

七分钟理解什么是 KMP 算法
本文是介绍 什么是 BF算法、KMP算法、BM算法 三部曲之一。
KMP算法 内部涉及到的数学原理与知识太多,本文只会对 KMP算法 的运行过程、 部分匹配表 、next数组 进行介绍,如果理解了这三点再去阅读其它有关 KMP算法 的文章肯定能有个清晰的认识。
以下的文字描述请结合视频动画来阅读~
视频地址:https://www.bilibili.com/video/av60334201/
定义
Knuth-Morris-Pratt 字符串查找算法,简称为 KMP算法,常用于在一个文本串 S 内查找一个模式串 P 的出现位置。
这个算法由 Donald Knuth、Vaughan Pratt、James H. Morris 三人于 1977 年联合发表,故取这 3 人的姓氏命名此算法。
是不是感觉 Donald Knuth 这个名字很眼熟?没错,在前面 这或许是讲解 Knuth 洗牌算法最好的文章 一文中也出现了他!
下面直接给出 KMP算法 的操作流程:
- 假设现在文本串 S 匹配到 i 位置,模式串 P 匹配到 j 位置
- 如果 j = -1,或者当前字符匹配成功(即 S[i] == P[j] ),都令 i++,j++,继续匹配下一个字符;
如果 j != -1,且当前字符匹配失败(即 S[i] != P[j] ),则令 i 不变,j = next[j]。此举意味着失配时,模式串 P相对于文本串 S 向右移动了 j - next [j] 位 - 换言之,将模式串 P 失配位置的 next 数组的值对应的模式串 P 的索引位置移动到失配处
看不明白?直接看动画!
运行过程
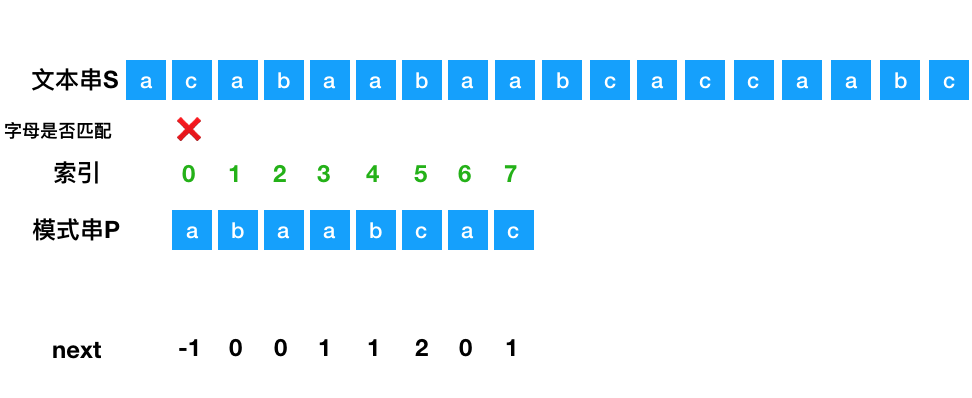
以下图文本串 S 与模式串 P 为例:
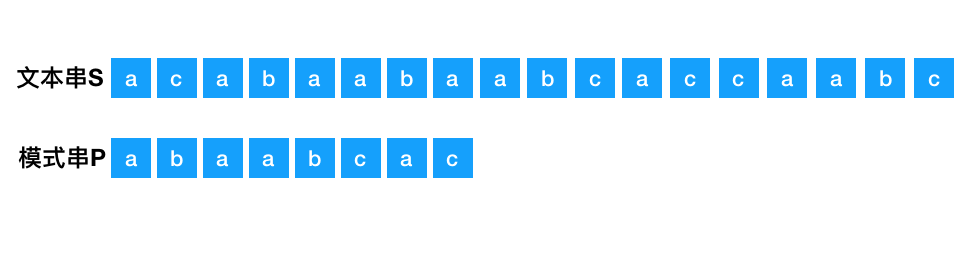
首先,列出模式串 P 的所有子串:
| a | |||||||
|---|---|---|---|---|---|---|---|
| a | b | ||||||
| a | b | a | |||||
| a | b | a | a | ||||
| a | b | a | a | b | |||
| a | b | a | a | b | c | ||
| a | b | a | a | b | c | a | |
| a | b | a | a | b | c | a | c |
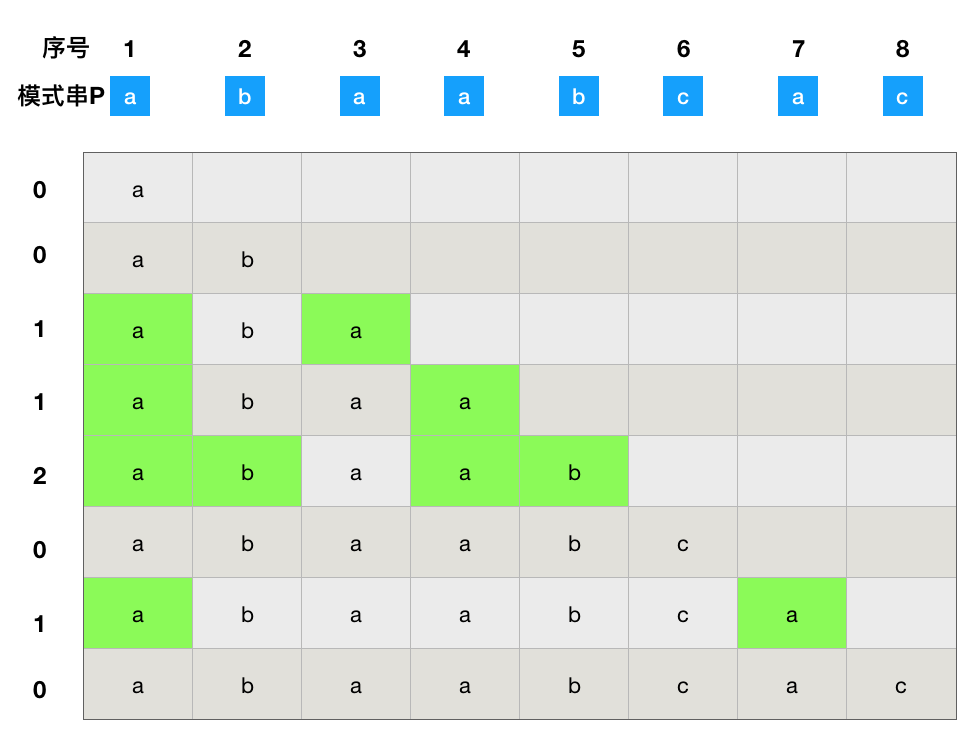
然后,求得每一个子串的所有前缀与后缀。
前缀 指除了最后一个字符以外,一个字符串的全部头部组合;后缀 指除了第一个字符以外,一个字符串的全部尾部组合。
以第五列为例进行演示。
前缀为
| a | |||
|---|---|---|---|
| a | b | ||
| a | b | a | |
| a | b | a |
后缀为
| b | |||
|---|---|---|---|
| a | b | ||
| a | A | b | |
| b | a | a | b |
因此,它的前缀后缀的公共元素的最大长度为 2。
求得原模式串 P 的子串对应的各个前缀后缀的公共元素的 最大长度表 下图。
根据最大长度表 去求 next 数组:next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。
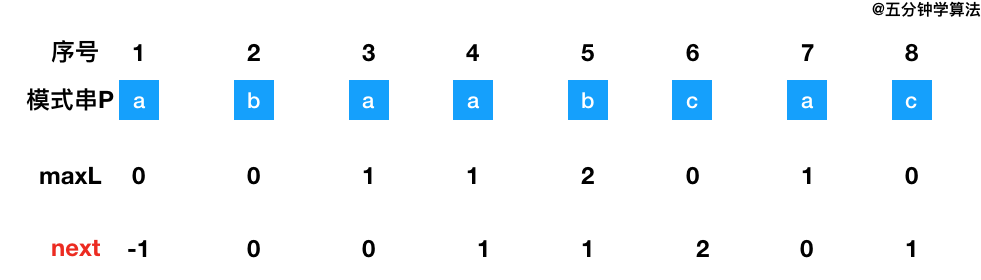
好了,获取了 next 数组 后,KMP 算法 的操作就很清晰了。
将模式串 P 与文本串 S 的字母一个个进行匹配,当失配的时候,模式串向右移动。
怎么移动?
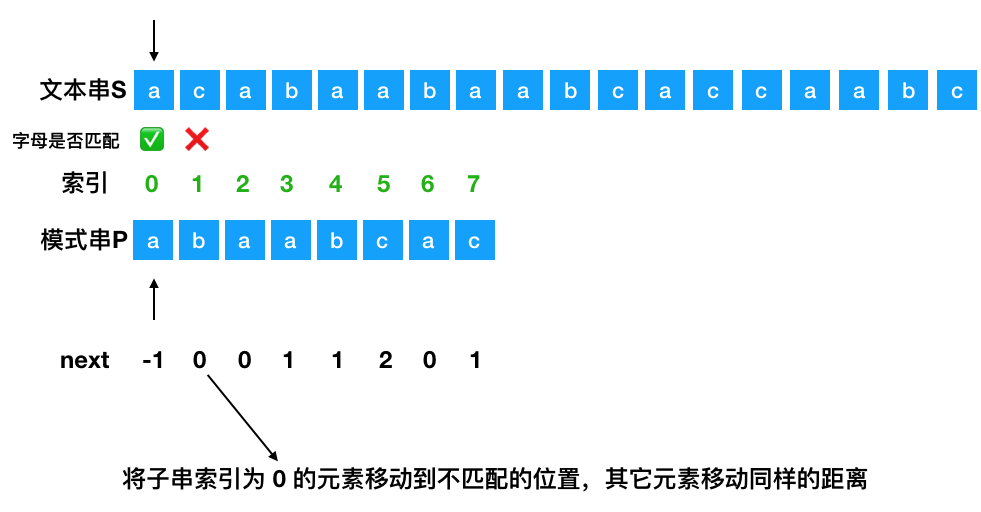
比如模式串的 b 与文本串的 c 失配了,找出失配处模式串的 next数组 里面对应的值,这里为 0,然后将索引为 0 的位置移动到失配处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号