

个人项目:论文查重
个人项目
| 软件工程 | 网工1934 |
|---|---|
作业要求: 1、在Github仓库中新建一个学号为名的文件夹。 2、在开始实现程序之前,在PSP表格记录下你估计在程序开发各个步骤上耗费的时间,在你实现程序之后,在PSP表格记录下你在程序的各个模块上实际花费的时间。 3、编程语言不限,将编译好的程序发布到Github仓库中的releases中 4、提交的代码要求经过Code Quality Analysis工具的分析并消除所有的警告。 5、完成项目的首个版本之后,请使用性能分析工具Studio Profiling Tools来找出代码中的性能瓶颈并进行改进。 6、使用Github[附录3]来管理源代码和测试用例,代码有进展即签入Github。签入记录不合理的项目会被助教抽查询问项目细节。 7、使用单元测试[附录4]对项目进行测试,并使用插件查看测试分支覆盖率等指标;写出至少10个测试用例确保你的程序能够正确处理各种情况。 |
作业要求 |
| 作业目标: 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 |
作业代码连接
- GitHub:地址
实现思路
1、命令行接收参数,判断是否出错
2、对文档进行处理,除去标点符号的影响
3、利用Levenshtein算法算出相似度
4、写入文件
- python包:Levenshtein,re,time,sys
核心算法
Levenshtein距离:两个字符之间,有一个转变成另一个所需的最少编辑操作次数

- 即数出转换所需要的步数,然后根据得到步数算相似度
- 和余弦算两者距离相似,只不过Levenshtein算法注重的是编辑距离
关键函数流程图
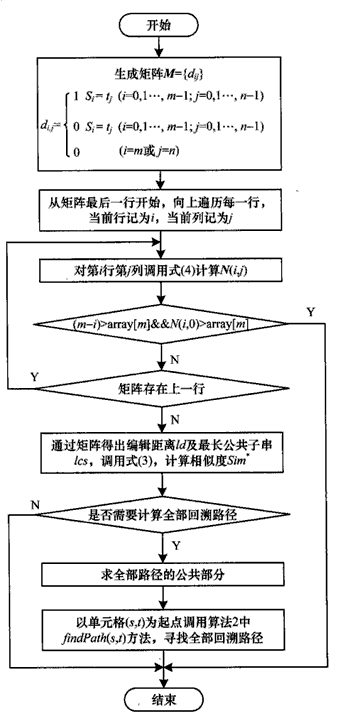
性能改进
改进前(动态规划)
def normal_leven(str1, str2):
len_str1 = len(str1) + 1
len_str2 = len(str2) + 1
matrix = [0 for n in range(len_str1 * len_str2)]
#矩阵的第一行
for i in range(len_str1):
matrix[i] = i
# 矩阵的第一列
for j in range(0, len(matrix), len_str1):
if j % len_str1 == 0:
matrix[j] = j // len_str1
# 根据状态转移方程逐步得到编辑距离
for i in range(1, len_str1):
for j in range(1, len_str2):
if str1[i-1] == str2[j-1]:
cost = 0
else:
cost = 1
matrix[j*len_str1+i] = min(matrix[(j-1)*len_str1+i]+1,
matrix[j*len_str1+(i-1)]+1,
matrix[(j-1)*len_str1+(i-1)] + cost)
return matrix[-1] # 返回矩阵的最后一个值,也就是编辑距离
可以看到,运行时间较长且占用很多系统资源

改进后(利用包Levenshtein将时间复杂度优化,提高准确率的同时,大大缩减了运行所需时间)


异常处理
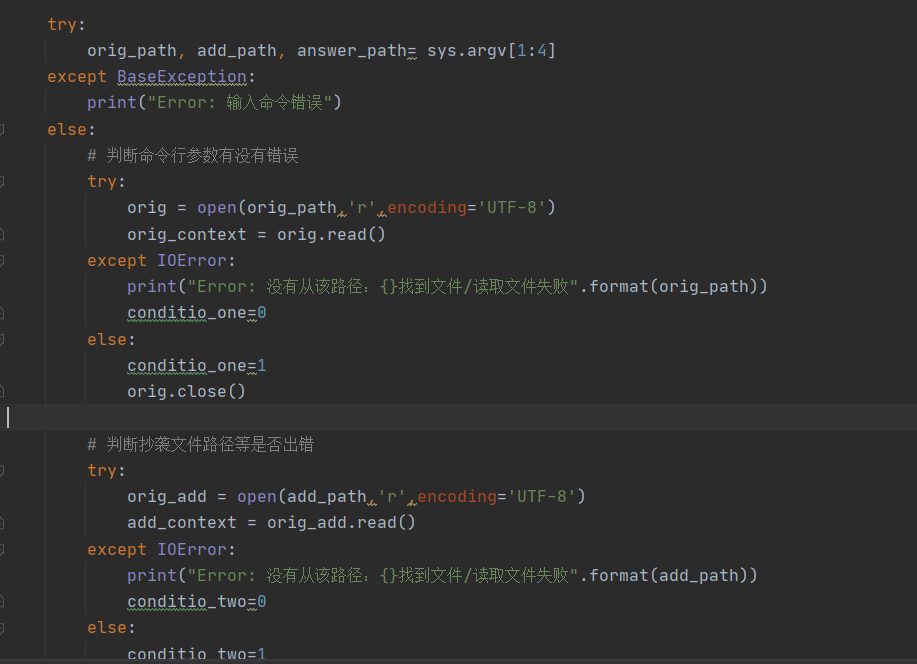
效果图:
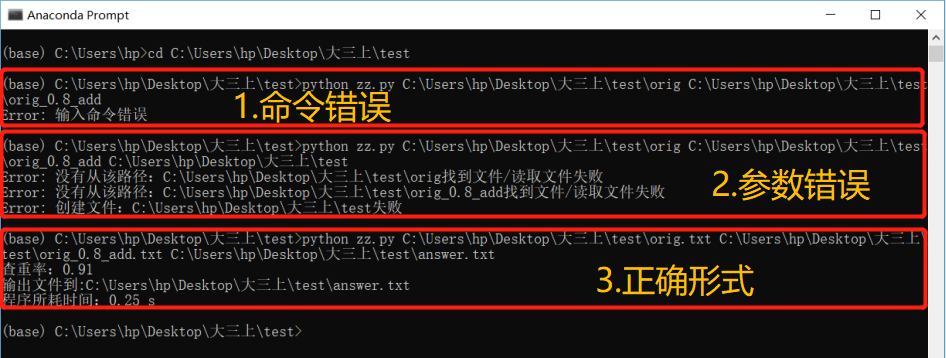
- 可以看到当输入命令错误/路径错误/文件不存在时,都会报错显示出原因
- 在读取指定文件路径时,如果文件路径不存在,程序将会出现异常并且报出相应错误,因此可以在读取指定文件内容之前先判断文件是否存在,若不存在则做出响应并且结束程序。
测试其他文件(单元测试结果)
在pycharm的Edit Configuration中添加Python test进行单元测试
代码覆盖率:100
源文件:orig.txt
抄袭文件:orig_copy.txt(同一份文件)
转换所需步长:0
查重率:1.00
源文件:orig.txt
抄袭文件:orig_other.txt(其他文件)
转换所需步长:8316
查重率:0.03
源文件:orig.txt
抄袭文件:orig_0.8_add.txt
转换所需步长:1763
查重率:0.91
源文件:orig.txt
抄袭文件:orig_0.8_del.txt
转换所需步长:1656
查重率:0.89
源文件:orig.txt
抄袭文件:orig_0.8_dis_1.txt
转换所需步长:429
查重率:0.97
源文件:orig.txt
抄袭文件:orig_0.8_dis_10.txt
转换所需步长:1562
查重率:0.84
源文件:orig.txt
抄袭文件:orig_0.8_dis_15.txt
转换所需步长:3123
查重率:0.67
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 200 | 250 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 35 |
| · Design Spec | · 生成设计文档 | 25 | 20 |
| · Design Review | · 需求分析 (包括学习新技术) | 45 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 10 |
| · Design | · 具体设计 | 35 | 30 |
| · Coding | · 具体编码 | 200 | 180 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 80 | 60 |
| Reporting | 报告 | 50 | 80 |
| · Test Repor | · 测试报告 | 35 | 20 |
| · Size Measurement | · 计算工作量 | 25 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 45 | 60 |
| · 合计 | 900 | 895 |
拓展
1、尝试过许多种办法,包括利用jieba分词,余弦算出距离得出相似度,gensim.dictionary.doc2bow等等,但是结果过于夸张(接近1)感觉不对劲
且当用在更大的文本数据时,所耗费的时间占用的系统资源结果不理想,改用Levenshtein算法
2、对于Levenshtein动态规划
中文解析

3、通过多次复制粘贴(扩大数据)做对照试验可得出,Levenshtein距离算法相比其他算法对数据较大得优化处理得更快更好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号