

 选用DF特征词选择法
选用DF特征词选择法

p.LoadDictionary(mymap,"F:\\finallyliuyu\\dict.dat");
p.DFcharicteristicWordSelection(mymap,2000,"F:\\finallyliuyu\\keywords.dat");
//建立VSM模型
p.LoadDictionary(mymap,"F:\\finallyliuyu\\dict.dat");
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
//为训练集建立VSM模型
p.VSMConstruction(mymap,trainingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
//为测试集建立VSM模型
p.GetManyVSM(1,600,"TestingCorpus",mymap,testingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
//KNN文本分类
p.LoadVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
p.LoadVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
p.KNNclassifier("TrainingCorpus",trainingSetVSM,testingSetVSM,labels,100,classifyResults);
ofstream ofile("F:\\finallyliuyu\\evaluation.txt");
//准确率召回率F值的计算, 评估分类器
map<string,vector<double> >evaluation;
for(vector<string>::iterator it=labels.begin();it!=labels.end();it++)
{
double precision=p.getPrecision(*it,classifyResults,"TestingCorpus");
double recall=p.getRecall(*it,classifyResults,"TestingCorpus");
double F=p.getFscore(*it,classifyResults,"TestingCorpus");
vector<double>temp;
temp.push_back(precision);
temp.push_back(recall);
temp.push_back(F);
evaluation[*it]=temp;
temp.clear();
}
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
cout<<it->first<<endl;
ofile<<it->first<<endl;
cout<<"precison"<<(it->second)[0]<<endl;
ofile<<"precison"<<(it->second)[0]<<endl;
cout<<"recall"<<(it->second)[1]<<endl;
ofile<<"recall"<<(it->second)[1]<<endl;
cout<<"Fscore"<<(it->second)[2]<<endl;
ofile<<"Fscore"<<(it->second)[2]<<endl;
cout<<"*************************"<<endl;
}
double avaP=0.;//平均准确率
double avaR=0.;//平均召回率
double avaF=0.;//平均F值
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
avaP+=(it->second)[0];
avaR+=(it->second)[1];
avaF+=(it->second)[2];
}
cout<<evaluation.size();
avaP/=evaluation.size();
avaR/=evaluation.size();
avaF/=evaluation.size();
cout<<"平均准确率为"<<avaP<<endl;
ofile<<"平均准确率为"<<avaP<<endl;
cout<<"平均召回率"<<avaR<<endl;
ofile<<"平均召回率"<<avaR<<endl;
cout<<"平均F值"<<avaF<<endl;
ofile<<"平均F值"<<avaF<<endl;
ofile.close();
分类效果评估:

选用卡方特征词选择算法
p.LoadDictionary(mymap,"F:\\finallyliuyu\\dict.dat");
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
p.ChiSquareFeatureSelection(labels,mymap,contingenyTable,2000,"F:\\finallyliuyu\\keywords.dat");
//建立VSM模型
p.LoadDictionary(mymap,"F:\\finallyliuyu\\dict.dat");
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
//为训练集建立VSM模型
p.VSMConstruction(mymap,trainingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
//为测试集建立VSM模型
p.GetManyVSM(1,600,"TestingCorpus",mymap,testingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
//KNN文本分类
p.LoadVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
p.LoadVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
p.KNNclassifier("TrainingCorpus",trainingSetVSM,testingSetVSM,labels,100,classifyResults);
ofstream ofile("F:\\finallyliuyu\\evaluation.txt");
//准确率召回率F值的计算, 评估分类器
map<string,vector<double> >evaluation;
for(vector<string>::iterator it=labels.begin();it!=labels.end();it++)
{
double precision=p.getPrecision(*it,classifyResults,"TestingCorpus");
double recall=p.getRecall(*it,classifyResults,"TestingCorpus");
double F=p.getFscore(*it,classifyResults,"TestingCorpus");
vector<double>temp;
temp.push_back(precision);
temp.push_back(recall);
temp.push_back(F);
evaluation[*it]=temp;
temp.clear();
}
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
cout<<it->first<<endl;
ofile<<it->first<<endl;
cout<<"precison"<<(it->second)[0]<<endl;
ofile<<"precison"<<(it->second)[0]<<endl;
cout<<"recall"<<(it->second)[1]<<endl;
ofile<<"recall"<<(it->second)[1]<<endl;
cout<<"Fscore"<<(it->second)[2]<<endl;
ofile<<"Fscore"<<(it->second)[2]<<endl;
cout<<"*************************"<<endl;
}
double avaP=0.;//平均准确率
double avaR=0.;//平均召回率
double avaF=0.;//平均F值
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
avaP+=(it->second)[0];
avaR+=(it->second)[1];
avaF+=(it->second)[2];
}
cout<<evaluation.size();
avaP/=evaluation.size();
avaR/=evaluation.size();
avaF/=evaluation.size();
cout<<"平均准确率为"<<avaP<<endl;
ofile<<"平均准确率为"<<avaP<<endl;
cout<<"平均召回率"<<avaR<<endl;
ofile<<"平均召回率"<<avaR<<endl;
cout<<"平均F值"<<avaF<<endl;
ofile<<"平均F值"<<avaF<<endl;
ofile.close();
分类效果评测:
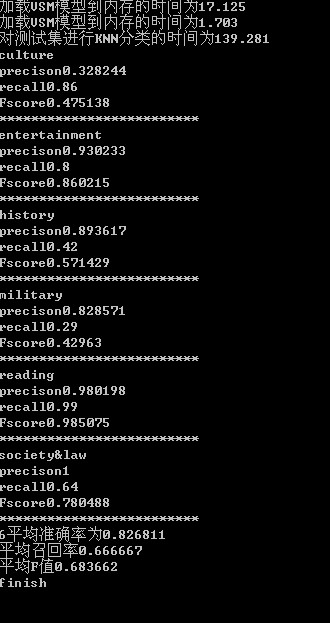
选用IG特征词选择算法
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
p.InformationGainFeatureSelection(labels,mymap,contingenyTable,2000,"F:\\finallyliuyu\\keywords.dat");
//建立VSM模型
p.LoadDictionary(mymap,"F:\\finallyliuyu\\dict.dat");
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
//为训练集建立VSM模型
p.VSMConstruction(mymap,trainingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
//为测试集建立VSM模型
p.GetManyVSM(1,600,"TestingCorpus",mymap,testingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
//KNN文本分类
p.LoadVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
p.LoadVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
p.KNNclassifier("TrainingCorpus",trainingSetVSM,testingSetVSM,labels,100,classifyResults);
ofstream ofile("F:\\finallyliuyu\\evaluation.txt");
//准确率召回率F值的计算, 评估分类器
map<string,vector<double> >evaluation;
for(vector<string>::iterator it=labels.begin();it!=labels.end();it++)
{
double precision=p.getPrecision(*it,classifyResults,"TestingCorpus");
double recall=p.getRecall(*it,classifyResults,"TestingCorpus");
double F=p.getFscore(*it,classifyResults,"TestingCorpus");
vector<double>temp;
temp.push_back(precision);
temp.push_back(recall);
temp.push_back(F);
evaluation[*it]=temp;
temp.clear();
}
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
cout<<it->first<<endl;
ofile<<it->first<<endl;
cout<<"precison"<<(it->second)[0]<<endl;
ofile<<"precison"<<(it->second)[0]<<endl;
cout<<"recall"<<(it->second)[1]<<endl;
ofile<<"recall"<<(it->second)[1]<<endl;
cout<<"Fscore"<<(it->second)[2]<<endl;
ofile<<"Fscore"<<(it->second)[2]<<endl;
cout<<"*************************"<<endl;
}
double avaP=0.;//平均准确率
double avaR=0.;//平均召回率
double avaF=0.;//平均F值
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
avaP+=(it->second)[0];
avaR+=(it->second)[1];
avaF+=(it->second)[2];
}
cout<<evaluation.size();
avaP/=evaluation.size();
avaR/=evaluation.size();
avaF/=evaluation.size();
cout<<"平均准确率为"<<avaP<<endl;
ofile<<"平均准确率为"<<avaP<<endl;
cout<<"平均召回率"<<avaR<<endl;
ofile<<"平均召回率"<<avaR<<endl;
cout<<"平均F值"<<avaF<<endl;
ofile<<"平均F值"<<avaF<<endl;
ofile.close();
分类结果评测:
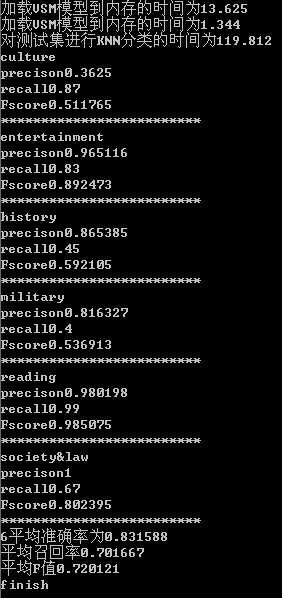
选用point-wiseMI特征词选择法
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
p.PointWiseMIFeatureSelection(labels,mymap,contingenyTable,2000,"F:\\finallyliuyu\\keywords.dat");
p.LoadDictionary(mymap,"F:\\finallyliuyu\\dict.dat");
p.LoadContingencyTable(contingenyTable,"F:\\finallyliuyu\\contingency.dat");
//为训练集建立VSM模型
p.VSMConstruction(mymap,trainingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
//为测试集建立VSM模型
p.GetManyVSM(1,600,"TestingCorpus",mymap,testingSetVSM,"F:\\finallyliuyu\\keywords.dat");
p.SaveVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
//KNN文本分类
p.LoadVSM(trainingSetVSM,"F:\\finallyliuyu\\trainingVSM.dat");
p.LoadVSM(testingSetVSM,"F:\\finallyliuyu\\testingVSM.dat");
p.KNNclassifier("TrainingCorpus",trainingSetVSM,testingSetVSM,labels,100,classifyResults);
ofstream ofile("F:\\finallyliuyu\\evaluation.txt");
//准确率召回率F值的计算, 评估分类器
map<string,vector<double> >evaluation;
for(vector<string>::iterator it=labels.begin();it!=labels.end();it++)
{
double precision=p.getPrecision(*it,classifyResults,"TestingCorpus");
double recall=p.getRecall(*it,classifyResults,"TestingCorpus");
double F=p.getFscore(*it,classifyResults,"TestingCorpus");
vector<double>temp;
temp.push_back(precision);
temp.push_back(recall);
temp.push_back(F);
evaluation[*it]=temp;
temp.clear();
}
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
cout<<it->first<<endl;
ofile<<it->first<<endl;
cout<<"precison"<<(it->second)[0]<<endl;
ofile<<"precison"<<(it->second)[0]<<endl;
cout<<"recall"<<(it->second)[1]<<endl;
ofile<<"recall"<<(it->second)[1]<<endl;
cout<<"Fscore"<<(it->second)[2]<<endl;
ofile<<"Fscore"<<(it->second)[2]<<endl;
cout<<"*************************"<<endl;
}
double avaP=0.;//平均准确率
double avaR=0.;//平均召回率
double avaF=0.;//平均F值
for(map<string,vector<double> >::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
avaP+=(it->second)[0];
avaR+=(it->second)[1];
avaF+=(it->second)[2];
}
cout<<evaluation.size();
avaP/=evaluation.size();
avaR/=evaluation.size();
avaF/=evaluation.size();
cout<<"平均准确率为"<<avaP<<endl;
ofile<<"平均准确率为"<<avaP<<endl;
cout<<"平均召回率"<<avaR<<endl;
ofile<<"平均召回率"<<avaR<<endl;
cout<<"平均F值"<<avaF<<endl;
ofile<<"平均F值"<<avaF<<endl;
ofile.close();
实验结果评测:
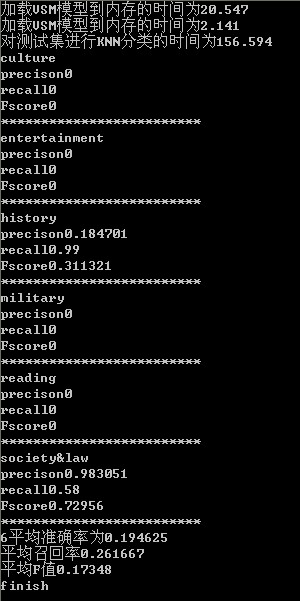
四种特征词选择算法得到的precision,recall,F-score对比如下

图1
从上面的结果可以看出IG法和CHI法各项评测指标对比结果相当,point-wise MI法性能最不稳定。DF法的各项评测指标似乎没有达到预期的与IG,CHI持平,这里的原因是上面采用的DF法是针对整个训练语料库按词频排序并且进行特征词选择的,或者我们可以称其为“全局DF法”,这种DF法可以在聚类问题中使用,因为在聚类问题中事先没有类别标识信息。如果采用局部DF法,即将全部候选词针对某个特定的类别按DF排序,某个特定类别分别选取特征词,然后构成整个分类问题的特征词空间

图2
从上面的图可以看出,在总类别选2000个特征词的情况下,按类别的DF算法的评测结果要优于全局DF法;point-wise MI效果最差。
另外我们要求对的训练语料库选取2000个特征词,但实际中由于针对各个类别遴选出的特征词有交集,故实际特征词数目不足2000。下面给出实际特征词数量数据

表1
综合图1,图2和表一。我们可以得出下列结论: IG和CHISquare的鲁棒性要比按类别DF法(local DF法)强:即这两种特征词选择法选出来的词更distinctive for each categorization,也就是说交集比较小;特征词本身的“性质”要比单纯的特征词数量更能对分类结果造成影响(比如: MI法选了1998个特征词的分类效果远不如local DF法选取889个特征词的分类效果);同理推出point MI法选取的特征词分类性能之所以不好,是因为选取的特征词“本身”不好。具体原因是因为这种方法选取了很多不具有类别标引向功能的罕见词(具体分析见Yi Ming Yang 论文)由于MI法趋向于选择稀有词,所以MI法选择的词交集比较小,distingwished between classlabel。
当我们把按类别DF法(或称localDF)的总特征维度设置为4000时,实际特征词数目为1696。各项评测指标如下
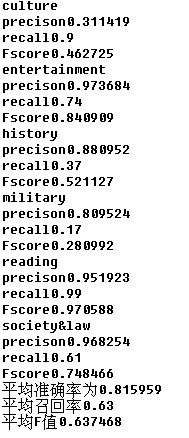
由此可见:Yi Ming Yang论文中所提到的DF法和IG,CHI-square法对分类效能影响相当是在三种特征词选择方法选取的特征维数也相当的条件下得出的。但是总体上来讲还是IG,CHI-square的鲁棒性更强:在全局DF法中,很可能会造成特征词对类别选取不均匀,比如本博文的例子中,全局DF法选取的2000个词中几乎不包含索引reading类别的词,从而导致reading类的precison h和recall都为0;在局部DF法中,针对各个类别用DF法选择的特征词有很大的交集,不太具有类别区分性。
我们下面选取1000个特征词,重复上面的实验
结果如下:

实际选取的特征词情况如下表:

通过选取2000个特征词与选取1000个特征词两次实验的对比:

我们可以再次验证上面的结论。并且得出结论,并不是特征词数目越多,分类性能越好。
总结:评价一个特征词是否是好词,一个特征词集合是否选择的合理。主要看所选择的词是否具有类别标识性。所谓类别标识性有以下两点含有:1。Distinctive for categorization:也就是说,如果该词出现则可以以一个很大的概率将文章归为某类。2。该词在它所“标识”的类别中应该频繁出现。DF法选择的特征词满足第二个条件多一点;而点互信息法选择的特征词只满足第一个条件多一点;而IG法和卡方法在满足两个条件方面达到了均衡。所以 IG和卡方法性能差不多优于DF法优于点互信息法。(注:这是我个人的一点见地,如有偏颇的地方欢迎指正)
下面再上一张图,我们“透视”一下DF,按类别DF,IG,卡方,点互信息法选取的特征词

上图中给了5种算法所遴选出的前37个特征词的情况,通过查看特征词文件我们可以进一步论证我们的结论:IG和卡方法遴选出的特征词集合交集比较大,所以这两种特征词选择算法对文本分类性能的影响也类似,MI倾向于选择稀有词。
我们观察一下按类别DF法,IG法,卡方法搜选取的top1 词汇,均为BigNews.其实这个词是一个噪声词。凤凰网新闻的每一个新闻正文网页都有这个词,而且我的新闻正文提取算法会把BigNews当成正文抓取下来。
由此我们可以得出这样的结论: IG法,卡方法,虽然有抑制高频词噪声和低频词噪声的能力,但是归根结底,这两种方法是基于频率的统计推断,不能够有效抑制全部高频词噪声,如果要提高特征词集合抑制高频词噪声的能力,可能要求诸于统计贝叶斯推断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号