Scrapy小问题总结
- 数据提取
- response.xpath(........./text()).extract_first( )
- 提取xpath到的第一个文本
- response.xpath(.........//text()).extract( )
- 提取xpath到的所有文本,其中可能有br分段
- 请求传参
- 在请求传参过程中可以使用meta将主函数的item和其他参数传给回调函数
![]()
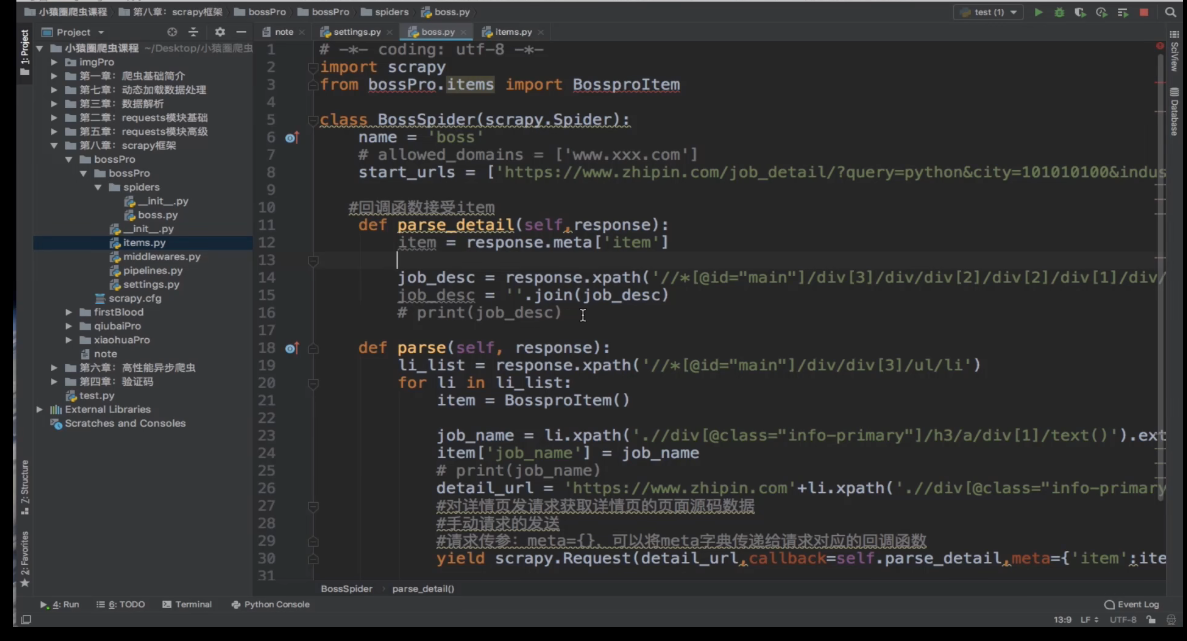
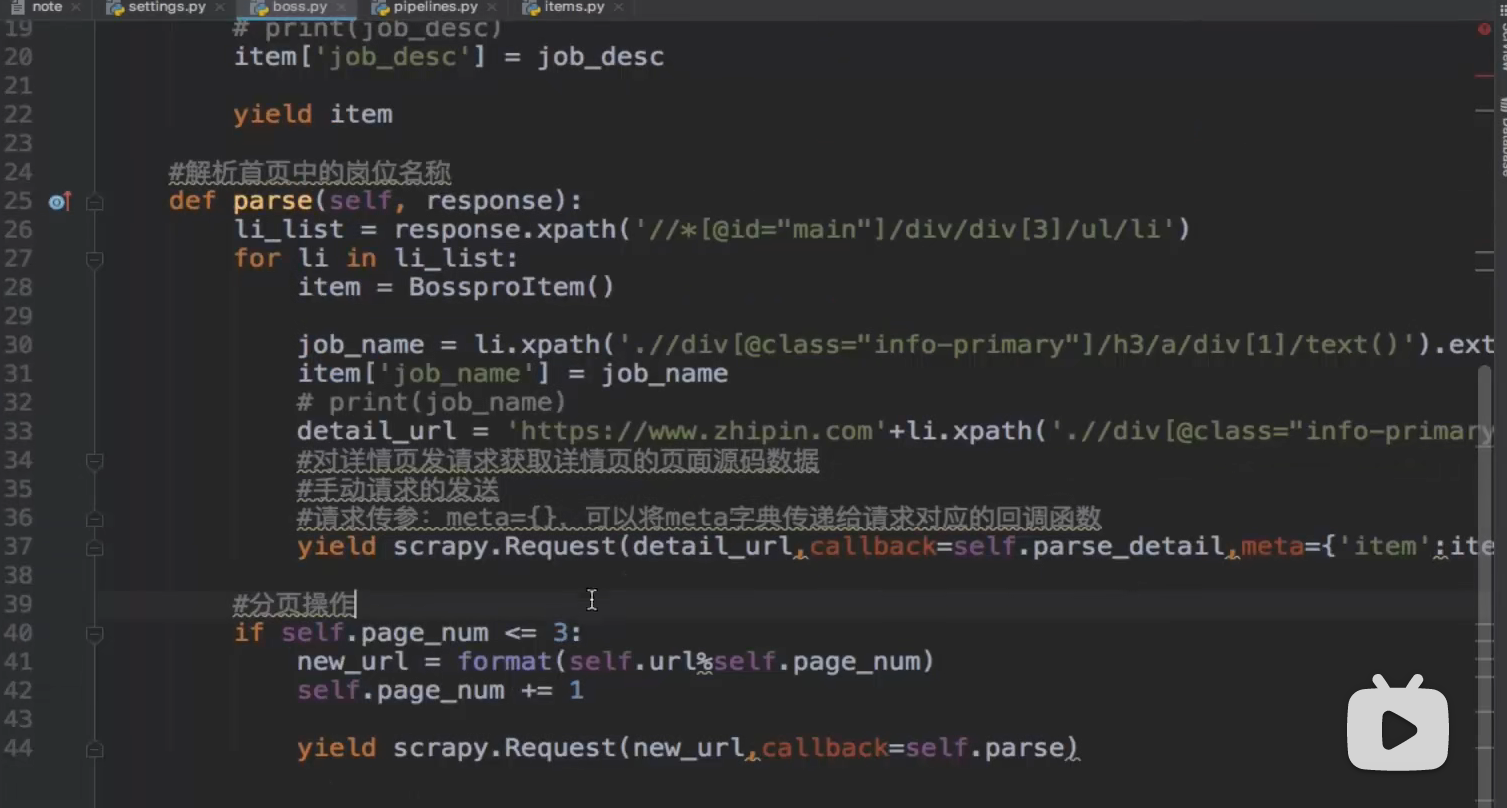
- 递归法全站数据爬取(分页操作)
- 前提是分页后网页网址相应参数会随页面递增则可用递归法,每次将页数加到网址中递归调用爬虫函数
![]()
![]()

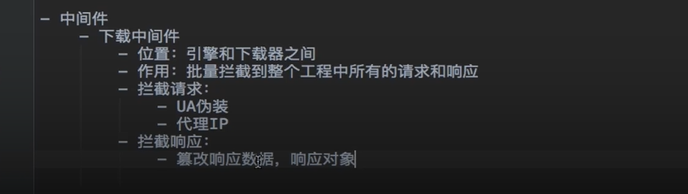
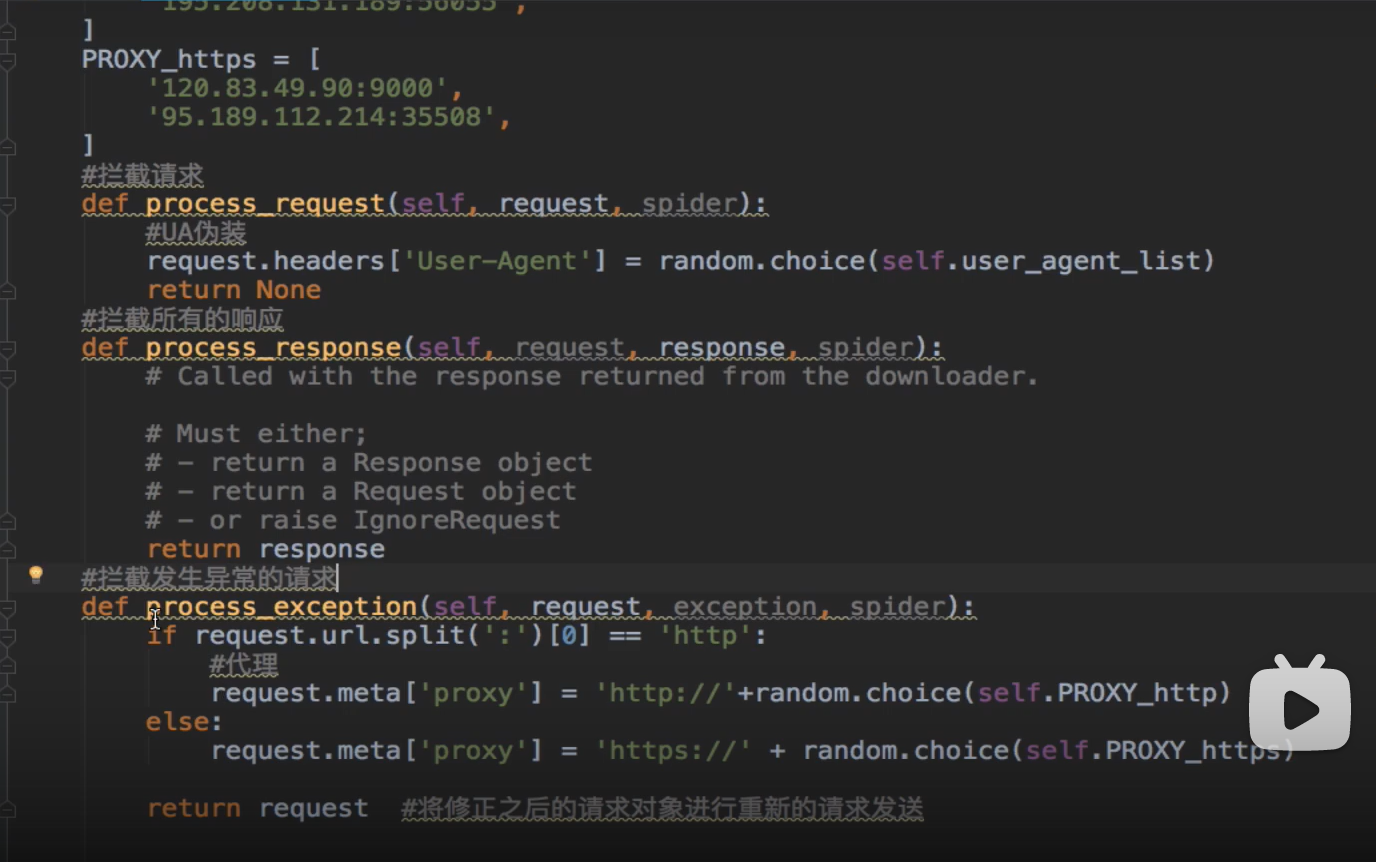
- 下载中间件
![]()
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号