


SQL查询语句
MySQL中select的基本语法形式:
Select 属性列表from 表名[where 条件表达式1][group by 属性名1 [having 条件表达式2]]
[order by 属性名2 [asc | desc]]
先输入show databases; 查看之前创建好的tel数据库,随后使用use命令切换到tel数据库
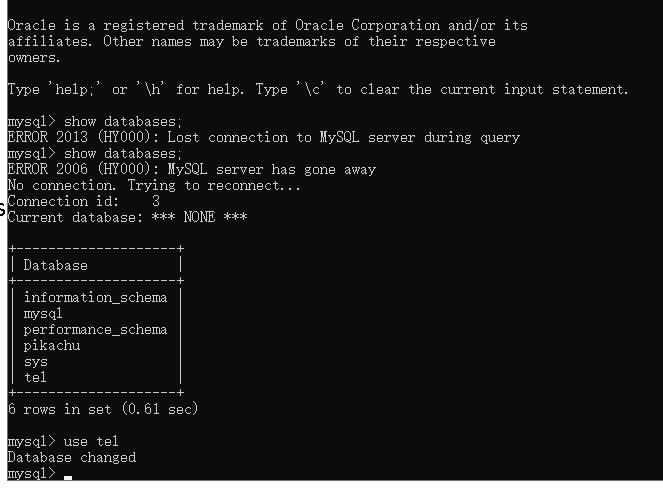
输入select * from tbox;查看表中的内容
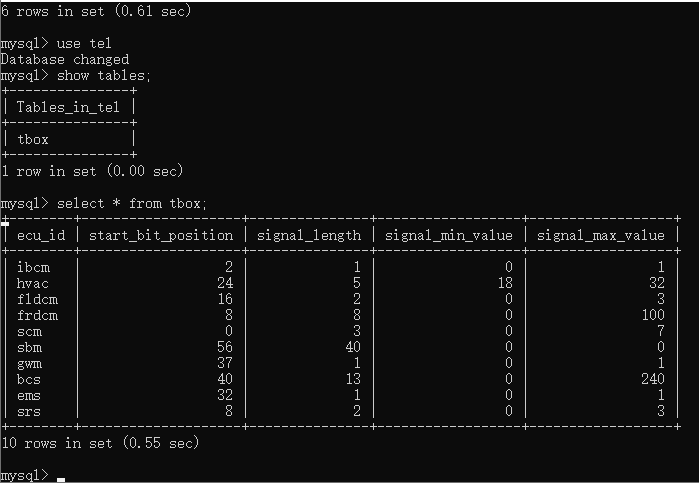
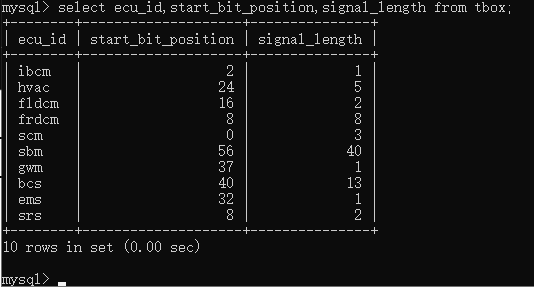
此时,如果我们要查看sbm节点的start_bit_position 和 signal_length的信息,可以使用此sql语句select ecu_id,start_bit_position,signal_length from tbox; 即可单独显示
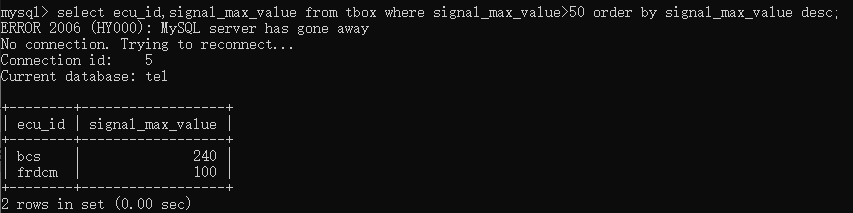
如果要查找signal_max_value 大于50 的记录并且让搜索结果按照降序排列,输入select ecu_id,signal_max_value from tbox where signal_max_value>50 order by signal_max_value desc;
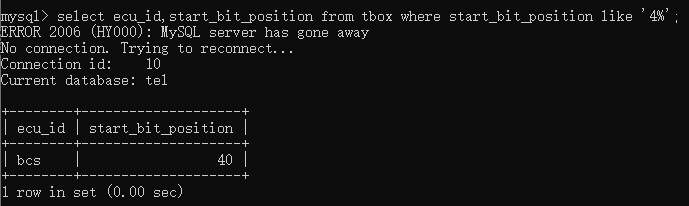
如果想筛选时,去掉重复的值,可以这样:例如,要去掉signal_min_value 的重复值,输入select distinct signal_min_value from tbox;
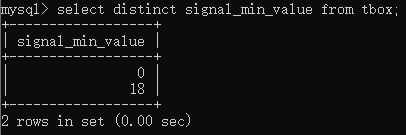
如果想查询哪一个ecu的signal_length是40,可以使用where的条件表达式,输入select ecu_id,signal_length from tbox where signal_length=40; 得到相对应的ecu是sbm。注意,此处的“=”可以被替换为like关键字,但当字符串中包含通配符时,“=”不能代替like
如果想查询某个字段的值是否在指定的整合中。如果字段的值在集合中,则满足查询条件,该记录将被查询出来;如果不在集合中,则不满足查询条件。可以使用in关键字。例如,要筛选出查询出哪些ecu的start_bit_position 的值是24和32,则可以输入select ecu_id,start_bit_position from tbox where start_bit_position in (24,32);

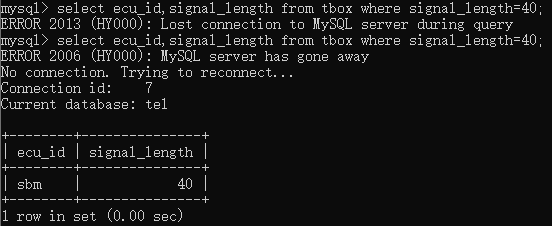
如果要判断字段的值是否在指定范围,则可以使用between关键字。例如,要判断哪些ecu的start_bit_position的值在8和34之间,则可以输入select ecu_id,start_bit_position from tbox where start_bit_position between 8 and 34;
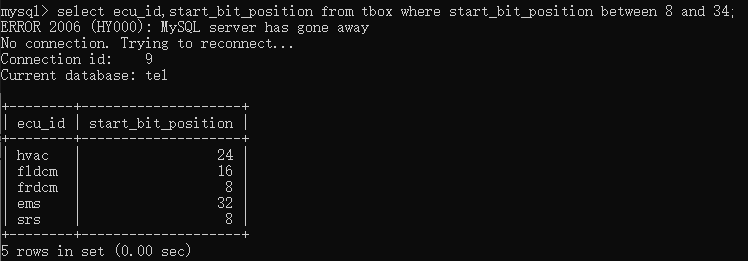
如果要用通配符的方式判断数值,则可以使用%通配符。注意,如果是要匹配单个字符,则可以用_代替% 例如,要筛选出哪些ecu的start_bit_position值是4开头的,则可以输入 select ecu_id,start_bit_position from tbox where start_bit_position like '4%';
如果要联合多个条件进行查询,例如要查询start_bit_position中以2开头和signal_max_value是1的ecu,则可以输入select ecu_id,start_bit_position,signal_max_value from tbox where signal_max_value = 1 and start_bit_position like“2%”;

如果只要满足几个查询条件中的其中一个,例如要查询start_bit_position值大于30或者signal_max_value 大于50的,则可以输入select ecu_id,start_bit_position,signal_max_value from tbox where start_bit_position>30 or signal_max_value>50;
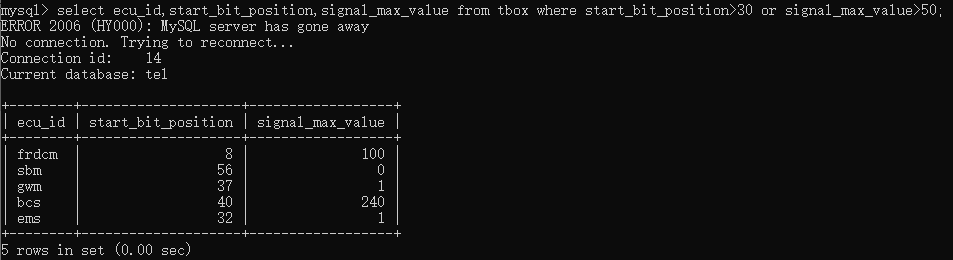
当需要同时使用and和or关键字,and的优先级要高于or,例如要查询start_bit_position值大于30和signal_max_value 大于50或者signal_length是13的,则可以输入select ecu_id,start_bit_position,signal_length,signal_max_value from tbox where start_bit_position>30 and signal_max_value>50 or signal_length=13;
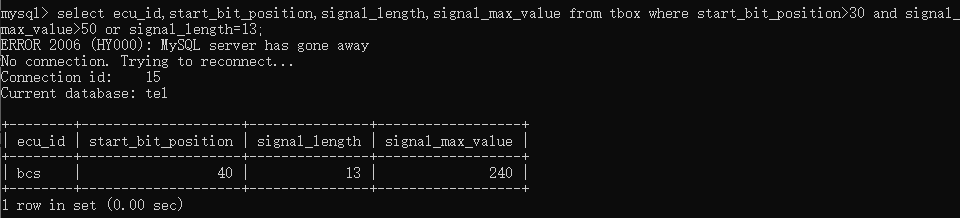
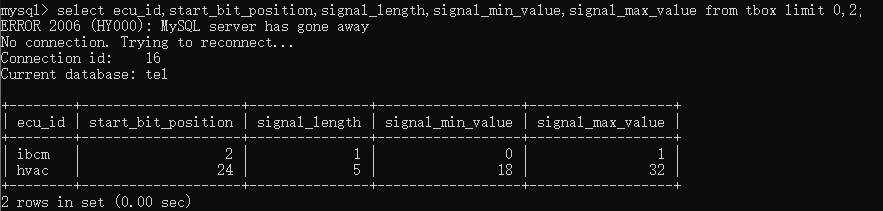
如果要限制查询结果的数量,可以使用limit关键字,例如要从查询第一行开始查询,且只查询两行,则可以输入
select ecu_id,start_bit_position,signal_length,signal_min_value,signal_max_value from tbox limit 0,2;
注意:
limit n,m
n:开始位置
m:要检索的行数
行0 :检索出来的第一行为行0,而不是行1,
因此,limit 1,1将检索出第二行而不是第一行。
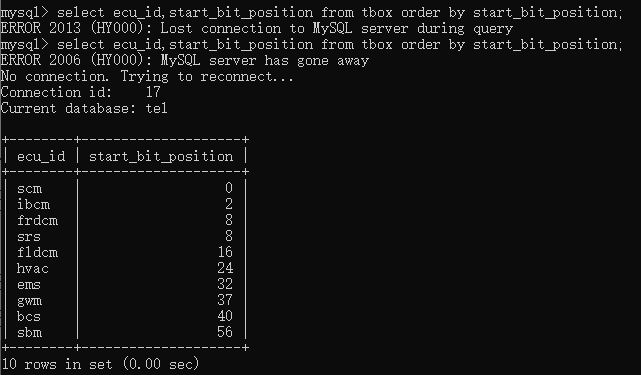
如果要对查询结果进行排序,则可以order by关键字,其中ASC:升序(默认升序)
DESC:降序。例如现在要按照start_bit_position进行升序排序,则可以输入select ecu_id,start_bit_position from tbox order by start_bit_position;
如果要进行降序排序,则可以输入select ecu_id,start_bit_position from tbox order by start_bit_position desc;
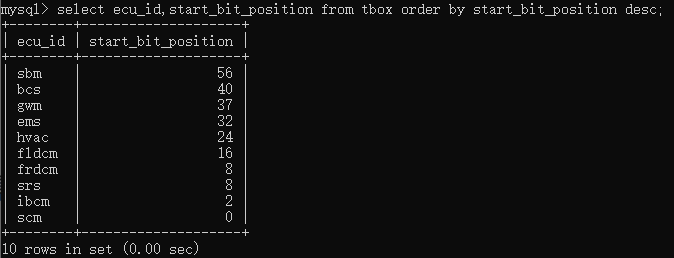
如果想找出一列中最高或者最低的值,则可以将order by 和limit关键字来联合使用。
例如如果想查询start_bit_position中对应哪个ecu的最小值,则输入select ecu_id,start_bit_position from tbox order by start_bit_position limit 1;
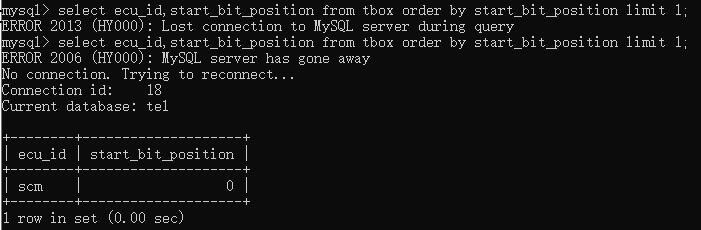
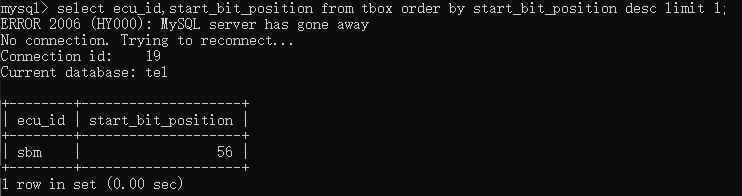
相反,要找出对应ecu的最大值,则输入select ecu_id,start_bit_position from tbox order by start_bit_position desc limit 1;
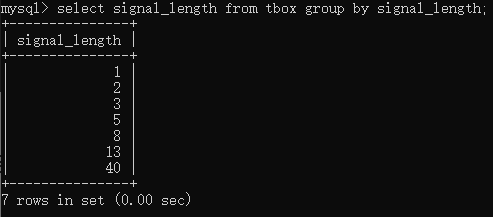
如果要分组查询,则可以使用group by 关键字。例如要按照signal_length进行分组,则可以输入select signal_length from tbox group by signal_length;
如果想分组后的结果按条件进行筛选,则可以使用having关键字,在order by关键字后门加上having关键字和等式。例如像上面的例子,输入select signal_length from tbox group by signal_length having signal_length=3;

集合函数
包括COUNT()、SUM()、AVG()、MAX()和MIN()。
当需要对表中的记录求和、求平均值、查询最大值和查询最小值等操作时,可
以使用集合函数。GROUP BY关键字通常需要与集合函数起使用。
COUNT()用来统计记录的条数;
SUM()用来计算字段的值的总和;
AVG()用来计算字段的值的平均值:
MAX() 用来查询字段的最大值;
MIN()用来查询字段的最小值。
如果要统计记录的条数,则可以使用count()关键字。例如要统计有几条数据,则可以输入select count(*) from tbox;
由结果得出,总共有十条
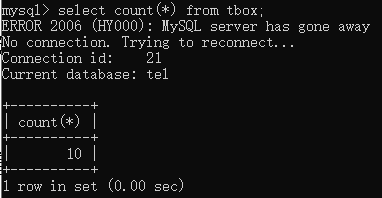
如果要计算字段值的综合,则可以使用sum()关键字。例如要统计start_bit_position的总和,则可以输入select sum(start_bit_position) from tbox;
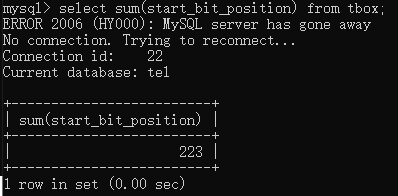
如果要计算字段值的平均值,则可以使用avg()关键字。例如要统计start_bit_position的平均值,则可以输入select avg(start_bit_position) from tbox;
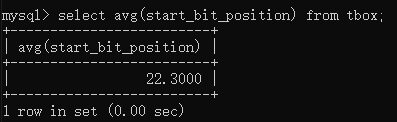
如果要计算字段值的最大值,则可以使用max()关键字。例如要统计start_bit_position的最大值,则可以输入select max(start_bit_position) from tbox;
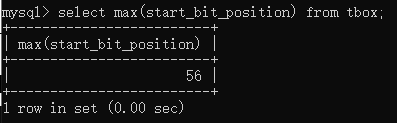
如果要计算字段值的最小值,则可以使用min()关键字。例如要统计start_bit_position的最小值,则可以输入select min(start_bit_position) from tbox;
正则表达式
是用某种模式去匹配一类字符串的一一个方式。例如,使用正则表达式可以查询
出包含A、B和C其中任一字母的字符串。正则表达式的查询能力比通配字符的查询能
力更强大,而且更加的灵活。正则表达式可以应用于非常复杂查询。
使用REGEXP关键字来匹配查询正则表达式。其基本形式如下:
属性名 REGEXP '匹配方式’
“属性名”参数表示需要查询的字段的名称;
“匹配方式” 参数表示以哪种方式来进行匹配查询。

如果要查询以特定字符或者字符串开头的记录,则可以使用^关键字。例如要统计ecu_id以b开头的ecu,则可以输入select * from tbox where ecu_id regexp ’^b’;

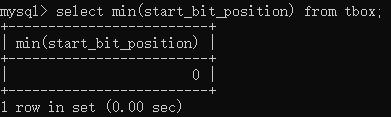
如果要查询以特定字符或者字符串结尾的记录,则可以使用$关键字。例如要统计ecu_id以m结尾的ecu,则可以输入select * from tbox where ecu_id regexp ’m$’;
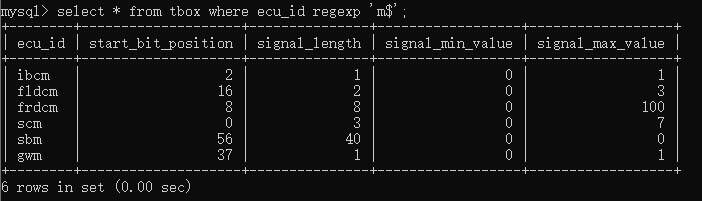
如果要查询以特定字符或者字符串的任意字符,则可以使用’.’关键字。例如要统计ecu_id以s匹配任意字符的ecu,则可以输入select * from tbox where ecu_id regexp ’^s.’;
注:“.”和“_”的区别
两个都可以代替任意一个字符进行查询。
“.”只能用于regexp关键字进行匹配
“_”不能用于regexp关键字进行匹配
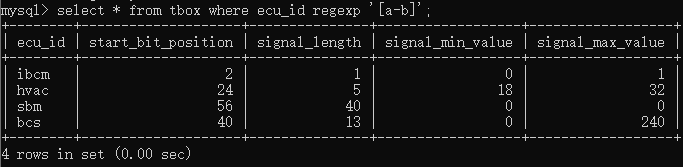
[]可以指定集合的区间,例如要统计ecu_id包含a和b字符的ecu,则可以输入select * from tbox where ecu_id regexp ‘[a-b]’;
这里还有一种写法,是用|代替-也是可行的输入select * from tbox where ecu_id regexp ‘[a|b]’;
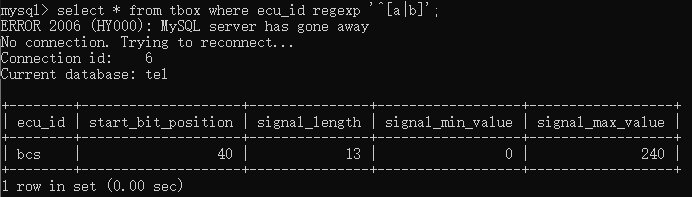
如果想要查询以a和b开头的ecu,则可以输入select * from tbox where ecu_id regexp ‘^[a-b]’;

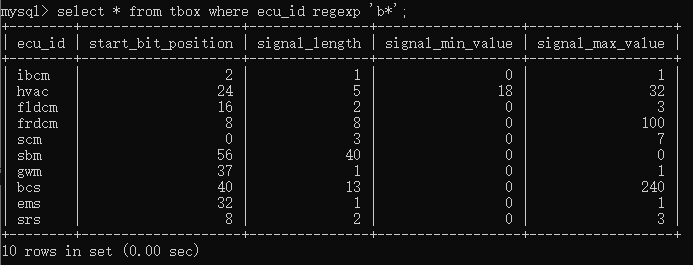
如果要查询所有包含0个或者多个“b”的ecu名称,则可以输入select * from tbox where ecu_id regexp 'b*';则可以全部查询得到
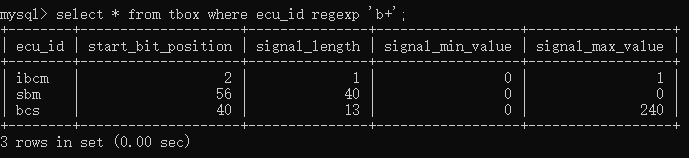
如果要查询所有包含1个或者多个“b”的ecu名称,则可以输入select * from tbox where ecu_id regexp 'b+';
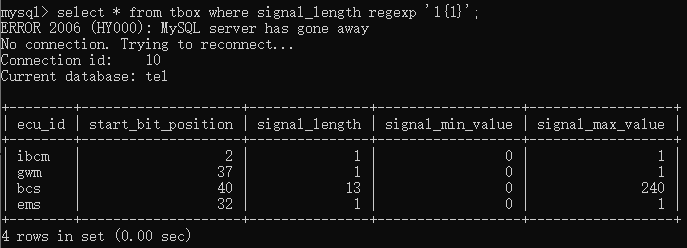
如果要查询signal_length中值1出现1次的,则可以输入select * from tbox where signal_length regexp '1{1}';
如果要查询signal_length中值1出现2到3次的,则可以输入select * from tbox where signal_length regexp '1{2,3}';此时查询不到任何数据,因为没有数据符合要求

MySQL运算符
可以指明对表中数据所进行的运算。
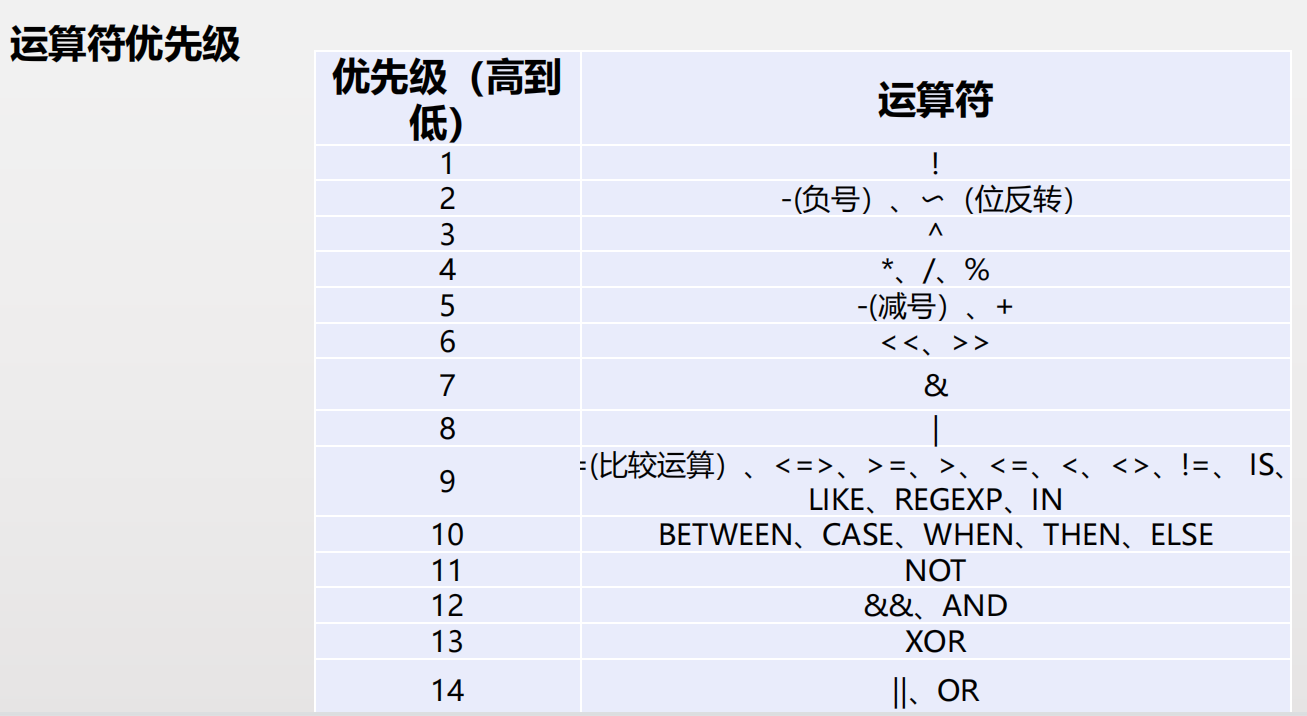
MySQL 主要有以下几种运算符:
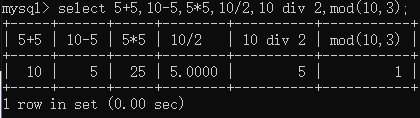
算术运算符:加减乘除求余,主要是用在数值计算上。
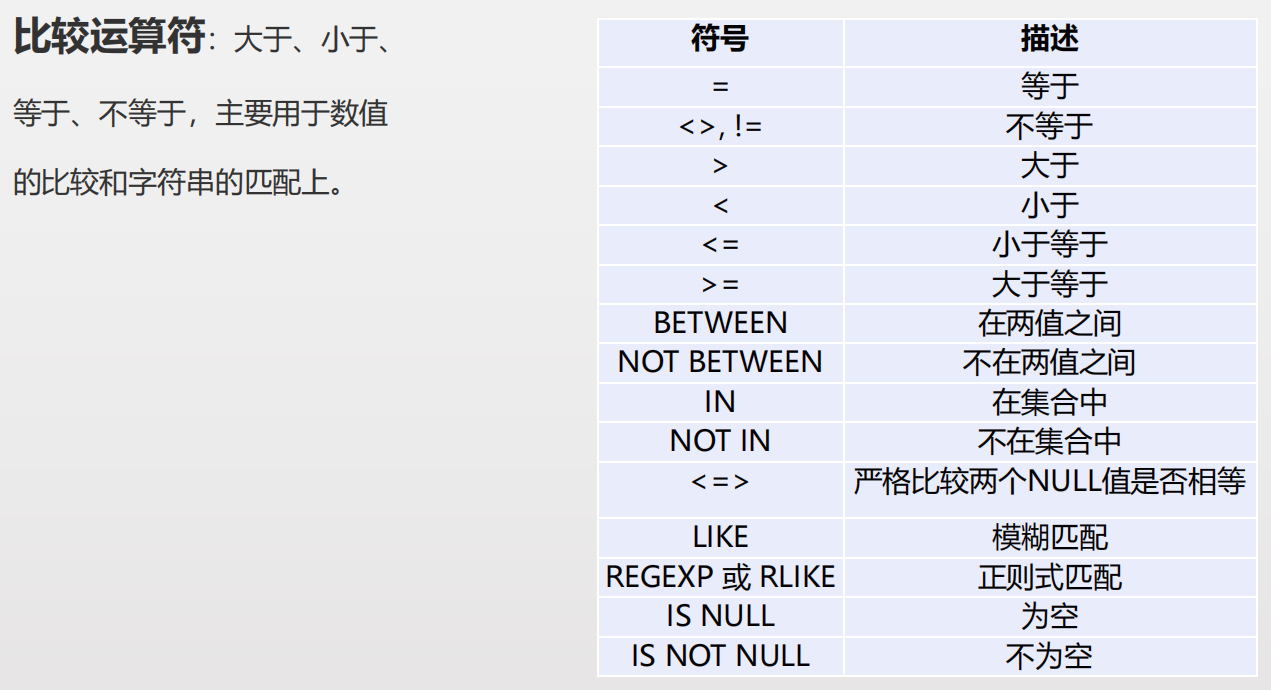
比较运算符:大于、小于、等于、不等于,主要用于数值的比较和字符串的匹配上。
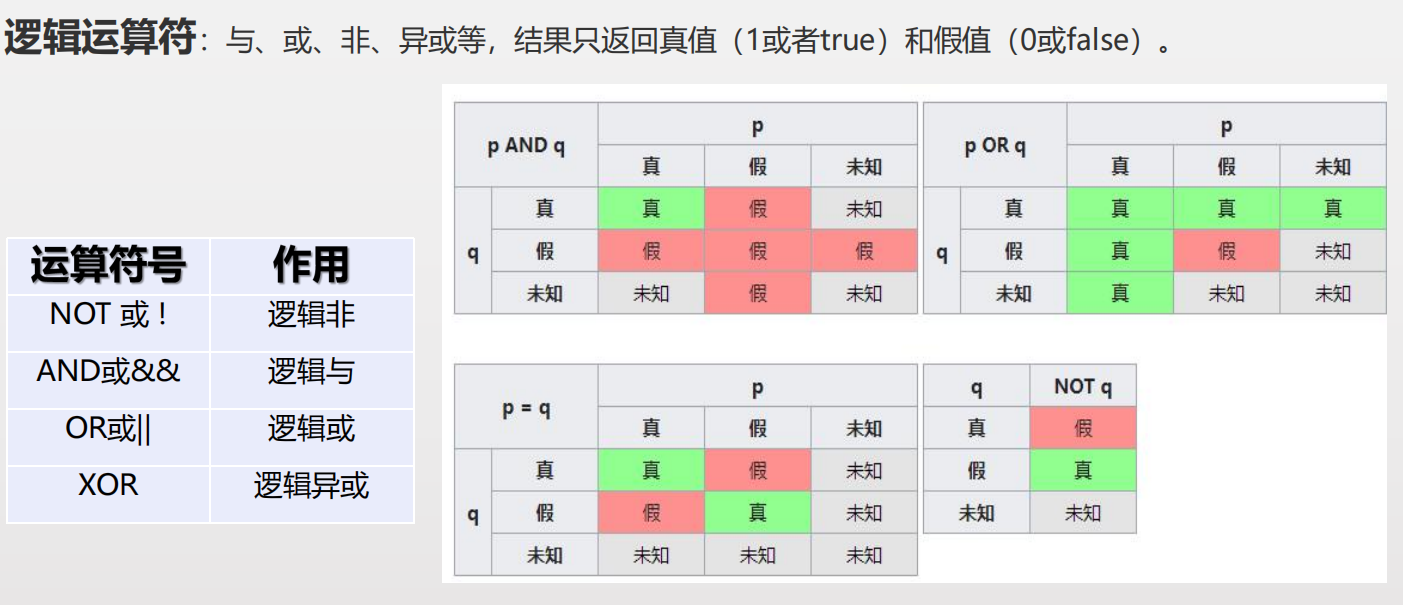
逻辑运算符:与、或、非、异或等,结果只返回真值(1或者true)和假值(0或false)。

MySQL 注释符号有三种,分别如下所示。
- #...
- 2. "-- "(注意:"--" 后面有一个空格)
3. /*...*/
1、“#”,表示单行注释,语法“#注释内容”
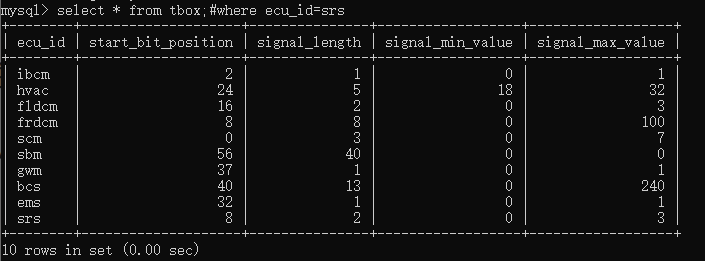
- “--”,表示单行注释,语法“-- 注释内容”
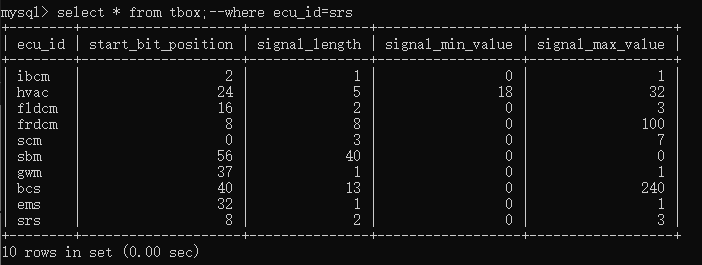
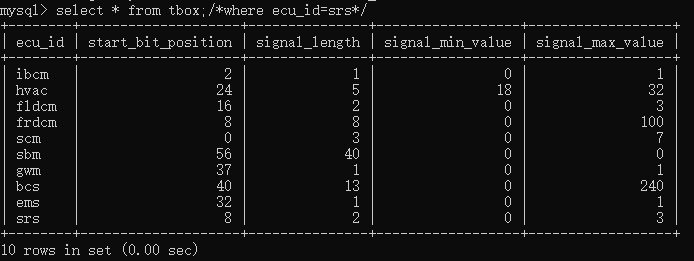
3、“/**/”,表示多行注释,语法“/*注释内容*/”
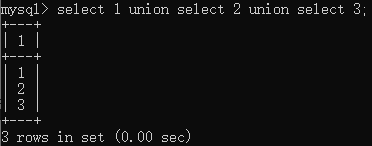
联合查询 : UNION
并操作 union、交操作 intersect、差操作 except
UNION用于合并具有相同字段结构的两个表的内容,主要用在一个结果中集中显示不同表的内容
select * from venus1
union
select * from venus2
union查询默认不返回重复记录
union查询的表的字段必须一样
union查询的数据类型必须能兼
#union查询结果只增加了行数而列数不变
union操作符用于合并两个或多个select语句的结果集。
union所查询的列数、列的顺序必须相同,数据类型必须兼容。
如果现在要查询tbox数据库的前五列信息,则可以输入select * from tbox order by 5;
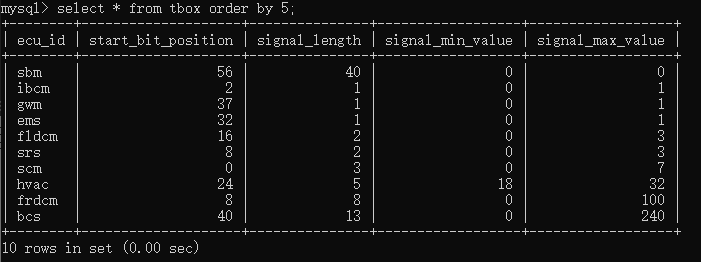
如果现在要查询tbox数据库的前六列信息,因为已经超出数据库tbox表列数的最大值,则查询不到

如果在现实情况下有更多的数据库表,此时我们还可以使用嵌套查询
嵌套查询包括:
1.子查询
2.子查询可以继续嵌套
3.子查询中不可以使用order by子句,只对最后结果排序
4.子查询要用括号括起来
子查询结果为集合时可用如下关键字判断
[NOT]IN [不]包含其中
ANY//ALL 任何一个//所有的
[NOT]EXISTS [不]存在
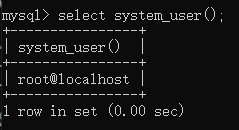
接下来给大家介绍一些mysql的系统函数
系统用户名:system_user()
查询语句:
select system_user();
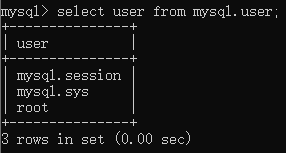
select user from mysql.user;
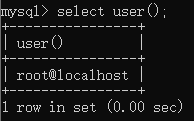
用户名:user()
查询语句:
select user();
当前用户名:current_user()
查询语句:current_date()当前日期
select current_user();
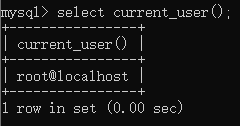
连接数据库用户名:session_user()
查询语句:
select session_user();
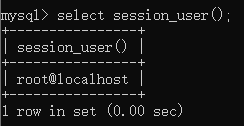
数据库名:database()
查询语句:
select database();
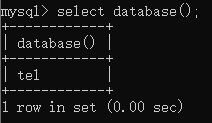
数据库版本:version()
查询语句:
select version();
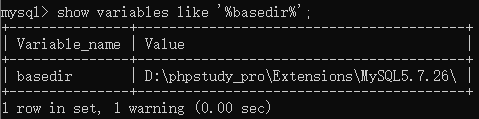
数据库读取路径:@@basedir
查询语句:
show variables like '%basedir%';
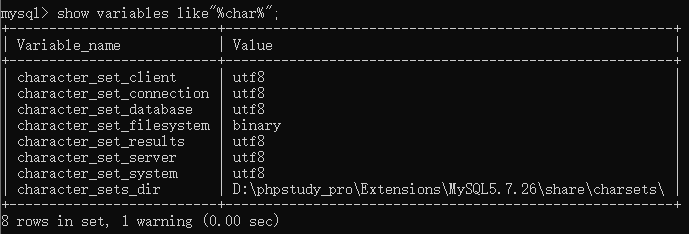
MYSQL安装路径:@@char
查询语句:
show variables like"%char%";
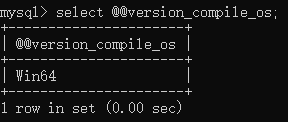
查看当前系统版本:@@version_compile_os
查询语句:
select @@version_compile_os;
其它相关函数:
left(s,n) #返回字符串s最左边的字符 n是个数
right(s,n) #返回字符串s最右边的字符
substr(s,n,len) mid(s,n,len)
#截取字符串s的第n个字符,且截取长度为len
lpad(string,length,’str2’) rpad(string,length,’str’)
#string:需要填充的字符串 length:填充之后的总长度 str:填充字符串,默认空格
其它相关函数:
LOCATE(‘str’,’str1’) LOCATE(str,str1,pos) locate(‘a’,’locala’,5)
#返回str在str1中第一次出现的位置 pos--从pos位置开始检索
insert(str1,pos,len,str2)
#str1:指定字符串 pos:开始被替换的位置 len:被替换字符串长度 str2:新字符串
instr(field, str)
#返回field字符串中出现str字符串的位置
position(str1 in str2)
#返回字符串中第一次出现的子字符串的位置,若没有返回0
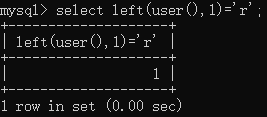
判断当前用户的第一字符:
查询语句:
select left(user(),1)=’r’;
判断当前用户的最后一个字符:
查询语句:
select right(user(),1)=’r’;
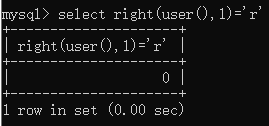
截取函数:
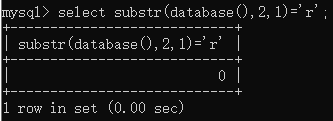
截取当前数据第二个字符是否为r
查询语句:
select substr(database(),2,1)=’r’;
select mid(database(),2,1)=’r’;
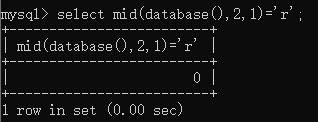
#正确返回1,错误返回0
其它相关函数:
concat(str1, str2,...) select concat(“abc”,NULL,”fg”) NULL
#返回结果为连接参数产生的字符串
concat_ws(separator, str1, str2, ...) select concat_ws(“+”,”123”,”345”) 123+345
#用第一个参数作为连接符号将字符串连接
group_concat(str1)
#将group by产生的同一个分组中的值连接起来,返回一个字符串
if(expr,v1,v2) select if(1<2,1,0);
#expr:条件 满足条件返回V1,不满足条件返回V2
case when expr then v1 else v2 end
#满足expr,则返回V1,不满足则返回V2
sleep(N)
#执行select sleep(N)可以让此语句运行N秒
oct() #转换为8进制 ord() 返回第一个字符串的第一个字符的ascii值
hex() #转换为16进制
char() #转换为字符串
ascii() #ASCII值
数据库函数:
infomation_schema
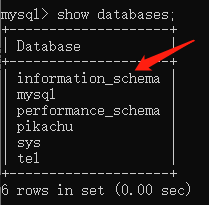
information_schema 用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类
型、访问权限等。
infomation_schema.schemata infomation_schema.tables infomation_schema.cloumns

 浙公网安备 33010602011771号
浙公网安备 33010602011771号