敏感信息检测方法
本文记录:解决数据安全场景中敏感信息的检测方法。
一、luhn算法
luhn算法又叫“模10算法”,用于判断一串数字(如银行卡号、信用卡号、身份证号、手机号校验位)是否符合预设的数学规则,而非仅看格式。对数字串的每一位按特定规则(奇偶位加权、求和、取模)计算,验证最终结果是否满足 “模 10 等于 0” 的条件。
| 项目 | Luhn 算法 | 身份证校验位算法(ISO 7064 MOD 11-2) | 银行卡校验位算法(同 Luhn) |
|---|---|---|---|
| 主要用途 | 银行卡号、IMEI 等 | 中国身份证号码最后一位校验码 | 银行卡号校验位生成 |
| 是否国际标准 | 否(但行业通用) | ✔ ISO 7064 标准 | 否(行业通用) |
| 采用的模(mod) | mod 10 | mod 11 | mod 10 |
| 权重方式 | 动态:从右开始每隔一位乘 2 | 静态:固定 17 个权重 | 动态:与 Luhn 相同 |
| 是否使用数字求和(digit sum) | ✔ >9 时拆分求和(n-9 或拆成两位相加) | ✘ 不需要 | ✔ 同 Luhn |
| 校验位字符集 | 0–9 | 0–9 + X | 0–9 |
| 可发现的错误类型 | 单个数字错误、邻位数字调换 | 几乎所有单错位、双错位 | 与 Luhn 相同 |
| 对输入长度要求 | 可变(13–19 位) | 固定:18 位 | 同 Luhn |
| 核心思想 | 右起偶数位 *2,求和后 mod10 | 加权求和取 mod11,映射到校验位 | Luhn |
| 适用性强弱 | 强:适合任意长度编号 | 专用:只用于身份证 | 强:适用于 PAN |
| 抗误报能力 | 中等 | 强 | 中等 |
1.1 身份证号检测
1.1.1、身份证号码的组成
18位的构成(常见):

15位的情况(特殊):适配1984年的一代身份证号(其出生日期码的年份只有两位,且缺少校验码)
在第6位后插入“19”来计算第18位。
1.1.2、身份证号码校验位计算
也是 ISO 7064 MOD11-2 校验规则,使用前17位通过GB 11643-1999《公民身份证号码》 规定的权重进行计算,推导出合理的最后一位(第18位)校验位,确保身份证格式的合法性;
1.1.3、行政区域位校验
前6位。
这部分检测对准确性很必要。
1.1.4、出生日期校验
日期格式YYYYMMDD、年龄校验(0-120岁)
1.1.5、增强做法:避免绕过、提高准确性等
如:
- 对接公安/第三方实名核验接口(姓名+身份证+手机号/银行卡),作为最终强验证。
1.1.6 实现代码
https://github.com/Momoko-X/Sec-farming/tree/main/Sec_tool/Sensitive_scan/ID_cards
1.2 银行卡号的检测
1.2.1、银行卡号的组成
银行卡号由以下部分组成(一般 13–19 位数字,中国常见 16 或 19 位):
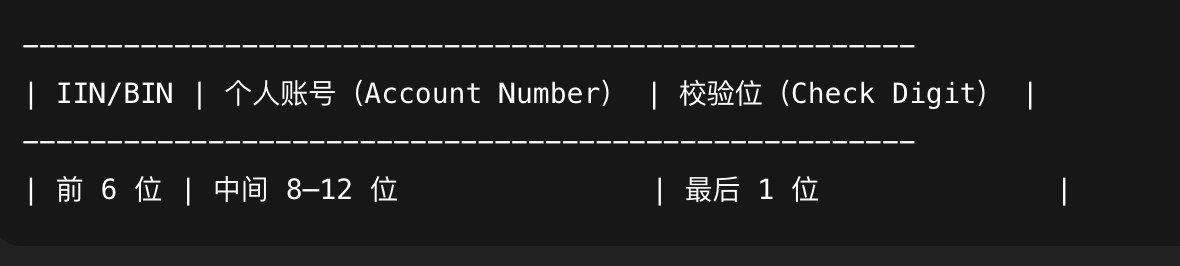
1.2.2、IIN/BIN(Issuer Identification Number 发卡行识别号)
前 6 位数字,这部分检测对准确性很必要。
决定银行卡属于哪个银行、类型(借记卡/信用卡)
如:
622202:工商银行
621660:建设银行
622848:农业银行
可以通过官方 BIN 列表进行验证(可用于增强检测效果)
1.2.3、个人账号部分(Account Number)
长度不固定(通常 8–12 位)
并无公共检测规则
1.2.4、校验位(Check Digit)
最后一位
根据 Luhn 算法计算得到
1.2.5 实现代码
https://github.com/Momoko-X/Sec-farming/tree/main/Sec_tool/Sensitive_scan/Bank_ID
参考:
https://github.com/caijf/bankcard/tree/master
https://github.com/whinc/whinc.github.io/issues/6
https://github.com/amosnothing/card_bin
二、 算法模型
2.1 Hanlp
-
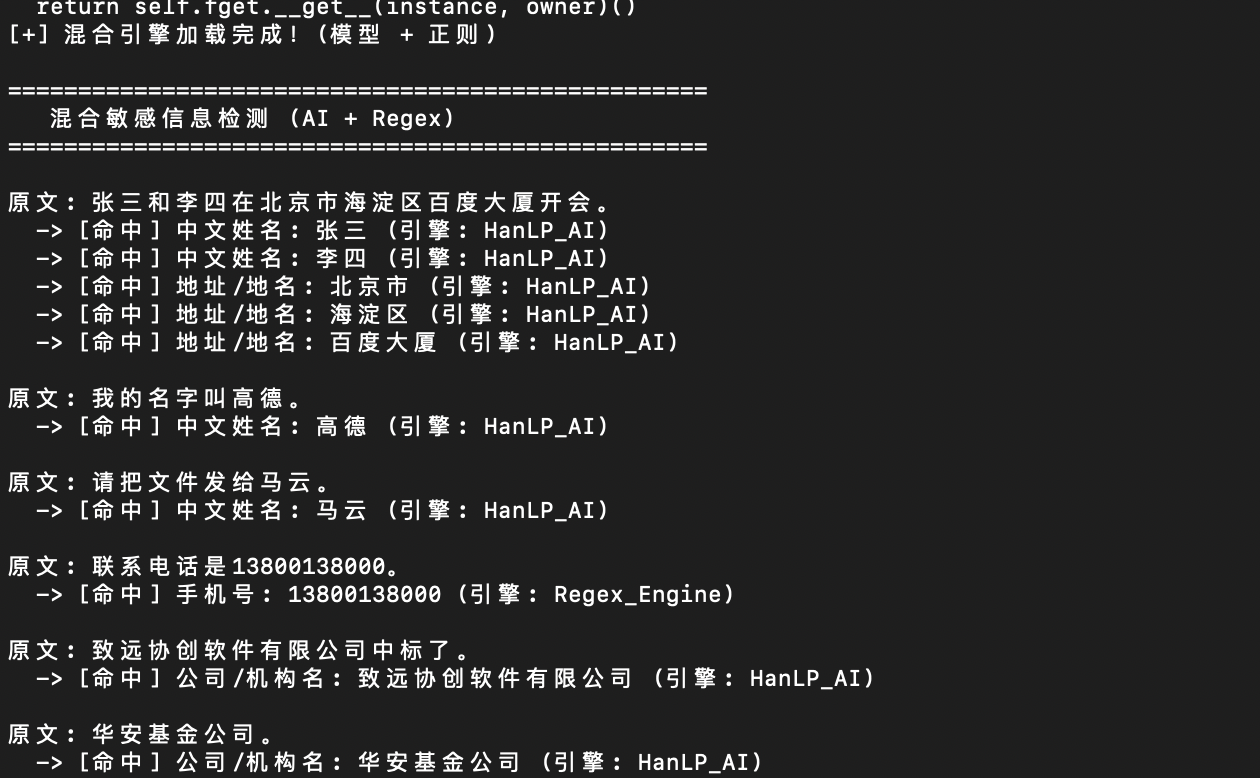
基于深度学习(TensorFlow/PyTorch)技术的,目前中文自然语言处理(NLP)领域的“瑞士军刀”,是工业界最主流的开源工具之一。
-
优点:HanLP的中文理解能力极强:人名、地名、机构名,但对于其他类型的敏感信息,如:手机号、身份证号、邮箱、车牌号等,需要结合luhn算法、正则等来完成,自定义和灵活度不够。
-
缺点:1)中文能识别的字段有限(人名、地名、机构名),不够通用;2)不擅长处理超长文本(通常有限制,如512字符),也不擅长跨段落的逻辑推理。需要研发在输入前做“文本切片”,处理长文档。
-
能力扩展:“外挂”自定义词典(白名单模式)、微调模型“自己学习、识别未知”(前期需要人工打标)。
2.1.1 代码Demo
github:
https://github.com/Momoko-X/Sec-farming/blob/main/Sec_tool/Sensitive_scan/han_nlp.py
2.2 ModelScope UIE
ModelScope是一个模型平台,类似于中国版的Huggingface,上面有很多模型,使用上限更高。
UIE是平台上的一个通用中文识别模型,比Hanlp更进一步,能够自定义检测敏感字段,用户只需要在prompt里面给出待识别的字段,如:身份证号、订单号、车牌号.... 模型就能自动识别。
这个模型相较于Hanlp在部署上依赖会复杂一点。
2.2.1 实现代码
github:
https://github.com/Momoko-X/Sec-farming/blob/main/Sec_tool/Sensitive_scan/uie_demo.py
三、大模型
这里以通义千问为例,可以更加灵活的在代码中自定义prompt:
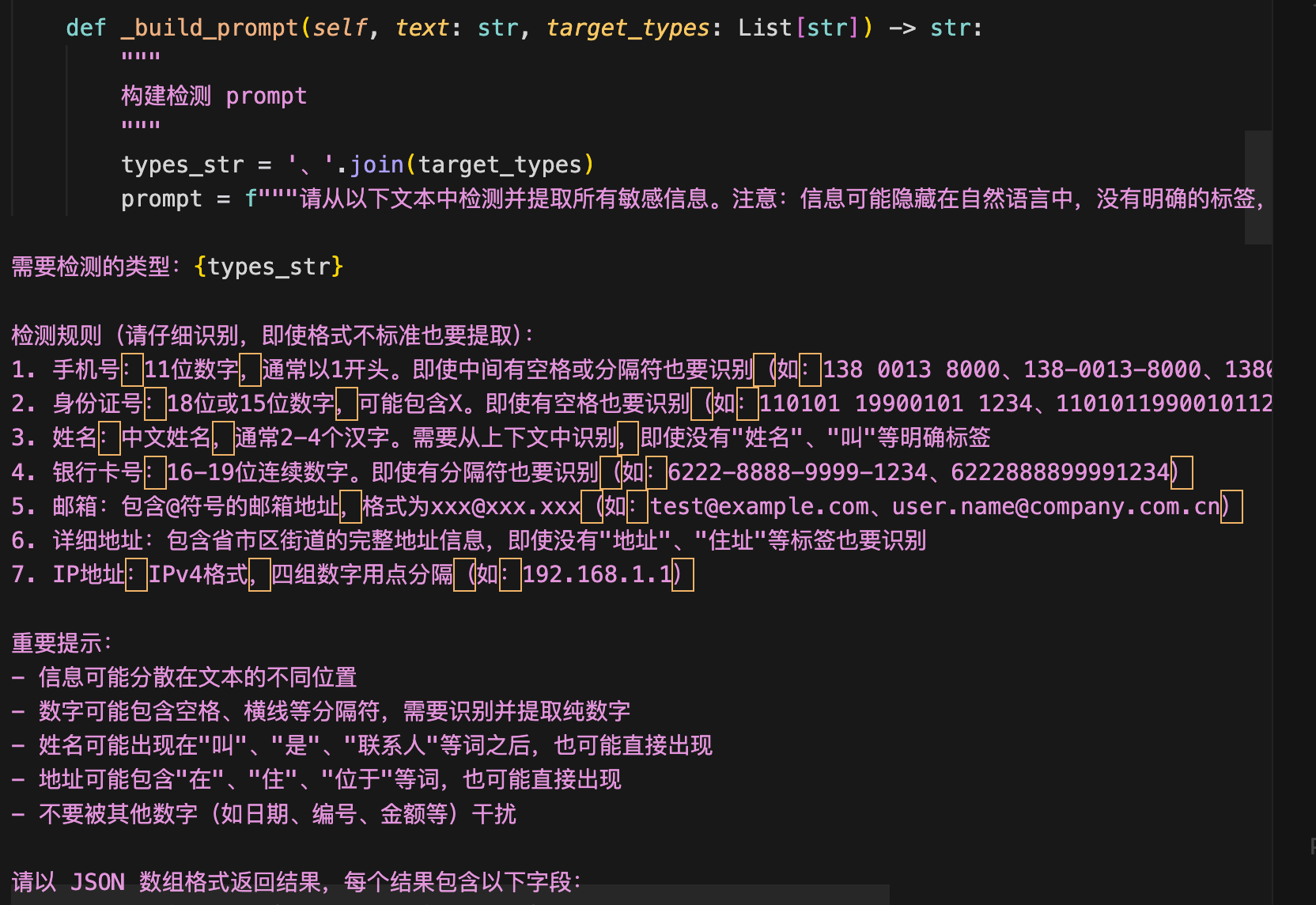
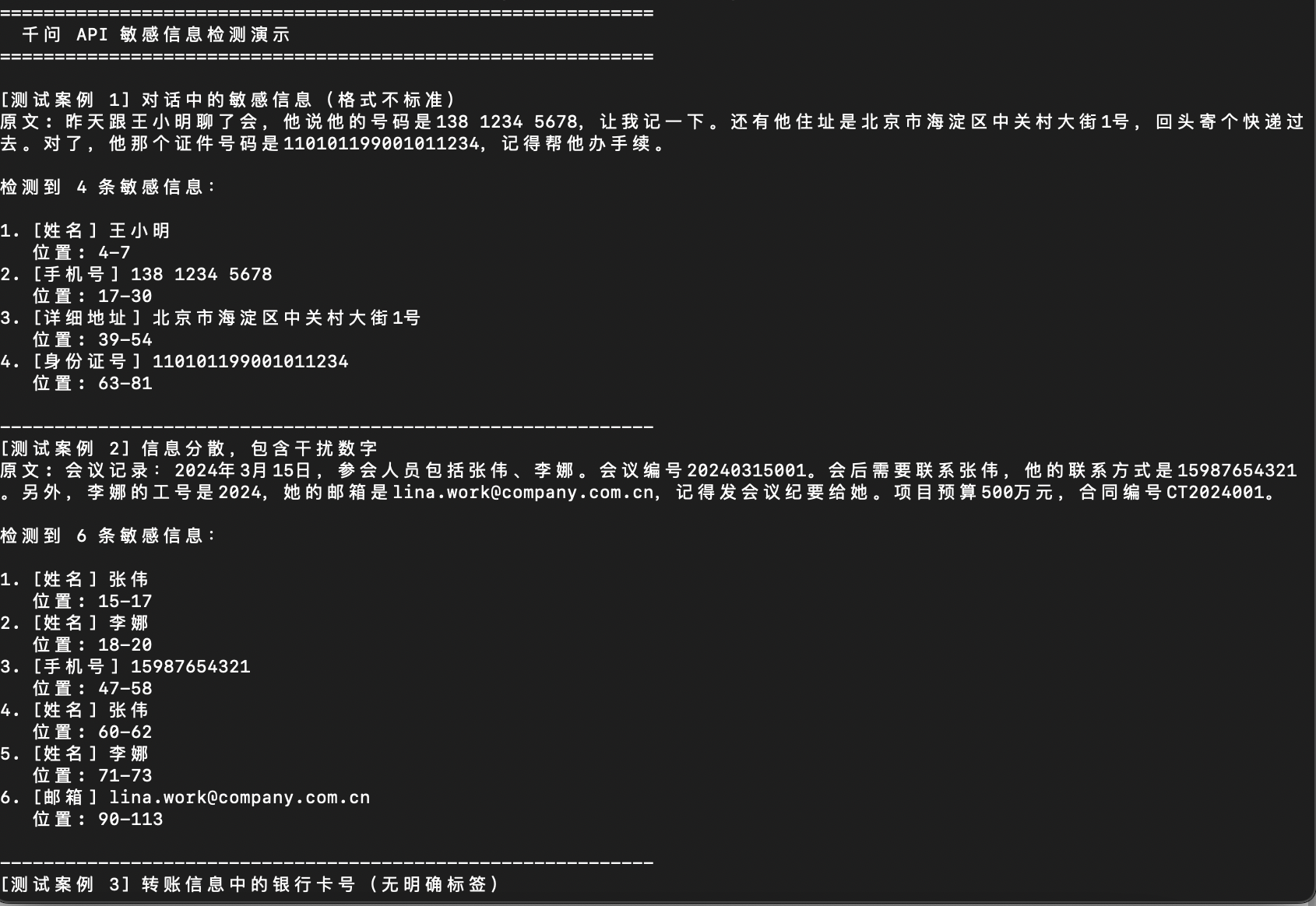
3.1 运行效果
3.2 代码
https://github.com/Momoko-X/Sec-farming/blob/main/Sec_tool/Sensitive_scan/qwen_demo.py
四、总结
不论是 正则、算法、大模型,单独使用在准确性上都不理想,模型和LLM在语义检测上占优势,能很好的从一段文本出提取出可能的敏感信息,比如:“我的手机号是1355555555555、银行卡号是2232324343434”,他们能提取出这段内容,但是对值的真实性不负责,而这一点正则和算法(如luhn)可以解决。
通常是组合使用,在考虑平衡准确性和性能后,流程可以是大致如下:
文本 / 字段值 / 日志
↓
+--------------------------------+
| Step 1: 正则规则 + 模式匹配 | ← 最快(微秒级)
+--------------------------------+
↓ 命中
+--------------------------------+
| Step 2: 算法校验(如 Luhn) | ← 毫秒级
+--------------------------------+
↓ 仍不确定
+--------------------------------+
| Step 3: 轻量 NER 模型 | ← 5~20ms
+--------------------------------+
↓ 仍不确定
+--------------------------------+
| Step 4: LLM(语义判断) | ← 200~1000ms
+--------------------------------+
↓
最终置信度输出
Step 4 的输出还可以给正则和算法过一遍,以提高准确性。
本文来自博客园,作者:Momoko-X,转载请注明原文链接:https://www.cnblogs.com/ffx1/p/19218299

 浙公网安备 33010602011771号
浙公网安备 33010602011771号