【Fitz】Rust 泛型和特征
说明:本文主要是Rust语言圣经相关章节的学习笔记,基本与其内容相同。泛型和 Trait 是 Rust 中非常重要的内容,原文内容深入浅出,强烈推荐阅读原文。
泛型 Generics
编程中常见的需求是:用同一功能的函数处理不同类型的数据。在不支持泛型的编程语言中,通常需要为每一种类型编写一个函数。而泛型的存在,就可以为开发者提供编程的便利,减少代码的臃肿,同时可以极大地丰富语言本身的表达能力。即可以用一个函数,代替很多个完成同样功能但处理不同类型数据的函数。
泛型详解
在 Rust 中,泛型参数的名称可以任意起,处于惯例都是用 T(type 的首字母)作为首选,这个名称越短越好。
使用泛型参数,必须在使用前对其进行声明:
let largest<T> (list: &[T]) -> T {
largest<T> 首先对泛型参数 T 进行了声明,然后才在函数参数中进行使用该泛型参数 list: &[T]。
因此这个函数的定义可以理解为:函数有泛型参数 T,函数的参数是 list,其类型是元素为 T 的数组切片,函数返回值类型也是 T。
函数体中的实现过程中,需要对 T 类型的数据进行比较,此时需要我们给 T 添加一个类型限制:使用 std::cmp::PartialOrd 特征(Trait)对 T 进行限制,该 trait 的目的就是让类型实现可比较的功能。
结构体中使用泛型
结构体中的字段类型也可以用泛型来定义,如:
struct Point<T> {
x: T,
y: T,
}
需要注意:在使用泛型参数之前必须进行声明 Point<T>,然后才可以在结构体的字段类型中使用 T 来替代具体的类型,同时 x 和 y 是相同的类型。
如果想要让 x 和 y 具有不同的类型,需要使用不同的泛型参数:
struct Point<T,U> {
x: T,
y: U,
}
枚举中使用泛型
在枚举中也可以使用泛型。Rust 中最常见的枚举类型是 Option 和 Result:
enum Option<T> {
Some(T),
None,
}
enum Result<T, E> {
Ok(T),
Err(E),
}
Option 和 Result 都常用于函数的返回值,Option 用于值的存在与否,Result 主要关注值的正确性。
如果函数正常运行,则最后返回一个 Ok(T),T 是函数具体的返回值类型,如果函数异常运行,则返回一个 Err(E),E 是错误类型。例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File),因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error),E 对应的就是 std::io::Error 类型。
方法中使用泛型
在方法上也可以使用泛型,在使用泛型参数前,依然需要提前声明:impl<T>,只有提前声明了,才能在 Point<T> 中使用,这样 Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
需要注意:方法声明中的 Point<T> 不是泛型声明,而是一个完整的结构体类型,因为定义的结构体就是 Point<T> 而不是 Point。
除了结构体中的泛型参数,还能在该结构体的方法中定义额外的泛型参数,就跟泛型函数一样:
struct Point<T, U> {
x: T,
y: U,
}
impl<T, U> Point<T, U> {
fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> {
Point {
x: self.x,
y: other.y,
}
}
}
该例子中,T, U 是定义在结构体 Point 上的泛型参数,V, W 是定义在方法上的泛型参数,它们并不冲突,可以理解为,一个是结构体泛型,一个是函数泛型。
为具体的泛型类型实现方法
对于 Point<T> 类型,不仅能定义基于 T 的方法,还能针对特定的具体类型进行方法定义。这意味着该特定类型会有一个定义的方法,而其他的 T 不是该类型的 Point<T> 实例则没有定义此方法。这样就能针对特定的泛型类型实现某个特定的方法,对于其它泛型类型则没有定义该方法。
const 泛型(Rust 1.51 版本引入的重要特性)
之前的泛型中,可以抽象为一句话:针对类型实现的泛型,所有的泛型都是为了抽象不同的类型。
同一类型不同长度的数组也是不同的数组类型,如 [i32, 2] 和 [i32, 3] 就是不同的数组类型。可以使用数组切片(引用)和泛型来解决处理任何类型数组的问题,例如:
fn display_array<T: std::fmt::Debug>(arr: &[T]) {
println!("{:?}", arr);
}
但是使用上面的方法,不适用于引用不好用或不能用的场景。这时就可以用 const 泛型,也就是针对值的泛型,来处理数组长度的问题:
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) {
println!("{:?}", arr);
}
代码中定义了一个类型为 [T; N] 的数组,其中 T 是一个基于类型的泛型参数,N 是一个基于值的泛型参数,此处替代的是数组的长度。
N 就是 const 泛型,定义的语法是 const N: usize,表示 const 泛型 N,它基于的值类型是 usize。在泛型参数之前,Rust 完全不适合复杂矩阵的运算,自从有了 const 泛型,一切即将改变。
const 泛型表达式
假设某段代码需要在内存很小的平台上工作,因此需要限制函数参数占用的内存大小,此时就可以使用 const 泛型表达式来实现。
泛型的性能
Rust 中的泛型是零成本抽象,因此在使用泛型时,完全不用担心性能上的问题。另一方面,我们失去的是编译速度和增大了最终生成文件的大小,因为 Rust 在编译期为泛型对应的多个类型都生成了各自的代码。
Rust 通过在编译时进行泛型代码的 单态化 ( monomorphization ) 来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。编译器所做的工作正好与我们创建泛型函数的步骤相反,编译器寻找所有泛型代码被调用的位置并针对具体类型生成代码。因此使用泛型时没有运行时开销,单态化过程正是 Rust 泛型在运行时及其高效的原因。
特征 Trait
Trait 用于把不同类型的行为抽象出来,这跟其他语言中的接口很类似。
之前也许用到过 #[derive(Debug)],它在定义的类型(struct)上自动派生 Debug 的 trait,使得我们可以使用 println!("{:?}", x) 来打印这个类型。
Trait 定义了一个可以被共享的行为,只要实现了 trait,就能使用该行为。
定义 trait
如果不同的类型具有相同的行为,那么就可以定义一个 trait,然后为这些类型实现该 trait。定义 trait 就是把一些方法组合在一起,目的是定义一个实现某些目标所必需的行为和集合。
例如我们希望为文章 Post 和微博 Weibo 两种内容实现一个总结的行为,这个行为就是共享的,因此可以用 trait 来定义:
pub trait Summary {
fn summarize(&self) -> String;
}
trait 关键字用来声明 trait,Summary 是 trait 名,大括号中定义了该 trait 的所有方法。Trait 只是定义行为看起来是什么样的,而不定义行为具体是怎么样的。因此代码中只定义了 trait 方法的签名,而不进行实现。
每一个实现这个 trait 的类型都需要具体实现该 trait 的相应的方法。编译器也会确保任何实现 Summary 特征的类型都拥有与这个签名的定义完全一致的 summarize 方法。
为类型实现 trait
Trait 只定义行为看起来是什么样的,因此需要为类型实现具体的 trait,定义行为具体是什么样的。示例代码:
pub trait Summary { //定义trait
fn summarize(&self) -> String;
}
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
impl Summary for Post { //实现trait
fn summarize(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo { //实现trait
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
实现 trait 的语法与为结构体、枚举实现方法很像:impl Summary for Post,然后在 impl 的花括号中实现该 trait 的具体方法。然后就可以在这个类型上调用 trait 的方法。
trait 定义与实现的位置(孤儿原则)
关于特征实现与定义的位置,有一条非常重要的原则: 如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的! 。例如可以为 Post 类型实现 Display trait 因为 Post 类型定义是在当前作用域中,也可以为 String 类型实现 Summary trait 因为 Summary 定义在当前作用域中。
这个规则可以确保其他人编写的代码不会破坏你的代码,也确保了你不会莫名其妙破坏别人的代码。
默认实现
可以在 trait 中定义具有默认实现的方法,其他类型就无需再实现该方法,或者也可以选择重载该方法:
pub trait Summary {
fn summarize(&self) -> String { //默认实现
String::from("(Read more...)")
}
}
impl Summary for Post {} //使用该方法的默认实现
impl Summary for Weibo { //重载该方法
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
默认实现允许调用相同 trait 中的其他方法,哪怕这些方法没有默认实现。因此,trait 可以提供很多有用的功能而只需要实现指定的一小部分功能。例如,我们可以定义 Summary trait,使其具有一个需要实现的 summarize_author 方法,然后定义一个 summarize 方法,此方法的默认实现调用 summarize_author 方法。这时,为了使用 Summary,只需要实现 summarize_author 方法即可。
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
使用 trait 作为函数参数
Trait 可以用作函数参数,这里先定义一个函数,使用 trait 用作函数参数:
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
参数的意思就是 实现了 Summary trait 的 item 参数。可以使用任何实现了 Summary trait 的类型作为该函数的参数,同时在函数体内,还可以调用该 trait 的方法。
Trait 约束 (trait bound)
上面使用的 impl Trait 实际上只是一个语法糖,其完整书写形式如下,形如 T: Summary 被称为特征约束。
pub fn notify<T: Summary> (item: &T) {
println!("Breaking news! {}", item.summarize());
}
对于比较复杂的使用场景,特征约束可以让我们拥有更大的灵活性和语法表现能力,例如一个函数接受两个 impl Summary 的参数:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {} //↓
pub fn notify<T: Summary>(item1: &T, item2: &T) {} //泛型类型T说明item1和item2必须拥有同样的类型,同时说明T必须实现 Summary trait
多重约束
除了单个约束条件,还可以指定多个约束条件,例如让参数实现多个 trait:
pub fn notify(item: &(impl Summary + Display)) {} //语法糖形式
pub fn notify<T: Summary + Display> (item: &T) {} //完整形式
where 约束
当特征约束变得很多时,函数的签名就会变得很复杂,这时如果使用 where 可以对其做一些形式上的改进:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {
//使用where
fn some_function<T, U>(t: &T, u: &U) -> i32
where T: Display + Clone,
U: Clone + Debug
{
使用特征约束有条件地实现方法或特征
特征约束,可以让我们在指定类型+指定特征的条件下实现方法,例如:
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
该方法只有 T 同时实现了 Display + PartialOrd 的 Pair<T> 才可以拥有此方法。该函数可读性会更好,因为泛型参数、参数、返回值都在一起,可以快速的阅读,同时每个泛型参数的特征也在新的代码行中通过特征约束进行了约束。
也可以有条件地实现 trait,例如标准库为任何实现了 Display trait 的类型实现了 ToString trait,就可以对任何实现了 Display trait 的类型调用由 ToString 定义的 to_string 方法,将其转换为 String 值。
impl<T: Display> ToString for T {
// --snip--
}
函数返回中的 impl Trait
可以通过 impl Trait 来说明一个函数返回了一个类型,该类型实现了某个 trait:
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
Post { ... } //此处不能返回两个不同的类型
} else {
Weibo { ... } //此处不能返回两个不同的类型
}
}
该函数可以使用任意的实现了 Summary trait 的对象作为返回值。这种 impl Trait 形式的返回值在一种场景下非常非常有用,就是返回的真实类型非常复杂,不知道怎么声明时,就可以用 impl Trait 的方式简单返回。但这种返回值只能有一个具体的类型,上面的代码示例就不行,因为返回了两个不同的类型 Post 和 Weibo。如果想要实现返回不同的类型,需要使用特征对象。
通过 derive 派生 trait
常见到的形如 #[derive(Debug)] 的代码已经出现了多次,这是一种 trait 派生语法,被 derive 标记的对象会自动实现对应的默认特征代码,继承相应的功能。
derive 派生出来的是 Rust 默认给我们提供的特征,在开发过程中极大的简化了自己手动实现相应特征的需求,当然,如果你有特殊的需求,还可以自己手动重载该实现。
调用方法需要引入 trait
如果要使用一个 trait 的方法,那么需要引入该 trait 到当前的作用域中。
同时 Rust 也提供了一个便利的办法:即把最常用的标准库中的 trait 通过 std::prelude 模块提前引入到当前作用域中。
几个综合例子
为自定义类型实现 + 操作
下面代码示例,实现了为自定义类型实现 + 操作:
use std::ops::Add;
// 为Point结构体派生Debug特征,用于格式化输出
#[derive(Debug)]
struct Point<T: Add<T, Output = T>> { //限制类型T必须实现了Add特征,否则无法进行+操作。
x: T,
y: T,
}
impl<T: Add<T, Output = T>> Add for Point<T> {
type Output = Point<T>;
fn add(self, p: Point<T>) -> Point<T> {
Point{
x: self.x + p.x,
y: self.y + p.y,
}
}
}
fn add<T: Add<T, Output=T>>(a:T, b:T) -> T {
a + b
}
fn main() {
let p1 = Point{x: 1.1f32, y: 1.1f32};
let p2 = Point{x: 2.1f32, y: 2.1f32};
println!("{:?}", add(p1, p2));
let p3 = Point{x: 1i32, y: 1i32};
let p4 = Point{x: 2i32, y: 2i32};
println!("{:?}", add(p3, p4));
}
自定义类型的打印输出
在开发过程中,往往只要使用 #[derive(Debug)] 对我们的自定义类型进行标注,即可实现打印输出的功能。但是在实际项目中,往往需要对我们的自定义类型进行自定义的格式化输出,以让用户更好的阅读理解我们的类型,此时就要为自定义类型实现 std::fmt::Display trait:
#![allow(dead_code)]
use std::fmt;
use std::fmt::{Display};
#[derive(Debug,PartialEq)]
enum FileState {
Open,
Closed,
}
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
state: FileState,
}
impl Display for FileState {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match *self {
FileState::Open => write!(f, "OPEN"),
FileState::Closed => write!(f, "CLOSED"),
}
}
}
impl Display for File {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "<{} ({})>",
self.name, self.state)
}
}
impl File {
fn new(name: &str) -> File {
File {
name: String::from(name),
data: Vec::new(),
state: FileState::Closed,
}
}
}
fn main() {
let f6 = File::new("f6.txt");
//...
println!("{:?}", f6);
println!("{}", f6);
}
Trait 对象
上面给出的代码示例中,在用 impl Trait 作为返回值类型时并不支持多种不同的类型返回。
假设现在在做一款游戏,需要将多个对象渲染在屏幕上,这些对象属于不同的类型存储在列表中,渲染的时候,需要循环该列表并顺序渲染每个对象。在编写 UI 库时,我们无法知道所有的 UI 对象类型,只知道:
- UI 对象的类型不同
- 需要一个统一的类型来处理这些对象,无论是作为函数参数还是作为列表中的一员
- 需要对每一个对象调用
draw方法。
特征对象定义
为了解决上面的问题,Rust 引入了 —— 特征对象。
先为 UI 组件定义一个 trait:
pub trait Draw {
fn draw(&self);
}
只要组件实现了 Draw 的 trait,就能调用 draw 方法来进行渲染。假设有一个 Button 和 SelectBox 组件实现了 Draw trait。此时还需要一个动态数组来存储这些 UI 对象:
pub struct Screen {
pub components: Vec<?>,
}
代码中的 ? 的意思是:我们应该填入什么类型。由于 Button 和 SelectBox 都实现了 Draw trait,那么可以把 Draw trait 的对象作为类型填入到数组中。
特征对象指向了实现了 Draw trait 类型的实例,也就是指向了 Button 或者 SelectBox 的实例,这种映射关系是存储在一张表中,可以在运行时通过特征对象找到具体调用的类型方法。
可以通过 & 引用或者 Box<T> 智能指针的方式来创建特征对象:
trait Draw {
fn draw(&self) -> String;
}
impl Draw for u8 {
fn draw(&self) -> String {
format!("u8: {}", *self)
}
}
impl Draw for f64 {
fn draw(&self) -> String {
format!("f64: {}", *self)
}
}
fn draw1(x: Box<dyn Draw>) {
x.draw();
}
fn draw2(x: &dyn Draw) {
x.draw();
}
fn main() {
let x = 1.1f64;
// do_something(&x);
let y = 8u8;
draw1(Box::new(x));
draw1(Box::new(y));
draw2(&x);
draw2(&y);
}
上面代码示例中:
draw1函数的参数是Box<dyn Draw>形式的特征对象,该特征对象是通过Box::new(x)的方式创建的draw2函数的参数是&dyn Draw形式的特征对象,该特征对象是通过&x的方式创建的dyn关键字只用在特征对象的类型声明上,在创建时无需使用dyn
对于前面的 UI 组件代码,首先来实现 Screen:
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
其中存储了一个动态数组,里面元素的类型是 Draw 特征对象:Box<dyn Draw> ,任何实现了 Draw 特征的类型都可以存放在里面。然后再为 Screen 定义 run 方法,用于将列表中的 UI 组件渲染在屏幕上:
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
至此就完成了之前的目标:即在列表中存储多种不同类型的实例,然后将它们使用同一个方法逐一渲染在屏幕上。
如果通过泛型可以这么实现:
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where T: Draw {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
这种写法限制了 Screen 实例的 Vec<T> 中的每个元素必须是 Button 类型或者全是 SelectBox 类型。如果只需要同质(相同类型)集合,更倾向于这种写法,即使用泛型和特征约束,因为实现更清晰,且性能更好(特征对象需要在运行时从 vtable 动态查找需要调用的方法)。
在动态类型语言中,有一个很重要的概念:鸭子类型(duck typing),简单来说,就是只关心值长啥样,而不关心它实际是什么。当一个东西走起来像鸭子叫起来像鸭子,那么它就是一只鸭子,就算它实际上是一个奥特曼,也不重要,我们就当它是鸭子。
代码示例中定义的 Screen 在 run 的时候,我们并不需要知道各个组件的具体类型是什么。它也不检查组件到底是 Button 还是 SelectBox 的实例,只要它实现了 Draw 特征,就能通过 Box::new 包装成 Box<dyn Draw> 特征对象,然后被渲染在屏幕上。
使用特征对象和 Rust 类型系统来进行类似鸭子类型操作的优势是,无需在运行时检查一个值是否实现了特定方法或者担心在调用时因为值没有实现方法而产生错误。如果值没有实现特征对象所需的特征, 那么 Rust 根本就不会编译这些代码。
dyn 不能单独作为特征对象的定义,原因是特征对象可以是任意实现了某个特征的类型,编译期在编译期不知道该类型的大小,不同的类型大小是不同的。而 &dyn 和 Box<dyn> 在编译期都是已知大小,所以可以用作特征对象的定义。
fn draw2(x: dyn Draw) {
x.draw();
}
特征对象的动态分发
先来说一下泛型,泛型是在编译期完成处理的:编译期会为每一个泛型参数对应的具体类型生成一份代码,这种方式是静态分发(static dispatch),因为在编译期完成,对运行期性能没有任何影响。
与静态分发相对应的是动态分发(dynamic dispatch),这种情况下,直到运行时,才能确定需要调用什么方法。前面代码中的关键字 dyn 正是在强调“动态”的特性。
当使用特征对象时,Rust 必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法。动态分发也阻止编译器有选择的内联方法代码,这会相应的禁用一些优化。
下图解释了静态分发 Box<T> 和动态分发 Box<dyn Trait> 的区别:
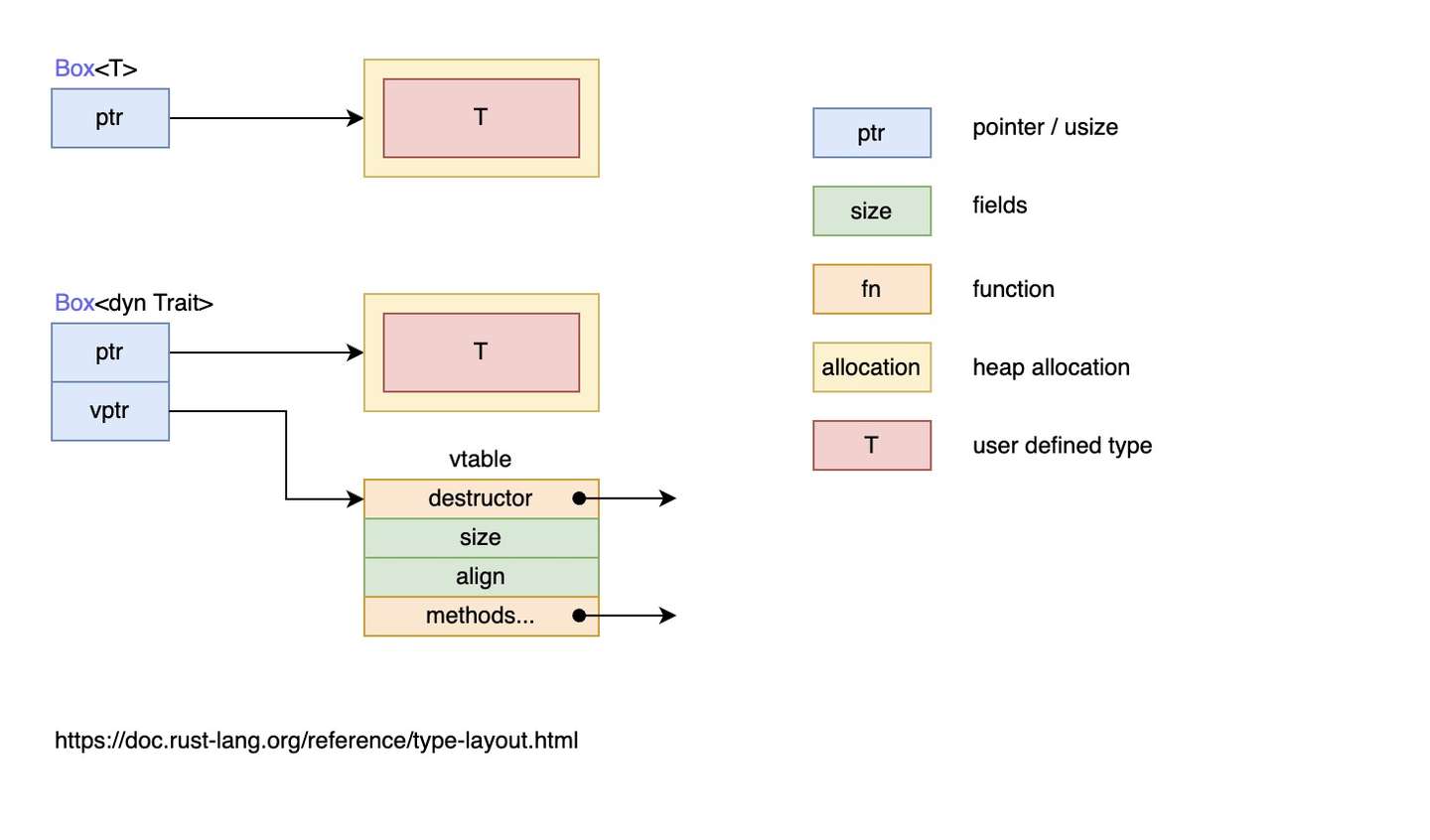
总结一下以上内容:
-
特征对象大小不固定 :这是因为,对于特征
Draw,类型Button可以实现特征Draw,类型SelectBox也可以实现特征Draw,因此特征没有固定大小 -
几乎总是使用特征对象的引用方式 ,如
&dyn Draw、Box<dyn Draw>- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
ptr和vptr),因此占用两个指针大小 - 一个指针
ptr指向实现了特征Draw的具体类型的实例,也就是当作特征Draw来用的类型的实例,比如类型Button的实例、类型SelectBox的实例 - 另一个指针
vptr指向一个虚表vtable,vtable中保存了类型Button或类型SelectBox的实例对于可以调用的实现于特征Draw的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了特征Draw的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征Draw来使用时(此时,它们全都看作是特征Draw类型的实例),有必要区分这些实例各自有哪些方法可调用
- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
简而言之,当类型 Button 实现了特征 Draw 时,类型 Button 的实例对象 btn 可以当作特征 Draw 的特征对象类型来使用,btn 中保存了作为特征对象的数据指针(指向类型 Button 的实例数据)和行为指针(指向 vtable)。
一定要注意,此时的 btn 是 Draw 的特征对象的实例,而不再是具体类型 Button 的实例,而且 btn 的 vtable 只包含了实现自特征 Draw 的那些方法(比如 draw),因此 btn 只能调用实现于特征 Draw 的 draw 方法,而不能调用类型 Button 本身实现的方法和类型 Button 实现于其他特征的方法。也就是说,btn 是哪个特征对象的实例,它的 vtable 中就包含了该特征的方法。
Self 与 self
在 Rust 中,有两个self,一个(self)指代当前的实例对象,一个(Self)指代特征或者方法类型的别名。
fn draw(&self) -> Self {
return self.clone()
}
特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下属性时,它的对象才是安全的:
- 方法的返回类型不能是
Self - 方法没有任何泛型参数
对象安全对于特征对象是必须的,因为一旦有了特征对象,就不再需要知道实现该特征的具体类型是什么了。如果特征方法返回了具体的 Self 类型,但是特征对象忘记了其真正的类型,那这个 Self 就非常尴尬,因为没人知道它是谁了。但是对于泛型类型参数来说,当使用特征时其会放入具体的类型参数:此具体类型变成了实现该特征的类型的一部分。而当使用特征对象时其具体类型被抹去了,故而无从得知放入泛型参数类型到底是什么。例如上面代码中使用的 clone 就是错误的,因为标准库中的 Clone trait 不符合对象安全的要求:
pub trait Clone {
fn clone(&self) -> Self;
}
深入了解 Trait
一些不常用但是该了解的 trait 特性。
关联类型
首先说明,方法中的关联函数与关联类型没有任何交集。
关联类型是在 trait 定义的语句块中,申明一个自定义类型,这样就可以在 trait 的方法签名中使用该类型。如标准库中的迭代器 trait Iterator,它有一个 Item 关联类型,用于替代遍历的值的类型:
pub trait Iterator {
type Item; //不一定都取该名,还可以用 type A; type B; 等等
fn next(&mut self) -> Option<Self::Item>;
}
Self 用来指代当前调用者的具体类型,Self::Item 就用来指代该类型实现中定义的 Item 类型:
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<self::Item> {
// ...
}
}
既然关联类型是用来替代值的类型,那么为什么不使用泛型呢?因为使用关联类型可以让代码可读性更高,而使用了泛型之后,在所有地方都需要写 Iterator<Item>,即需要增加泛型的声明。当类型定义复杂时,使用关联类型可以极大增加可读性。
默认泛型类型参数
当使用泛型类型参数时,可以为其指定一个默认的具体类型,例如标准库中的 std::ops::Add trait:
trait Add<RHS=Self> {
type Output;
fn add(self, rhs: RHS) -> Self::Output;
}
该 trait 有一个泛型参数 RHS,这里给 RHS 一个默认值,也就是当用户不指定 RHS 时,默认使用两个同样类型的值进行相加,然后返回一个关联类型 Output。
可以为其他类型的结构体实现 add 方法,为该类型结构体提供 + 的能力,也就是运算符重载。但 Rust 并不支持创建自定义的运算符,也无法为所有运算符进行重载,只有定义在 std::ops 中的运算符才能进行重载。
如果在为类型实现 Add trait 时使用 impl Add for Struct { } 则是使用默认类型,如果在为类型实现 trait 时使用 impl Add<SOME_TYPE> for Struct { } 则是使用了指定的类型。
默认类型参数主要用于两个方面:
- 减少实现的样板代码
- 扩展类型但是无需大幅修改现有的代码
对于第二点,如果在一个复杂类型的基础上,新引入一个泛型参数,可能需要修改很多地方,但是如果新引入的泛型参数有了默认类型,情况就会好很多,添加泛型参数后,使用这个类型的代码需要逐个在类型提示部分添加泛型参数,就很麻烦;但是有了默认参数(且默认参数取之前的实现里假设的值的情况下)之后,原有的使用这个类型的代码就不需要做改动了。
调用同名的方法
不同 trait 拥有同名方法是很正常的事情,另外在类型上也可能有同名的方法。
优先调用类型上的方法
当调用某个类型实例的方法时,编译器默认优先调用该类型中定义的方法。例如:
let person = Human;
person.fly();
调用 trait 上的方法
为了调用 trait 的方法,需要使用显式调用的语法:
Pilot::fly(&person); // 调用Pilot特征上的方法
Wizard::fly(&person); // 调用Wizard特征上的方法
person.fly(); // 调用Human类型自身的方法
fly 方法的参数是 self,显式调用时,编译器就可以根据调用的类型(self 的类型)决定具体调用哪个方法。
但如果方法没有 self 参数,就需要使用完全限定语法。
完全限定语法
完全限定语法是调用函数最为明确的方式,完全限定语法定义为:
<Type as Trait>::function(receiver_if_method, next_arg, ...);
as 关键字向 Rust 编译器提供了类型注解,最终会调用 impl Trait for Type 中的方法。
完全限定语法可以用于任何函数或方法调用,那么我们为何很少用到这个语法?原因是 Rust 编译器能根据上下文自动推导出调用的路径,因此大多数时候,我们都无需使用完全限定语法。只有当存在多个同名函数或方法,且 Rust 无法区分出你想调用的目标函数时,该用法才能真正有用武之地。
特征定义中的特征约束
有时,我们会需要让某个 trait A 能使用另一个 trait B 的功能(另一种形式的特征约束),这种情况下,不仅要为类型实现 trait A,还要为类型实现 trait B,这就是 supertrait。
use std::fmt::Display;
trait OutlinePrint: Display {
fn outline_print(&self) {
let output = self.to_string();
// ...
}
}
例如上例中,要实现 OutlinePrint trait,首先要实现 Display trait,因为 to_string() 方法会为实现了 Display trait 的类型自动实现。
在外部类型上实现外部特征(newtype)
上面提到的孤儿原则:特征或者类型必需至少有一个是本地的,才能在此类型上定义特征。
但是有个方法可以绕过孤儿原则:使用 newtype 模式,就是为元组结构体创建新类型。该元组结构体封装有一个字段,该字段就是希望实现特征的具体类型。
该封装类型是本地的,因此我们可以为此类型实现外部的特征。newtype 不仅仅能实现以上的功能,而且它在运行时没有任何性能损耗,因为在编译期,该类型会被自动忽略。
使用 newtype 之后,访问元组结构体只能使用 self.0,如果该元素是个数组,那么要使用数组的方法就需要先取出数组再调用。对于这个问题,解决办法是为该结构体实现 Deref trait,实现该 trait 后 Rust 就会自动解引用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号