
小数据玩转pyspark(1)

sqoop:导入结构化数据
kafka:导入流式数据
HDFS:文件存储形式(数据存在Hadoop上是,存在HDFS)怎么访问呢?最传统的肯定是MR,后期有Hive(其实就是把MR通过sql转换了一下,Hive本身并没有存储功能,存储还是HDFS),现在也可以用spark进行数据操作(spark SQL),PIG是一种脚本式操作语言,可以直接操作HDFS
HBASE:键值对存储形式(MPP的数据库)
MR在计算的时候时间比较长,如果做交互式的想立即得到结果的不现实,所以只能做批处理
流式处理,spark\storm, spark streaming流式处理(秒级)
建模主要用的Spark: HDFS数据导入spark,这样可以享受内存级别的运算,如果是在HDFS上是在硬盘上运行,io比较多,数据挖掘的速度非常慢。
spark
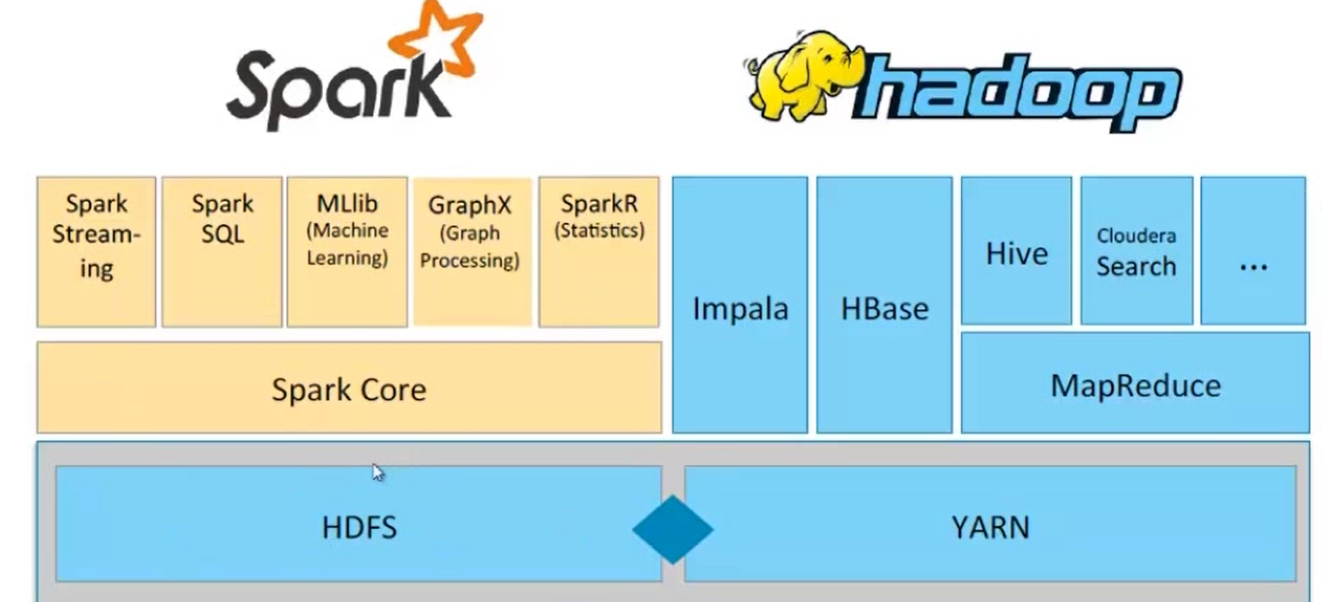
spark是hadoop生态的重要一环,一般spark是建立在HDFS基础上,当然你也可以单机版直接运行。
spark批处理数据ETL性能比Hadoop的MR高100倍
中间数据在内存中,更高效、低延迟(但存在内存溢出问题)
机器学习——适合迭代多次,数据重复利用的场合
RDD:只读、可分区的分布式数据集。添加新列必须重新创建RDD。
在notebook里面运行的话,要自己建立SparkSession,不像交互式编辑器会帮我们建立
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("CreditCard").getOrCreate() #创建sparksession
sc = spark.sparkContext #创建sparkcontext
#数据读入
loanfile = os.listdir()
createVar = locals() #每个变量是个名字
for i in loanfile:
if i.endwith("csv"):
createVar[i.split('.')[0]] = spark.read.csv(i, inferSchema=True, header=True, encoding='gbk')
print(i.split(',')[0]
#聚合操作
data_4temp3=spark.sql("select account_id,type,sum(amount) as amount\
from data_4temp1 \
group by account_id,type \
order by account_id,type")
data_4temp4 = data_4temp3.groupby('account_id').pivot('type', values=['credit', 'debit']).sum('amount')
#去掉列
data6 = data5.drop('data','birth_date')
#spark dataframe转成pandas dataframe
data6 = data5.drop('data','birth_date')
data6_df = data6.toPandas()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号