基于隐式反馈的推荐算法MFLogLoss
论文:Christopher C. Johnson. Logistic matrix factorization for implicit feedback data [C]. In: Proceedings of the Workshop on Distributed Machine Learning and Matrix Computations at NeurIPS 2014.https://web.stanford.edu/~rezab/nips2014workshop/submits/logmat.pdf
数据集:ML1M数据集 https://grouplens.org/datasets/movielens/1m/
单类协同过滤问题定义和数据集描述
问题定义
单类反馈:能获得的数据并没有评分这种类型的数据,而是一种行为是否发生,比如用户听音乐,可获取的数据大都是单类反馈的,即用户是否听过这首歌。
单类协同过滤:用户与物品之间发生过交集,就作上标记1,表示用户可能喜欢,作为正样本,而没有发生过行为的用户-物品对,也就是缺失值,用户也可能会喜欢。但是缺失值相对于正样本来说是非常多的,所以从缺失值中采样一部分作为负样本。然后通过模型训练,使得用户对正样本的预测分数越高越好,而对负样本的预测分数越低越好。
数据集描述
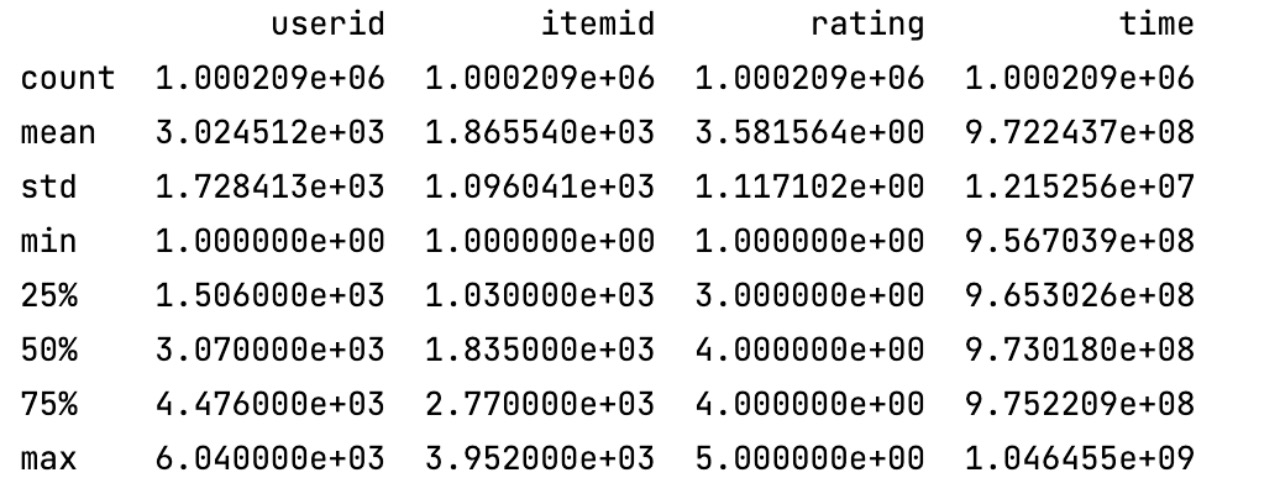
所有的评分数据都包含在ratings.dat中,其结构为‘UserID::MovieID::Rating::Timestamp’
-
UserID:用户的ID,范围在1到6040
-
MovieID:电影的ID,范围在1到3952
-
Rating:用户u对电影i的评分,共五个阶段
-
Timestamp:评分行为的发生时间
每一个用户至少有20条评分。
基于矩阵分解的单类协同过滤推荐方法和实验
符号说明
| 符号 | 含义 |
|---|---|
| \(n\) | 用户数量 |
| \(m\) | 物品数量 |
| \(u\in\left\{1,2,...,n\right\}\) | 用户 id |
| \(i,i'\in\left\{1,2,...,m\right\}\) | 物品 id |
| \(P\) | 正样本集(观测到的用户-物品对) |
| \(A,|A|=\rho|P|\) | 负样本集(没有观测到的用户-物品对) |
| \(r_{ui}\) | 对于具体的用户 u 和物品 i,如果(u,i)属于正样本,则为1,负样本为-1 |
| \(b_u\in{R}\) | 用户 bias |
| \(b_i\in{R}\) | 物品 bias |
| \(d\in{R}\) | 特征维度 |
| \(V_i\in{R}^{1*d}\) | 物品 i 在物品空间的特征向量 |
| \(V\in{R}^{m*d}\) | 物品的特征矩阵 |
| \(U_u\in{R}^{1*d}\) | 用户 u 在用户空间的特征向量 |
| \(U\in{R}^{n*d}\) | 用户的特征矩阵 |
方法形式化
用户 u 对物品 i 的预测分数:
\(\hat{r}_{ui}=b_u+b_i+U_{u\cdot}V{i\cdot}^T\)
MFLogLoss 的目标函数:
\(min\sum_{(u,i)\in{P\bigcup{A}}}f_{ui}\)
\(f_{ui}=log(1+exp(-r_{ui}\hat{r}_{ui}))+\frac{\alpha_{u}}{2}||U_{u\cdot}||_F^2+\frac{\alpha_{v}}{2}||V_{i\cdot}||_F^2+\frac{\beta_u}{2}b_u^2 +\frac{\beta_v}{2}b_i^2\)
根据目标函数对正样本和采样到的负样本进行计算,然后计算用户特征、用户 bias、物品特征、物品 bias 的梯度:
\(\nabla{b_u}=\frac{\partial{f_{ui}}}{\partial{b_u}}=-e_{ui}+\beta_ub_u\)
\(\nabla{b_i}=\frac{\partial{f_{ui}}}{\partial{b_i}}=-e_{ui}+\beta_vb_i\)
\(\nabla{V_{i\cdot}}=\frac{\partial{f_{ui}}}{\partial{V_{i\cdot}}}=-e_{ui}U_{u\cdot}+\alpha_vV_{i\cdot}\)
\(\nabla{U_{u\cdot}}=\frac{\partial{f_{ui}}}{\partial{U_{u\cdot}}}=-e_{ui}V_{i\cdot}+\alpha_uU_{u\cdot}\)
\(e_{ui}=\frac{r_{ui}}{1+exp(r_{ui}\hat{r}_{ui})}\)
然后根据梯度对参数进行更新学习:
\(b_u=b_u-\gamma\nabla{b_u}\)
\(b_i=b_i-\gamma\nabla{b_i}\)
\(V_{i\cdot}=V_{i\cdot}-\gamma\nabla{V_{i\cdot}}\)
\(U_{u\cdot}=U_{u\cdot}-\gamma\nabla{U_{u\cdot}}\)
算法伪代码
1:初始化模型参数:用户特征、物品特征、用户bias、物品bias
2:for t = 1,...,T do
3: 随机选取负样本集合,大小是正样本的 \(\rho\) 倍
4: for 将正样本和负样本的并集按照随机的顺序对每个 (u,i) do
5: 计算预测分数:\(\hat{r}_{ui}=b_u+b_i+U_{u\cdot}V{i\cdot}^T\)
6: 计算各个参数的梯度
7: 使用梯度对参数进行更新
8: end for
9:end for
核心代码
# MFLogLoss模型
class MFLogLoss:
def __init__(self, user_set, item_set, observed_record_list, dimensions=20, learning_rate=0.01, alpha_user=0.001,
alpha_item=0.001, beta_user=0.001, beta_item=0.001, rho=3):
self.users = user_set # 先是用于保存用户id的集合,初始化特征向量后,保存用户的特征
self.items = item_set # 物品特征
self.userBias = {} # 用户bias
self.itemBias = {} # 物品bias
self.observedRecords = observed_record_list # 正样本
self.unobservedRecords = [] # 所有负样本
self.dimensions = dimensions # 特征维度
self.learning_rate = learning_rate # 学习率
self.alpha_user = alpha_user # 用户特征正则化系数
self.alpha_item = alpha_item # 物品特征正则化系数
self.beta_user = beta_user # 用户bias正则化系数
self.beta_item = beta_item # 物品bias正则化系数
self.rho = rho # 负样本采样比例
self.loss = 0 # 损失
def initialize(self):
users_dict = {} # 用户特征 字典结构: {用户id: 用户特征向量,...}
items_dict = {} # 物品特征
for user in self.users:
user_vector = np.random.rand(self.dimensions) # 初始化 0-1 均匀分布
users_dict[user] = (user_vector - 0.5) * 0.01
self.userBias.setdefault(user, 0) # 该用户bias初始化为0
for item in self.items: # 物品特征初始化
item_vector = np.random.rand(self.dimensions)
items_dict[item] = (item_vector - 0.5) * 0.01
self.itemBias.setdefault(item, 0)
self.users = users_dict
self.items = items_dict
m = len(self.items) # 物品数量
n = len(self.users) # 用户数量
mu = len(self.observedRecords) / m / n # 训练集中正样本数量
for record in self.observedRecords:
self.userBias[record[0]] += 1 # 该用户在训练集正样本中出现的次数
self.itemBias[record[1]] += 1 # 该物品在训练集正样本中出现的次数
for userIndex in self.userBias:
self.userBias[userIndex] = self.userBias[userIndex] / m - mu # 初始化用户bias
for itemIndex in self.itemBias:
self.itemBias[itemIndex] = self.itemBias[itemIndex] / n - mu # 初始化物品bias
def unobservedRecords_initialize(self):
temp_unobservedRecords = [] # 存储所有用户和物品的pair对
for user in self.users:
for item in self.items:
temp_unobservedRecords.append((user, item))
self.unobservedRecords = list(set(temp_unobservedRecords).difference(set(self.observedRecords))) # 去除掉训练集中出现的正样本,剩余的就是所有负样本(没有观察到的记录)
def train(self, epochs):
for epoch in range(epochs):
self.loss = 0 # 初始化loss
sampleUnobservedRecords = random.sample(self.unobservedRecords, self.rho * len(self.observedRecords)) # 从所有负样本集中取出正样本集大小三倍的负样本子集
unionRecords = [] # 合并正样本和负样本子集,作为整个训练集
for record in self.observedRecords:
unionRecords.append((record[0], record[1], 1)) # 正样本的rui为1
for record in sampleUnobservedRecords:
unionRecords.append((record[0], record[1], -1)) # 负样本的rui为-1
random.shuffle(unionRecords) # 打乱训练集
for record in unionRecords: # 遍历训练集
user_vector = self.users[record[0]] # 当前record记录的用户特征向量
item_vector = self.items[record[1]] # 当前record记录的物品特征向量
user_bias = self.userBias[record[0]] # 当前record记录的用户bias
item_bias = self.itemBias[record[1]] # 当前record记录的物品bias
rui = record[2] # rui
error = self.loss_function(user_vector, item_vector, user_bias, item_bias, rui) # 计算这条record所产生的损失
self.loss += error # 累加到此次epoch总共的损失
eui = rui / (1 + np.exp(rui * (user_bias + item_bias + np.dot(user_vector, item_vector)))) # 梯度所使用到的公共部分
grad_user = -eui * item_vector + self.alpha_user * user_vector # 当前用户特征向量的梯度
grad_item = -eui * user_vector + self.alpha_item * item_vector # 当前物品特征向量的梯度
grad_user_bias = -eui + self.beta_user * user_bias # 当前用户bias的梯度
grad_item_bias = -eui + self.beta_item * item_bias # 当前物品bias的梯度
self.users[record[0]] -= self.learning_rate * grad_user # 更新用户特征
self.items[record[1]] -= self.learning_rate * grad_item # 更新物品特征
self.userBias[record[0]] -= self.learning_rate * grad_user_bias # 更新用户bias
self.itemBias[record[1]] -= self.learning_rate * grad_item_bias # 更新物品bias
# 损失函数
def loss_function(self, user_vector, item_vector, user_bias, item_bias, rui):
return np.log(1 + np.exp(-rui * (user_bias + item_bias + np.dot(user_vector, item_vector)))) + \
self.alpha_user * 0.5 * math.pow(np.linalg.norm(user_vector, ord=2), 2) + \
self.alpha_item * 0.5 * math.pow(np.linalg.norm(item_vector, ord=2), 2) + \
self.beta_user * 0.5 * math.pow(user_bias, 2) + self.beta_item * 0.5 * math.pow(item_bias, 2)
实验结果和分析(含不同活跃程度用户上的结果)
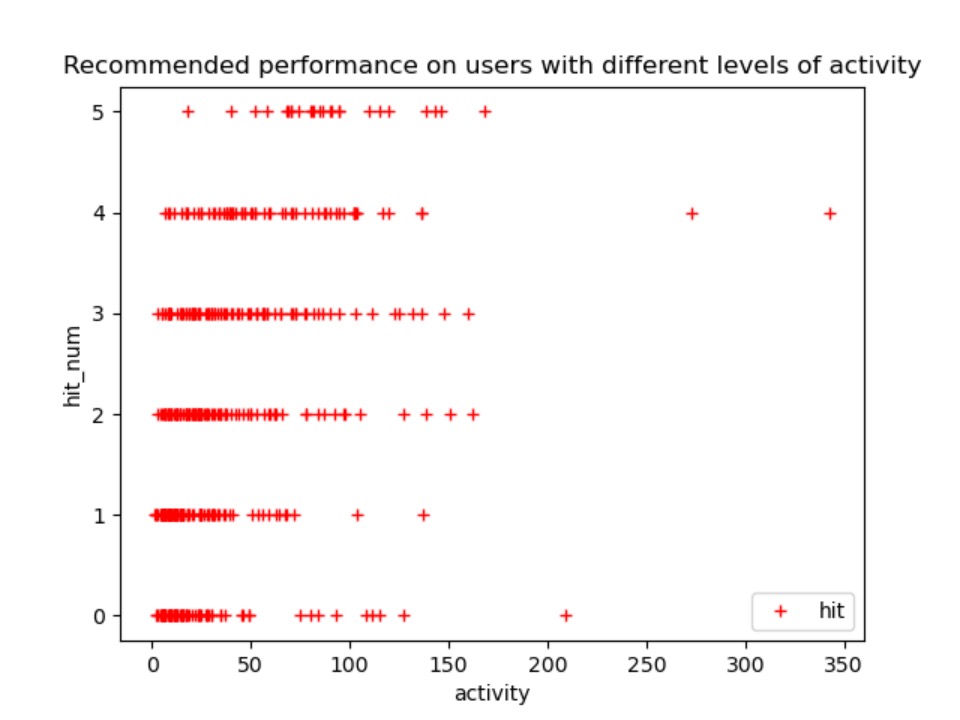
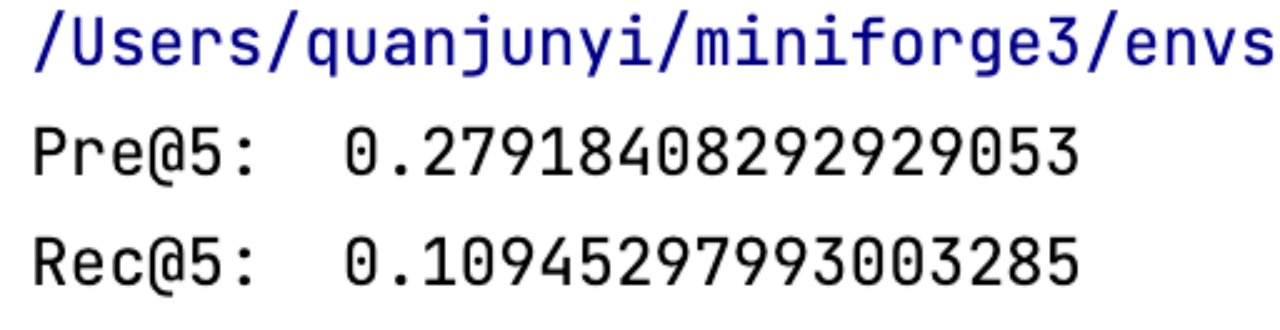
首先在 100K 小数据集上进行测试,得到的 top5 的 precision 和 recall 与课件上的结果相似,说明训练程序和测试程序没有问题。

100K 不同活跃程度用户的结果:
然后,再在 1M 数据集上进行训练,实验结果如下:
1M 不同活跃程度用户的结果:
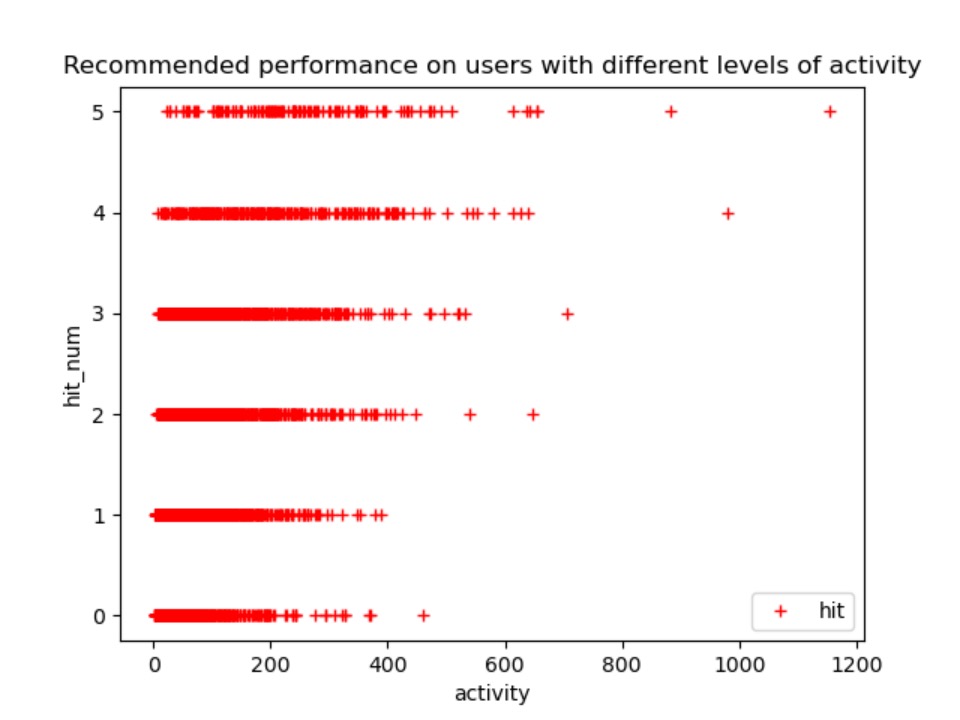
分析:图8每一个点表示一个用户,横坐标表示该用户的活跃度(训练集正样本数),纵坐标表示对该用户预测前五的物品在测试集中命中次数。
- 命中次数为0的样本中,不会出现活跃度大于800的用户,一定程度上说明活跃度高的预测准确度越高。
- 命中次数为0和5的用户个数相对来说较少。
基于深度学习的单类协同过滤推荐方法和实验
模型示意图
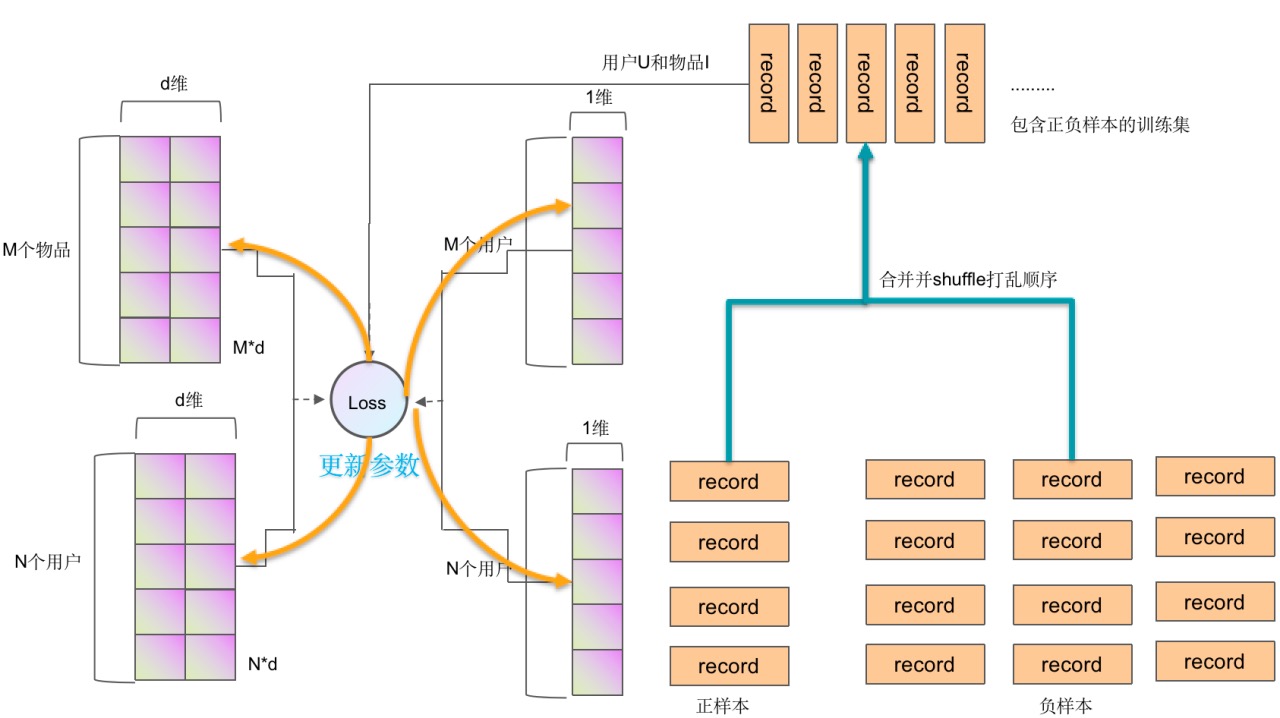
核心代码
# 初始化用户和物品的特征和bias
def initialize(rating_matrix):
users_num = rating_matrix.shape[0] # 训练集中用户的个数
items_num = rating_matrix.shape[1] # 训练集中物品的个数
users_vector = torch.rand(users_num, 20, requires_grad=True) # 初始化用户特征矩阵,users_num*20
users_vector.data.add_(-0.5)
users_vector.data.mul_(0.01)
items_vector = torch.rand(items_num, 20, requires_grad=True) # 初始化物品特征矩阵,items_num*20
items_vector.data.add_(-0.5)
items_vector.data.mul_(0.01)
users_ui = rating_matrix.apply(lambda x: my_sum(x), axis=1).astype(float) # 初始化用户特征
items_ui = rating_matrix.apply(lambda x: my_sum(x), axis=0).astype(float) # 初始化物品特征
mu = users_ui.sum() / items_num / users_num
# users_bias = torch.tensor(data=users_ui.values, requires_grad=True, dtype=torch.float)
users_bias = torch.from_numpy(users_ui.values)
users_bias.data.div_(items_num)
users_bias.add_(-mu)
# items_bias = torch.from_numpy(items_ui.values)
items_bias = torch.from_numpy(items_ui.values)
items_bias.data.div_(users_num)
items_bias.add_(-mu)
return users_vector, items_vector, users_bias, items_bias
# MFLogLoss模型
class MFLogLoss(torch.nn.Module):
def __init__(self, alpha_user=0.001, alpha_item=0.001, beta_user=0.001, beta_item=0.001, rho=3):
super().__init__()
self.alpha_user = alpha_user # 用户特征正则化系数
self.alpha_item = alpha_item # 物品特征正则化系数
self.beta_user = beta_user # 用户bias正则化系数
self.beta_item = beta_item # 物品bias正则化系数
self.rho = rho # 负样本采样比例
# 前向传播函数,定义了损失函数
# user_vector 表示用户特征向量,item_vector 表示物品特征向量,user_bias 表示用户bias, item_bias表示物品bias,rui表示该记录是正样本还是负样本
def forward(self, user_vector, item_vector, user_bias, item_bias, rui):
predict = torch.dot(user_vector, item_vector) + user_bias + item_bias # 预测分数
error = torch.log(1 + torch.exp(-rui * predict)) # log误差
user_vector_regularization = self.alpha_user * torch.pow(torch.norm(user_vector), 2) / 2 # 用户特征正则化项
item_vector_regularization = self.alpha_user * torch.pow(torch.norm(item_vector), 2) / 2 # 用户特征正则化项
user_bias_regularization = self.beta_user * torch.pow(user_bias, 2) / 2 # 用户bias正则化项
item_bias_regularization = self.beta_item * torch.pow(item_bias, 2) / 2 # 物品bias正则化项
return error + user_vector_regularization + item_vector_regularization + user_bias_regularization + item_bias_regularization
def train(model, users_vector, items_vector, users_bias, items_bias, observed_record_list, unobserved_record_list, users_index_dict, items_col_dict, epochs):
for epoch in range(epochs):
sampleUnobservedRecords = random.sample(unobserved_record_list, model.rho * len(observed_record_list)) # 从所有负样本集中取出正样本集大小三倍的负样本子集
union_records = [] # 合并正样本和负样本子集,作为整个训练集
for record in observed_record_list:
union_records.append((record[0], record[1], 1))
for record in sampleUnobservedRecords:
union_records.append((record[0], record[1], -1))
random.shuffle(union_records) # 打乱训练集
total_loss = 0 # 当前epoch所产生的损失
for record in union_records:
rui = record[2]
model.optimizer.zero_grad() # 模型优化器梯度置零
# loss = model(user_vector, item_vector, user_bias, item_bias, rui)
# 执行model的前向传播函数,计算一次迭代的总loss
loss = model(users_vector[users_index_dict[record[0]]], items_vector[items_col_dict[record[1]]], users_bias[users_index_dict[record[0]]], items_bias[items_col_dict[record[1]]], rui)
# 计算用户特征矩阵和物品特征矩阵的梯度
loss.backward()
# 梯度更新
model.optimizer.step()
# 累计损失,如果直接累加loss,单次loss无法释放,会造成内存溢出,无法训练,因此要加loss.item()
total_loss += loss.item()
print("epoch: ", epoch, "loss:", total_loss)
# 迭代训练完成之后,保存用户和物品的特征矩阵和bias向量
torch.save(users_vector, "pytorchResult1M/users_vector.pt")
torch.save(items_vector, "pytorchResult1M/items_vector.pt")
torch.save(users_bias, "pytorchResult1M/users_bias.pt")
torch.save(items_bias, "pytorchResult1M/items_bias.pt")
实验结果和分析(含与非深度学习方法的比较)
首先,在 100K 的小数据集上进行训练,训练结果如下:

在 100K 上的训练结果达到了预期效果,然后再在 1M 数据上进行训练,训练结果如下:

分析:在100K数据集上,框架训练的结果不管是precision还是recall都略低于不用框架训练的结果。而在1M数据集上,框架训练的结果反而略高于不用框架训练的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号