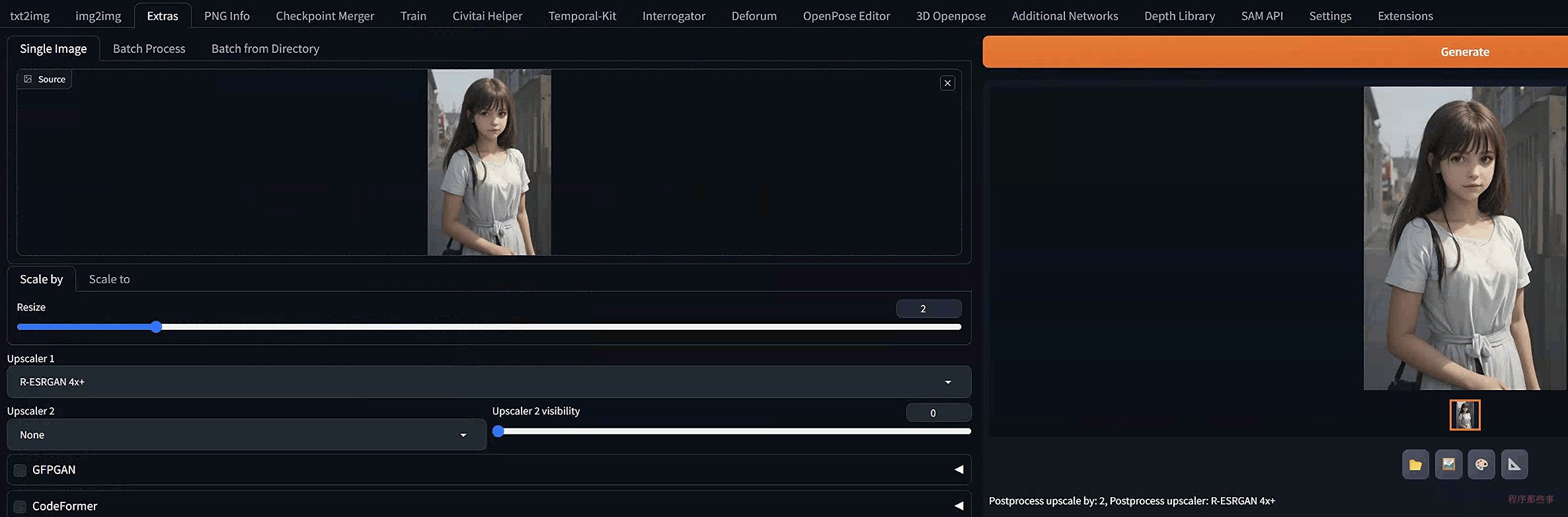
图像放大器的种类
AUTOMATIC1111默认提供了一些图像放大器。
Lanczos和Nearest是老式图像放大器。它们的功能不是很强大,但行为是可预测的。
ESRGAN,R-ESRGAN,ScuNet和SwinIR是AI图像放大器。它们可以通过创造内容来增加分辨率。
在extra中还有一个upscaler2,通过使用它,你可以结合两个图像放大器的效果。通过旁边的visibility滑块来控制混合的程度。
人脸修复
在放大过程中,你可以选择进行人脸修复。
有两个选项可供选择:GFPGAN 和CodeFormer。勾选他们中的任何一个就可以开启人脸修复功能了。

PNG Info
如果AI图像是PNG格式,你可以尝试查看提示和其他设置信息是否写在了PNG元数据字段中。
首先,将图像保存到本地。
打开AUTOMATIC1111 WebUI。导航到PNG信息页面。
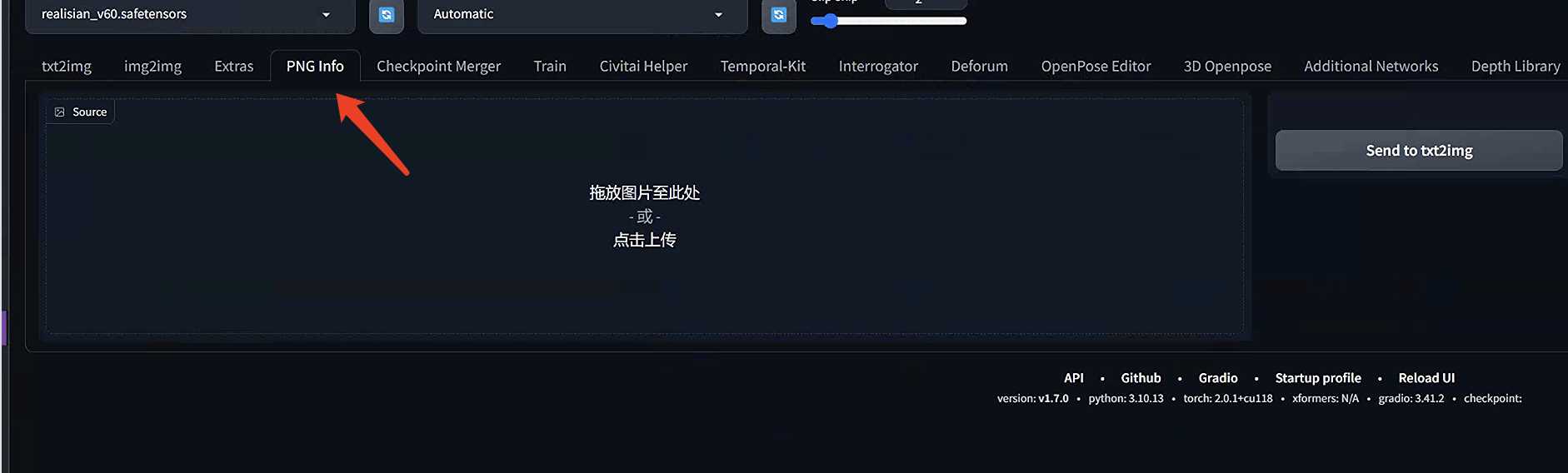
将图像拖放到左侧的源画布上。
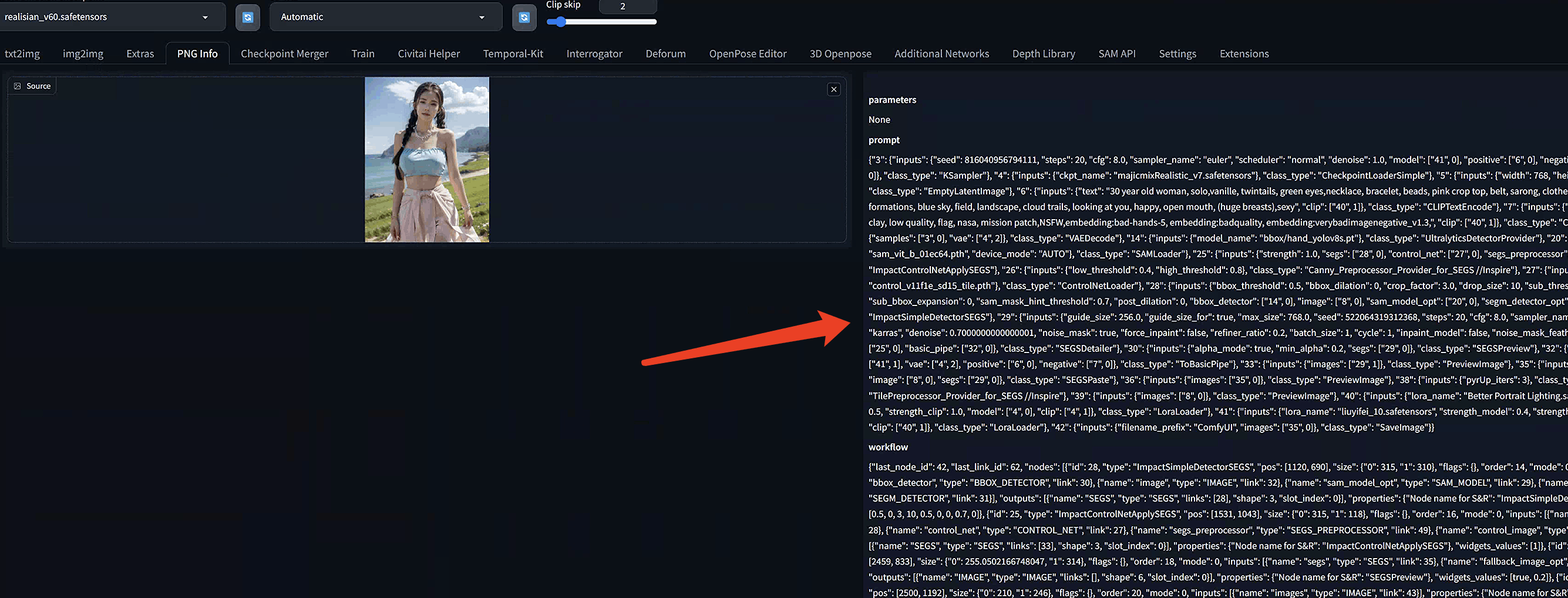
在右边你会找到关于提示词的有用信息。你还可以选择将提示和设置发送到txt2img、img2img、inpainting或者Extras页面进行放大。
安装扩展
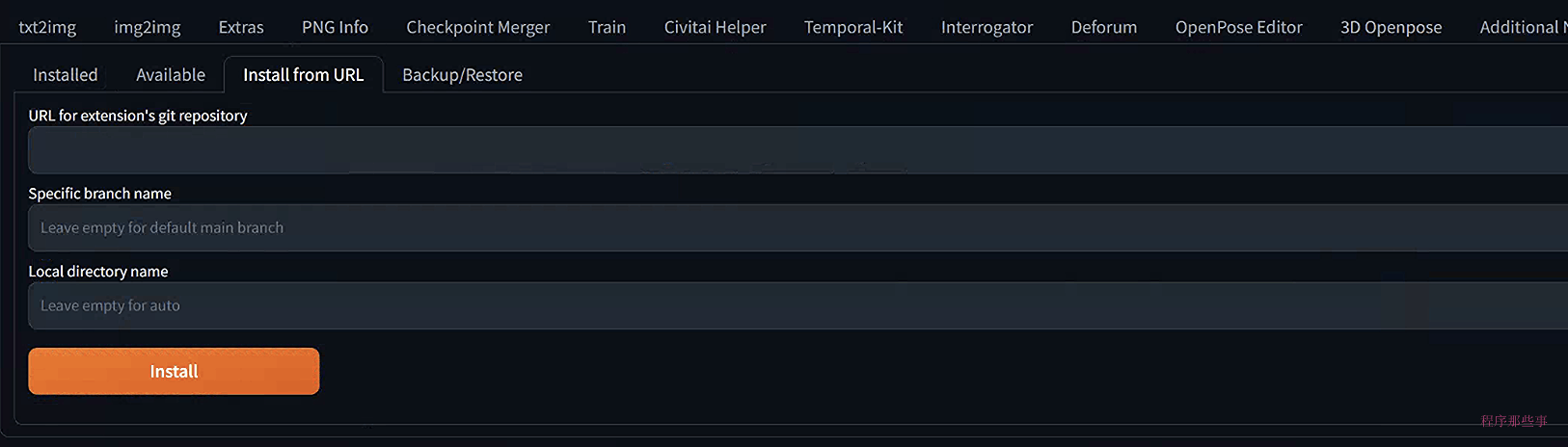
要在AUTOMATIC1111 Web UI中安装扩展,请按照以下步骤进行:
-
正常启动AUTOMATIC1111 Web UI。
-
转到扩展页面。
-
点击从URL安装选项卡。
-
在扩展git仓库的URL字段中输入扩展的URL。
-
等待安装完成的确认消息。
-
重新启动AUTOMATIC1111。(提示:不要使用“应用并重启”按钮。有时不起作用。完全关闭并重新启动Stable Diffusion WebUI)
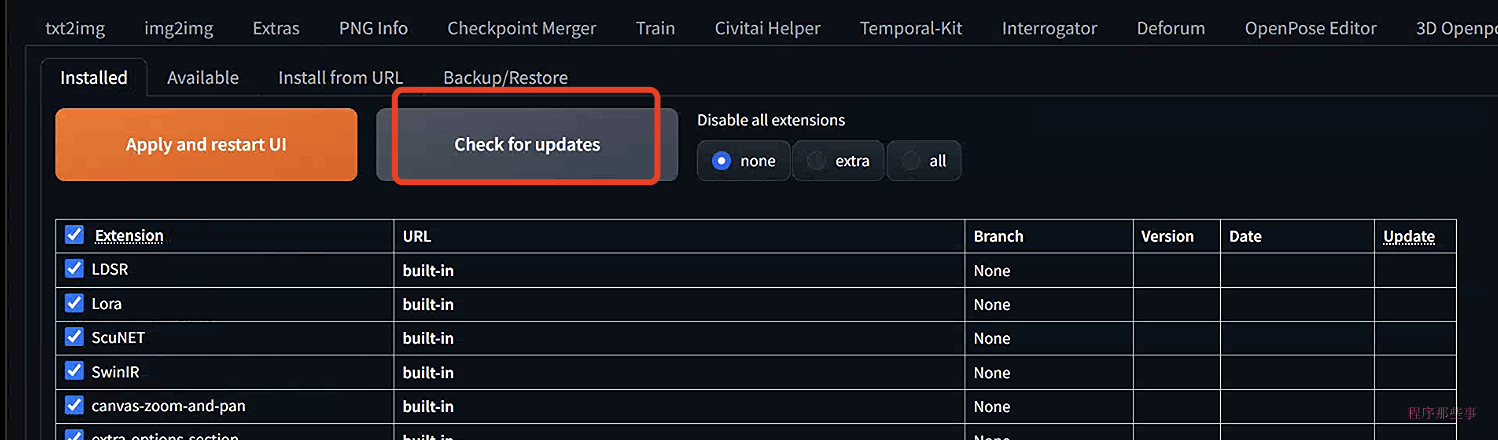
另外,在已安装的扩展列表中,你也可以点击check for updates来对扩展进行升级。
总结
好了,基本上所有的web UI操作说明都在这里了。欢迎大家积极尝试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号