
Build an ETL Pipeline With Kafka Connect via JDBC Connectors
This article is an in-depth tutorial for using Kafka to move data from PostgreSQL to Hadoop HDFS via JDBC connections.
Read this eGuide to discover the fundamental differences between iPaaS and dPaaS and how the innovative approach of dPaaS gets to the heart of today’s most pressing integration problems, brought to you in partnership with Liaison.
Tutorial: Discover how to build a pipeline with Kafka leveraging DataDirect PostgreSQL JDBC driver to move the data from PostgreSQL to HDFS. Let’s go streaming!
Apache Kafka is an open source distributed streaming platform which enables you to build streaming data pipelines between different applications. You can also build real-time streaming applications that interact with streams of data, focusing on providing a scalable, high throughput and low latency platform to interact with data streams.
Earlier this year, Apache Kafka announced a new tool called Kafka Connect which can helps users to easily move datasets in and out of Kafka using connectors, and it has support for JDBC connectors out of the box! One of the major benefits for DataDirect customers is that you can now easily build an ETL pipeline using Kafka leveraging your DataDirect JDBC drivers. Now you can easily connect and get the data from your data sources into Kafka and export the data from there to another data source.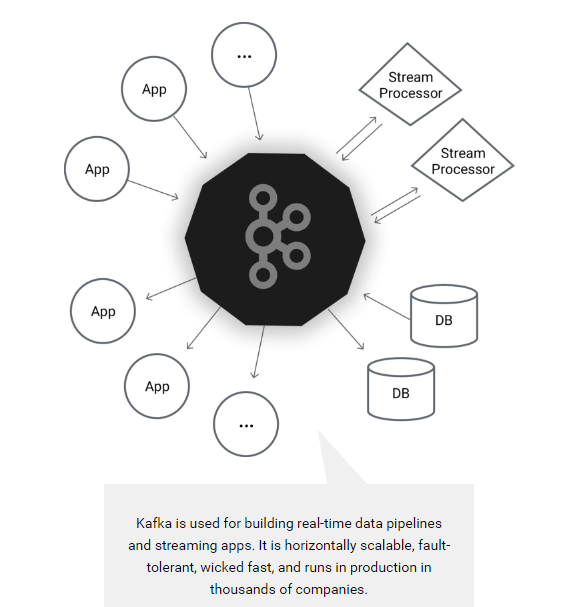
Image From https://kafka.apache.org/
Environment Setup
Before proceeding any further with this tutorial, make sure that you have installed the following and are configured properly. This tutorial is written assuming you are also working on Ubuntu 16.04 LTS, you have PostgreSQL, Apache Hadoop, and Hive installed.
- Installing Apache Kafka and required toolsTo make the installation process easier for people trying this out for the first time, we will be installing Confluent Platform. This takes care of installing Apache Kafka, Schema Registry and Kafka Connect which includes connectors for moving files, JDBC connectors and HDFS connector for Hadoop.
- To begin with, install Confluent’s public key by running the command:
wget -qO -http://packages.confluent.io/deb/2.0/archive.key | sudo apt-key add - - Now add the repository to your sources.list by running the following command:
sudo add-apt-repository "deb http://packages.confluent.io/deb/2.0 stable main" - Update your package lists and then install the Confluent platform by running the following commands:
sudo apt-get updatesudo apt-get install confluent-platform-2.11.7
- To begin with, install Confluent’s public key by running the command:
- Install DataDirect PostgreSQL JDBC driver
- Download DataDirect PostgreSQL JDBC driver by visiting here.
- Install the PostgreSQL JDBC driver by running the following command:
java -jar PROGRESS_DATADIRECT_JDBC_POSTGRESQL_ALL.jar - Follow the instructions on the screen to install the driver successfully (you can install the driver in evaluation mode where you can try it for 15 days, or in license mode, if you have bought the driver)
- Configuring data sources for Kafka Connect
- Create a new file called postgres.properties, paste the following configuration and save the file. To learn more about the modes that are being used in the below configuration file, visit this page.
name=test-postgres-jdbcconnector.class=io.confluent.connect.jdbc.JdbcSourceConnectortasks.max=1connection.url=jdbc:datadirect:postgresql://<;server>:<port>;User=<user>;Password=<password>;Database=<dbname>mode=timestamp+incrementingincrementing.column.name=<id>timestamp.column.name=<modifiedtimestamp>topic.prefix=test_jdbc_table.whitelist=actor - Create another file called hdfs.properties, paste the following configuration and save the file. To learn more about HDFS connector and configuration options used, visit this page.
name=hdfs-sinkconnector.class=io.confluent.connect.hdfs.HdfsSinkConnectortasks.max=1topics=test_jdbc_actorhdfs.url=hdfs://<;server>:<port>flush.size=2hive.metastore.uris=thrift://<;server>:<port>hive.integration=trueschema.compatibility=BACKWARD - Note that postgres.properties and hdfs.properties have basically the connection configuration details and behavior of the JDBC and HDFS connectors.
- Create a symbolic link for DataDirect Postgres JDBC driver in Hive lib folder by using the following command:
ln -s /path/to/datadirect/lib/postgresql.jar /path/to/hive/lib/postgresql.jar - Also make the DataDirect Postgres JDBC driver available on Kafka Connect process’s CLASSPATH by running the following command:
export CLASSPATH=/path/to/datadirect/lib/postgresql.jar - Start the Hadoop cluster by running following commands:
cd /path/to/hadoop/sbin./start-dfs.sh./start-yarn.sh
- Create a new file called postgres.properties, paste the following configuration and save the file. To learn more about the modes that are being used in the below configuration file, visit this page.
- Configuring and running Kafka Services
- Download the configuration files for Kafka, zookeeper and schema-registry services
- Start the Zookeeper service by providing the zookeeper.properties file path as a parameter by using the command:
zookeeper-server-start /path/to/zookeeper.properties - Start the Kafka service by providing the server.properties file path as a parameter by using the command:
kafka-server-start /path/to/server.properties - Start the Schema registry service by providing the schema-registry.properties file path as a parameter by using the command:
schema-registry-start /path/to/ schema-registry.properties
Ingesting Data Into HDFS using Kafka Connect
To start ingesting data from PostgreSQL, the final thing that you have to do is start Kafka Connect. You can start Kafka Connect by running the following command:
connect-standalone /path/to/connect-avro-standalone.properties \ /path/to/postgres.properties /path/to/hdfs.properties
This will import the data from PostgreSQL to Kafka using DataDirect PostgreSQL JDBC drivers and create a topic with name test_jdbc_actor. Then the data is exported from Kafka to HDFS by reading the topic test_jdbc_actor through the HDFS connector. The data stays in Kafka, so you can reuse it to export to any other data sources.
Next Steps
We hope this tutorial helped you understand on how you can build a simple ETL pipeline using Kafka Connect leveraging DataDirect PostgreSQL JDBC drivers. This tutorial is not limited to PostgreSQL. In fact, you can create ETL pipelines leveraging any of our DataDirect JDBC drivers that we offer for Relational databases like Oracle, DB2 and SQL Server, Cloud sources likeSalesforce and Eloqua or BigData sources like CDH Hive, Spark SQL and Cassandra by following similar steps. Also, subscribe to our blog via email or RSS feed for more awesome tutorials.
Discover the unprecedented possibilities and challenges, created by today’s fast paced data climate andwhy your current integration solution is not enough, brought to you in partnership with Liaison.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号