
目标:
- 文件的概念
- 文件的基本操作
- 文件/文件夹的常用操作
- 文本文件的编码方式
1.文件的概念
1.1文件的概念和作用
- 计算机的文件,就是存储在某种长期存储设备上的一段数据
- 长期存储设备包括:硬盘、U盘、移动硬盘、光盘····
文件的作用:
将数据长期存储下来,在需要的时候使用

1.2文件的存储方式
- 在计算机中,文件是以 二进制 的方式保存在磁盘上的
文本文件和二进制文件
- 文本文件
- 可以用 文本编辑软件查看
- 本质上还是二进制
- 例如:Python源文件
- 二进制文件
- 保存的内容不是给人直接阅读的,而是提供给其他软件使用的
- 例如:图片文件、音频文件、视频文件等等
- 二进制文件不能直接使用文本编辑器查看
2.文件的基本操作
2.1操作文件的套路
在计算机中,要操作文件的套路非常固定,一共包含三个步骤:
- 打开文件
- 读、写文件
- 读:将文件内容读入内存
- 写:将内存内容写入文件
- 关闭文件
2.2操作文件的函数/方法
- 在Python中操作文件需要记住1个函数和3个方法
| 序号 | 函数/方法 | 说明 |
| 1 | open | 打开文件,并返回文件操作对象 |
| 2 | read | 将文件内容读取到内存 |
| 3 | write | 将指定内容写入到文件 |
| 4 | close | 关闭文件 |
- open() 函数负责打开文件,并返回文件对象
- read/write/close三个方法都需要通过文件对象来调用
2.3read方法——读取文件
- open函数的第一个参数,是被打开的文件名(文件名区分大小写)
- 如果文件存在,返回文件操作对象
- 如果文件不存在,会抛出异常
- read方法 可以一次性读入并返回 文件的所有内容
- close方法 负责关闭文件
- 如果忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
- 注意:方法执行后,会把文件指针移动到文件的末尾
- 提示:
- 在开发中,通常先编写打开和关闭的代码,在编写中间针对文件读/写操作!
-
#获得文件操作对象(sis.txt文件) file = open("sis.txt") #读取 text = file.read() print(text) #关闭文件 file.close() ''' 运行结果 我是中文的哦 nidie中文 '''
- 文件指针
- 文件指针 标记 从那个位置开始读取数据
- 第一次打开文件时,通常文件指针会指向文件开始的位置
- 当执行了read方法后,文件指针会移动到读取内容的末尾
- 默认情况下会移动到文件末尾
- 思考:如果执行了一次read方法,读取了所有内容,那么再次调用read方法还能获取到内容吗?
- 答案:不能。第一次读取内容后,文件指针移动到文件末尾,再次调用不会读取到任何内容
-
![]() 文件指针演示
文件指针演示1 #获得文件操作对象(sis.txt文件) 2 file = open("sis.txt") 3 #读取 4 text = file.read() 5 #查看读取文件的长度 (14) 6 print(len(text)) 7 #输出读取到的文件 8 print(text) 9 print("*"*30) 10 #重新读取文件 11 text = file.read() 12 print(text) # 空 13 print(len(text)) # (0) 14 #关闭文件 15 file.close() 16 17 """ 18 运行结果: 19 14 20 我是中文的哦 21 nidie中文 22 ****************************** 23 24 0 25 """

2.4打开文件的方式
- open函数默认以只读方式打开,并返回文件对象
语法如下:
-
- f = open( " 文件名 " , " 访问方式 " )
![]()
-
x:以x打开一个文件,如果这个文件存在,那么报错
- t:以t打开一个文件,底层是以二进制的形式打开,但是会默认帮我们将文件解码(linux:默认以UTF-8).
- b:以b打开一个文件,是以二进制的形式打开,获取到的信息都是字节。
-
r+、rt+、rb+,默认光标位置:起始位置 w+、wt+、wb+,默认光标位置:起始位置(清空文件) - x+、xt+、xb+,默认光标位置:起始位置(新文件) - a+、at+、ab+,默认光标位置:末尾
提示:频繁的移动指针,会影响文件读写效率,开发中更多的时候会以 只读、只写 的方式来操作文件

2.5读写文件内容
-
-
f = open('info.txt', mode='r',encoding='utf-8') data = f.read() f.close() f = open('info.txt', mode='rb') data = f.read() f.close()
-
- 读n个字符(字节)【会用到】
f = open('info.txt', mode='r', encoding='utf-8') # 读1个字符 data = f.read(1) f.close() print(data) # 武 f = open('info.txt', mode='rb') # 读1个字节 data = f.read(3) f.close() print(data, type(data)) # b'\xe6\xad\xa6' <class 'bytes'>
- read方法默认会把文件的 所有内容 一次性读到内存
- 如果文件太大,对内存的占用会非常严重
readline 方法:
-
- 可以一次读取一行内容
- 方法执行后,会把指针移动到下一行,准备再次读取
读取大文件的姿势:
-
-
![]() View Code
View Code1 #打开文件 2 file = open("sis.txt") 3 while True: 4 #读取一行内容 5 text = file.readline() 6 #判断是否读取到内容 7 if text == "": #或者 if not text: 8 print(type(text)) #<class 'str'> 9 break 10 #每读取到末尾都会有一个 \n 11 print(text,end="") 12 """ 13 运行结果: 14 python1一 15 python2二 16 python3三 17 python4四<class 'str'> 18 """
-
readlines,读所有行,每行作为列表的一个元素
f = open('info.txt', mode='rb') data_list = f.readlines() f.close() print(data_list)
循环,读大文件(readline加强版)【常见】
f = open('info.txt', mode='r', encoding='utf-8') for line in f: print(line.strip()) f.close()
write,写
f = open('info.txt', mode='a',encoding='utf-8') f.write("你好") f.close() f = open('info.txt', mode='ab') f.write( "你好".encode("utf-8") ) f.close()
flush,刷到硬盘
f = open('info.txt', mode='a',encoding='utf-8') while True: # 不是写到了硬盘,而是写在缓冲区,系统会将缓冲区的内容刷到硬盘。 f.write("你好") f.flush() f.close()
移动光标位置(字节)
f = open('info.txt', mode='r+', encoding='utf-8') # 移动到指定字节的位置 f.seek(3) f.write("武沛齐") f.close()
移动到指定字节的位置,再插入数据时,会覆盖后面的数据
注意:在a模式下,调用write在文件中写入内容时,永远只能将内容写入到尾部,不会写到光标的位置。
获取当前光标位置(按字节算)
f = open('info.txt', mode='r', encoding='utf-8') p1 = f.tell() print(p1) # 0 f.read(3) # 读3个字符 3*3=9字节 p2 = f.tell() print(p2) # 9 f.close() f = open('info.txt', mode='rb') p1 = f.tell() print(p1) # 0 f.read(3) # 读3个字节 p2 = f.tell() print(p2) # 3 f.close()
2.6文件读写案例——复制文件
目标:用代码实现文件的复制过程
- 小文件复制
- 打开一个已有文件,读取完整内容,并写入到另一个文件
-
![]() 小文件复制
小文件复制1 #复制小文件方式1 2 file_read = open("sis.txt","r") 3 file_write = open("test.txt","w") 4 text_1 = file_read.read() 5 text_2 = file_write.write(text_1) 6 file_write.close() 7 file_read.close() 8 9 #复制小文件方式2 推荐(with关键字,会自动释放文件对象空间) 10 test = None 11 with open("sis.txt","r") as file: 12 test = file.read() 13 with open("test1.txt","w") as file: 14 file.write(test)
- 大文件复制
- 打开一个已有文件,逐行读取内容,并顺序写入到另一个文件
-
![]() 大文件复制
大文件复制1 #大文件复制 2 file_read = open("五笔词根1.jpg","rb") 3 file_write = open("五笔词根2.jpg","wb") 4 while True: 5 text = file_read.readline() 6 #python中,除了‘’、""、0、()、[]、{}、None为False, 其他转换都为True。 也就是说字符串如果不为空,则永远转换为True。 7 if not text: 8 break 9 file_write.write(text) 10 file_read.close() 11 file_write.close()
2.7上下文管理、文件读写中的函数
之前对文件进行操作时,每次都要打开和关闭文件,比较繁琐且容易忘记关闭文件。
以后再进行文件操作时,推荐大家使用with上下文管理,它可以自动实现关闭文件。
with open("xxxx.txt", mode='rb') as file_object: data = file_object.read() print(data)
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open("xxxx.txt", mode='rb') as f1, open("xxxx.txt", mode='rb') as f2: pass
文件读取 — Python 3.10.1 文档
3.文件/目录的常用管理操作
- 在 终端/文件浏览 中可以执行常规的 文件/目录 管理操作,例如
- 创建、重命名、删除、改变路劲、查看目录内容........
- 在Python中如果希望通过程序实现上述功能,需要导入 os 模块
文件操作:

目录操作:
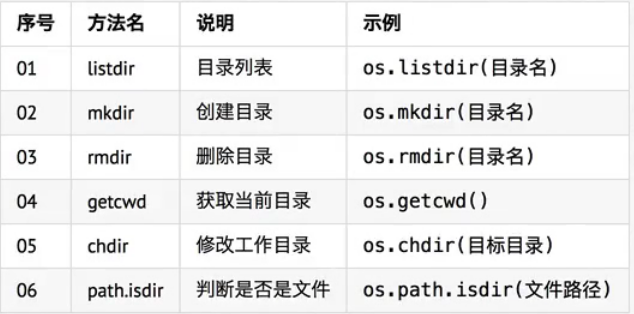
- 提示:文件或者目录操作,都支持 相对路径 和 绝对路劲
4.文本文件的编码方式
pass
# -*- coding: utf8 -*-
# -*- coding: utf-8 -*-
# -*- coding: gbk -*-
读文件:
-
r打开文件,默认使用GBK(windows是默认GBK,但是MAC和linux是默认UTF-8)的编码格式打开,所以在读文件时,默认编码需要与文件编码相同否则报错
-
rb打开文件,是一个字节流,所以需要decode()解码,默认decode("utf-8")
-
rt打开,以文本的形式打开一个文件(默认使用(windows是默认GBK,但是MAC和linux是默认UTF-8)打开文件)
-
由上可知,python中的默认编码是基于操作系统决定的 UTF-8:MAC、linux GBK:WIN
写文件:
-
w打开文件,默认使用GBK(windows是默认GBK,但是MAC和linux是默认UTF-8)的编码格式打开,所以在写文件时,如果文件已存在并且该文件的默认编码,与打开时的编码不同,也会乱码(因为它只会清空文件,不会修改文件的编码格式)。在写文件时,不需要encode。
-
wb打开二进制文件,不会受到编码影响,在write写入文件时,需要encode()压缩,压缩时指定编码,那么生成的文件就是什么编码。
-
所以:在打开一个文件时,最好指定其编码格式,推荐为UTF-8
5.csv格式文件
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
对于这种格式的数据,我们需要利用open函数来读取文件并根据逗号分隔的特点来进行处理。
 CSV文件内容
CSV文件内容练习题案例:下载文档中的所有图片且以用户名为图片名称存储。
import requests import os with open("test.txt", mode="r", encoding="utf-8") as read_f: read_f.readline() for line in read_f: user_id, name, url = line.strip().split(",") res = requests.get( url=url, headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } ) if not os.path.exists("images"): #判断文件夹是否存在,如果不存在,就创建 os.makedirs("images") with open("images/{}.png".format(name), mode="wb") as write_f: write_f.write(res.content)
6.ini格式文件
ini文件是Initialization File的缩写,平时用于存储软件的的配置文件。例如:MySQL数据库的配置文件。
[mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-bin=py-mysql-bin character-set-server=utf8 collation-server=utf8_general_ci log-error=/var/log/mysqld.log # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 [mysqld_safe] log-error=/var/log/mariadb/mariadb.log pid-file=/var/run/mariadb/mariadb.pid [client] default-character-set=utf8
这种格式是可以直接使用open来出来,考虑到自己处理比较麻烦,所以Python为我们提供了更为方便的方式。configparser(配置解析器)
import configparser # 获取可以处理ini文件的对象 config = configparser.ConfigParser() # 打开文件 config.read("test.ini", encoding="UTF-8") # 1.获取所有节点 sections()(章节) result = config.sections() print(result) # 2.获取节点下的键值 items(): 返回一个列表,列表中存储键值对,键值对以元组的形式存储 result = config.items("mysqld") print(result) for x, y in config.items("mysqld_safe"): # 可以使用这种方式将键值对取出 print(x, y) # 3.获取节点下,键对应的值 get() result = config.get("mysqld", "datadir") print(result) # 4.检测节点是否存在 has_section() result = config.has_section("mysqld") print(result) # 5.增加一个节点 add_section():如果节点已经存在,那么会报错 config.add_section("root") # 6.给节点设置键值 set():节点必须存在,可创建键值对,也可修改值 config.set("root", "niha", "456") config.set("root", "niha1", "456") # 7.删除节点 remove_section() :会删除节点下的所有键值对 config.remove_section("root") # 8.删除节点下的键值对 remove_option(节点,键) config.remove_option("root", "niha") # 4-8操作虽然给文件更改了数据,但是数据还在缓冲区中,所以在修改了文件后,需要使用write写入 config.write(open('test.ini', 'w'))
5.拓展:eval函数
eval函数功能非常强大——将字符串当成有效的表达式来求值,并返回计算结果
# -*- coding: gbk -*- #基本的数学计算 print(eval("1+1")) #字符串重复 print(eval("'*'*30")) #将字符串转变成列表 print(type(eval("[1,2,3,4,5]"))) #将字符串转变成元组 print(type(eval("(1,2,3,4,5)"))) #将字符串转变成字典 print(type(eval("{'name':'苹果','age':18}")))
案例——计算器
input_str = input("输入算数题") print(eval(input_str)) ''' 运行: 输入算数题1+1 2 '''
注意:在开发的时候千万不要使用 eval 直接转换 input 的结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号