译文:DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
摘要 - 场景刚度假设在SLAM算法中是典型的。 如此强烈的假设限制了大多数视觉SLAM系统在人口密集的现实环境中的使用,这些环境是服务机器人或自动驾驶车辆等几个相关应用的目标。
在本文中,我们介绍了DynaSLAM,一个基于ORB-SLAM2 [1]的视觉SLAM系统,增加了动态对象检测和背景修复的功能。 DynaSLAM在单目,双目和RGB-D配置的动态场景中非常强大。我们能够通过多视图几何,深度学习或两者来检测移动对象。拥有场景的静态地图允许修复已被这些动态对象遮挡的帧背景。
我们在公共单目,双目和RGB-D数据集中评估我们的系统。 我们研究了几种准确性/速度权衡的影响,以评估所提方法的局限性。 DynaSLAM在高度动态的场景中优于标准可视SLAM基线的准确性。 它还估计了场景的静态部分的地图,这是在现实世界环境中长期应用的必要条件。
I. INTRODUCTION
同时定位和映射(SLAM)是许多机器人应用程序的先决条件,例如无碰撞导航。SLAM技术仅通过其机载传感器的数据流共同估计未知环境的地图和这种地图内的机器人姿态。 该地图允许机器人在相同的环境中连续定位而不会累积漂移。这与将测量增量运动集成在局部窗口内并且在重新访问场所时无法校正漂移的里程计方法形成对比。
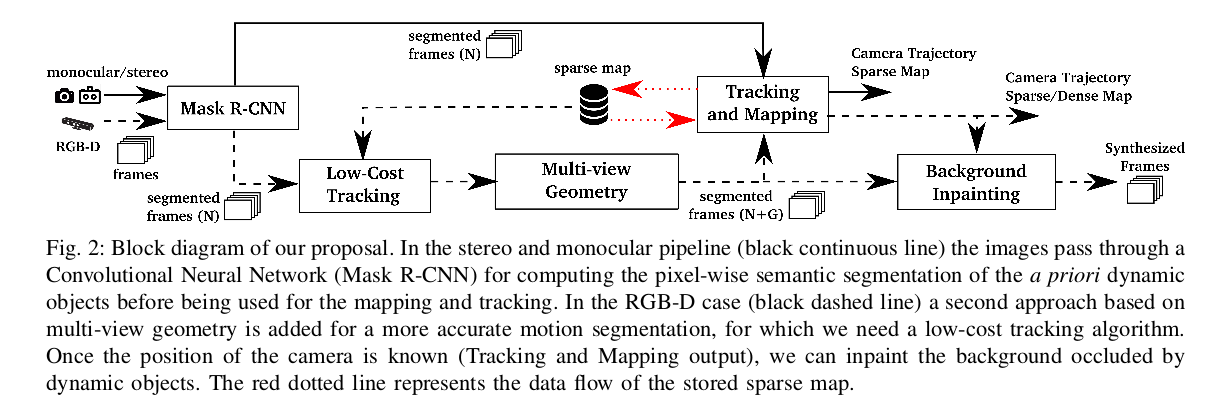
A. Segmentation of Potentially Dynamic Content using a CNN
为了检测动态对象,我们建议使用CNN来获得图像的逐像素语义分段。 在我们的实验中,我们使用Mask R-CNN [19],这是对象实例分割的最新技术。 掩码R-CNN可以获得逐像素语义分割和实例标签。 对于这项工作,我们使用像素方式的语义分割信息,但实例标签可能在将来跟踪不同移动对象的工作中很有用。 我们使用Matterport 1的TensorFlow实现。
Mask R-CNN的输入是RGB原始图像。 这个想法是划分那些潜在动态或可移动的类(人,自行车,汽车,摩托车,飞机,公共汽车,火车,卡车,船,鸟,猫,狗,马,羊,牛,大象,熊,斑马和 长颈鹿)。 我们认为,对于大多数环境,可能出现的动态对象都包含在此列表中。 如果需要其他类,可以使用新的训练数据对在MS COCO [20]上训练的网络进行微调。
假设输入是大小为m×n×3的RGB图像,网络的输出是大小为m×n×1的矩阵,其中l是图像中的对象的数量。 对于每个输出通道i∈1,获得二元掩模。 通过将所有通道组合成一个,我们可以获得出现在场景的一个图像中的所有动态对象的分割。
B. Low-Cost Tracking
在潜在动态内容被分割之后,使用图像的静态部分跟踪相机的姿势。 由于线段轮廓通常成为高梯度区域,因此突出点特征趋于出现。 我们不考虑这种轮廓区域的特征。
在算法的这个阶段实现的跟踪是ORB-SLAM2 [1]中更简单,因此计算更轻的版本。 它在图像框架中投影地图要素,搜索图像静态区域中的对应关系,并最小化重投影错误以优化相机姿势。
C. Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry
通过使用Mask R-CNN,大多数动态对象可以被分段,不用于跟踪和映射。但是,有些对象无法通过这种方法检测到,因为它们不是先验动态,而是可移动的。最新的示例 是由某人携带的书,有人正在移动的椅子,甚至是长期制图中的家具变化。 本节详细介绍了处理这些案例的方法。
对于每个输入框架,我们选择具有最高重叠的先前关键帧。 这是通过考虑新框架和每个关键帧之间的距离和旋转来完成的,类似于Tan等人[9]。 在我们的实验中,重叠关键帧的数量已经设置为5,作为计算成本和动态对象检测精度之间的折衷。
然后,我们计算每个关键点x从先前关键帧到当前帧的投影,获得关键点x 0,以及根据相机运动计算的投影深度z proj。 请注意,关键点x来自ORB-SLAM2中使用的特征提取器算法。对于其对应的3D点是X的每个关键点,我们计算x和x 0的背投影之间的角度,即它们的视差角α。如果此角度大于30°,则该点可能会被遮挡,并且从那时起将被忽略。我们观察到,在TUM数据集中,对于大于30°的视差角,静态物体由于它们的视点差异而被认为是动态的。我们在考虑到重投影误差的情况下获得当前帧z 0中的剩余关键点的深度(直接来自深度测量),并且我们将它们与z proj进行比较。如果差Δz= z proj-z 0超过阈值τz,则关键点x 0被认为属于动态对象。这个想法如图3所示。为了设置阈值τz,我们手动标记了TUM数据集中30个图像的动态对象,并评估了不同阈值τz的方法的精度和召回率。通过最大化表达式0.7×P recision + 0.3×Recall,我们得出结论,τz= 0.4m是一个合理的选择。


标记为动态的一些关键点位于移动对象的边界上,可能会导致问题。 为了避免这种情况,我们使用深度图像给出的信息。如果关键点设置为动态,但深度图中的自身周围的补丁具有高方差,我们将标签更改为静态。
到目前为止,我们知道哪些关键点属于动态对象,哪些关键点不属于动态对象。 为了对属于动态对象的所有像素进行分类,我们在动态像素周围的深度图像中增长区域[21]。 在图4a中可以看到RGB帧的示例及其对应的动态掩模。
CNN的结果(图4b)可以与这种几何方法的结果相结合,用于全动态物体检测(图4c)。 我们可以在两种方法中找到优势和局限,因此可以综合运用它们。 对于几何方法,主要问题是初始化因其多视图性质而不是微不足道的。使用单一视图学习方法及其令人印象深刻的性能,没有这样的初始化问题。 但它们的主要限制是可以移动应该是静态的对象,并且该方法无法识别它们。 最后一种情况可以使用多视图一致性测试来解决。
面对运动物体检测问题的这两种方式在图4中示出。在图4a中,我们看到后面的人,其可能是动态物体,未被检测到。 有两个原因。 首先,RGB-D相机在测量远处物体的深度时面临的困难。 其次,可靠的特征在于定义的,因此附近的图像部分。 尽管如此,这个人是通过深度学习方法检测到的(图4b)。 除此之外,一方面我们在图4a中看到,不仅检测到图像前面的人,还检测到他正拿着的书和他坐的椅子。 另一方面,在图4b中,两个人是唯一被检测为动态的对象,并且它们的分割也不太准确。 如果仅使用深度学习方法,则浮动书将留在图像中并且将错误地成为3D地图的一部分。
由于两种方法的优点和缺点,我们认为它们是互补的,因此它们的组合使用是实现精确跟踪和映射的有效方式。 为了实现这一目标,如果用两种方法检测到对象,则分割掩模应该是几何方法的分割掩模。 如果仅通过基于学习的方法检测到对象,则分段掩码也应包含该信息。 可以在图4c中看到前一段中的示例的最终分段图像。 分割的动态部分将从当前帧和地图中删除。
D. Tracking and Mapping
系统此阶段的输入包含RGB和深度图像,以及它们的分割掩码。 我们在分类为静态的图像片段中提取ORB特征。 由于线段轮廓是高梯度区域,因此必须删除落在此交叉点中的关键点。

E. Background Inpainting
对于每个被移除的动态对象,我们的目标是使用来自先前视图的静态信息来修复被遮挡的背景,以便我们可以在不移动内容的情况下合成逼真的图像。 我们相信这种包含环境静态结构的合成帧对于虚拟和增强现实等应用非常有用,并且在创建地图后可用于重定位和相机跟踪。
由于我们知道前一帧和当前帧的位置,因此我们将当前帧的动态片段投影到一组所有先前关键帧(我们实验中的最后20个)中的RGB和深度通道。 一些间隙没有对应关系并且留空:某些区域无法修复,因为它们的相应部分在关键帧中没有出现,或者,如果它已经出现,则它没有有效的深度信息。 这些间隙不能用几何方法重建,需要更精细的修复技术。 图5示出了来自TUM基准的不同序列的三个输入帧的合成图像。 请注意如何成功分割和删除动态内容。 此外,大多数分段部分已经适当地修复了来自静态背景的信息。
这些合成帧的另一个应用如下:如果帧动态区域被静态内容修复,则系统可以在静态假设下使用修复图像作为SLAM系统工作。
IV. EXPERIMENTAL RESULTS
我们在公共数据集TUM RGB-D和KITTI中评估了我们的系统,并与动态环境中的其他最先进的SLAM系统进行了比较,使用了原始论文中公布的可能结果。 此外,我们将我们的系统与原始的ORB-SLAM2进行了比较,以量化我们在动态场景中的方法的改进。在这种情况下,某些序列的结果未公布,我们自己完成了评估。 Mur和Tardós[1]建议运行每个序列五次并显示中位数结果,以说明系统的非确定性。 我们已经运行了十次每个序列,因为动态对象倾向于增加这种非确定性效果。
A. TUM Dataset

根据表I,使用学习和几何的系统(N + G)在大多数序列中是最准确的。对(N)的改进来自可移动对象的分割和动态分段的细化。系统(G) )因为它需要运动并且其分段仅在一小段延迟之后才准确,因此动态内容在估计中引入了一些误差。
在摄像机定位之前添加背景修复阶段(BI)(图6)通常会导致跟踪精度降低。 原因是背景重建与相机姿势密切相关。 因此,对于具有纯旋转运动(rpy,半球)的序列,估计的相机姿势具有更大的误差并导致不准确的背景重建。因此,一旦跟踪阶段结束,应该完成背景修复阶段(BI)(图2)。 背景重建的主要成就见于静态图像的合成(图5),用于虚拟现实或电影摄影等应用。 从现在开始显示的DynaSLAM结果来自最佳变体,即(N + G)。

表II显示了我们对相同序列的结果,与RGB-D ORB-SLAM2进行了比较。 我们的方法在高度动态的场景(步行)中优于ORB-SLAM2,在静态场景中达到类似于原始RGB-D ORB-SLAM2系统的误差。
在低动态场景(坐着)的情况下,跟踪结果稍微差一些,因为跟踪的关键点发现自己比属于动态对象的关键点更远。 尽管如此,DynaSLAM的地图不包含沿序列出现的动态对象。 图7显示了与地面实况相比的DynaSLAM和ORB-SLAM2的估计轨迹的示例。

表III显示了我们的系统与为动态环境设计的几种最先进的RGB-D SLAM系统之间的比较。考虑到我们和最先进的运动检测方法(与所使用的SLAM系统无关)的有效性,我们还显示了针对在每种情况下使用的原始SLAM系统的相应改进值。 DynaSLAM在所有序列(高动态和低动态序列)中都明显优于所有序列。 该误差通常约为1-2厘米,类似于静态场景中的现有技术。我们的运动检测方法也优于其他方法。
ORB-SLAM是ORB-SLAM2的单目版本,由于它们的初始化算法不同,它们在动态场景中通常比RGB-D更准确。


RGB-D ORB-SLAM2被初始化并从第一帧开始跟踪,因此动态对象可能引入错误。 ORB-SLAM延迟初始化,直到使用静态假设存在视差和共识。 因此,它不会跟踪相机的完整序列,有时会遗漏相机的大部分,甚至不会初始化。
表IV显示了TUM数据集中ORB-SLAM和DynaSLAM(单目)的跟踪结果和跟踪轨迹的百分比。 DynaSLAM中的初始化总是比ORB-SLAM更快。 事实上,在高度动态的序列中,ORB-SLAM初始化仅在移动对象从场景中消失时才会发生。 总之,虽然DynaSLAM的准确性略低,但它成功地用动态内容引导系统并产生没有这种内容的地图(见图1),以便重新用于长期应用。 DynaSLAM稍微不准确的原因是估计的轨迹更长,因此存在累积误差的空间。

B. KITTI Dataset
KITTI数据集[23]包含从城市和高速公路环境中的汽车记录的双目序列。表V显示我们在11个训练序列中的结果,与双目ORB-SLAM2进行比较。 我们使用两个不同的度量,[22]中提出的绝对轨迹RMSE,以及[23]中提出的平均相对平移和旋转误差。 表VI显示了ORB-SLAM和DynaSLAM的单目变体的相同序列的结果。

请注意,单目和双目情况下的结果相似,但前者对动态对象更敏感,因此对DynaSLAM中的添加更敏感。 在一些序列中,当不使用属于先验动态对象的特征(即,汽车,自行车等)时,跟踪的准确性得到改善。这样的示例是序列KITTI 01和KITTI 04,其中出现的所有车辆正在移动。在大多数记录的汽车和车辆停放的序列中(因此是静态的),绝对轨迹RMSE通常更大,因为用于跟踪的关键点更远并且通常属于低纹理区域(KITTI 00,KITTI 02,KITTI06)。 然而,循环闭合和重定位算法更加鲁棒地工作,因为得到的映射仅包含结构对象,即,映射可以被重用并且在长期应用中工作。
作为未来的工作,通过仅使用RGB信息来区分可移动和移动对象是有趣的。 如果CNN检测到汽车(可移动)但当前没有移动,则其相应的关键点应该用于本地跟踪,但不应该在地图中。
C. Timing Analysis
为完成对我们提案的评估,表VII显示了其不同阶段的平均计算时间。请注意,DynaSLAM未针对实时操作进行优化。 但是,它创建静态场景内容的终身地图的能力也与在离线模式下运行相关。

Mur等人展示了ORB-SLAM2 [1]的实时结果[1] He等[19]报道,在Nvidia Tesla M40 GPU上,Mask R-CNN每张图像运行195 ms。
多视图几何阶段的增加是一个额外的减速,主要是由于区域增长算法。背景修复也引入了延迟,这是它应该在跟踪和映射阶段之后完成的另一个原因,因为它已经显示 在图2中。
V. CONCLUSIONS
我们提出了一种视觉SLAM系统,该系统基于ORB-SLAM,增加了一种运动分割方法,使其在单目,立体和RGB-D相机的动态环境中具有强大的稳定性。 我们的系统可以精确地跟踪摄像机并创建静态且因此可重复使用的场景地图。 在RGB-D情况下,DynaSLAM能够获得没有动态内容且具有被遮挡的背景的合成RGB帧,以及它们相应的合成深度帧,这些帧可能对虚拟现实应用非常有用。 我们提供了一个显示DynaSLAM 2潜力的视频。
与现有技术的比较表明,DynaSLAM在大多数情况下达到了最高的准确度。
在TUM动态对象数据集中,DynaSLAM是目前最好的RGB-D SLAM解决方案。 在单目情况下,我们的精度类似于ORB-SLAM的精度,但是通过较早的初始化获得场景的静态映射。
在KITTI数据集中,DynaSLAM比单目和双目ORB-SLAM稍微不准确,除了动态对象代表场景的重要部分的那些情况。 但是,我们的估计地图仅包含结构对象,因此可以在长期应用程序中重复使用。
这项工作的未来扩展可能包括实时性能,基于RGB的运动检测器,或通过使用更精细的修复技术,例如Pathak等人使用的技术,更合理的RGB帧的更逼真的外观。 [24]通过使用GAN。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号