聚类算法
一、聚类算法简介
聚类是无监督学习的典型算法,不需要标记结果。试图探索和发现一定的模式,用于发现共同的群体,按照内在相似性将数据划分为多个类别使得内内相似性大,内间相似性小。有时候作为监督学习中稀疏特征的预处理(类似于降维,变成K类后,假设有6类,则每一行都可以表示为类似于000100、010000)。有时候可以作为异常值检测(反欺诈中有用)。
应用场景:新闻聚类、用户购买模式(交叉销售)、图像与基因技术
相似度与距离:这个概念是聚类算法中必须明白的,简单来说就是聚类就是将相似的样本聚到一起,而相似度用距离来定义,聚类是希望组内的样本相似度高,组间的样本相似度低,这样样本就能聚成类了。
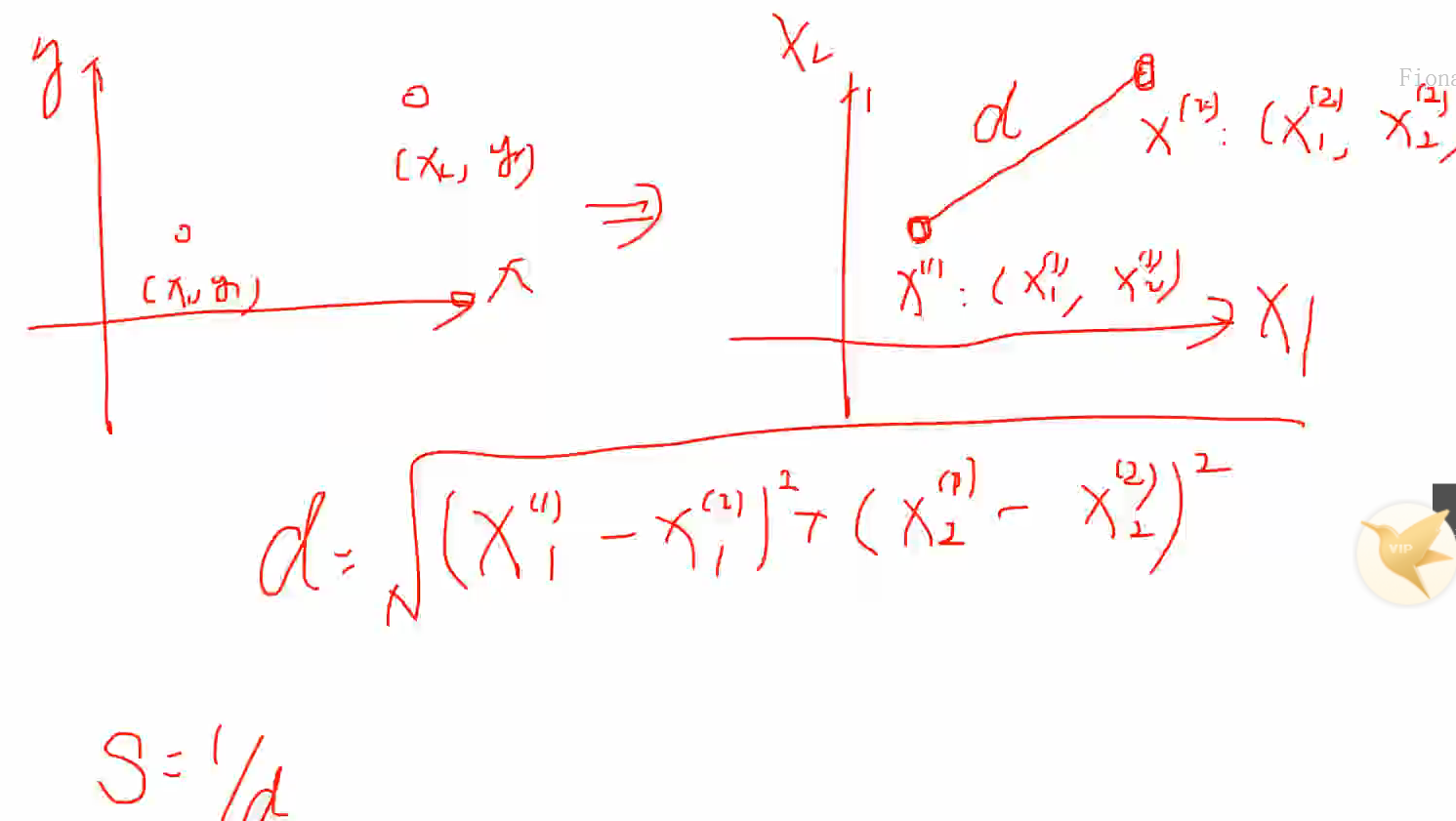
1.Minkovski距离,当p=2时,就是欧式距离: 相似性就被定义为了d的倒数,1/d ;当P=1时就说城市距离(曼哈顿距离):下图中直角的距离,直接同维度相减后加总
2.余弦距离 夹角的距离cosθ = (at* b)/(|a|*|b|) 余弦距离比较难收敛,优势是不受原来样本线性变换影响
3. 皮尔斯相关系数 从概率论角度得到的距离 当x和y的均值为0时,皮尔森相关系数就等于余弦距离
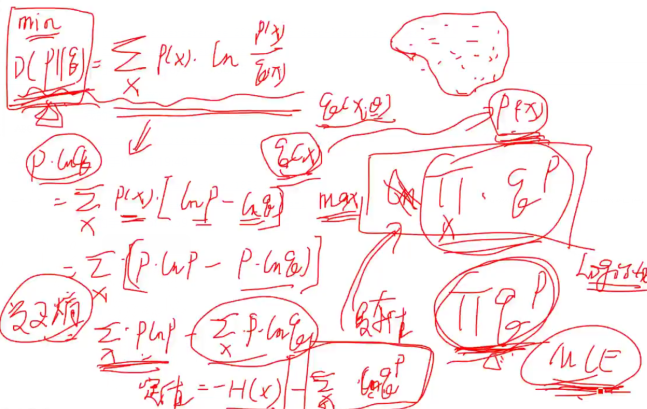
4. KL散度(交叉熵) 衡量两个分布之间的差异,不是传统意义上的距离,其中p(x)是真实样本分布,Q(x)是数据的理论分布,或者说是一种更简单的分布。有时候p(x)的分布很难写出,可以通过求KL散度最小而求出Q(X)。
http://www.cnblogs.com/charlotte77/p/5392052.html
聚类算法分类:基于位置的聚类(kmeans\kmodes\kmedians)层次聚类(agglomerative\birch)基于密度的聚类(DBSCAN)基于模型的聚类(GMM\基于神经网络的算法)
二、Kmeans算法
1.确定聚类个数K
2.选定K个D维向量作为初始类中心
3.对每个样本计算与聚类中心的距离,选择最近的作为该样本所属的类
4.在同一类内部,重新计算聚类中心(几何重心) 不断迭代,直到收敛:
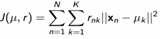 (损失函数为此就是Kmeans算法(其实是默认了我们样布服从均值为μ,方差为某固定值的K个高斯分布,混合高斯分布),如果(x-μ)不是平方,而只是绝对值那就是Kmedian算法,混合拉普拉斯分布)每个样本到聚类中心的距离之和或平方和不再有很大变化。对损失函数求导,
(损失函数为此就是Kmeans算法(其实是默认了我们样布服从均值为μ,方差为某固定值的K个高斯分布,混合高斯分布),如果(x-μ)不是平方,而只是绝对值那就是Kmedian算法,混合拉普拉斯分布)每个样本到聚类中心的距离之和或平方和不再有很大变化。对损失函数求导,![]() ,可以看到其实我们更新聚类中心的时候,就是按照梯度的方向更新的。由于损失函数有局部极小值点,所以它是初值敏感的,取不同的初值可能落在不同的极小值点。
,可以看到其实我们更新聚类中心的时候,就是按照梯度的方向更新的。由于损失函数有局部极小值点,所以它是初值敏感的,取不同的初值可能落在不同的极小值点。
轮廓系数(silhouetee)可以对聚类结果有效性进行验证。python中有该方法,metrics.silhouetee_score。越接近1聚的越好,越接近-1聚的越不好。适用于球形聚类的情况。
缺点:1.对初始聚类中心敏感,缓解方案是多初始化几遍,选取损失函数小的。2.必须提前指定K值(指定的不好可能得到局部最优解),缓解方法,多选取几个K值,grid search选取几个指标评价效果情况3.属于硬聚类,每个样本点只能属于一类 4.对异常值免疫能力差,可以通过一些调整(不取均值点,取均值最近的样本点)5.对团状数据点区分度好,对于带状不好(谱聚类或特征映射)。尽管它有这么多缺点,但是它仍然应用广泛,因为它速度快,并且可以并行化处理。
优点:速度快,适合发现球形聚类,可发现离群点
缺失值问题:离散的特征:将缺失的作为单独一类,90%缺失去掉。连续的特征:其他变量对这个变量回归,做填补;样本平均值填补;中位数填补。
对于初始点选择的问题,有升级的算法Kmeans++,每次选取新的中心点时,有权重的选取(权重为距离上个中心店的距离),
cls = KMeans(n_clusters=4, init='k-means++',random_state=0)不给出随机种子 每次聚类结果会不一样
另外,想要收敛速度进一步加快,可以使用Mini-BatchKmeans,也就是求梯度的时候用的是随机梯度下降的方法,而不是批量梯度下降。sklearn.cluster.MiniBatchKMeans
三、层次聚类算法
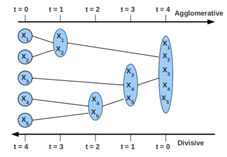
也称为凝聚的聚类算法,最后可以生成一个聚类的图,但Python中不容易生成这种图,一般直接在界面软件中生成。其实更像是一种策略算法,画出来有点类似于树模型的感觉。
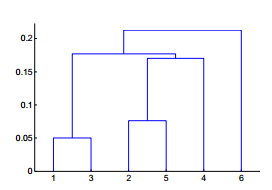
有自顶而下和自底向上两种,只是相反的过程而已,下面讲自顶而下的思路。
1.计算所有个体和个体之间的距离,找到离得最近的两个样本聚成一类。
2.将上面的小群体看做一个新的个体,再与剩下的个体,计算所有个体与个体之间距离,找离得最近的两个个体聚成一类,依次类推。
3.直到最终聚成一类。
群体间的距离怎么计算呢?(下图用的是重心法,还有ward法)
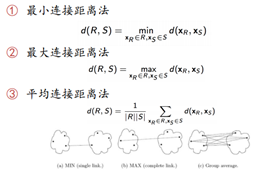
优点:不需要确定K值,可根据你的主观划分,决定分成几类。
缺点:虽然解决了层次聚类中Kmeans的问题,但计算量特别大。与Kmeans相比两者的区别,除了计算速度,还有kmeans只产出一个聚类结果和层次聚类可根据你的聚类程度不同有不同的结果。
层次聚类中还有一种是brich算法,brich算法第一步是通过扫描数据,建立CF树(CF树中包含簇类中点的个数n,n个点的线性组合LS=![]() ,数据点的平方和SS;而簇里面最开始只有一个数据点,然后不断往里面加,直到超过阈值);第二步是采用某个算法对CF树的叶节点进行聚类。优点就是一次扫描就行进行比较好的聚类。缺点是也要求是球形聚类,因为CF树存储的都是半径类的数据,都是球形才适合。
,数据点的平方和SS;而簇里面最开始只有一个数据点,然后不断往里面加,直到超过阈值);第二步是采用某个算法对CF树的叶节点进行聚类。优点就是一次扫描就行进行比较好的聚类。缺点是也要求是球形聚类,因为CF树存储的都是半径类的数据,都是球形才适合。
四、DBSCAN
Dbscan是基于密度的算法,之前的一些算法都是考虑距离,而DBscan是考虑的密度,只要样本点的密度大于某阈值,则将该样本添加到最近的簇中(密度可达的簇)
核心点:在半径eps内含有超过Minpts数目的点,则该点为核心点。边界点:在半径eps内含有小于Minpts数目的点但是在核心点的邻居。 核心点1连接边界点2,边界点2又连接核心点2,则核心点1和边界点2密度可达。
噪音点:任何不是核心点或是边际点的点。密度:在半径eps内点的数目。
DBscan过程:

簇:密度相连点的最大集合
算法的关键要素:距离的度量有欧几里德距离,切比雪夫距离等,最近邻搜索算法有Kd_tree, ball_tree
Python中可调的参数:eps和m, eps为半径,m为要求的半径内点的个数即密度,m越大聚出的类越多,因为即要求成某个类的密度要比较高,一旦中间比较稀疏的就不算一个类了;eps越大,类的个数越少。
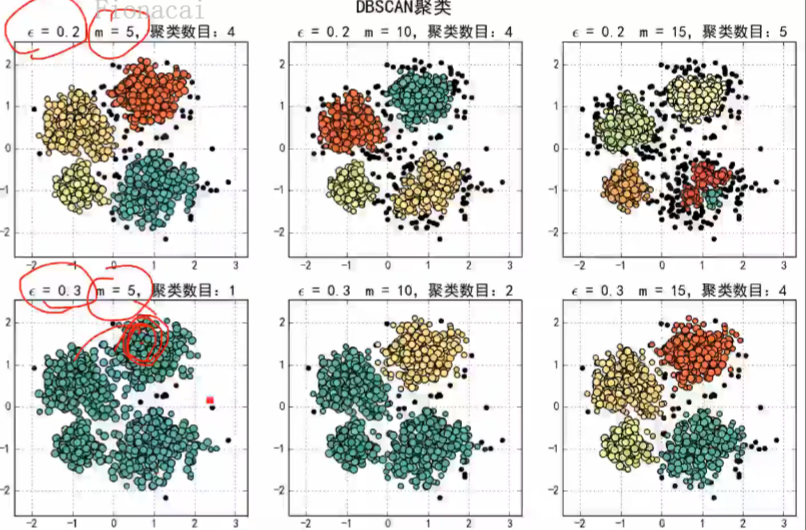
优点:相对抗噪音(可发现离群点),可以发现任意形状的样本。
缺点:但计算密度单元的计算复杂度大,但计算密度单元的计算复杂度;不能很好反应高维数据,高维数据不好定义密度
五、GMM(混合高斯模型)
属于软聚类(每个样本可以属于多个类,有概率分布)GMM认为隐含的类别标签z(i),服从多项分布![]() ,并且认为给定z(i)后,样本x(i)满足多值高斯分布,
,并且认为给定z(i)后,样本x(i)满足多值高斯分布,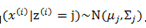 ,由此可以得到联合分布
,由此可以得到联合分布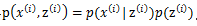 。
。
GMM是个鸡生蛋、蛋生鸡的过程,与KMEANS特别像,其估计应用EM算法。
1.首先假设知道GMM参数,均值、协方差矩阵、混合系数,基于这些参数算出样本属于某一类的概率(后验概率)wji:
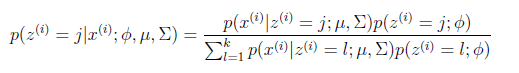
2.然后根据该概率,重新计算GMM的各参数。此参数求解利用了最大似然估计。
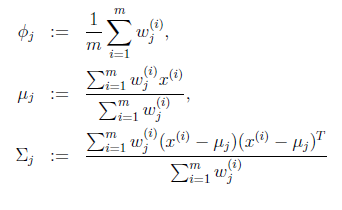
3.一直迭代,直到参数稳定。
EM(Expectation Maximization)算法是,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
混合高斯模型,实质上就是一个类别一个模型。先从k个类别中按多项式分布抽取一个z(i),然后根据z(i)所对应的k个多值高斯分布中的一个生成样本x(i),整个过程称作混合高斯模型。
GMM优点:可理解、速度快
劣势:初始化敏感、需要手工指定k(高斯分布)的个数、不适合非凸分布数据集(基于密度的聚类和核方法可以处理)
Kmeans可以看做混合高斯聚类在混合成分方差相等、且每个样本派给一个混合成分时的特例。
六、谱聚类
首先什么是谱呢?比如矩阵A,它的所有特征值的全体就统称为A的谱,AU=λU,λ1...λn。如果下次看到跟谱相关的算法,多半就是跟特征值相关的算法了。什么是谱半径呢?就是最大的那个特征值。
谱聚类就是基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据的聚类。
1. 第i个样本和第j个样本度量相似![]() 高斯相似度,其中delta是超参数,svm里面也用到过这个核函数
高斯相似度,其中delta是超参数,svm里面也用到过这个核函数
2. 形成相似度矩阵W=(Sij)n*n,对称矩阵,其中sii本来应该等于1,但为了方便计算都写成0,所以相似度矩阵就变长了主对角线上都为0的对称阵。
3. 计算第i个样本到其他所有样本的相似度的和di = si1+Si2+....Sin(这里关于Si的相加,有些比如要聚成K类的就只会使用前K个si相加,或者设定一个阈值,小于阈值的si都舍去),在图论中,di叫做度,可以理解为连接边的权值。将所有点的度di,构成度矩阵D(对角阵)
4. 形成拉普拉斯矩阵L=D-W,L是对称半正定矩阵,最小特征值是0,相应的特征向量是全1向量。把L的特征值从小到大排列,λ1...λn,对应特征向量u1 u2...un,如果我们要求聚成K类,我们就取前K个特征值对应的特征向量,形成矩阵Un*k,这样我们认为对应第一个样本的特征就是u11,u12..u1k,第二个样本的特征就是u21,u22...u2k,第n个样本的特征就是un1,un2...unn,对这n个样本做K均值,最后对这n个样本的聚类结果是什么,我们原始的聚类结果就是什么。
优点:可以发现非球形的样本
缺点:也要事先给定K值
七、部分应用经验
可以先对样本进行基于其分布的抽样,然后在小样本范围内进行层次聚类,然后用层次聚类得出的K值,应用于整个样本进行Kmeans聚类。
聚类分析结果评价:
当知道实际分类时:Homogeneity(均一性), completeness(完整性) and V-measure(同时考虑均一性和完整性)
不知道实际分类时:轮廓系数(求出每个样本的Si,再取平均值就是整体的轮廓系数),Calinski-Harabaz Index

http://blog.csdn.net/sinat_26917383/article/details/70577710
建模步骤:1.变量预处理:缺失值、异常值(用p1或P99替代)、分类变量变成数值型、分类变量转为哑变量、分类变量过多 这里涉及一系列recoding的过程。2.变量标准化:变量的量纲不一样会引起计算距离的差距。3.变量的筛选:商业意义、多个维度、变量间相关性。4.确定分类个数:区分性足够好,又不能太细
在聚类之前往往先做主成分分析,或者变量的聚类。
------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------
八、无监督深度学习
用AE的输出或 VAE的中间状态作为Kmeans的输入,结合起来可以提高Kmeans的聚类效果。因为数据压缩后距离质心可能就更近了,这样就更加容易分类了。
GAN。VAE没有GAN的对抗的。依赖于先验知识。
AE(autoencoder)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号