JDK1.8下HashMap多线程并发问题
HashMap多线程并发情况(JDK1.8)
很早就知道Hashmap是线程不安全的,并且也看过hashmap的源码,知道他的各个操作的过程,今天来实践下,在多线程的情况下,hashmap的哪些步骤会出问题。
测试程序,扩容重哈希时的典型状况。
很简单,跑五个线程不停的往map里面put数据就好了,为了防止变量操作在多线程下对实验产生干扰,我们使用AtomicInteger来操作。
import java.util.HashMap; import java.util.Iterator; import java.util.Map.Entry; import java.util.concurrent.atomic.AtomicInteger; public class HashThreadTest extends Thread{ static HashMap<Integer, Integer> map=new HashMap<Integer, Integer>(1); static AtomicInteger aInteger=new AtomicInteger(); public void run(){ while(aInteger.get()<10000){ map.put(aInteger.get(), aInteger.get()); //sysout操作非常耗时,加入将很难遇到冲突。 //System.out.println(Thread.currentThread().getName()+"put了: "+aInteger.get()); aInteger.incrementAndGet(); } } public static void main(String[] args) throws InterruptedException { HashThreadTest t=new HashThreadTest(); Thread[] threads=new Thread[5]; for (int i = 0; i < 5; i++) { threads[i]=new Thread(t,"线程"+i); threads[i].start(); } //默认还有个守护线程 while (Thread.activeCount() > 2) { // Thread.currentThread().getThreadGroup().list(); Thread.yield(); } System.out.println(t.map.size()); int count=0; for(int i=0;i<10000;i++){ if(!t.map.containsKey(i)){ count++; //System.out.println("key: "+i+" is not contains"); } } System.out.println(t.map.size()); System.out.println(count); } }
多次运行后结果:
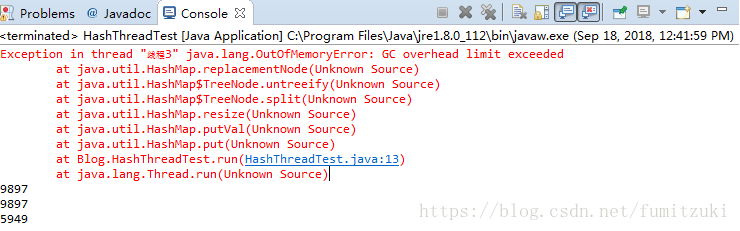
Map 综述(三):彻头彻尾理解 ConcurrentHashMap 这位dalao写的文章具体描述了在jdk1.6的情况下rehash造成的死循环。
但是在1.8中,引入了红黑树优化数组链表,同时改成了尾插,理论上是不会有环了,但在上面的结果中,还是出现了重哈希导致的问题。在优化为红黑树的链表中,重哈希的过程为:
1.resize()方法调用了split()方法拆分红黑树
2.接着调用untreeify()方法将拆分出来的树转换为链表
3.由于replacementNode这个方法会生成新的Node,所以产生的新链表不再具有树的信息了,原本的TreeNode会被gc。
我们看到因为奇怪的原因,gc失败,堆被撑爆了,我们看到了新的问题,
那么是什么情况造成了gc失败呢。这个问题我们来日再说!
非典型状况-数据丢失
我们将hashmap初始容量设置为最终的容量,这样就不会调用resize方法了,运行结果为:
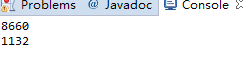
我们看到有大量的数据丢失。贴上put的源码
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //此时,已经拿到了头节点---① if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
在标注①的位置,线程已经拿到了头结点和hash桶,若此时cpu时间让出,而在该重新获得时间前,这个hash桶已经发被其他线程更改过,那么在该线程重入后,他将持有一个过期的桶和头结点,并且覆盖之前其他线程的记录,造成了数据丢失。
非典型状况-size()的值不准确
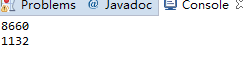
如果按照理论来说,上下数据加起来应该等于10000,说明size()函数在多线程的情况下也会出现问题。
另外设计一个实验,代码如下:
public class MapSize extends Thread { static HashMap<Integer, Integer> map = new HashMap<>(); static AtomicInteger aInteger=new AtomicInteger(); public void run() { while (aInteger.get()<1000) { map.put(aInteger.get(), aInteger.get()); map.remove(aInteger.get(), aInteger.get()); System.out.println(Thread.currentThread().getName()+"插入数据为:"+aInteger+" 此时容量为: "+map.size()); aInteger.incrementAndGet(); } }
}
当只有一个线程时
没有任何问题。
启用5个线程,结果:
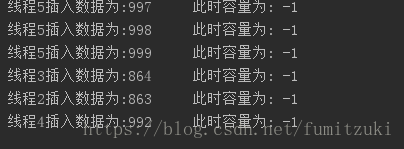
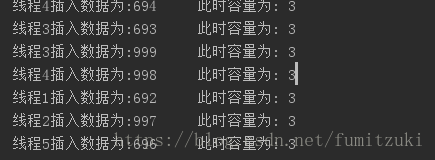
每次运行都会造成偏差,分析源码:
/** * The number of key-value mappings contained in this map. */ transient int size;
我们看到,size只是用了transient关键字修饰(不参与序列化),也就是说,在各个线程中的size副本不会及时同步,在多个线程操作的时候,size将会被覆盖。
————————————————
版权声明:本文为CSDN博主「fumitzuki」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fumitzuki/article/details/82760236

 浙公网安备 33010602011771号
浙公网安备 33010602011771号