财通国际人才网佛山区域爬虫
一、选题背景:通过爬虫,可以更清楚地了解各公司的招聘要求的真实情况,从而在最短的时间内发现问题,找到自己最适合的岗位,从而节约了很多时间。
二、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
链家招聘网站佛山区域爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取链家上面发布的职位信息,分析佛山各区域,不同岗位的学历要求
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
爬取链家当中佛山各区域不同岗位所需各种学历人才数的通过分析其网页特征来使用python代码切换不同的区域页面再通过提取出不同城市不同岗位所需各种学历人才数进行绘制柱状图。
技术难点:链家的内容较多,在分析其网页结构可能会比普通的求职网站要来得复杂一些,并且注意识别其中一些广告内容。
三、主题页面的结构特征分析(15分)
1.主题页面的结构与特征分析:通过观察页面HTML源代码,可以发现每个职位名称的标题都位于'div',class="jobsList"标签的子标签中,而学历要求则位于'span', class_="line_list"标签的子标签中,通过标签的关系进行遍历得到需要的内容


3.节点(标签)查找方法与遍历方法
#获取总的div数据量 divs = html.xpath('//div[@id="infolists"]/div[position()>1]') for div in divs: #提取数据 job_dic ={} #工作信息 job_dic['job'] = div.xpath('.//dt[@class="mouseListen"]/div[1]/a/text()')[0].strip() #地区信息 job_dic['area'] = div.xpath('.//span[@class="cityConJobsWork"]/text()')[0].strip()
四、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
def get_page_and_parser(): #35 #统计数据的类型总量 data_num = 1 #创建pandas数据集 data = pd.DataFrame() #设置访问的最大页数 for page in range(1,35): url = "https://www.job001.cn/jobs?keyType=0&" \ "jobType=%E8%81%8C%E4%BD%8D%E7%B1%BB%E5%9E%8B" \ "&industryname=%E8%A1%8C%E4%B8%9A%E7%B1%BB%E5%9E%8B" \ f"&workId=25.296&workPlace=" \ f"%E4%BD%9B%E5%B1%B1%E5%B8%82&pageNo={str(page)}" print(url) #请求网页 resp = requests.get(url,headers=headers) print(resp.text)
结果:
2.对数据进行清洗与处理
job_dic ={} #工作信息 job_dic['job'] = div.xpath('.//dt[@class="mouseListen"]/div[1]/a/text()')[0].strip() #地区信息 job_dic['area'] = div.xpath('.//span[@class="cityConJobsWork"]/text()')[0].strip() #刷新时间信息 job_dic['flash_time'] = div.xpath('.//dt[@class="mouseListen"]/div[1]/span[2]/text()')[0].strip() #薪水信息 salary = div.xpath('.//span[@class="salaryList"]//text()')[0].strip() #对提取的薪水信息进行处理 salary = salary.split("-")[0] if salary.startswith("("): salary = salary.split(")")[-1] if salary == "": salary =0 job_dic['salary'] = float(salary) #公司信息 company = div.xpath('.//div[@class="jobRight"]/dt/a/text()')[0] #招聘公司信息 job_dic['company'] = company.strip() #职位类型 job_dic['type'] = div.xpath(".//dd[@class='company-info']/span[1]/text()")[0] #输出提取的信息 print(f"data num:{str(data_num)}--", job_dic['job'], job_dic['area'], job_dic['salary'], job_dic['flash_time'], job_dic['company'],job_dic['type'])

2.2对工作区域数据处理
def draw_area(data): #对area数据处理 data = data.groupby(['area'])['salary']\ .agg(['mean','count']).reset_index() data = sorted([(row['area'],round(row['mean'],1)) for _,row in data.iterrows()], key=lambda x:x[1]) print(data)

2.3对工作数据进行处理
def draw_job(data): # 对job数据进行分类处理 data = data.groupby(['salary'])['area'].\ count().reset_index() data = sorted([(row['salary'], row['area']) for _, row in data.iterrows()], key=lambda x: x[1], reverse=True) print(data)

#存入pandas if data.empty: data = pd.DataFrame(job_dic, index=[0]) else: data = data.append(job_dic, ignore_index=True) data_num += 1 #设置延时,防止被墙 time.sleep(random.randint(1,3)) if page%5 ==0: time.sleep(10) #把所有数据写入excl中 data.head() print(data) data.to_excel("foshan.xlsx")

3.数据分析与可视化
bar = ( Funnel() .add( "企业性质和平均薪资排行", data, sort_="ascending", label_opts=opts.LabelOpts(position="inside"), ) .set_global_opts(title_opts= opts.TitleOpts(title="佛山招聘企业性质和平均薪资占比")) ) bar.render("templates/佛山招聘企业性质和平均薪资排行.html")

pie = ( Pie(init_opts=opts.InitOpts(theme='dark')) .add('', data, radius=["30%", "75%"], rosetype="radius") .set_global_opts(title_opts=opts.TitleOpts(title="佛山各个区域招聘薪资范围的占比"), legend_opts=opts.LegendOpts(is_show=False), ) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) ) pie.render("templates/佛山招聘薪资范围的占比.html")
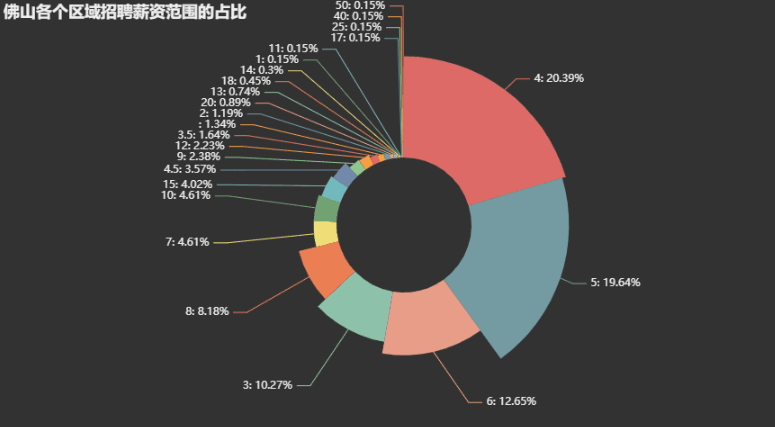
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
bar = ( Bar(init_opts=opts.InitOpts(theme='dark')) .add_xaxis([x[0] for x in data]) .add_yaxis('佛山各区域招聘均价', [x[1] for x in data]) .set_global_opts( title_opts=opts.TitleOpts(title="佛山各区域招聘均价排行"), legend_opts=opts.LegendOpts(is_show=False), tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}千元')) .reversal_axis() ) bar.render("templates/佛山各区域招聘均价排行.html")

完整代码
1 import requests 2 from lxml import etree 3 import time 4 import random 5 import pandas as pd 6 from flask import Flask,render_template 7 from jinja2 import Markup 8 from pyecharts import options as opts 9 from pyecharts.charts import Bar, Pie,Funnel 10 11 12 13 #添加请求头,防止被墙 14 headers = { 15 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 " 16 "(KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 17 } 18 19 #定义需要解析的信息 20 def get_page_and_parser(): 21 #35 22 #统计数据的类型总量 23 data_num = 1 24 #创建pandas数据集 25 data = pd.DataFrame() 26 #设置访问的最大页数 27 for page in range(1,35): 28 url = "https://www.job001.cn/jobs?keyType=0&" \ 29 "jobType=%E8%81%8C%E4%BD%8D%E7%B1%BB%E5%9E%8B" \ 30 "&industryname=%E8%A1%8C%E4%B8%9A%E7%B1%BB%E5%9E%8B" \ 31 f"&workId=25.296&workPlace=" \ 32 f"%E4%BD%9B%E5%B1%B1%E5%B8%82&pageNo={str(page)}" 33 print(url) 34 #请求网页 35 resp = requests.get(url,headers=headers) 36 # print(resp.text) 37 #解析网页 38 html = etree.HTML(resp.text) 39 #获取总的div数据量 40 divs = html.xpath('//div[@id="infolists"]/div[position()>1]') 41 for div in divs: 42 #提取数据 43 job_dic ={} 44 #工作信息 45 job_dic['job'] = div.xpath('.//dt[@class="mouseListen"]/div[1]/a/text()')[0].strip() 46 #地区信息 47 job_dic['area'] = div.xpath('.//span[@class="cityConJobsWork"]/text()')[0].strip() 48 #刷新时间信息 49 job_dic['flash_time'] = div.xpath('.//dt[@class="mouseListen"]/div[1]/span[2]/text()')[0].strip() 50 #薪水信息 51 salary = div.xpath('.//span[@class="salaryList"]//text()')[0].strip() 52 #对提取的薪水信息进行处理 53 salary = salary.split("-")[0] 54 55 if salary.startswith("("): 56 salary = salary.split(")")[-1] 57 if salary == "": 58 salary =0 59 job_dic['salary'] = float(salary) 60 #公司信息 61 company = div.xpath('.//div[@class="jobRight"]/dl/dt/a/text()')[0] 62 63 #招聘公司信息 64 job_dic['company'] = company.strip() 65 #职位类型 66 job_dic['type'] = div.xpath(".//dd[@class='company-info']/span[1]/text()")[0] 67 68 69 #输出提取的信息 70 print(f"data num:{str(data_num)}--", job_dic['job'], 71 job_dic['area'], job_dic['salary'], 72 job_dic['flash_time'], job_dic['company'],job_dic['type']) 73 74 #存入pandas 75 if data.empty: 76 data = pd.DataFrame(job_dic, index=[0]) 77 78 else: 79 data = data.append(job_dic, ignore_index=True) 80 data_num += 1 81 82 #设置延时,防止被墙 83 time.sleep(random.randint(1,3)) 84 if page%5 ==0: 85 time.sleep(10) 86 87 #把所有数据写入excl中 88 data.head() 89 print(data) 90 data.to_excel("foshan.xlsx") 91 92 93 #佛山各区域招聘的均价 94 def draw_area(data): 95 #对area数据处理 96 data = data.groupby(['area'])['salary']\ 97 .agg(['mean','count']).reset_index() 98 data = sorted([(row['area'],round(row['mean'],1)) 99 for _,row in data.iterrows()], 100 key=lambda x:x[1]) 101 # #图像绘制 102 #[('三水区/西南', 3.0), ('南海区/官窑', 3.0), ('南海区/南海周边', 3.4), ('广东', 3.4), 103 print(data) 104 bar = ( 105 Bar(init_opts=opts.InitOpts(theme='dark')) 106 107 .add_xaxis([x[0] for x in data]) 108 .add_yaxis('佛山各区域招聘均价', [x[1] for x in data]) 109 110 .set_global_opts( 111 title_opts=opts.TitleOpts(title="佛山各区域招聘均价排行"), 112 legend_opts=opts.LegendOpts(is_show=False), 113 tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}千元')) 114 .reversal_axis() 115 ) 116 bar.render("templates/佛山各区域招聘均价排行.html") 117 return bar 118 119 #佛山招聘企业性质和平均薪资 120 def draw_type(data): 121 #对type数据进行分类处理 122 data = data.groupby(['type'])['salary'].\ 123 agg(['mean', 'count']).reset_index() 124 data = sorted([(row['type'], round(row['mean'], 1)) 125 for _, row in data.iterrows()], key=lambda x: x[1]) 126 print(data) 127 bar = ( 128 Funnel() 129 .add( 130 "企业性质和平均薪资排行", 131 data, 132 sort_="ascending", 133 label_opts=opts.LabelOpts(position="inside"), 134 ) 135 .set_global_opts(title_opts= 136 opts.TitleOpts(title="佛山招聘企业性质和平均薪资占比")) 137 ) 138 bar.render("templates/佛山招聘企业性质和平均薪资排行.html") 139 return bar 140 141 #佛山各个区域招聘薪资范围的占比 142 def draw_job(data): 143 # 对job数据进行分类处理 144 data = data.groupby(['salary'])['area'].\ 145 count().reset_index() 146 data = sorted([(row['salary'], row['area']) 147 for _, row in data.iterrows()], 148 key=lambda x: x[1], reverse=True) 149 150 pie = ( 151 Pie(init_opts=opts.InitOpts(theme='dark')) 152 .add('', data, 153 radius=["30%", "75%"], 154 rosetype="radius") 155 .set_global_opts(title_opts=opts.TitleOpts(title="佛山各个区域招聘薪资范围的占比"), 156 legend_opts=opts.LegendOpts(is_show=False), ) 157 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) 158 ) 159 pie.render("templates/佛山招聘薪资范围的占比.html") 160 return pie 161 162 #创建flask app 163 app = Flask(__name__,static_folder="templates") 164 165 #创建pandas数据集 166 df = pd.read_excel("foshan.xlsx",engine="openpyxl") 167 168 #对数据进行重复值删除,None值删除 169 data = df.drop_duplicates() 170 data = data.dropna() 171 172 #设置主页路由 173 @app.route("/") 174 def index(): 175 return render_template("index.html") 176 177 #地区的路由 178 @app.route("/area") 179 def area(): 180 #生成area图例 181 area = draw_area(data) 182 # 生成area图例 183 return Markup(area.render_embed()) 184 185 #类型的路由 186 @app.route("/type") 187 def salary(): 188 # 生成area图例 189 type = draw_type(data) 190 # 渲染area图例 191 return Markup(type.render_embed()) 192 193 #工作的路由 194 @app.route("/job") 195 def job(): 196 # 生成job图例 197 job = draw_job(data) 198 # 生渲染job图例 199 return Markup(job.render_embed()) 200 201 #主要调用模块 202 if __name__ == '__main__': 203 #生成数据 204 get_page_and_parser() 205 #开启flask服务器展示数据 206 app.run(host="0.0.0.0",port=8080) 207 208 209
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.顺德区的薪资占各区域的前三名,其中乐从远高于其他区。
2.建筑建材的薪资最高,外商独资其次,事业单位的薪资最低。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
完成此项作业才发现自己还有如此多的不懂,仍然需要不断学习,刻苦专研。在完成作业的途中,通过查阅各种资料,提升了我对这门学科浓厚的兴趣。我觉得这次爬虫的内容还挺有意思的,也让我学到了很多书本以外的知识,一步一步自己探索出来,遇到不懂的问题及时问同学答疑解惑。这一次任务按照老师的要求一步一步来实现,虽然有一些没有完全实现出来,还存在在很多问题,但是发现问题多了也就能及时查缺补漏,让我们对Python这门语言有了更深的理解,也让我增加了更多的兴趣对于这个课程,能够让自己能更好地进步。今后一定会更加努力的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号