Java集合-HashMap
HashMap 是 Map接口的一个实现类,它的使用频率是这些实现类中最高的。

-
HashMap 的实现不是同步的,这意味着它不是线程安全的。
-
它的key、value都可以为null,但是key不能重复。
-
此外,HashMap中的映射不是有序的,因为底层是以 hash表的方式来存储的(jdk8的 HashMap底层:数组+链表+红黑树)
-
常用方法:
与Map接口的一样。
![image]()
put方法:当 put 两个键相同的 k-v 的时候,后面 put 的 value 会覆盖掉前面的v alue
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} -
四个构造方法:
(1)HashMap(int initialCapacity, float loadFactor):int 类型为自己设置的初始化容量,float 类型为自己设置的加载因子。
(2)HashMap(int initialCapacity):其实调用的也是第一个构造器,第二个参数是默认加载因子0.75。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}(3)HashMap():无参构造器,里面初始化加载因子,第一次 put 才会扩容到16.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}(4)HashMap(Map<? extends K, ? extends V> m):包含“子Map”的构造函数
-
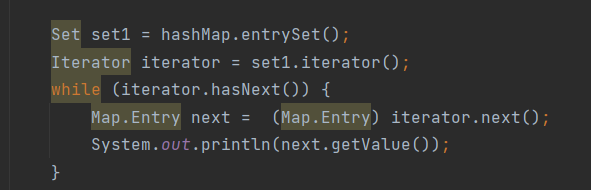
遍历方式:实现了Map接口,使用Map接口遍历的方式来遍历
获取集合(keySet,entrySet,values),然后遍历(迭代器,增强for循环)
注意转型
![image]()


-
扩容机制:
和 HashSet的完全一样,因为 HashSet 底层就是 HashMap。
参考文章:Java-HashMap工作原理及实现
链接:Java-HashSet
结论:
![image]()
6)Java8中,若一条链表的元素已经至少有8个(即插入第 9个时),会进入treeifyBin方法(进行树化的方法),里面再判断table表的大小,若小于64,则继续使用resize方法对table表进行扩容,若大于或等于64,才进行树化。 -
put() 源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}![image]()
putVal() 源码:
参考文章(针对语句:if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))):http://bbs.itheima.com/thread-218310-1-1.htmlfinal V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量
//table 就是 HashMap 的一个数组, 类型是 Node[]
//进入👇的if:当前 table 是 null,或者其大小=0
//就是第一次扩容,空间为16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//进入👇的if:p为null(表示该索引的table表处还没有存放过元素)
//i = (n - 1) & hash]:根据key,得到hash 去计算该key应该存放到table表的哪个索引位置
//p = tab[i = (n - 1) & hash]):并把这个位置的对象,赋给 p
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//进入👇的else:p不为空(即tab[i]不为null)
else {
Node<K,V> e; K k;
//进入👇的if:p不为空;当前索引位置对应的链表的第一个元素和准备添加的 key 的 hash值一样
//(判断头结点)
//(&&)并且满足以下两个条件之一,就不进行插入
//(||)(1)准备加入的 key 和 p 指向的 Node 结点的 key 是同一个对象
//(||)(2)p 指向的 Node 结点的 key 的equals() 和准备加入的key比较后相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//进入👇的else if :p不为空;p 是一棵红黑树结点
//调用 putTreeVal方法 ,来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//进入👇的else:p不为空;如果table对应索引位置,已经是一条链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//头结点的 next为空,直接插入
p.next = newNode(hash, key, value, null);
//每次成功在一条链表上插入后,会判断该链表是否至少有了 8 个结点
//若是,则进入 treeifyBin方法中判断是否需要进行树化:
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// resize(); //【MIN_TREEIFY_CAPACITY 为64】
//由上面代码可知,若 table表长度小于 64,则会调用resize方法继续对table表进行扩容;
//若大于64,则进行树化。转换成TreeNode,然后每次插入会进入 27 行代码的else if中。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//TREEIFY_THRESHOLD:8
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//进入👇的if:插入失败
//覆盖掉该结点的 value
if (e != null) { // existing mapping for key
V oldValue = e.value;
//进入👇的if:
//* @param onlyIfAbsent if true, don't change existing value
//onlyIfAbsent 在 put 方法里可以看到传入的是false,所以这里的 !onlyIfAbsent 为 true
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//这里的 size 是:每加入一个结点 Node (k,v,h,next),size++
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}



 浙公网安备 33010602011771号
浙公网安备 33010602011771号