一次结果不理想的经验|使用Coze搭建GDPR合规小助手
一、前言
从结果上来说,这是一次不太成功的尝试,遇到的坑文中会讲(RAG对文档结构的理解和解析);
从过程上来说,也学到了一些之前不了解的知识,这里作为记录。
说不定哪天可以把这个坑填上。
二、产品说明
使用智能体、RAG、工作流等搭建一个“GDPR合规小助手”,实现用户的条款咨询(包含articles、recitals)、GDPR场景咨询等。
在这个场景中,或许有人会问“为什么不直接使用LLM,直接和chatgpt对话”,我的想法是在实现这个MVP的过程中体验智能体搭建的方法,后续可以迁移到本地知识库的搭建、其他安全场景的智能体等。
三、核心架构
用户问题
↓
GDPR 安全小助手(Agent)
↓
问题理解 / 场景拆解
↓
RAG 检索 GDPR 知识库
↓
证据片段(条款 / Recital)
↓
大模型推理(限定引用)
↓
结构化回答 + 条款引用
1、组件说明
1)Workflow
把AI的工作过程流程化,过程可控、结果可靠:
“先查法条 → 再解释 → 再结合场景”
2)RAG
GDPR 条文长,条款之间强关联,模型容易“编故事”,RAG 的目标不是“补充知识”,而是“限制自由度”。
- RAG是什么
![image]()
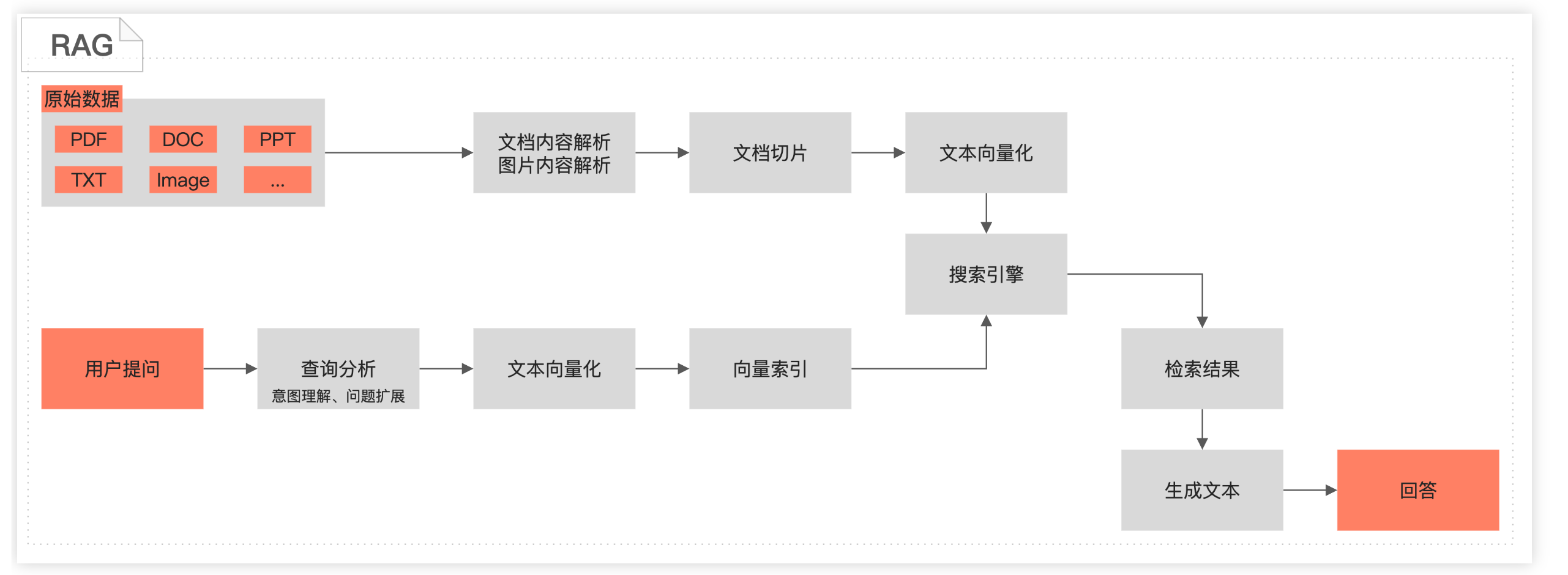
不是模型、不是算法、不是某个库,他是一种工作模式:“检索 + 生成”
- RAG能实现什么
联想下普通的搜索是怎么样的?搜索框完全匹配、模糊(%value%)搜索。RAG 具备语义分析(embedding)能力,能够从语义上理解你在说什么,另一方面,他能解析文档内容存储在向量数据库中;当你搜索时,在理解了你的语义后,从数据库匹配语义最接近的向量,获得检索结果。
3)智能体
不漂移、有约束,Agent = 角色 + workflow + 约束规则,在coze上可以将workflow封装一层为agent使用。
四、实现步骤
1、知识库文档准备
准备articles和recitals文档
2、关联articles和recitals
Articles 就是我们常见的GDPR的条款内容,是硬性义务,可执法、可处罚,共99条;
Recitals 是对Articles的说明,帮助理解规则的背景和解释,解释性说明,本身不直接执法。
每一个Articles都有对应的Recitals,我们这个步骤要做的就是将这两个文档进行关联,这样可以防止大模型“一本正经胡说八道”、让他只基于我们的知识库来回答。
如何关联,有几种方案,颗粒度从粗到细:
1)直接分别上传Articles和Recitals两个文档,这样也能跑,就是太粗犷了。
2)在每个Articles后面加一句,例如:“Related Recitals: 51, 52, 53, 54...”,让大模型去解析、去引用。例如:
Article 5 – Principles relating to processing of personal data
Related Recitals: 39, 40, 41
Personal data shall be:
(a) processed lawfully, fairly and in a transparent manner...
3)每个 Articles 下面有bullet(1、2、3....),bullet下面还有a)、b)、c).....,如果想做到工业级别,可以增加一个中间表(配置)来关联两者,将 Recitals 和 Articles的关联精确到每个最小点。例如:
{
"article_id": "6(1)(f)",
"related_recitals": ["47", "48", "49"],
"topic": "legitimate_interest"
}
毫无疑问,方案3的做法准确度和规范性会大大提高,也会更加耗人力:对条款的理解和解读、分类标记。
鉴于我们是在MVP验证阶段,先采用方案2的方式快速体验。
一开始我让chatgpt给出一版核心Articles 及其对应关联的 recitals ,核对了两个“权威”文档后,我决定按照参考gdpr-info 和 dpocentre的映射手动整理。
gdpr-info :
https://gdpr-info.eu/art-14-gdpr/ 每个Articles下面都有对应的 Suitable Recitals
https://gdpr-info.eu/recitals/no-1/ 可以查看每个Recitals
dpocentre:
https://www.dpocentre.com/resources/gdpr/
实现的样例如下:
第一、二两个红框,Related Recitals: xx,xx,xx
吭哧弄完才发现,这个文档里面,英文部分,其实人家已经标注了Suitable Recitals(红框部分) 。。。。。 ,就暂且留着吧,做个容错冗余。

3、创建知识库
coze和dify等平台都提供了知识库功能,为我们封装了RAG的底层实现,只需要上传文档、然后配置相关参数就行了。
这里chatgpt建议我创建两个知识库,分别存放两个文档,这种独立性是为了便于后续更加明确查询先后逻辑。我理解这么做是让操作更加“原子化”、过程可靠、从而实现结果可控。
例如,可以直接在prompt里面说:先查 Article 再根据 Article 中的 Related Recitals 去查 Recital Dataset。
4、搭建workflow
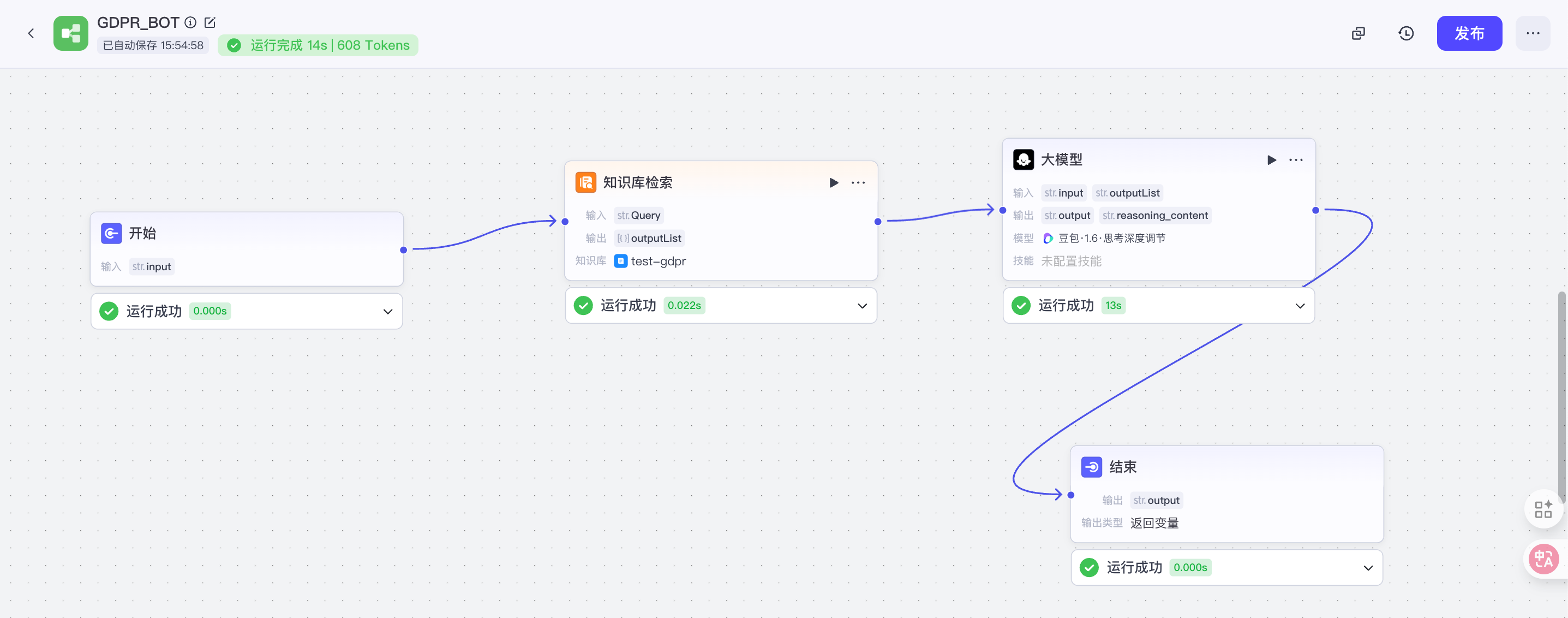
工作流程是:用户输入-> 知识检索->大模型(基于系统prompt、用户prompt,依据userinput和知识库result回答)->输出
在逐个节点调试后发现,问题出在“知识检索”这个节点。由于我上传的是非结构化文档(写过安全制度的都知道),coze不能很好的理解和解析我的文档,解析过程中甚至出现了文档内容的缺失(尝试了coze自带的几种解析方式)。
文档样式:


解析缺失:例如图中可见的,article 4 过完居然直接就article 10了,中间的部分内容被“吃掉了”。

调试验证:
我又新建了一个临时的知识库,里面只有一个文档、一句话:article 6 xxxxxxxxx ,发现知识库并没有解析和识别到内容,如下图。
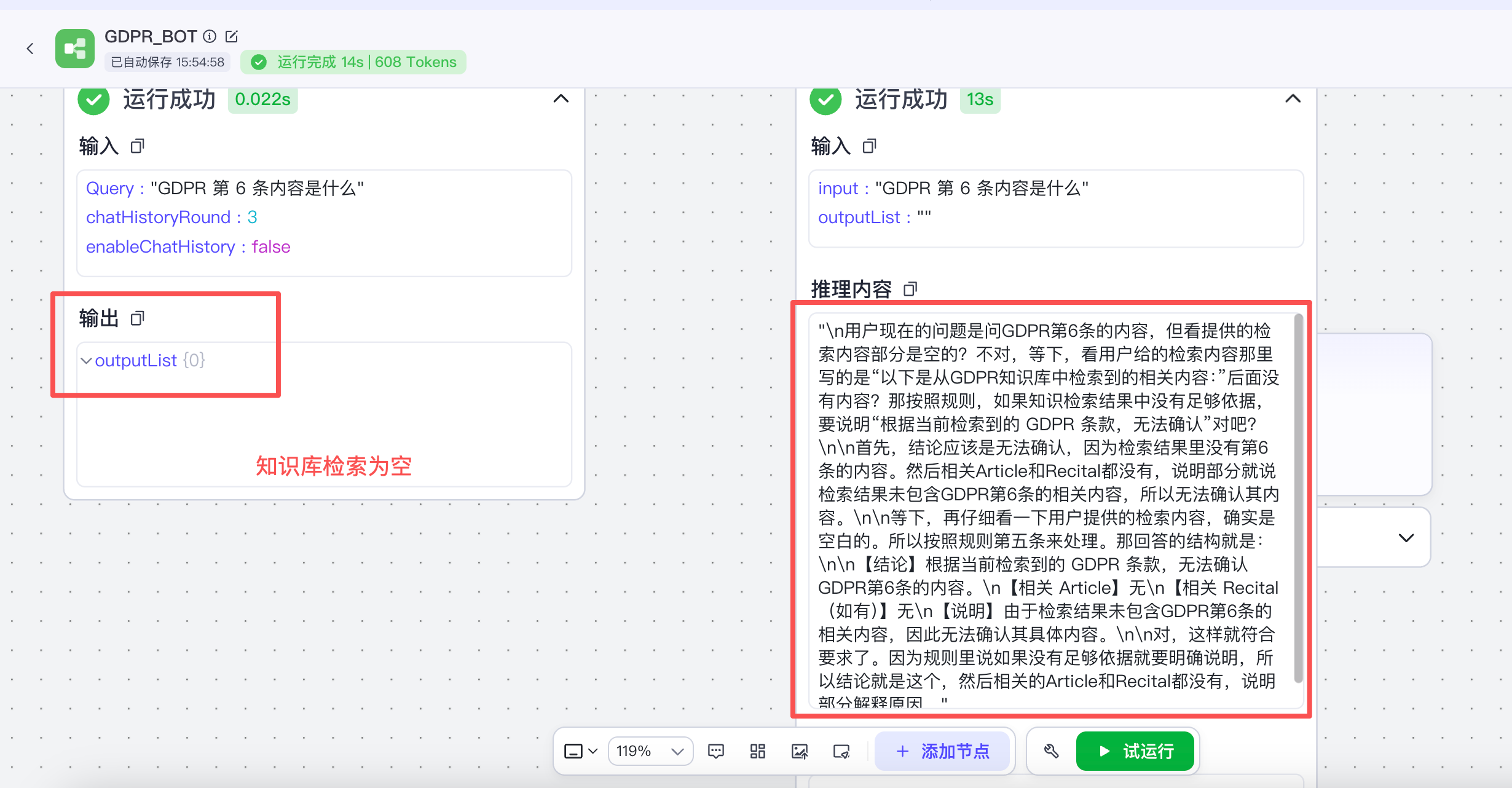
后记
兴致勃勃开始,最后效果不及预期确实有点沮丧。
流程是这么个流程,结果不是预期内的。。用dify的知识库召回测试了下,依然不能返回我预期的结果。。
我在想,如果人工的逐条 严格编号清晰,如: art 6.f.(a) ,程序应该是能识别的,但这样就失去了我做这个小工具的初衷,试想如果涉及到的文档很多,难不成都要这样来处理?!....
先留一个坑吧,如:
- 工业级RAG如何工作和实现
- 如何定性和定量评估一个RAG系统的好坏
- .....
等我研究完再来补。
如果有解决了这个问题的小伙伴也欢迎和我沟通~
refer:
https://mp.weixin.qq.com/s/BBIpsIkCSbuBEJRvddmYAQ
https://mp.weixin.qq.com/s/ZXhVizFBnRLEnhTFhAHOeA
https://mp.weixin.qq.com/s/fEanoepIdoh5fC_1AATY1Q
本文来自博客园,作者:Momoko-X,转载请注明原文链接:https://www.cnblogs.com/ffx1/p/19387894

 浙公网安备 33010602011771号
浙公网安备 33010602011771号