数仓:基于Docker搭建大数据集群
集群规划
| cluster-master | cluster-slave1 | cluster-slave2 | cluster-slave3 | |
|---|---|---|---|---|
| IP | 172.20.0.2 | 172.20.0.3 | 172.20.0.4 | 172.20.0.5 |
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode | DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager | NodeManager |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper | Zookeeper |
| Kafka | Kafka | Kafka | Kafka | Kafka |
| Flume(采集日志) | Flume | Flume |
Docker 使用
下载 Centos 镜像
(base) quanjunyi@Tys-MacBook-Pro ~ % docker pull daocloud.io/library/centos:7
7: Pulling from library/centos
75f829a71a1c: Pull complete
Digest: sha256:fe2347002c630d5d61bf2f28f21246ad1c21cc6fd343e70b4cf1e5102f8711a9
Status: Downloaded newer image for daocloud.io/library/centos:7
daocloud.io/library/centos:7
创建子网
创建容器时需要设置固定 IP,所以先要在 docker 中创建固定 IP 的子网。
(base) quanjunyi@Tys-MacBook-Pro ~ % docker network create --subnet=172.20.0.0/16 netgroup
ec438fc074c00d1ee3643615ad746f766fc8422f6e6450e64bf1331c9ce3d76e
创建容器
子网创建完成之后就可以创建固定 IP 的容器了。
# cluster-master
# -p 设置 docker 映射到容器的端口 后续查看 web 管理页面使用
# --platform linux/amd64 如果是mac需要添加此参数
docker run -d --privileged -ti --platform linux/amd64 --name cluster-master -h cluster-master -p 18088:18088 -p 9870:9870 --net netgroup --ip 172.20.0.2 daocloud.io/library/centos:7 /usr/sbin/init
# cluster-slaves
docker run -d --privileged -ti --platform linux/amd64 --name cluster-slave1 -h cluster-slave1 --net netgroup --ip 172.20.0.3 daocloud.io/library/centos:7 /usr/sbin/init
docker run -d --privileged -ti --platform linux/amd64 --name cluster-slave2 -h cluster-slave2 --net netgroup --ip 172.20.0.4 daocloud.io/library/centos:7 /usr/sbin/init
docker run -d --privileged -ti --platform linux/amd64 --name cluster-slave3 -h cluster-slave3 --net netgroup --ip 172.20.0.5 daocloud.io/library/centos:7 /usr/sbin/init
进入容器
创建完容器之后就可以进入容器了。
# 进入 cluster-master 容器
docker exec -it cluster-master /bin/bash
免密登录
cluster-master安装以下
# cluster-master需要修改配置文件(特殊)
# 安装openssh
yum -y install openssh openssh-server openssh-clients
# 开启服务
systemctl start sshd
# 执行上面脚本时,报错 Failed to get D-Bus connection: No such file or directory
# 解决方法:将下面配置文件中的 "deprecatedCgroupv1": false 改为 true,然后重启 Docker,重新生成容器
# https://blog.csdn.net/weixin_44338712/article/details/127028369
vi ~/Library/Group\ Containers/group.com.docker/settings.json
# 设置 StrictHostKeyChecking:no
vi /etc/ssh/ssh_config
# 重启服务
systemctl restart sshd
- 分别对
slaves安装OpenSSH
yum -y install openssh openssh-server openssh-clients
systemctl start sshd
cluster-master公钥分发
在 master 上执行 ssh-keygen -t rsa 并一路回车,完成之后会生成 ~/.ssh 目录,目录下有 id_rsa (私钥文件)和 id_rsa.pub(公钥文件),再将 id_rsa.pub 重定向到文件 authorized_keys
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
需要先设置 slave 服务器密码。
# 在 slave 机器上执行以下命令,设置密码为root
passwd
文件生成之后在 master 上用 scp 将公钥文件分发到集群 slave 主机。
ssh root@cluster-slave1 'mkdir ~/.ssh'
scp ~/.ssh/authorized_keys root@cluster-slave1:~/.ssh
ssh root@cluster-slave2 'mkdir ~/.ssh'
scp ~/.ssh/authorized_keys root@cluster-slave2:~/.ssh
ssh root@cluster-slave3 'mkdir ~/.ssh'
scp ~/.ssh/authorized_keys root@cluster-slave3:~/.ssh
分发完成之后,测试是否已经可以免输入密码登录。
[root@cluster-master /]# ssh root@cluster-slave1
[root@cluster-slave1 ~]# exit
logout
Connection to cluster-slave1 closed.
Ansible 安装
安装并配置
Ansible 是自动化运维工具,基于 Python 开发,集合了众多运维工具(puppet、cfengine、chef、func、fabric)的优点,实现了批量系统配置、批量程序部署、批量运行命令等等功能。
# ansible 会被安装到 /etc/ansible 目录下
[root@cluster-master /]# yum -y install epel-release
[root@cluster-master /]# yum -y install ansible
此时再去编辑 ansible 的 hosts 文件。
[root@cluster-master /]# vim /etc/ansible/hosts
# 添加以下内容
[cluster]
cluster-master
cluster-slave1
cluster-slave2
cluster-slave3
[master]
cluster-master
[slaves]
cluster-slave1
cluster-slave2
cluster-slave3
配置容器 hosts
由于 /etc/hosts 文件在容器启动时被重写,直接修改内容在容器重启后不能保留,为了让容器在重启之后获取集群 hosts,使用了一种启动容器后重写 hosts 的方法。需要在 ~/.bashrc 中追加以下指令。
[root@cluster-master /]# vim ~/.bashrc
:>/etc/hosts
cat >>/etc/hosts<<EOF
127.0.0.1 localhost
172.20.0.2 cluster-master
172.20.0.3 cluster-slave1
172.20.0.4 cluster-slave2
172.20.0.5 cluster-slave3
EOF
[root@cluster-master /]# source ~/.bashrc
使配置文件生效后,可以看到 /etc/hosts 文件已经被改为需要的内容。
[root@cluster-master /]# cat /etc/hosts
127.0.0.1 localhost
172.20.0.2 cluster-master
172.20.0.3 cluster-slave1
172.20.0.4 cluster-slave2
172.20.0.5 cluster-slave3
用 ansible 分发 .bashrc 至集群 slave 下。
[root@cluster-master /]# ansible cluster -m copy -a "src=~/.bashrc dest=~/"
安装 Java
上传并解压
上传 JDK1.8 并解压缩至 /opt/module 目录下。
# 将主机上的jdk压缩包上传到master的/opt目录下
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp jdk-8u212-linux-x64.tar.gz cluster-master:/opt/
# 创建目录
[root@cluster-master opt]# mkdir /opt/module
# 解压master的jdk
[root@cluster-master /]# tar -zxvf /opt/jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置环境
编辑 ~/.bashrc 文件。
[root@cluster-master module]# vim ~/.bashrc
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
# 使文件生效
[root@cluster-master module]# source ~/.bashrc
# 测试
[root@cluster-master module]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
分发文件
ansible 主机节点编辑剧本。
# 将jdk1.8.0_212压缩为jdk-dis.tar
[root@cluster-master opt]# tar -cvf /opt/module/jdk-dis.tar /opt/module/jdk1.8.0_212/
编写分发配置文件 jdk-dis.yaml。
[root@cluster-master opt]# vim jdk-dis.yaml
---
- hosts: cluster
tasks:
- name: copy .bashrc to slaves
copy: src=~/.bashrc dest=~/
notify:
- exec source
- name: copy jdk-dis.tar to slaves
unarchive: src=/opt/module/jdk-dis.tar dest=/
handlers:
- name: exec source
shell: source ~/.bashrc
# jdk-dis.tar会自动解压到slave主机的/opt/module目录下
[root@cluster-master opt]# ansible-playbook jdk-dis.yaml
安装 Hadoop
上传并解压
上传 Hadoop 并解压至 /opt/module 目录下。
# 将主机上的hadoop压缩包上传到master的/opt目录下
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp hadoop-3.1.3.tar.gz cluster-master:/opt/
# 解压master的hadoop
[root@cluster-master opt]# tar -zxvf /opt/hadoop-3.1.3.tar.gz -C /opt/module/
配置环境
编辑 ~/.bashrc 文件。
[root@cluster-master module]# vim ~/.bashrc
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 使文件生效
[root@cluster-master module]# source ~/.bashrc
配置文件
配置 hadoop 运行所需配置文件。
- 配置核心文件
[root@cluster-master module]# cd $HADOOP_HOME/etc/hadoop/
[root@cluster-master hadoop]# vim core-site.xml
<configuration>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster-master:8020</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为qjy -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>qjy</value>
</property>
<!-- 配置qjy(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.qjy.hosts</name>
<value>*</value>
</property>
<!-- 配置该qjy(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.qjy.groups</name>
<value>*</value>
</property>
<!-- 配置该qjy(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.qjy.users</name>
<value>*</value>
</property>
<!-- 以分钟为单位的垃圾回收时间 -->
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
</configuration>
- HDFS 配置文件
[root@cluster-master hadoop]# vim hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>cluster-master:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cluster-slave2:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 存放hadoop的名称节点namenode里的metadata -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/tmp/dfs/name</value>
</property>
<!-- 存放hadoop的数据节点datanode里的多个数据块 -->
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/data</value>
</property>
<!-- 开启webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 关闭权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
- MapReduce 配置文件
[root@cluster-master hadoop]# vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>cluster-master:9001</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>cluster-master:50030</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhisotry.address</name>
<value>cluster-master:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cluster-master:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/jobhistory/done</value>
</property>
<property>
<name>mapreduce.intermediate-done-dir</name>
<value>/jobhisotry/done_intermediate</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
</configuration>
- YARN 配置文件
[root@cluster-master hadoop]# vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cluster-slave1</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://cluster-master:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
- 配置 workers
[root@cluster-master hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
cluster-master
cluster-slave1
cluster-slave2
cluster-slave3
分发文件
ansible 主机节点编辑剧本。
# 将jdk1.8.0_212压缩为jdk-dis.tar
[root@cluster-master opt]# tar -cvf /opt/module/hadoop-dis.tar /opt/module/hadoop-3.1.3/
编写分发配置文件 hadoop-dis.yaml。
[root@cluster-master opt]# vim hadoop-dis.yaml
---
- hosts: cluster
tasks:
- name: copy .bashrc to slaves
copy: src=~/.bashrc dest=~/
notify:
- exec source
- name: copy hadoop-dis.tar to slaves
unarchive: src=/opt/module/hadoop-dis.tar dest=/
handlers:
- name: exec source
shell: source ~/.bashrc
# hadoop-dis.tar会自动解压到slave主机的/opt/module目录下
[root@cluster-master opt]# ansible-playbook hadoop-dis.yaml
主节点修改环境变量
[root@cluster-master opt]# vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
启动 Hadoop
- 如果集群是第一次启动,需要在
cluster-master节点格式化namenode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@cluster-master hadoop-3.1.3]# bin/hdfs namenode -format
- 启动 HDFS
[root@cluster-master hadoop-3.1.3]# sbin/start-dfs.sh
- 在配置了
ResourceManager的节点(cluster-slave1)启动 YARN
[root@cluster-slave1 hadoop-3.1.3]# sbin/start-yarn.sh
- Web 端查看 HDFS 的 Web 页面:http://172.20.0.2:9870
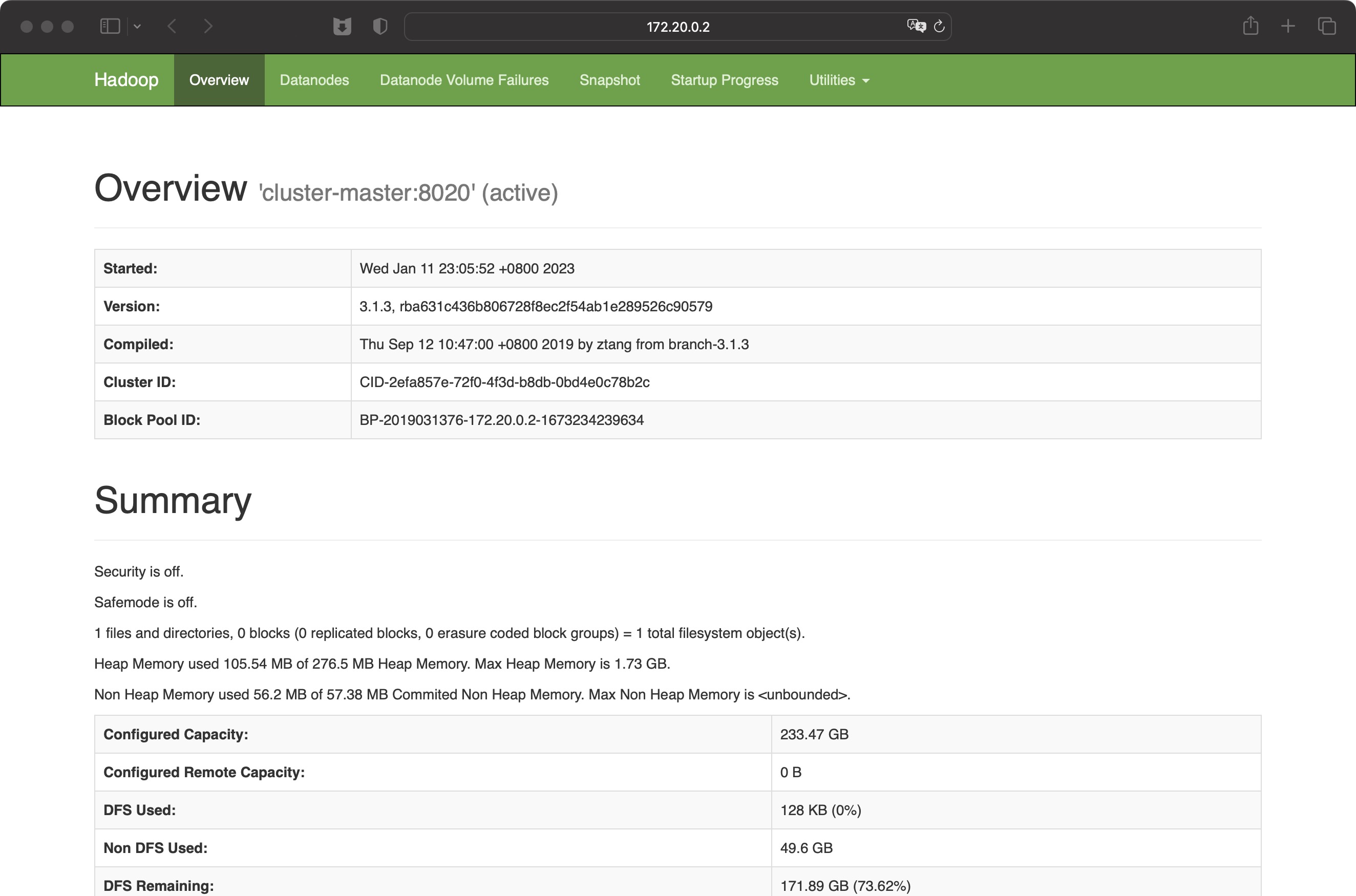
- Web 端查看 Yarn 的 Web 页面:http://172.20.0.3:8088

Hadoop 群起脚本
[root@cluster-master home]# mkdir -p /home/qjy/bin
[root@cluster-master home]# cd /home/qjy/bin/
[root@cluster-master bin]# vim hdp.sh
[root@cluster-master bin]# chmod 777 hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== start hadoop cluster ==================="
echo " --------------- start hdfs ---------------"
ssh cluster-master "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- start yarn ---------------"
ssh cluster-slave1 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- start historyserver ---------------"
ssh cluster-master "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== stop hadoop cluaster ==================="
echo " --------------- stop historyserver ---------------"
ssh cluster-master "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- stop yarn ---------------"
ssh cluster-slave1 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- stop hdfs ---------------"
ssh cluster-master "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
查看集群进程脚本
[root@cluster-master module]# cd /home/qjy/bin/
[root@cluster-master bin]# vim xcall
[root@cluster-master bin]# chmod 777 xcall
[root@cluster-master qjy]# bin/xcall jps
for i in cluster-master cluster-slave1 cluster-slave2 cluster-slave3
do
echo "-------------$i-------------"
ssh $i "$*"
done
安装 Zookeeper
上传并解压
上传 Zookeeper 并解压缩至 /opt/module 目录下。
# 将主机上的zookeeper压缩包上传到master的/opt目录下
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp apache-zookeeper-3.5.7-bin.tar.gz cluster-master:/opt/
# 解压master的zookeeper
[root@cluster-master opt]# tar -zxvf /opt/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
# 修改文件名
[root@cluster-master module]# mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
配置服务器编号
- 在
/opt/module/zookeeper-3.5.7/这个目录下创建zkData
[root@cluster-master module]# cd zookeeper-3.5.7/
[root@cluster-master zookeeper-3.5.7]# mkdir zkData
- 在
/opt/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件,在文件中添加与 server 对应的编号
[root@cluster-master zkData]# vim myid
2
配置 zoo.cfg 文件
- 重命名
/opt/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
[root@cluster-master conf]# mv zoo_sample.cfg zoo.cfg
- 修改
zoo.cfg文件
[root@cluster-master conf]# vim zoo.cfg
# 修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
# 增加如下配置
# zoo.cfg配置参数解读server.A=B:C:D
# A是一个数字,表示这个是第几号服务器,Zookeeper启动时会读取myid文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
# B是这个服务器的地址
# C是这个服务器Follower与集群中的Leader服务器交换信息的端口
# D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
server.2=cluster-master:2888:3888
server.3=cluster-slave1:2888:3888
server.4=cluster-slave2:2888:3888
server.5=cluster-slave3:2888:3888
- 同步
/opt/module/zookeeper-3.5.7目录内容到 cluster-slave1、cluster-slave2、cluster-slave3
# 将zookeeper-3.5.7压缩为zookeeper-dis.tar
[root@cluster-master opt]# tar -cvf /opt/module/zookeeper-dis.tar /opt/module/zookeeper-3.5.7/
[root@cluster-master opt]# vim zookeeper-dis.yaml
---
- hosts: cluster
tasks:
- name: copy zookeeper-dis.tar to slaves
unarchive: src=/opt/module/zookeeper-dis.tar dest=/
# zookeeper-dis.tar会自动解压到slave主机的/opt/module目录下
[root@cluster-master opt]# ansible-playbook zookeeper-dis.yaml
- 分别修改 cluster-slave1、cluster-slave2、cluster-slave3 上的
myid文件中内容为 3、4、5
集群操作
- 分别启动 Zookeeper
[root@cluster-master zookeeper-3.5.7]# bin/zkServer.sh start
[root@cluster-slave1 zookeeper-3.5.7]# bin/zkServer.sh start
[root@cluster-slave2 zookeeper-3.5.7]# bin/zkServer.sh start
[root@cluster-slave3 zookeeper-3.5.7]# bin/zkServer.sh start
- 查看状态
[root@cluster-master zookeeper-3.5.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@cluster-slave1 zookeeper-3.5.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@cluster-slave2 zookeeper-3.5.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@cluster-slave3 zookeeper-3.5.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
Zookeeper 群起脚本
[root@cluster-master zookeeper-3.5.7]# cd /home/qjy/bin
[root@cluster-master bin]# vim zk.sh
# 增加脚本执行权限
[root@cluster-master bin]# chmod 777 zk.sh
# Zookeeper集群启动脚本
[root@cluster-master qjy]# bin/zk.sh start
# Zookeeper集群停止脚本
[root@cluster-master qjy]# bin/zk.sh stop
# Zookeeper集群查看状态脚本
[root@cluster-master qjy]# bin/zk.sh status
#!/bin/bash
case $1 in
"start"){
for i in cluster-master cluster-slave1 cluster-slave2 cluster-slave3
do
echo "---------- zookeeper " $i " start ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in cluster-master cluster-slave1 cluster-slave2 cluster-slave3
do
echo "---------- zookeeper " $i "stop ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in cluster-master cluster-slave1 cluster-slave2 cluster-slave3
do
echo "---------- zookeeper " $i " status ------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
安装 Kafka
上传并解压
上传 Kafka 并解压缩至 /opt/module 目录下。
# 将主机上的Kafka压缩包上传到master的/opt目录下
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp kafka_2.12-3.0.0.tgz cluster-master:/opt/
# 解压master的Kafka
[root@cluster-master opt]# tar -zxvf /opt/kafka_2.12-3.0.0.tgz -C /opt/module/
修改配置文件
进入到 /opt/module/kafka_2.12-3.0.0 目录,修改配置文件。
[root@cluster-master kafka_2.12-3.0.0]# cd config/
[root@cluster-master config]# vim server.properties
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka_2.12-3.0.0/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=cluster-master:2181,cluster-slave1:2181,cluster-slave2:2181,cluster-slave2:2181,cluster-slave3:2181/kafka
分发文件
# 将kafka_2.12-3.0.0压缩为kafka-dis.tar
[root@cluster-master opt]# tar -cvf /opt/module/kafka-dis.tar /opt/module/kafka_2.12-3.0.0/
[root@cluster-master opt]# vim kafka-dis.yaml
---
- hosts: cluster
tasks:
- name: copy kafka-dis.tar to slaves
unarchive: src=/opt/module/kafka-dis.tar dest=/
# kafka-dis.tar会自动解压到slave主机的/opt/module目录下
[root@cluster-master opt]# ansible-playbook kafka-dis.yaml
分别在 cluster-slave1、cluster-slave2、cluster-slave3 上修改配置文件 /opt/module/kafka_2.12-3.0.0/config/server.properties 中的 broker.id=1、broker.id=2、broker.id=3。
配置环境变量
在集群所有主机的 ~/bashrc 文件中增加 kafka 环境变量配置。
[root@cluster-master opt]# vim ~/.bashrc
# KAFKA
export KAFKA_HOME=/opt/module/kafka_2.12-3.0.0
export PATH=$PATH:$KAFKA_HOME/bin
[root@cluster-master opt]# source ~/.bashrc
启动集群
- 先启动 Zookeeper 集群,然后启动 Kafka
[root@cluster-master qjy]# bin/zk.sh start
- 依次在
cluster-master、cluster-slave1、cluster-slave2、cluster-slave3节点上启动 Kafka
[root@cluster-master kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
[root@cluster-slave1 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
[root@cluster-slave2 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
[root@cluster-slave3 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
- 关闭集群
[root@cluster-master kafka_2.12-3.0.0]# bin/kafka-server-stop.sh
[root@cluster-slave1 kafka_2.12-3.0.0]# bin/kafka-server-stop.sh
[root@cluster-slave2 kafka_2.12-3.0.0]# bin/kafka-server-stop.sh
[root@cluster-slave3 kafka_2.12-3.0.0]# bin/kafka-server-stop.sh
Kafka 群起脚本
[root@cluster-master kafka_2.12-3.0.0]# cd /home/qjy/bin
[root@cluster-master bin]# vim kf.sh
# 增加脚本执行权限
[root@cluster-master bin]# chmod 777 kf.sh
# Kafka集群启动脚本
[root@cluster-master qjy]# bin/kf.sh start
# Kafka集群停止脚本
[root@cluster-master qjy]# bin/kf.sh stop
#! /bin/bash
case $1 in
"start"){
for i in cluster-master cluster-slave1 cluster-slave2 cluster-slave3
do
echo " --------start " $i " Kafka-------"
ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.0.0/config/server.properties"
done
};;
"stop"){
for i in cluster-master cluster-slave1 cluster-slave2 cluster-slave3
do##
echo " --------stop " $i " Kafka-------"
ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-stop.sh "
done
};;
esac
注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper 集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止,Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了。
安装 Flume
上传并解压
上传 Flume 并解压缩至 /opt/module 目录下。
# 将主机上的Flume压缩包上传到master的/opt目录下
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp apache-flume-1.9.0-bin.tar.gz cluster-master:/opt/
# 解压master的Flume
[root@cluster-master opt]# tar -zxvf /opt/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
# 修改文件名
[root@cluster-master module]# mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume-1.9.0
# 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[root@cluster-master module]# rm -rf /opt/module/flume-1.9.0/lib/guava-11.0.2.jar
修改配置文件
修改 conf 目录下的 log4j.properties 配置文件,配置日志文件路径。
[root@cluster-master flume-1.9.0]# vim conf/log4j.properties
flume.log.dir=/opt/module/flume-1.9.0/logs
修改 conf 目录下的 flume-env.sh。
[root@cluster-master conf]# mv flume-env.sh.template flume-env.sh
[root@cluster-master conf]# vim flume-env.sh
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
分发文件
# 将flume-1.9.0压缩为flume-dis.tar
[root@cluster-master opt]# tar -cvf /opt/module/flume-dis.tar /opt/module/flume-1.9.0/
[root@cluster-master opt]# vim flume-dis.yaml
---
- hosts: cluster
tasks:
- name: copy flume-dis.tar to slaves
unarchive: src=/opt/module/flume-dis.tar dest=/
# flume-dis.tar会自动解压到slave主机的/opt/module目录下
[root@cluster-master opt]# ansible-playbook flume-dis.yaml
Flume 群起脚本
[root@cluster-master flume-1.9.0]# cd /home/qjy/bin
[root@cluster-master bin]# vim fl.sh
# 增加脚本执行权限
[root@cluster-master bin]# chmod 777 fl.sh
# flume集群启动脚本
[root@cluster-master qjy]# bin/fl.sh start
# flume集群停止脚本
[root@cluster-master qjy]# bin/fl.sh stop
#!/bin/bash
case $1 in
"start"){
for i in cluster-master cluster-slave3
do
echo " --------start $i flume-------"
ssh $i "nohup /opt/module/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.9.0/conf/ -f /opt/module/flume-1.9.0/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in cluster-master cluster-slave3
do
echo " --------stop $i flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
Flume 实操
需要采集的用户行为日志文件分布在 cluster-master,cluster-slave3 两台日志服务器,故需要在这两台节点配置日志采集 Flume。日志采集 Flume 需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到 Kafka。
模拟数据
# 创建目录/opt/module/applog
[root@cluster-master module]# mkdir applog
# 上传文件到cluster-master、cluster-slave3
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp application.yml cluster-master:/opt/module/applog/
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp gmall2020-mock-log-2021-10-10.jar cluster-master:/opt/module/applog/
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp logback.xml cluster-master:/opt/module/applog/
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp path.json cluster-master:/opt/module/applog/
# 生成日志
[root@cluster-master applog]# java -jar gmall2020-mock-log-2021-10-10.jar
# 在cluster-master、cluster-slave3上一起生成日志的脚本
[root@cluster-master applog]# cd /home/qjy/bin
[root@cluster-master bin]# vim lg.sh
# 增加脚本执行权限
[root@cluster-master bin]# chmod 777 lg.sh
# 启动日志生成脚本
[root@cluster-master qjy]# bin/lg.sh
#!/bin/bash
for i in cluster-master cluster-slave3
do
echo "--------------$i----------------"
ssh $i "cd /opt/module/applog;java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &"
done
创建配置文件
在 cluster-master 节点的 /opt/module/flume-1.9.0/job 目录下创建 file_to_kafka.conf
[root@cluster-master flume-1.9.0]# mkdir job
[root@cluster-master flume-1.9.0]# vim job/file_to_kafka.conf
# 定义组件
a1.sources = r1
a1.channels = c1
# 配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
# 配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = cluster-master:9092, cluster-slave3:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
# 组装
a1.sources.r1.channels = c1
编写拦截器
- 创建 Maven 工程
flume-interceptor - 创建包
com.atguigu.gmall.flume.interceptor - 在
pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<!--provided打包的时候,不会把flume-ng-core这个包打包进去-->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 在
com.atguigu.gmall.flume.utils包下创建JSONUtil类
package com.atguigu.gmall.flume.utils;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONException;
public class JSONUtil {
/*
* 通过异常判断是否是json字符串
* 是:返回true 不是:返回false
* */
public static boolean isJSONValidate(String log){
try {
JSONObject.parseObject(log);
return true;
}catch (JSONException e){
return false;
}
}
}
- 在
com.atguigu.gmall.flume.interceptor包下创建ETLInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.atguigu.gmall.flume.utils.JSONUtil;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 1、获取body当中的数据并转成字符串
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
// 2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回null
if (JSONUtil.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
- 打包

- 需要先将打好的包放入到
cluster-master的/opt/module/flume-1.9.0/lib文件夹下面
(base) quanjunyi@Tys-MacBook-Pro ~ % docker cp flume-interceptor.jar cluster-master:/opt/module/flume-1.9.0/lib
Flume 测试
- 启动 Zookeeper、Kafka 集群
- 启动
cluster-master的日志采集 Flume
[root@cluster-master flume-1.9.0]# bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
- 启动一个 slave3 上 Kafka 的
Console-Consumer
[root@cluster-slave3 kafka_2.12-3.0.0]# bin/kafka-console-consumer.sh --bootstrap-server cluster-master:9092 --topic topic_log
- 生成模拟数据
[root@cluster-master qjy]# bin/lg.sh
踩坑
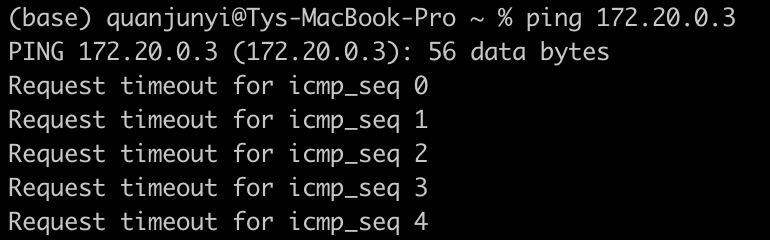
关于 Mac 宿主机无法 ping 通 Docker 容器的问题
在 Mac 上启动 docker 容器以后,宿主机 ping 不通容器的ip。
原因是 Mac 和 Docker 是物理隔离的,对于 docker run 启动的容器来说,通常会通过 -p 参数映射相应的服务端口,一般不会遇到要直接访问容器 IP 的情况。但是当我们在 docker 中运行多个微服务并想进行本地调试的时候,在 Mac 上却没法实现。
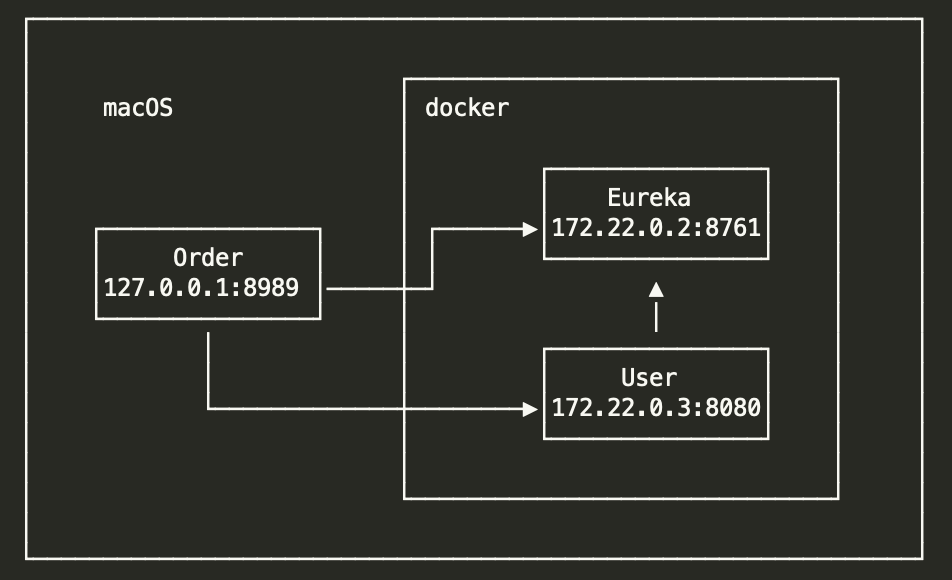
Eureka Server 和 User 服务均存在于容器中,本地调试 Order 服务。Order 需要调用 User,但是我们在本机上是访问不到 172.22.0.3:8080 的。
解决方法:
- 首先 Mac 端通过
brew安装docker-connector
(base) quanjunyi@Tys-MacBook-Pro ~ % brew install wenjunxiao/brew/docker-connector
- 手动修改
/opt/homebrew/etc/docker-connector.conf文件中的路由
(base) quanjunyi@Tys-MacBook-Pro ~ % vim /opt/homebrew/etc/docker-connector.conf
route 172.20.0.0/16
(base) quanjunyi@Tys-MacBook-Pro ~ % docker network ls --filter driver=bridge --format "{{.ID}}" | xargs docker network inspect --format "route {{range .IPAM.Config}}{{.Subnet}}{{end}}" >> /opt/homebrew/etc/docker-connector.conf
- 配置完成,直接启动服务(需要
sudo,路由配置启动之后仍然可以修改,并且无需重启服务立即生效),需要输入本机密码
(base) quanjunyi@Tys-MacBook-Pro ~ % sudo brew services start docker-connector
Error: Running Homebrew as root is extremely dangerous and no longer supported.
# sudo会报上述错误,所以去掉了sudo,亲测也可以
- 使用一下命令在 docker 端运行
wenjunxiao/mac-docker-connector
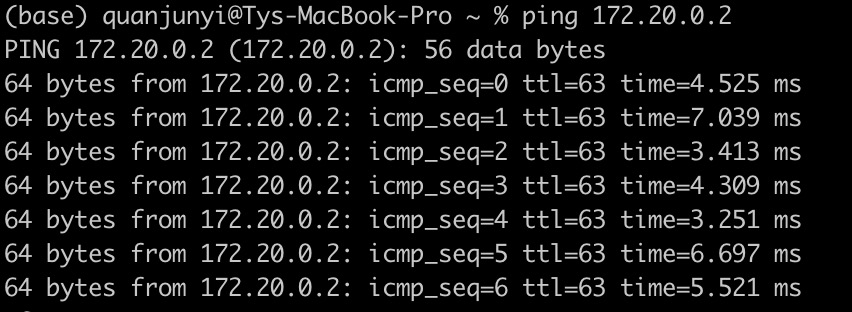
(base) quanjunyi@Tys-MacBook-Pro ~ % docker run -it -d --restart always --net host --cap-add NET_ADMIN --name connector wenjunxiao/mac-docker-connector
- 安装完成,重试 ping 操作,重启后需要再执行第三步(此时可以加
sudo)
启动 yarn 报错
[root@cluster-slave1 hadoop-3.1.3]# sbin/start-yarn.sh
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
出现以上报错信息需要到 sbin 目录下 更改 start-yarn.sh 和 stop-yarn.sh 信息,在两个配置文件的第一行添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
NodeManager 未启动
[root@cluster-slave1 hadoop-3.1.3]# sbin/start-yarn.sh
Starting resourcemanager
Last login: Tue Jan 10 14:04:20 UTC 2023
Starting nodemanagers
Last login: Wed Jan 11 15:11:01 UTC 2023 on pts/2
cluster-slave3: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
cluster-slave2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
cluster-master: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
localhost: nodemanager is running as process 14516. Stop it first.
NodeManager 只在 slave1 本机上启动了,集群中其他节点均为启动。原因是免密登录只配置了 master 到 slave1、2、3,而没有配置 slave1 到 master、slave2、slave3 的。
[root@cluster-slave1 hadoop-3.1.3]# cd ~/.ssh/
[root@cluster-slave1 .ssh]# ssh-keygen -t rsa
# 由于之前只在slave上设置了密码,因此,要对master单独设置一次密码,密码为root
[root@cluster-master qjy]# passwd
Changing password for user root.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
[root@cluster-slave1 .ssh]# ssh-copy-id cluster-master
[root@cluster-slave1 .ssh]# ssh-copy-id cluster-slave1
[root@cluster-slave1 .ssh]# ssh-copy-id cluster-slave2
[root@cluster-slave1 .ssh]# ssh-copy-id cluster-slave3
# 重启yarn,NodeManager就都启动了
[root@cluster-slave1 hadoop-3.1.3]# sbin/stop-yarn.sh
[root@cluster-slave1 hadoop-3.1.3]# sbin/start-yarn.sh
Slave3 的 Datanode 未启动
查看 slave3 的 /opt/module/hadoop-3.1.3/logs/hadoop-root-datanode-cluster-slave3.log 日志文件。
2023-01-10 15:04:11,025 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.net.BindException: Problem binding to [0.0.0.0:9866] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:831)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:736)
at org.apache.hadoop.ipc.Server.bind(Server.java:621)
at org.apache.hadoop.ipc.Server.bind(Server.java:593)
at org.apache.hadoop.hdfs.net.TcpPeerServer.<init>(TcpPeerServer.java:52)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initDataXceiver(DataNode.java:1141)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1417)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:501)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:2806)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:2714)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:2756)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:2900)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2924)
Caused by: java.net.BindException: Address already in use
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at org.apache.hadoop.ipc.Server.bind(Server.java:604)
... 10 more
意思就是说 slave3 的 9866 端口号被占用了。
- 首先查看谁占用了端口号
[root@cluster-slave3 logs]# netstat -anp | grep 9866
tcp 0 0 0.0.0.0:9866 0.0.0.0:* LISTEN 6760/qemu-x86_64
- 然后查看进程的具体信息
[root@cluster-slave3 logs]# ps -ef | grep 6760
root 6760 1 0 06:52 ? 00:00:00 /usr/bin/qemu-x86_64 /opt/module/jdk1.8.0_212/bin/java /opt/module/jdk1.8.0_212/bin/java -Dproc_datanode -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS -Dyarn.log.dir=/opt/module/hadoop-3.1.3/logs -Dyarn.log.file=hadoop-root-datanode-cluster-slave3.log -Dyarn.home.dir=/opt/module/hadoop-3.1.3 -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/module/hadoop-3.1.3/lib/native -Dhadoop.log.dir=/opt/module/hadoop-3.1.3/logs -Dhadoop.log.file=hadoop-root-datanode-cluster-slave3.log -Dhadoop.home.dir=/opt/module/hadoop-3.1.3 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.datanode.DataNode
root 8194 188 0 14:58 pts/1 00:00:00 /usr/bin/qemu-x86_64 /usr/bin/grep grep --color=auto 6760
- 可以
kill -9 3307结束进程 , 重新启动 datanode 启动成功。
[root@cluster-slave3 logs]# kill -9 6760
zookeeper 错误
# 查看状态时报如下错误
[root@cluster-master zookeeper-3.5.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Error contacting service. It is probably not running.
可能是 zoo.cfg 配置参数 server.A=B:C:D 中的 B 用的是主机名,zookeeper 没有办法识别,尝试换成 IP,但是没有效果。
# 采用前台启动的方式再次启动,发现启动报错
[root@cluster-master zookeeper-3.5.7]# bin/zkServer.sh start-foreground
2023-01-09 07:39:24,010 [myid:] - ERROR [main:QuorumPeerMain@89] - Invalid config, exiting abnormally org.apache.zookeeper.server.quorum.QuorumPeerConfig$ConfigException: Error processing /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:156) at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:113) at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:82) Caused by: java.lang.IllegalArgumentException: myid file is missing at org.apache.zookeeper.server.quorum.QuorumPeerConfig.checkValidity(QuorumPeerConfig.java:736) at org.apache.zookeeper.server.quorum.QuorumPeerConfig.setupQuorumPeerConfig(QuorumPeerConfig.java:607) at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parseProperties(QuorumPeerConfig.java:422) at org.apache.zookeeper.server.quorum.QuorumPeerConfig.parse(QuorumPeerConfig.java:152)
... 2 more
Invalid config, exiting abnormally
原因是 myid 文件不存在,但是我确定已经编写了 myid 文件了。最后发现,myid 文件放在了 /opt/module/zookeeper-3.5.7 目录下了,应该放在 /opt/module/zookeeper-3.5.7/zkData 目录下。
[root@cluster-master zookeeper-3.5.7]# mv myid zkData/
flume 报错
[root@cluster-master flume-1.9.0]# bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume-1.9.0/lib/flume-interceptor.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/flume-1.9.0/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html
SLF4J: slf4j-api 1.6.x (or later) is incompatible with this binding.
SLF4J: Your binding is version 1.5.5 or earlier.
SLF4J: Upgrade your binding to version 1.6.x.
启动 Flume 时,找到了多个 SLF4J bindings(绑定)。
启动 Flume 时,在 /flume-1.9.0 目录下找到了 SLF4J,又在 /hadoop-3.1.3 目录下找到了 SLF4J。由于 Flume 是 Hadoop 生态的一个日志采集工具,所以当启动 Flume 后,Flume 就会去加载 Hadoop_HOME 中的类,所以启动时可以看到加载了许多 Hadoop 下的包,当 SLF4J 时,在 Flume 自己目录下也有 SLF4J,就导致了类的冲突,而且版本不一样。
解决方法:将该 jar 包重命名为 .jar.bak 结尾的文件,bak 表示 backup(备份)。
[root@cluster-master module]# mv flume-1.9.0/lib/slf4j-log4j12-1.7.25.jar /opt/module/flume-1.9.0/lib/slf4j-log4j12-1.7.25.jar.bak
[root@cluster-master flume-1.9.0]# mv /opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar /opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar.bak
进行上述操作之后,还有如下错误:
SLF4J: slf4j-api 1.6.x (or later) is incompatible with this binding.
SLF4J: Your binding is version 1.5.5 or earlier.
SLF4J: Upgrade your binding to version 1.6.x.
在最开始的错误中,是有我上传的 jar 文件的目录的,所以可能是打包出现问题,把依赖包也打包进去了。因此尝试重新打包,上传。
再次启动 Flume 后(未配置拦截器),报如下错误:
# Agent没有配置configfilters,没有关系
2023-01-12 06:04:24,181 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'a1' has no configfilters.
# Agent没有配置sink,没有关系
2023-01-12 06:04:24,505 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateSinks(FlumeConfiguration.java:809)] Agent configuration for 'a1' has no sinks.
# 这是因为在配置文件job/file_to_kafka.conf中配置了a1.sources.r1.interceptors=i1,却没有a1.sources.r1.interceptors.i1.type=com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder。可以先把a1.sources.r1.interceptors=i1这行配置去掉。
2023-01-12 06:04:25,530 (conf-file-poller-0) [ERROR - org.apache.flume.channel.ChannelProcessor.configureInterceptors(ChannelProcessor.java:106)] Type not specified for interceptor i1
2023-01-12 06:04:25,556 (conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSources(AbstractConfigurationProvider.java:355)] Source r1 has been removed due to an error during configuration
org.apache.flume.FlumeException: Interceptor.Type not specified for i1
at org.apache.flume.channel.ChannelProcessor.configureInterceptors(ChannelProcessor.java:107)
at org.apache.flume.channel.ChannelProcessor.configure(ChannelProcessor.java:82)
at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
at org.apache.flume.node.AbstractConfigurationProvider.loadSources(AbstractConfigurationProvider.java:342)
at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:105)
at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:145)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
# 无关
2023-01-12 06:04:25,574 (conf-file-poller-0) [WARN - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:111)] Channel c1 has no components connected and has been removed.
然后就可以成功的启动 Flume 了,但是在启动 slave3 上 Kafka 的消费者之后,Flume 又报以下错误:
# 这是因为slave3没有启动kafka
2023-01-13 06:39:59,171 (PollableSourceRunner-TaildirSource-r1) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:565)] Sending events to Kafka failed
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Expiring 28 record(s) for topic_log-0: 30006 ms has passed since last append
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:94)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:64)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:29)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:557)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194)
at org.apache.flume.source.taildir.TaildirSource.tailFileProcess(TaildirSource.java:276)
at org.apache.flume.source.taildir.TaildirSource.process(TaildirSource.java:239)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.kafka.common.errors.TimeoutException: Expiring 28 record(s) for topic_log-0: 30006 ms has passed since last append
2023-01-13 06:39:59,185 (PollableSourceRunner-TaildirSource-r1) [WARN - org.apache.flume.source.taildir.TaildirSource.tailFileProcess(TaildirSource.java:279)] The channel is full or unexpected failure. The source will try again after 5000 ms
kafka 报错
在进行 Flume 实操的过程中,启动 Flume 后,在启动 slave1 上 Kafka 的消费者之后,在 master 上生成日志数据时,slave1 上控制台报如下错误:
[2023-01-12 06:06:18,418] WARN [Consumer clientId=consumer-console-consumer-27952-1, groupId=console-consumer-27952] Connection to node 2147483645 (cluster-slave2/172.20.0.4:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
这是因为 Flume 启动加载的配置文件如下:
a1.channels.c1.kafka.bootstrap.servers = cluster-master:9092, cluster-slave3:9092
所以应该是启动 slave3 上 Kafka 的消费者。
参考文章
https://www.cnblogs.com/luo-c/p/15830769.html
https://blog.csdn.net/qq_15604349/article/details/123717540
https://blog.csdn.net/weixin_47243236/article/details/121448677
https://blog.csdn.net/weixin_39453361/article/details/103689831

 浙公网安备 33010602011771号
浙公网安备 33010602011771号