数据库内核:数据库前置知识点
数据模型
网络数据模型
Schema

Instance
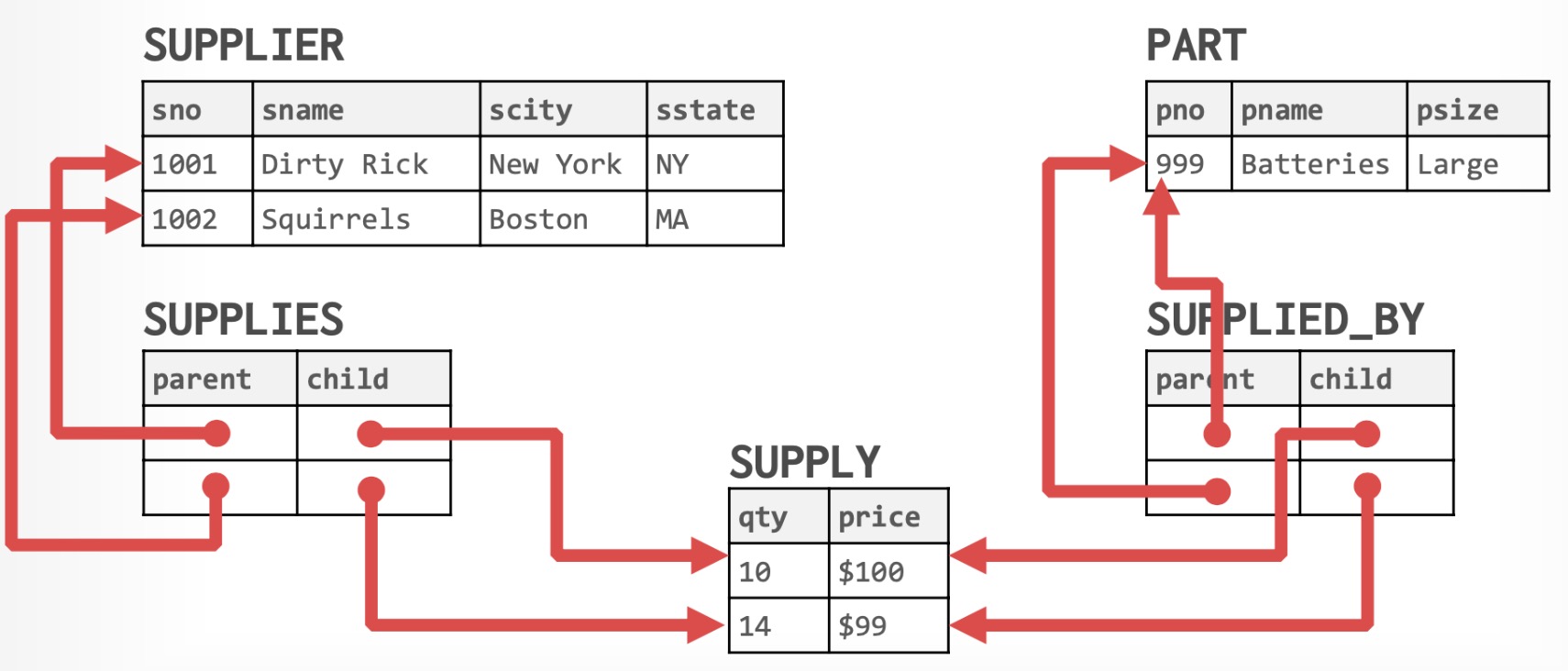
满足以下两个条件的模型称为网络数据模型:
- 允许一个以上的节点无双亲,例如 SUPPLIER 和 PART 节点。
- 一个节点可以有多余一个的双亲,例如 SUPPLY 节点有 SUPPLES 和 SUPPLED_BY 两个双亲节点。
层次数据模型
Schema 和 Instance

层次数据模型采用树形结构来表示实体与实体之间的关系。需要满足以下两个条件:
- 有且只有一个节点没有双亲,这个节点称为根节点例如 SUPPLIER 节点。
- 根节点以外的其他节点有且只有一个双亲,例如 PART 节点。
关系数据模型
Schema
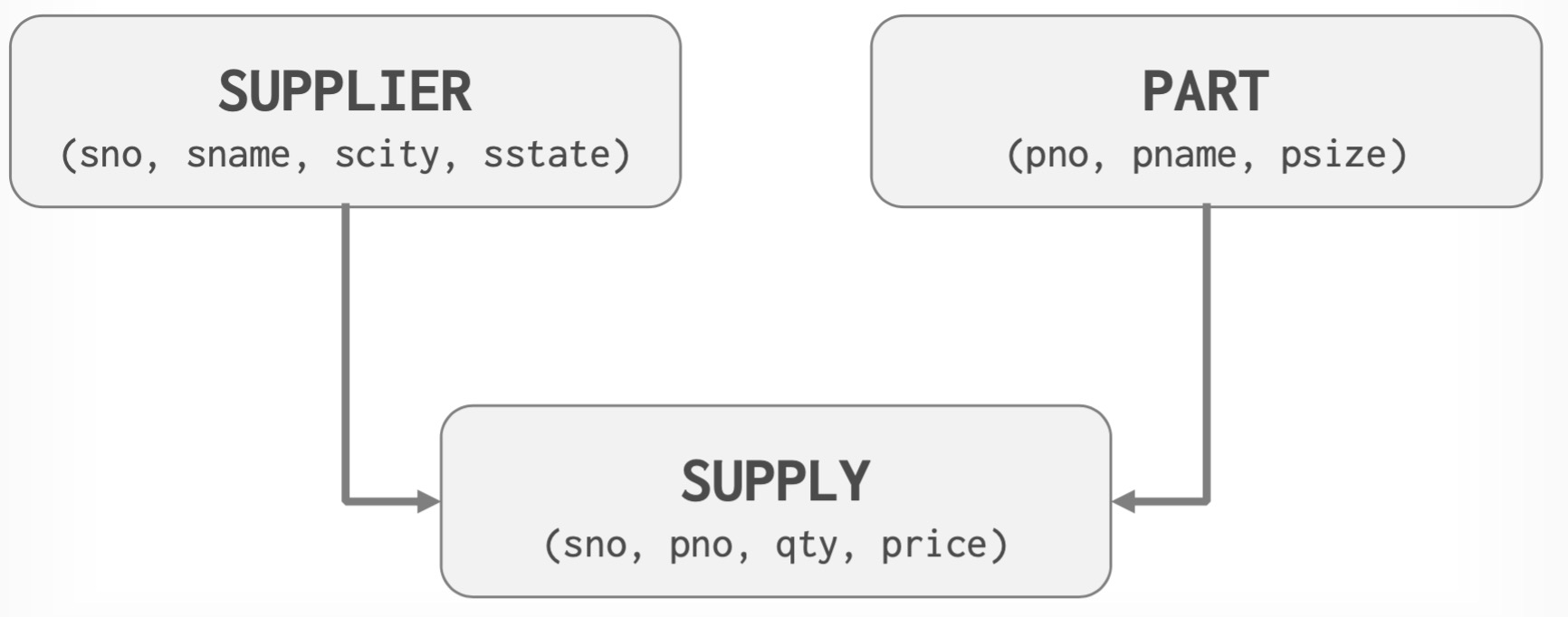
Instance

关系数据模型中的数据逻辑结构是一张二维表,它由行和列组成。关系的每一个分量必须是一个不可分割的数据项,不允许表中还有表。
- 关系(Relation):一张表就是一个关系。
- 元组(Tuple):表中的一行数据就是一个元组。
- 属性(Attribute):表中的一列表示同一属性。
- 码(Key):也称为键,用于表示元组的唯一性。
- 分量:元组中的一个属性值。
优缺点对比
| 优点 | 缺点 | |
|---|---|---|
| 网络数据模型 | 关系表示直接,存取效率高 | 结构复杂,引用程序访问时,必须选择适当的路径 |
| 层次数据模型 | 结构简单,查询效率高 | 多对多关系表示不方便,对插入和删除操作的限制条件多 |
| 关系数据模型 | 表示方便,表中行和列没有顺序 | 存取路径对用户透明,查询效率不高,关系必须规范化 |
面向对象数据模型
Instance
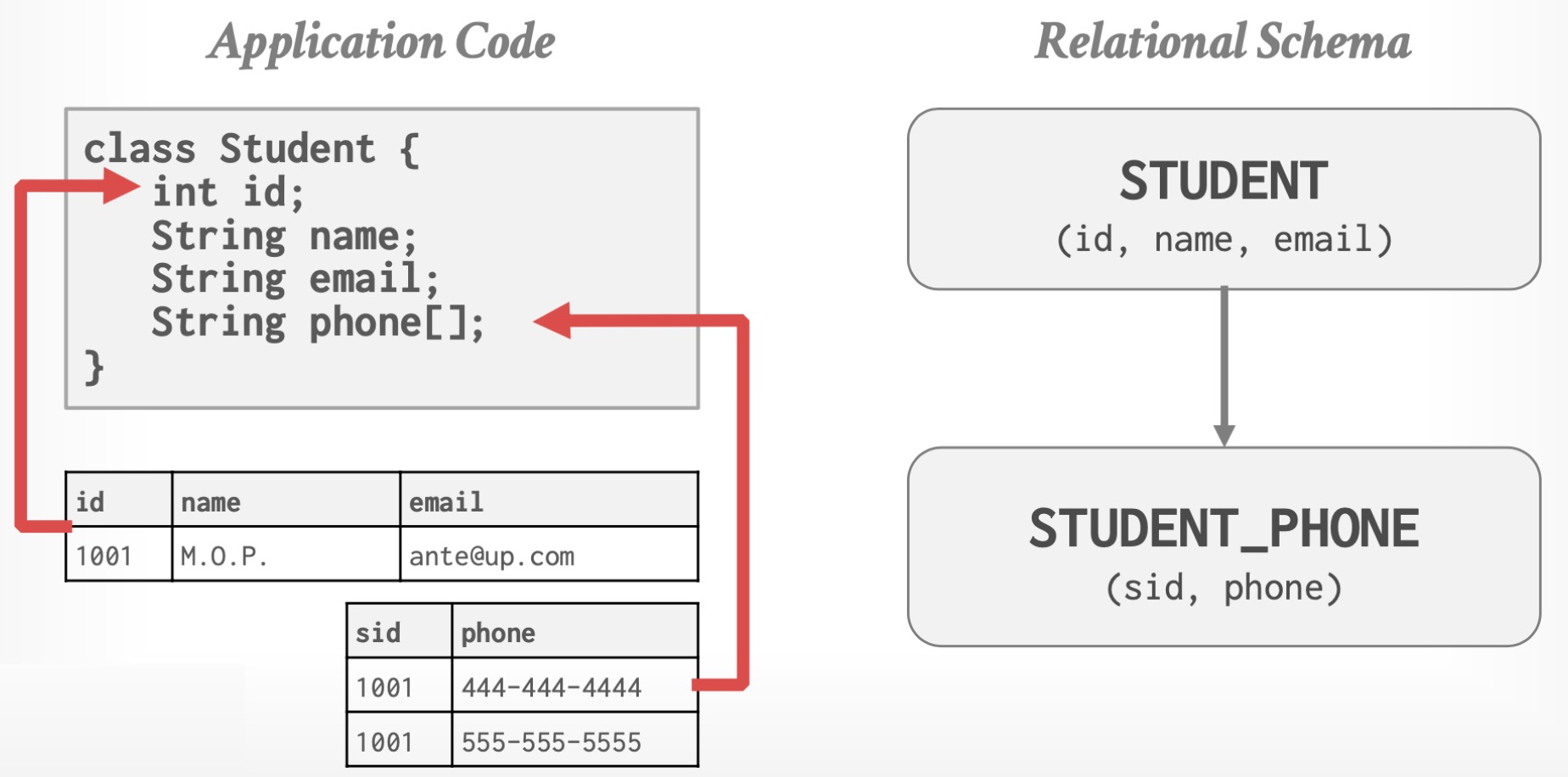
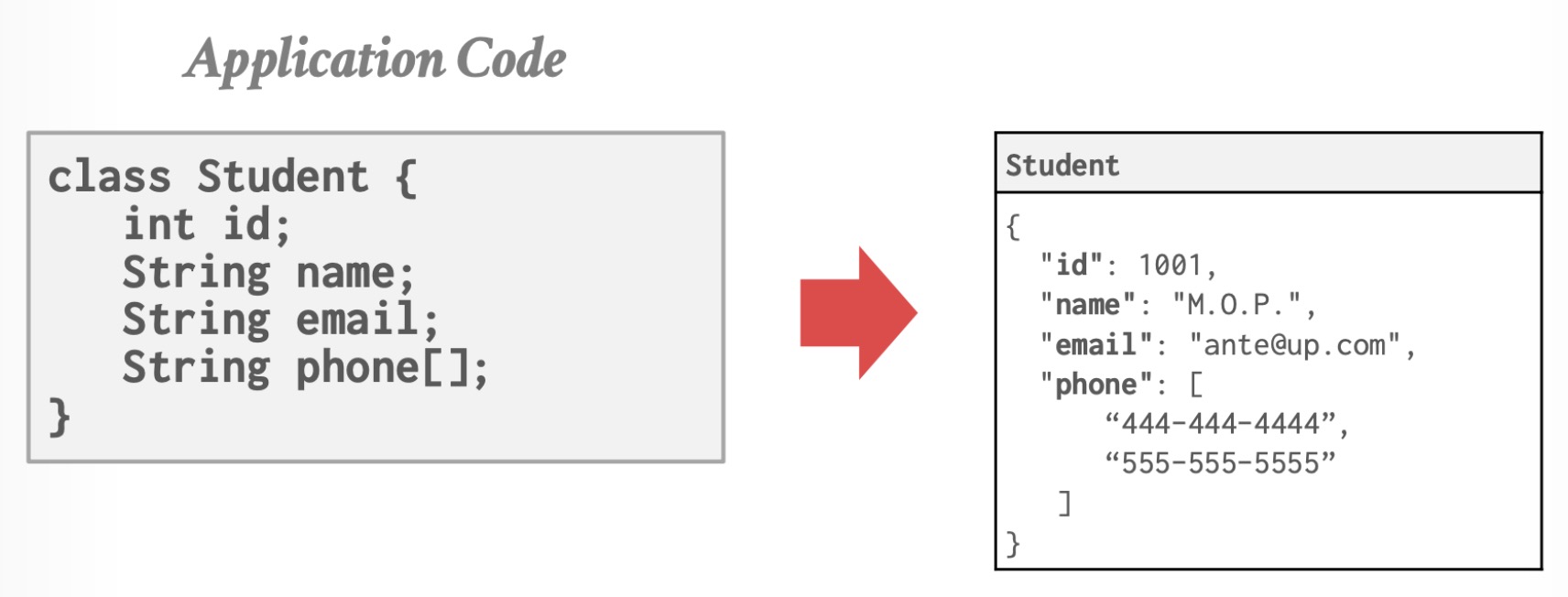
通过紧密耦合对象和数据库,避免“关系对象阻抗不匹配”。这类数据模型在现在的主流数据库中几乎没有使用,但是其思想在 XML、JSON 等技术中有所体现。
DBMS
数据库管理系统(DBMS)是对数据进行管理的大型系统软件。
功能
- 数据定义:存储、修改数据和元数据
- 约束定义、存储、维护和检查
- SQL:对数据的声明性操作
- 通过视图、触发器和过程的可扩展性
- 查询重写(规则)、优化(索引)
- 事务处理、并发和恢复
数据定义(DDL,Data Define Language)
数据定义:定义数据的三级模式结构(模式、内模式、外模式),定义二级映射(模式-内模式、外模式-模式),定义相关的约束条件。
关系数据:关系(表)、元组、值、类型、约束。
DBMS 通常将元数据存储为特殊表(Catelog)。
指定约束是数据定义的一个重要方面:
- 属性(列)约束
- 元组约束
- 关系(表)约束
- 引用完整性约束
数据修改(DML,Data Manipulation Language)
数据修改:实现对数据库的基本操作,包括检索、更新(增删改)。SQL 就是 DML 的一种。
大多数 DBMS 还提供批量下载和上传机 制:
- 转储数据和模式的文本副本
- 将数据和模式信息加载到数据库中
在 PostgreSQL 中:
- pg_dump 应用程序转储数据库
- 复制 SQL 命令加载整个表
架构
DBMS 体系结构的基本原则:
- 数据永久存储在大型慢速设备上(有可能已经被打破)
- 数据在小型快速存储器中处理(内存)
数据库系统实现的复杂性在于:
- 可能对数据结构进行多次并发访问,不仅仅是数据表,还有索引、缓冲区、目录等
- 事务性需求(原子性、回滚等)
- 原始数据的高可靠性要求(恢复)
- 锁定有助于并发,但可能会降低性能
- 可能需要新的“并发容忍”数据结构
- 事务和可靠性需要某种形式的日志记录
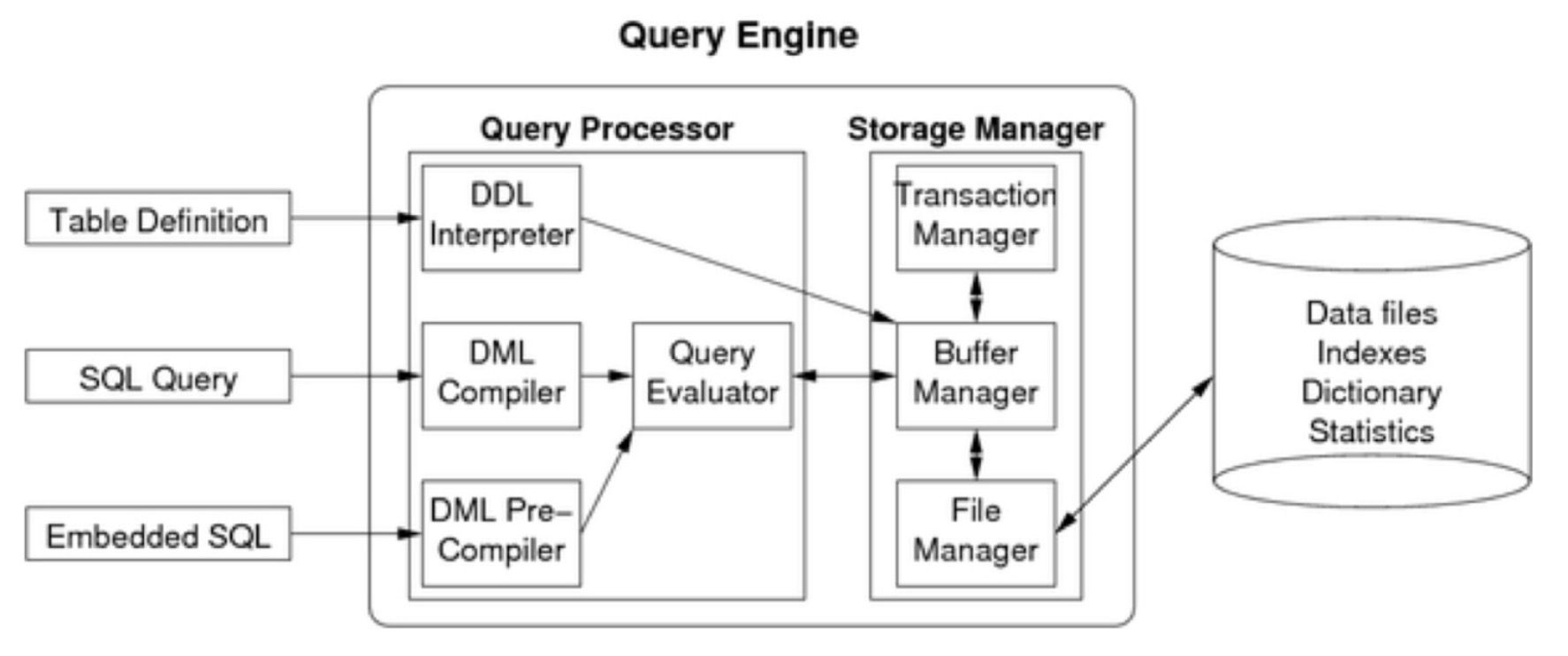
Silberschatz/Korth/Sudarshan (SKS) 架构:
Elmasri/Navathe (EN) 架构:

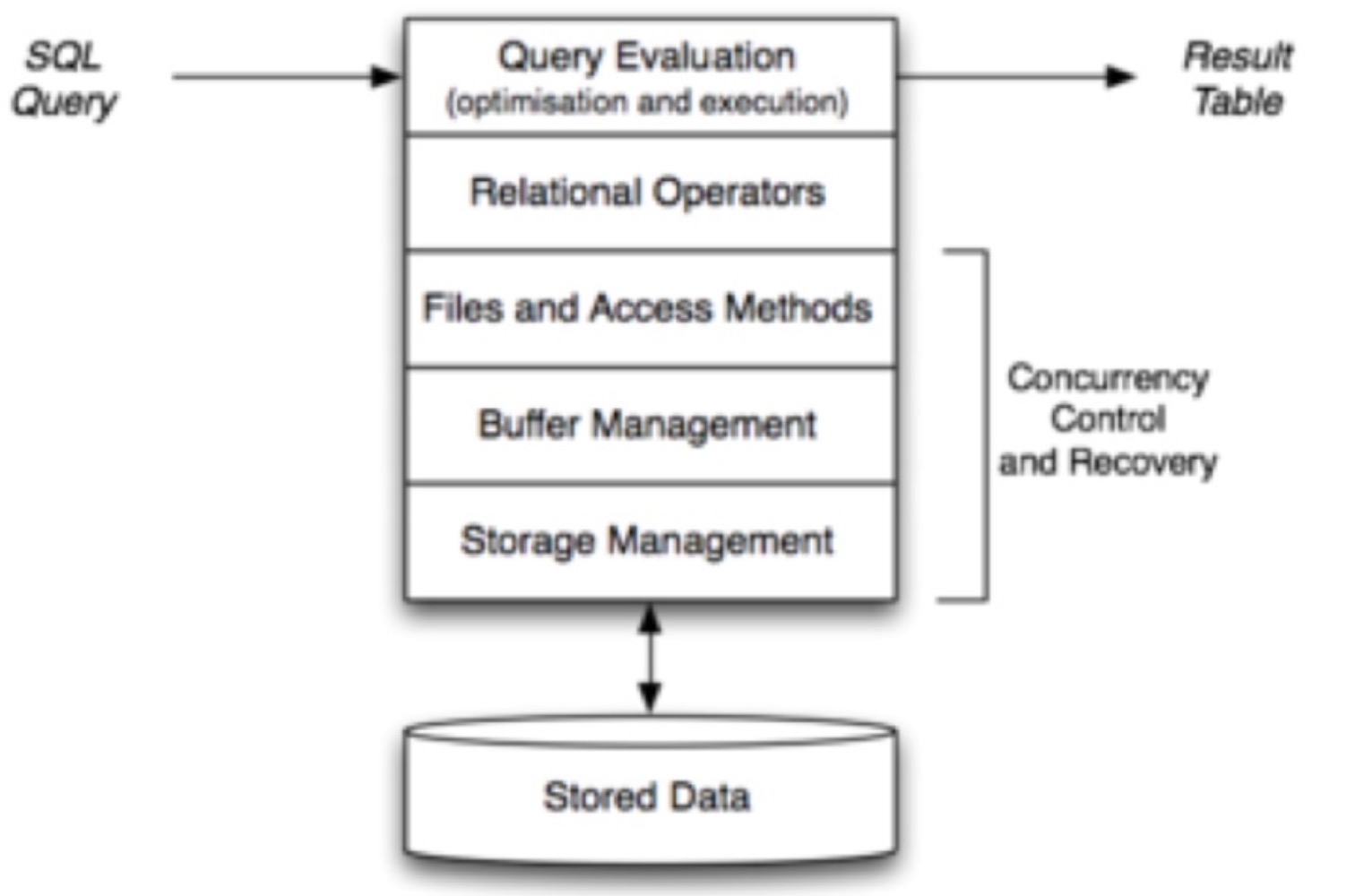
Ramakrishnan/Gerhke (RG) 架构:
PostgreSQL 的实用性
PostgreSQL 的 SQL 大多数是标准的(但有扩展)。
用户层面可见的差异:
- 属性包含原子值的数组
- 表类型继承,表值函数
实现层面的差异:
- 引用完整性检查是通过触发器完成的
- 视图是通过查询重写规则实现
PostgreSQL 存储过程与 SQL 标准不同
- 只提供函数,不提供过程(但函数可以返回 void)
- 允许函数重载(相同的函数名称,不同的参数类型)
- 为函数提供自己的类似 PL/SQL 的语言
并发是通过多版本并发控制(MVCC,Multi-Version Concurrency Control)来处理的
- 数据库存在多个“版本”
- 事务可以看到在开始时有效的版本
- 读与写操作不会相互阻塞
- 旧版本元组的需要额外的存储
允许事务对并发指定一致性级别
- 读取-提交级别(允许有一些不一致),可序列化级别(不允许有不一致)
- 默认隔离级别是读取-提交级别
显式的锁定也是可以使用的
- 不同的类型:共享锁/独占锁,行锁/表锁
- 通过超时的方式来检测死锁的存在
PostgreSQL 有一个定义明确且开放的可扩展性模型
- 存储过程作为字符串保存在数据库中,允许使用各种语言,语言解释器可以集成到 PostgreSQL 引擎中。
- 可以添加新的数据类型、运算符、聚合、索引,通常需要用 C 语言编写代码,遵循相应的 API。对于新的数据类型,需要编写输入/输出函数。对于新的索引,需要实现文件结构。
- 有额外的数据类型:嵌入式的(几何、点、线等等)、分布式的(复数、ISBN/ISSN、加密密码)。
- 更广泛的访问方法:B 树、线性散列、R 树、GiST/GIN 索引、全文索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号