mysql 索引
mysql 索引
索引是帮助Mysql高效获取数据的而且已经是排好序的数据结构
索引数据结构一般有以下几种:
- 二叉树
- 红黑树
- hash表
- B(+)Tree
推荐一个外国的网站学习数据结构:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
红黑树相较于二叉树,可以自动旋转至左右子树平衡,高度差不超过1,降低了树高,减少了磁盘的读取次数,节省了查找时间。
当数据量过大,即使红黑树,树高也不可控 ,由于数据库查找索引,每遍历一个节点,都要进行一次磁盘IO读取数据,由于磁盘IO读取数据比较慢,显得查找效率依然不是特别高。
有没有什么办法能够大大降低树高,而且可控,这样就提高了查找效率,查找索引的时间就稳定于是引出了B树,相当于二叉树的横向扩展,一个子节点存储多个索引,数据库在查找索引的时候,把这个节点的索引全部加载到内存中,然后在查找比较,这样效率就提高了很多。
B树:
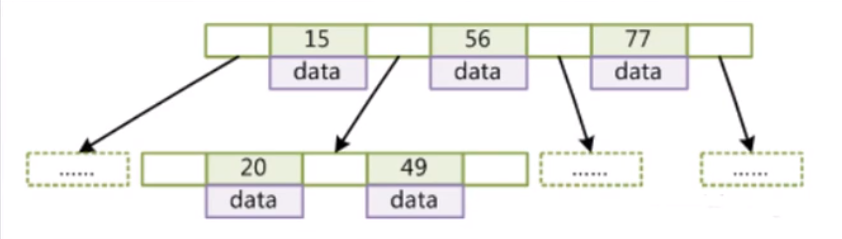
然而mysql底层用的是B树的一个变种叫B+树;
- 非叶子节点不能存储data,只能存储索引,这样一个节点就可以存放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高了区间访问的性能
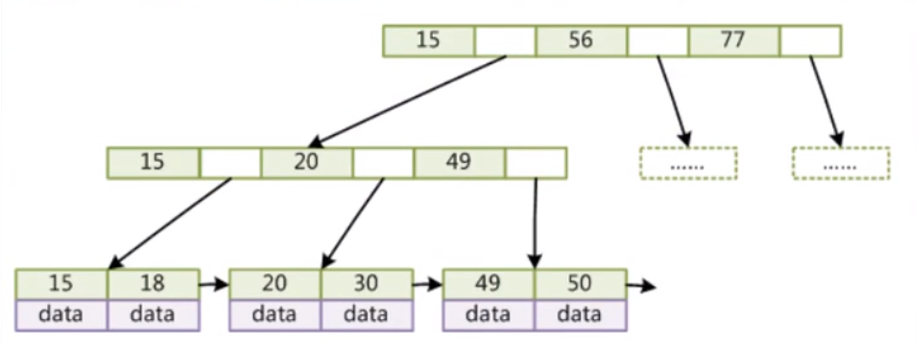
B+树和hash表的区别:
B+ Tree索引和Hash索引区别 哈希索引适合等值查询,但是不无法进行范围查询 哈希索引没办法利用索引完成排序 哈希索引不支持多列联合索引的最左匹配规则 如果有大量重复键值得情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
MYISAM存储引擎索引的实现
MyISAM的索引文件和数据文件是分离的(非聚集)
使用show global variables like "%datadir%";查看数据库数据存放位置
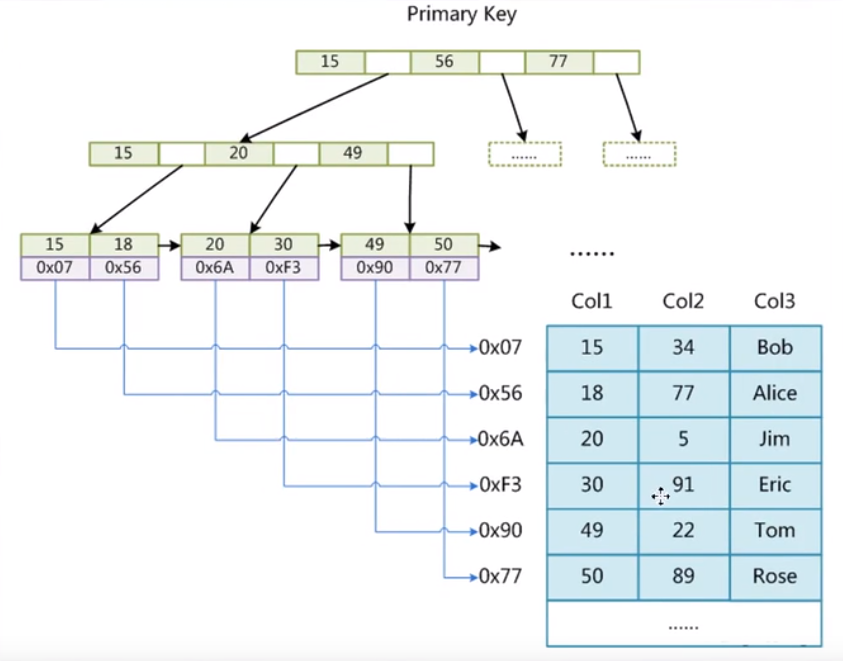
在MyIsam中,数据文件有两种,MYD文件存储的是数据,MYI文件存储的索引,使用MyIsam数据库引擎进行查找时,会先去MYI去查找索引,找到后采取MYD获取数据。
InnoDB索引实现
InnoDB叶子节点的索引和行数据存放在一起(聚集表),都放在ibd文件中
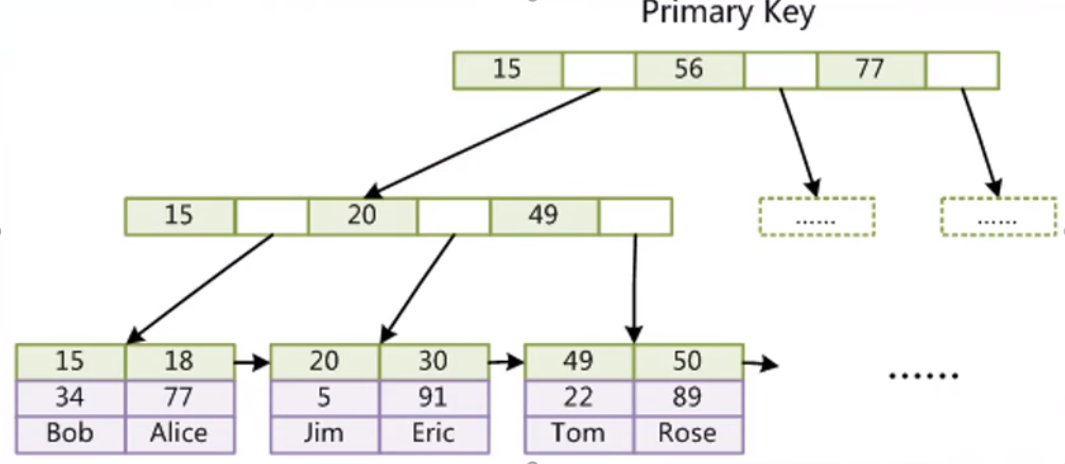
一般情况下,为什么Innodb的效率更高,因为根据索引查找数据时,MyIsam需要查找两个文件,而Innodb只需要到1个文件中查找就行了,少了一次磁盘IO操作。
key和index的关系:
key有两个作用,一个是约束(偏重于约束和规范数据库的结构完整性),而是索引(辅助查询用的),包括primary key, unique key, foreign key 等。
primary key 有两个作用,一是约束作用(constraint),用来规范一个存储主键和唯一性,但同时也在此key上建立了一个index;
unique key 也有两个作用,一是约束作用(constraint),规范数据的唯一性,但同时也在这个key上建立了一个index;
foreign key也有两个作用,一是约束作用(constraint),规范数据的引用完整性,但同时也在这个key上建立了一个index;
而index仅仅是就是索引。
聚集索引一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为NULL的唯一索引,如果还是没有的话,就采用Innodb存储引擎为每行数据内置的6字节ROWID作为聚集索引。
每张表只有一个聚集索引,其他都是非聚集索引,也称为二级索引。
普通索引一般不与数据存放在一个文件中,有时通过普通索引查询数据会触发回表查询。
回表查询:
先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
索引覆盖:
一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。
联合索引和最佳左前缀:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号