【C++】2、类与对象
零、准备工作
1、安装及配置
为了提前适应后续Qt的学习,所以讲师给我们推荐的是使用Qt来编写C++工程的,当时使用了一段时间,说实话感觉还行,不用咋配置都能自带一个G++,虽然我不是很喜欢那种原始的弹出式的黑窗口,但也差强人意吧。
除却配置环境外,我们还需要安装一些插件,但目前已经重新安装好了,懒得重新来一次,等下次有机会在这里补充一下过程。
下面是一个Qt的安装包:
https://pan.quark.cn/s/1de46ba66e74
2、快捷键
| 快捷键 | 功能 |
|---|---|
Ctrl + R |
运行当前工程 |
一、面向过程和面向对象
这两个玩意其实还是比较抽象的,讲师并没有讲的透彻,甚至连这玩意到底是什么个东西都没讲清楚。
找了一会,发现了一个可以对二者有一个简单直观认识的博客:https://zhuanlan.zhihu.com/p/28427324
然后还发现了一片对于二者辨析和描述很不错的文章:https://developer.aliyun.com/article/1003526,在本标题下我会大篇幅引用本文章的内容,在此处提前做一下说明,侵联删。
1、什么是面向过程
自顶而下的编程模式,把问题分解为一个一个步骤,每个步骤用函数实现,依次调用即可。
也就是说,在进行面向过程编译的时候,不需要考虑那么多,上来先定义一个函数,然后使用各种诸如 if-else、for、switch 等方式进行代码执行。
我们之前学习的 C 语言就是典型的面对过程的语言,例如在写项目的时候,我们就是先写出一个个小的功能模块,然后在大的功能模块中中用各种逻辑语法将其进行整合,使能够执行比较复杂的功能,即变成一个较大的功能模块,然后我们就直接在主函数中调用这些较大的功能模块即可,在开发上还是较为简单的。
2、什么是面向对象
将事物高度抽象化的编程模式,将问题分解为一个一个步骤,对每个步骤进行相应的抽象,形成对象,通过不同对象之间的调用,组合解决问题。
就是说,在进行面向对象进行编程的时候,要把属性、行为等封装成对象,然后基于这些对象及对象的能力进行业务逻辑的实现。
我们现在学习的 C++就是一门面向对象的语言,除此之外,还有 Java,C#
3、二者的区别
编程思想的不同:
- 面向过程:是一种以过程为中心的编程思想,都是以正在发生的事情为主要目标进行编程;
- 面向对象:是一种以对象为基本编程单位的编程思想,用于描述事件的基本属性和基本行为
编程特点的不同:
- 面向过程:分析出解决问题的需求步骤,然后通过函数将这些步骤逐步实现,使用的时候依次调用
- 面向对象:系统中将事物的基本属性和行为方法进行抽象,在使用过程中建立不同的操作对象进行执行,对象具有唯一的静态类型和多个可能的动态模型,在基本层次关系不同类对象共享数据
优势不同:
- 面向过程:不支持丰富的代码复用(继承)和接口多用(多态)
- 面向对象:在内部被表示为一个指向一组属性的指针,任何对这个对象的操作都会经过该指针,通过它操作对象的属性和行为
二、抽象和封装
1、抽象
即对于具体事物 进行概括,抽出这类对象的共有特性加以描述。
- 数据抽象(性质抽象):描述该类对象的属性或者状态,形成数据成员,成员属性在代码中表现为变量
- 方法抽象(行为抽象):描述该类行为的行为特征或具有的功能,形成方法成员,成员方法在代码中表现为函数
2、封装
将抽象出来的数据和方法成员进行接合,把可以公开的属性和方法设置为公有权限,将不可以公开的属性和方法设置为私有或者保护权限,通过 C++的语法对抽象内容进行封装成一个整体(也就是我们常说的类)
C++ 中的类是具备权限限定的,主要指的是对象访问时是否有权限进行操作。
C++中的结构体都是共有属性,也就是说谁都可以直接访问。
三、类的设计
类是一种复杂的数据类型,类和对象的关系类似于基本数据类型和变量的关系。
1、类的关键字
class
2、类的框架
class 类名
{
权限限定:
成员;
};
3、类的特点
- 成员包括成员数据(属性、数据变量)和操作方法(行为、成员函数)
- 成员具备的访问权限:
- public 公开权限,对外公开,结构体中的成员都是默认共有属性
- protected 保护属性,对外隐藏,对内公开
- private 私有权限,对外隐藏,对内公开,该属性属于默认属性,即在类中若不声明成员属性,则默认为私有属性
- 类的设计属于自定义数据类型,类本身不占用内存空间,只有在实例化的时候才会分配内存空间
- 定义类的时候尽量首字母大写
#include <iostream>
using namespace std;
// define a class for student
class Student
{
};
int main()
{
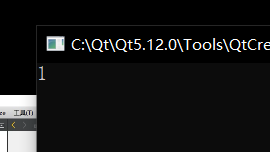
cout << sizeof(Student) << endl;
return 0;
}
#include <iostream>
using namespace std;
// define a class for student
class Student
{
int a;
};
int main()
{
cout << sizeof(Student) << endl;
return 0;
}
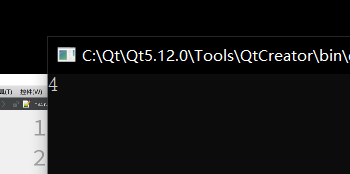
可以看到,在仅仅定义出类的时候,还是有一个字节的内存的,这不代表它就是会占用一个内存,而是因为 C++的规定,每个实例在内存中都有一个唯一的地址,为了达到这个目的,编译器会给空类隐含添加一个字节,以保证空类实例化后所在内存中得到的地址是独一无二的,这里用 sizeof 计算类的大小时,实际上是计算该类实例化后的大小,当然会打印出一个字节。
基于这个观点,我给 Student 类中给一个 int 型变量,这个类的大小也仅仅是 4 字节,压根就没有计算刚刚那个 1 字节,也印证了类本身并不会占用内存。
以上说法参照了博客:<https://www.cnblogs.com/zhongqifeng/p/14622947.html#:~: text=%E7%B1%BB%E5%8D%A0%E5%86%85%E5%AD%98%E7%A9%BA%E9%97%B4%E6%98%AF%E5%8F%AA,%E4%BC%9A%E5%8D%A0%E5%86%85%E5%AD%98%E7%A9%BA%E9%97%B4%E7%9A%84%E3%80%82>
其中对类的内存进行了较深的讲解,可以看看。
四、类和对象的调用
1、实例化对象
即创建对象,而对象这玩意也比较抽象,但总归使能用一个变量去表示的,这一点不应该去怀疑,就比如我们之前用到过的结构体,里面可以包含的小变量很多,用来逐个代表不同属性,足以描述一个事物。
而既然能够用变量去描述对象,那么兼容性强于变量的指针自然也行,所以对于对象这玩意,在这里主要将他们分为两类:变量类对象,指针类对象
变量类对象:类名 对象名 :
指针类对象: 类名 *指针名 = new 类名;
#include <iostream>
using namespace std;
// define a class for student
class Student
{
public:
void func()
{
cout << "func()" << endl;
}
private:
int a;
};
int main()
{
// Instantiate object
Student jack;
Student* rose = new Student();
// Calculate size
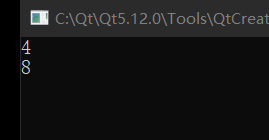
cout << sizeof(jack) << endl;
cout << sizeof(rose) << endl;
return 0;
}
2、对象如何调用
与结构体类似,对象调用类中的数据是通过操作运算符 . 和 -> 来实现的:
#include <iostream>
using namespace std;
// define a class for student
class Student
{
public:
void func()
{
cout << "func()" << endl;
}
private:
int a = 1;
public:
int b = 2;
};
int main()
{
// Instantiate object
Student jack;
Student* rose = new Student();
// Calculate size
cout << sizeof(jack) << endl;
cout << sizeof(rose) << endl << endl;
// Call object
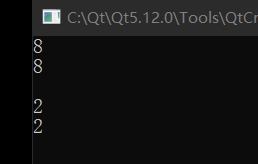
cout << jack.b << endl;
cout << rose->b << endl;
return 0;
}
可以看到,上面的调用都是针对 public 的,若是换成 private,则会报错:
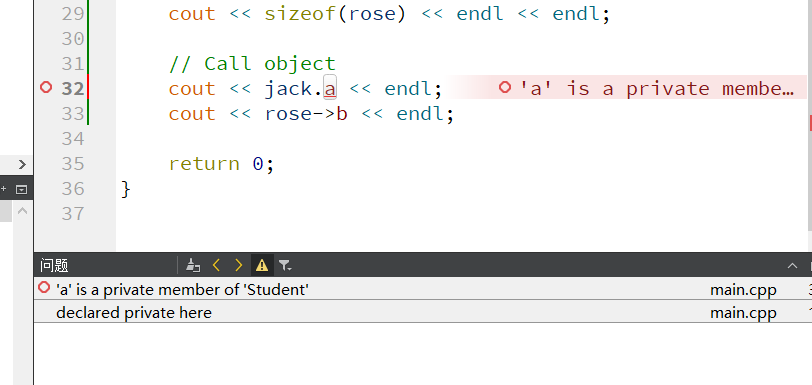
但private 的数据若是通过公开接口来获取,也是可以得到其数据的:
#include <iostream>
using namespace std;
// define a class for student
class Student
{
public:
void func()
{
cout << "func()" << endl;
cout << a << endl;
}
private:
int a = 1;
};
int main()
{
// Instantiate object
Student jack;
// Call object
jack.func();
return 0;
}
将这个例程写的更复杂一点:
#include <iostream>
using namespace std;
// define a class for student
class Student
{
public:
// Set function
void set_data(string name1, int age1, double height1)
{
name = name1; // The right side is the parameter for this function, the left side are the variables for private permissions
age = age1;
height = height1;
}
void get_data()
{
cout << "name:" << name << " age:" << age << " height:" << height << endl;
}
private:
string name;
int age;
double height;
};
int main()
{
// Instantiate object
Student jack;
Student* rose = new Student;
// Call object
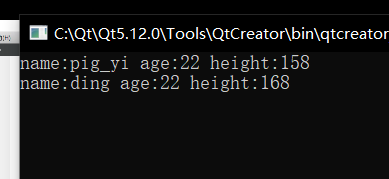
jack.set_data("pig_yi", 22, 158);
jack.get_data();
rose->set_data("ding", 22, 168);
rose->get_data();
return 0;
}
对以上的代码再次进行优化,优化内容在于可以单独修改对象的属性,当然,跟之前的思路一样,修改的函数也要写在 public 里面:
#include <iostream>
using namespace std;
// define a class for student
class Student
{
public:
// Set function
void set_data(string name1, int age1, double height1)
{
name = name1; // The right side is the parameter for this function, the left side are the variables for private permissions
age = age1;
height = height1;
}
void get_data()
{
cout << "name:" << name << " age:" << age << " height:" << height << endl;
}
// Set a variable separately
void set_name(string name1)
{
name = name1;
}
void get_name()
{
cout << "name:" << name << endl;
}
private:
string name;
int age;
double height;
};
int main()
{
// Instantiate object
Student jack;
// Call object
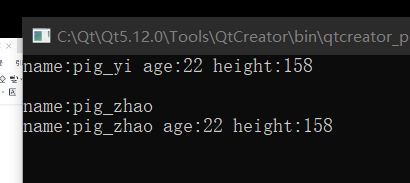
jack.set_data("pig_yi", 22, 158);
jack.get_data();
cout << endl;
// Call a variable individually
jack.set_name("pig_zhao");
jack.get_name();
jack.get_data();
return 0;
}
对于 protected 类型的,讲师暂时没有讲,我认为暂时不需要了解,就先看后面了。
五、this 指针
1、this 指针是什么东东
在上面的调用对象环节,我出现了一个 bug,起初没有注意,因为按照 C 的逻辑,那个 bug 是不应该出现的,可他出现了,就证明 C++在那个地方有所改进。
也是看讲师的课没听懂,去 B 站逛了逛,发现小神仙小姐姐有一期视频,就很开心,打开后小神仙写了个例程,没想到就是我之前的那个 bug,实在是太巧了。
我现在懒得复现自己的,直接把小姐姐的例程搬过来:
#include <cstdio>
#include <iostream>
using namespace std;
class Student
{
public:
int get_age()
{
return age;
}
void set_age(int age)
{
age = age;
cout << "age = " << age << endl;
}
private:
int age;
};
int main()
{
Student s;
s.set_age(18);
cout << s.get_age() << endl;
return 0;
}
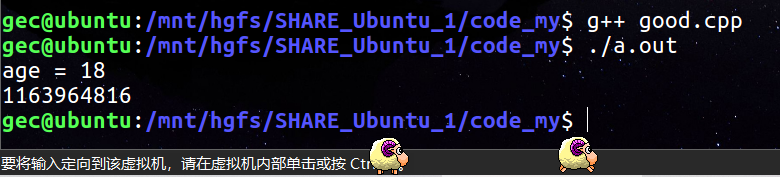
可以看到,cout << s.get_age() << endl; 这行代码打出来的是一个随机值,这个说明在 set_age 函数中,age = age; 的右边的 age 并没有把值顺利传递到 get_age 函数中
`
按照小神仙小姐姐的说法,当函数的形参名和类的属性名相同的时候,如果不手动对其进行区分,系统默认两个 age 都是这个函数里面的 age 都是属性的那个 age,也就是说自己把一个随机值赋值给了自己。
这时候,我们就可以用 this 来对其进行区分了:
void set_age(int age)
{
this->age = age;
cout << "age = " << age << endl;
}
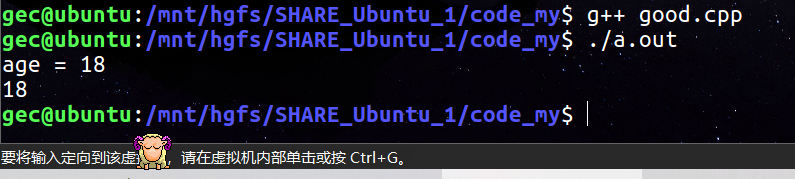
当然,我们也可以对这个函数进行优化,让他可以直接返回:
#include <cstdio>
#include <iostream>
using namespace std;
class Student
{
public:
int get_age()
{
return age;
}
Student set_age(int age)
{
this->age = age;
cout << "age = " << age << endl;
return *this;
}
private:
int age;
};
int main()
{
Student s;
s = s.set_age(18);
cout << s.get_age() << endl;
return 0;
}
2、this 指针的三个结论
(1)、this 指针不占用内存
继续按照神仙小小姐姐的视频看下去:先来看她的第一个问题的答案回答:this 指针不占用内存空间,验证的代码如下:
int main()
{
cout << sizeof(Student) << endl;
return 0;
}

可以看到对象 Student 的大小为 4 个字节,刚好等于其内的 int 型的 age 的大小,所以说该对象中的 this 指针是不占内存的。
为什么呢?去问编译器吧,是他干的。
(2)、this 指针的指向与概念
第二个结论:this 指针是指向对象的指针,即指向对象的首地址,验证如下:
#include <cstdio>
#include <iostream>
using namespace std;
class Student
{
public:
int get_age()
{
return age;
}
Student set_age(int age)
{
this->age = age;
cout << "age = " << age << endl;
return *this;
}
void test()
{
cout << "The address pointed to by the test pointer:\t" << this << endl;
}
private:
int age;
};
int main()
{
Student s;
s.test();
cout << "Address of instance object s:\t" << &s << endl;
return 0;
}

可以看到结论是得到了验证的,那么这是如何实现的呢?
这个问题其实还的看 C++本身,或者说编译器为我们做了很多我们不知道的事情,就比如说在类中定义函数的时候,给我们添加了一个叫做 this 的指针,然后又在我们调用该函数的时候把对象的地址偷偷传了进去。
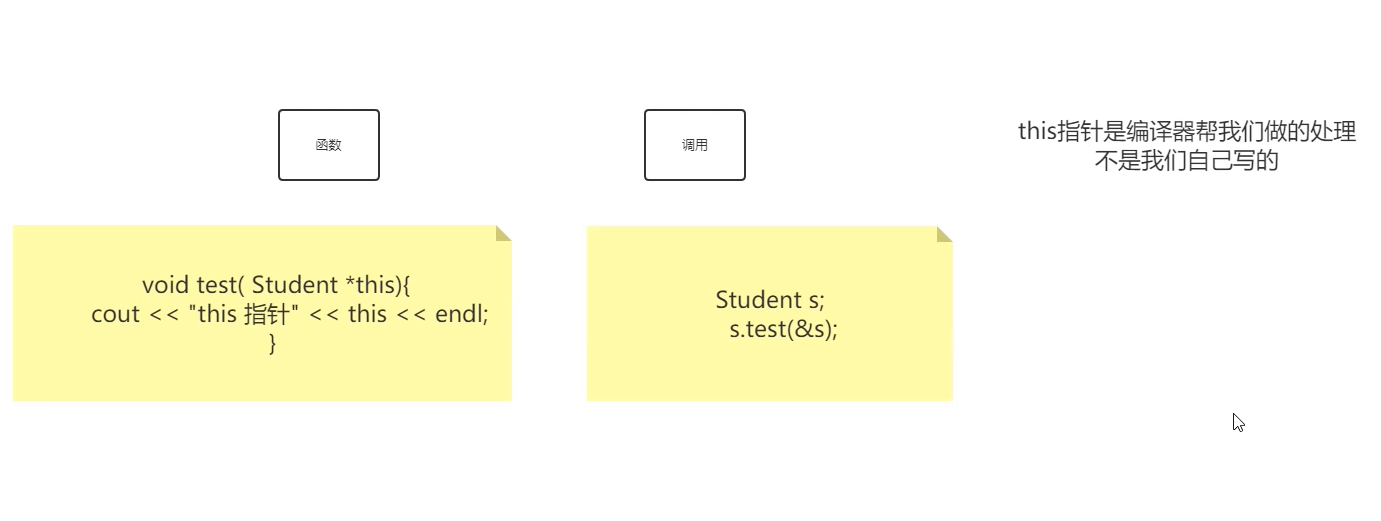
上面是小小神仙姐姐画的,大致表达出了意思,我结合讲师的笔记也大致理解了,下面贴出我修改过后的讲义:
C++ 为对象的成员提供了一个名为 this 的指针,这个指针称为自引用指针,每当创建一个对象的时候,系统就把 this 指针初始化并指向该对象,即 this 指针的值就是当前被调用的成员函数所在对象的起始地址。
每当调用一个成员函数,系统就会自动把对应的对象的地址,通过 this 指针,作为一个隐含参数传递到该函数中。
也就是说,类里面的那个函数,在编辑器看来应该是:
Student set_age(int age, Student *this)
{
this->age = age;
cout << "age = " << age << endl;
return *this;
}
s.set_age(18, &s);
但也仅供理解罢了,ChatGPT认为这样是几乎正确,但毕竟没说绝对的对,但我们也不是编辑器,自然无法直接看到,所以在未接触到相关的很专业的知识前,不要太肯定
(3)、静态的成员函数无法操作 this
第三个结论:静态函数先于对象存在,开始操作静态函数的时候,不存在 this 指针,看验证:
#include <cstdio>
#include <iostream>
using namespace std;
class Student
{
public:
static void lazy()
{
cout << "i want to sleep " << endl;
}
};
int main()
{
// There is no object at this time, and test cannot instantiate the first address of the object
Student :: lazy();
// you can see, Strings in lazy functions can still be printed,
// so, Static variables take precedence over objects
//=========================================================
Student s;
s.lazy();
return 0;
}
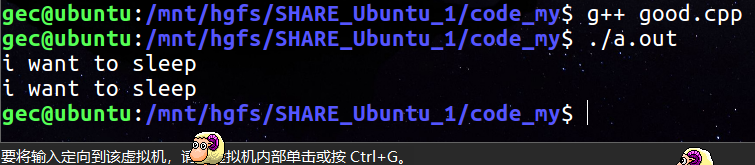
可以看出,静态函数的优先级是大于对象的,而且是所有独享共有的,并不存在 this,我自己估计又是编译器的设定。
(4)、返回对象
如果有成员函数需要返回整个对象,可以使用return *this,此时函数的返回值应该设置为引用来返回,防止出现函数结束时,返回值消失的情况
首先来看一下返回引用的情况,这种情况我们在上一篇博客中已经介绍过了,我们来简单回忆一下其要点,具体的例程以及分析可以参考上一篇博客。
引用作为函数返回值的时候,引用名和返回值数据类型一致的情况下,可以将这个函数作为赋值运算符的右边充当变量名,赋值给左边的引用名。
除此之外,还可以将这个函数作为赋值运算符的左侧,作为被赋值的那一端。但是需要在返回值之后,所引用的空间(即被引用的变量所具有的的空间)没有被释放(静态数据、全局变量、堆空间数据、传入的指针数据)。当然,等号两边的数据类型,即函数返回值的数据类型和变量名的数据类型还是要保持一致的。
然后再来看看返回一个对象,这种情况其实我们在上一篇博客中也见过,但是当时其实我是不太在意的,包括我在最开始的笔记中也没有记下这些,只有当现在有了GPT的辅助后,我才有了探索的可能。
关于返回对象,我们回头看看之前的程序:
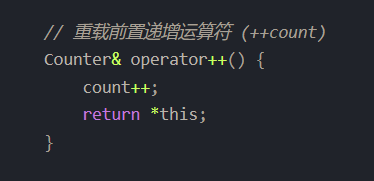
我们在上文中提到,this 指针是指向对象的指针,即指向对象的首地址,所以我们若想返回对象本身,自然应该从this指针上入手,而在函数体中,*this 表示当前对象的引用,即正在进行递增操作的对象本身,至于为什么用*this 表示当前对象的引用,以及*this 为什么能表示当前对象的引用,暂时先不去做探索,我搞这个四级标题的内容已经很绕自己了,先缓缓。
至于这里还指出了的 ”当函数返回一个对象的拷贝而不是引用时,存在返回值被销毁的情况“,我用ChatGPT生成了一种情况,但后面的内容忘记的差不多了,现在看不大懂,以后在回头看看吧。
#include <cstdio>
#include <iostream>
using namespace std;
class Example {
private:
int value;
public:
Example(int v = 0) : value(v) {}
/* 它声明了一个名为 add 的成员函数,该函数接受一个常量引用 other 作为参数,并且被声明为 const */
Example add(const Example& other) const {
Example result(value + other.value);
return result; // 返回对象的拷贝
}
int getValue() const {
return value;
}
};
int main() {
Example e1(5);
Example e2(10);
Example e3 = e1.add(e2); // 调用 add 函数并返回对象的拷贝
cout << e3.getValue() << endl; // 输出:15
return 0;
}
在上述示例中,add 函数返回了一个临时创建的 Example 对象 result 的拷贝。这个临时对象在函数调用结束后将会被销毁。
如果我们在 add 函数中返回对象的引用而不是拷贝,就能避免返回值被销毁的情况:
Example& add(const Example& other) const {
Example result(value + other.value);
return result; // 错误:返回局部对象的引用
}
但是请注意,上述代码是错误的,因为我们不能返回对局部对象的引用。局部对象在函数调用结束后被销毁,引用将变成悬空引用,导致未定义的行为。
因此,在需要返回对象时,最好返回对象的引用或者使用动态内存分配来创建对象并在适当的时候进行释放,以确保返回的对象在使用时仍然有效。
六、构造函数和析构函数
为了防止类的对象在被定义的时候,出现有成员属性未初始化(防止出现野指针),所以编译器会在对象被建立的时候,调用构造函数申请空间来进行初始化,在对象被销毁时,调用析构函数进行收尾工作。
当类没有定义构造函数和析构函数的时候,有系统自动生成默认的构造和析构函数。
1、构造函数
主要负责类中成员的初始化,定义对象的时候自动调用构造函数。
特点:
- 构造函数的函数名和种类名一致
- 构造函数没有返回值(也不能写 void)
- 构造函数支持函数重载和默认参数的规则
- 构造函数是对象创建的时候自动调出,对象创建的时候自动传参(无默认参数)
- 一般设置为公有权限,若设置为私有权限只能在类中调用
- 如果没有自动洗构造函数,则系统会默认生成构造函数
构造函数是允许重载的,此时要遵守重载的规则,灵活运用占位参数很关键。
首先来看一下最简单的一个构造函数:
#include <iostream>
using namespace std;
class Data
{
public:
// Define constructor functions without parameters
Data()
{
cout << "Data() without parameters" << endl;
}
// Define a constructor function with parameters
Data(int a, int b)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
private:
int a;
int* p;
};
int main()
{
Data data; // constructor functions without parameters
Data data1(12, 13); // constructor function with parameters
return 0;
}
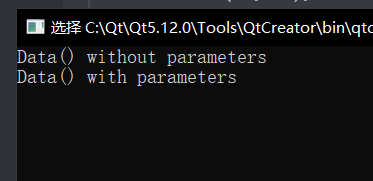
这里也是可以用默认参数的,但正常情况下意义不大,我一直认为随便使用默认参数这个玩意会影响到可读性。
#include <iostream>
using namespace std;
class Data
{
public:
// Constructor function with default parameters
Data(int a, int b = 8)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
void display()
{
cout << a << "---" << *p << endl;
}
private:
int a;
int* p;
};
int main()
{
Data data1(12); // constructor function with parameters
data1.display();
return 0;
}
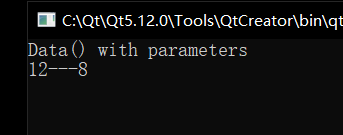
2、析构函数
类中成员数据收尾工作,也就是销毁数据
特点:
- 析构函数的函数名和类名一直,但是需要在函数名之前加上
~ - 析构函数没有返回值类型,没有参数列表,不支持重载
- 在一个类中有且仅有一个析构函数支持数据的释放
- 在对象销毁的时候,自动释放成员空间,即程序自动调用析构函数
#include <iostream>
using namespace std;
class Data
{
public:
// Constructor function with default parameters
Data(int a, int b = 8)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
// Define a destructor function
~Data()
{
delete this ->p;
cout << "~Data " << endl;
}
void display()
{
cout << a << "---" << *p << endl;
}
private:
int a;
int* p;
};
int main()
{
Data data1(12); // constructor function with parameters
data1.display();
return 0;
}
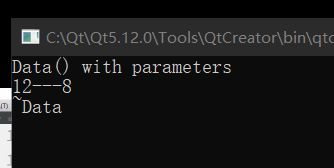
继续看,当我加一个无参构造:
#include <iostream>
using namespace std;
class Data
{
public:
// Define constructor functions without parameters
Data()
{
cout << "Data() without parameters" << endl;
}
// Constructor function with default parameters
Data(int a, int b = 8)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
// Define a destructor function
~Data()
{
cout << "~Data " << endl;
delete this ->p;
}
void display()
{
cout << a << "---" << *p << endl;
}
private:
int a;
int* p;
};
int main()
{
Data data;
Data data1(12); // constructor function with parameters
data1.display();
return 0;
}
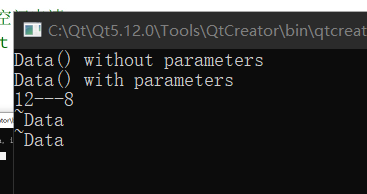
这是为什么呢?其实不难猜出,我这次的类中同时有了无参数和有参数两种构造,析构函数自然要把重载的构造给消灭掉。
但是仔细看,我这里其实是把 cout << "~Data " << endl; 给提前了,若是不提前,就会发生一个有意思的情况:
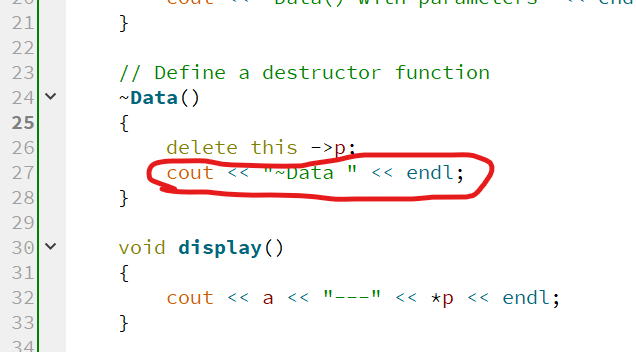
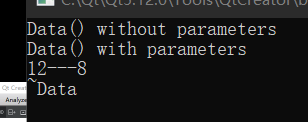
看,这里是不是少了一个打印!
这个说明了什么呢?
只因你太美……
再仔细看,看~Data 中的 delete 内容,可以发现,析构函数仅仅是针对使用到了对应内容的构造函数,即定义了 this->p = new int(b); 的有参构造。
为了验证这个观点,我们也在无参构造中给了一个堆空间,但是得到的尝试结果并不理想:
#include <iostream>
using namespace std;
class Data
{
public:
// Define constructor functions without parameters
Data()
{
this->q = new int('1');
cout << "Data() without parameters" << endl;
}
// Constructor function with default parameters
Data(int a, int b = 8)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
// Define a destructor function
~Data()
{
delete this ->p;
// delete this ->q;
cout << "~Data " << endl;
}
void display()
{
cout << a << "---" << *p << endl;
}
private:
int a;
int* p;
int* q;
};
int main()
{
Data data;
Data data1(12); // constructor function with parameters
data1.display();
return 0;
}
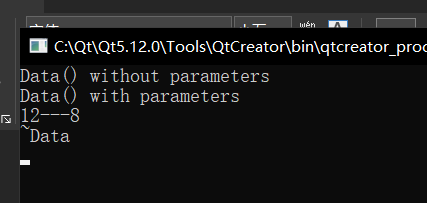
出现这个结果其实是在预期当中的,也符合我们上面的程序尝试经验,但是我在 delete 上稍微改一下:

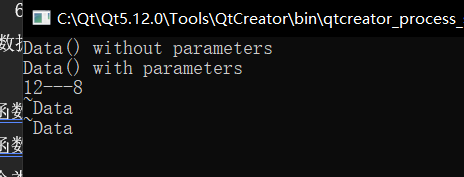
同样都是在构造函数中定义出来的堆空间,得到的结果却不一样,奇奇怪怪。
3、构造函数列表初始化数据
(1)、傻瓜式初始化
按照 C 语言的方法直接在构造函数中初始化
(2)、参数列表初始化格式
构造函数名(参数 1, 参数 2):类成员 1(参数 1), 类成员 2(参数 2){}
注:参数列表并不需要对应后面的类成员,后面的类成员所初始化的变量完全可以与参数列表半毛钱关系都无
#include <iostream>
using namespace std;
class Data
{
public:
// Define constructor functions without parameters
Data()
{
cout << "Data() without parameters" << endl;
}
// Constructor function with default parameters
Data(int a, int b)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
// Constructor function for parameter list initializer
Data(int a): a(a)
{
cout << "Data() for parameter list initializer \n";
}
// Define a destructor function
~Data()
{
delete this ->p;
cout << "~Data " << endl;
}
void display()
{
cout << a << "---" << *p << endl;
}
private:
int a;
int* p;
};
int main()
{
Data data;
Data data1(12, 13); // constructor function with parameters
data1.display();
Data data2(15);
return 0;
}
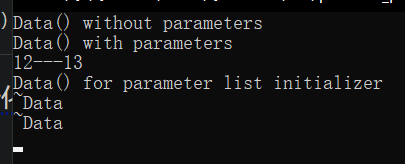
但这里为什么又析构了两次了,你说神不神奇
2023.2.16:我现在觉得是 delete 的时候是第一次,程序完了第二次,没毛病
2023.6.26:我现在记得后面的笔记中我是记录了原因和解决办法的,只可惜现在忘得很干净,,,
七、类的函数封装
在类中声明函数,在类外实现函数定义
1、单文件中的格式
声明函数: 返回值类型 函数名(参数列表);
定义函数: 返回值类型 类名 :: 函数名(参数列表){函数体}
#include <iostream>
using namespace std;
class Data
{
public:
// Constructor function with default parameters
Data(int a, int b)
{
// assignment
this->a = a;
this->p = new int(b);
cout << "Data() with parameters" << endl;
}
// Constructor function for parameter list initializer
Data(int a): a(a)
{
cout << "Data() for parameter list initializer \n";
}
// Define a destructor function
~Data()
{
delete this ->p;
cout << "~Data " << endl;
}
void display();
private:
int a;
int* p;
};
void Data::display()
{
cout << a << "---" << *p << endl;
}
int main()
{
Data data(12, 13); // constructor function with parameters
data.display();
Data data1(15);
return 0;
}
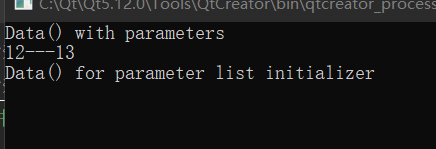
这次更神奇,两个构造直接一个都不析构了
2、模块化编程
C++的模块化编程的方式与 C 语言类似,我们用的 Qt 也比我们之前用的编辑器更智能,所以我们在这里的操作其实是不难的,只需要模仿单文件中的封装方式即可。
#ifndef STUDENT_H
#define STUDENT_H
#include <iostream>
using namespace std;
class Student
{
public:
Student(); // Note that there is no return value here
private:
string name;
string sex;
int age;
};
#endif // STUDENT_H
#include "student.h"
Student::Student()
{
cout << "student() \n";
}
#include "student.h"
using namespace std;
int main()
{
Student();
cout << "Hello World!" << endl;
return 0;
}
下面是讲师上课时候的一个例程:
定义一个游戏类 Game,类中成员包括镔铁数量、宝石数量、木材数量、金币、VIP 等级。
程序要求实现:
1、完成对象的所有资源初始化,设置相关数据
2、能够显示对象的相关数据
3、能够实现外挂(设置资源、vip 等级等...)
#ifndef GAME_H
#define GAME_H
#include <iostream>
using namespace std;
class Game
{
public:
Game();
Game(int iron, int wood, int gem, int gold, int vip);
~Game();
void display();
void SetData();
private:
int iron, wood, gem, gold, vip;
};
#endif // GAME_H
#include "game.h"
Game::Game()
{
cout << "Game() without parameters\n";
}
Game::Game(int iron, int wood, int gem, int gold, int vip)
: iron(iron), wood(wood), gem(gem), gold(gold), vip(vip)
{
cout << "Game() with parameters\n";
}
Game::~Game()
{
cout << "destructor for Game\n";
}
void Game::display()
{
cout << "data:\t" << iron << "---" << wood << "---" << gem << "---" << gold << "---" << vip << endl;
}
void Game::SetData()
{
// the modification check code
int check;
cout << "Please enter the modification check code:\t";
cin >> check;
if(check == 1234)
{
cout << "Verification successful!\n";
cout << "please input iron:\t";
cin >> this->iron;
cout << "please input wood:\t";
cin >> this->wood;
cout << "please input gem:\t";
cin >> this->gem;
cout << "please input gold:\t";
cin >> this->gold;
cout << "please input vip:\t";
cin >> this->vip;
cout << "Good luck!\n";
}
else
{
cout << "authentication failed";
}
}
#include "game.h"
int main()
{
Game game(100, 100, 100, 100, 0);
game.display();
int num = 0, flag = 0;
while(1)
{
if(flag == 0)
{
cout << "1.view information\n" << "2.Use a modifier\n";
cout << "Please enter your selection:\t";
cin >> num;
flag = 1;
}
switch(num)
{
case 1:
game.display();
flag = 0;
break;
case 2:
game.SetData();
flag = 0;
break;
}
}
return 0;
}
八、拷贝构造函数
1、什么是拷贝
在 C++当中利用一个对象去构建另外一个对象,会选用拷贝构造函数,默认的情况下,编译器会自动添加拷贝构造函数。
#include <iostream>
using namespace std;
class Data
{
public:
Data()
{
cout << "Data() without parameters\n";
}
~Data()
{
cout << "~Data()\n";
}
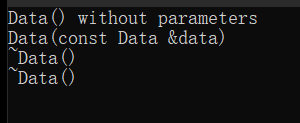
// copy constructor
Data(const Data& data)
{
cout << "Data(const Data &data)\n";
}
private:
};
int main()
{
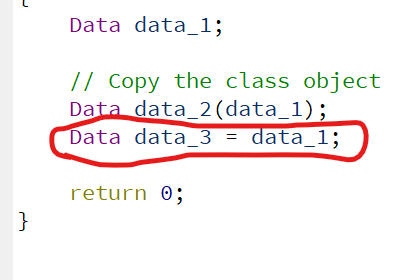
Data data_1;
// Copy the class object
Data data_2(data_1);
return 0;
}
2、拷贝格式
构造函数名(const 类名 &对象名)
{
赋值数据内容
}
(1)、为什么用 const 修饰
保证在拷贝过程中数据不会被修改,保证原对象的完整性。
(2)、为什么要引用
如果不添加引用,那么在调用拷贝构造函数的时候,会申请栈空间,又创建了一个新的对象。实参给形参赋值的时候又是一个拷贝过程,可能就会进入一直递归进入死循环。
如果写成引用,那么改参数不会再申请新的内存空间,他只是实参的一个别名,共用空间。
现在看来,C++的很多操作确实是沿袭的 C 语言,或者说是将 C 语言中很多不必要的操作给除掉,但在根本上却是改变了,即由面对过程变成了面对对象,所以说有时候也不能完全用 C 的逻辑去思考 C++,当然,现在并没有学到那种程度就是了。
3、拷贝构造函数的调用形式
(1)、通过一个对象构造另一个新对象
以上面的例程为例,格式:Data data_2(data_1);
上面的那个例子就是如此,注意要在定义拷贝构造函数的时候需要加上 const 和引用。
(2)、通过类对象的默认赋值运算符
以上面的例程为例,格式:Data data_3 = data_1;
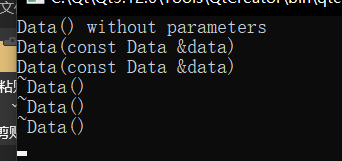
(3)、类对象作为函数返回值,启用拷贝构造函数
#include <iostream>
using namespace std;
class Data
{
public:
Data()
{
cout << "Data() without parameters\n";
}
~Data()
{
cout << "~Data()\n";
}
// copy constructor
Data(const Data& data)
{
cout << "Data(const Data &data)\n";
}
private:
};
// A reference to the return value of a function
Data& Copy()
{
static Data data;
return data;
}
int main()
{
Data data_1;
// Copy the class object
Data data_2(data_1);
Data data_3 = data_1;
Data data_4 = Copy();
return 0;
}
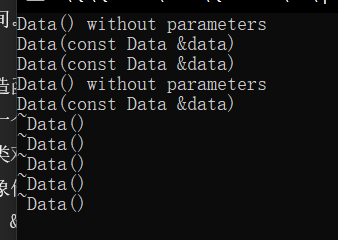
这里有 5 个析构,四个是主函数中的对象,第五个应该是那个 Copy 函数中的 data
4、什么时候需要使用自定义拷贝构造
当类持有其他特殊资源的时候,不能使用默认拷贝构造函数。
例如:
- 在构造函数中存在文件相关操作
- 动态内存空间(堆空间)
- 网络连接相关的操作
- 指针指向一些特殊数据
5、浅拷贝和深拷贝
(1)、浅拷贝
默认将原对象所有的数据成员,按照直接复制的方式拷贝,这就是浅拷贝,只有数据的传递。
#include <iostream>
using namespace std;
class A
{
public:
A(int a)
{
// Application space assignment
this->data = new int(a);
cout << "A()" << endl;
}
~A()
{
cout << "~A() \n";
}
// shallow copy
A(const A& a)
{
this->data = a.data; // Only numeric passes here
cout << "shallow copy\n";
}
void display()
{
cout << "data:\t" << *data << endl;
cout << "Address:\t" << (void*)data << endl;
}
private:
int* data;
};
int main()
{
A a(15); // instantiate object
a.display();
A data(a); // // shallow copy
data.display();
return 0;
}
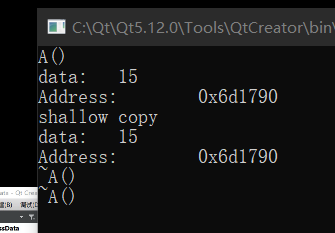
看地址,是一样的
(2)、深拷贝
将对象所持有的的资源一并拷贝,并未新对象申请一个新的堆空间,将资源拷贝到申请的堆空间中,申请空间并拷贝数据,就是深拷贝。
#include <iostream>
using namespace std;
class A
{
public:
A(int a)
{
// Application space assignment
this->data = new int(a);
cout << "A()" << endl;
}
~A()
{
cout << "~A() \n";
}
// deep copy
A(const A& a)
{
this->data = new int; // Application space
memcpy(this->data, a.data, sizeof(int));
cout << "deep copy \n";
}
void display()
{
cout << "data:\t" << *data << endl;
cout << "Address:\t" << (void*)data << endl;
}
private:
int* data;
};
int main()
{
A a(15); // instantiate object
a.display();
A data(a); // // shallow copy
data.display();
return 0;
}
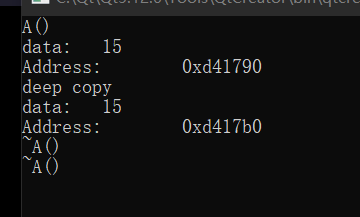
看地址,是不一样的
九、类的注意事项
- 类是一种自定义数据类型,属于复杂的数据类型,定义的类作为一种数据类型的使用的,本身不占用内存空间,会给实例化对象申请操作空间
- 类的对象大小,是类的普通数据成员的大小(函数成员和静态成员不占用对象内存,但是虚函数和纯虚函数是占用内存的,因为存在虚表指针),存在地址对齐问题(类似于结构体)
- 如果没有数据成员的时候,那么类的大小默认为 1
- 一个空类中,存在默认构造函数,默认析构函数,默认拷贝析构函数,默认赋值运算符
这里演示一下地址对齐,首先,看一下最简单的,在共有和私有中都只有几个 int 类型:
#include <iostream>
using namespace std;
class Data
{
public:
int c;
private:
int a;
int b;
};
int main()
{
Data data;
cout << sizeof(data) << endl;
return 0;
}
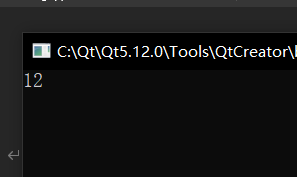
然后加一个 char,就会发现类也是符合结构体的地址对齐的:
#include <iostream>
using namespace std;
class Data
{
public:
int c;
char d;
private:
int a;
int b;
};
int main()
{
Data data;
cout << sizeof(data) << endl;
return 0;
}
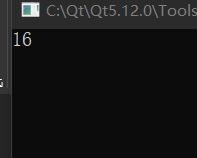
十、类中的 static 修饰
1、复习一下C中的static修饰
在C语言中,static 关键字有以下几种作用:
-
作用于函数:
static可以用于函数内部的局部变量,将其生命周期扩展为整个程序运行期间,而不是函数执行期间。这使得变量的值在多次函数调用之间保持持久。static修饰的函数可以限制其作用域为当前编译单元(源文件),使其只能在当前文件中访问,而不能被其他文件引用。这样可以隐藏函数的实现细节,增加程序的安全性和模块化特性。
-
作用于全局变量:
static可以用于全局变量,将其作用域限制在当前编译单元内,只能在当前文件中访问,不能被其他文件引用。这样可以防止全局变量被其他文件非法修改,避免命名冲突。static修饰的全局变量在程序运行期间都存在,但其可见性仅限于当前文件,不会被其他文件看到,起到了信息隐藏和封装的作用。
-
作用于函数和变量的链接属性:
static修饰的函数和变量具有内部链接属性,意味着它们只在当前编译单元内可见,不会与其他编译单元中同名的函数或变量发生冲突。- 未使用
static修饰的函数和变量具有外部链接属性,默认情况下可被其他编译单元引用,可能导致命名冲突。
总的来说,static 在C语言中的作用是:
- 延长函数内部局部变量的生命周期并保持其持久性。
- 控制函数和全局变量的作用域,限制其只能在当前编译单元内可见。
- 避免函数和变量与其他编译单元中的同名符号发生冲突,提高程序的安全性和可维护性。
- 增加模块化编程的特性,隐藏实现细节并提供信息封装。
关于static修饰函数,这里举一个例程,先不进入正题,先看看下面的一个简单例程,此时我们不用到static,只是简单的写出一个模块化编程例程:
/* main函数存在的主文件exa.c */
#include "exa.h"
int main(int argc, char const *argv[])
{
helloworld();
return 0;
}
/* 功能函数helloworld所在的文件exa.c */
#include "exa.h"
void helloworld()
{
printf("helloworld\n");
}
/* 本例程相关的source函数通用的头文件 */
#ifndef EXA_H
#define EXA_H
#include <stdio.h>
void helloworld();
#endif

我们可以很清楚的看到,此时的程序非常正常的运行了,过程中没有啥需要注意的,只是记录一下我犯过的一个错误,就是没有联合编译,于是乎就显示我没有定义helloworld函数。
然后看看加了static修饰函数的情况,我们分别在函数和引用中加上static即可:
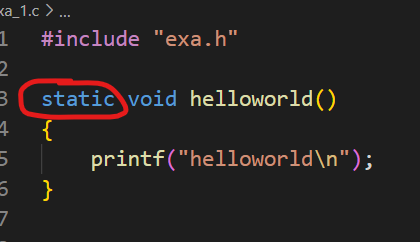
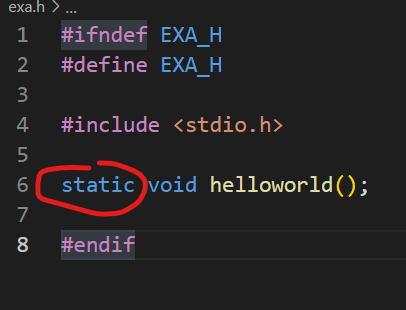
按照上面我们对static的描述,此时我们的函数是只在当前的文件中可见的,所以不出意外的话主函数是识别不到我们的helloworld函数的,事实也正是如此:

2、类比C与C++中的static
由于C++是C的好大儿,所以static在C++中的作用其实跟在C中并没有什么很大的区别,只不过由于C++相较于C补充了不少的东西,所以在某些地方,比如类跟命名空间以及他们造成的某些关联,导致static在两种语言多多少少会存在一些差异,下面是我用GPT总结的:
-
静态变量初始化:
- 在C语言中,静态变量在声明时可以指定初始值,只会初始化一次,并保持其值在程序执行期间不变。
- 在C++语言中,静态变量可以在声明时指定初始值,也可以在定义时通过类外的赋值语句进行初始化。
-
静态成员变量和函数:
- 在C语言中,
static关键字只能用于函数和全局变量,没有类的概念,因此不存在静态成员变量和函数。 - 在C++语言中,
static关键字可以用于类的成员变量和成员函数,用于指示它们与类本身关联,而不是与类的实例对象关联。静态成员变量在所有类的实例之间共享,静态成员函数可以直接通过类名调用,无需创建对象。
- 在C语言中,
-
命名空间的作用:
- 在C语言中,没有命名空间的概念,因此
static主要用于限制函数和变量的作用域和可见性。 - 在C++语言中,除了限制作用域和可见性外,
static还可用于定义命名空间内的静态变量、函数和类的静态成员。
- 在C语言中,没有命名空间的概念,因此
-
类的隐藏和封装:
- 在C语言中,通过将函数和变量声明为
static可以将它们的作用域限制在当前编译单元内,达到隐藏和封装的效果。 - 在C++语言中,除了使用
static进行作用域限制外,还可以使用访问修饰符private、protected、public来控制类的成员的可访问性,实现更强大的隐藏和封装。
- 在C语言中,通过将函数和变量声明为
虽然在某些方面存在差异,但 static 关键字在C和C++中的核心作用是相似的,用于控制作用域、可见性和存储属性,并提供隐藏和封装的能力。
回看刚刚C的那个例程,若是放在C++中,也是存在如此的情况:
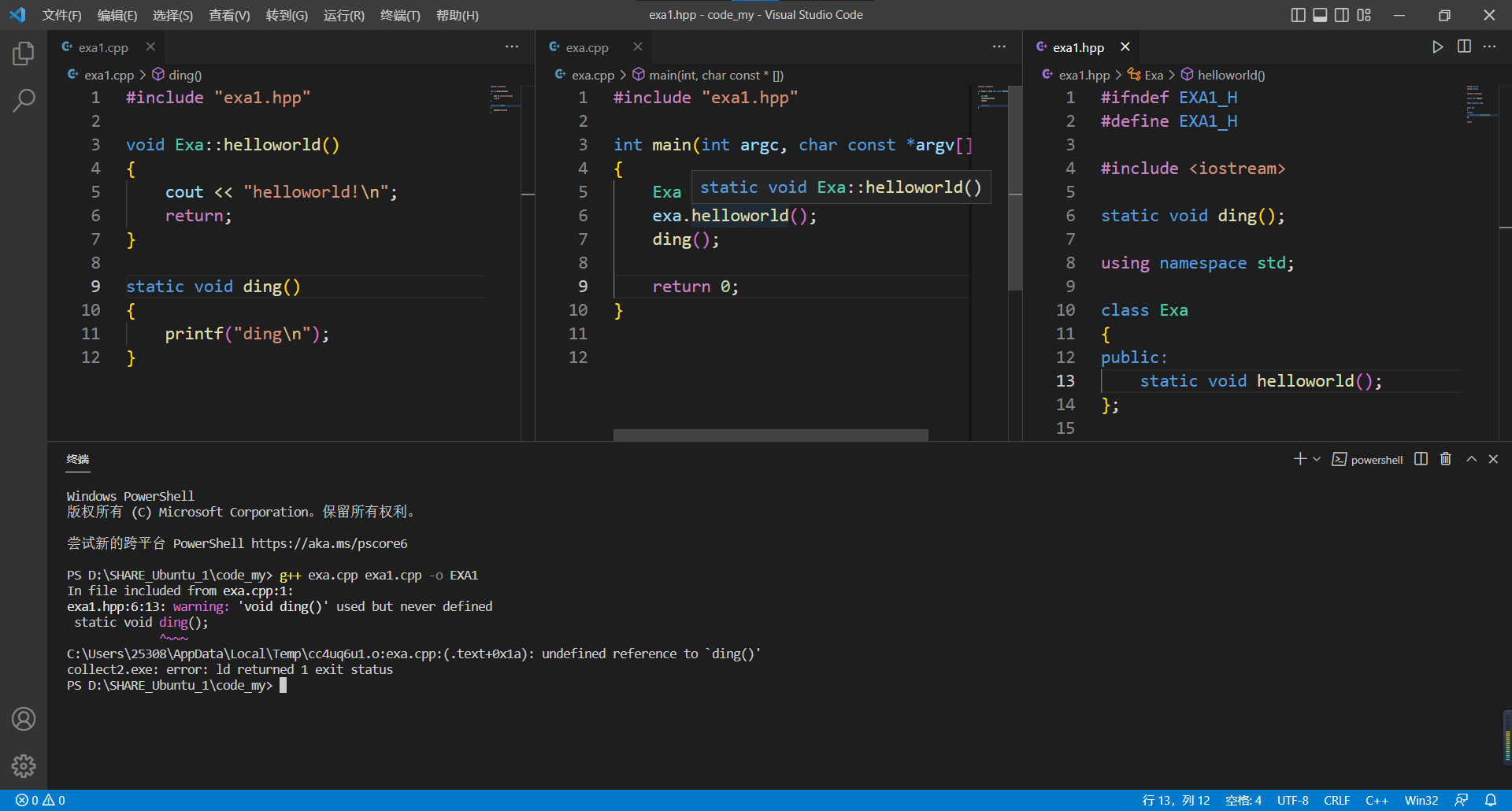
可从上面vscode的窗口截图中我们也可以看到,在类中我们其实也有一个被static修饰的函数,可是这样的函数是可以被其它函数调用的:
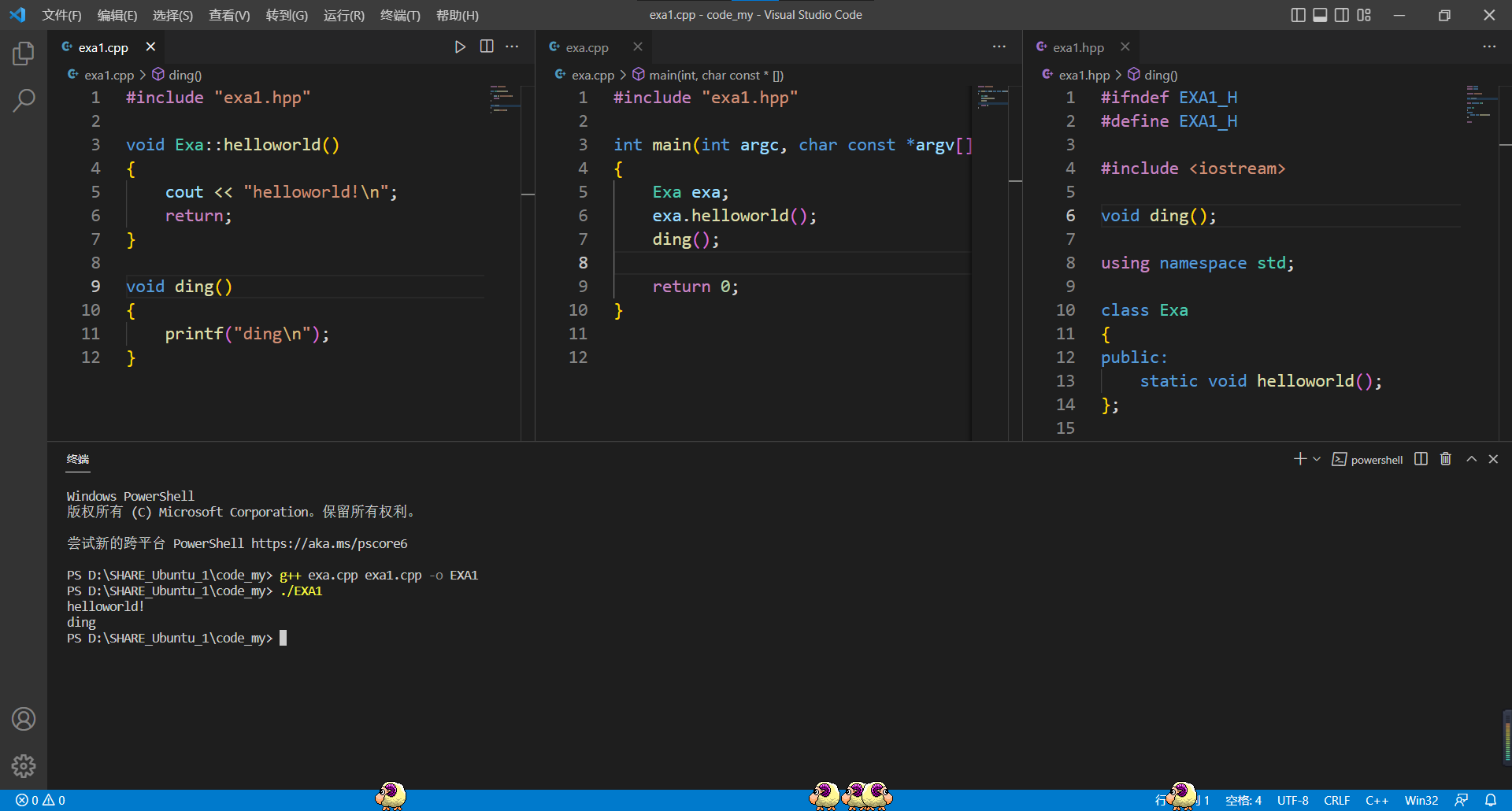
3、C++中static 的特点
static成员变量的存储空间存在于数据段中,而不是对象的内存空间中,因此它们不占用对象的内存空间。static成员变量限定了其作用域为所属的类,也可以在类外部访问,但是必须使用类名限定访问。- 静态成员变量的初始化有其自身的规则。在类中只是声明静态成员变量,并且在类外部的全局作用域中进行定义和初始化。
- 静态成员变量属于类的共享数据,所有的类对象共享同一个静态成员变量,无论创建了多少个类的对象,静态成员变量只有一份。
- 静态成员变量在类对象之前存在,因此它们在对象创建之前就已经存在于内存中。
- 对于公有权限的静态成员变量,可以通过类名直接访问,但仍然受到私有权限的限制,无法绕过私有权限直接访问私有成员变量。
关于第4条,这里有一个讲师上课时候的例程:
设计一个生产线,在生产线类中包含一个静态成员(任务总量起始 10000 台),
设计一个生产函数,
设一个查看剩余生产任务,
创建一个生产线 1 生产 1200,
创建一个生产线 2 生 产 3200,
创建一个生产线 3 生产 1000,看最后剩余多少台未生产
#include <iostream>
using namespace std;
// 定义生产线类
class Bletline
{
public:
// 生产
void production(int num)
{
this->number -= num;
}
// 返回结果
int num()
{
return this->number;
}
private:
static int number; // 总台数
};
// 初始化
int Bletline::number = 10000;
int main()
{
Bletline blet1, blet2, blet3;
blet1.production(1200);
cout << blet1.num() << endl;
blet2.production(3200);
cout << blet2.num() << endl;
blet3.production(1000);
cout << blet3.num() << endl;
return 0;
}

4、类中的静态成员的访问
(1)、类中的共有成员
类中的成员函数使用:
- 直接使用静态数据成员
this->静态成员名类名 :: 静态成员名
#include <iostream>
class MyClass
{
public:
static int staticData;
static int staticData_1;
static int staticData_2;
/* 类的成员函数中 直接使用静态数据成员 */
void printStaticData()
{
std::cout << "Static data: " << staticData << std::endl;
}
/* 类的成员函数中使用 this->静态成员名 */
void printStaticData_1()
{
std::cout << "Static data: " << this->staticData_1 << std::endl;
}
/* 类的成员函数中使用 类名 :: 静态成员名 */
void printStaticData_2()
{
std::cout << "Static data: " << MyClass::staticData_2 << std::endl;
}
};
int MyClass::staticData = 10;
int MyClass::staticData_1 = 11;
int MyClass::staticData_2 = 12;
int main()
{
MyClass obj;
obj.printStaticData();
obj.printStaticData_1();
obj.printStaticData_2();
return 0;
}

类外的成员使用:
对象名.静态成员名对象指针->静态成员名类名 :: 静态成员名
#include <iostream>
using namespace std;
class MyClass
{
public:
static int staticData;
};
int MyClass::staticData = 10;
int main()
{
MyClass obj;
MyClass* ptr = new MyClass();
/* 在类外成员引用中 使用对象名加上静态成员名 */
cout << "Static data: " << obj.staticData << endl;
/* 在类外成员引用中 使用对象指针加上箭头操作符 -> 和静态成员名 */
cout << "Static data: " << ptr->staticData << endl;
/* 在类外成员引用中 使用类名加上作用域解析运算符 :: 和静态成员名 */
cout << "Static data: " << MyClass::staticData << endl;
return 0;
}

(2)、私有和保护成员:
- 在类中,无论是公有成员、私有成员还是保护成员,都可以通过以上三种方式进行访问。
- 在类外部访问私有成员和保护成员时,只能通过公开接口(公有成员函数或友元函数)进行访问。这是因为私有成员只能在类的内部访问,而保护成员除了类的内部,还可以在派生类中进行访问。
- 对于私有成员,无法直接使用对象名、对象指针或类名来访问,需要通过公开接口来间接访问私有成员的值或进行操作。
- 对于保护成员,如果派生类继承了基类的保护成员,那么派生类可以直接访问基类的保护成员,无需通过公开接口。
这种访问控制机制确保了类的封装性和数据隐藏性,私有成员和保护成员只能通过类的公开接口进行访问,从而维护了类的内部实现的隐私性和安全性。
5、类中的静态成员初始化
静态成员保证所有的类对象共享该数据,在类中使用 static 声明变量,在类外完成静态数据初始化
格式:
- 类中,
static 数据类型 变量名; - 类外,
static 类名::变量名;
#include <iostream>
using namespace std;
class Data
{
public:
static int c;
char d;
private:
int a;
int b;
};
int main()
{
Data data;
cout << sizeof(data) << endl;
return 0;
}
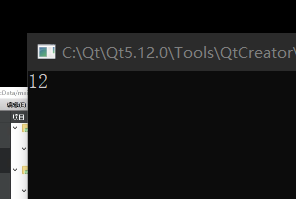
此时被 static 修饰的变量已经从对象的内存空间中移动到了数据区,不会被 sizeof(data)计算
然后来看看调用上,若是不遵循上面的格式,而是按照C语言的习惯直接调用,他并不会直接返回0,而是会报错:
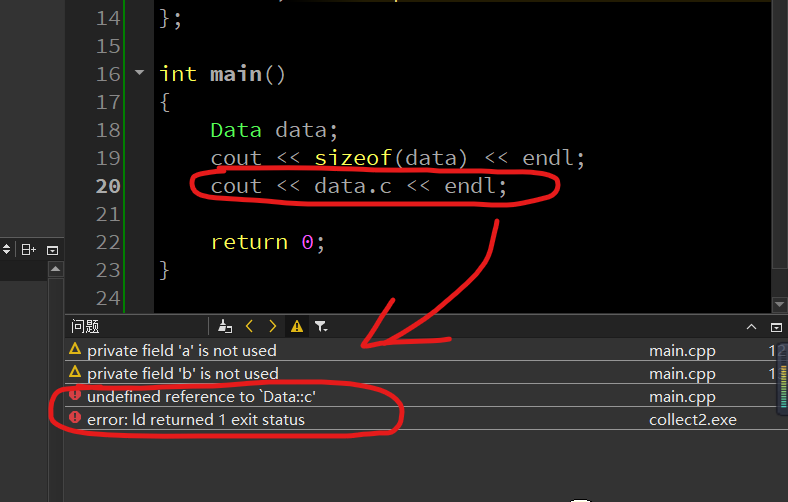
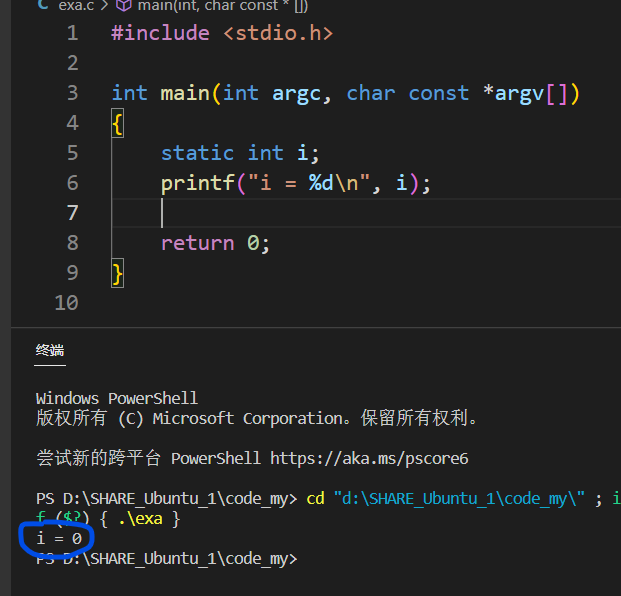
为什么会报错呢,回首看一下,刚刚的程序我并未对其进行初始化,所以我们加上初始化.
但跟C不同的是,这里是不能直接在声明的时候初始化的:
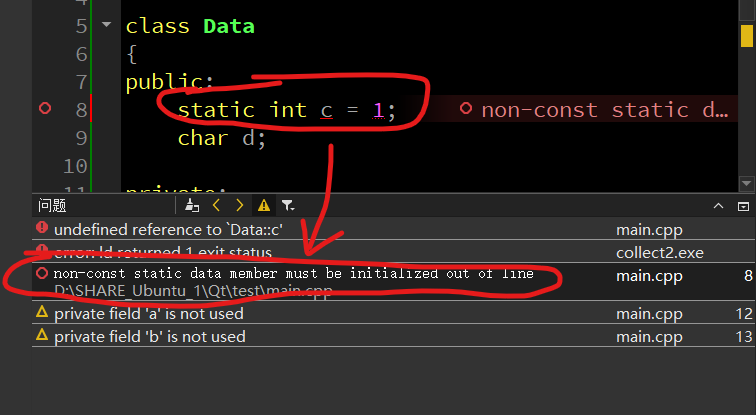
D:\SHARE_Ubuntu_1\Qt\test\main.cpp: 8:错误:非常量静态数据成员必须初始化出线
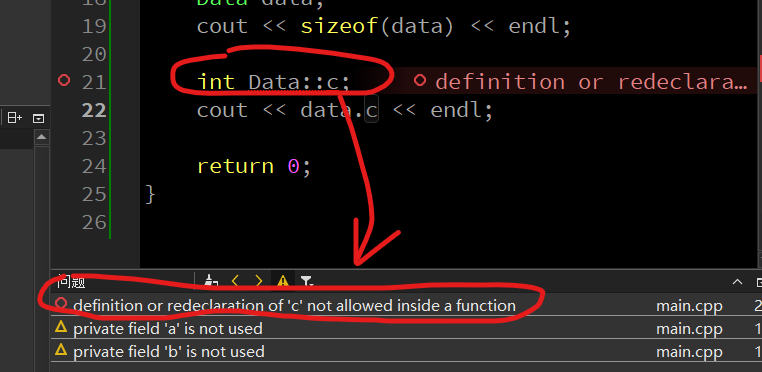
所以说,还是要按照格式来,所以我们尝试在main函数中加上初始化,但是有报错了,看看提示我们知道,竟然也不能把初始化写在函数里面:
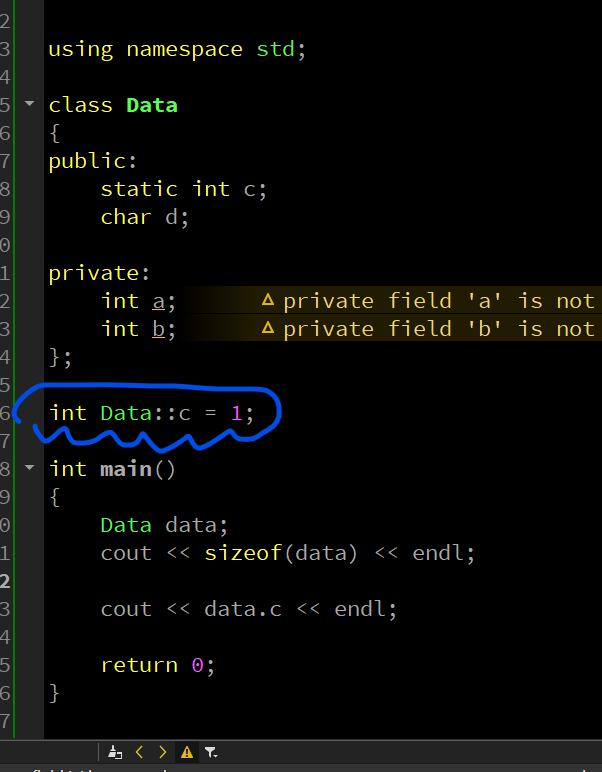
写在函数外面就 OK:
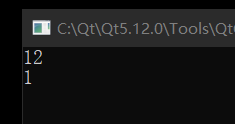
注意,上面一直讨论的都是关于 public 的,对于 private,即使是 static 也不能突破这个私有的权限:
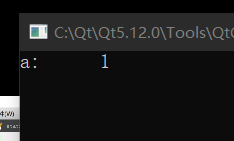
但这个私有权限也是可以被打破的,在不加 static 的情况下我们就已经试过了,现在也同样适用,没错,就是利用在 public 中创一个成员函数,把私有变量塞进去:
#include <iostream>
using namespace std;
class Data
{
public:
void func()
{
cout << "a:\t" << a << endl;
}
private:
static int a;
};
int Data::a = 1;
int main()
{
Data data;
data.func();
return 0;
}
5、类中 static 修饰函数
(1)、格式
在类中声明并实现:static 数据类型(形参列表){函数体}
(2)、特点
- 静态函数先于对象存在,函数公有权限时,可以通过类名直接访问
- 在静态函数中,不能使用非静态成员(函数)
- 静态函数当中,不能使用 this 指针,因为此时没有这玩意
- 普通成员函数可以访问静态函数成员
首先看一个最基本的 static 使用:
#include <iostream>
using namespace std;
class Data
{
public:
void func()
{
cout << "func()" << endl;
}
static void func1()
{
cout << "func1" << endl;
cout << a << endl;
}
static int a;
private:
};
int Data::a = 1;
int main()
{
Data data;
data.func();
data.func1();
cout << endl << endl;
// 此时静态函数是公有权限,没有实例化直接调用
Data::func1();
return 0;
}
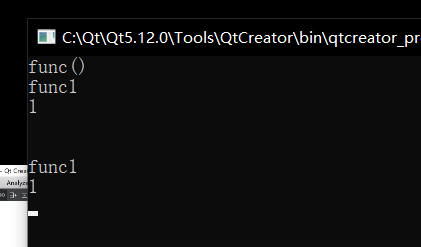
然后我将普通成员用在 static 修饰的函数中:
·
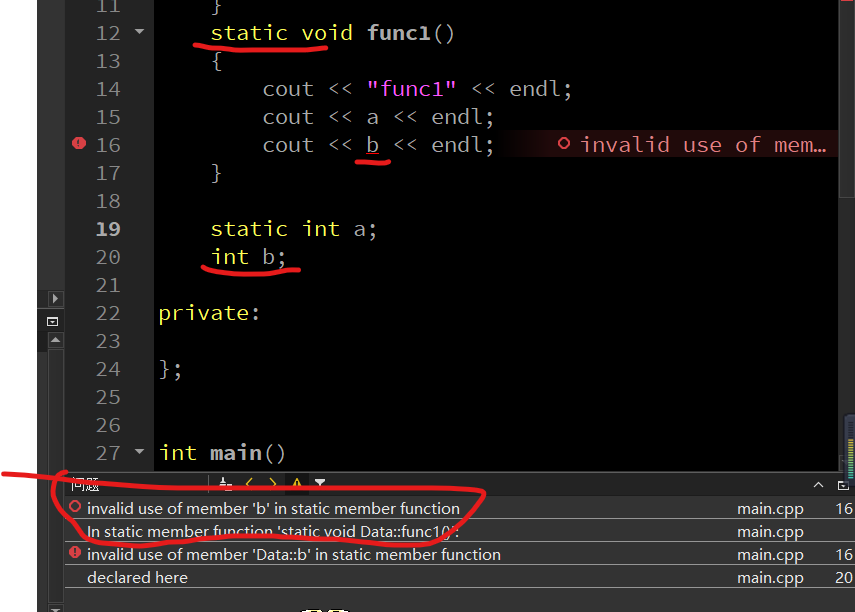
这里也不只是普通成员,普通的成员函数也不能用在 static 修饰的函数中:
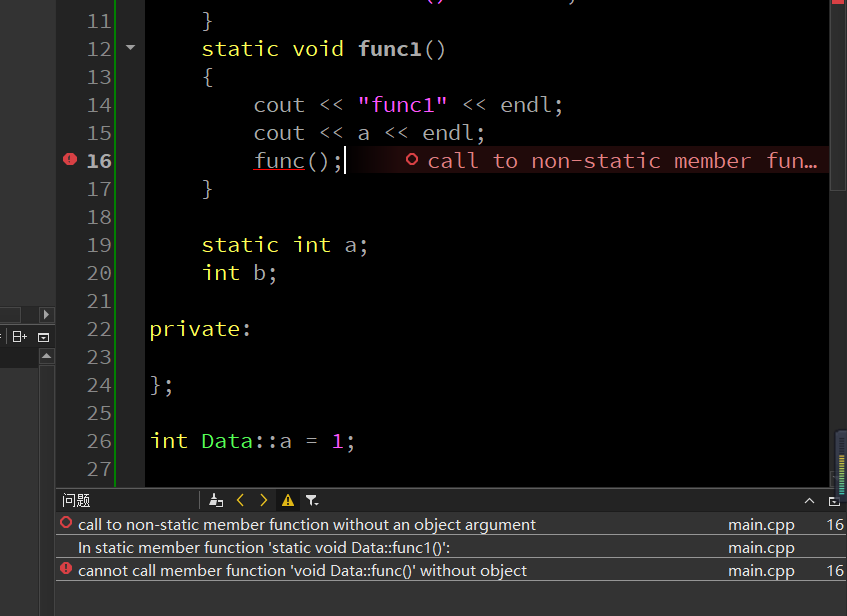
接下来试一下 this 指针的情况:
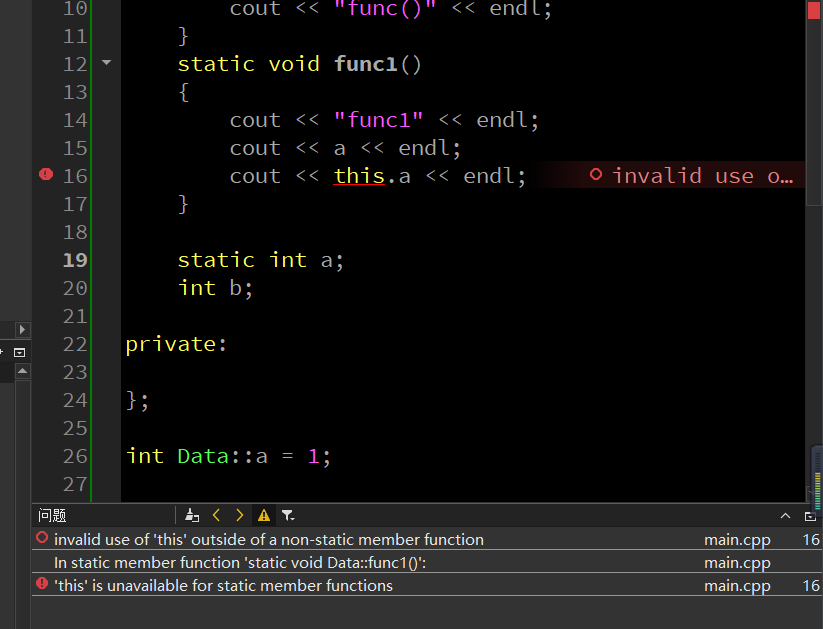
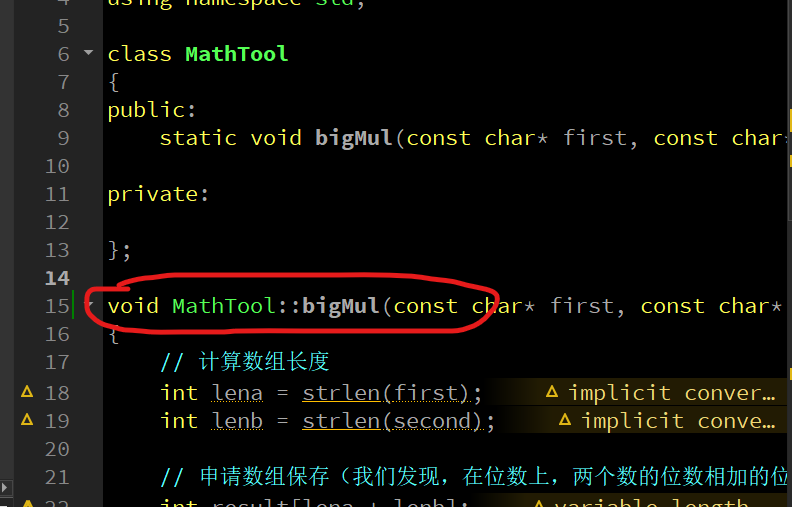
6、static 的类外实现
类外实现的前提自然是类中声明了,注意看,格式是这样的:
7、static 的单例模式
单例模式要求系统中的对应类有且仅有一个实例对象,是一种常见的应用设计模式
主要的要点:
- 提供了对唯一实例的受控访问
- 由于系统内存中只存在一个对象,因此可以节省系统资源,对于一些需要频繁创建和销毁的对象,单例模式可以提高系统的使用效率。
- 允许可变数目的实例
懒汉模式指的是全局的单例实例在第一次时直接构建:
#include <iostream>
using namespace std;
class Singleton
{
public:
// 设定一个全局接口,用于获取该类的唯一实例
static Singleton* GetInstance()
{
// 判断指针为空申请内存
if(instance == NULL)
{
instance = new Singleton;
}
return instance;
}
~Singleton()
{
delete instance;
cout << "~Singleton() \n";
}
private:
Singleton(const Singleton& other) {}; // 私有化构造,防止复制
Singleton() // 私有化构造函数
{
cout << "Singleton() \n";
}
static Singleton* instance; // 唯一的对象
};
// 类外声明对象
Singleton* Singleton::instance;
int main()
{
// 定义对象,获取全局唯一的实例
Singleton* s1 = Singleton::GetInstance();
Singleton* s2 = Singleton::GetInstance();
cout << (void*)s1 << endl;
cout << (void*)s2 << endl;
// Singleton s3(*s1); // 无法进行拷贝,因为拷贝函数被私有化了
return 0;
}
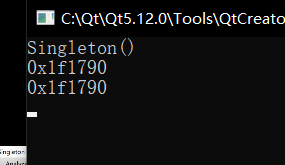
这个程序实现了单例模式,即确保一个类只有一个实例,并提供全局访问点来获取该实例。
让我们逐步解析这个程序:
-
首先,定义了一个名为
Singleton的类,它包含了一个私有的静态成员变量instance,用于保存类的唯一实例。 -
类中的公有静态成员函数
GetInstance()用于获取该类的唯一实例。在函数中,通过判断静态成员变量instance是否为空来确定是否需要创建新的实例。如果为空,就通过new运算符动态分配内存创建一个新的实例,并将其赋值给instance。如果不为空,直接返回已有的实例。 -
构造函数
Singleton()被私有化,因此外部无法直接创建该类的对象。这样确保了类的实例只能通过GetInstance()函数获取,从而实现了单例模式的要求。 -
析构函数
~Singleton()被定义为删除实例时释放内存的操作。 -
在类外部声明了静态成员变量
instance,以便在程序中进行定义。 -
在
main()函数中,通过调用Singleton::GetInstance()获取Singleton类的唯一实例。由于该类只有一个实例,s1和s2指针指向的是同一个对象。 -
最后,输出
s1和s2的指针地址,可以发现它们是相同的,说明确实获得了类的唯一实例。
此外,注释中提到了一个无法进行拷贝的例子,因为拷贝构造函数 Singleton(const Singleton& other) 被私有化了,这样可以防止通过拷贝创建新的实例,确保只有一个实例存在。
总之,这个程序通过将构造函数私有化、提供一个静态成员函数获取唯一实例,并使用静态成员变量保存实例,实现了单例模式。
发现析构函数并没有收回指针,所以我们需要提供一个专门的回收接口,来主动释放。
#include <iostream>
using namespace std;
class Singleton
{
public:
// 设定一个全局接口
static Singleton* GetInstance()
{
// 判断指针为空申请内存
if(instance == NULL)
{
instance = new Singleton;
}
return instance;
}
~Singleton()
{
delete instance;
cout << "~Singleton() \n";
}
// 提供一个回收接口,主动释放堆空间
static void Free()
{
delete instance;
cout << "Free() \n";
}
private:
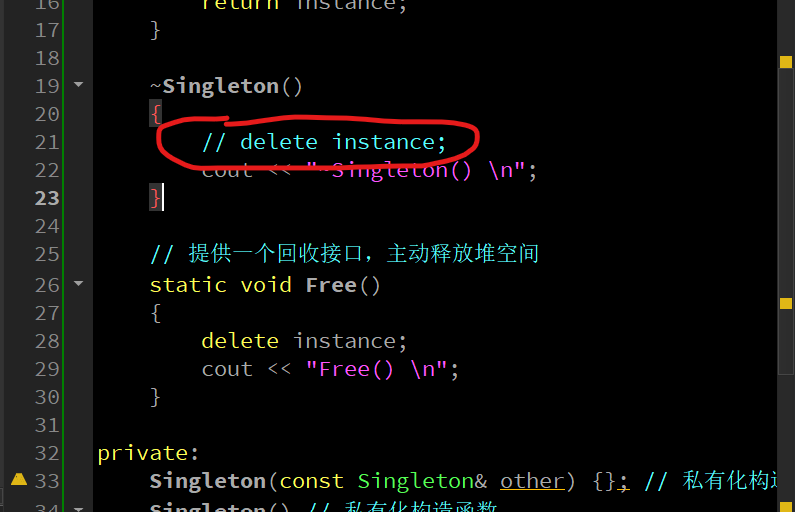
Singleton(const Singleton& other) {}; // 私有化构造,防止复制
Singleton() // 私有化构造函数
{
cout << "Singleton() \n";
}
static Singleton* instance; // 唯一的对象
};
// 类外声明对象
Singleton* Singleton::instance;
int main()
{
// 定义对象,获取全局唯一的实例
Singleton* s1 = Singleton::GetInstance();
Singleton* s2 = Singleton::GetInstance();
cout << (void*)s1 << endl;
cout << (void*)s2 << endl;
// Singleton s3(*s1); // 无法进行拷贝,因为拷贝函数被私有化了
Singleton::Free();
return 0;
}
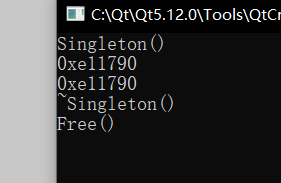
但是发现结果还是如此,我回去看了下老师的代码,发现原因是这里的析构函数中我重复写了一个 delete instance;,去掉后:
还有一种回收方式:通过类的内存逐层管理的方式,来帮助回收
#include <iostream>
using namespace std;
class Singleton
{
public:
// 设定一个全局接口
static Singleton* GetInstance()
{
// 判断指针为空申请内存
if(instance == NULL)
{
instance = new Singleton;
}
return instance;
}
~Singleton()
{
// delete instance;
cout << "~Singleton() \n";
}
// 方式二:通过类的内存逐层管理方式,帮助回收
public:
class GarFrea
{
public:
~GarFrea()
{
if(Singleton::instance != NULL)
{
delete instance;
}
}
};
private:
Singleton(const Singleton& other) {}; // 私有化构造,防止复制
Singleton() // 私有化构造函数
{
cout << "Singleton() \n";
}
static Singleton* instance; // 唯一的对象
static GarFrea garfree; // 回收对象定义
};
// 类外声明对象
Singleton* Singleton::instance;
Singleton::GarFrea Singleton::garfree;
int main()
{
// 定义对象,获取全局唯一的实例
Singleton* s1 = Singleton::GetInstance();
Singleton* s2 = Singleton::GetInstance();
cout << (void*)s1 << endl;
cout << (void*)s2 << endl;
return 0;
}
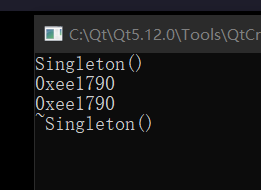
此处依旧不能在析构函数中重复写 delete instance;,需要去掉才能正常运行析构函数。
十一、类中的 const 修饰
1、const 不在类中时
我也是到做练习的时候才意识到这个问题的。
我发现,在类中的 const 修饰定义变量的时候压根就不用赋初值,可以在后续的代码中进行初始化,但是不能省去初始化的这一个步骤。
而在若是不再类中,就必须在定义变量的时候就对其进行初始化,要不然就会报错:
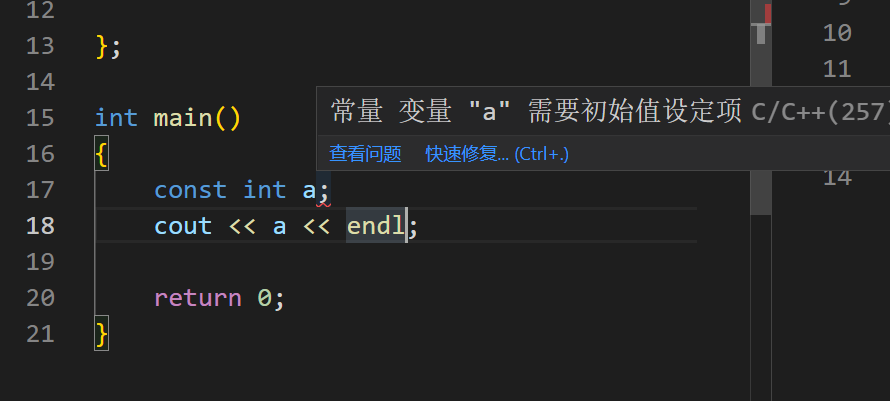
但是在 C 语言中,对 const 的要求就较为宽松一点,被 const 修饰的变量依然不能被改变,但是却可以不进行初始化,系统会自己给他一个初值 0:
#include <stdio.h>
int main(int argc, char const *argv[])
{
const int a;
printf("%d\n", a);
return 0;
}

2、const 在类中的用法
const 主要修饰在成员函数的首尾部分,表示在函数的内部不能改变函数外面的数据。
这个写法主要用于对象被 const 修饰后,只能调用被 const 进行首尾修饰的函数,即在这个修饰模式下,将类中的其他成员看做为只读数据。
首先看一个最简单的 cpp 程序:
#include <iostream>
using namespace std;
class Data
{
public:
Data(int a): a(a)
{
cout << "Data() \n";
}
~Data()
{
cout << "~Data() \n";
}
void func()
{
cout << a << endl;
}
private:
int a;
};
int main()
{
Data data(50);
data.func();
return 0;
}
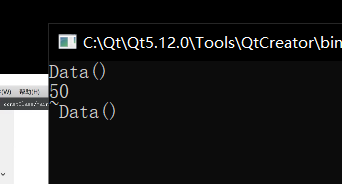
然后尝试用 const 修饰实体化对象:
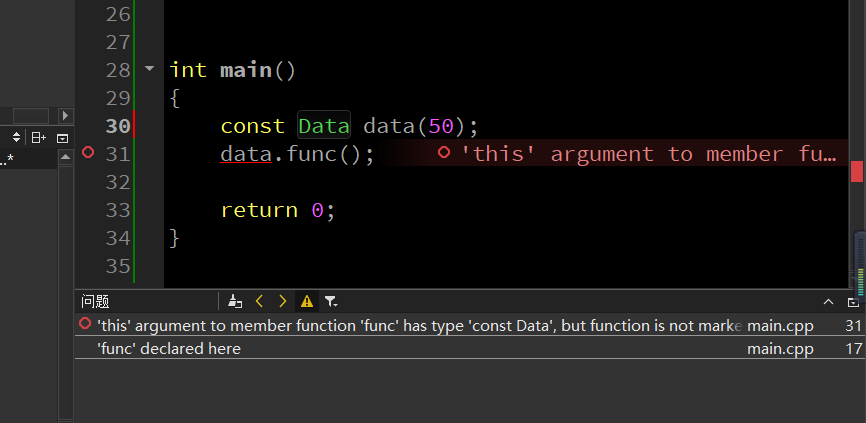
我们发现仅仅是加了一个 const 修饰,这个对象就好像不能用了。去看看报错:error: 'this' argument to member function 'func' has type 'const Data', but function is not marked const。
这里可以理解为调用的时候发现理想中的函数和实际上的不一样,理想中是 const 过的对象调用的自然是可读属性的成员(函数),但我们实际调用的却没有 const,所以说,只要在类中的成员函数前面也加上 const 修饰,满足预期即可。
但注意,这里的格式有些奇怪,要加两个 const:
const 数据类型 函数名(参数列表)const{函数体}
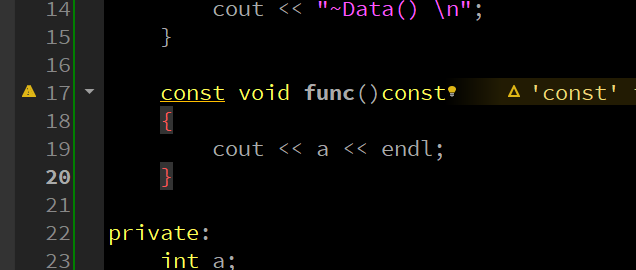
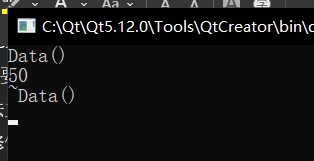
若是我要在这个加了 const 的函数中进行一些赋值操作呢?
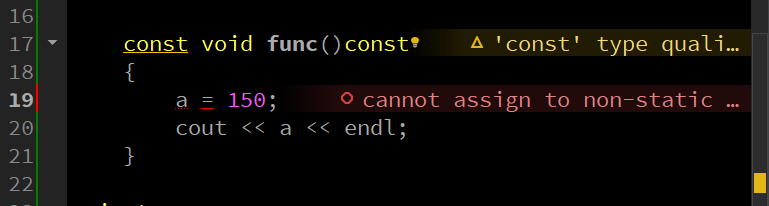
发现也是不行的,看了一下报错,翻译出来为:不能分配给 const 成员函数“func”中的非静态数据成员,简单一点立即,就是说在函数内部不能改变函数外面的数据,函数之外的数据只被看做可读。
至于函数里面定义的,是可以修改的:
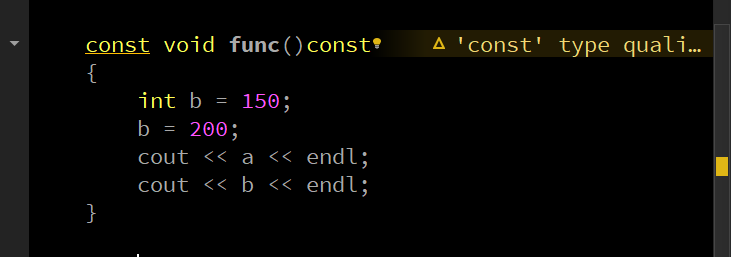
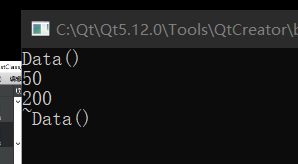
当然,对于原本就是可读的,这里自然也是不能修改的,这是毫无疑问的
另外,我们应该还记得 static 的一个特性:在静态函数中,不能使用非静态成员(函数)。在 const 修饰的函数中,其实也是有类似的操作的。
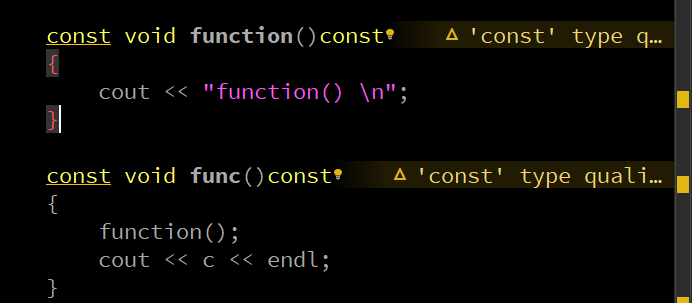
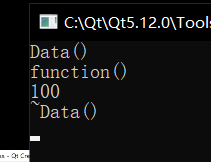
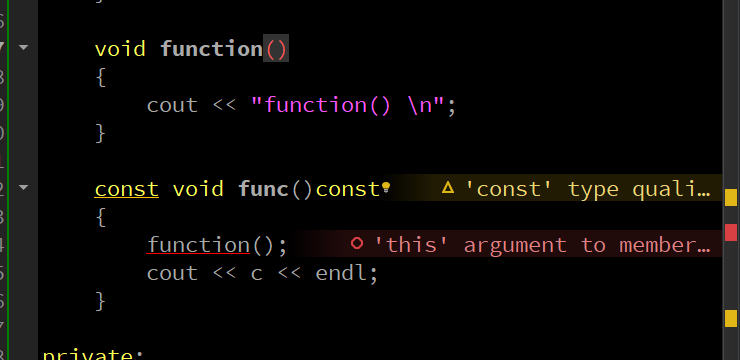
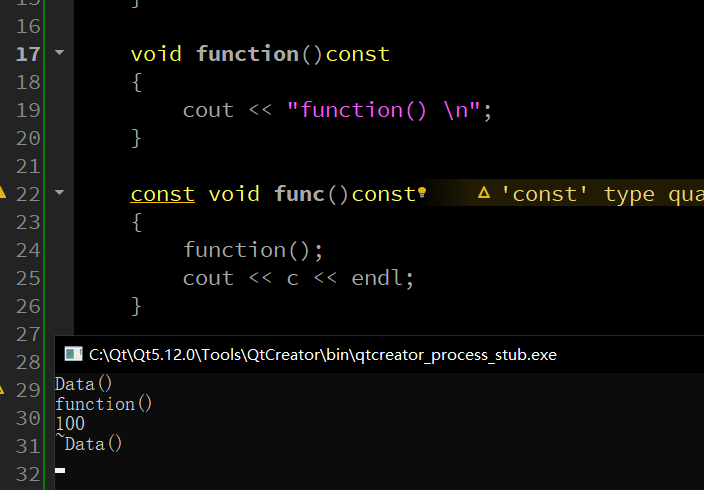
可以看到,这里不加 const 就会报错,但是我还发现了一个有意思的地方:只写后面的那个 const 也不会报错
3、const 在类中的特点
- 在类中被 const 进行尾部修饰函数的时候,函数内部只能调用被 const 修饰的函数
- 在类中被 const 修饰函数之后,那么该函数的内部变为只读状态
- 如果类中需要只读型静态数据,那么可以使用 const 和 static 联合修饰变量
关于 const 和 static 的联合修饰,这里看看这个例程:
#include <iostream>
using namespace std;
class Data
{
public:
Data(int a): a(a)
{
cout << "Data() \n";
}
~Data()
{
cout << "~Data() \n";
}
const void func()const
{
cout << a << endl;
cout << d << endl;
}
private:
int a;
const static int d = 200; // 静态数据
};
int main()
{
const Data data(50);
data.func();
return 0;
}
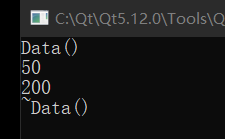
可以看到,此处声明的地方静态数据被给了只读属性后压根就不需要在类外声明,就可以直接在被 const 修饰的成员函数中使用了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号