

集合
集合的由来
通常,我们的程序需要根据程序运行时才知道创建多少个对象。但若非程序运行,程序开发阶段,我们根本不知道到底需要多少个数量的对象,甚至不知道它的准确类型。为了满足这些常规的编程需要,我们要求能在任何时候,任何地点创建任意数量的对象,而这些对象用什么来容纳呢?我们首先想到了数组,但是数组只能放统一类型的数据,而且其长度是固定的,那怎么办呢?集合便应运而生了!
集合是什么?
Java集合类存放于 java.util 包中,是一个用来存放对象的容器。
注意:①、集合只能存放对象。比如你存一个 int 型数据 1放入集合中,其实它是自动转换成 Integer 类后存入的,Java中每一种基本类型都有对应的引用类型。
②、集合存放的是多个对象的引用,对象本身还是放在堆内存中。
③、集合可以存放不同类型,不限数量的数据类型。
Java 集合框架图
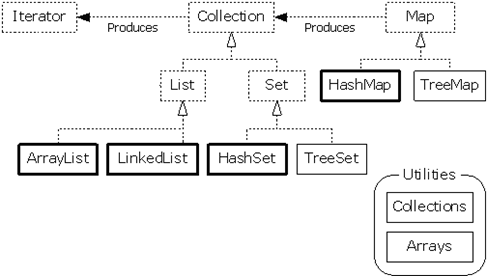
List :有序,可以重复的集合。

由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
List 接口遍历还可以使用普通 for 循环进行遍历,指定位置添加元素,替换元素等等。
//产生一个 List 集合,典型实现为 ArrayList
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
//System.out.println(obj);
}
//在指定地方添加元素
list.add(2, 0);
//在指定地方替换元素
list.set(2, 1);
//获得指定对象的索引
int i=list.indexOf(1);
System.out.println("索引为:"+i);
//遍历:普通for循环
for(int j=0;j<list.size();j++){
System.out.println(list.get(j));
}
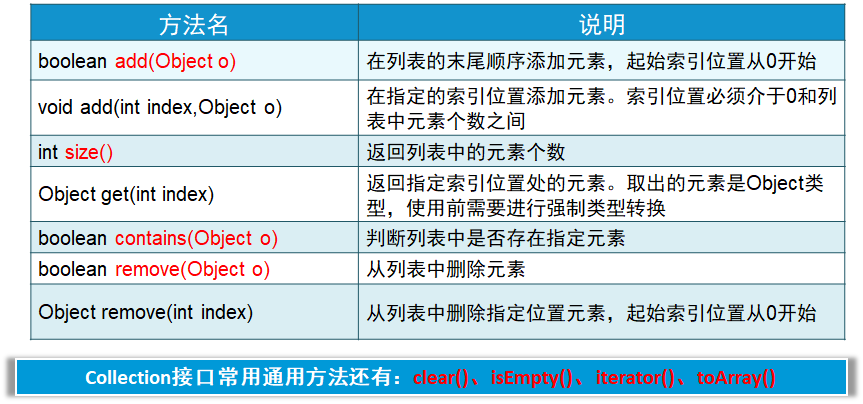
Arraylist常用方法:
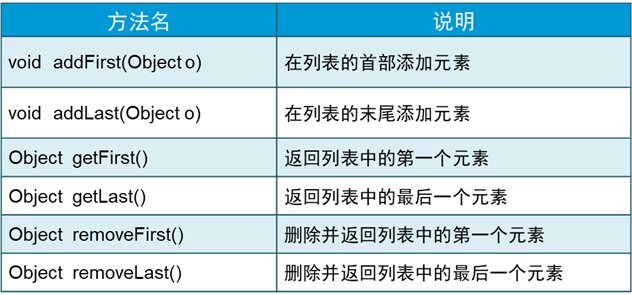
LinkList的常用方法:
List :有序,可以重复的集合。
由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
public class TreeSetTest {
public static void main(String[] args) {
//自然排序: 从低到高
TreeSet<Integer> sets=new TreeSet<>();
sets.add(5);
sets.add(4);
sets.add(3);
sets.add(2);
sets.add(1);
for (Integer integer : sets) {
System.out.print(integer+" ");
}
List<Student> asList = Arrays.asList(new Student("a",18),
new Student("b",17),
new Student("a",15),
new Student("c",24),
new Student("b",20),
new Student("c",25)
);
Collections.sort(asList,new Student());
for (Student student : asList) {
System.out.println(student);
}
}
}
自动排序:添加自定义对象的时候,必须要实现 Comparable 接口,并要覆盖 compareTo(Object obj) 方法来自定义比较规则
如果 this > obj,返回正数 1
如果 this < obj,返回负数 -1
如果 this = obj,返回 0 ,则认为这两个对象相等
public int compare(Student o1, Student o2) {
if(o1.getName().equals(o2.getName())){
return -(o1.getAge()-o2.getAge());//通过比较年龄排序
}else{
return -o1.getName().compareTo(o2.getName());
}
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Student() {
super();
// TODO Auto-generated constructor stub
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
以上三个 Set 接口的实现类比较:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号