第一次个人编程作业
第一次个人编程作业:论文查重
github链接(点击查看代码):https://github.com/Rossalliong/031802315/blob/master/论文查重.py
一.计算模块接口的设计与实现过程
·所用函数
1.readLines(filepath)
该函数用于读取路径为filepath的文本内容,其中包含了函数f.readlines(),该函数作用为:读取文本所有行,结果保留在一个列表变量中,每行作为一个元素。

2.compare(file1,file2)
该函数用于比较两个文本的相似度,其中用到了函数count(),通过它可以知道文本二的每一行内容是否能在文本一中找到相似部分。
·流程图

·程序核心部分
在动手之前,阅读了已完成提交的同学的博客,大部分都采用了jieba分词、TF-IDF与余弦相似性的应用等方法,我就想还有没有其它不一样的方法,便自己上网百度,到处搜索,无意中就找到了count()这个函数(附上链接https://www.cnblogs.com/daniumiqi/p/12154827.html),用于统计字符串里某个字符出现的次数,可选参数为在字符串搜索的开始与结束位置,那通过这个函数是不是也可以达到要求呢?首先进行一个循环,若lines2.count(line) > 0(lines2来自file2,line来自file1),count(此前已令count=0)进行自加一,遍历结束后,最后通过式子count / max(len(lines1), len(lines2))返回答案,可以说这样达到了一个异曲同工之妙,但是性能可能会有所差别,这便进入了下一个步骤。
二.计算模块接口部分的性能改进
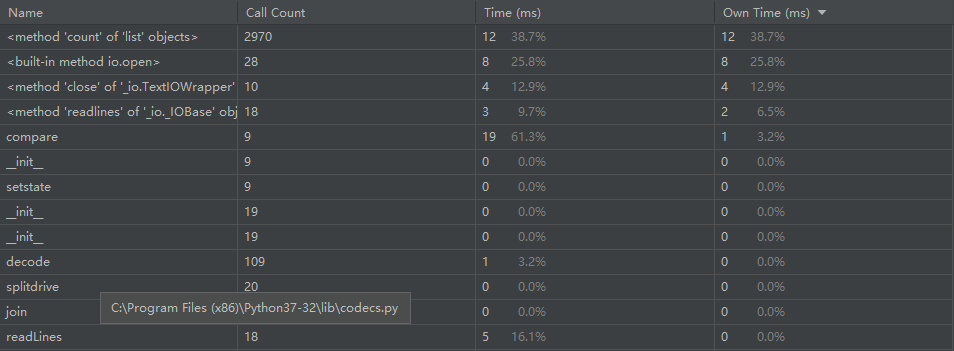
因为我是用IDLE进行代码的一个编写,我就直接用IDLE的性能分析工具进行性能测试,在代码中加入“cProfile.run('foo()', 'foo.out')”,然后在代码目录下运行cmd,输入命令“python -m cProfile del.py”,就会出现相关的一些性能分析。但后面发现可能pc自带的profile性能测试工具会比较好用一些,所以这里我就贴上用pc的性能测试工具测试出的性能分析。
Statistics:
Call Graph:
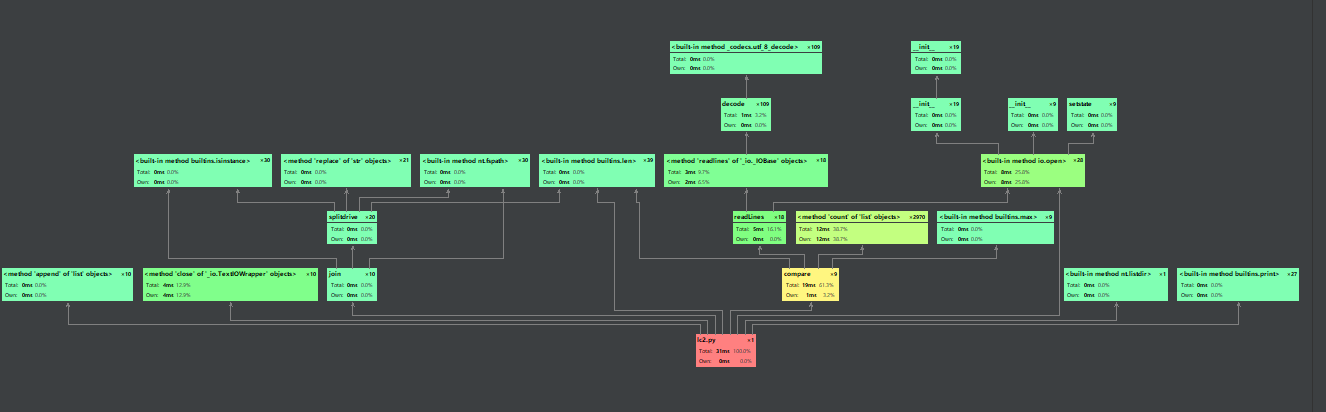
因为图表比较小,我这里就重要部分进行放大截取:
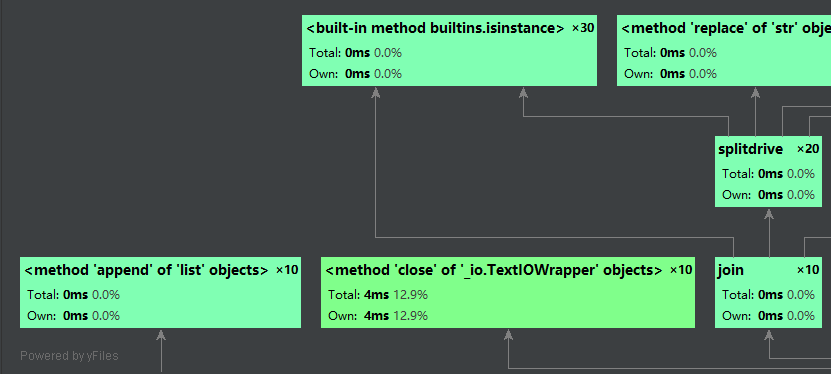
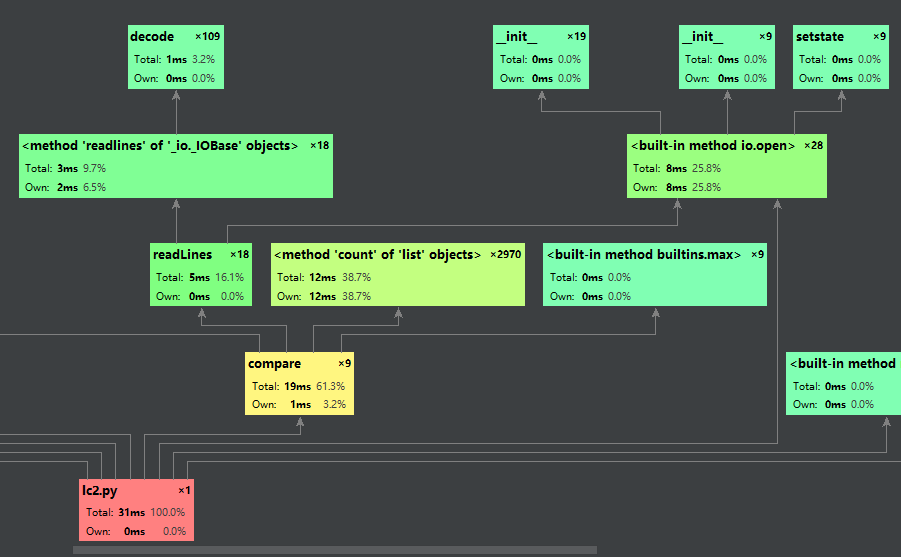
从以上可以看出,compare()这个函数所占用的时间是最多的,因为是关键函数,所以可以接受,下面贴出这部分代码。
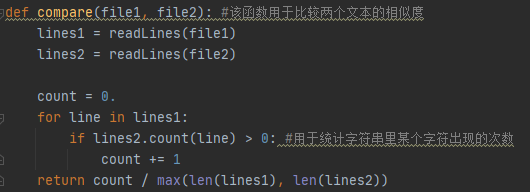
三.计算模块部分单元测试展示
·单元测试代码部分展示
import lc2
import unittest
class MyTest(unittest.TestCase):
def tearDown(self) -> None:
print("test over!")
def test_add(self):
print("orig_0.8_add.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\orig_0.8_add.txt")
print(similarity)
def test_del(self):
print("orig_0.8_del.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\orig_0.8_del.txt")
print(similarity)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt", "C:\测试文件\orig_0.8_dis_1.txt")
print(similarity)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt", "C:\测试文件\orig_0.8_dis_3.txt")
print(similarity)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt", "C:\测试文件\orig_0.8_dis_7.txt")
print(similarity)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\orig_0.8_dis_10.txt")
print(similarity)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\orig_0.8_dis_15.txt")
print(similarity)
def test_mix(self):
print("orig_0.8_mix.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\orig_0.8_mix.txt")
print(similarity)
def test_rep(self):
print("orig_0.8_rep.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\orig_0.8_rep.txt")
print(similarity)
def test_mine1(self):
print("mine1.txt 相似度")
similarity = lc2.compare("C:\测试文件\orig.txt","C:\测试文件\mine1.txt")
print(similarity)
if name == 'main':
unittest.main()
·测试结果
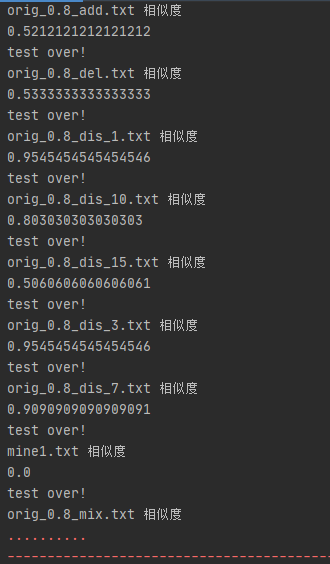
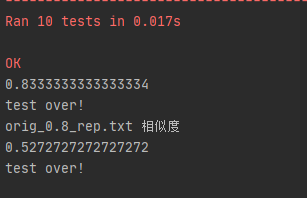
刚开始是想自己写一个单元测试代码,但写完运行时存在一些bug,上网查询相关问题也没有得到有效解决,因为卡住太久便放弃了,后来通过百度又知道了可以用python自带的unittest函数,查找了一下模板,进行一些修改和完善,很快便实现了测试功能。
四.计算模块部分异常处理说明
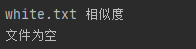
我自己在测试文本目录里加了一个空白文本“white”,同时在compare()函数里加入了一个if语句“if len(lines2)=='': print("文件为空")”,若lines2为空,则输出“文件为空”,在单元测试代码中也加入相应代码:

最终结果如下:
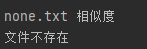
后面又测试了若文件不存在:
单元测试加入相应代码:

最终结果如下:
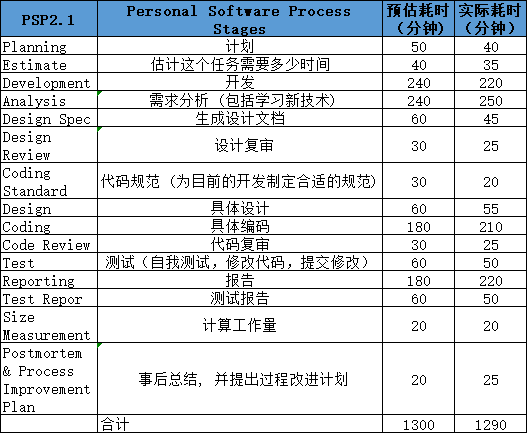
五.PSP表格
六.总结
·因为这是之前从未碰到过的题目,可以说这是一个难得的开始。
·在完成本次作业过程中,遇到了很多知识盲区,一次次通过百度搜索,一次次尝试,问题一个个慢慢解决,虽然麻烦,但实话说,学到了很多。
·总结出一句话,办法总比困难多,老师、同学、网络等都可以成为你解决问题的方法。
·山重水复疑无路,柳暗花明又一村,遇到难题不要急着放弃,再坚持一会,说不定事情就会有转机。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号