大数据测试
1 导入数据
tmdb_5000_movies="static/data/tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
#显示宽度
pd.set_option('display.width', None)
df_tmdb_5000_movies = pd.read_csv(tmdb_5000_movies)
print(df_tmdb_5000_movies.head(3))

2 缺失值处理 缺失记录仅________条,采取网上搜索,补全信息。
2.1 补全 release_date
print(df_tmdb_5000_movies[df_tmdb_5000_movies['release_date']!=df_tmdb_5000_movies['release_date']])#输出指定列为控制的行
#利用任何两个控制都不相等

缺失记录的电影标题为《America Is Still the Place》,日期为__ 2014-06-01__。
2.2 补全 runtime
print(df_tmdb_5000_movies[df_tmdb_5000_movies['runtime']!=df_tmdb_5000_movies['runtime']])#输出指定列为控制的行

缺失记录的电影 runtime 分别为_______min 和 _______min。
Chiamatemi Francesco - Il Papa della gente 94.0
To Be Frank, Sinatra at 100 81.0
3 重复值处理
print(df_tmdb_5000_movies['id'].drop_duplicates())

运行结果:有___4803__个不重复的 id,可以认为没有重复数据。
4 日期值处理
将 release_date 列转换为日期类型:
#df_tmdb_5000_movies['release_date'] = df_tmdb_5000_movies['release_date'].apply(lambda x: time.mktime(time.strptime(x, '%Y-%m-%d')))
#有比1970年小的年份,无法使用time.mktime转换
5 筛选数据
使用数据分析师最喜欢的一个语法:
评分人数vote_count
票房revenue、预算budget、受欢迎程度popularity、评分vote_average为___0__的数据应该去除;
评分人数过低的电影,评分不具有统计意义,筛选评分人数大于__100___的数据。
此时剩余______条数据,包含______个字段。
先对平分列进行一个简单的统计:
print(df_tmdb_5000_movies['vote_average'].describe())z
在对评论人数进行简单统计
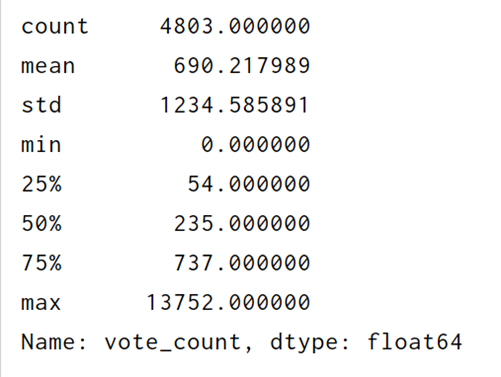
print(df_tmdb_5000_movies['vote_count'].describe())
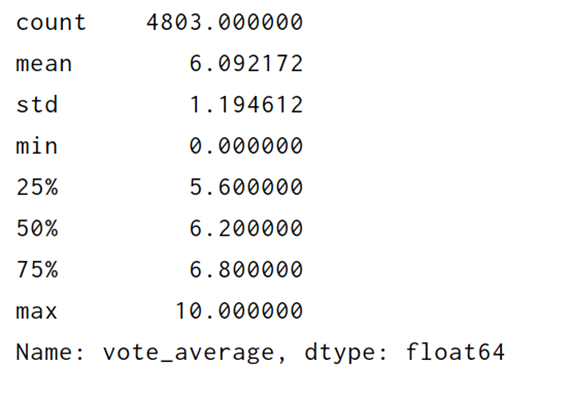
取100人小于100的去掉
print(df_tmdb_5000_movies[df_tmdb_5000_movies['vote_count']>=100].shape)
票房revenue、预算budget、受欢迎程度popularity、评分vote_average为___0__的数据应该去除;
print(df_tmdb_5000_movies['revenue'].describe())#票房
print(df_tmdb_5000_movies['budget'].describe())#预算
print(df_tmdb_5000_movies['popularity'].describe())#受欢迎程度
print(df_tmdb_5000_movies['vote_average'].describe())#评分的描述
print(df_tmdb_5000_movies['vote_count'].describe())#评论人数的描述
df_tmdb_5000_movies_vote=df_tmdb_5000_movies[df_tmdb_5000_movies['vote_count'] >= 100]#评论人数小于100的去掉
print(df_tmdb_5000_movies_vote.shape)
df_tmdb_5000_movies_vote_0=df_tmdb_5000_movies_vote[df_tmdb_5000_movies_vote['revenue']>0]
print(df_tmdb_5000_movies_vote_0.shape)
df_tmdb_5000_movies_vote_0 = df_tmdb_5000_movies_vote_0[df_tmdb_5000_movies_vote_0['budget'] > 0]
print(df_tmdb_5000_movies_vote_0.shape)
df_tmdb_5000_movies_vote_0 = df_tmdb_5000_movies_vote_0[df_tmdb_5000_movies_vote_0['popularity'] > 0]
print(df_tmdb_5000_movies_vote_0.shape)
df_tmdb_5000_movies_vote_0 = df_tmdb_5000_movies_vote_0[df_tmdb_5000_movies_vote_0['vote_average'] > 0]
print(df_tmdb_5000_movies_vote_0.shape)
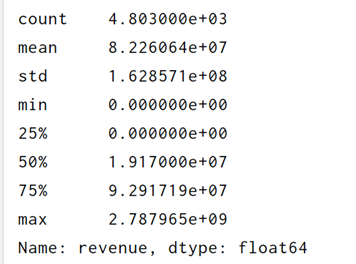

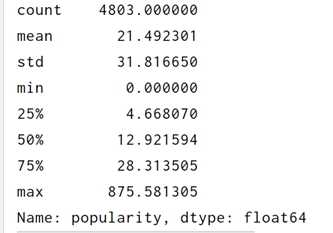

最后剩下2715条
6 json 数据转换 **说明:
genres,
keywords,
production_
companies,
production_countries,
cast,crew
这 6 列都是 json 数据,需要处理为列表进行分析。 处理方法: json 本身为字符串类型,先转换为字典列表,再将字典列表转换为,以’,'分割的字符串
Genres
Keywords
production_companies
production_countries
spoken_languages
只有这几个是json字符串的格式
先将字符转换为字典,在取name属性进行拼接。
def to_str(key,df_tmdb_5000_movies_vote_0):
str_list=[]
for i in range(num):
dictionary=eval(df_tmdb_5000_movies_vote_0[key].iloc[i])#eval将字符串转换为字典
str=""
for j in dictionary:
str=str+j["name"]+","
str_list.append(str)
df_tmdb_5000_movies_vote_0[key]=str_list
pass
print(df_tmdb_5000_movies_vote_0[key].head(10))
to_str('genres', df_tmdb_5000_movies_vote_0)
to_str('keywords', df_tmdb_5000_movies_vote_0)
to_str('production_companies', df_tmdb_5000_movies_vote_0)
to_str('production_countries', df_tmdb_5000_movies_vote_0)
to_str('spoken_languages', df_tmdb_5000_movies_vote_0)
print(df_tmdb_5000_movies_vote_0.head(10))





可以看到这几个属性已经变为字符串以逗号分隔了



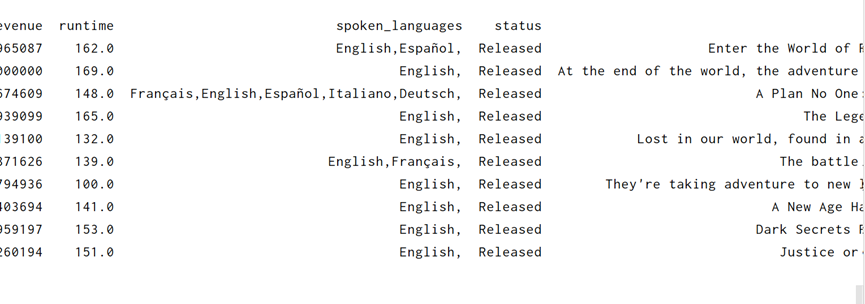
7 数据备份
保存为csv一份,数据库一份
df_tmdb_5000_movies_vote_0.to_csv('clean_df_tmdb_5000_movies.csv')

将csv导入到数据库,利用之前的大作业导入

 浙公网安备 33010602011771号
浙公网安备 33010602011771号