

计算机系统基础/ICS 笔记
第三章 程序的转换及机器级表示
x86, IA-32, x64 的关系
x86 是 Intel 最早的一批处理器系列,只有 16 位,因为以 86 结尾所以称为 x86。IA-32 是扩展到 32 位的版本,兼容了 x86 的指令。x64 是 64 位版本。
ISA 和 ABI 的关系
CPU 只需要考虑 ISA 规范:ISA(指令集架构)是 CPU 的 “语言规范”(也就是指导电路怎么连接),定义了 CPU 能执行的指令格式、操作、寄存器使用等。比如 x86-64 架构的 CPU,只需要按照 x86-64 的 ISA 规范设计,能识别并执行mov、add等指令即可,不需要关心 ABI。
ABI 是软件层面的规范:ABI(应用程序二进制接口)是给编译器、操作系统、应用程序定的规则,规定了 “二进制程序之间怎么交互”(比如函数传参、内存布局、系统调用方式)。CPU 本身不直接参与 ABI 的实现,而是由软件(编译器、操作系统)遵循 ABI 来生成和运行二进制程序。
寄存器
IA-32 有 8 个通用寄存器,2 个专用寄存器,6 个段寄存器。其中 EAX, EBX, ECX, EDX 属于通用寄存器(General-Purpose Registers, GPRs),他们的低 16 位称为 AX, BX, CX, DX,这是为了兼容 x86 的寄存器。
EFLAGS 属于专用寄存器,叫标志寄存器,其有 32 位。数字系统中的 ZF, CF, OF, SF 在这 32 位中占 4 位。
Intel 格式和 AT&T 格式指令
二者表达相同的语义,但是语法稍有不同。
AT&T 格式特征:
- 寄存器名带%(如%ax、%bx)。
- 指令操作数顺序是 “源在前,目标在后”(比如addw %bx, %ax,是把bx的值加到ax里)。
- 指令后缀表示操作数长度(b字节、w字、l双字,如addw是 “字加法”)。
Intel 格式特征:
- 寄存器名不带%(如ax、bx)。
- 指令操作数顺序是 “目标在前,源在后”(比如add ax, bx,是把bx的值加到ax里)。
解读 AT&T 指令
以 "imull $(-16), (%eax, %ebx, 4), %eax" 为例:
- imull 分为 imul 和 l,表示有符号乘法,32 位;
- (%eax, %ebx, 4) 是内存寻址逻辑,%eax 是基址,%ebx 是变址,4 是比例因子,即找到 %eax + 4 * %ebx 的位置
- %eax 是目的,运算结果存放处
- 用PTR、BYTE等关键字指定操作数长度(如ADD WORD PTR [bx], ax)。
浮点数运算指令
大概了解一下概念,一个是 x87 FPU,另一个是从 SSE 发展出的 MMX 指令集。x87 有 8 个 80 位寄存器,SSE 有 8 个 64 位寄存器(是 x87 的 8 个寄存器的低 64 位),MMX 有另外的 8 个 128 位寄存器。
指令不做要求。
过程调用的机器级表示
ABI 规定:
- eax, ecx, edx 是被调用者可以随意使用的,故调用者如果需要其值需要自己保存好这份环境
- ebx, esi, edi 是被调用者要负责恢复环境的,故被调用者要负责保存并恢复这份环境
这就是模块化的原理,每个模块负责好自己的部分,由 ABI 来统筹每个模块。
题外话,这些寄存器都是有英文名的,记住英文名对于记忆功能有一定用处。
调用过程直接看书就好了,流程挺简单的,分为调用者准备,被调用者执行,调用者恢复现场三个部分。
小细节:栈帧的大小必须是 16 字节的倍数,这是栈帧对齐规则。
小细节:用户栈区是 0xbfffxxxx,只读代码段是 0x8048xxx,全局静态数据区是 0x8049xxx。
选择结构,循环结构的机器表示
都挺简单的,和正常的代码使用 goto 实现版本差不多。
数组元素在内存的存放与访问
数组 a 的地址就是 a[0] 的地址,即 a=&a[0]。而 &a[i]=a+SIZE*i,SIZE 为该类型字节数。
高维数组就是展开成 1 维存放。
结构体元素在内存的存放与访问
在栈中存放和静态内存中存放方法都是类似的。比如结构体有 { int id; char name[20]; },那么就先分配首地址 x,然后 [x, x+4) 是 int id 的,[x+4, x+24) 是 char name 的。按顺序放。
联合体元素在内存的存放与访问
联合体就是共享同一片内存的变量,然后按照最长的那个元素分配内存。
数据对齐
cpu 可以一次读若干个连续的字节,比如 8 个字节 64 位。那么为了高效读写数据,就可以尝试对齐的策略。
比如基础的按自身长度对齐的策略:
- char:无对齐要求(因为长度是 1 字节,任何地址都满足)。
- short(2 字节):地址必须是2 的倍数(如 0x2、0x4、0x6…)。
- int(4 字节)、float(4 字节):地址必须是4 的倍数(如 0x4、0x8、0xC…)。
- double、long long(8 字节):地址必须是8 的倍数(如 0x8、0x10…)。
如果做到这些,那么 cpu 每次读取 [8k, 8k+8) 地址的数据即可。
这个 trade-off 看起来还是很有趣的。
结构体数据对齐就三条核心:
- 整体对齐看最严格的成员(比如有 int、double,就按 double 的要求来);
- 成员存的时候要 “凑位置”,可能中间插空;
- 结构体整体大小得是对齐长度的整数倍,可能末尾插空。
缓冲区溢出攻击
就是在栈里面写出自己的栈帧,比如篡改上一个栈帧的返回地址从而实现攻击,此事在网络攻防实战一课中亦有记载。
x86-64
学累了,不学了。
第四章 程序的链接
难点在于有很多生词,不过就像 pwn 作业一样,碰到生词不需要一下子理解,先定性了解大概即可。
链接的发明是有效且简单的。最开始的程序员使用纸带穿孔的方式写代码,这种代码就是固定不能变化的,例如 jmp 5 这条指令,如果在 5 之前又加入一条指令,则这个 jmp 也要随着改变。这就很不方便。因此使用符号化的方式,jmp LC0,则改变 LC0 并不会导致大规模的程序改变;同时,这种方式还允许了主函数和 LC0 的分开变成,即模块化编程。那么新的问题就是,怎么把不同模块链接起来。
可重定位目标文件的 ELF 头和节表头
一个 ELF 文件的两个部分,但是看不懂。去看了看 b 站的网课,还得是有人教好学一些。
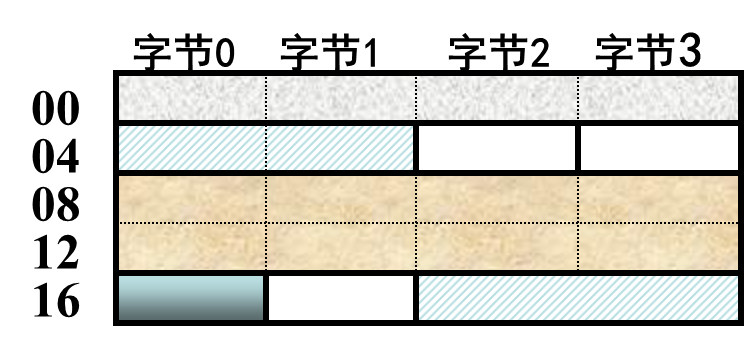
ELF 头一共有 52 个字节,前 16 个字节是 ELF 的魔数,用来标志文件类型,还有一些其它信息(包括节头表的节数,每节长度和起始位置)。
节头表则是每个节为 40 字节,描述了这个节的各种信息,例如起始地址,长度等。
可执行目标文件的程序头表
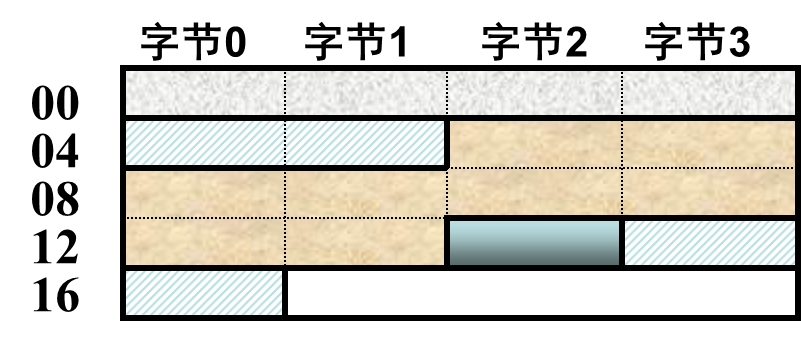
相比于上一种文件,这种文件可以执行,所以多了三个东西:
- e_entry 不为 0,而是第一条指令的地址
- 程序头表,节头表用于描述节,则程序头表用于描述段
- .init 节,用于初始化
少两个重定位节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号