python生成汉字图片字库
最近做文档识别方面的项目,做汉字识别需要建立字库,在网上找了各种OCR,感觉都不好,这方面的技术应该比较成熟了,OCR的软件很多,但没有找到几篇有含金量量的论文,也没有看到哪位大牛公开字库,我用pygame渲染字体来生成字库,也用PIL对整齐的图片进行切割得到字库。
pygame渲染字体来生成字库
用pygame渲染字体我参考的这篇文章,根据GB2323-8标准,汉语中常用字3500个,覆盖了99.7%的使用率,加上次常用共6763个,覆盖99.99%的使用率。先生成一个字体图片,从网上找来3500个常用汉字,对每一个子按字体进行渲染:
1 def pasteWord(word): 2 '''输入一个文字,输出一张包含该文字的图片''' 3 pygame.init() 4 font = pygame.font.Font(os.path.join("./fonts", "a.ttf"), 22) 5 text = word.decode('utf-8') 6 imgName = "E:/dataset/chinesedb/chinese/"+text+".png" 7 paste(text,font,imgName) 8 9 def paste(text,font,imgName,area = (0, -9)): 10 '''根据字体,将一个文字黏贴到图片上,并保存''' 11 im = Image.new("RGB", (32, 32), (255, 255, 255)) 12 rtext = font.render(text, True, (0, 0, 0), (255, 255, 255)) 13 sio = StringIO.StringIO() 14 pygame.image.save(rtext, sio) 15 sio.seek(0) 16 line = Image.open(sio) 17 im.paste(line, area) 18 #im.show() 19 im.save(imgName)
渲染图片次数多总是报错,对于渲染失败的文字我又重试,最终得到了一个包含3510字(加上10个数字)的字库:
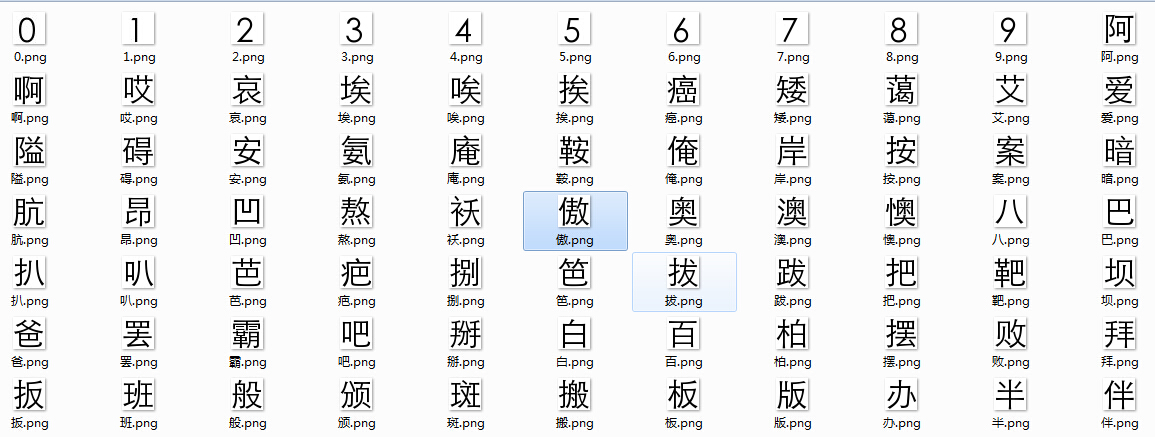
字符分割生成字库
另外一种办法就是把3500个字放在word排好,然后转PDF保存成图片,像下面这样:

密密麻麻的字,但非常整齐,不需要什么图片处理算法,只要找到空白的行和列,按行和列就可以进行切割,切割出来也好,只要保存有序切割,切出来的图片依然可以与字对应,下面是切割的代码:
1 #!encoding=utf-8 2 import Image 3 import os 4 5 def yStart(grey): 6 m,n = grey.size 7 for j in xrange(n): 8 for i in xrange(m): 9 if grey.getpixel((i,j)) == 0: 10 return j 11 def yEnd(grey): 12 m,n = grey.size 13 for j in xrange(n-1,-1,-1): 14 for i in xrange(m): 15 if grey.getpixel((i,j)) == 0: 16 return j 17 18 def xStart(grey): 19 m,n = grey.size 20 for i in xrange(m): 21 for j in xrange(n): 22 if grey.getpixel((i,j)) == 0: 23 return i 24 def xEnd(grey): 25 m,n = grey.size 26 for i in xrange(m-1,-1,-1): 27 for j in xrange(n): 28 if grey.getpixel((i,j)) == 0: 29 return i 30 def xBlank(grey): 31 m,n = grey.size 32 blanks = [] 33 for i in xrange(m): 34 for j in xrange(n): 35 if grey.getpixel((i,j)) == 0: 36 break 37 if j == n-1: 38 blanks.append(i) 39 return blanks 40 41 def yBlank(grey): 42 m,n = grey.size 43 blanks = [] 44 for j in xrange(n): 45 for i in xrange(m): 46 if grey.getpixel((i,j)) == 0: 47 break 48 if i == m-1: 49 blanks.append(j) 50 return blanks 51 52 def getWordsList(): 53 f = open('3500.txt') 54 line = f.read().strip() 55 wordslist = line.split(' ') 56 f.close() 57 return wordslist 58 59 count = 0 60 wordslist = [] 61 def getWordsByBlank(img,path): 62 '''根据行列的空白取图片,效果不错''' 63 global count 64 global wordslist 65 grey = img.split()[0] 66 xblank = xBlank(grey) 67 yblank = yBlank(grey) 68 #连续的空白像素可能不止一个,但我们只保留连续区域的第一个空白像素和最后一个空白像素,作为文字的起点和终点 69 xblank = [xblank[i] for i in xrange(len(xblank)) if i == 0 or i == len(xblank)-1 or not (xblank[i]==xblank[i-1]+1 and xblank[i]==xblank[i+1]-1)] 70 yblank = [yblank[i] for i in xrange(len(yblank)) if i == 0 or i == len(yblank)-1 or not (yblank[i]==yblank[i-1]+1 and yblank[i]==yblank[i+1]-1)] 71 for j in xrange(len(yblank)/2): 72 for i in xrange(len(xblank)/2): 73 area = (xblank[i*2],yblank[j*2],xblank[i*2+1]+32,yblank[j*2]+32)#这里固定字的大小是32个像素 74 #area = (xblank[i*2],yblank[j*2],xblank[i*2+1],yblank[j*2+1]) 75 word = img.crop(area) 76 word.save(path+wordslist[count]+'.png') 77 count += 1 78 if count >= len(wordslist): 79 return 80 81 82 def getWordsFormImg(imgName,path): 83 png = Image.open(imgName,'r') 84 img = png.convert('1') 85 grey = img.split()[0] 86 #先剪出文字区域 87 area = (xStart(grey)-1,yStart(grey)-1,xEnd(grey)+2,yEnd(grey)+2) 88 img = img.crop(area) 89 getWordsByBlank(img,path) 90 91 def getWrods(): 92 global wordslist 93 wordslist = getWordsList() 94 imgs = ["l1.png","l2.png","l3.png"] 95 for img in imgs: 96 getWordsFormImg(img,'words/') 97 98 if __name__ == "__main__": 99 getWrods()
切出来的字的效果也很好的:
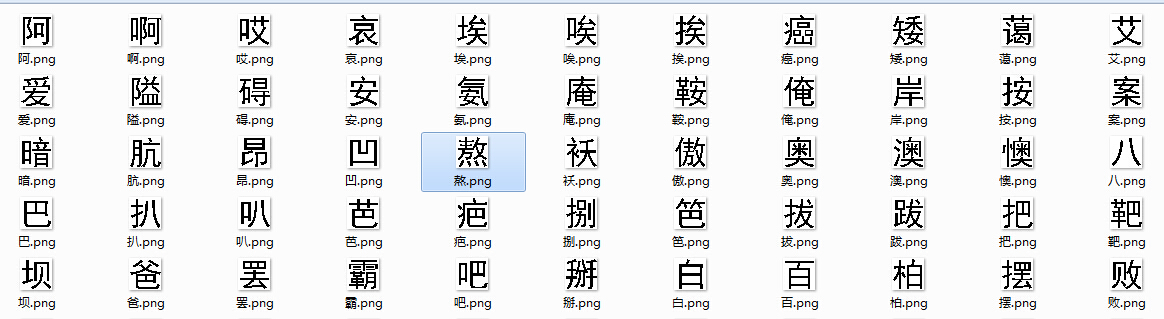
自己对这图像处理本来就不熟悉,用的都是土包子的方法。汉字的识别难度是比较大的,对应整齐的图片,采样DTW对字库求相似项,效果还不错,但用扫描仪、相机拍下来的文章切割处理后,效果很差。我用了BP神经网络,但3500个汉字相当于3500个类,这个超多类别的分类问题,BP也很难应付,主要是训练数据太少,手里只有一份字库。
如果您有什么好的方法识别图片汉字的方法,希望给与我分享,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号