
正则表达式
正则表达式
定义
正则表达式是一种文本模式。
正则表达式 = 普通字符 + 特殊字符(元字符)
语法
| 特殊字符 | 描述 |
|---|---|
| [...] | 匹配其中的所有字符,也即“取值范围” |
| [^...] | 不匹配其中的所有字符,当^在[]中时表示取反操作 |
| (...) | 子表达式 |
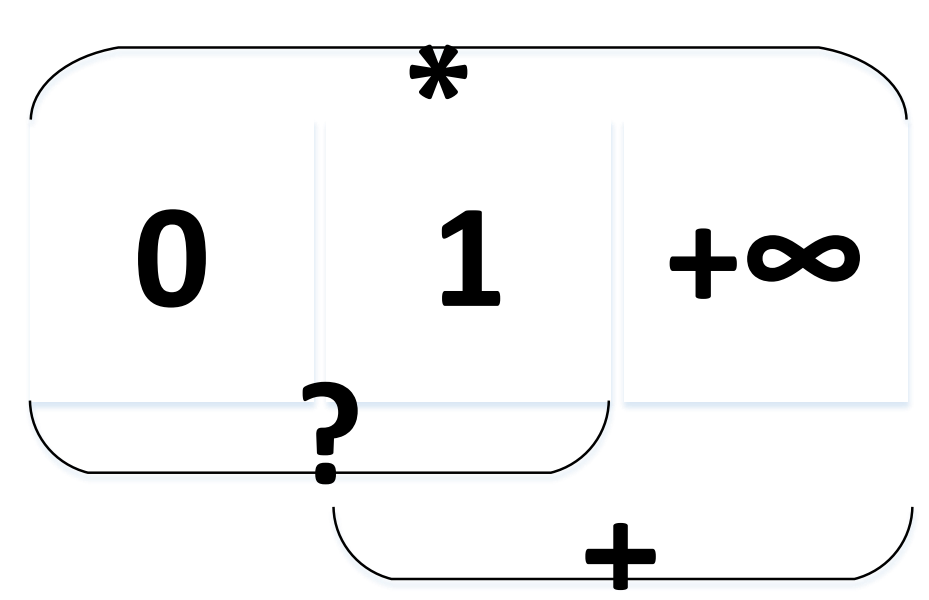
| 限定前一个组件的匹配次数为大于beg次,小于end次,也即“取值范围” | |
| | | 左右两项之间的一个选择,也即“或” |
| ^...$ | ^匹配字符串开始的位置 $匹配字符串结束的位置 | |
| . | 匹配换行符 |
| * | 匹配前面的模式任意次 |
| + | 匹配前面的模式至少一次 |
| ? | 匹配前面的模式零次或一次 |
| exp1(?=exp2) | 查找 exp2 前面的 exp1 |
| (?<=exp2)exp1 | 查找 exp2 后面的 exp1 |
| exp1(?!exp2) | 查找后面不是 exp2 的 exp1 |
| (?<!exp2)exp1 | 查找前面不是 exp2 的 exp1。 |
Python3 实现
re.match
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.match(pattern, string, flags=0)
re.search
re.search 扫描整个字符串并返回第一个成功的匹配。
re.match(pattern, string, flags=0)
python3 匹配中英文标点符号
在某些敏感词检测场景中,需要忽略敏感词内部的标点符号,以此来提升检测的准确率。
代码示例如下:
import regex as re
p = "稳[\p{P}|\s]*赚"
s = "稳,。:;‘“!?、- ——%@#()【】{} ,.:;'\"!?- _%@#()[]{}赚不赔"
pattern = re.compile(p)
print(pattern.search(s))
程序运行结果显示,成功识别出敏感词。
[Reference]
智慧在街市上呼喊,在宽阔处发声。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号