spark 写csv文件出现乱码 以及写文件读文件总结
参考链接:https://blog.csdn.net/qq_56870570/article/details/118492373
result_with_newipad.write.mode("Append").csv("C:\\Users")
数据格式如下:
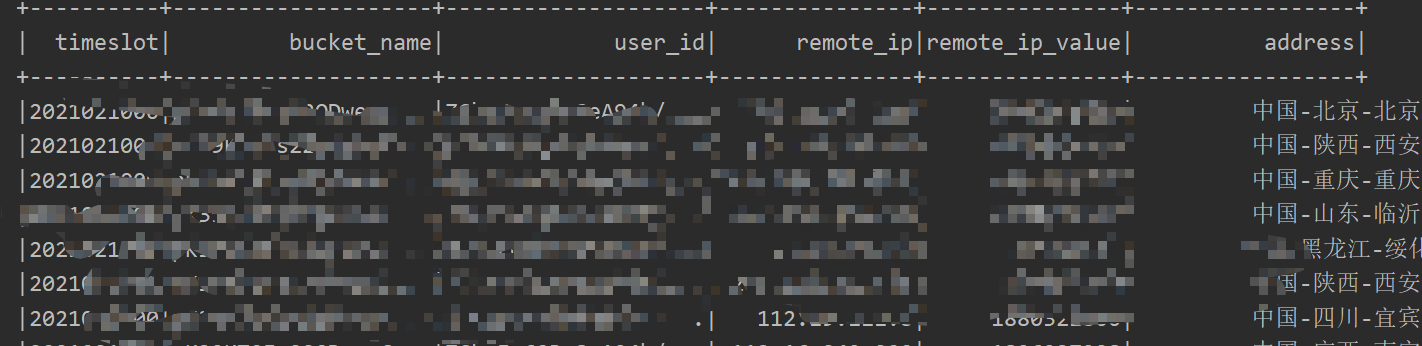
但在写文件时最后一列address报的是乱码
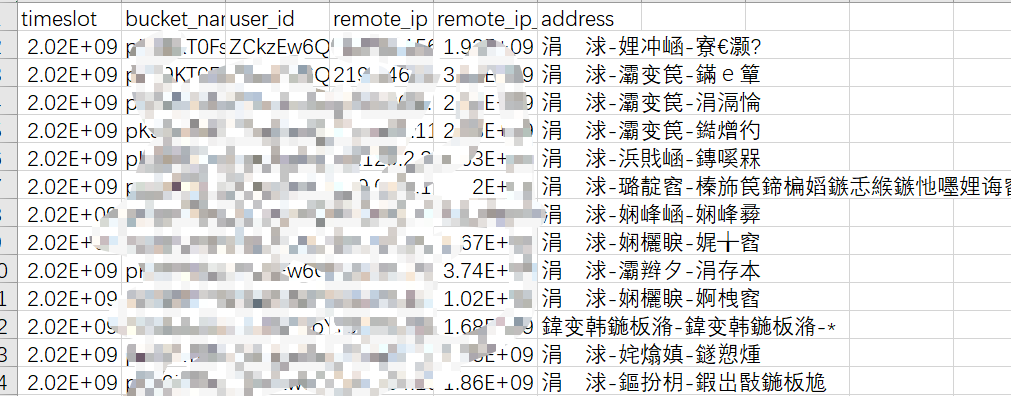
具体方式可以在写csv下写option添加utf-8格式
result_with_newipad.writer.mode("overwrite").option("header","ture").option("encoding","utf-8").csv("")
关键参数:
format:指定读取csv文件。
header:是否指定头部行作为schema。
multiLine:在单元格中可能因为字数多有换行,但是不指定这个参数,处理数据时可能会报错。指定这个参数为true,可以将换行的单元格合并为1行。
encoding:指定编码格式如gbk或utf-8
如下表对option里面的参数,进行介绍:
| 参数 | 解释 |
| header | 默认是false,将第一行作为列名 |
| encoding | 默认是uft-8通过给定的编码类型进行解码 |
| sep | 默认是, 指定单个字符分割字段和值 |
| inferSchema | inferSchema(默认为false`):从数据自动推断输入模式。 *需要对数据进行一次额外的传递 |
| multiLine | 默认是false,解析一条记录,该记录可能跨越多行 |
| inferSchema | inferSchema(默认为false`):从数据自动推断输入模式。 *需要对数据进行一次额外的传递。如:option("inferSchema", true.toString) //这是自动推断属性列的数据类型 |
| nullValue | 默认是空的字符串,设置null值的字符串表示形式。从2.0.1开始,这适用于所有支持的类型,包括字符串类型 |
| emptyValue | 默认是空字符串,设置一个空值的字符串表示形式 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号