Shell脚本之正则表达式
通配符
通配符:linux命令中可使用通配符替代或者识别某一些文件名。
- *:代表的是0个或者多个任意字符。
- ?:代表的是有且只有1个任意字符。
- [xxxxxx]:代表的是任意一个中括号内的列表中的字符。
通配符通常会用在模糊查询的场景中,正则表达式匹配的精确度比通配符更高。
- 通配符是用来处理文件名。
- 正则表达式是处理文本内容中字符。必须加双引号。
正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能。
正则表达式被很多程序和开发语言所广泛支持:vim、less、grep、sed、awk、nginx、mysql 等,主要用来匹配字符串(命令结果,文本内容)。
正则表达式—通常用于判断语句中,用来检查某一字符串是否满足某一格式。
正则表达式是由普通字符与元字符组成:
- 普通字符 包括大小写字母、数字、标点符号及一些其他符号。
- 元字符 是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式。
基础正则表达式常见元字符
(支持的工具:grep、egrep、sed、awk)
| 元字符 | 含义 |
|
\ 匹配字符串开始的位置,例:^ a、^ the、^ #、^ [a-z] |
*转义字符,用于取消特殊符号的含义,例:\!、\n、\s等 |
| $ | 匹配字符串结束的位置,例:word、^ 匹配空行 |
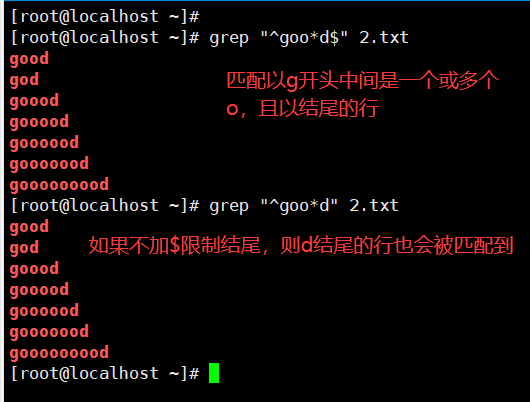
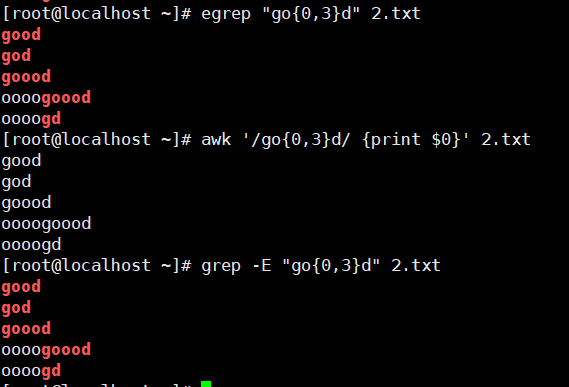
| . | 匹配除\n之外的任意的一个字符,有且仅有一个。例:go.d、g…d |
| * | 匹配前面子表达式0次或者多次,例:goo*d、go.*d |
| [list] | 匹配list列表中的一个字符,例:go[ola]d,[abc]、[a-z]、[a-z0-9] |
| [^list] | 匹配任意非list列表中的一个字符,例:[ ^A-Z0-9],[ ^a-z]匹配任意一位非小写字母 |
| [[:alpha:]] | 代表任意一个大小写英文字母,相当于[A-Za-z] |
| [:[:digit:]] | 代表任意一个十进制数字,相当于[0-9] |
| [[:alnum:]] | 代表任意一个大小写英文字母及数字,相当于[A-Za-z0-9] |
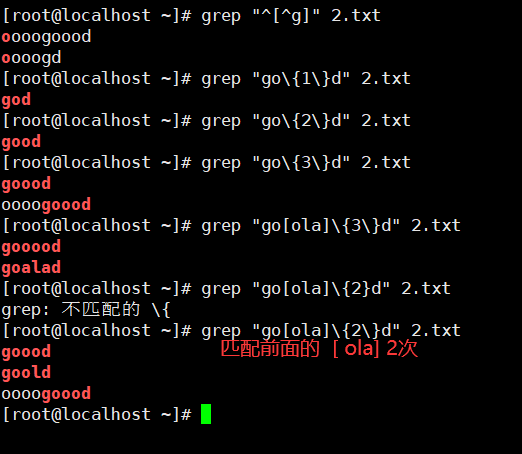
| \ {n\ } | 匹配前面的子表达式n次,例:go{2}d、 '[0-9]{2}'匹配两位数字 |
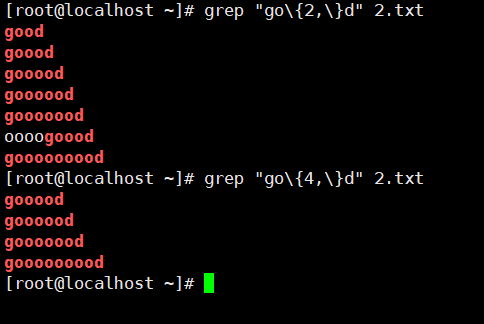
| \ {n,\ } | 匹配前面的子表达式不少于n次,例:go{2,}d、'[0-9]{2,}'匹配两位及两位以上数字 |
| \ {n,m\ } | 匹配前面的子表达式n到m次,例:go{2,3}d、'[0-9]{2,3}'匹配两位到三位数字 |
注: egrep、 awk使用{n}、{n,}、{n, m}匹配时 "{ }" 前不用加" \ "
示例1:转义字符\
\ 可以把一些特殊的符号转换成普通的符号字符,还可以把一些普通字符转换成特殊功能。
| 将特殊的符号转换成普通字符 | |
| \ & | 单个&代表后台运行 |
| \ l | 单个 l 代表“或” |
| \ ! | 单个 ! 代表取反 |
| \ = | 单个=代表复制或者字符判断 |
| \ $ | 单个$代表引用变量 |
| 将普通字符转换成特殊功能: | |
| \n | 转换后是换行符 |
| \t | 转换后是制表符 |
| \r | 转换后是回车符 |
| \w | 匹配包括下划线的任何单词字符 |
| \W(大写) | 匹配任何非单词字符。等价于"[^A-Za-z0-9_]" |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符。等价于[^0-9] |
| \s | 空白符 |
| \S | 非空白符 |
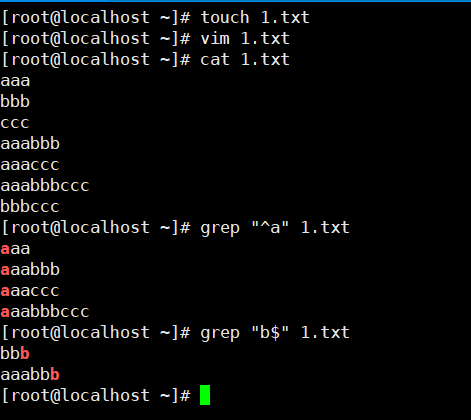
示例2:^匹配开头,$匹配结尾
[root@localhost ~]# touch 1.txt [root@localhost ~]# vim 1.txt [root@localhost ~]# cat 1.txt aaa bbb ccc aaabbb aaaccc aaabbbccc bbbccc [root@localhost ~]# grep "^a" 1.txt aaa aaabbb aaaccc aaabbbccc [root@localhost ~]# grep "b$" 1.txt bbb aaabbb
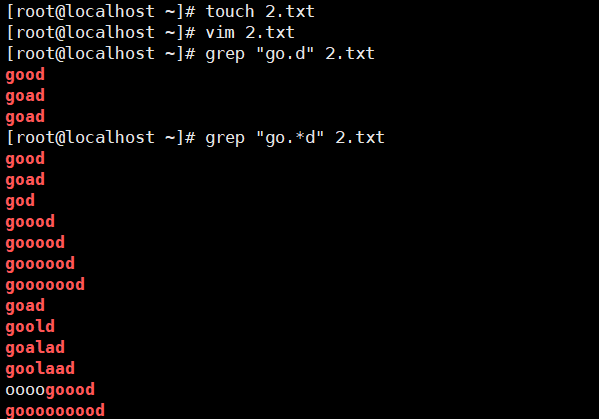
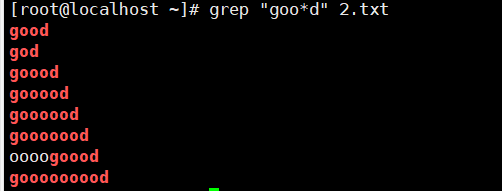
示例3:. 和 *
点:匹配除\n之外的任意的一个字符,有且仅有一个。
星:匹配前面子表达式0次或者多次。
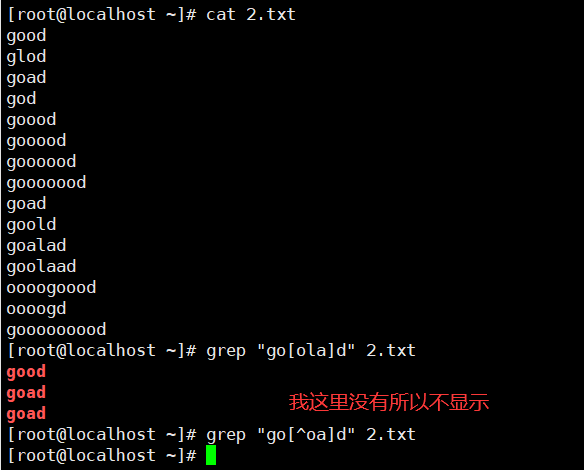
示例4:[list]
[list] 匹配括号内的任意一个字符,只能匹配单个字符。
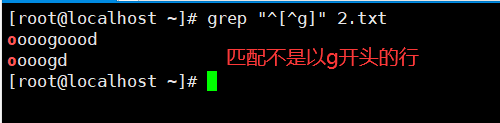
[ ^list] ,^在括号内表示取反。即匹配括号内字符以外的任意一个字符,只能匹配单个字符。
示例5:复合使用
1、^与$复合使用
2、^与 [^list] 复合使用
示例6:{n}
{n} 匹配前面的子表达式n次。
示例7:{n,}
{n,} 匹配前面的子表达式不少于n次。
示例8:{n,m}
{n,m} 匹配前面的子表达式n到m次。

示例9:
egrep,awk在使用{n}、{n,}、{n,m}时,括号{}前不需要加反斜杠\。如果加了\,反而失去效果。
grep -E 可以实现 egrep 的效果。
扩展正则表达式元字符
(支持的工具:egrep、 awk、 grep-E、 sed -r)
| 元字符 | 含义 |
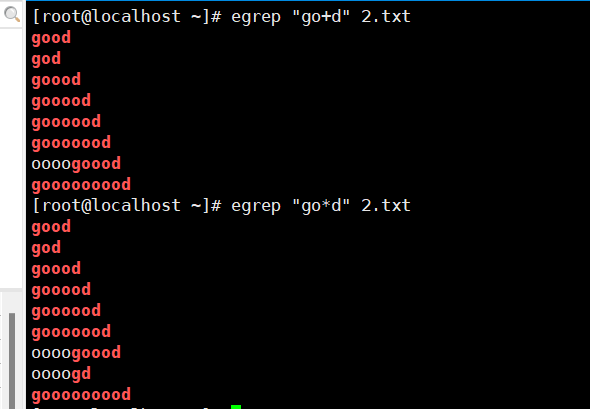
| + | 匹配前面子表达式1次及以上,例: go+d,将匹配至少一个o,如god、good、 goood等 |
| ? | 匹配前面子表达式0次或者1次,例: go?d,将匹配gd或god |
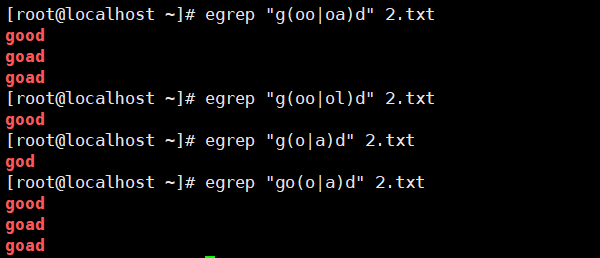
| () | 将括号中的字符串作为一个整体,例1: g(0o)+d,将匹配oo整体1次以上,如good、gooood等 |
| | | 以"或"的方式匹配字符串 |
示例1:+
+:匹配前面的子表达式1次及以上(至少1次)。
示例2:?
?:匹配前面子表达式0次或者1次

示例3:( )
( ):将括号中的字符串作为一个整体
案例演示
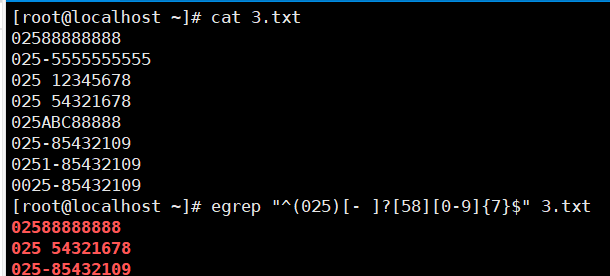
案例1:匹配电话号码
要求:
- 匹配 025 开头的区号。
- 电话号码要5 或者 8开头的八位数。
- 格式如下:
区号 号码 区号-号码 区号号码 123
- 要求全号码格式匹配。
操作:
[root@localhost ~]# cat 3.txt 02588888888 025-5555555555 025 12345678 025 54321678 025ABC88888 025-85432109 0251-85432109 0025-85432109 [root@localhost ~]# egrep "^(025)[- ]?[58][0-9]{7}$" 3.txt 02588888888 025 54321678 025-85432109
案例2:匹配电子邮箱
电子邮箱:
用户名@子域名.[二级域名].顶级域
要求:
- 用户名:长度要求在6-18位,任意大小写英文,任意数字,除了@符号和空格以外的其它任意符号字符,开头只能是 _ 或者字母。
- 子域名.[二级域名]:长度任意,符号只能包含 - _ .
- .顶级域名:长度在2-5,任意大小写英文。
- 完整匹配。
需求分解:
用户名长度要求在6-18位 {6,18}
除了@符号和空格以外的其它任意符号字符 [^@ ]
开头只能是 _ 或者字母 ^[a-zA-Z_]
长度任意,符号只能包含-_. [a-zA-Z0-9-_.]+
长度在2-5,任意大小写英文 .[a-zA-Z]{2,5}
复制代码
操作:
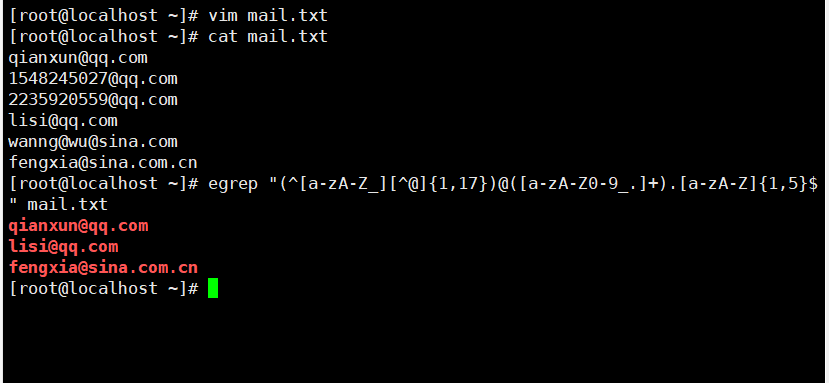
[root@localhost ~]# vim mail.txt
[root@localhost ~]# cat mail.txt
qianxun@qq.com
1548245027@qq.com
2235920559@qq.com
lisi@qq.com
wanng@wu@sina.com
fengxia@sina.com.cn
[root@localhost ~]# egrep "(^[a-zA-Z_][^@]{1,17})@([a-zA-Z0-9_.]+).[a-zA-Z]{1,5}$" mail.txt
qianxun@qq.com
lisi@qq.com
fengxia@sina.com.cn
总结
- 表示任意字符(包括换行符):
[.\n]或者(.|\n) - 匹配前面子表达式0次或多次:
[.\n] * - 匹配前面子表达式1次或多次:
[.\n]+或者[.\n]{1,} - 匹配前面子表达式0次或1次:
[.\n]? [...]中括号表示去匹配括号内的任意一个字符,中括号内不需要加 "|" 。- 判断一个表达式中使用的是正则表达式还是通配符,可以看用的是什么命令。例如,“ls” 查看的是文件名,用的就是通配符;“grep” 查看的是文件内容,用的就是正则表达式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号