
客户环境没办法查看Spark UI页面,怎么办?让我们来使用Spark REST API查看作业信息吧!
文章目录
场景
- 通过跳转机才能访问到spark集群的Linux机器,自己的机器访问不到集群;
- 想定制属于自己公司的spark监控界面
环境
| 软件 | 版本 |
|---|---|
| CDH | 5.13 |
| Spark | 1.6以上 |
IP关系
| IP类型 | 作用 |
|---|---|
配置的yarn.resourcemanager.webapp.address,即运行过程中,日志输出提示 tracking URL,如:http://namenode01:8088/proxy/applicationID/ | 监控运行过程中的应用 |
配置的spark.yarn.historyServer.address | 监控应用情况 |
使用步骤
1. 获取链接IP及端口
1. 获取spark主机域名或ip(适用于查找历史应用)
一般在实际场景中,客户只是提供集群的单台机器作为spark任务的节点。所以当前主机的IP不是spark集群History Server的IP。所以需要找到spark集群的History Server的IP。那么如何获取History Server的IP呢,一般都会在配置文件的spark-defaults.conf里面的spark.yarn.historyServer.address。一般CDH都会在/etc/spark/conf/目录下面。但是如果没有在这个目录下面,可以用以下命令:
find / -name spark-defaults.conf
然后找到文件,在里面查找spark.yarn.historyServer.address,可以使用以下命令:
cat spark-defaults.conf |grep spark.yarn.historyServer.address
像我这里的地址如下:
spark.yarn.historyServer.address=http://namenode01:18088
2. 根据日志查找该应用运行的链接(适用于查找运行中应用)
一般在运行过程中,会提示监控链接。比如:http://namenode01:4040,这个端口一般不固定,如果4040被占用了,就会顺延到下一位。不过这个是运行过程中的链接,如果应用结束了,就没办法根据这个链接访问了。所以,一般都会启动spark的historyServer服务,专门来查看历史应用的日志。不过,在运行过程中,也不一定只需要类似4040端口才能看,也可以根据上一步得到的historyServer的地址,将端口改为8080,然后替换以下链接的{$applicationID},使用curl命令也可以查看:
curl http://namenode01:8088/proxy/{$applicationID}/api/v1/applications/{$applicationID}/jobs
如下图:
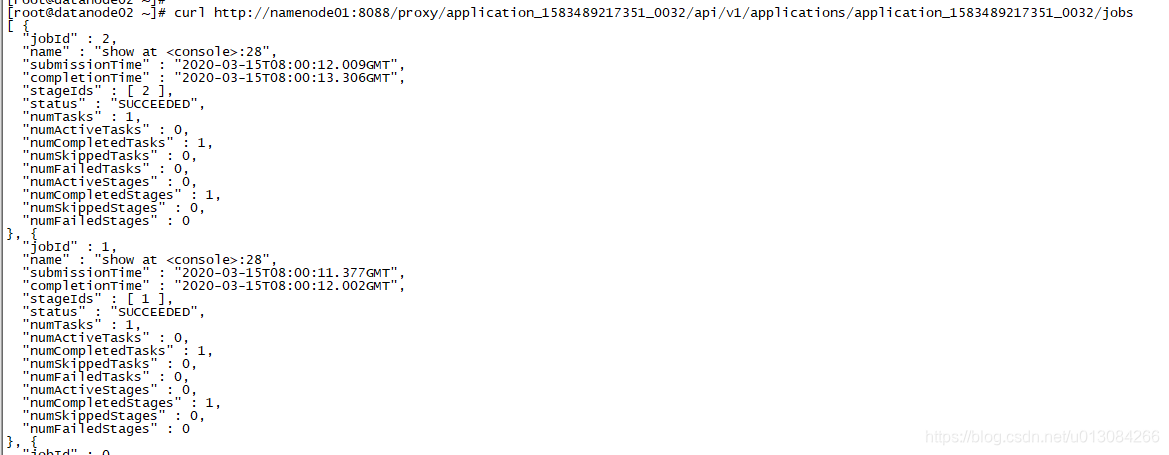
从上图,我们可以了解到该应用的job的信息,包括id,执行时间、状态、运行过程中的stageID、task数量、task完成数量等。其实根据这个,可以很直观地查看到该job的很多信息了。
2. 查看方法
根据上面的获取到的链接,我们就可以查看具体的应用信息、应用阶段信息或者相关的指标统计信息。接下来会罗列比较常用的方法,具体的方法可以到文末的URL 参数清单,根据自己的需求进行更改。以下主要是使用historyServer的链接进行说明,不过即使是正在运行的应用,也可以直接根据这个进行查询,不局限于历史已结束的应用。
-
查看应用列表
curl http://namenode01:18088/api/v1/applications截图如下:
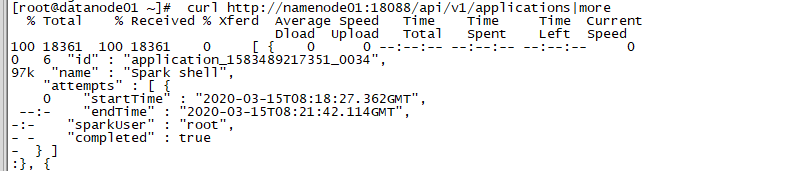
-
获取具体的应用信息
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934截图如下:

-
展示指定应用的所有jobs
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/jobs截图如下:

-
展示指定应用的指定job的相关细节
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/jobs/0截图如下:
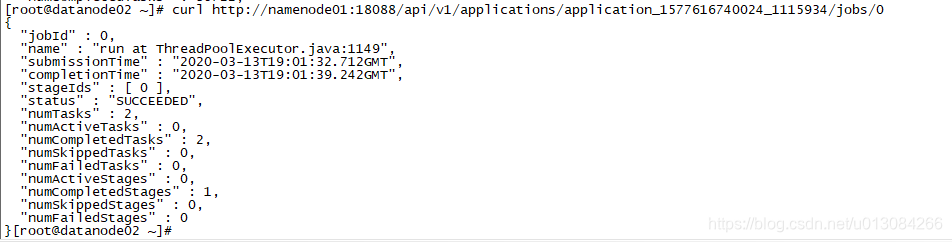
-
指定应用的所有stage
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/stages截图如下:
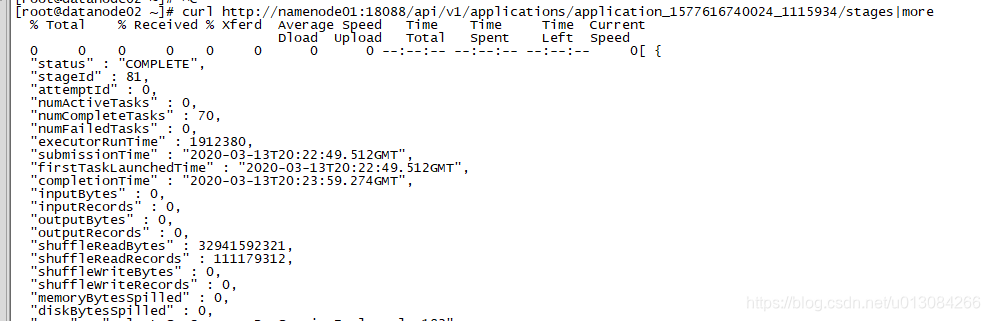
-
指定应用的特定stage的相关信息
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/stages/30截图如下:
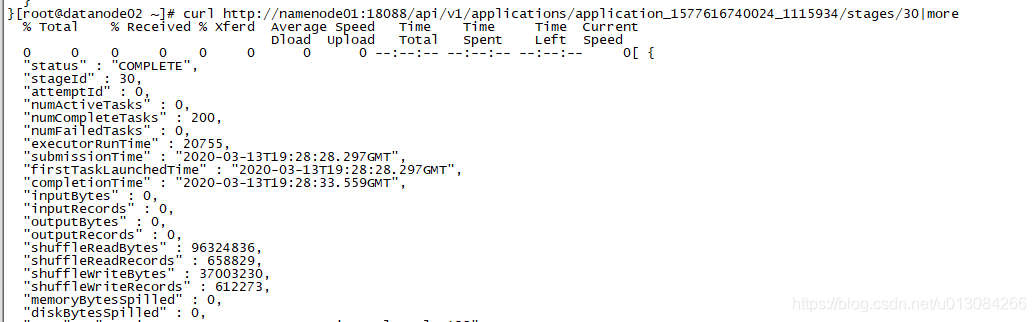
-
输出指定应用的某个阶段的task统计指标
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/stages/30/0/taskSummary截图如下:
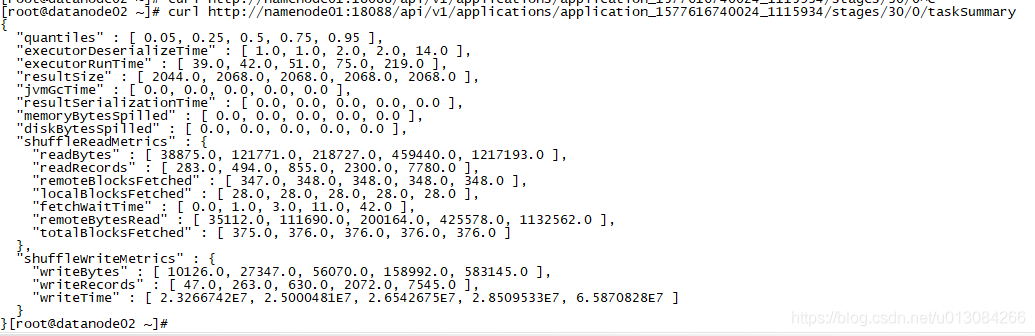
-
下载指定应用的相关日志
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/logs > application_1577616740024_1115934_log.zip截图如下:

-
展示指定应用的executors信息
curl http://namenode01:18088/api/v1/applications/application_1577616740024_1115934/executors截图如下:
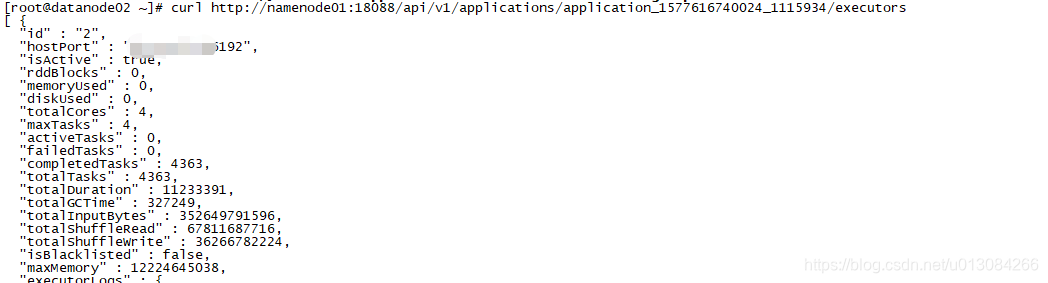
总结
根据调用链接,即使我们看不了spark WEB UI界面,也可以获取到应用的相关信息。我们也可以根据这些信息,在运行过程中根据运行过程信息,动态更新我们代码,比如进行重新划分分区等。不过,这个属于spark的高阶调优过程,本文暂时不涉及。
求赞、求转发、求粉
大家看到这里,如果我的文章对大家产生了帮忙,可以在文章底部点个赞或者收藏;如果有好的讨论,也可以留言;如果想继续查看我以后的文章,可以左上角点击关注。谢谢大家的观看!
URL 参数清单
| Endpoint | Meaning |
|---|---|
| /applications | 罗列所有的应用 |
| /applications/[app-id]/jobs | 展示指定应用的所有jobs |
| /applications/[app-id]/jobs/[job-id] | 展示指定应用的指定job的相关细节 |
| /applications/[app-id]/stages | 指定应用的所有stage |
| /applications/[app-id]/stages/[stage-id] | 指定应用的特定stage的相关信息 |
| /applications/[app-id]/stages/[stage-id]/[stage-attempt-id] | 输出指定应用的某个阶段的指定attempt信息,在yarn下可能会存在多个attempt-id |
| /applications/[app-id]/stages/[stage-id]/[stage-attempt-id]/taskSummary | 输出指定应用的某个阶段的task统计指标 |
| /applications/[app-id]/stages/[stage-id]/[stage-attempt-id]/taskList | 输出指定应用的某个阶段的task列表信息 |
| /applications/[app-id]/executors | 展示指定应用的executors信息 |
| /applications/[app-id]/storage/rdd | 罗列指定应用执行过程中的rdd的相关信息 |
| /applications/[app-id]/storage/rdd/[rdd-id] | 展示指定应用的指定RDD的相关信息 |
| /applications/[app-id]/logs | 下载指定应用的相关日志,调用该命令要将输出保存为zip格式文件 |
| /applications/[app-id]/[attempt-id]/logs | 下载指定应用的指定attempt的日志,调用该命令要将输出保存为zip格式文件 |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号