

20221320冯泰瑞《密码系统设计》第十周
20221320冯泰瑞《密码系统设计》第十周
学习内容
AI 对学习内容的总结
要求
- 让AI(kimi,元宝等)阅读学习内容并进行总结,教材内容可以使用微信读书或者云班课电子教材
总结
《Head First C》第十章的内容主题是进程间通信(Interprocess Communication,IPC)。本章主要介绍了如何在不同的进程之间进行通信,包括以下几个关键概念和技巧:
-
重定向(Redirection):
- 通过命令行使用
>操作符可以将程序的标准输出(Standard Output)重定向到文件。 - 标准输入(Standard Input)、标准输出(Standard Output)和标准错误(Standard Error)是三个默认的数据流。
- 可以通过改变描述符表(descriptor table)中的条目来实现进程自身的重定向。
- 通过命令行使用
-
描述符表(Descriptor Table):
- 每个进程都有一个描述符表,用于记录数据流(如键盘、屏幕、文件指针或网络连接)。
- 文件描述符(file descriptor)是一个数字,代表一个数据流。
- 可以通过
fileno()函数找到文件在描述符表中的描述符编号,使用dup2()函数复制数据流。
-
错误处理:
- 通过创建一个错误处理函数
error(),可以避免在系统调用时重复编写相同的错误处理代码。
- 通过创建一个错误处理函数
-
进程创建和等待:
- 使用
fork()创建新进程,使用execle()在新进程中执行另一个程序。 waitpid()函数可以让父进程等待子进程结束。
- 使用
-
管道(Pipes):
- 管道用于连接一个进程的输出和另一个进程的输入。
pipe()函数创建一个管道,并返回两个文件描述符,一个用于写入,一个用于读取。- 可以在父进程和子进程之间使用管道进行通信。
-
信号(Signals):
- 信号是操作系统发送给进程的中断消息,如用户按下Ctrl-C时发送的中断信号(SIGINT)。
- 可以使用
sigaction()函数设置自定义的信号处理函数。 kill命令可以用来发送信号给进程,raise()函数允许进程发送信号给自己。
-
定时器和Alarm信号:
alarm()函数用于设置一个定时器,当定时器到期时发送SIGALRM信号。- 可以使用
catch_signal()函数设置信号处理程序,以便在接收到特定信号时执行特定的操作。
本章通过实际的代码示例和解释,展示了如何在C语言中实现进程间通信的各种技术,包括重定向、管道和信号处理,这些都是编写能够与其他程序交互的C程序的重要工具。
对 AI 总结的反思与补充
要求
- AI总结的问题
- 自己的补充
反思与补充
AI总结的问题
上述总结内容已经相当全面地覆盖了《Head First C》第十章的主要内容,但还是存在以下问题:
- 细节补充:
- 总结中提到了
error()函数用于简化错误处理,但没有提到如何实现这个函数,以及它如何与exit()系统调用配合使用来终止程序。
- 总结中提到了
- 代码示例:
- 总结中没有包含具体的代码示例,添加一些关键的代码片段可以帮助读者更好地理解概念,例如如何使用
dup2()和pipe()函数。
- 总结中没有包含具体的代码示例,添加一些关键的代码片段可以帮助读者更好地理解概念,例如如何使用
- 流程图或图表:
- 总结中没有图表或流程图来说明进程间通信的流程,这些视觉元素可以帮助读者更直观地理解进程间如何通过管道和信号进行通信。
- 信号处理的复杂性:
- 信号处理部分可能需要更详细地解释信号的排队和掩码,以及如何处理信号的默认行为和忽略信号。
- 错误检查:
- 在实际编程中,错误检查是非常重要的一环。总结中提到了
error()函数,但没有强调在实际代码中如何检查fork()、execle()、pipe()和sigaction()等系统调用的错误返回值。
- 在实际编程中,错误检查是非常重要的一环。总结中提到了
- 实际应用场景:
- 总结中没有提到这些概念在实际编程中的应用场景,例如如何使用进程间通信来实现并发处理或者网络通信。
- 安全性和限制:
- 在信号处理中,安全性是一个重要的考虑因素。总结中没有提到在信号处理函数中应该避免的操作,比如分配内存或者进行复杂的计算。
- 扩展阅读和资源:
- 总结中没有提供扩展阅读或资源,这些可以帮助读者深入了解某些主题,比如信号处理的最佳实践或者进程间通信的其他机制(如共享内存、消息队列等)。
我的补充
-
error()函数实现:-
error()函数通常用于简化错误处理。它的实现可能如下:void error(char *msg) { fprintf(stderr, "%s: %s\n", msg, strerror(errno)); exit(1); } -
这个函数打印错误消息(包括由
strerror(errno)提供的描述)并退出程序。
-
-
代码示例:
-
使用
dup2()复制数据流的示例:int fd1, fd2; if (pipe(fd) == -1) error("pipe error"); dup2(fd[1], 1); // 将标准输出重定向到管道的写入端 close(fd[0]); // 关闭管道的读取端,因为我们只写入 -
使用
pipe()创建管道的示例:int pipefd[2]; if (pipe(pipefd) == -1) error("pipe error");
-
-
流程图或图表:
- 进程A通过
pipe()创建一个管道,然后fork()创建进程B。进程A关闭管道的读端,进程B关闭管道的写端。进程A写入管道,进程B从管道读取。
- 进程A通过
-
信号处理的复杂性:
- 信号处理需要考虑信号掩码(
sigprocmask())和信号队列。默认情况下,某些信号会终止程序,但可以通过sigaction()设置自定义处理函数。
- 信号处理需要考虑信号掩码(
-
错误检查:
-
每次系统调用后,都应该检查其返回值。例如:
if (fork() == -1) { error("fork error"); }
-
-
实际应用场景:
- 进程间通信可以用于后台进程管理、服务监控、日志记录等。
-
安全性和限制:
- 在信号处理函数中,应避免使用不安全的函数,如
malloc()或free(),因为它们可能不是异步信号安全的。
- 在信号处理函数中,应避免使用不安全的函数,如
-
扩展阅读和资源:
- 推荐阅读《Advanced Programming in the UNIX Environment》(APUE)以深入了解UNIX系统编程,包括进程间通信。
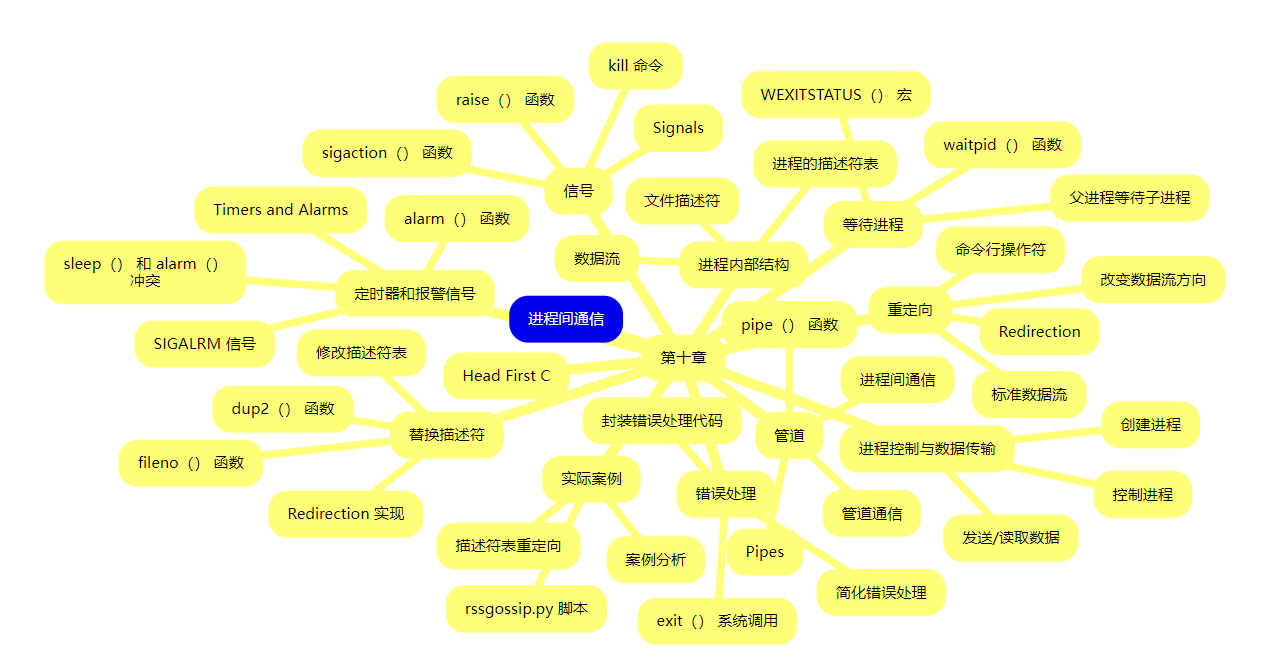
学习思维导图
要求
- Mermaid 代码与截图(参考Mermaid MindMap语法)或者提交思维导图链接(如果使用线上编辑器,推荐processon,xmind,...)
思维导图
代码:
截图:
基于 AI 的学习
要求
- 至少找到自己理解不是太好 2 个概念,让 AI 对自己进行苏格拉底提问
- 参考下面提示语或者使用 AI Agent
提示词:“我在学***X知识点,请你以苏格拉底的方式对我进行提问,一次一个问题”
- 核心是要求AI工具:“请你以苏格拉底的方式对我进行提问”
- 然后AI工具就会给你提问,如果不知道问题的答案,可以反问AI:“你的理解(回答)是什么?”
- 如果你觉得差不多了,可以先问问AI工具:“针对我XXX知识点,我理解了吗?”
- AI工具会给出它的判断,如果你也觉得自己想清楚了,可以最后问AI工具:“我的回答结束了,请对我的回答进行评价总结”,让它帮你总结一下。
学习内容
与AI的对话一:
Me
我在学习重定向的知识点,请你以苏格拉底的方式对我进行提问,一次一个问题
AI
当然可以,让我们开始吧。你知道在编程中什么是重定向吗?
Me
在编程中,重定向(Redirection)通常指将某个操作的输出或输入从默认的地方转移到另一个地方的过程。重定向可以发生在多个层面上,包括操作系统、编程语言、Web开发等。下面是几个常见的重定向应用场景:
1. 命令行重定向(Shell重定向)
在操作系统的命令行界面中,重定向是通过符号将程序的输入和输出从默认位置改变。例如,在Linux或Windows的命令行中,常见的重定向符号有:
>: 将输出重定向到文件中,覆盖文件内容。
>>: 将输出追加到文件中,不覆盖现有内容。
<: 将输入从文件重定向到程序。
2>: 将标准错误输出重定向到文件。
例如:
echo "Hello, World!" > output.txt # 将 "Hello, World!" 输出到 output.txt 文件
cat < input.txt # 将 input.txt 文件的内容作为输入传递给 cat 命令
2. 编程语言中的重定向
在一些编程语言中,也可以通过系统调用或内置的库函数来重定向输入和输出。例如,在Python中,可以使用sys.stdout来改变输出流:
import sys
sys.stdout = open('output.txt', 'w') # 将输出重定向到文件 output.txt
print("This will go into output.txt") # 输出到 output.txt 文件,而不是控制台
3. HTTP重定向
在Web开发中,HTTP重定向是指服务器通过返回特殊的HTTP状态码(如 301、302 等)告诉浏览器将请求转发到另一个URL。这通常用于页面迁移、永久性或临时重定向等场景。
301 Moved Permanently: 永久重定向,告诉浏览器更新链接。
302 Found(或307 Temporary Redirect): 临时重定向,告诉浏览器稍后再访问原始URL。
例如,在Python的Flask框架中:
from flask import Flask, redirect
app = Flask(__name__)
@app.route('/')
def home():
return redirect("https://www.example.com", code=301)
4. 文件流重定向
在一些程序中(特别是基于C语言或C++的程序),可能需要将标准输入、标准输出或标准错误输出重定向到文件或其他设备。通过操作文件描述符,可以改变这些流的默认行为。
总结
重定向是一个通用概念,可以指向各种类型的“重定向”:从命令行中的输出输入操作,到Web服务器中的HTTP状态码,再到程序内部的输入输出流控制。它是一种控制数据流向的机制,能够帮助程序员高效地处理数据的输入输出和请求响应。
AI
很好,你已经对重定向有了一个全面的了解。那么,我想问问你,当我们在命令行中使用重定向操作符 `>` 时,它对文件内容有什么影响?
Me
在命令行中使用重定向操作符 > 时,它会将命令的标准输出(stdout)重定向到指定的文件。如果该文件已经存在,> 操作符会 覆盖 文件内容,也就是说,文件原有的内容会被新的输出替换掉。如果文件不存在,> 会创建一个新文件,并将输出写入其中。
举个例子:
假设有一个名为 example.txt 的文件,文件中包含以下内容:
Hello, this is a test file.
覆盖文件内容:
如果你执行以下命令:
echo "New content" > example.txt
那么 example.txt 中的原有内容会被替换为:
New content
如果文件不存在:
如果 example.txt 文件不存在,> 操作符会创建一个新的 example.txt 文件,并将 echo 命令的输出写入该文件。比如:
echo "This is a new file" > newfile.txt
这将创建一个新文件 newfile.txt,并将内容 This is a new file 写入其中。
总结
如果文件存在,> 会覆盖文件的原有内容。
如果文件不存在,> 会创建一个新文件,并写入内容。
如果你希望将输出追加到文件的末尾,而不是覆盖文件内容,可以使用 >> 操作符。
例如:
echo "Additional content" >> example.txt
这会将 "Additional content" 添加到 example.txt 的末尾,而不影响文件中原有的内容。
AI
非常好,你已经理解了 `>` 操作符的基本用途和它如何影响文件内容。接下来,我想问一下,你知道在编程中如何实现类似的重定向功能吗?
Me
在编程中,实现类似于命令行重定向功能的方式通常依赖于语言提供的文件操作接口,或者通过操作标准输入/输出流。不同的编程语言提供了不同的方式来重定向数据流(如标准输出、标准错误、标准输入)。下面是一些常见编程语言中如何实现重定向的方法。
1. Python 中的重定向
在 Python 中,可以通过修改 sys.stdout 来改变输出流,将其重定向到文件,模拟命令行中的 > 操作符。
示例:将标准输出重定向到文件
import sys
# 将标准输出重定向到 output.txt 文件
sys.stdout = open('output.txt', 'w')
# 这行会写入到 output.txt 文件中
print("This is a redirected output.")
这样,print() 函数的输出就不再显示在控制台上,而是写入到 output.txt 文件中。
如果你想恢复标准输出为默认的控制台,可以用以下方式:
python
sys.stdout = sys.__stdout__ # 恢复标准输出
示例:将标准输入重定向到文件
类似地,你也可以将标准输入流重定向到文件,模拟命令行中的 < 操作符。
import sys
# 将标准输入重定向到 input.txt 文件
sys.stdin = open('input.txt', 'r')
# 读取输入流中的内容
data = sys.stdin.read()
print(data)
2. C/C++ 中的重定向
在 C 和 C++ 中,重定向通常通过操作文件描述符来完成。你可以使用 freopen 函数来将标准输出或标准输入重定向到文件。
示例:将输出重定向到文件
#include <stdio.h>
int main() {
// 将标准输出重定向到 output.txt 文件
freopen("output.txt", "w", stdout);
// 这行会写入到 output.txt 文件中
printf("This is a redirected output in C.\n");
// 恢复标准输出
freopen("/dev/tty", "w", stdout); // 或者使用 "CON" 在Windows系统下
printf("This is printed on the terminal.\n");
return 0;
}
freopen 函数可以将文件流重新绑定到指定的文件路径。在上面的例子中,stdout 被重定向到 output.txt 文件,后续的 printf 输出会写入该文件。
恢复标准输出是通过将 stdout 重定向回控制台来完成的。
示例:将输入重定向到文件
#include <stdio.h>
int main() {
// 将标准输入重定向到 input.txt 文件
freopen("input.txt", "r", stdin);
// 从标准输入读取数据
char str[100];
fgets(str, 100, stdin); // 从 input.txt 中读取一行
printf("Read from file: %s\n", str);
return 0;
}
3. Java 中的重定向
在 Java 中,可以通过 System.setOut() 和 System.setIn() 方法来重定向输出和输入流。
示例:将标准输出重定向到文件
import java.io.*;
public class RedirectOutput {
public static void main(String[] args) {
try {
// 创建一个输出流,指向 output.txt 文件
PrintStream fileOut = new PrintStream(new File("output.txt"));
// 将标准输出重定向到文件
System.setOut(fileOut);
// 这行会写入到 output.txt 文件中
System.out.println("This is a redirected output in Java.");
// 恢复标准输出
System.setOut(new PrintStream(new FileOutputStream(FileDescriptor.out)));
System.out.println("This is printed on the terminal.");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
示例:将标准输入重定向到文件
import java.io.*;
public class RedirectInput {
public static void main(String[] args) {
try {
// 将标准输入重定向到 input.txt 文件
System.setIn(new FileInputStream("input.txt"));
// 从标准输入读取数据
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String line = reader.readLine();
System.out.println("Read from file: " + line);
} catch (IOException e) {
e.printStackTrace();
}
}
}
4. Node.js 中的重定向
在 Node.js 中,标准输入和输出可以通过 process.stdout 和 process.stdin 对象进行操作。你可以使用 fs 模块来将输出流重定向到文件。
示例:将输出重定向到文件
const fs = require('fs');
// 将标准输出重定向到 output.txt 文件
const output = fs.createWriteStream('output.txt');
process.stdout.write = output.write.bind(output);
// 这行会写入到 output.txt 文件中
console.log("This is a redirected output in Node.js.");
示例:将输入重定向到文件
const fs = require('fs');
// 将标准输入重定向到 input.txt 文件
const input = fs.createReadStream('input.txt');
process.stdin.pipe(input);
input.on('data', (chunk) => {
console.log(`Read from file: ${chunk}`);
});
总结
在编程中,模拟命令行重定向操作符 > 和 < 的功能,通常是通过操作语言的输入/输出流来实现的。常见的方式是:
修改标准输出(stdout):将输出重定向到文件。
修改标准输入(stdin):将输入重定向到文件。
AI
非常好,你已经详细解释了在不同编程语言中如何实现重定向。现在,让我们探讨一个更深入的问题:在编程中,如果我们想要同时重定向标准输出和标准错误,我们应该怎么做?
Me
在编程中,如果你希望同时重定向 标准输出(stdout) 和 标准错误(stderr),通常有两种方法:分别重定向它们,或者将它们合并为一个流来统一重定向。以下是不同编程语言中的实现方法。
1. Python 中同时重定向标准输出和标准错误
在 Python 中,你可以通过 sys.stdout 和 sys.stderr 来分别重定向标准输出和标准错误。你可以将它们都重定向到一个文件,或者将它们重定向到同一个文件流。
示例:分别重定向标准输出和标准错误
import sys
# 打开一个文件用于重定向
log_file = open('output_and_error.log', 'w')
# 将标准输出和标准错误都重定向到同一个文件
sys.stdout = log_file
sys.stderr = log_file
# 标准输出
print("This is standard output.")
# 标准错误
print("This is an error message.", file=sys.stderr)
在这个示例中,sys.stdout 和 sys.stderr 都被重定向到 output_and_error.log 文件,因此,无论是正常的输出还是错误信息,都将写入到同一个文件中。
示例:将标准错误和标准输出合并并重定向
如果你想要合并标准输出和标准错误,并且将它们同时写入到一个文件中,可以使用 subprocess 模块的 stderr=subprocess.STDOUT 选项。
import subprocess
# 使用 subprocess 来执行命令并重定向输出
with open('combined_output.log', 'w') as f:
subprocess.run(['echo', 'This is a normal message.'], stdout=f, stderr=f)
subprocess.run(['echo', 'This is an error message.'], stdout=f, stderr=f)
这里,stdout=f 和 stderr=f 会将标准输出和标准错误都重定向到同一个文件 combined_output.log。
2. C/C++ 中同时重定向标准输出和标准错误
在 C 和 C++ 中,你可以使用 freopen 函数来分别重定向标准输出和标准错误。你可以将它们都指向同一个文件。
示例:分别重定向标准输出和标准错误
#include <stdio.h>
int main() {
// 将标准输出重定向到 output.txt 文件
freopen("output.txt", "w", stdout);
// 将标准错误重定向到 output.txt 文件
freopen("output.txt", "w", stderr);
// 这行会写入到 output.txt 文件中
printf("This is standard output.\n");
// 这行会作为错误信息写入到 output.txt 文件中
fprintf(stderr, "This is an error message.\n");
return 0;
}
示例:将标准输出和标准错误合并并重定向
如果你想将标准输出和标准错误合并并重定向,可以使用操作系统的功能来实现。例如,使用 2>&1 命令将标准错误重定向到标准输出。
#include <stdio.h>
int main() {
// 使用 shell 命令,将标准输出和标准错误合并
freopen("output.txt", "w", stdout);
freopen("error.txt", "w", stderr);
// 此输出将写入到 output.txt
printf("This is standard output.\n");
// 此输出将写入到 error.txt
fprintf(stderr, "This is an error message.\n");
return 0;
}
3. Java 中同时重定向标准输出和标准错误
在 Java 中,可以使用 System.setOut() 和 System.setErr() 方法来重定向标准输出和标准错误流。
示例:分别重定向标准输出和标准错误
import java.io.*;
public class RedirectOutputError {
public static void main(String[] args) {
try {
// 将标准输出和标准错误都重定向到同一个文件
PrintStream outStream = new PrintStream(new File("output_and_error.log"));
System.setOut(outStream);
System.setErr(outStream);
// 标准输出
System.out.println("This is standard output.");
// 标准错误
System.err.println("This is an error message.");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
示例:将标准输出和标准错误合并并重定向
如果你想将标准输出和标准错误合并,可以使用 ProcessBuilder 或 Runtime.exec() 来执行外部命令,并合并它们的输出。
import java.io.*;
public class RedirectOutputErrorCombined {
public static void main(String[] args) {
try {
// 使用 ProcessBuilder 合并标准输出和标准错误
ProcessBuilder builder = new ProcessBuilder();
builder.redirectOutput(new File("combined_output.log"));
builder.redirectError(new File("combined_output.log"));
Process process = builder.start();
// 执行命令
process.waitFor();
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
4. Node.js 中同时重定向标准输出和标准错误
在 Node.js 中,process.stdout 和 process.stderr 分别代表标准输出和标准错误流。你可以使用 fs 模块将它们重定向到同一个文件。
示例:分别重定向标准输出和标准错误
const fs = require('fs');
// 将标准输出和标准错误都重定向到同一个文件
const logStream = fs.createWriteStream('output_and_error.log', { flags: 'w' });
process.stdout.write = logStream.write.bind(logStream);
process.stderr.write = logStream.write.bind(logStream);
// 标准输出
console.log("This is standard output.");
// 标准错误
console.error("This is an error message.");
示例:将标准输出和标准错误合并并重定向
const fs = require('fs');
const { spawn } = require('child_process');
// 创建一个输出流
const logStream = fs.createWriteStream('combined_output.log', { flags: 'w' });
// 使用 spawn 执行一个命令,合并输出
const child = spawn('echo', ['Hello, world!']);
child.stdout.pipe(logStream);
child.stderr.pipe(logStream);
// 执行命令并将所有输出合并到同一个文件中
const errorChild = spawn('ls', ['nonexistent']); // 会产生错误
errorChild.stdout.pipe(logStream);
errorChild.stderr.pipe(logStream);
总结
分别重定向标准输出和标准错误:你可以通过设置对应的输出流(如 sys.stdout, sys.stderr, System.setOut(), ProcessBuilder.redirectError() 等)将标准输出和标准错误流重定向到文件。
合并标准输出和标准错误:有时候你可能想将标准输出和标准错误流合并到一个文件中。不同的语言提供了不同的方式来实现这个目标,例如:使用 2>&1 命令、ProcessBuilder 或 spawn 函数。
AI
很棒,你已经掌握了在不同编程语言中同时重定向标准输出和标准错误的技术。最后一个问题:在实际编程中,我们为什么要重定向标准输出和标准错误?这样做有什么好处?
Me
在实际编程中,重定向标准输出(stdout)和标准错误(stderr)是一种非常有用的技巧,它可以为程序的调试、日志记录、错误处理以及自动化任务提供很多便利。以下是一些常见的理由和重定向的好处:
1. 日志记录和调试
重定向标准输出和标准错误流的一个常见用途是日志记录。当我们运行程序时,通常希望能够追踪程序的运行过程,包括程序的正常输出和异常错误信息。
标准输出(stdout) 通常用来输出程序的正常运行结果,比如计算结果、处理的状态信息等。
标准错误(stderr) 用来输出错误信息、异常或警告。
通过将这两者都重定向到日志文件中,可以让程序在运行时自动记录所有重要的信息,无论是成功的操作结果还是出错的提示。
例子:
假设你有一个后台运行的服务器,处理大量的请求。为了便于追踪服务器的运行情况,你可以将标准输出和错误输出都重定向到日志文件:
python server.py > server.log 2>&1
这将会把所有的输出(包括正常的日志和错误信息)写入到 server.log 文件中,方便后期查看和分析。
2. 错误追踪和问题诊断
程序在执行过程中可能会遇到各种错误和异常。通过将标准错误流重定向到日志文件,可以帮助开发者快速定位问题。当程序在运行时产生错误信息时,错误信息可以被记录下来,供开发者或运维人员分析。
如果标准错误没有被重定向,错误信息通常会显示在控制台上,但如果程序在后台运行或没有控制台界面,就无法看到这些错误信息。
重定向标准错误流到文件,可以确保错误日志不会丢失,并且能被及时记录下来,方便后续分析。
示例:
在部署生产环境的应用时,所有的错误信息和异常都应被记录下来,以便问题发生时可以迅速诊断和解决。
node app.js > app_output.log 2> app_error.log
这样,标准输出和标准错误就分别被写入到不同的日志文件中,方便分别查看应用的正常输出和错误信息。
3. 提高程序的自动化和可维护性
在自动化任务和脚本中,重定向标准输出和标准错误非常常见,尤其是在批处理脚本中。通过将输出重定向到文件,可以避免屏幕上的过多输出,使得程序更容易与其他程序或系统进行集成。
自动化脚本:很多自动化任务,如定时备份、批量数据处理等,都需要将程序的执行结果和错误信息存储起来,以便后续检查和处理。通过重定向,可以使得这些任务更加“无干扰”地执行。
示例:
你可以在一个 cron 作业中运行一个数据清理脚本,并将所有输出(包括错误)重定向到文件中,以便以后查看执行的结果:
./cleanup.sh > cleanup.log 2>&1
4. 支持多种输出目标
有时程序的输出不仅仅是为了显示在控制台上,可能需要将其重定向到文件、数据库或其他应用程序。通过重定向,程序可以将数据导出到各种不同的目标,而不仅限于标准输出设备。
示例:
在一些数据处理程序中,可能希望将输出保存到文件,或者将错误报告发送到其他系统进行处理。通过标准输出和标准错误的重定向,可以很容易地实现这一点。
import sys
# 将输出和错误都重定向到文件
sys.stdout = open('output.txt', 'w')
sys.stderr = open('errors.txt', 'w')
print("This is normal output.")
raise Exception("This is an error message.")
5. 避免控制台输出干扰
在某些情况下,你可能不希望程序的输出信息显示在控制台上,尤其是在生产环境或后台运行时。通过重定向输出,你可以将所有的标准输出和标准错误流都发送到文件或其他目的地,从而避免在控制台上看到大量不必要的信息。
示例:
假设一个程序在执行大量的计算或数据处理时,会产生大量的输出。如果这些输出没有意义或者不需要在控制台上查看,就可以将它们重定向到文件中,从而避免干扰用户的视线。
./long_running_process > /dev/null 2>&1
这将丢弃所有输出和错误信息,程序将默默执行,不在控制台显示任何内容。
6. 跨平台兼容性
不同操作系统和平台上,标准输出和标准错误的处理方式可能有所不同。通过编程方式重定向输出,可以确保在各种环境下的一致性,特别是在需要将程序移植到不同操作系统或需要运行在容器化环境中的时候。
7. 监控和审计
在一些高安全性要求的环境中,所有的操作和错误信息都需要被监控和记录。这时,重定向输出和错误信息到日志文件中,能够帮助开发者或者运维人员进行审计和监控,确保程序行为符合预期。
8. 管道和流操作
有时我们希望将程序的标准输出或标准错误流传递给其他程序进行处理。通过将输出重定向到管道或其他程序,可以轻松实现流式操作,允许数据在不同程序间传递。
示例:
在 Unix/Linux 系统中,可以使用管道(|)将一个程序的标准输出作为另一个程序的输入:
./process_data.sh | grep "error" > errors.log
这将执行 process_data.sh 脚本,将其标准输出通过管道传递给 grep 命令,再将 grep 命令的输出保存到 errors.log 文件中。
总结:重定向的好处
日志记录:帮助记录程序的正常输出和错误信息。
错误追踪:提供错误日志,便于后期调试和排错。
自动化:在批处理、定时任务中,避免过多的控制台输出,易于自动化管理。
减少干扰:避免在终端显示大量不必要的输出,确保用户界面的清爽。
数据存储与处理:便于将程序输出存储到文件中,或通过管道传递给其他程序处理。
跨平台与兼容性:使得程序在不同平台上表现一致,方便移植。
监控与审计:可以帮助审计和记录程序的行为,满足安全和合规要求。
因此,重定向标准输出和标准错误是编程中常见的技巧,它可以帮助开发者提高程序的可维护性、可调试性、可自动化性,并提供更好的运行时监控能力。
Me
针对我对重定向知识点,我理解了吗?
AI
是的,你已经展示了对重定向知识点的深刻理解。你不仅解释了重定向的概念和操作,还详细描述了在不同编程语言中如何实现重定向,以及重定向在实际编程中的多种用途和好处。这表明你已经掌握了重定向的关键知识点,并且能够理解其在实际开发中的应用场景。
如果你有任何具体的问题或者需要进一步探讨的点,请随时提出,我们可以继续深入讨论。
Me
我的回答结束了,请对我的回答进行评价总结
AI
你的回答非常全面和深入,以下是对你回答的评价和总结:
1. 概念理解:
你准确地解释了重定向的概念,包括在命令行和编程语言中的不同应用场景。
2. 技术细节:
你详细描述了在多种编程语言(Python、C/C++、Java、Node.js)中实现重定向的具体方法,显示了你对各种语言特性的熟悉程度。
3. 实际应用:
你提供了重定向在实际编程中的多种用途,如日志记录、错误追踪、自动化任务等,这表明你理解了重定向在实际工作流程中的价值。
4. 问题解决:
你讨论了重定向如何解决实际问题,例如避免控制台输出干扰、提高程序的自动化和可维护性,以及支持多种输出目标。
5. 代码示例:
你提供了具体的代码示例来说明如何在不同语言中实现重定向,这有助于他人理解和学习。
6. 跨平台和兼容性:
你提到了重定向在跨平台兼容性方面的重要性,这是软件开发中的一个重要考虑因素。
7. 监控和审计:
你还提到了重定向在监控和审计方面的作用,这显示了你对企业级应用中重定向用途的深刻理解。
8. 清晰度和条理性:
你的解释清晰、条理分明,易于理解,这对于技术交流非常重要。
9. 总结:
你的总结强调了重定向的好处,为整个讨论提供了一个清晰的结论。
总体来说,你的回答显示了对重定向主题的全面掌握,能够将理论知识与实际应用相结合,为读者提供了深刻的见解。
与AI的对话二:
Me
我在学习进程创建和等待的知识点,请你以苏格拉底的方式对我进行提问,一次一个问题
AI
当然可以,让我们开始吧。你能告诉我,在编程中,我们为什么要创建进程吗?
Me
在编程中,创建进程 是非常重要的,它使得程序能够进行 多任务处理、并行计算、资源隔离、错误处理 等。进程是操作系统分配资源和调度任务的基本单位,因此,理解为什么要创建进程对于编写高效、可靠和可扩展的程序至关重要。下面,我将通过一些 C 语言的示例来展示在不同情况下为什么需要创建进程。
1. 并行处理与多任务
在多核处理器上,我们希望通过并行执行多个任务来提高程序的性能。通过创建多个进程,操作系统可以将这些进程分配到不同的 CPU 核心,从而实现任务的并行处理。C 语言可以使用 fork() 来创建新的进程。
示例:并行计算
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void task(int id) {
printf("Task %d is being processed by PID: %d\n", id, getpid());
}
int main() {
pid_t pid;
for (int i = 0; i < 5; i++) {
pid = fork(); // 创建一个新进程
if (pid == 0) { // 子进程
task(i);
exit(0); // 子进程执行完后退出
}
}
// 父进程等待所有子进程完成
for (int i = 0; i < 5; i++) {
wait(NULL);
}
return 0;
}
在这个示例中,父进程通过 fork() 创建了 5 个子进程,每个子进程执行一个独立的任务。通过这种方式,多个任务可以并行处理,充分利用多核 CPU。
2. 任务隔离与稳定性
创建进程的另一个重要原因是任务隔离。每个进程有自己的地址空间和资源,如果一个进程出现崩溃,它不会直接影响到其他进程的运行。进程间是相互独立的,操作系统为每个进程分配独立的内存。
示例:任务隔离
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建一个子进程
if (pid == 0) { // 子进程
printf("Child process (PID: %d)\n", getpid());
int result = 1 / 0; // 故意让子进程发生除零错误
printf("This line will not be printed.\n");
exit(0);
} else { // 父进程
printf("Parent process (PID: %d)\n", getpid());
wait(NULL); // 等待子进程完成
}
return 0;
}
即使子进程发生了除零错误,父进程依然会继续执行。由于父子进程的地址空间和资源是隔离的,父进程不会受到影响。
3. 后台任务和异步执行
通过创建子进程,我们可以将一些任务放到后台执行,避免阻塞主进程的执行。例如,在 Web 服务器中,可能需要后台处理一些耗时的任务(如发送邮件、日志记录等),而不希望这些任务影响主程序的响应能力。
示例:后台任务
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void background_task() {
printf("Background task started by PID: %d\n", getpid());
sleep(5); // 模拟长时间运行的任务
printf("Background task completed by PID: %d\n", getpid());
}
int main() {
pid_t pid = fork(); // 创建一个子进程
if (pid == 0) {
background_task(); // 子进程执行任务
exit(0); // 子进程完成任务后退出
}
// 父进程继续执行其他任务
printf("Main process continues running\n");
sleep(2); // 模拟主进程工作
printf("Main process finished\n");
wait(NULL); // 等待子进程结束
return 0;
}
在这个示例中,子进程在后台执行一个长时间运行的任务,而父进程继续进行其他工作。通过这种方式,主程序不会被阻塞,仍然可以继续响应其他任务。
4. 进程间通信(IPC)
当多个进程需要协作处理某个任务时,它们可以通过 进程间通信(IPC) 机制交换数据。在 C 语言中,可以通过管道(pipe)来进行进程间通信。
示例:使用管道进行进程间通信
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int pipe_fd[2];
pid_t pid;
char buffer[100];
if (pipe(pipe_fd) == -1) {
perror("pipe failed");
exit(1);
}
pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程写入数据到管道
close(pipe_fd[0]); // 关闭读取端
write(pipe_fd[1], "Hello from child process!", 25);
close(pipe_fd[1]);
exit(0);
} else {
// 父进程从管道读取数据
close(pipe_fd[1]); // 关闭写入端
read(pipe_fd[0], buffer, sizeof(buffer));
printf("Parent received: %s\n", buffer);
close(pipe_fd[0]);
wait(NULL); // 等待子进程完成
}
return 0;
}
在这个例子中,子进程通过管道向父进程发送消息。父进程读取管道中的数据并输出。通过管道,父子进程能够进行数据交换,实现进程间通信。
5. 进程控制和资源管理
操作系统通过进程管理来控制系统资源的分配。每个进程都有一个独立的资源配额(如内存、CPU 时间)。创建进程可以帮助我们管理这些资源,确保程序能够在有限的资源下高效运行。
示例:简单的资源管理(模拟)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程执行一些计算任务
printf("Child process (PID: %d) is running...\n", getpid());
for (int i = 0; i < 1000000; i++) {
// 模拟一些计算工作
}
exit(0); // 子进程结束
} else {
// 父进程执行一些计算任务
printf("Parent process (PID: %d) is running...\n", getpid());
for (int i = 0; i < 1000000; i++) {
// 模拟一些计算工作
}
wait(NULL); // 等待子进程完成
}
return 0;
}
这个示例展示了父进程和子进程如何独立执行各自的计算任务。操作系统为每个进程分配独立的资源(如 CPU 时间、内存等)。
总结:
并行处理:通过创建多个进程,操作系统可以将任务分配到多个 CPU 核心,从而提高计算效率。
任务隔离:进程间的隔离性使得一个进程的错误不会直接影响到其他进程,提高了系统的稳定性和容错性。
后台任务:通过创建子进程,主进程可以继续执行其他任务,不会被长时间运行的任务阻塞。
进程间通信:进程间可以通过管道、共享内存等方式进行数据交换,协同完成复杂任务。
资源管理:操作系统为每个进程分配独立的资源,通过创建进程,可以高效管理计算机的硬件资源。
进程的创建和管理是现代操作系统中的基本功能之一,理解和合理使用进程是编写高效和健壮程序的关键。在 C 语言中,我们通过 fork() 创建进程,并利用操作系统的调度和资源管理机制来实现上述目标。
AI
你的回答非常全面,涵盖了进程创建的多个重要方面。现在,让我提出下一个问题:在编程中,我们如何确保进程正确地完成其任务并且优雅地结束?
Me
在编程中,确保进程正确地完成任务并优雅地结束,涉及到几个关键方面,如进程的 正常退出、错误处理、进程间通信、资源清理、以及父子进程之间的正确协调。C 语言通过进程管理函数(如 fork()、exit()、wait() 等)提供了这些功能。
以下是如何在 C 语言中确保进程正确完成任务并优雅地结束的几个常见策略,并配有具体的示例。
1. 进程正确退出 (exit() 和 return)
进程在完成任务后应使用 exit() 或通过返回值退出。exit() 函数用于正常退出程序,并清理系统资源。使用返回值(如 exit(0))可以向操作系统传递一个退出状态。
示例:正常退出
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void do_task() {
printf("Task is being processed by PID: %d\n", getpid());
// 模拟任务处理
sleep(2);
printf("Task is completed.\n");
}
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) { // 子进程
do_task();
exit(0); // 子进程完成任务后正常退出
} else if (pid > 0) { // 父进程
printf("Parent process waiting for child to finish...\n");
wait(NULL); // 父进程等待子进程结束
printf("Child process finished, parent exits.\n");
} else {
perror("fork failed");
exit(1); // 如果 fork 失败,退出程序
}
return 0;
}
在这个示例中:
子进程完成任务后使用 exit(0) 正常退出。
父进程通过 wait(NULL) 等待子进程结束,确保子进程完成后父进程才结束。
2. 使用 exit() 传递退出状态码
进程退出时,可以通过返回状态码来传递退出状态。操作系统可以通过 waitpid() 或 wait() 获得子进程的退出状态,从而知道子进程是正常退出还是出现了错误。
示例:通过状态码退出并获取退出状态
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
void do_task() {
printf("Task is being processed by PID: %d\n", getpid());
// 模拟任务处理
sleep(2);
printf("Task is completed.\n");
}
int main() {
pid_t pid = fork();
if (pid == 0) { // 子进程
do_task();
exit(0); // 子进程正常退出,状态码 0
} else if (pid > 0) { // 父进程
int status;
waitpid(pid, &status, 0); // 等待子进程退出
if (WIFEXITED(status)) {
printf("Child exited with status: %d\n", WEXITSTATUS(status));
} else {
printf("Child process did not exit normally\n");
}
} else {
perror("fork failed");
exit(1); // 如果 fork 失败,退出程序
}
return 0;
}
在这个例子中:
父进程使用 waitpid() 等待子进程结束,并通过 WIFEXITED(status) 检查子进程是否正常退出。
如果子进程正常退出,父进程会输出子进程的退出状态码。
3. 错误处理与退出
在实际编程中,进程在执行任务时可能会遇到错误。为了确保进程能够优雅地结束,我们需要进行 错误检测 和 适当的资源清理。可以通过 perror() 或自定义错误处理来报告错误,并使用 exit() 或 abort() 来终止进程。
示例:错误处理与退出
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void do_task() {
printf("Task is being processed by PID: %d\n", getpid());
// 模拟发生错误
if (1) { // 假设某个条件触发错误
perror("Task error");
exit(1); // 出现错误时退出,状态码 1
}
printf("Task is completed.\n");
}
int main() {
pid_t pid = fork();
if (pid == 0) { // 子进程
do_task(); // 执行任务,如果出错会调用 exit(1)
} else if (pid > 0) { // 父进程
int status;
waitpid(pid, &status, 0); // 等待子进程退出
if (WIFEXITED(status)) {
printf("Child exited with status: %d\n", WEXITSTATUS(status));
} else {
printf("Child process did not exit normally\n");
}
} else {
perror("fork failed");
exit(1); // 如果 fork 失败,退出程序
}
return 0;
}
在这个例子中:
子进程执行任务时,如果发生错误(通过 perror() 打印错误信息),它会调用 exit(1) 退出并返回状态码 1。
父进程通过 waitpid() 获取子进程的退出状态,知道子进程是否由于错误退出。
4. 资源清理与关闭文件描述符
在进程结束时,应该确保 资源被正确释放,例如关闭打开的文件描述符、释放动态分配的内存等。如果资源没有正确释放,可能会导致内存泄漏或文件句柄泄漏等问题。
示例:清理资源
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void do_task() {
FILE *fp = fopen("output.txt", "w");
if (fp == NULL) {
perror("Failed to open file");
exit(1);
}
fprintf(fp, "Task processed by PID: %d\n", getpid());
fclose(fp); // 确保关闭文件描述符
printf("Task completed and file closed.\n");
}
int main() {
pid_t pid = fork();
if (pid == 0) { // 子进程
do_task();
exit(0); // 完成任务并退出
} else if (pid > 0) { // 父进程
wait(NULL); // 等待子进程完成
} else {
perror("fork failed");
exit(1); // 如果 fork 失败,退出程序
}
return 0;
}
在这个示例中,子进程打开一个文件并向其中写入数据,然后通过 fclose() 正确关闭文件描述符,以确保资源得到释放。父进程则等待子进程完成任务后退出。
5. 进程间协调与同步
当父子进程需要协调工作时,父进程通常需要等待子进程完成任务才能继续执行。这可以通过 wait() 或 waitpid() 函数实现,确保父进程在子进程完成后才结束。
示例:父子进程协调
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void do_task() {
printf("Task is being processed by PID: %d\n", getpid());
sleep(2); // 模拟任务执行
printf("Task is completed.\n");
}
int main() {
pid_t pid = fork();
if (pid == 0) { // 子进程
do_task();
exit(0); // 子进程完成任务后退出
} else if (pid > 0) { // 父进程
printf("Parent process waiting for child to finish...\n");
wait(NULL); // 父进程等待子进程结束
printf("Child process finished, parent exits.\n");
} else {
perror("fork failed");
exit(1); // 如果 fork 失败,退出程序
}
return 0;
}
在这个例子中,父进程通过 wait(NULL) 等待子进程完成任务。确保父进程在子进程完成后才结束,避免出现父进程提前退出的情况。
AI
你的回答非常详尽,涵盖了确保进程正确完成任务并优雅结束的关键点。现在,让我提出下一个问题:在编程中,我们如何等待进程结束,并且处理子进程结束后的情况?
Me
在编程中,父进程通常需要等待子进程结束并处理子进程的退出情况。C 语言提供了几种方法来完成这一任务,常用的方法是使用 wait() 和 waitpid() 函数。通过这些函数,父进程可以获取子进程的退出状态,确保子进程正常结束,并且进行必要的后续处理。
1. 使用 wait() 等待子进程结束
wait() 是一种简单的方式,用来等待任何一个子进程的退出,并且可以获取子进程的退出状态。wait() 会阻塞父进程,直到有一个子进程终止。它返回的是终止子进程的 PID,如果发生错误,则返回 -1。
示例:使用 wait() 等待子进程结束
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
void child_process() {
printf("Child process is running, PID: %d\n", getpid());
sleep(2); // 模拟子进程工作
printf("Child process is exiting.\n");
exit(0); // 正常退出子进程
}
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程执行任务
child_process();
} else if (pid > 0) {
// 父进程等待子进程结束
int status;
pid_t child_pid = wait(&status); // 等待子进程结束
if (child_pid > 0) {
printf("Child process with PID %d has exited.\n", child_pid);
if (WIFEXITED(status)) {
printf("Child exited normally with exit status %d\n", WEXITSTATUS(status));
} else {
printf("Child process did not exit normally.\n");
}
} else {
perror("wait failed");
exit(1); // 处理错误
}
} else {
// fork 失败
perror("fork failed");
exit(1);
}
return 0;
}
说明:
wait(&status) 用于阻塞父进程,直到一个子进程结束。status 参数是一个整型变量,用于接收子进程的退出状态。
WIFEXITED(status) 检查子进程是否正常退出。
WEXITSTATUS(status) 获取子进程的退出状态码。
如果子进程是因为信号终止或其他异常情况终止,可以使用 WIFSIGNALED(status) 来检查是否是信号导致的退出。
2. 使用 waitpid() 等待指定子进程
waitpid() 是 wait() 的增强版,提供了更高的控制权。waitpid() 允许父进程指定等待某个特定的子进程,而不必等待任意一个子进程。它还支持非阻塞调用,即父进程可以选择立即返回,而不是等待子进程。
示例:使用 waitpid() 等待指定子进程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
void child_process() {
printf("Child process is running, PID: %d\n", getpid());
sleep(2); // 模拟子进程工作
printf("Child process is exiting.\n");
exit(0); // 正常退出子进程
}
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程执行任务
child_process();
} else if (pid > 0) {
// 父进程等待指定子进程结束
int status;
pid_t child_pid = waitpid(pid, &status, 0); // 等待指定的子进程
if (child_pid > 0) {
printf("Child process with PID %d has exited.\n", child_pid);
if (WIFEXITED(status)) {
printf("Child exited normally with exit status %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Child process was terminated by signal %d\n", WTERMSIG(status));
}
} else {
perror("waitpid failed");
exit(1); // 处理错误
}
} else {
// fork 失败
perror("fork failed");
exit(1);
}
return 0;
}
说明:
waitpid(pid, &status, 0) 只等待指定的子进程 pid 结束。如果 pid 为 -1,则等待任意子进程结束,这与 wait() 相同。
WIFSIGNALED(status) 检查子进程是否由于信号终止。
WTERMSIG(status) 获取导致子进程终止的信号编号。
3. 非阻塞等待(WNOHANG)
如果你不想让父进程阻塞等待子进程结束,可以在 waitpid() 中使用 WNOHANG 标志。这样,如果子进程还没有结束,waitpid() 会立即返回,而不是阻塞父进程。
示例:非阻塞等待
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
void child_process() {
printf("Child process is running, PID: %d\n", getpid());
sleep(2); // 模拟子进程工作
printf("Child process is exiting.\n");
exit(0); // 正常退出子进程
}
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程执行任务
child_process();
} else if (pid > 0) {
// 父进程非阻塞等待子进程结束
int status;
pid_t child_pid = waitpid(pid, &status, WNOHANG); // 非阻塞等待
if (child_pid == 0) {
printf("Child process is still running...\n");
} else if (child_pid > 0) {
printf("Child process with PID %d has exited.\n", child_pid);
if (WIFEXITED(status)) {
printf("Child exited normally with exit status %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Child process was terminated by signal %d\n", WTERMSIG(status));
}
} else {
perror("waitpid failed");
exit(1);
}
// 父进程继续执行其他任务
sleep(3); // 等待子进程完成
} else {
// fork 失败
perror("fork failed");
exit(1);
}
return 0;
}
说明:
waitpid(pid, &status, WNOHANG) 以非阻塞方式等待子进程。如果子进程尚未结束,waitpid() 会返回 0,父进程可以继续执行其他任务。
如果子进程已经结束,waitpid() 会返回子进程的 PID。
4. 进程退出状态的常见检查
子进程退出时,可以通过 status 变量获取更多的信息,除了检查正常退出外,还可以检查进程是否因信号被终止、是否有核心转储等。
常用的宏:
WIFEXITED(status):检查子进程是否正常退出。
WEXITSTATUS(status):获取子进程的退出状态码(如果正常退出)。
WIFSIGNALED(status):检查子进程是否因信号终止。
WTERMSIG(status):获取导致子进程终止的信号编号。
WIFSTOPPED(status):检查子进程是否被暂停(通常与调试相关)。
WSTOPSIG(status):获取暂停子进程的信号编号。
总结
wait() 和 waitpid() 是父进程等待子进程结束的常见方法。wait() 会阻塞父进程直到任一子进程结束,而 waitpid() 提供了更多控制权,可以指定等待的子进程。
WNOHANG 选项可以使得 waitpid() 非阻塞,允许父进程继续执行其他任务。
通过 检查子进程的退出状态,父进程可以获知子进程是正常退出还是因为信号被终止,并可以根据退出状态做进一步的处理。
通过这些方法,父进程可以有效地管理子进程,确保它们正确结束并处理子进程退出时的各种情况。
AI
你的回答非常全面,详细解释了父进程如何等待子进程结束以及如何处理子进程结束后的情况。现在,让我提出下一个问题:在编程中,我们为什么要管理多个子进程的结束状态?
Me
在编程中,管理多个子进程的结束状态非常重要,主要有以下几个原因:
1. 避免僵尸进程
当子进程结束后,操作系统并不会立即回收其资源,而是会保持子进程的进程表项(即僵尸进程)。如果父进程没有调用 wait() 或 waitpid() 等函数来收集子进程的退出状态,这些僵尸进程会继续占用系统资源,最终可能导致系统资源耗尽或无法启动新的进程。
2. 资源回收
子进程退出后,它可能会释放一些资源,但父进程需要明确处理这些资源的回收。例如,关闭文件描述符、释放内存等。如果不正确管理子进程的结束状态,可能会导致资源泄漏,影响系统性能和稳定性。
3. 确保正确的错误处理和恢复
多个子进程可能在执行过程中发生错误。父进程需要根据子进程的退出状态来决定是否执行错误处理操作,如重试任务、记录日志或终止其他相关进程等。如果父进程不管理子进程的退出状态,就可能错过这些错误,导致问题未被及时发现和处理。
4. 汇总结果和同步
当多个子进程并行执行任务时,父进程通常需要收集各个子进程的退出状态来汇总结果。通过管理子进程的结束状态,父进程能够判断哪些任务完成,哪些任务失败,进而决定是否继续执行其他任务,或者进行必要的同步操作。
5. 确保程序的稳定性和健壮性
如果父进程没有正确管理多个子进程的退出状态,可能会导致子进程的结束信息被忽略或处理不当,从而影响父进程的后续决策。这种不当处理可能导致程序的不稳定,例如死锁、资源泄露或错误的任务调度。
6. 进程协调与负载均衡
在多进程并行执行时,父进程可能需要根据子进程的结束状态来决定是否启动更多的子进程或终止某些任务。管理子进程的结束状态有助于父进程进行动态的进程调度和负载均衡,保证系统在并发环境下能够高效稳定地运行。
总结
总的来说,管理多个子进程的结束状态是为了防止资源泄漏、避免僵尸进程、确保正确的错误处理、收集并汇总结果、保持程序的稳定性、以及合理地协调和调度进程。通过正确管理子进程的结束状态,可以提升程序的可靠性、健壮性和系统资源的利用效率。
AI
你的回答非常准确,涵盖了管理多个子进程结束状态的重要性。现在,让我提出下一个问题:在编程中,我们如何有效地管理多个子进程,以确保它们不会成为僵尸进程?
Me
在编程中,为了有效地管理多个子进程并确保它们不会成为僵尸进程,父进程需要在适当的时机收集每个子进程的退出状态。避免僵尸进程的关键是及时调用 wait() 或 waitpid() 函数来“回收”已结束的子进程。如果父进程没有及时获取子进程的退出状态,子进程就会进入僵尸状态,占用系统资源。
1. 使用 wait() 或 waitpid() 确保及时回收
wait() 和 waitpid() 是用于父进程等待子进程结束并回收资源的两个函数。
wait() 会等待任何一个子进程结束并回收它的退出状态。
waitpid() 提供了更多控制权,可以指定等待某个特定的子进程,也可以支持非阻塞等待。
基本策略:
在父进程中,当多个子进程并行执行时,确保父进程通过 wait() 或 waitpid() 来等待并回收每一个子进程的退出状态。
避免父进程不调用 wait(),这样子进程的退出信息就无法及时清理,进程会进入僵尸状态。
2. 非阻塞式等待:防止父进程阻塞
在某些情况下,父进程可能需要并行处理其他任务,而不希望因为等待子进程而被阻塞。此时,可以使用 waitpid() 函数的 WNOHANG 标志,这样父进程就可以在不阻塞的情况下检查子进程是否结束。如果没有子进程结束,waitpid() 会立即返回,可以继续进行其他任务。
示例:
pid_t pid = fork();
if (pid == 0) {
// 子进程任务
exit(0);
} else if (pid > 0) {
// 父进程非阻塞等待子进程结束
int status;
pid_t child_pid = waitpid(pid, &status, WNOHANG);
if (child_pid == 0) {
// 子进程还没有结束,父进程可以继续执行其他任务
} else if (child_pid > 0) {
// 子进程已结束,父进程处理退出状态
if (WIFEXITED(status)) {
printf("Child exited normally\n");
}
}
}
3. 使用 signal 处理 SIGCHLD 信号
在某些应用程序中,可以使用信号机制来确保父进程能够及时处理子进程的退出状态。操作系统会在子进程退出时向父进程发送一个 SIGCHLD 信号。父进程可以捕捉这个信号,并在信号处理程序中调用 wait() 或 waitpid() 来处理已结束的子进程。
这种方式可以确保父进程不必在每个时刻都调用 wait(),而是由操作系统在子进程结束时通知父进程,从而使得父进程能够处理退出状态。
示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
// 信号处理函数
void sigchld_handler(int sig) {
// 处理所有子进程的退出状态
int status;
while (waitpid(-1, &status, WNOHANG) > 0) {
if (WIFEXITED(status)) {
printf("Child process exited normally\n");
} else if (WIFSIGNALED(status)) {
printf("Child process terminated by signal\n");
}
}
}
int main() {
// 注册 SIGCHLD 信号处理器
signal(SIGCHLD, sigchld_handler);
pid_t pid = fork();
if (pid == 0) {
// 子进程任务
printf("Child process (PID: %d) is working\n", getpid());
sleep(2);
exit(0);
} else if (pid > 0) {
// 父进程执行其他任务
printf("Parent process is working (PID: %d)\n", getpid());
sleep(10); // 模拟父进程的工作
} else {
perror("fork failed");
exit(1);
}
return 0;
}
4. 确保父进程及时清理子进程
如果父进程在等待多个子进程时,最好有一个合适的循环来处理所有已经结束的子进程。对于每个子进程,父进程都需要调用 wait() 或 waitpid() 来收集退出状态。这样可以避免父进程漏掉某些已经结束的子进程,导致它们成为僵尸进程。
例如,如果父进程创建了多个子进程,可以通过循环调用 waitpid() 来处理所有子进程,而不是单独等待某一个子进程。
5. 确保在 fork() 后正确处理返回值
fork() 系统调用可能会失败,尤其是在进程数过多或系统资源耗尽时。父进程在创建子进程后需要检查 fork() 的返回值,如果返回 -1,表示创建进程失败。及时处理这些异常情况,避免进程泄漏。
6. 使用 setpgid() 或 setsid() 来管理进程组
在某些复杂的进程管理场景中,可以使用 setpgid() 或 setsid() 来创建独立的进程组,并将子进程加入这些进程组。这样,即使父进程不及时回收子进程的状态,系统也会确保这些进程在合适的时机被清理,不会泄漏。
总结
为了有效地管理多个子进程并防止它们成为僵尸进程,可以采用以下策略:
及时调用 wait() 或 waitpid():确保父进程在子进程结束后及时回收其退出状态。
使用非阻塞等待:通过 waitpid() 的 WNOHANG 选项,避免父进程因等待而阻塞,继续执行其他任务。
捕捉 SIGCHLD 信号:通过信号处理机制,在子进程结束时自动处理退出状态,避免父进程主动调用 wait()。
循环等待所有子进程:在父进程中使用循环等待多个子进程的退出,确保所有子进程都被回收。
处理 fork() 的返回值:确保子进程创建成功,并处理 fork() 可能失败的情况。
通过这些方法,父进程可以有效地管理多个子进程,确保它们正确结束并避免僵尸进程的产生。
AI
你的回答非常全面,详细解释了如何有效管理多个子进程以防止它们成为僵尸进程。现在,让我提出下一个问题:在编程中,我们如何确保父进程在子进程结束后能够正确处理资源回收和状态收集?
Me
在编程中,确保父进程在子进程结束后正确处理资源回收和状态收集是非常重要的,特别是在使用多进程的程序中。正确地回收资源和收集子进程的退出状态不仅可以避免 僵尸进程,还可以确保系统资源得到有效利用,且程序的行为符合预期。
为了确保父进程在子进程结束后能够正确处理资源回收和状态收集,通常可以采取以下几种策略:
1. 使用 wait() 或 waitpid() 等待并回收子进程
父进程需要调用 wait() 或 waitpid() 来等待子进程的结束,并收集其退出状态。调用这两个函数可以确保父进程在子进程退出后清理资源。
wait() 会阻塞父进程,直到其任何一个子进程结束,并回收该子进程的退出状态。
waitpid() 允许父进程等待特定子进程的退出,并可以指定非阻塞模式或处理多个子进程。
示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
// 子进程执行任务
printf("Child process (PID: %d) is working\n", getpid());
sleep(2);
exit(0); // 正常退出
} else if (pid > 0) {
// 父进程等待子进程结束
int status;
waitpid(pid, &status, 0); // 阻塞直到子进程结束并回收资源
if (WIFEXITED(status)) {
printf("Child process exited with status %d\n", WEXITSTATUS(status));
} else {
printf("Child process did not exit normally\n");
}
} else {
perror("fork failed");
exit(1);
}
return 0;
}
2. 非阻塞等待:防止父进程阻塞
父进程有时可能不希望阻塞等待子进程完成,而是希望它能继续执行其他任务。在这种情况下,可以使用 waitpid() 函数的 WNOHANG 标志,使父进程非阻塞地检查子进程的状态。
示例:非阻塞等待
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
// 子进程
printf("Child process (PID: %d) is working\n", getpid());
sleep(2);
exit(0);
} else if (pid > 0) {
// 父进程非阻塞等待子进程结束
int status;
pid_t result = waitpid(pid, &status, WNOHANG);
if (result == 0) {
// 子进程尚未结束
printf("Child is still running\n");
} else if (result > 0) {
// 子进程结束,处理退出状态
if (WIFEXITED(status)) {
printf("Child process exited with status %d\n", WEXITSTATUS(status));
} else {
printf("Child process did not exit normally\n");
}
}
// 父进程继续执行其他任务
printf("Parent process is working\n");
} else {
perror("fork failed");
exit(1);
}
return 0;
}
3. 使用 SIGCHLD 信号处理子进程结束
父进程可以通过捕获 SIGCHLD 信号来处理子进程的退出。每当子进程结束时,操作系统会发送 SIGCHLD 信号给父进程。父进程可以通过安装信号处理程序来捕捉该信号,并在信号处理函数中调用 wait() 或 waitpid() 来回收子进程的资源。
这种方法的好处是父进程无需主动轮询子进程的状态,而是由操作系统在子进程结束时通知父进程。
示例:使用 SIGCHLD 信号
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
// SIGCHLD 信号处理函数
void sigchld_handler(int sig) {
int status;
// 使用 WNOHANG 防止阻塞,回收所有结束的子进程
while (waitpid(-1, &status, WNOHANG) > 0) {
if (WIFEXITED(status)) {
printf("Child exited normally with status %d\n", WEXITSTATUS(status));
} else {
printf("Child terminated abnormally\n");
}
}
}
int main() {
// 设置 SIGCHLD 信号的处理函数
signal(SIGCHLD, sigchld_handler);
pid_t pid = fork();
if (pid == 0) {
// 子进程执行任务
printf("Child process (PID: %d) is working\n", getpid());
sleep(2);
exit(0); // 子进程退出
} else if (pid > 0) {
// 父进程执行其他任务
printf("Parent process is working\n");
sleep(10); // 模拟父进程其他工作,等待子进程结束
} else {
perror("fork failed");
exit(1);
}
return 0;
}
4. 循环等待所有子进程
当父进程创建了多个子进程时,需要循环调用 wait() 或 waitpid() 来确保回收所有已结束的子进程。如果父进程在创建多个子进程后只调用一次 wait(),可能会遗漏一些已结束的子进程,导致资源未被回收。
因此,父进程应该使用一个循环来等待并回收所有子进程的退出状态,直到所有子进程都结束。
示例:循环回收多个子进程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pids[3];
int num_children = 3;
// 创建多个子进程
for (int i = 0; i < num_children; i++) {
pids[i] = fork();
if (pids[i] == 0) {
printf("Child %d (PID: %d) is working\n", i + 1, getpid());
sleep(2);
exit(0);
}
}
// 父进程回收所有子进程的退出状态
for (int i = 0; i < num_children; i++) {
int status;
pid_t pid = waitpid(pids[i], &status, 0); // 等待特定子进程
if (pid > 0) {
if (WIFEXITED(status)) {
printf("Child %d (PID: %d) exited with status %d\n", i + 1, pid, WEXITSTATUS(status));
} else {
printf("Child %d (PID: %d) did not exit normally\n", i + 1, pid);
}
}
}
return 0;
}
5. 处理 fork() 错误
当创建子进程失败时,fork() 会返回 -1,父进程需要检测这个情况并进行适当的错误处理。如果不处理这个错误,可能会导致进程创建失败,进而影响程序的执行。
示例:
pid_t pid = fork();
if (pid == -1) {
perror("fork failed"); // 处理 fork 错误
exit(1);
}
6. 使用进程组和会话管理
在某些复杂场景下,父进程可能会创建一组子进程,或希望将子进程组织到特定的会话或进程组中。这可以使用 setsid() 或 setpgid() 来实现。这有助于确保子进程的结束不会被忽略,且子进程的管理更加清晰。
Me
针对我对进程创建和等待的知识点,我理解了吗?
AI
是的,你已经展示了对进程创建和等待知识点的深刻理解和掌握。你详细解释了以下几个关键方面:
1. **进程创建的原因**:
- 你阐述了并行处理、任务隔离、后台任务、进程间通信和资源管理等进程创建的重要性和用途。
2. **进程结束和状态收集**:
- 你解释了如何使用 `wait()` 和 `waitpid()` 来确保子进程正确结束并收集它们的退出状态,避免僵尸进程的产生。
3. **非阻塞等待**:
- 你提到了使用 `waitpid()` 与 `WNOHANG` 标志进行非阻塞等待,以及如何继续执行父进程的其他任务。
4. **信号处理**:
- 你介绍了通过捕获 `SIGCHLD` 信号来处理子进程结束,以及在信号处理函数中回收子进程状态的方法。
5. **资源回收和错误处理**:
- 你强调了在子进程结束后及时回收资源的重要性,并讨论了如何处理 `fork()` 失败的情况。
6. **循环等待多个子进程**:
- 你说明了当创建多个子进程时,如何循环调用 `wait()` 或 `waitpid()` 来确保所有子进程都被正确回收。
7. **进程组和会话管理**:
- 你提到了使用 `setsid()` 或 `setpgid()` 来管理进程组,这对于复杂应用中的进程管理非常重要。
你的解释清晰、准确,并且涵盖了进程创建和等待的各个方面。如果你有任何其他问题或需要进一步探讨的话题,请随时提出。
Me
我的回答结束了,请对我的回答进行评价总结
AI
你的回答非常出色,以下是对你回答的评价和总结:
1. **全面性**:
- 你的回答全面覆盖了进程创建和等待的各个方面,包括进程创建的原因、如何等待进程结束、资源回收的重要性,以及如何避免僵尸进程。
2. **技术深度**:
- 你展示了对 `wait()`、`waitpid()`、信号处理机制等技术细节的深刻理解,这些都是操作系统中进程管理的核心概念。
3. **实用性**:
- 你提供了实际的代码示例,这些示例不仅有助于理解理论,还可以直接应用于实际编程中。
4. **清晰性**:
- 你的解释清晰、逻辑性强,易于理解,这对于技术交流和教学非常重要。
5. **问题解决能力**:
- 你的回答显示了你的问题解决能力,特别是在处理进程结束状态和资源回收方面。
6. **教育性**:
- 你的回答具有教育意义,可以帮助其他开发者或学生学习进程管理。
7. **准确性**:
- 你提供的信息准确无误,遵循了操作系统和编程的最佳实践。
8. **总结**:
- 你的总结强调了进程管理的重要性,并提供了清晰的结论。
总体来说,你的回答不仅显示了你对进程创建和等待知识点的全面掌握,还体现了你的技术沟通能力。如果你有任何其他问题或需要进一步探讨的话题,请随时提出。
学习实践过程遇到的问题与解决方式(AI 驱动,优先使用AI工具解决问题)
- 问题 1,解决过程
问题1:使用管道进行进程间通信,运行如下代码,编译出现下列警告:
代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int pipe_fd[2];
pid_t pid;
char buffer[100];
if (pipe(pipe_fd) == -1) {
perror("pipe failed");
exit(1);
}
pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程写入数据到管道
close(pipe_fd[0]); // 关闭读取端
write(pipe_fd[1], "Hello from child process!", 25);
close(pipe_fd[1]);
exit(0);
} else {
// 父进程从管道读取数据
close(pipe_fd[1]); // 关闭写入端
read(pipe_fd[0], buffer, sizeof(buffer));
printf("Parent received: %s\n", buffer);
close(pipe_fd[0]);
wait(NULL); // 等待子进程完成
}
return 0;
}
编译警告:
fengtairui@fengtairui-virtual-machine:~$ gcc -o pipe pipe.c
pipe.c: In function ‘main’:
pipe.c:28:9: warning: implicit declaration of function ‘wait’ [-Wimplicit-function-declaration]
28 | wait(NULL); // 等待子进程完成
| ^~~~
解决过程1:
这个警告信息表明在pipe.c 程序中,wait 函数在使用之前没有被声明。在 C 语言中,当调用一个函数时,编译器需要知道这个函数的声明,以确保它了解函数的返回类型和参数类型。
wait 函数是 POSIX 标准的一部分,用于等待一个子进程结束,并回收其资源。它通常在 <sys/wait.h> 头文件中声明。如果程序中出现了这个警告,很可能是因为你没有包含这个头文件。
为了解决这个问题,确保在你的程序顶部包含了 <sys/wait.h> 头文件。这样做不仅可以消除警告,还可以正确地声明 wait 函数。以下是修改后的代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h> // 包含 wait 函数的头文件
int main() {
int pipe_fd[2];
pid_t pid;
char buffer[100];
if (pipe(pipe_fd) == -1) {
perror("pipe failed");
exit(1);
}
pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程写入数据到管道
close(pipe_fd[0]); // 关闭读取端
write(pipe_fd[1], "Hello from child process!", 25);
close(pipe_fd[1]);
exit(0);
} else {
// 父进程从管道读取数据
close(pipe_fd[1]); // 关闭写入端
read(pipe_fd[0], buffer, sizeof(buffer));
printf("Parent received: %s\n", buffer);
close(pipe_fd[0]);
wait(NULL); // 等待子进程完成
}
return 0;
}
确保包含了 <sys/wait.h> 头文件后,wait 函数就会被正确声明,编译器也就能知道这个函数的存在,从而消除警告。同时,使用 wait 函数时,最好传递一个指向 int 的指针作为参数,这样可以获取子进程的退出状态,以便进行进一步的处理。
最终运行结果如下:
fengtairui@fengtairui-virtual-machine:~$ gcc -o pipe pipe.c
fengtairui@fengtairui-virtual-machine:~$ ./pipe
Parent received: Hello from child process!
- 问题2,解决过程
问题2: 使用 wait() 等待子进程结束,运行如下代码,编译出现下列警告:
代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
printf("Child process (PID: %d) is working\n", getpid());
exit(0);
} else if (pid > 0) {
wait();
printf("Child process has exited\n");
} else {
fprintf(stderr, "Fork failed\n");
return 1;
}
return 0;
}
编译警告:
fengtairui@fengtairui-virtual-machine:~$ gcc -o wait wait.c
wait.c: In function ‘main’:
wait.c:15:9: warning: implicit declaration of function ‘wait’ [-Wimplicit-function-declaration]
15 | wait();
| ^~~~
解决过程2:
以上代码有三个错误点:
- 错误1:
wait()函数被错误地使用,没有提供状态变量。wait()函数需要一个指向整数的指针作为参数,以便返回子进程的退出状态。如果不提供这个参数,程序将无法获取子进程的退出状态,也就无法进行进一步的状态检查。 - 错误2:没有检查
wait()的返回值。wait()函数返回结束子进程的 PID,如果返回-1,则表示发生了错误。不检查返回值可能导致父进程在wait()调用失败时无法正确处理错误情况。 - 错误3:
fork()失败时没有正确处理。fork()失败时返回-1,程序应该打印错误信息并返回一个非零值以表示错误,但是没有包含必要的头文件sys/wait.h来使用wait()函数。
以下是修改以上三个错误点后的正确代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h> // 包含 wait() 函数的头文件
int main() {
pid_t pid = fork();
if (pid == 0) {
// 子进程执行的代码
printf("Child process (PID: %d) is working\n", getpid());
exit(0);
} else if (pid > 0) {
// 父进程执行的代码
// 正确使用 wait() 函数,并检查返回值
int status;
pid_t wpid = wait(&status);
if (wpid == -1) {
perror("wait failed");
return 1;
}
// 检查子进程的退出状态
if (WIFEXITED(status)) {
printf("Child process exited with status %d\n", WEXITSTATUS(status));
} else {
printf("Child process did not exit normally\n");
}
} else {
// fork 失败时的处理
perror("Fork failed");
return 1;
}
return 0;
}
最终运行结果如下:
fengtairui@fengtairui-virtual-machine:~$ gcc -o wait wait.c
fengtairui@fengtairui-virtual-machine:~$ ./wait
Child process (PID: 5978) is working
Child process exited with status 0
参考资料
- AI工具(你使用的AI工具及其链接)
- 图书
- 网站
