

Python编程基础
- format输出
1 按顺序输出
2 print('{}and{}'.format('hello',25)) #先输出hello后输出25
3 不按顺序输出
4 print('{1}and{0}'.format('hello',25)) #先输出25后输出hello
5 按照键值对输出
6 print('网站是{name},网址是{url}'.format(name='新闻网',url='www.news.com'))
7 输出浮点数
8 print('{:.2f}'.format(3.1415926)) #输出小数点后两位
9 使用f关键字输出
10 print(f'我今年{25}岁')
- 格式符输出
1 输出整数
2 print('我今年%d岁' %(25))
3 print('我今年%5d岁' %(25)) #指定输出字符宽度为5个字符数
4 输出字符串
5 print('我叫%s' %('张三'))
6 输出浮点数
7 print('我的存款是%.2f' %(123.345)) #输出小数点后两位
- math模块
1 math.ceil(3.14) #输出大于等于3.14的最小整数4 2 math.ceil(-3.14) #输出大于等于3.14的最小整数-3 3 math.floor(3.14) #输出小于等于3.14的最大整数3 4 math.floor(-3.14) #输出小于等于3.14的最小整数-4 5 math.fabs(-6) #输出绝对值,输出类型为浮点数6.0 6 math.fsum([1,2,3,4]) #输出可迭代对象的数值集合,输出也是浮点型10.0 7 math.pow(8,3) #幂运算,输出8的3次方512.0 8 math.sqrt(5) #开方运算,输出也是浮点数。
- Random模块
1 random.random() #从[0,1)之间选出一个浮点数,可以是0.0,但不可以是1.0 2 random.uniform(2,4) #从[2,4]之间选出一个浮点数 3 random.randint(2,4) #从[2,4]之间选出一个整数 4 random.randrange(2,4) #从[2,4)之间选出一个整数 5 random.choice([1,2,3,4,5]) #从列表中任选出一个数 6 random.sample([1,2,3,4,5],3) #从列表中任选出3个整数 7 random.shuffle([1,2,3,4,5]) #将列表打乱后再输出
- 字符串
print('this is a dag.\n that is a apple') #换行输出,因为有转义字符\n
print('this is a dog.\\n that is a apple') #不换行输出
print(r'this is a dog. that is a apple') #和上句效果相同
s = '欢迎大家学习python课程'
print(s[:]) #输出全部字符
print(s[0:5]) #输出从0位置开始到(5-1)位置的字符
print(s[:5]) #输出从开始位置到(5-1)位置的字符
print(s[0:]) #输出从0位置到结尾的字符
print(s[::-1]) #反向输出全部字符
print(s[-3:-9:-1]) #反向输出python字符
#字符串常用函数
len(s) #获取字符串s的长度
'hello'.capitalize() #字符串第一个字母置为大写
s.count('a') #统计字符串s中a字符的个数。如果有,返回个数,否则,返回0
s.find('a') #找出a第一次出现的位置。没找到,则返回-1
s.index('a') #找出a第一次出现的位置。没找到,抛出异常。
s.replace('a','b',n) #用b替换a。a有多个位置,替换n次。
s.split('a') #使用a分割字符串
s.isdigit() #判断s是否全部都是数字
s.islower() #判断s中是否包含至少一个小写字符
s.lower() #将s中大写字符全部转为小写
s.upper() #将s中小写字符全部转为大写
s.startswith('#') #判断s是否以#开头
s.endswith('#') #判断s是否以#结束
s.strip('#') #删除字符串中两边#字符
s.strip() #删除字符串两边空格字符
s.lstrip() #删除字符串左边指定字符
s.rstrip() #删除字符串右边指定字符
- 列表
列表特性
列表是一个真正的容器,可以容纳所有的数据类型,包括整型,字符型,字符串,列表,元组,集合,字典;列表中的元素又唯一的顺序;列表中的元素可以修改;
a = [1,2,3,4]
print(len(a)) #输出列表的长度
print(max(a)) #输出列表中的最大元素。列表只能是数值型,否则会报错
print(min(a)) #输出列表中的最小元素。
print(1 in a) #输出1是否在列表a中,输出值为布尔型
for i in a #循环输出a中的元素
print(i)
a.insert(2,''hello) #在指定的位置2处插入一个元素
a.append('hello') #在列表末尾插入一个元素
a.pop(2) #删除位置2处的元素
a.remove(2) #删除列表中元素值为2的元素
a.clear() #清除列表中所有元素
del a #清除列表a的空间,彻底删除
a.reverse() #将列表a逆序
a.sort() #将列表从小到大排序
a.sort(reverse=true) #将列表逆序
a = [1,2,3,'4','8',7]
a.sort(key=lambda x: int(x)) #强制类型转换列表中元素后,再排序
a.count(1) #列表中1元素的个数
a.index(1) #列表中元素1首次出现的索引位置
b = [1,'world',[1,2,3],{'name':'frank'}]
a+b #合并两个列表,形成一个新列表
a.extend(b) #合并两个列表,在a列表后添加b列表元素
a=b #将列表a的引用赋给b,修改a后,列表b也会改变
b=a.copy() #将列表a的值赋给b,修改a后,列表b不发生改变
- 元组
a=(1,2,3)
元组中元素无法修改。
len(a),max(a),min(a)都成立
a.count(1) #找到元素1出现的次数
a.index(1) #找到元素1的索引位置
a[:] #切片操作,可以取到元组中所有元素
a=(1,) #只有一个元素的元组必须带有逗号
- 集合
集合使用{}定义,集合中元素无序,不可重复。
a={1,2,3}
a.add(4) #向集合中增加一个元素4
a.remove(3) #删除集合中元素3
a.clear() #释放集合空间
b=(1,2,3)
b=[1,2,3]
b='hello'
set(b) #均可强制类型转换b成集合
集合满足数学中的并,交,差,非对称差的运算
- 字典
字典采用键值对{key:value}来存储数据
dic={'name':'张三','age':'23'}
dic['sex']='M' #向字典中新增一个键值对
del dic['sex'] #删除字典中的键值对
dic.pop('hello',not seist) #根据键删除字典中值。若键不存在,参数赋值not exist,也会返回not exist
dic.popitem() #从末尾删除键值对
dic.clear() #删除字典空间
dic['sex']='F' #修改字典中键值对
dict={'name':'李四','city':'西安'}
dic.update(dict) #把dict元素增加到dic中,重复元素覆盖掉。
dic.get('sex') #获取字典中键对应的值。若字典中键不存在,则返回None
dic.setdefault('sex') #获取对应键的值。若键不存在,则会将此键添加到字典中。而get方法不会添加
print(dic['sex']) #获取字典中键对应的值
for key in dict.keys(): #输出字典中键
print(key)
for value in dict.values(): #输出字典中值
print(value)
for k,v in dic.items(): #以键值对的形式输出字典元素
print(k,v)
for item in dic.items(): #以元组的形式输出字典元素
print(item)
print(len(dic)) #获取字典长度
a=['name','sex','age']
dict.formkeys(a) #将列表a转为一个字典
dic1=dic.copy() #将字典dic做为一个整体都赋给dic1,对dic做出修改,dic1不发生变化。
dic={'name':'张三','age':'23','count':[1,2,3]}
dic['count'].append(4) #做此操作后,dic1也会发生改变
- Python文件读写
with open(url='',mode='') #使用with open语句可以不用手动关闭文件
文件打开方式,mode取值情况
r:只读,不主动创造文件,从文件开头开始读
r+:读写,不主动创造文件,从文件开头开始读写
w:只写,主动创造文件,清空以前内容,从文件开头开始写
w+:读写,主动创造文件,清空以前内容,从文件开头开始读写
a:只写,主动创造文件,不请客以前内容,从文件末尾开始写
a+:读写,主动创造文件,不清空以前内容,从文件末尾开始读写
对于二进制文件,只需在以上六种模式后,加上字母b即可,变为rb,rb+,wb,wb+,ab,ab+。
- 魔法方法
__repr__方法,返回对象的内存地址
class student:
def __repr__(self):
stu=student()
print(stu) #返回对象内存地址,类中没有__repr__方法。
print(stu.__repr__()) #返回对象内存地址,类中有__repr__方法
__del__方法将类实例化后,如果没有其他操作,会执行该方法。
class student():
def __init__(self,name):
self.name=name
def __del__(self):
print('del方法被调用')
stu=student('张三',24) #初始化实例后,没有其他操作会执行del方法
del stu #删除对象,执行del方法
print('--------') #删除对象后,执行该语句。
#Python提供自动引用计数器,如果发现引用不为0,则不会执行del方法
a=stu
del stu #这种情况,将stu赋给a,删除stu,先执行下一句,再删除对象
print('------------')
__new__方法,创建一个对象实例
class student:
def __new__(cls,*args,**kwargs):
print('执行new方法')
return object.__new__(cls) #返回一个传递到init方法的实例对象
def __init(self): #self属性就是从new方法中传递过来
print('执行init方法')
stu=student() #初始化实例
使用new方法可以完成一些类型转换的操作
class newInt(int): #类型转换的函数
def __new__(cls,value):
return int.__new__(cls,abs(value)) #完成类型转换
a=newInt(-4.89) #使用该方法创建类
print(a) #输出a后为4
单例模式创建对象,在一次创建对象时完成,以后,每次创建的对象依然是第一次创建的对象。
class student:
__isinstance=False
def __new__(cls): #创建对象
if not __isinstance:
cls.__isinstance=object.__new__(cls)
return cls.__isinstance #返回第一个创建的对象
def __init__(self,name):
self.name=name
s1=student('张三')
s2=student('李四')
print(s1) #返回两个对象的内存地址相同,说明创建的是单例对象
print(s2)
dir(对象或类)方法。
- 查看对象的所有属性和方法,会进行处理,以一个列表的形式出现。
- 查看类的属性时,不会出现对象的有关属性
__dir__()方法。显示对象的所有属性,包括一些私有属性。_student__age即是通过该方法显示的私有属性。student为类名。age为私有属性名。
__dict__方法,作用于对象时,会查看该对象的所有属性和值。作用于类时,会查看类的所有方法和共享属性。
使用__dict__方法可动态设置对象中没有的属性。
class stu:
def __init__(self,name):
self.name=name
s=stu('张三')
print(s.__dict__) #查看s的所有属性
s.__dict['id']=89 #设置对象s的属性id
print(s.id) #设置属性后,再查看属性
__getattribute__方法在对象访问任意属性时自动调用。
class student(): #定义类
def __init__(self,name,age):
self.name=name
self.age=age
def __getattribute(self,item): #重写魔法方法
try:
return super().__getattribute_(item) #返回一个属性
except Exception as e:
print('异常类型是',e)
return 'default' #对对象中不存在的属性返回一个默认值
stu=student('张三',24)
stu.name #访问对象属性就会调用__getattribute__方法
stu.age
print(stu.name) #输出属性名称会使用__getattribute__方法中的返回值
print(stu.age)
stu.xxx #xxx属性不存在于stu对象中,使用异常处理机制依然能够处理,返回默认值
__getattr__方法适用于对象中没有的属性。如果使用__getattribute__方法获取没有定义的属性,且没有进行一场处理时,就会触发这个方法。
__setattr__方法用来设置对象中没有设置的属性。
class student():
def __init__(self,name):
self.name=name
def __setattr__(self,key,value): #定义没有设置的属性
if key=='age': #设置年龄属性
if value<18:
raise Exception('年龄属性应该大于18')
else:
self.__dict__[key]=value
else:
self.__dict__[key]=value
def __delattr__(self,item):
pass
stu=student('张三')
stu.age=19 #设置年龄属性为19,调用__setattr__方法
print(stu.age) #输出年龄属性19
del stu.age #删除年龄属性,调用__detattr__方法
反射。根据用户的输入来动态执行对象的各种方法。提高了程序的灵活性。
class dog():
def __init__(self,name):
self.name=name
def eat(self):
print('{}正在吃'.format(self.name))
def sleep(self):
print('{}正在睡'.format(self.name))
d=dog('二哈')
choice=input('请输入选择') #根据用户输入执行操作
if hasattr(d,choice):
try:
func=getattr(d,choice) #根据输入返回输入对应的方法
func() #执行这个方法
except Exception as e:
print(getattr(d,choice)) #如果输入的是属性名称,输出属性值
else:
print('您的输入有误')
使用反射可以动态添加对象方法和属性
class dog():
def __init__(self,name):
self.name=name
def eat(self):
print('{}正在吃'.format(self.name))
def sleep(self):
print('{}正在睡'.format(self.name))
d=dog('二哈')
attr=input('请输入属性名')
value=input('请输入属性值')
if value.isdigit():
setattr(d,attr,int(value))
else:
setattr(d,attr,value) #动态定义属性值
if hasattr(d,attr): #判断增加属性后,是否出现
print(getattr(d,attr)) #输出新增的属性值
def talk():
print('二哈汪汪汪...')
method=input('请输入新增的方法名')
setattr(d,method,talk) #将新定义的方法增加到对象中
getattr(d,attr)() #执行新增的方法
- 为什么需要使用异常?
使用if作为错误处理机制时,无法穷举所有的异常情况,而且在处理异常时处理代码和业务代码混合在一起,严重影响程序的可读性。

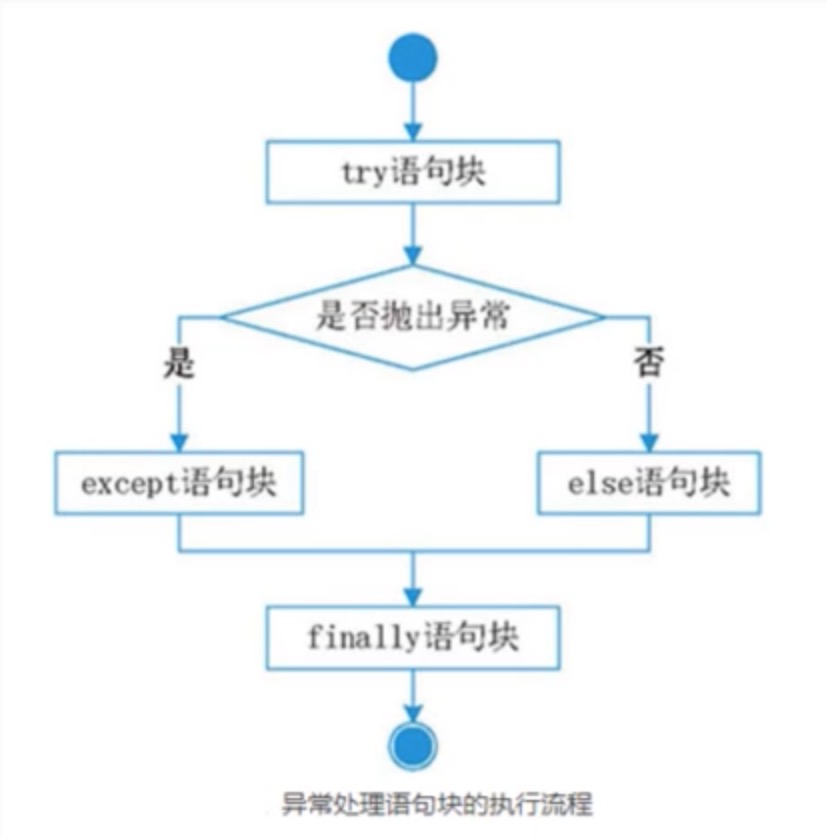
使用raise语句自动引发异常。如果raise语句在try中,则会抛出RuntimeError异常。如果raise在exception语句中,则会将exception中的异常抛出。
- Python网络编程TCP,UDP网络编程,不管是使用TCP还是UDP,都有socket程序包。
server = socket.socket(socket.AF_INET,socket.SOCK_STEWAM) #建立服务器套接字对象,第二个参数表示使用TCP
server.bind(('127.0.0.1',8000)) #建立的套接字对象绑定服务器主机和端口
server.listen() #由于TCP是基于连接的协议,所以需要使用监听
sock, addr = server.accept() #服务器接受来自客户端的连接
data = sock.recv(1024) #服务器接受到客户端发送的消息
sock.send('hello client'.encode()) #服务器向客户端发送消息
server.close() #服务器关闭连接
sock.close() #连接对象关闭
client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #建立客户端套接字对象
client.connect(('127.0.0.1',8000)) #建立的套接字对象连接到服务器上
client.send('hello server'.encode()) #客户端向服务器发送信息
client.recv(1024) #客户端收到服务器发送的消息
client.close() #通信结束后,关闭客户端的连接
server = socket.socket(socket.AF_INET,socket.SOCK_DGRAM) #建立服务器套接字对象,第二个参数表示使用UDP协议
server.bind(('127.0.0.1',8000)) #建立的服务器套接字对象绑定相应的地址和端口
data,addr=server.recvfrom(1024) #由于传输层使用UDP协议,所以不需要监听,只是在接收信息时收到客户端的地址和信息
server.sendto('hello client'.encode(),addr) #根据收到的客户端地址,再发送信息
server.close() #通信结束,关闭服务器对象
client = socket.socket(socket.AF_INET,socket.SOCK_DGRAM) #建立客户端套接字对象
client.sendto('hello server'.encode(),('127.0.0.1',8000)) #客户端不需要连接到服务器,只需在发送信息时指定相应的服务器地址即可
client.recv(1024) #客户端收到服务器的信息
client.close() #通信结束关闭客户端连接
- HTTP协议
HTTP协议在应用层中使用。具有以下特点。
HTTP协议需要请求和响应来完成通信。
HTTP是一个无状态的连接,所以引入了cookie,使得服务器了解第二次连接的客户端。
HTTP协议的请求资源一般都是用URL。
HTTP请求中有各种方法,其中get,post方法使用频率最高。get方法获取资源,将各种参数加在URL之后,POST方法把请求放在请求体中,增加安全性。
HTTP为持久连接,在服务器响应的报文中,connection :keep-alive这个属性使得下一次请求可以立刻连接,节约网络资源。
import urllib.request
import urllib.parse
def test_get():
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
headers = {
'User-Agent':user_agent
}
req = urllib.request.Request('http://www.woniuxy.com/',headers=headers)
resp = urllib.request.urlopen(req)
print(resp.read().decode())
def test_post():
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
headers = {
'User-Agent':user_agent
}
data = {
'user.tel': '15798769876',
'user.password': '123456',
'checkcode': '1111'
}
data = urllib.parse.urlencode(data).encode()
req = urllib.request.Request('http://www.woniuxy.com/login/userLogin',headers=headers,data=data)
resp = urllib.request.urlopen(req)
print(resp.read().decode())
- 子类继承父类的初始化方法
class student1(student): #student为父类,父类有name,age,stno这些属性
def __init__(self,name,age,stno,addr): #在父类的基础上加了一个addr属性
student.__init(self,name,age,stno) #显示调用父类的初始化方法
self.addr=addr #不在父类的属性自行初始化
class myThread(threading.Thread): #继承父类Thread
def __init__(self,url):
super().__init__() #通过super()关键字显示调用父类
self.url=url
- 通过Thread类构造器来创建线程
def get_web(url): #定义创建线程之后要执行的方法,即是线程的执行体
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
req = urllib.request.Request(url,headers=headers)
resp = urllib.request.urlopen(req)
print(resp.read().decode()[:50])
if __name__=='__main__':
t=threading.Thread(target=get_web,args=(url,)) #使用Thread类的构造器来创建线程,在线程参数中规定线程的执行方法和方法的参数
t.start() #运行线程
t.join() #阻塞线程,执行主程序
- 通过继承Thread类创建线程
class myThread(threading.Thread) #定义类来继承Thread,创建新线程
def __init__(self,url): #定义新类的初始化方法
super().__init__() #显示调用父类的初始化方法
self.url=url
def run(self) #定义父类中的run方法,表示线程的执行过程
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
req = urllib.request.Request(self.url,headers=headers)
resp = urllib.request.urlopen(req)
print(resp.read().decode()[:50])
if __name__=='__main__':
t=myThread(url) #初始化新定义的线程,传递新线程所需的各种参数
t.start() #运行线程
t.join() #阻塞主程序,执行线程
- 全局解释器锁GIL。当前线程执行I/O操作时,会释放GIL。当前线程执行超过100字节码,也会释放GIL。
import threading
n = 0
lock = threading.Lock()
def add():
for i in range(1000000):
with lock:
global n
n += 1
def minus():
for i in range(1000000):
with lock:
global n
n -= 1
if __name__=='__main__':
t1 = threading.Thread(target=add)
t2 = threading.Thread(target=minus)
t1.start()
t2.start()
t1.join()
t2.join()
print(n) #最后执行结果还是0,加入了锁
- 使用Queue,消息队列来实现线程间的通信
import threading
import time
from queue import Queue
def produce(q):
kind=('猪肉','白菜','豆沙')
for i in range(3):
print(threading.current_thread().name,'包子生产者开始生产包子')
time.sleep(1)
q.put(kind[i%3]) #生产者生产后,放入一个包子到消息队列
print(threading.current_thread().name,'包子生产者生产完包子')
def consume(q):
while True:
print(threading.current_thread().name,'消费者准备吃包子')
time.sleep(1)
t=q.get() #get方法是一个阻塞方法,如果消息队列中没有包子,就会阻塞当前线程
print('消费者吃了{}包子'.format(t))
if __name__=='__main__':
q=Queue(maxsize=1)
threading.Thread(target=produce,args=(q,)).start() #启动两个生产者线程
threading.Thread(target=produce,args=(q,)).start()
threading.Thread(target=consume,args=(q,)).start() #启动一个消费者线程
#执行流程
#先启动三个线程分别执行到线程中的一部分
# 包子生产者1开始生产包子
# 包子生产者2开始生产包子
# 消费者准备吃包子
#此时消息队列中没有包子,生产者1执行剩余部分后,又循环回到头部重新生产包子
# 包子生产者1生产完包子
# 包子生产者1开始生产包子
#此时,消息队列中有包子,消费者开始消费
# 消费者吃了什么包子
#消费者消费完包子后,消息队列中没有包子,生产者2开始生产包子
# 包子生产者2生产完包子
# 包子生产者2开始生产包子
#生产者2生产包子后,消息队列中有包子,消费者吃完包子后又回到循环等待包子
# 消费者吃了什么包子
# 消费者准备吃包子
#此后,生产者1又重新开始生产包子,消费者消费包子,生产者2开始生产包子,消费者消费包子。直到两个生产者都生产完3个包子后,消息队列中没有包子,结束执行。
- 使用Event事件对象让线程通信。适合与集合点的测试,线程启动后,不是立刻执行,而是等待所有线程都启动后,测试系统的并发执行效率
import threading
import time
class myThread(threading.Thread): #自定义线程对象
def __init__(self,event):
super().__init__() #继承父类初始化方法
self.event=event
def run(self): #自定义run方法
print('线程{}已经启动\n'.format(self.name))
self.event.wait() #启动线程后,使用wait方法阻塞所有线程,等待event指令
print('线程{}开始运行'.format(self.name))
if __name__=='__main__':
event=threading.Event() #创建Event对象
threads=[] #定义线程列表
[threads.append(myThread(event) for i in range(1,11))] #创建10个线程,放入到threads列表中
event.clear() #创建线程后,使所有Event对象都处于待命状态
[t.start() for t in threads] #执行线程
event.set() #执行每个线程时,都会进入等待Event对象发送指令状态,需要set方法发送指令
[t.join() for t in threads] #使每个线程和主线程分割
- 在多个线程之间交替执行或一个线程在等待其他线程时,使用Condition条件对象就很合适
import threading
cond=threading.Condition() #定义Condition对象
class k(threading.Thread): #定义一个要通信的对象
def __init__(self,cond,name):
threading.Thread.__init__(self,name=name)
self.cond=cond
def run(self): #定义线程执行体
self.cond.acquire() #线程k获得锁
print(self.getName() +':一支穿云箭')
self.cond.notify() #线程k发送消息后,通知线程x接收消息
self.cond.wait() #线程k通知x后,等待x的消息
print(self.getName()+':山无棱,天地合,乃敢与君决')
self.cond.notify()
self.cond.wait()
print(self.getName()+':紫薇')
self.cond.notify()
self.cond.wait()
print(self.getName()+':是你')
self.cond.notify()
self.cond.wait()
print(self.getName()+':借点钱')
self.cond.notify() #线程k与线程x之间最后一次通信,通知x后,释放锁
self.cond.release() #线程k释放锁
class x(threading.Thread): #定义另一个要通信的线程
def __init__(self,cond,name): #定义线程x的初始化方法
threading.Thread.__init__(self,name=name)
self.cond=cond
def run(self): #定义线程x的执行体
self.cond.acquire() #线程x获得锁
self.cond.wait() #线程x等待线程k发送消息
print(self.getName()+':千军万马来相见')
self.cond.notify()
self.cond.wait()
print(self.getName()+':海可枯,石可烂,激情永不散')
self.cond.notify()
self.cond.wait()
print(self.getName()+':尔康')
self.cond.notify()
self.cond.wait()
print(self.getName()+':是我')
self.cond.notify()
self.cond.wait()
print(self.getName()+':滚')
self.cond.release() #线程x在发送完最后一条信息后,释放锁
if __name__ =='__main__':
k = kongbeige(cond,'空白哥')
x = ximige(cond,'西米哥')
x.start()
k.start()
- 执行过程

- 线程之间的消息隔离。定义一个全局变量,在每个子线程中都会使用到。比如网络开发中,每个用户都有一个session,使用线程之间的全局变量可以让每个用户管理自己的session对象。在线程类之中的上下文管理中,数据库连接中,都能够使用到消息隔离。
import threading
local_data=threading.local() #定义一个全局变量
local_data.name='local_data'
class localThread(threading.Thread): #定义子线程
def run(self):
print('赋值前,主线程',threading.current_thread(),local_data.__dict__)
local_data.name=self.getName() #在子线程中修改全局变量
print('赋值后,子线程',threading.current_thread(),local_data.__dict__)
if __name__=='__main__':
print('赋值前,主线程',threading.current_thread,local_data.__dict__) #定义主线程,和子线程比较,观察全局变量是否改变
t1 = localThread()
t1.start()
t1.join()
t2 = localThread()
t2.start()
t2.join()
print('赋值后,主线程',threading.current_thread,local_data.__dict__)
- 最后的输出结果说明进程内部的全局变量,在主线程中没有发生改变,在两个子线程中分别被修改。

为了降低创建线程造成的资源消耗,引入了线程池,在线程池中的线程执行结束后,会被回收,下一个相同的任务到来,线程会直接执行。
线程池中,主线程会获取某个线程的任务或状态,以及返回值。某个子线程执行结束后,主线程立刻知道,会回收。
from concurrent.futures import ThreadPoolExecutor
import time
executor=ThreadingPoolExecutor(max_workers=3) #定义一个线程池对象,最大只允许三个线程
def get_html(times): #定义线程池中子线程的执行过程
time.sleep(times)
print('获取网页{}信息'.format(times))
return times
task1=executor.submit(get_html,1) #把第一个线程装入线程池,只需要把子线程的方法名传入,后面跟上方法中的参数即可。
task2=executor.submit(get_html,2)
task3=executor.submit(get_html,3)
在线程池中提交了线程后,可以通过提交后的函数句柄来查看线程的执行状况。
print(task1.done()) #查看线程1是否执行结束,一般在将线程提交后不会立即执行,会返回false值。 #在上面代码之前添加time.sleep(3)后,即在主线程中添加时间延迟后,线程会执行,此时查看线程状态,会返回true值 print(task2.cancel()) #查看线程2是否撤销,一般在线程没有提交到线程池,才能撤销线程 print(task1.result()) #拿到线程执行的结果,这是一个阻塞方法
在线程池中的线程执行结束后,如何查看运行结果。Python提供task.done()方法获取线程执行情况。但是这个方法在线程还没执行结束时,无法查看线程执行过程。所以有as_completed,map,wait方法可以在线程执行结束后,查看线程的状态。
from concurrent.futures import ThreadPoolExecutor,as_completed,ALL_COMPLETED
urls=[1,2,3,4] #定义需要抓取的地址
def get_web(): #定义线程的执行过程
pass
all_tasks=[executor.submit(get_web,url) for url in urls] #定义要执行的任务队列
for item in as_completed(all_tasks): #使用as_completed查看线程的执行情况
data=item.result()
print('主线程获取任务的返回值{}'.format(data))
#使用as_completed是按照线程的执行情况来先后输出线程状态
#使用map只是按照线程的装入顺序来输出线程执行情况
for data in executor.map(get_web,urls): #定义map方法获取线程执行的状态
print('主线程获取任务的返回值{}'.format(data))
#使用wait方法即是在所有子线程结束后,再去运行主线程
wait(all_tasks,return_when=ALL_COMPLETED) #参数ALL_COMPLETED就是所有子线程执行结束后,再执行主线程
多进程的实现和多线程大体相同。
多线程具有效率高,耗费资源少,所以非常适合I/O密集型的作业,比如文件读取,爬虫程序。这些程序主要的时间消耗集中在等待时间,多线程就非常适合。多线程缺点就是稳定性差,一个线程崩溃,其余线程也会受到影响。
多进程稳定性高,进程之间互不干扰。所以非常适合计算密集型的作业。多进程缺点耗费计算机大量资源。
- 什么是装饰器?
装饰器是装饰其它函数,为其它函数增加特定功能。在原来的函数上,增加一些限制或制约的条件,称为装饰器。
使用装饰器不会修改原函数的源码,也不会修改原函数的调用方式。
装饰器的基础知识有,函数也是变量,高阶函数,嵌套函数。
函数名和变量名一样只是一个变量的标识符,指向函数定义的内存地址。在函数定义中取调用其它函数时,不会立即调用调用该函数。
高阶函数的两个要求为,在函数形参中可以传递函数,函数的返回值包含函数名。
1 import time
2 def timer(func): #定义装饰器函数
3 def gcf(): #定义一个嵌套函数
4 start_time=time.time()
5 func() #调用作为参数传入的函数名
6 end_time=time.time()
7 print('程序运行时间',end_time-start_time)
8 return gcf #返回嵌套函数的函数名
9 @timer
10 def foo(): #定义被装饰函数
11 time.sleep(1)
12 print('in foo')
13 foo()
14 #执行过程
15 #到达第二行,装饰器函数的定义,把装饰器函数整体加载到CPU
16 #到达第九行,语句的执行过程实际是foo=timer(foo),所以执行timer函数
17 #回到第三行,把嵌套函数gcf整体加载到CPU
18 #执行到第八行,返回一个嵌套函数名给装饰器函数timer,也即返回函数名给foo
19 #到达第十四行,执行返回的foo函数,又回到第三行,执行foo函数体
20 #到达第五行,执行func函数,转到第十行
21 #执行了func函数后,依次执行程序,直到结束程序
当被装饰函数中有参数时,参数传递过程遵循一定的规则。被装饰函数中有一个参数,使用以下方式。
import time
def timer(func): #定义高阶函数,参数传递foo,装饰foo
def gf(name): #定义嵌套函数,装饰foo
start_time=time.time()
func(name) #执行被装饰函数
end_time=time.time()
print('程序运行时间',end_time-start_time)
return gf #在高阶函数中返回嵌套函数
@timer
def foo(name): #被装饰函数中有参数
time.sleep(1)
print('in foo',name)
foo('woniu')
被装饰函数有多个参数时,需要使用不定义参数传参
import time
def timer(func):
def gf(*args,**kwargs):
start_time = time.time()
func(*args,**kwargs)
end_time = time.time()
print('程序运行时间为',end_time-start_time)
return gf
@timer
def foo(name,age):
time.sleep(1)
print('in foo',name,age)
foo('woniu',24)
在装饰函数中传递参数,需要使用以下的规则
import time
def timer(timer_type): #定义高阶函数作为装饰器,带有参数
def outter(func): #定义嵌套函数,参数为被装饰函数
def inner(*args,**kwargs): #定义嵌套函数,参数为被装饰函数的参数
start_time=time.time()
func(*args,**kwargs) #调用被装饰函数
end_time=time.time()
return inner #返回内层嵌套函数
return outter #返回外层嵌套函数
@timer(timer_type='min')
def foo(name,args): #定义被装饰函数
time.sleep(1)
print('in foo',name,age)
foo('woniu',24)
被装饰函数有返回值,遵循如下规则
import timer
def timer(timer_type): #定义高阶函数为装饰器函数,带有参数
def outter(func): #定义嵌套函数,参数为被装饰函数
def inner(*args,**kwargs) #定义嵌套函数,被装饰函数有参数
start_time = time.time()
res = func(*args,**kwargs)
end_time = time.time()
print('程序运行时间为',end_time-start_time)
return res #返回被装饰函数的返回值
return inner #返回内层嵌套函数
return outter #返回外层嵌套函数
@timer(timer_type='min')
def foo(name,age): #定义被装饰函数,有返回值,有多个参数
time.sleep(1)
print('in foo',name,age)
return name
print(foo('woniu',24)) #输出被装饰函数的返回值
- 迭代器
在Python的任意对象中,定义了返回一个迭代器的__iter__方法,或定义了支持下表索引的__getitem__方法,就称为可迭代对象。
#判断可迭代对象的两种方式
form collections import Iterable
print(isinstance([],Iterable)) #使用isinstance方法判断
print(hasattr([],'__getitem__')) #使用是否具有方法__getitem__判断
class emp(): #定义对象
def __init__(self,employee):
self.employee=employee
def __getitem__(self,item): #定义方法,表示是一个可迭代对象
return self.employee[item] #返回一个类中的属性
emp=emp(['张三','李四','王五'])
for i in emp: #emp对象增加了__getitem__对象后,变成了可迭代对象
print(i)
迭代器就是包括一个__iter__方法来返回迭代器本身,__next__方法返回迭代器的下一个值。
有了可迭代对象,为什么还需要迭代器?这是因为迭代器是一个工厂模式,是懒加载。预先不需要指定迭代器的大小,是根据需要动态的加载空间。所以也就没有长度属性。
from itertools import count
from collections import iterator
counter=count(start=10) #定义了一个迭代器对象
for i in range(10): #只需要指定循环次数,就可以随机生成迭代器
print(next(counter)) #每次循环都输出下一个迭代器值
print(isinstance(counter,iterator)) #判断是否迭代器
a=[1,2,3,4,5,6] #列表为可迭代对象
a_iter=iter(a) #列表强制转为迭代器
for item in a_iter: #对迭代器进行迭代
print(item)
#迭代器对象进行迭代后,不能再次迭代。可迭代对象迭代后,依然可以迭代。
- 生成器
生成器是一个特殊的迭代器,不需要写__next__方法,__iter__方法,只需要在函数内部写一个yield关键字即可。
使用yield关键字,可以返回一个值。也可以保留函数的运行状态,等待下次函数的执行,函数下次执行是从yield语句后开始执行。
def demo(): #定义生成器
print('hello')
yield 5
print('world')
c=demo() #只是生成生成器对象,不运行
print(next(c)) #调用生成器,输出hello,由于yield返回5,再输出5
next(c) #在此输出world,程序从上次yield语句后开始执行
生成器的两种调用方法。next方法,send方法。
send方法也能够调用生成器,同时还会传递一个数据到生成器内部。
生成器的两种预激活机制。使用next方法,使用c.send(None)方法传递一个空值到生成器内部。
- 协程
协程是一种微线程,是一种用户级的轻量级线程。在同一个线程中,不同子程序可以中断转去执行其它程序,在执行结束后,又回来继续执行中断前的程序。这种任务调度的模式称为协程。协程拥有自己的上下文,寄存器和栈。
def consume(): #定义消费者
r=''
while True:
n=yield r #出现yield关键字,表示是一个生成器
print('[consumer] consuming %s' %n)
r='200 OK'
def produce(c): #定义生产者
c.send(None) #启动消费者
n=0
while n<5:
n=n+1
print('[producer] produceing %s' %n)
r=c.send(n)
print('[producer] consumer return %s' %n)
c=consume()
produce(c)
执行过程

使用协程可以降低系统的开销,不想创建线程那样创建协程。也不必使用锁的机制来控制不同线程之间的运行。因为协程本来就是在一个线程之中运行。
import asyncio
from collections.abc import Generator,Coroutine
@asyncio.coroutine #使用装饰器来定义协程
def hello(): #定义测试函数
pass
async def hello(): #使用async关键字来定义协程
pass
h=hello()
print(isinstance(h,Generator)) #测试是否生成器
print(isinstance(h,Coroutine)) #测试是否协程
#使用装饰器方法定义协程属于一个生成器,
#使用原生协程定义方法定义协程就属于一个协程
使用asyncio框架来执行协程
import asyncio
async def hello(name): #定义协程函数
print('hello',name)
h=hello('woniu') #定义协程对象
loop=asyncio.get_event_loop() #定义事件循环对象容器
task=loop.create_task(h) #将协程对象转为task
task=asyncio.ensure_future(h) #将协程对象转为task的另一种方法
loop.run_until_complete(task) #将task放到事件循环对象容器中运行
由于协程使用在异步I/O中,在协程中需要回调函数,来返回某个协程被中断后执行操作的结果。
import asyncio
async def hello(x): #定义协程函数
await asyncio.sleep(x) #异步操作,休眠当前协程
return x #在协程休眠后,执行操作,返回操作的结果
h=hello(2) #定义协程对象
loop=asyncio.get_event_loop() #定义事件循环对象容器
task=asyncio.ensure_future(h) #将协程对象转为task
loop.run_until_complete(task) #事件循环对象执行task
print('返回结果:{}'.format(task.result())) #协程休眠后,执行的操作结果保存在task.result()方法中
#上述方法仅适用在返回操作结果。如果要对返回结果进行操作,再返回就需要使用函数
async def hello(x): #定义协程函数
await asyncio.sleep(x) #异步操作,休眠当前协程
return x #协程休眠结束,返回中断操作执行的结果
def callback(future): #定义回调函数
sum=10+future.result() #不经过任何操作的返回结果存放在future.result()方法中
print('返回结果:',sum)
h=hello(2)
loop=asyncio.get_event_loop() #创建事件循环对象容器
task=asyncio.ensure_future(h) #将协程对象转为task
task.add_done_callback(callback) #将回调函数添加到task中
loop.run_until_complete(task) #事件循环对象容器中执行task
使用协程并发操作,使用更少的资源完成大的运行任务。
import asyncio
import time
def hello(x): #定义协程函数
print('等待:',x)
await asyncio.sleep(x) #协程休眠
return '等待了{}'.format(x)
if __name__=='__main__':
start=time.time()
h1=hello(1) #定义多个协程对象
h2=hello(2)
h3=hello(3)
tasks=[ #将协程对象转task放到列表中
asyncio.ensure_future(h1),
asyncio.ensure_future(h2),
asyncio.ensure_future(h3)
]
loop=asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks)) #使用 asyncio.wait()方法运行多个task
for task in tasks:
print('任务返回结果:',task.result())
print('程序运行时间是',time.time()-start)
使用协程和多线程生成多数文件比较两者之间的性能
import asyncio
import time
async def write(path,x): #定义协程执行体,生成文件
with open(path,'w') as f:
f.write('this is file %s' %x)
if __name__=='__main__':
start=time.time() #设置标记开始时间
loop=asyncio.get_event_loop() #创建事件循环对象容器
tasks=[]
for i in range(10000): #创建一万个文件
tasks.append(write('/Users/tone/Desktop/h/'+str(i)+'.txt',i))
loop.run_until_complete(asyncio.wait(tasks)) #运行多个协程
print('程序的执行时间:',time.time()-start)
#上述方法使用协程创建一万个文件
#以下方法使用多线程创建一万个文件
import threading
import time
def write(path,x): #定义线程函数
with open(path,'w') s f:
f.write('this is fiile %s' %x)
if __name__=='__main__':
start=time.time()
therads=[]
for i in range(10000): #创建一万个文件
t=threading.Thread(target=write,args=('/Users/tone/Desktop/h/'+str(i)+'.txt'',i))
threads.append(t)
t.start()
[t.join() for t in threads]
print('程序的执行时间:',time.time()-start)
- 实现双向通信
import socket server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('0.0.0.0',8002)) server.listen() print('server 已经启动,欢迎连接') sock,addr = server.accept() while True: #使用循环实现服务器端永久等待消息 data=socl.recv(1024) print(data.decode()) if data.decode()=='exit': #如果客户端发来exit,就断开连接,判断语句要放在接收到客户端消息后,立刻执行,否则,不起作用。 break send_to_client=input() #输入发送给客户端的消息 sock.send(send_to_client.encode()) server.close() #关闭客户端连接 sock.close() #关闭sock连接 #上述代码为服务器端代码 #以下代码是客户端代码 import socket client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(('127.0.0.1',8002)) while True: send_to_server = input() client.send(send_to_server.encode()) data = client.recv(1024) print(data.decode()) if data.decode()=='exit': break client.close()
以上代码只能实现一个客户端和服务器通信。要实现多个客户端和服务器通信,就需要使用线程。把每个客户端和服务器的连接都当做是一个线程,这样,线程之间互不干扰,顺利运行。
import socket import threading server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('0.0.0.0',8002)) server.listen() print('server 已经启动,欢迎连接') def handle_client(sock): #定义函数,线程执行体 while True: #每一个线程和服务器的通信都是多次 data = sock.recv(1024) print(data.decode()) send_to_client = input() sock.send(send_to_client.encode()) while True: #服务器不知道客户端连接的数量,所以依然使用循环 sock,addr=server.accept() #服务器连接到了一个客户端 threading.Thread(target=handle_client,args=(sock,)).start() #启动一个线程执行和客户端的交互
在使用线程实现了多个客户端和服务器之间的通信后。
要实现群聊的功能,就把服务器当做一个转发机构,专门转发各种客户端发来的信息。
由于在客户端中input方法输入发送数据,而该方法是一个阻塞方法,必须先输入再发送。所以也可把客户端的接收,发送看做是一种线程,发送接收互不干扰。
在群聊中,设置客户端标识,方便所有客户端明确信息从哪里发出。
关闭某个客户端后,服务器不会报错,需要异常处理机制。
import socket import threading server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('0.0.0.0',8004)) server.listen() print('server 已经启动,欢迎连接') client_sockets = [] def handle_client(sock): #服务器转发数据,定义客户端标识,处理客户端退出异常 try: #处理某个客户端退出的异常 username=sock.recv(1024).decode() #接收客户端标识 for client in client_sockets: #发送消息说明每个客户端加入群聊 client.send(('欢迎【'+username+'】加入群聊').encode()) while True: #接收客户端标识后,开始接收客户端消息 data=sock.recv(1024).decode() #接收客户端标识 if len(client_sockets)>0: #客户端列表中国如果有客户,向每个客户端发送消息 for client in client_sockets: client.send((username+'说:'+data).encode()) except Exception as e: client_socket.remove(sock) #出现客户端退出群聊,服务器出现异常,删掉该连接 for client in clietn_sockets: #向每个客户端发送某客户端退出群聊 client.send((username+'已退出群聊').encode()) while True: #循环出现多个客户端连接 sock,addr= server.accept() client_sockets.append(sock) sock.send('欢迎加入群聊,请输入您的昵称:'.encode()) threading.Thread(target=handle_client,args=(sock,)).start() #启动服务器连接客户端 #上述是实现群聊的完全代码 #以下是客户端代码 import socket import threading client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) client.connect(('127.0.0.1',8004)) def receive(client): while True: print(client.recv(1024).decode()) def sendto(client): while True: send_to_other_client = input() client.send(send_to_other_client.encode()) threading.Thread(target=receive,args=(client,)).start() threading.Thread(target=sendto,args=(client,)).start()
在群聊的基础上,实现私聊。需要使用字典数据类型存储每个客户端的连接和输入的昵称名。
客户端的代码不需要做出改变。
import socket import threading server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server.bind(('0.0.0.0',8004)) server.listen() print('server 已经启动,欢迎连接') client_sockets = {} #使用字典数据类型,存放连接和输入昵称之间的映射 def handle_client(sock): #处理私聊 try: #处理私聊,某客户端退出群聊异常不能缺失 username=sock.recv(1024).decode() #获取输入昵称 client_sockets[sock]=username #连接和输入昵称相互匹配 for client in client_sockets.keys(): client.send(('欢迎【'+username+'】加入群聊').encode()) while True: #客户端输入循环 data=sock.recv(1024).decode() #服务器接受了客户端昵称后,再接受信息 send_data = '【'+username+'】说:'+data if data.startswith('@'): #处理私聊,私聊以@开头 msg=data.split(' ') #分割输入信息, private_name=msg[0][1:] #获取输入昵称 for k,v in client_sockets.items(): #遍历映射,查找符合的昵称 if v==private_name: #找到符合的用户昵称 k.send(send_data.encode()) #向该昵称的连接发生私聊信息 else: #不是私聊,就是普通群聊 if len(client_sockets)>0: for client in client_sockets.keys(): #依次遍历各个连接 client.send(send_data.encode()) exception Exception as e: client_sockets.pop(sock) #出现异常,删除连接 for client in client_sockets.keys(): client.send((username+'已退出群聊').encode()) while True: #客户端连接未知 sock,addr=server.accept() client_sockets[sock]='' sock.send('欢迎您加入群聊,请输入您的昵称:'.encode()) threading.Thread(target=handle_client,args=(sock,)).start() #启动服务器,连接客户端

 浙公网安备 33010602011771号
浙公网安备 33010602011771号