软件工程实践寒假作业2/2
软件工程实践寒假作业2/2
| 这个作业属于哪个课程 | 2021年春软件工程实践|W班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 阅读构建之法并提问;设计一个程序,能够满足一些词频统计的需求 |
| 其他参考文献 | 无 |
任务一: 阅读构建之法并提问
单元测试的密度如何安排?
我看了《构建之法》的有关单元测试的文章,其中有提到这样的一句话:“单元测试应该在最低的功能/参数上验证程序的正确性。”,之后我对这句话提出了我自己的疑问,如果单元测试都是在最低功能上验证,那么整体功能的正确性要如何验证,根据我的实践,我认为有一些代码完成的功能十分复杂,通常是由几个功能函数共同合作实现,如果在单元测试中我只能保证每个函数的正确性,但我要如何保证函数之间的配合不会出错呢,因为只有这样我才能得到我想要的功能。 后来查阅了资料才发现,单元测试主要是在开发过程中同步进行,而功能整体的正确性大多数时候要等到全部函数写完,测试完成之后才可以看出是否正确,但是我还是有疑问,有没有更高效地,能够在进行函数单元测试的同时就能预测最终效果的方法?
单元测试一定要由程序的作者来写吗?
同样也是这篇有关单元测试的文章,其中有这样的一句话:“单元测试必须由最熟悉代码的人(程序的作者)来写”,我对这句话以及其接下来的内容有一个疑问,根据我的实践经历,有的时候代码的编写者可能很难发现自己的错误,有可能是因为“思维惯性”,代码的编写者有可能比旁观者更难发现自己的错误,比如,在大一的C++课程的一次实践作业中,我自己看了一个小时也没看出来的bug,我室友3分钟就看出来了。单元测试只能由最熟悉代码的人编写,从效率上来看,是否过于绝对?我认为单元测试可以让程序的作者以及不参与编写的其他程序员一起进行,当然,主要由程序的编写者来测试是没有问题的。
敏捷开发一定是好的吗?
我看了《构建之法》的有关于敏捷开发的文章,文章中提到:“敏捷开发需要尽早并持续地交付有价值的软件以满足顾客需求,只有不断关注技术和设计才能越来越敏捷”,即不断地推出新功能来保证产品的优势,这种想法看似没有什么问题,但是实际执行起来效果如何呢?根据知乎用户王先生所说,敏捷开发实际上就是将产品经理的工作量转移到了程序员身上,会极大幅度提高程序员的工作量和疲劳程度,并且有可能因为时间太过于仓促而不去关注功能是否真的满足客户的需要,例如知乎里的商城系统,开发麻烦,却没有人用,这样的“敏捷”开发是否违背了敏捷开发的初衷?或者说,如果多花一点时间在功能的设计,以及创意的构想上,让一周一次的更新“延长”到一月一次的更新,会不会比赶时间开发功能更有效果,更能满足客户的需求?敏捷开发需要有多敏捷,这是我们需要考虑的。
团队之间如何配合做好代码的整理工作?
我看了《构建之法》中有关于合作开发的内容,文章中提到合作开发需要制定代码规范,并在最后需要做好代码复审工作,但是在一个团队中,往往是多人开发,一个人负责一个独立的模块,即使代码的编写风格相同,每个人编写代码的思维逻辑不同,有可能给代码复审带来较大的麻烦,而且如果代码的标准过于严苛,可能会给开发人员带来一定的负面情绪,而且统一每个人的代码风格并不是一件容易的事情,需要大家多多交流,都做出一点让步。
关于创新的思考。
根据书中材料,姜万勐与孙燕生受图像解压缩技术启发,想到可以用光盘同时记录图像、声音信息,从而记录视频信息,并从而开发了世界上第一台VCD,几乎可以说开创了一个时代。这是一个非常好的创新案例,告诉了我们紧跟技术前沿的意义之所在。个人感悟:在竞争的时候,保护自己的特色、自己的知识产权很重要,把握好技术变现、投入市场的时机也很重要。假如我是当时的竞争者,我会选择前期好好积累技术、研究需求,并观察市场的变化;等到第一批用户有了好的回馈、后期用户开始接纳新技术时进入市场,这时仍然没有到竞争的白热化阶段,仍然可以占据一个较为领先的地位。此后,一定要观察市场动向、注重创新,对于新的技术要投入一定的精力去研究。因为媒体介质更新换代较快,不能够将自己局限;只有不断地创新,才能尽量不被淘汰。
附加题:bug的来源
1945年9月9日,下午三点。哈珀中尉正领着她的小组构造一个称为“马克二型”的计算机。这还不是一个完全的电子计算机,它使用了大量的继电器,一种电子机械装置。第二次世界大战还没有结束。哈珀的小组日以继夜地工作。机房是一间第一次世界大战时建造的老建筑。那是一个炎热的夏天,房间没有空调,所有窗户都敞开散热。
突然,马克二型死机了。技术人员试了很多办法,最后定位到第70号继电器出错。哈珀观察这个出错的继电器,发现一只飞蛾躺在中间,已经被继电器打死。她小心地用摄子将蛾子夹出来,用透明胶布帖到“事件记录本”中,并注明“第一个发现虫子的实例。”。从此以后,人们将计算机错误戏称为虫子(bug),而把找寻错误的工作称为(debug)。
任务二:词频统计程序WordCount
作业描述
- 统计文件的字符数 (对应输出第一行)
- 统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
项目地址:Fino的Github
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 55 |
| ·Estimate | 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 60 | 60+30 |
| ·Analysis | 需求分析(包括学习新技术) | 30 | 40 |
| ·Design Spec | 生成设计文档 | 30 | 40 |
| ·Design Review | 设计复审 | 60 | 53 |
| ·Coding Standard | 代码规范(为目前的开发制定合适的规范) | 14 | 10 |
| ·Design | 具体设计 | 1*60 | 1*60 |
| ·Coding | 具体编码 | 1*60 | 1*60 |
| ·Code Review | 代码复审 | 30 | 30 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| ·Reporting | 报告 | 20 | 20 |
| ·Test Repor | 测试报告 | 20 | 20 |
| ·Size Measurement | 计算工作量 | 10 | 10 |
| ·Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 60 |
| 合计 | 559 | 618 |
解题思路描述
- 统计文件的字符数,按题目所述,问题的关键在于如何区分ASCII字符和非ASCII字符,查阅资料发现,java中ASCII的字符转成int类型后值在0~127之间,故只需要判断下即可。
- 统计文件单词总数,这里注意到“空格,非字母数字符号为分隔符”,故只需要遍历一遍文件,将其分割符统一设为空格,然后再调用java的字符串的split函数即可,注意还需要写一个函数判断单词的合法性
- 统计文件的有效行数,任何包含非空白字符的行,都需要统计。按行读取文件,然后过滤掉只有空白字符的行,可以用正则表达式实现。
- 统计文件中出现最多次数的10个单词,这里可以用java中的Map<String,Integer>来实现,需要注意下应该将单词转为小写。
代码规范连接(节选自阿里巴巴java编程规范)
https://github.com/Fino123/PersonalProject-Java/blob/main/221801435/codestyle.md
计算模块接口的设计与实现过程。
代码总共有三个类,Lib类和WordCount类,以及Lib的测试类LibTest。Lib类作为一个工具类为WordCount类提供处理文件的接口,LibTest类用于测试Lib的功能函数是否正确,这三个类的关系如下图所示:
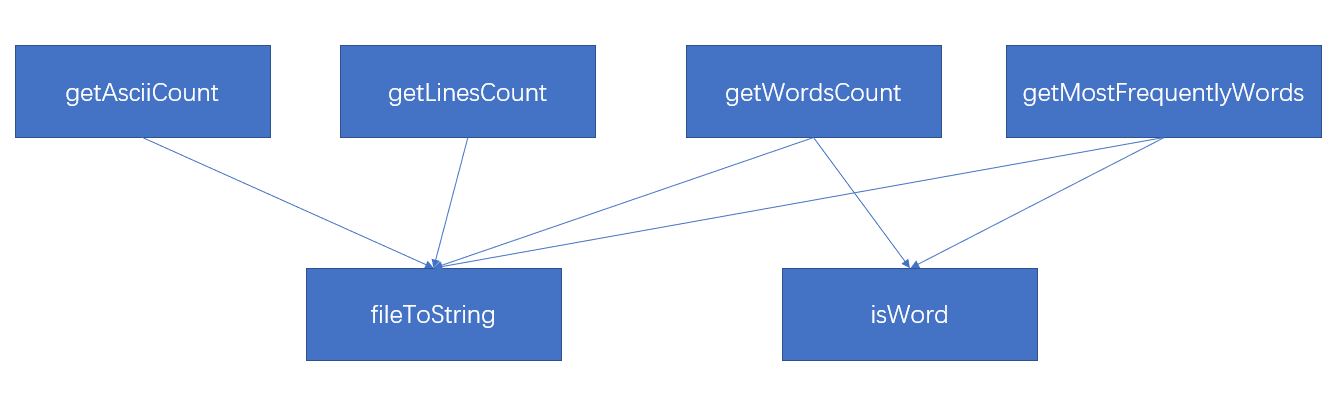
其中主要的核心在于Lib类,Lib一共有6个函数,其中5个函数对外开放,分别是getAsciiCount,getLinesCount,getWordsCount,getMostFreguentlyWords,fileToString,这几个函数分别负责统计Ascii字符,统计文件行数,统计文件中出现次数最多的10个单词,以及将文件读取为字符串的形式,最后还有一个isWord函数,用于判断是否是合法单词,这里的fileToString和isWord函数被另外四个函数多次调用,这六个函数的关系可以表示成如下的形式:
这里先介绍两个被调用的函数:

fileToString函数
该函数的目的主要是读取文件,并将文件内容保存在一个字符串当中。之所以把读取文件提取出来,是因为这样可以在后续调用的过程中,少一些文件读取时的异常检查,提高代码的可读性,同时,该字符串可以保留,不需要在执行完一个功能之后再次读取文件,这也提高了代码的效率。
public String fileToString(String file_path){
BufferedReader reader = null;
StringBuilder builder = new StringBuilder();
try {
reader = new BufferedReader(new InputStreamReader(new FileInputStream(file_path)));
int c;
while ((c=reader.read())!=-1){
builder.append((char)c);
}
}catch (FileNotFoundException e){
System.out.println(file_path+"文件不存在");
}catch (IOException e){
System.out.println(file_path+"文件打开失败");
}
...
return builder.toString();
}
isWord函数
该函数负责判断传进来的字符串是否是一个正确的单词,即由四个英文开头,后接字母和数字。
private boolean isWord(String word){
if (word.length()<4){
return false;
}
//不区分大小写
String test = word.toLowerCase();
//前4位是字母
for(int i=0;i<4;i++){
char c = test.charAt(i);
if (!(c>='a'&&c<='z')){
return false;
}
}
//后跟字母数字符号
for(int i=3;i<word.length();i++){
if(!Character.isDigit(test.charAt(i))&&!Character.isLetter(test.charAt(i))){
return false;
}
}
return true;
}
getAscii函数
该函数接收一个文件信息字符串file_info,然后遍历整个字符串,判断字符的范围,若在0~127之间,则计数器加1。
public int getAsciiCount(String file_info){
int counter = 0;
for (int i=0;i<file_info.length();i++){
int c = (int)file_info.charAt(i);
if (c>=0&&c<=127){
counter++;
}
}
return counter;
}
getLinesCount函数
该函数接收一个文件的地址file_path。之所以不使用fileToString,是因为不好在一个字符串中判断该行是否是空行。如果按行读取文件,则可以利用正则表达式"\s+"来匹配任意长度的空行。虽然牺牲了一点性能(但是时间复杂度还是和文件长度线性相关),但可以提高开发效率,代码也更易于阅读。
public int getLinesCount(String file_path){
String file_info = fileToString(file_path);
BufferedReader reader = null;
int counter = 0;
try {
reader = new BufferedReader(new InputStreamReader(new FileInputStream(file_path)));
String line = null;
while((line=reader.readLine())!=null){
//判断改行是否非空
if (line.length()>0&&!line.matches("\\s+")){
counter++;
}
}
}catch (IOException e){
System.out.println(file_path+"文件打开失败");
}
...
return counter;
}
getWordsCount函数
该函数先将文件字符串中的非数字字母的字符替换为空格字符,然后再调用String的split函数将其分开,得到一个字符串数组,最后对字符串数组中的每一个字符串进行判断,调用isWord函数,如果该字符串是合法单词,则计数器加1。
public int getWordsCount(String file_info){
//先遍历一遍,将所有非字母数字的符号都换成空格符
StringBuilder builder = new StringBuilder(file_info);
for (int i=0;i<builder.length();i++){
char c = builder.charAt(i);
if (!Character.isDigit(c)&&!((c>='a'&&c<='z'||c>='A'&&c<='Z'))){
builder.setCharAt(i,' ');
}
}
//将其按空格拆分
String []words = builder.toString().split("\\s+");
//判断是否是合法字符,统计单词数量
int counter = 0;
for(int i=0;i<words.length;i++){
if (isWord(words[i])){
counter++;
}
}
return counter;
}
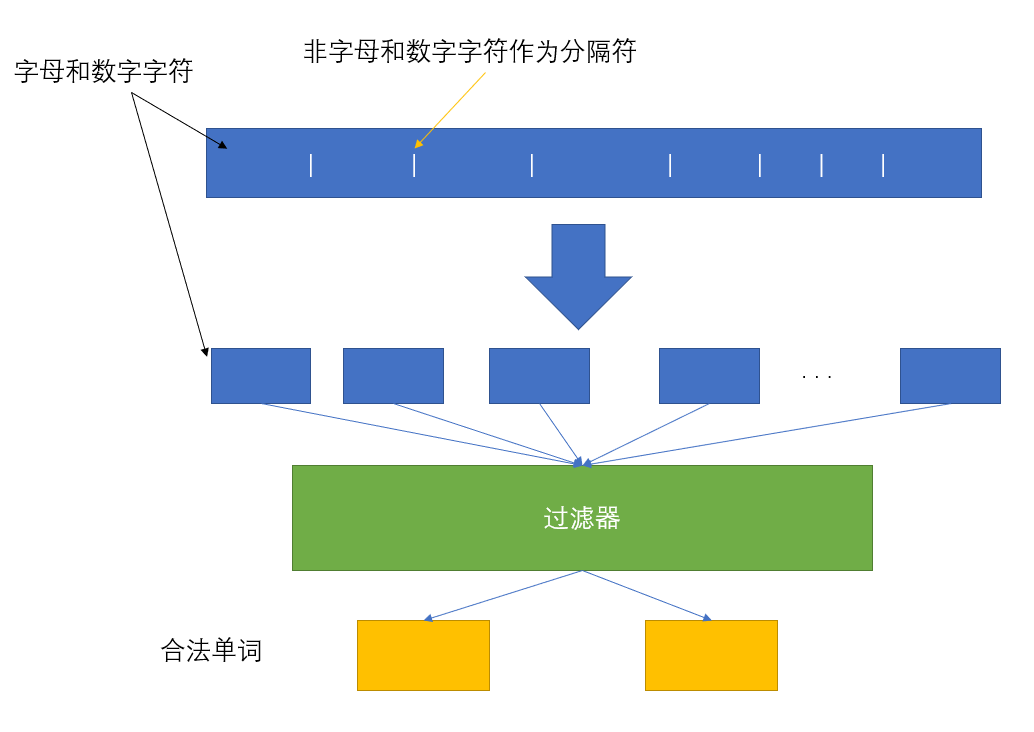
该算法的独到之处在于,其将文件看成是一个字符流,将所有的非字符数字的字符看成“剪刀”,首先将“剪刀”格式化成空格(这一步很重要,因为分隔符的可能性太多了),然后再统一分割,即可得到一个个独立的“候选单词”,最后再统一过滤即可,其示意图如下:
getMostFrequentlyWords函数
该函数返回文件流中出现次数最多的10个单词及其频率。这里的原理和getWordsCount函数类似,只不过在判断合法单词的时候,需要用Map记录每个单词出现的次数,最后将Map导入到一个List中,对于List里的每一个Map.Entry按出现频率->单词字典序的顺序排序即可。
public List<Map.Entry<String,Integer>> getMostFrequentlyWords(String file_info){
//先遍历一遍,将所有非字母数字的符号都换成空格符
StringBuilder builder = new StringBuilder(file_info);
for (int i=0;i<builder.length();i++){
char c = builder.charAt(i);
if (!Character.isDigit(c)&&!((c>='a'&&c<='z'||c>='A'&&c<='Z'))){
builder.setCharAt(i,' ');
}
}
//将其按空格拆分
String []words = builder.toString().split("\\s+");
//保存每个单词和其出现的频率
Map<String,Integer> words_map = new HashMap<>();
//该数组用于排序
List<Map.Entry<String,Integer>> words_arr = null;
//开始统计
for (int i=0;i<words.length;i++){
//首先得是合法单词
if (isWord(words[i])){
...
}
}
//排序
words_arr = new ArrayList<>(words_map.entrySet());
...
//从大到小,所以要翻转
Collections.reverse(words_arr);
return words_arr;
}
计算模块接口部分的性能改进
改进方向一:减少文件的读取次数
一开始我设计的函数是孤立存在的,每个函数都接收一个字符串参数,代表读取文件的路径,然后在每个函数中都进行一次文件存取,使得程序的效率十分低下。后来我利用fileToString函数,每次在程序执行最开始读取文件,将文件的内容保存到一个字符串当中,随后只对这个字符串进行处理,这使得程序进行IO的次数减少了一倍,速度也提升了许多。利用java里Date类的getTime函数可以计算程序总的执行时间,对于一个760339字符的文本,优化前后的结果如下所示。
| 优化前 | 优化后 |
|---|---|
| 425ms | 371毫秒 |
改进方向二:使用正则表达式来匹配空字符。
利用 split("\s+") 来划分字符串,而不是split(" "),这样做的好处是split(" ")有可能划分出空字符串,虽然空字符串不是一个正确合法的单词,但是函数的调用也需要额外的时间。

计算模块部分单元测试展示
部分单元测试代码
所有的测试函数均位于LibTest类中,对于Lib的每一个函数XXX,LibTest中都有一个testXXX函数与之对应。
@Test
//用于测试getAsciiCount函数
public void testGetAsciiCount(){
Lib lib = new Lib();
assertEquals(36,lib.getAsciiCount(lib.fileToString("test0.txt")));
assertEquals(0,lib.getAsciiCount(lib.fileToString("test1.txt")));
assertEquals(41,lib.getAsciiCount(lib.fileToString("test3.txt")));
}
@Test
//用于测试getWordsCount函数
public void testGetWordsCount(){
Lib lib = new Lib();
assertEquals(0,lib.getWordsCount(lib.fileToString("test1.txt")));
assertEquals(0,lib.getWordsCount(lib.fileToString("test0.txt")));
assertEquals(2,lib.getWordsCount(lib.fileToString("test3.txt")));
}
...
单元测试思路
- 应该考虑到空文件的输入情况。
- 应该考虑到输入参数少于2或者大于2的情况。
- 应该尽可能的使用ASCII字符和非ASCII字符,如汉字。
- 测试应该要包括空行,空格,以及其他非字母数字字符(作为分割符)
- 尽可能使得代码的每一个if,每一个case,每一个catch里的内容都得到执行。
其中,部分测试输入如下:
空文件test1.txt:
包含空格、空行、以及非ASCII字符的文件test4.txt:
单元测试覆盖率截图
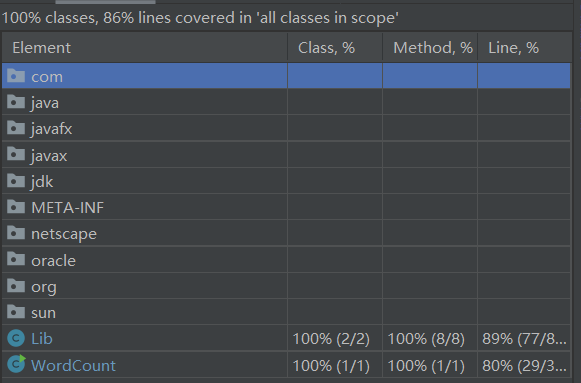
如何优化覆盖率?
在IDEA中,执行完Run Test with Coverage之后,会在代码的最左边显示绿条或者红条。如果是绿条,则说明测试代码已经覆盖该区域;若为红色,则说明没有覆盖,这时候需要专门设计一个针对该区域代码的测试用例,来提升覆盖率。

计算模块部分异常处理说明
在WordCount开头,先判断用户输入的参数个数是否正确?
对应场景:用户输入的文件地址参数过多或者过少。测试用例如下:
public void testWordCount(){
WordCount.main(new String[]{"input.txt"});
WordCount.main(new String[]{"input.txt","output.txt","aaa.txt"});
}
测试结果:

在WordCount验证参数个数正确之后,还要判断input.txt文件是否存在。
对应场景:用户输入的Input.txt文件不存在,或者路径错误。测试用例如下:
public void testWordCount(){
//这里input3333.txt不存在
WordCount.main(new String[]{"input3333.txt","output.txt"});
}
测试结果

输出的时候,判断output.txt是否创建成功。
对应场景:程序输出时,用户内存空间不足,或者创建output.txt文件失败。其测试用例如下:
@Test
public void testWordCount(){
//这里f:output.txt不存在,因为我的系统上没有f盘
WordCount.main(new String[]{"input.txt","f:output.txt"});
}
测试结果

关闭文件时,判断文件是否关闭成功。
对应场景:输出结果到程序,最后文件关闭失败。对应代码如下:
finally {
if (writer!=null){
try {
writer.close();
}catch (IOException e){
System.err.println(args[1]+"文件关闭失败");
}
}
}
PSP表格完善
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 55 |
| ·Estimate | 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 60 | 60+30 |
| ·Analysis | 需求分析(包括学习新技术) | 30 | 40 |
| ·Design Spec | 生成设计文档 | 30 | 40 |
| ·Design Review | 设计复审 | 60 | 53 |
| ·Coding Standard | 代码规范(为目前的开发制定合适的规范) | 14 | 10 |
| ·Design | 具体设计 | 1*60 | 1*60 |
| ·Coding | 具体编码 | 1*60 | 1*60 |
| ·Code Review | 代码复审 | 30 | 30 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| ·Reporting | 报告 | 20 | 20 |
| ·Test Repor | 测试报告 | 20 | 20 |
| ·Size Measurement | 计算工作量 | 10 | 10 |
| ·Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 60 |
| 合计 | 559 | 618 |
心路历程与收获
在本次作业中,我学会了:
- 利用测试单元来验证代码的准确性。
- 利用github来管理源代码。
- 体会了软件从设计到开发,再到测试,最后上线(上传到github)的全过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号