
Python数据处理 I:数据的读取与存储
简介:Python是一种面向对象的解释型计算机脚本语言。即使对于半导体从业人员,掌握一门脚本语言对于工程数据的处理也是十分有帮助的。今天我们就来说一说如何用Python进行数据的读取和存储。
标签:计算机技术,Python
人生苦短,我用Python。 —— 鲁迅
引 子:
在半导体制造公司里,每天都会产生数以亿计的生产和测试数据。采用自动化的脚本语言对生产测试数据进行批量,将大大提高工程师的工作效率。虽然Perl语言在半导体制造公司内具有更高的普及率,但是随着大数据和人工智能技术的不断发展,Python受到了越来越高的重视,因此我选择了Python作为数据处理的脚本工具。
平台:Windows系统,Spyder 3.1.4 软件,Python 3.6 环境。
这个系列包括如下3部分:
1. 数据的读取与存储
2. 数据的清洗(预处理)
3. 数据的处理方法简介
今天,我们先说一说数据的读取和存储。
实现数据处理,首先要能让python读取本地的数据文件。
通常来说,数据都保存在Excel表格里,我们可以使用xlrd库来读取Excel表格中的数据,用xlwt库将处理后的数据保存为Excel文件。更一般的情况下,我推荐大家使用pandas库的read_xxx函数(常用的诸如read_excel、read_csv、read_sql_query等)来读取数据。
此外,通过os库可以指定文件位置、循环遍历文件夹中的全部数据文件,实现数据的批量处理。
本文的主要内容:
1. xlwt库和xlrd库
2. 用pandas库读取和存储数据
3. 标签型文本的处理:beautifulsoup
4. 用os库实现数据批量处理
1. xlwt库和xlrd库
用xlrd库读取数据的基本步骤:
① 用xlrd.open_workbook()打开Excel并在python中生成一个workbook对象;
② 用workbook.sheet_by_index()或者workbook.sheet_by_name()创建一个sheet对象;
③ 用sheet.row_values()或者sheet.col_values()获取特定行或者列的数据。
④ 用sheet.cell(x,y).value可以获得特定单元格的数据。
示例代码如下,这里参考了脚本之家的一篇博文。在这篇博文中还介绍了如何指定单元格的数据类型、如何输出复杂的Excel表格,有兴趣可以了解一下,这里就不展开了。
import xlrd #载入xlrd库 workbook = xlrd.open_workbook(r'C:\demo.xlsx') # 打开Excel文件 # 根据sheet索引或者名称获取sheet内容 sheet2 = workbook.sheet_by_index(1) sheet2 = workbook.sheet_by_name('sheet2') # sheet对象的基本属性:名称,行数,列数等: print(sheet2.name,sheet2.nrows,sheet2.ncols) # 获取整行和整列的值(数组): rows = sheet2.row_values(3) # 获取第四行内容 cols = sheet2.col_values(2) # 获取第三列内容 # 获取单元格内容: print sheet2.cell(1,0).value.encode('utf-8') print sheet2.cell_value(1,0).encode('utf-8') print sheet2.row(1)[0].value.encode('utf-8')
用xlwt库写数据到Excel的基本步骤:
用xlwt库输出数据的方法比较简单,主要还是用遍历的方法将每一个数据输入到对应的单元格,使用的函数是sheet.write(x,y,data),其中x,y指单元格的列数和行数(从0开始计数)。
输出的过程和读取类似,首先要创建一个工作簿对象,然后在工作簿中添加sheet对象,并向sheet中的单元格写入数据,最后用f.save(‘文件路径’)保存。
这里需要注意如下几点:
- xlwt一次最多保存65532行、256列,否则会报错!这也是使用xlwt库最大的问题,目前我还没找到解决方法。
- 用sheet.write_merge(x1,x2,y1,y2,data)可以实现单元格的合并。
- 通过f.add_sheet()可以一次保存多个sheet到Excel中。
- 通过设置和指定保存的style(包括字体、字号、颜色等)可以实现Excel表格的格式化输出。在如下的代码中有提到set_style的方法,这里不展开说了。
import xlwt # 载入xlwt数据库 f = xlwt.Workbook() # 创建工作簿 sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) # 创建sheet row0 = [u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计'] column0 = [u'机票',u'船票',u'火车票',u'汽车票',u'其它'] status = [u'预订',u'出票',u'退票',u'业务小计'] # 生成第一行 for i in range(0,len(row0)): sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True)) # 生成第一列和最后一列(合并4行) i, j = 1, 0 while i < 4*len(column0) and j < len(column0): sheet1.write_merge(i,i+3,0,0,column0[j],set_style('Arial',220,True)) # 第一列 sheet1.write_merge(i,i+3,7,7) # 最后一列"合计" i += 4 j += 1 sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True)) # 生成第二列 i = 0 while i < 4*len(column0): for j in range(0,len(status)): sheet1.write(j+i+1,1,status[j]) i += 4 f.save('demo1.xlsx') # 保存文件
(代码参考了上述脚本之家的博客)
总的来说,通过xlrd和xlwt库可以实现简单数据的读取。并且该方法可以通过指定单元格、行或者列的形式获取特定的数据,自定义程度高。
但是,这两个库的问题也很明显:致命问题在于xlwt的处理数据量有限制。而且,使用这两个库打开和保存Excel表格的过程复杂,无法直接读取全部数据,还需要通过其他函数转换成数据处理常用的DataFrame格式,比较繁琐。
因此,如果你需要对数据进行自定义读取和写入,并且数据量比较小(小于),你也不怕麻烦的话,可以使用xlrd和xlwt库来读取数据。对于通常的数据读取,我更推荐采用接下来要介绍的pandas的函数来读取。
2. 用pandas库读取和存储数据
用pandas库读取数据非常的方便,一句代码即可轻松实现。
pandas库是python数据处理领域非常重要也是非常强大的一个库,它采用一种叫“DataFrame”的结构来存储数据(类数据库结构)。在这种结构下,可以方便的对数据进行处理。建议下载pandas库的官方document看,能对这个库有一个全面的了解。这里,我们只介绍一下简单的用法。
使用pandas库读取数据的常用函数:
-
import pandas as pd table = pd.read_table('http:\\somelink.csv') # 读取任一结构型文本数据 csv = pd.read_csv(r'c:\data.csv') # 读取csv文件 excel = pd.read_excel(r'c:\data.xlsx') # 读取Excel文件
使用 pd.read_table( ) 函数时,可以通过sep变量自定义数据的分割符,从而方便地对txt文本数据进行结构化读取:
-
df = pd.read_table(path, sep = '|') # 用“|”对每行数据拆分
- 此外,还可以自定义表格的标题行:
-
user_cols = ["Name", 'Data_A', 'Data_B'] df = pd.read_table(path, sep = '|', head = None, names = user_cols)
还可以自定义读取表格的某些行和列:
# 读取特定的列(按顺序编号) df = pd.read_excel(filename, sheetname, usecols = [0,1,4,5,6,7,12,13]) # 跳过特定行 df = pd.read_excel(filename, sheetname, skiprows=[0]) # 跳过第一行
对于导入的 df 数据,可以通过向屏幕打印如下参数来对数据的导入结果进行快速检验:
df.head() # 返回DataFrame的前几行 df.describe() # 返回DataFrame中数字部分的概要信息 df.shape() # 返回DataFrame的大小(列数x行数) df.dtypes() # 返回DataFrame中各列的数据类型
进 阶:用pandas库的 pd.read_sql_query 函数读取数据库中的数据:
import psycopg2 # 用psycopg2库连接数据库 import pandas as pd # 用pd.read_sql_query在本地创建数据表 # 定义数据库的名称,用户名,密码,链接地址和接口 dbname = 'database' username = "admin" password = "password" hosturl = "test.redshift.amazonaws.com" portnum = '5400' # 连接数据库,返回一个数据库对象 try: conn = psycopg2.connect("dbname=%s port=%s user=%s host=%s password=%s" %(dbname, portnum, username, hosturl, password)) except: print("Fail in connect the database!") #如果连接失败,打印该语句到屏幕上 # 定义查询语句query # 这里需要注意: # 1. 查询语句和SQLWorkbench中的几乎一模一样,唯一的区别是语句的最后要以英文分号结尾 # 2. 在Python中无法在字符串中直接输入单引号,要在单引号前加上反斜杠 \ query = 'SELECT data, teststep FROM db.database WHERE rownumber < 100;') # 根据query的语句到conn数据库中查询,并将结果返回给data这个DataFrame df = pd.read_sql_query(query, conn) # 两个参数:检索语句和连接的数据库对象
pandas库导出数据到Excel的方法如下:
df.to_excel(filename,sheetname) # 将df这个DataFrame中的数据保存到excel表格中,保存路径为filename,sheet名为sheetname(sheetname缺省值为sheet1)
如果需要在一个Excel中保存多个sheet,需要先定义一个指向Excel路径的对象,然后向该对象中添加sheet,最后将Excel保存并关闭:
writer = pd.ExcelWriter(filename) # 定义一个向Excel写入数据的对象 df1.to_excel(writer,'Data1') # 向该Excel中写入df1到Data1这个sheet df2.to_excel(writer,'Data2') # 向该Excel中写入df2到Data2这个sheet writer.save() # 保存Excel表格 writer.close() # 关闭Excel表格
在输出数据的时候,还可以自定义输出时列的先后顺序:
# 写入数据到sheet中,并按output_cols的顺序对列进行排序 output_cols = ['Data_A', 'Data_B', 'Name'] df.to_excel(writer,'Data', columns = output_cols)
3. 标签型文本的处理:beautifulsoup
有时候,我们拿到的数据是标签型数据(如HTML,XML,JSON,YAML等等)。这时候,数据的结构是通过标签键值对来标记的。
![]() 这是一个XML型的数据文件。不难发现,X和Z的数据存储在了<X><\X>和<Z><\Z>包裹的键值对中了。
这是一个XML型的数据文件。不难发现,X和Z的数据存储在了<X><\X>和<Z><\Z>包裹的键值对中了。这样的数据并不适用之前的方法来读取。我采用的方法是,使用python网络爬虫时用到的BeatifulSoup函数来获取标签中的数据。通过BeautifulSoup函数可以把标签型数据转换为一个soup类,再对soup进行find_all('标签名称')并遍历,即可读取全部的数据了。代码实现如下:
from bs4 import BeautifulSoup # 导入BeautifulSoup模块。注意大小写 import pandas as pd soup = BeautifulSoup(open('DATA.xml', 'rb'), 'xml', from_encoding='utf-8') # 按照utf-8编码制度读取xml类型的文件 X = [] Z = [] for i in soup.find_all('X'): # 循环遍历所有标签为X的数据 X.append(i.string) # 将标签数据的string/comment写入到X这个列表中 for j in soup.find_all('Z'): Z.append(j.string) # 将列表a,b转换成字典后,把结果转换成DataFrame并保存到Excel中 c={"X" : X, "Z" : Z} # 转换为字典 df = pd.DataFrame(c) df.to_excel('DATA.xlsx')
在上述代码中,关键在于第4行,如何用BeautifulSoup读取标签型文件。这里详细说明一下。在BeautifulSoup中,一般需要定义三个部分:文件信息、解析方式、编码类型。
第一部分 open('DATA.xml', 'rb') 声明了打开文件的位置和读取方式。第二部分 'xml' 声明了解析方式。常用的解析方式包括 'html.parser'、'lxml'、'xml' 和 'html5lib'。第三部分声明了文件的编码类型,一般来说编码类型BeautifulSoup可以自动确定无需定义,但如果编码类型已知,建议在此处定义好。
建立BeautifulSoup类以后,通过 soup.find_all('X') 返回全部标签名为 X 的行的集合。从下图中可以看出,标签型数据包括了name,attrs,string/comment等结构,这些都已经被BeautifulSoup转换成了类的属性。比如,我这里需要读取content的内容,只需要用 i.string 即可。
![]() 标签型数据的基本结构
标签型数据的基本结构
4. 用os库实现数据批量处理
os库是一个操作系统指令库。在数据处理过程中,用os库可以读取某个文件目录下所有文件的名称,实现对多个数据文件的批量处理:
import os import pandas as pd path0 = r'C:\data' filelist = os.listdir(path0) # 读取文件目录下的所有文件名称,返回一个文件列表 sheet_name = 'sheet1' for excel_path in filelist: # 循环遍历filelist中的各个文件 df = pd.read_excel(excel_path,sheet_name) ...
os库可以实现对操作系统的各种命令,很多时候可以简化我们的工作。这里限于篇幅不展开叙述,有兴趣的同学可以查看如下的链接:
总 结
本文主要介绍了如何用Python进行数据的读取和存储。对于通常的数据形式,推荐采用pandas库来读取。如果需要自定义读取特定单元格,推荐使用xlrd库;如果需要读取标签型数据,推荐使用BeautifulSoup方法。在数据读写过程中,合理运用os库可以实现文件的批量导入,节省时间成本。
 这是一个XML型的数据文件。不难发现,X和Z的数据存储在了<X><\X>和<Z><\Z>包裹的键值对中了。
这是一个XML型的数据文件。不难发现,X和Z的数据存储在了<X><\X>和<Z><\Z>包裹的键值对中了。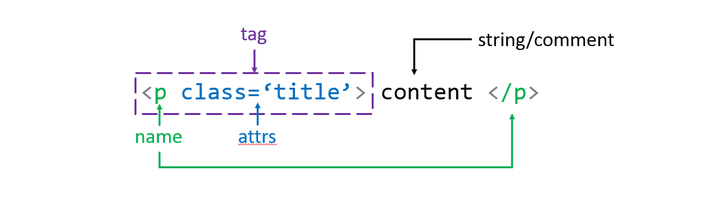 标签型数据的基本结构
标签型数据的基本结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号