大三寒假学习 spark学习 第一个spark应用程序WorldCount
在spark-shell进行词频统计:
flatMap将每一行按空格才分成为单词,map映射生成键值对,将单词计数,reduceByKey将相同单词叠加
wordCount.collect()将结果汇集,针对集群
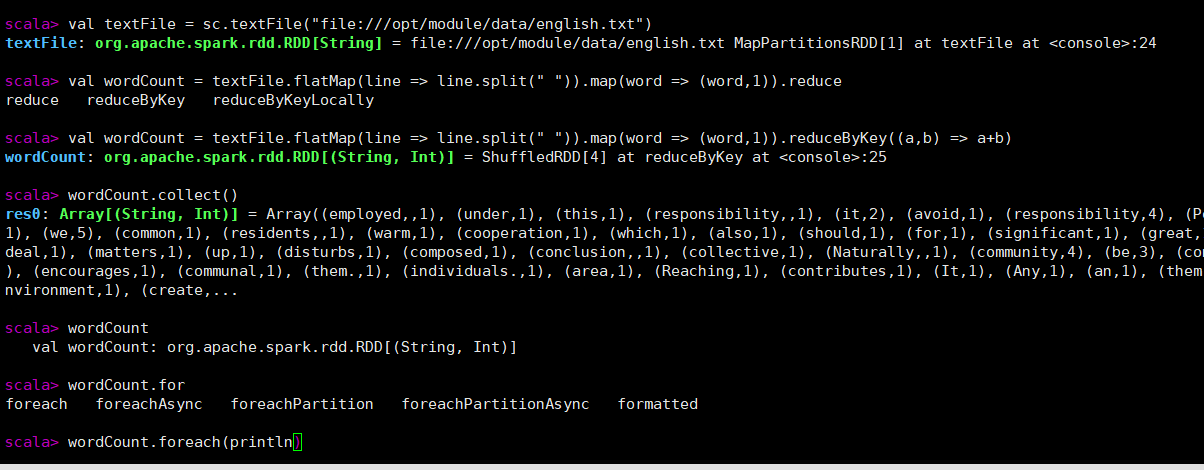
结果:
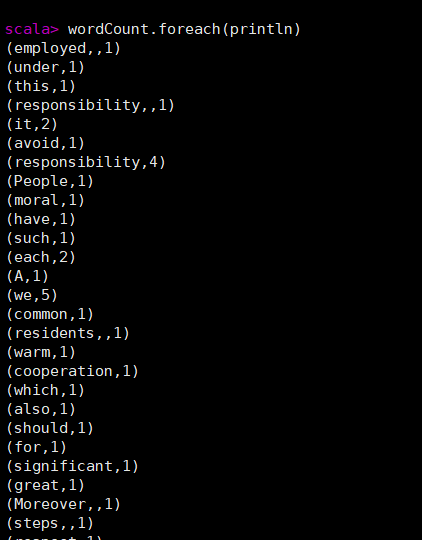
编写独立程序进行词频统计:
新建wordCount.scala写入以下代码
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object WordCount{ def main(args:Array[String]){ val inputFile = "file:///opt/module/data/english.txt" val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]") val sc = new SparkContext(conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a+b) wordCount.foreach(println) } }
打包:/opt/module/sbt/sbt package

spark-submit提交:/opt/module/spark-3.1.2/bin/spark-submit --class "WordCount" /opt/module/sbt/mycode/target/scala-2.12/simple-project_2.12-1.0.jar
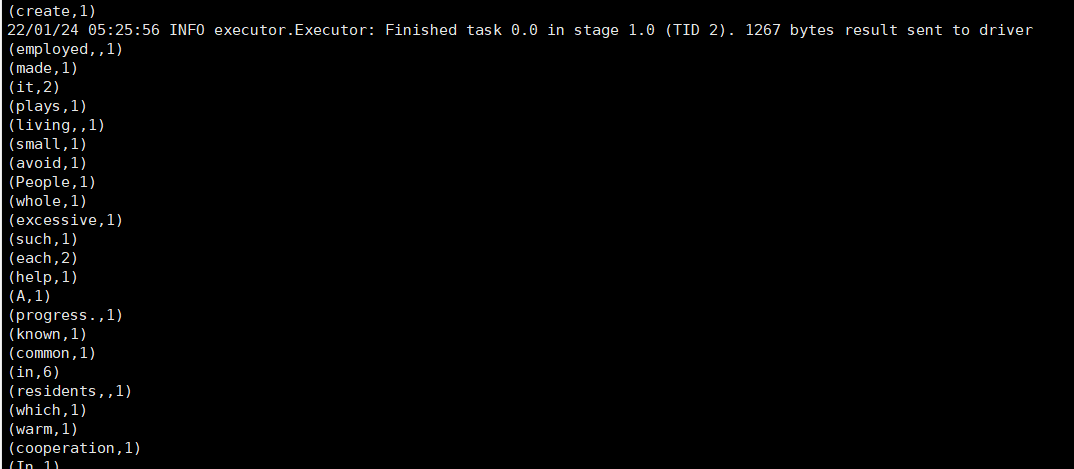
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号