python2、3字符编码
在python2中有两种字符串类型str和unicode
str类型
当python解释器执行到产生字符串的代码时(例如s='林'),会申请新的内存地址,然后将'林'encode成文件开头指定的编码格式,这已经是encode之后的结果了,所以s只能decode
1 #_*_coding:gbk_*_
2 #!/usr/bin/env python
3
4 x='林'
5 # print x.encode('gbk') #报错
6 print x.decode('gbk') #结果:林
所以很重要的一点是:
在python2中,str就是编码后的结果bytes,str=bytes,所以在python2中,unicode字符编码的结果是str/bytes


#coding:utf-8
s='林' #在执行时,'林'会被以conding:utf-8的形式保存到新的内存空间中
print repr(s) #'\xe6\x9e\x97' 三个Bytes,证明确实是utf-8
print type(s) #<type 'str'>
s.decode('utf-8')
# s.encode('utf-8') #报错,s为编码后的结果bytes,所以只能decode
unicode类型
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
s=u'林'
print repr(s) #u'\u6797'
print type(s) #<type 'unicode'>
# s.decode('utf-8') #报错,s为unicode,所以只能encode
s.encode('utf-8')
打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='林'
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode
对于unicode格式的数据来说,无论怎么打印,都不会乱码
python3中的字符串与python2中的u'字符串',都是unicode,所以无论如何打印都不会乱码
在pycharm中

在windows终端

但是在python2中存在另外一种非unicode的字符串,此时,print x,会按照终端的编码执行x.decode('终端编码'),变成unicode后,再打印,此时终端编码若与文件开头指定的编码不一致,乱码就产生了
在pycharm中(终端编码为utf-8,文件编码为utf-8,不会乱码)
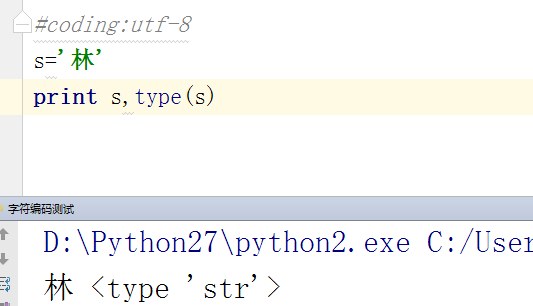
在windows终端(终端编码为gbk,文件编码为utf-8,乱码产生)

在python3 中也有两种字符串类型str和bytes
str是unicode
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s.encode('utf-8')
s.encode('gbk')
print(type(s)) #<class 'str'>
bytes是bytes
#coding:utf-8
s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中,
#s可以直接encode成任意编码格式
s1=s.encode('utf-8')
s2=s.encode('gbk')
print(s) #林
print(s1) #b'\xe6\x9e\x97' 在python3中,是什么就打印什么
print(s2) #b'\xc1\xd6' 同上
print(type(s)) #<class 'str'>
print(type(s1)) #<class 'bytes'>
print(type(s2)) #<class 'bytes'>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号