
大数据学习——hdfs集群启动
第一种方式:
1 格式化namecode(是对namecode进行格式化)
hdfs namenode -format(或者是hadoop namenode -format)
进入 cd /root/apps/hadoop/tmp/dfs/name/current
启动namecode hadoop-daemon.sh start namenode

启动datanode hadoop-daemon.sh start datanode
其他两台机器也执行下 hadoop-daemon.sh start datanode
mini1启动sn:
hadoop-daemon.sh start secondarynamenode
第二种方式:
先启动hdfs
sbin/start-dfs.sh
再启动yarn
sbin/start-yarn.sh
验证是否启动成功
1 jps查看进程
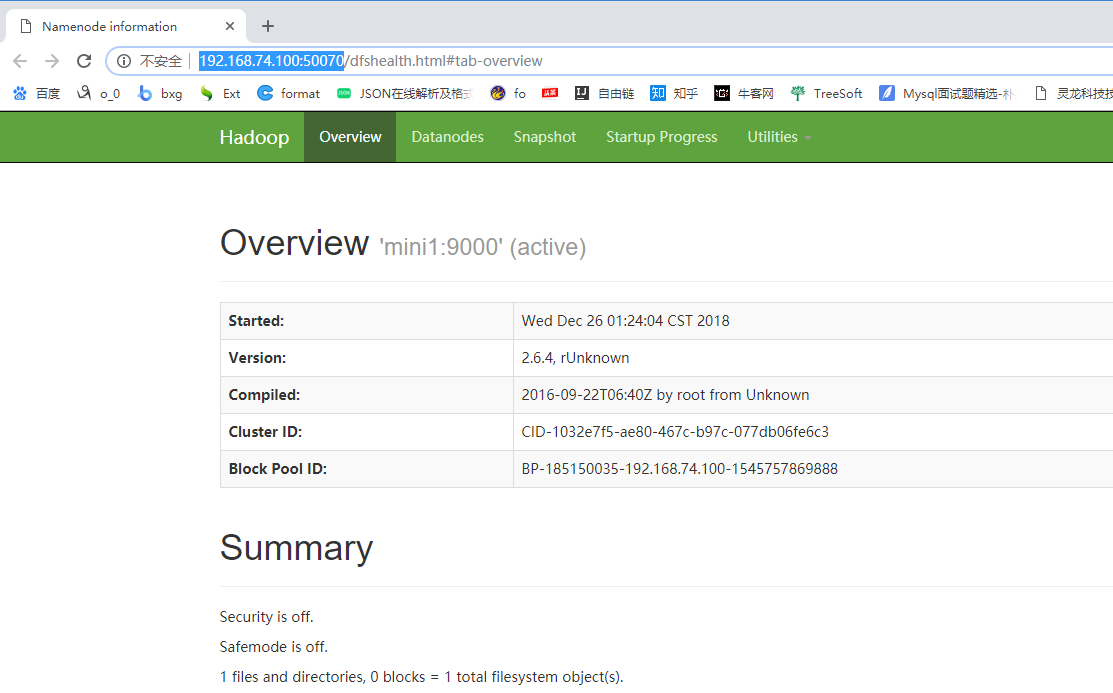
2 http://192.168.74.100:50070 查看
3 上传一个文件测试一下
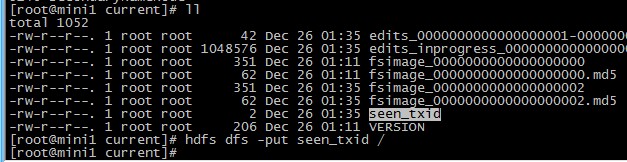
hdfs dfs -put seen_txid /
打开 http://192.168.74.100:50070 utilities——Brows the file system 可以查看到上传的文件
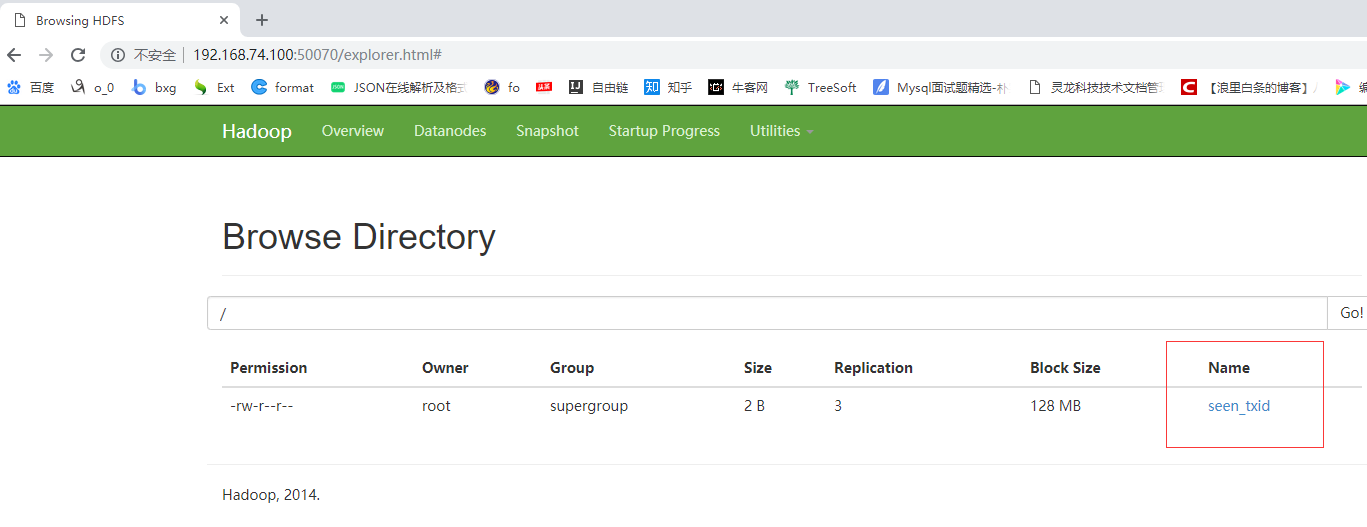
Browse Directory
集群关闭
1 手动关闭
2 一键关闭
cd /root/apps/hadoop/sbin/
stop-dfs.sh
配置 slaves
vi salves
写入
mini1
mini2
mini3
保存退出
mv ./slaves /root/apps/hadoop/etc/hadoop/
拷贝到另外两台机器
scp -r /root/apps/hadoop/etc/hadoop/slaves root@mini2:/root/apps/hadoop/etc/hadoop/
scp -r /root/apps/hadoop/etc/hadoop/slaves root@mini3:/root/apps/hadoop/etc/hadoop/
一键启动集群
start-dfs.sh
一键关闭集群
stop-dfs.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号