
Python开发:ORM sqlalchemy
本节内容
- ORM介绍
- sqlalchemy安装
- sqlalchemy基本使用
- 多外键关联
- 多对多关系
一、ORM介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
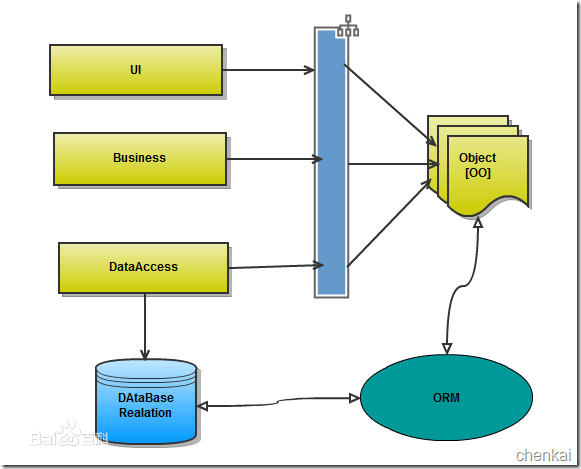
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
二、sqlalchemy安装
在Python中,最有名的ORM框架是SQLAlchemy。用户包括openstack\Dropbox等知名公司或应用,主要用户列表http://www.sqlalchemy.org/organizations.html#openstack
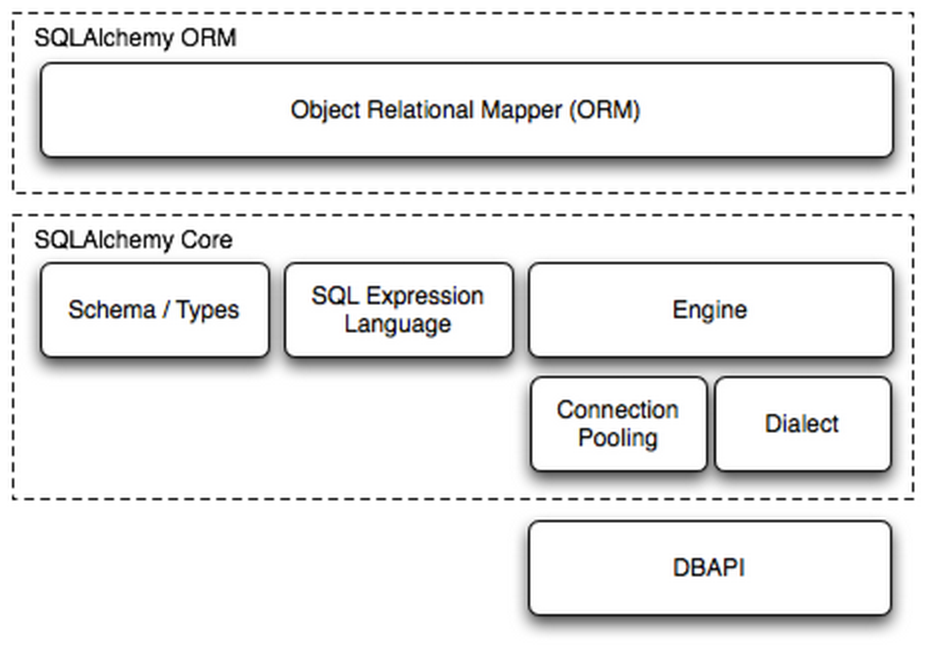
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html |
安装sqlalchemy
pip install SQLAlchemy pip install pymysql #由于mysqldb依然不支持py3,所以这里我们用pymysql与sqlalchemy交互
三、sqlalchemy基本使用
用table创建的方法
from sqlalchemy import Table, MetaData, Column, Integer, String, ForeignKey
from sqlalchemy.orm import mapper
'''metadata 创建表的方式
1、通过MetaData类生成metadata方法
2、通过metadata方法创建表
3、创建表对应的类
4、用mapper关联类和表
'''
metadata = MetaData() #直接创建的表,而不是Base = declarative_base() #生成orm基类
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('password', String(12))
)
class User(object):
def __init__(self, name, fullname, password):
self.name = name
self.fullname = fullname
self.password = password
mapper(User, user)
#the table metadata is created separately with the Table construct,
# then associated with the User class via the mapper() function
#将类和表关联起来
通过ORM的方式创建表,并添加一条数据
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
'''ORM 方式
1、链接数据库
2、创建一个orm基类
3、创建一个表对应的类
4、创建表结构
'''
engine = create_engine("mysql+pymysql://root:123@172.11.2.109/test2",
encoding='utf-8')
#echo=True表示打印数据,如果不写,则不打印
Base = declarative_base() #生成orm基类
class User(Base):
__tablename__ = 'user' #表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64))
#Base.metadata.create_all(engine) #创建表结构
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() #生成session实例
user_obj = User(name="alex",password="alex3714") #生成你要创建的数据对象
print(user_obj.name,user_obj.id) #此时还没创建对象呢,不信你打印一下id发现还是None
Session.add(user_obj) #把要创建的数据对象添加到这个session里, 一会统一创建
print(user_obj.name,user_obj.id) #此时也依然还没创建
Session.commit() #现此才统一提交,创建数据
增删改查
增
#生成一个对象,通过对象添加一条数据
obj = Users(name="alex0", extra='sb')
session.add(obj)
#添加多条数据
session.add_all([
Users(name="alex1", extra='sb'),
Users(name="alex2", extra='sb'),
])
session.commit()
删
#过滤后删除 session.query(Users).filter(Users.id > 2).delete() session.commit()
改
#修改
my_user = Session.query(User).filter_by(name="alex").first() #筛选出对象
my_user.name = "Alex Li" #重新赋值
Session.commit() #提交,只有提交后,数据库才会更新
session.query(Users).filter(Users.id > 2).update({"name" : "099"})
# 直接设置新值
session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + "099"}, synchronize_session=False)
# {Users.name: Users.name + "099"}表示增加增加字符"099",
session.query(Users).filter(Users.id > 2).update({"num": Users.num + 1}, synchronize_session="evaluate")
# 数字相加需要synchronize_session="evaluate"
session.commit()
查——原理讲解
#查询
my_user = Session.query(User).filter_by(name="alex")
print(my_user)
'''my_user为ORM生成的sql语句
SELECT user.id AS user_id, user.name AS user_name, user.password AS user_password
FROM user
WHERE user.name = %(name_1)s
'''
my_user = Session.query(User).filter_by().all()
print(my_user)
'''my_user对象地址
[<__main__.User object at 0x00000000040915C0>,
<__main__.User object at 0x0000000004091630>,
<__main__.User object at 0x00000000040916A0>]
'''
my_user = Session.query(User).filter_by(name="alex").all()
print('all >>',my_user)
print(my_user[0].id,my_user[0].name,my_user[0].password)
'''my_user输出一个列表
all >> [<__main__.User object at 0x0000000004092710>]
输出具体值 1 alex alex3714
'''
my_user = Session.query(User).filter_by(name="alex").first()
print('frist >>',my_user)
'''my_user输出一个对象
frist >> <__main__.User object at 0x0000000004092710>
'''
print(my_user.id,my_user.name,my_user.password)
'''my_user具体的值
1 alex alex3714
如果查询条件是Session.query(User).filter_by(name="alex").all(),则需要循环打印
'''
查——方法列举
obj_1 = session.query(Users).all()
print(obj_1)
#[<id:1,name:alex0>, <id:2,name:alex1>, <id:3,name:alex2>]
# 查看第一个值的方式 print(obj_1[0].id,obj_1[0].name)
obj_2 = session.query(Users.name, Users.extra).all()
print(obj_2)
#直接打印值 [('alex0', 'sb'), ('alex1', 'sb'), ('alex2', 'sb')]
obj_3 = session.query(Users).filter_by(name='alex1').all()
print(obj_3) #条件查找[<id:2,name:alex1>]
obj_4 = session.query(Users).filter_by(extra='sb').first()
print(obj_4) #只显示第一条 <id:1,name:alex0>
回滚
my_user = Session.query(User).filter_by(id=1).first() my_user.name = "Jack" fake_user = User(name='Rain', password='12345') Session.add(fake_user) print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #这时看session里有你刚添加和修改的数据, # 输出为[<__main__.User object at 0x000000000408A278>, <__main__.User object at 0x0000000004028A58>] # 但数据库里查不到 Session.rollback() #此时你rollback一下 print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #再查就发现刚才添加的数据没有了。 # 输出为[] Session Session.commit()
条件查询
obj_2 = session.query(Users).filter(Users.id > 1, Users.extra =='sb').all()
print(obj_2) #[<id:2,name:alex1>, <id:3,name:alex2>]
obj_3 = session.query(Users).filter(Users.id.between(1, 3), Users.extra =='sb').all()
print(obj_3) #[<id:1,name:alex0>, <id:2,name:alex1>, <id:3,name:alex2>]
obj_4 = session.query(Users).filter(Users.id.in_([1,3])).all()
print(obj_4) #id等于1,3的[<id:1,name:alex0>, <id:3,name:alex2>]
obj_5 = session.query(Users).filter(~Users.id.in_([1,3])).all()
print(obj_5) #id不等于1,3的[<id:2,name:alex1>]
obj_6 = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='alex0'))).all()
print(obj_6) #嵌套过滤[<id:1,name:alex0>]
from sqlalchemy import and_, or_
obj_7 = session.query(Users).filter(and_(Users.id > 3, Users.extra =='sb')).all()
print(obj_7) #[]
obj_8 = session.query(Users).filter(or_(Users.id < 2, Users.extra =='sb')).all()
print(obj_8) #[<id:1,name:alex0>, <id:2,name:alex1>, <id:3,name:alex2>]
obj_9 = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.extra =='sb', Users.id < 3),
Users.extra != ""
)).all()
print(obj_9) #[<id:1,name:alex0>, <id:2,name:alex1>, <id:3,name:alex2>]
(Users.extra =='sb', Users.id < 3) #先and查找,然后再or查询
通配符
obj_1 = session.query(Users).filter(Users.name.like('e%')).all()
print(obj_1) #[]
obj_2 = session.query(Users).filter(~Users.name.like('e%')).all()
print(obj_2) #[<id:1,name:alex0>, <id:2,name:alex1>, <id:3,name:alex2>]
限制
obj_1 = session.query(Users)[0:1] print(obj_1) #打印第2个元素,[<id:1,name:alex0>] obj_2 = session.query(Users)[1:2] print(obj_2) #打印第2个元素,[<id:2,name:alex1>]
排序
obj_1 = session.query(Users).order_by(Users.name.desc()).all() obj_2 = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() print(obj_1) #按名称倒叙 [<id:3,name:alex2>, <id:2,name:alex1>, <id:1,name:alex0>] print(obj_2) #先按Users.name.desc()排序,如果相同则按Users.id.asc()排序 [<id:3,name:alex2>, <id:2,name:alex1>, <id:1,name:alex0>]
分组
from sqlalchemy.sql import func
obj_1 = session.query(Users).group_by(Users.extra).all()
obj_2 = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
obj_3 = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
#group_by配合having进行过滤
print(obj_1) #基于(Users.extra)进行分组 [<id:1,name:alex0>]
print(obj_2) #[(1, Decimal('1'), 1), (2, Decimal('2'), 2), (3, Decimal('3'), 3)]
print(obj_3) #[(3, Decimal('3'), 3)]
连表
obj_1 = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
obj_2 = session.query(Person.name).join(Favor).all()
obj_3 = session.query(Person.name).join(Favor, isouter=True).all()
print(obj_1) #通过类的方式,查询两个表,这里没有外键,所以没有join[(<id:1,name:alex0>, 1-girl), (<id:2,name:alex1>, 2-meat), (<id:3,name:alex2>, 3-money)]
print(obj_2) #通过外键的方式,生成sql语句,进行链表查询。ORM会自己根据外键查找关系[('alex',), ('alex',), ('jack',), ('jack',)]
print(obj_3) #isouter=True表示外键left join的方式,如果不加,默认是inner join方式[('alex',), ('alex',), ('jack',), ('jack',)]
组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
obj_1 = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
obj_2 = q1.union_all(q2).all()
#union会去重,union_all不会去重
print(obj_1) #[('alex2',), ('girl',)]
print(obj_2) #[('alex2',), ('girl',)]
外键关联
创建表并插入数据
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,DATE
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
'''创建表'''
engine = create_engine("mysql+pymysql://root:123@172.11.2.109/test2",encoding='utf-8')
#echo=True表示打印数据,如果不写,则不打印
Base = declarative_base() #生成orm基类
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(32), nullable=False)
register = Column(DATE, nullable=False)
def __repr__(self):
return "<%s name:%s>" % (self.id,self.name)
class StudyRecord(Base):
__tablename__ = 'study_record'
id = Column(Integer,primary_key=True)
day = Column(Integer,nullable=False)
status = Column(String(32),nullable=False)
stu_id = Column(Integer,ForeignKey('student.id'))
student = relationship("Student",backref='my_study_record')
#这个nb,允许你在student表里通过backref字段反向查出所有它在StudyRecord表里的关联项
#student实例指向Student类,数据库里没有student字段
#my_study_record实例指向StudyRecord类,my_study_record相当于Student类里虚拟的实例
def __repr__(self):
return "<%s day:%s status:%s>" % (self.student.name,self.day,self.status)
Base.metadata.create_all(engine) #创建表结构
'''插入数据'''
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=engine)
session = Session_class()
s1 = Student(name = 'alex',register = '2016-04-13')
s2 = Student(name = 'jack',register = '2016-03-13')
s3 = Student(name = 'pert',register = '2016-04-23')
s4 = Student(name = 'rain',register = '2016-05-13')
study_obj1 = StudyRecord(day = 1,status='YES',stu_id=1)
study_obj2 = StudyRecord(day = 2,status='YES',stu_id=1)
study_obj3 = StudyRecord(day = 3,status='YES',stu_id=1)
study_obj4 = StudyRecord(day = 4,status='YES',stu_id=2)
session.add_all([s1,s2,s3,s4,study_obj1,study_obj2,study_obj3,study_obj4]) #添加数据
session.commit() #提交
查询
stu_obj = session.query(Student).filter(Student.name == 'alex').first() print(stu_obj) ''' 输出结果 <1 name:alex> '''
print(stu_obj.my_study_record)
'''
输出结果
[<alex day:1 status:YES>, <alex day:2 status:YES>, <alex day:3 status:YES>]
'''
多外键关联
下表中,Customer表有2个字段都关联了Address表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from sqlalchemy import Integer, ForeignKey, String, Columnfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy.orm import relationshipBase = declarative_base()class Customer(Base): __tablename__ = 'customer' id = Column(Integer, primary_key=True) name = Column(String) billing_address_id = Column(Integer, ForeignKey("address.id")) shipping_address_id = Column(Integer, ForeignKey("address.id")) billing_address = relationship("Address") shipping_address = relationship("Address")class Address(Base): __tablename__ = 'address' id = Column(Integer, primary_key=True) street = Column(String) city = Column(String) state = Column(String) |
创建表结构是没有问题的,但你Address表中插入数据时会报下面的错
|
1
2
3
4
5
6
|
sqlalchemy.exc.AmbiguousForeignKeysError: Could not determine joincondition between parent/child tables on relationshipCustomer.billing_address - there are multiple foreign keypaths linking the tables. Specify the 'foreign_keys' argument,providing a list of those columns which should becounted as containing a foreign key reference to the parent table. |
解决办法如下
|
1
2
3
4
5
6
7
8
9
10
|
class Customer(Base): __tablename__ = 'customer' id = Column(Integer, primary_key=True) name = Column(String) billing_address_id = Column(Integer, ForeignKey("address.id")) shipping_address_id = Column(Integer, ForeignKey("address.id")) billing_address = relationship("Address", foreign_keys=[billing_address_id]) shipping_address = relationship("Address", foreign_keys=[shipping_address_id]) |
这样sqlachemy就能分清哪个外键是对应哪个字段了
多对多关系
现在来设计一个能描述“图书”与“作者”的关系的表结构,需求是
- 一本书可以有好几个作者一起出版
- 一个作者可以写好几本书
此时你会发现,用之前学的外键好像没办法实现上面的需求了,因为

当然你更不可以像下面这样干,因为这样就你就相当于有多条书的记录了,太low b了,改书名还得都改。。。

那怎么办呢? 此时,我们可以再搞出一张中间表,就可以了

这样就相当于通过book_m2m_author表完成了book表和author表之前的多对多关联
用orm如何表示呢?
#一本书可以有多个作者,一个作者又可以出版多本书
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
#链接数据库
engine = create_engine('mysql+pymysql://root:123@172.11.2.109/test2?charset=utf8', max_overflow=5)
#创建基类
Base = declarative_base()
#定义类(表)
'''
第三张表,不用访问,所以用Table的方式创建
这里也不用自增id
通过Base.metadata方法创建表
'''
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
#通过第3张表连接,secondary=book_m2m_author指向第三张关系表
#注意:secondary=book_m2m_author这块是表名,而不是类名
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
Base.metadata.create_all(engine) #创建表结构
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
b1 = Book(name = 'learn python with alex',pub_date = "2015-04-26")
b2 = Book(name = 'learn zhuangbility with alex',pub_date = "2016-04-26")
b3 = Book(name = '跟alex学撩妹',pub_date = "2015-07-26")
a1 = Author(name='alex')
a2 = Author(name='jack')
a3 = Author(name='rain')
session.add_all([a1,a2,a3,b1,b2,b3])
#通过实例关联两张表
#先创建对象session.add_all([a1,a2,a3,b1,b2,b3]),再做关联,否则对应表有误
b3.authors=[a1,a2,a3]
b1.authors=[a1,a3]
session.commit()
删除
#删除 ''' 多对多删除 删除数据时不用管boo_m2m_authors , sqlalchemy会自动帮你把对应的数据删除 ''' # 通过书删除作者(删除一条关联) author_obj =session.query(Author).filter_by(name="Jack").first() book_obj = session.query(Book).filter_by(name="跟Alex学把妹").first() book_obj.authors.remove(author_obj) #从一本书里删除一个作者,这里是通过类删除 session.commit() # 直接删除作者 (删除表里的一条信息,关联表里的数据会自动删除) # 删除作者时,会把这个作者跟所有书的关联关系数据也自动删除 author_obj =session.query(Author).filter_by(name="Alex").first() # print(author_obj.name , author_obj.books) session.delete(author_obj) #这里是数据库操作 session.commit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号