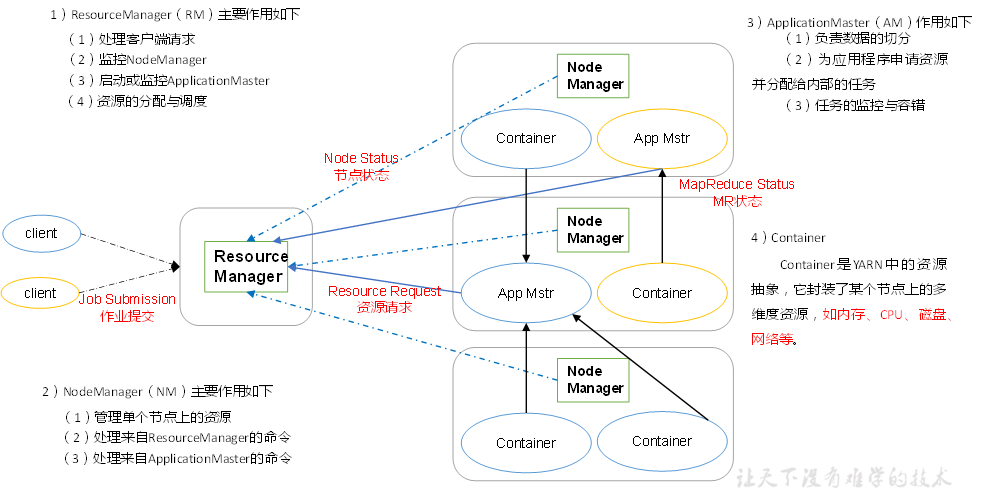
yarn架构
一、yarn的架构
二、yarn的工作机制
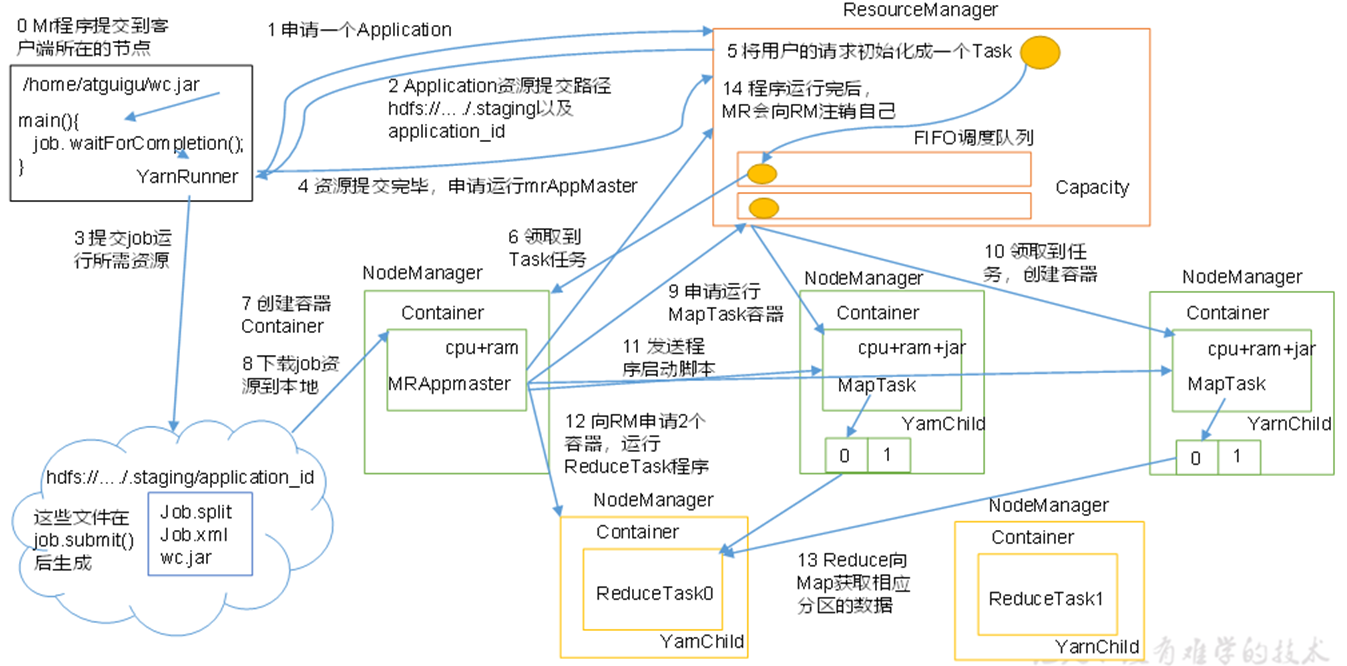
(0)Mr 程序提交到客户端所在的节点。
(1)Yarnrunner 向 Resourcemanager 申请一个 Application。
(2)rm 将该应用程序的资源路径返回给 yarnrunner。
(3)该程序将运行所需资源提交到 HDFS 上。
(4)程序资源提交完毕后,申请运行 mrAppMaster。
(5)RM 将用户的请求初始化成一个 task。
(6)其中一个 NodeManager 领取到 task 任务。
(7)该 NodeManager 创建容器 Container,并产生 MRAppmaster。
(8)Container 从 HDFS 上拷贝资源到本地。
(9)MRAppmaster 向 RM 申请运行 maptask 资源。
(10)RM 将运行 maptask 任务分配给另外两个 NodeManager,另两个 NodeManager 分别领取任务并创建容器。
(11)MR 向两个接收到任务的 NodeManager 发送程序启动脚本,这两个 NodeManager分别启动 maptask,maptask 对数据分区排序。
(12)MrAppMaster 等待所有 maptask 运行完毕后,向 RM 申请容器,运行 reduce task。
(13)reduce task 向 maptask 获取相应分区的数据。
(14)程序运行完毕后,MR 会向 RM 申请注销自己。
三、yarn的调度器
1.分类
FIFO、Capacity Scheduler(容量调度器)和Fair Scheduler(公平调度器)。
Hadoop2.7默认的是容量调度器。
2.区别
① FIFO调度器:先进先出,同一时间队列中只有一个任务在执行
② 容量调度器:多个队列,每个队列内部先进先出,同一时间队列只有一个任务在执行,队列的并行度为队伍的个数
③公平调度器:多队列,同一时间队列中有多个任务执行。根据提交任务的队列级别平分资源(默认以用户名为队列),队列可以多级嵌套
假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,
不过一会儿之后两个任务会各自获得一半的集群资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号