
一、了解 oracle 11g 的索引的分类
1,索引是与表相关的一个可选结构,用以提高 SQL 语句执行的性能,减少磁盘 I/O,使用 CREATE INDEX 语句创建索引
2,索引是在逻辑上和物理上都独立于表的数据,Oracle 是自动维护索引
3,索引分为:B树索引(平衡树索引)、位图索引。
3-1,B树索引分为:唯一索引、组合索引、反向键索引、基于函数的索引
3-1-1,唯一索引:确保在定义索引的列中没有重复值,Oracle 自动在表的主键列上创建唯一索引,使用 CREATE UNIQUE INDEX 语句创建唯一索引
3-1-2,组合索引:是在表的多个列上创建索引,索引中列的顺序是任意的,如果 SQL 语句的 WHERE 子句中引用了组合索引的所有列或大多数列,则可以提高检索速度
create index comp_index on itemfile(p_category,itenrate);
create unique index item_index on itemfile(itemcode); 注意在itemfile 表中的 itemcode 建产索引后可以随意的插入 null 值,不会报错
3-1-3,反向键索引:反转索引列键值的每个字节,通常建立在值是连续增长的列上,使数据均匀地分布在整个索引上,创建索引时使用 REVERSE关键字
CREATE INDEX rev_index ON itemfile(itemcode) REVERSE; 创建反向键索引
ALTER INDEX re_index REBUID NOREVERSE;
3-1-4,基于函数的索引:基于一个或多个列上的函数或表达式创建的索引,表达式中不能出现聚合函数,不能在 LOB 类型的列上创建,创建时必须具有 QUERY REWRITE 权限;
CREATE INDEX lowercase_idx NO toys (LOWER(toyname)); --创建一个基于 LOWER 的函数的索引;
SELECT toyid FROM toys where LOWER (toanme) = 'doll';
3-2,位图索引:位图索引适合创建在低基数列上,位图索引不直接存储 ROWID,而是存储字节位到 ROWID 的映射,节省空间占用,如果索引列被经常更新的话,不适合建立位图索引,总体来说,
位图索引适合于数据仓库中,不适合 OLTP 中;
CREATE BITMAP INDEX bit_index ON order_master(orderno); 创建位图索引
4,创建索引 create index ind1 on student(sno);表示创建一个标准索引 ind1;其指向为 student 表中的 sno 列;
5,select * from user_indexes; 表示查询当前表中的所有索引;
6,select * from user_ind_columns u where u.index_name='IND1'; 表示查询索引名为 IND1 的索引的信息
7,分析索引:当索引建好以后,随着长时间的对数据库操作,删除了许多记录,又新增了许多记录,但索引在建立之初,已经建好的叶分支块是不会随着指向的数据块删除而删除的,这个时候就需要分析索引
7-1,查看 index_stats 表中的 pct_used 列的值,如果 pct_used 的值过低,说明在索引中存在碎片,可以重建索引,来提高 pct_used 的值,减少索引中的碎片;例:
create table t(t1 char(8));
begin
for i in 1..1300000 loop
insert into t values(ltrim(to_char(i,'00000009'))); --表示插入数据的格式为不够8位时在前面补0;
if mod(i,100)=0 then commit; --表示如果插入的数据 % 100 等于0,就提交一次,提高效率
end if;
end loop
end;
说明:每一次要查看索引有没碎片时,先对索引进行分析:analyze index ind_t validate structrue;
然后再查看索引中 pct_used 的值:select name,pct_used from index_stats where name='IND_T'; 一般在索引刚建立时,pct_used 的值为90,表示使用率为 90%,一般默认空余 10%;
如果发现 pct_used 的值过低,可以修改索引:alter index ind_t rebuild;
8,重建索引:ALTER INDEX index_name REBUILD [ONLINE] [NOLOGGING] [COMPUTE STATISTICS];
8-1,ONLINE:使得在重建索引过程中,用户可用对原来的索引修改;
8-2,NOLOGGING 表示在重建过程中产生最少的重做条目 redoEntry;
8-3,COMPUTE STATISTICS 表示在重建过程中就生成了 oracle 优化器所需的统计信息,避免了索引重建之后再进行 analyze 或 dbms_stats 来收集统计信息;
9,删除索引:DROP INDEX item_index;
二、理解 oracle 11g 的索引查找的原理
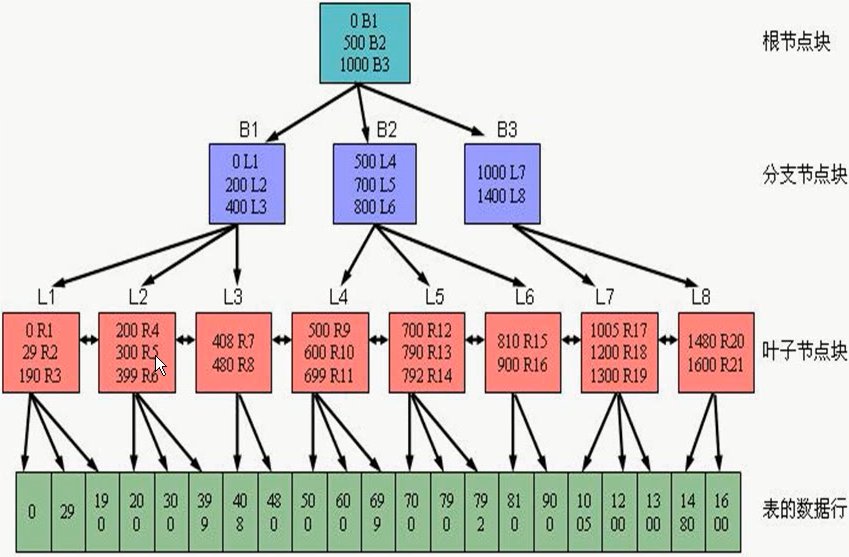
三、能够根据情况建立合适的索引
1,索引的分区:可以将索引存储在不同的分区中;
2,与分区有关的索引有三种类型:局部分区索引,全局分区索引,全局非分区索引
2-1,局部分区索引:在分区表上创建的索引,在每个表分区上创建独立的索引,索引的分区范围与表一致;例:
create table employee(code number, name varchar2(20)) --创建一个分区表
partition by range(clde)
(
partition p1 values less than(1000),
partition p2 values less than(2000),
partition p3 values less than(maxvalue)
);
create index ind_employee on employee(clde) local; 表示创建了一个局部分区表,且与表的分区是一致的;
select u.index_name, u.table_name, u.partitioned from user_indexes u; 表示查询用户中所有索引的基本信息;
select * from user_ind_partitions; 表示查询所有已分区的索引信息;
select * from user_ind_columns; 与索引相关的表列的信息
select index_name,table_name,column_name from user_ind_columns order by index_name,column_position;
2-2,全局分区索引:在分区表或非分区表上创建的索引,索引单独指定分区的范围,与表的分区范围或是否分区无关;
create index ind_employee2 on employee(code) global partition by range(code)
(
partition a1 values less than(1500),
partition a2 values less than(maxvalue)
);
3-3,全局非分区索引:在分区表上创建的全局普通索引,索引没有被分区;
create index ind_employee3 on employee(code) global;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号