宁德时代秋招一面
1.硕士的研究方向? 人工智能了解程度? python,java
2.携程实习时,软件工程的理念,软件工程的整个过程,软件开发模式,整个项目中的困难点、
实习的开发模式更接近于快速原型模型、V模型。在限定的时间内,用最经济的方法开发出一个可实际运行的系统模型,用户在运行使用整个原型的基础上,通过对其评价,提出改进意见,对原型进行修改,统一使用,评价过程反复进行,使原型逐步完善,直到完全满足用户的需求为止。
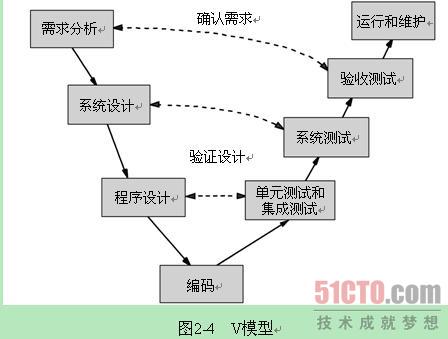
困难点
联动captain发布系统时有过几版解决方案
- 分支合并成功,生成镜像号x,可通过git webhook得到
merge 请求新建判别,是否合并的目的分支为默认分支。
此处还需要存入当前合并的代码仓库地址,便于后续判断- jira Releases中新建version
- captain发布时在高级设置 备注处填写version号
qmq 处接收变更消息, 需对 组织、变更阶段、是否完成、生成镜像的分支是否为 release|master- jira根据version搜索到其中的所有issue, 将所有和captain变更同仓库的issue --> done
2. 将镜像号x记录在issue某字段中,可通过x搜索到issue?
3. captain 发布成功后,通过webhook 镜像号定位到issue,更改issue状态为Done。
发布工具时,无法直接访问jira,需要内接一个proxy。
需要将一些筛选条件抽离出来,放入qconfig中
fws和prod生产环境的差异,调试时的一些额外操作。
3.gitlab 基于当前版本回滚上一版本,操作
git log查看commit记录,使用git reset --hard [commit_sha]
将修改push到远端git push -f -u origin target_branch
4.挂号平台项目,redis 中的数据类型? 使用的哪个版本? 新的数据类型
常见的有五种:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
随着 Redis 版本的更新,后面又支持了四种数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增,专为消息队列设计)。
5.redis 缓存的淘汰策略
常见的三种过期删除策略
- 定时删除策略,在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
- 惰性删除策略,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
- 定期删除策略,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。

内存淘汰策略

6.消息队列的作用
- 通过异步处理提高系统性能(减少响应所需时间)
- 削峰/限流
- 降低系统耦合性。
7.使用 MQ 需要注意的点,防止消息丢失,消息幂等,重复消费,服务端如何
消息丢失
- 生产者send后使用ListenableFuture通过添加回调函数得到最终结果。 消息发送失败是,设置重试次数和重试间隔
- 消费者
Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。设置 acks = all,acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后就算被成功发送。当我们配置 acks = all 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应
消息幂等 重复消费
出现的原因
- 服务端侧已经消费的数据没有成功提交 offset(根本原因)。
- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
解决方案 - 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
- 将 enable.auto.commit 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:什么时候提交 offset 合适?
- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
8.java 面向对象的三个特性
9.java 多线程,创建线程的方式,为什么不推荐直接创建 Thread 方法? 为什么使用线程池?线程池创建线程的操作
1)每次通过new Thread()创建对象性能不佳。
2)线程缺乏统一管理,可能无限制新建线程,相互之间竞争,及可能占用过多系统资源导致死机或oom。
3)缺乏更多功能,如定时执行、定期执行、线程中断。
4)因为线程类已经继承了Thread类,所以不能再继承其他父类。
相比new Thread,Java提供的四种线程池的好处在于:
1)重用存在的线程,减少对象创建、消亡的开销,提升性能。
2)可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
3)提供定时执行、定期执行、单线程、并发数控制等功能。
采用实现Runnable、Callable接口的方式创建多线程的优缺点。
1)线程类只是实现了Runnable接口与Callable接口,还可以继承其他类。
2)在这种方式下,多个线程可以共享一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
10.spring 三级缓存,循环依赖
11.数据库的引擎,两者的区别
MyISAM的优点:
- 简单和高效:MyISAM存储引擎的设计简单,性能较高,适用于读取频繁的应用场景。它对于大量的SELECT查询和插入操作具有较好的性能。
- 全文索引支持:MyISAM支持全文索引,可以提供更快速和灵活的文本搜索功能。
- 适用于静态数据:MyISAM适用于静态数据的存储和查询,例如博客文章、新闻等不经常更新的数据。
MyISAM的缺点:
- 不支持事务:MyISAM不支持事务,这意味着在并发写入的情况下,可能会导致数据不一致和丢失。
- 锁粒度大:MyISAM在执行写操作时会对整个表进行锁定,这会导致并发写入的性能下降。
- 不支持外键约束:MyISAM不支持外键约束,这意味着无法通过外键关联来保证数据的完整性。
InnoDB的优点:
- 支持事务:InnoDB支持事务,可以确保数据的一致性和完整性。
- 行级锁定:InnoDB使用行级锁定,可以提供更好的并发性能,多个事务可以同时读取和写入不同的行。
- 支持外键约束:InnoDB支持外键约束,可以通过外键关联来保证数据的完整性。
- Crash Recovery:InnoDB具有崩溃恢复能力,可以在数据库崩溃后自动恢复数据。
InnoDB的缺点:
- 相对复杂:InnoDB的设计较为复杂,对系统资源的消耗较大,可能会导致一些性能上的损失。
- 空间占用较大:InnoDB的数据文件相对较大,占用的磁盘空间较多。
综上所述,选择MyISAM还是InnoDB应根据具体的应用需求和场景来决定。如果需要支持事务、外键约束和并发写入,以及对数据完整性要求较高,那么InnoDB是更好的选择。如果应用场景是以读取为主,对性能要求较高,且对事务和数据完整性要求不高,那么MyISAM可能更适合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号