爬虫学习一(web请求基础知识)
Web请求过程:
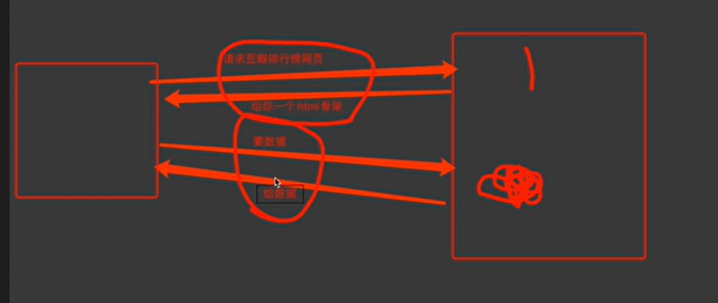
- 服务器渲染:收到请求后服务器把请求的数据和html整合在一起打包返回给浏览器,只需要一次访问就能得到想要的数据,查看网页源代码可以找到相应数据。
- 客户端渲染:收到请求后服务器直接返回网页骨架,但是没有数据,需要第二次请求数据才能得到相应数据,查看网页源代码没有相应数据,通过浏览器两次收到的内容(网页框架+数据)拼接在一起,这种需要使用浏览器抓包工具(f12)抓取数据。
http协议:
- 传递网站相关内容,规定数据传送的格式
- 请求
- 请求行:请求方式(get\post)抓包工具中会显示我们应该用哪个,请求url地址
- 请求头:存放服务器的附加信息,如headers等,user-agent:请求载体的身份标识(即用什么发送的请求),referer:防盗链,标识这次请求从哪来的,用于反爬,cookie:本地字符串数据信息(用户登录信息,反爬的token)
- 请求体:存放请求参数
- 响应
- 状态行:协议、状态码(200表示请求正确)
- 响应头:存放客户端要使用的附加信息(如cookie),
- 响应体:服务器返回的客户端真正需要的内容(html,json等)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号